道阻且長,行則將至,請相信我,你一定會更優秀!
「 人人都聽過的雪花演算法,你真的推敲過嗎?」
很多人聽過或用過雪花演算法,可是到底一個ID是如何計算出來的,沒幾個講明白,別上來就跟我聊時鐘回撥的問題,貌似你很懂一樣,首先這是個演算法,你先給我寫個代碼我看看?
技術人要對自己寫的每一行代碼負責,靜下心來,我帶你吃透雪花演算法,關于分布式ID的文章有很多,你可以自己去查閱,此處我們不再贅述,本文只聊雪花演算法,
目錄
一、為啥叫雪花?
二、技術設計點剖析
1、技術背景
a. 我們希望一個id有以下2個特性足以:
b. 我們希望id服務有以下幾個特點:
c. 綜上,雪花演算法的id由以下部分組成,完美匹配我們想要的規則:
d. 為啥不用納秒?納秒不是更精確嗎,更不容易沖突嗎?
2、twepoch 這個是干嘛的?
a. 那這個時間起啥作用?我們用的時候,這個時間寫什么呢?
3、假如同一毫秒內,12個bit位的序列自增用完了,咋辦?
4、如何判斷序列號用完了?比大小嗎?
5、計算 id的移位操作,是如何移位的?
6、生成的 id是單調遞增、趨勢遞增的,會出現第2次拿到的比第1次拿到的id小嗎?
7、生成 id的長度有多長?
8、這個 id的位數分配規則,自己能調整嗎?
9、workerId怎么計算的?
三、安全問題
1、時鐘回撥,即時間走著走著卻倒回去了,如何解決?
2、新起的節點中,機器時間不對,那就壓根不能提供服務,如何校正?
3、業務上,通過 getById 介面遍歷能拿走多少越權資料?
4、友商是否可以決議你的 id大概計算出你的業務量?
一、為啥叫雪花?
世界上沒有兩片完全相同的雪花,任何一個技術設計,都值得有一個代號,都值得有自己的 slogan 并為之努力讓它產生價值,
二、技術設計點剖析
雪花演算法的源代碼或者優秀代碼示例有很多,但思想是一樣的,我們這里不再一行行寫代碼,把里邊的關鍵代碼拿出來決議即可,這里提供一個代碼示例:https://github.com/Meituan-Dianping/Leaf,是美團的雪花演算法代碼實作(個人認為,美團開源出的代碼真的很糟糕,內部一定是有另外一套,這個代碼只是供大家參考的,不過不影響核心邏輯),不管你有沒有讀過雪花演算法代碼,關鍵的代碼我會在下邊一個個剖析,讀懂這些關鍵點,你就掌握了雪花演算法,
1、技術背景
a. 我們希望一個id有以下2個特性足以:
- 純正整數,占用記憶體小
- 遞增,后一個大于前一個,且多節點時依然這樣
第1條,純數字好說,十進制,不出現字母就行,表中用 bigint表示,對應 java中用 long表示即可(均占用8個byte,64個bit);
第2條,遞增,那我們就想,什么是遞增的?時間呀,時間天然是遞增的;那多個節點在同一時間不就生成了相同的id了?再加上每個節點的唯一標識;同一時間內有多個請求咋辦?再加上個序列號,就這點事,
b. 我們希望id服務有以下幾個特點:
- 速度快,并發高
- 支持集群高可用HA
- 對業務系統無侵入,與業務系統松耦合
第1條,速度快:純記憶體操作就可以,1s出100萬,夠用吧
第2條,可集群部署,且id也是遞增狀態,且單節點故障不影響集群HA
第3條,與業務系統松耦合,遵循業務各服務間呼叫方式即可,如業務系統服務呼叫使用Dubbo,此id服務也是Dubbo服務提供出去就好
c. 綜上,雪花演算法的id由以下部分組成,完美匹配我們想要的規則:
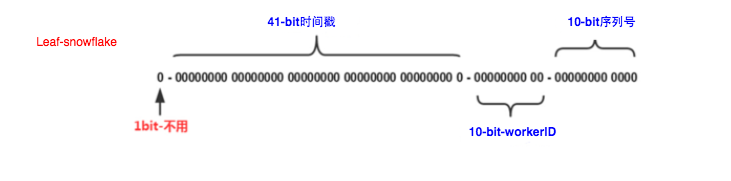
分析:一共 64個bit,占用 8個位元組,MySQL中是 bigint表示,java中是 long表示,注意是64個bit運算表示出一個數字,而不是幾個段的數字用字串拼接起來!
1個bit:第0位,符號位,0只要正數
41個bit:毫秒時間戳的數字,注意,和時間本身沒有任何關系,只是借助了時間戳的數字,要理解清楚,很重要
10個bit:集群部署的話,為避免不同節點生成出相同的id,給每個節點一個唯一的數字標識
10個bit:同1毫秒內,同一節點,需要多個id的話,用序列號自增記住上邊的位數分配,下邊會逐個決議,
d. 為啥不用納秒?納秒不是更精確嗎,更不容易沖突嗎?
- 你的業務并發需要納秒級別的嗎?1ms=1,000,000ns 我的業務并發連毫秒都到不了,然后我這里花時間、花記憶體去計算/存盤納秒?再說了,CPU主頻2G的時鐘周期算下來才 0.5ns,你上層建筑空想啥呢?毫無意義!
- 我們一共只有64個bit,要做好幾件事情呢,合理分配,省著點,留著bit給其他段用吧;
- 所以,用毫秒ms時間戳表示足以;
2、twepoch 這個是干嘛的?
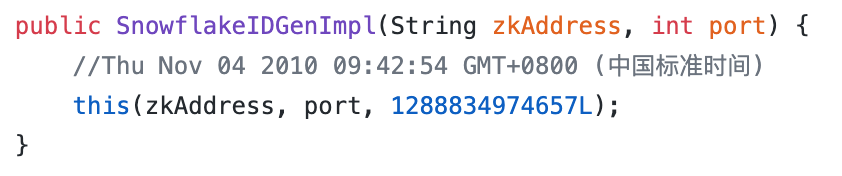
注意這行注釋:
//Thu Nov 04 2010 09:42:54 GMT+0800 (中國標準時間)首先要清楚,這個時間對于我們來說,不是什么特殊的時間點,對我們來講沒有意義,或許是美團內部開始用雪花演算法的時間點,我們不用研究這個時間,
a. 那這個時間起啥作用?我們用的時候,這個時間寫什么呢?
上邊說過用 41個bit表示時間戳,如果41個bit都占滿,能表示的最大數字是:2199023255551,也就是 2199023255551個毫秒,這么多毫秒換算下來是大概 69年,
2199023255551 / 1000 / 60 / 60 / 24 / 365 ≈ 69
毫秒 / 秒 /分鐘/ 小時 / 天 / 年也就是說,從這 41個bit都是0開始計算,到 41個bit都用滿,需要 69年的毫秒時間戳才能填滿,
可關鍵是不可能是從0開始呀,當前、現在的時間戳已經是一個很大的數字,那要是從現在開始算的話,能用多少年呢?(從0開始算只是理論值而已)
ok,繼續看代碼:
long id = ((timestamp - twepoch) << timestampLeftShift) | (workerId << workerIdShift) | sequence;為啥要減去 twepoch呢?(timestamp - twepoch),如果不減這個 twepoch,問題就出現了,我們的 69年算的是從 0開始計算,但是假如我們是 2021-05-05才開始用的雪花演算法,也就是說我們第一次使用的時候,就已經從 1620179006000時間戳開始了,不是從 0開始的,這個數字會浪費掉我的 41bit能表示的資料集中的一大部分,所以,必須要減,因為我才今天剛開始用,要從我的投產時間開始算的,如果不減我們會浪費掉多少呢?
1620179006000 / 1000 / 60 / 60 / 24 / 365 ≈ 51
毫秒 / 秒 /分鐘/ 小時 / 天 / 年也就是說,本來我的 41個bit夠我用 69年,但是剛一投產,就耗掉了51年的,剩下的只夠我用 69-51=18年!
那么我們的這個 twepoch設定為多少呢?
比方說我們是 2021-05-05 上線,雖然是我們第一次使用的時間,但是我們不能這么設定,因為我們有業務歷史資料,如果這個時間設定的不對,一定會遇到和現有id沖突的情況!可以設定一個公司成立或者業務線開始的時間,現在的時間和指定的時間點的差集耗掉的數字,我們認了,如果你是全新的開始,那完全可以設定為投產時間即可,
3、假如同一毫秒內,12個bit位的序列自增用完了,咋辦?
12個bit能表示的最大數字是 4095,一共 4096個 [0, 4095],
首先這個計算是在單個 JVM中計算的,按照美團的位數分配,即同一毫秒同一個worker最大能生成 4096個id,如果同一毫秒內,用完了,就等待到下一毫秒,
根據這個情況我們可以推理出,我們的批量獲取的介面中,一定要加上數量限制,如果不限制,如果業務端傳過來的是 Integer.MAX_VALUE,那就是說這一次呼叫需要等待的時間大概為:
2147483647 / 4096 ≈ 524287ms ≈ 524s ≈ 8.7min忽略呼叫時超時時間的問題,單純說這個事情,CPU打滿8分鐘... 我這里建議批量介面中數量引數不要超過1000,甚至是100,什么樣的業務場景中會一下子需要這么多id?業務上能處理過來嗎?自己根據情況權衡下,
4、如何判斷序列號用完了?比大小嗎?

注意這行代碼,很有意思:
sequence = (sequence + 1) & sequenceMask;sequenceMask為序列號的最大值,也就是序列號的 bit位都占滿,都是1,那 sequence的值在正常增長情況下,任何一個 bit &1,都是1,怎么可能會出現 if (sequence == 0) 這個情況呢?
只有一種情況,就是超出了 bit位,這些 bit位已經裝不下了,進位了,后面全是 0,所以 &出來結果成 0了,
5、計算 id的移位操作,是如何移位的?
long id = ((timestamp - twepoch) << timestampLeftShift) | (workerId << workerIdShift) | sequence;- (timestamp - twepoch) 是時間戳計算值,是long型別,64個bit,timestampLeftShift 是 12+10=22
- (timestamp - twepoch) << timestampLeftShift) 意思是將這 64個bit 左移22位,也就是原值的后 42個bit留下為有效的,這步完成后后面還有22個bit可用;
- (workerId << workerIdShift) 同理,這個是將 workerId 左移12位,12位為sequence的bit數,這步完成后后面還有12個bit可用,供sequence使用,sequence在末位,不用移位;
- ((timestamp - twepoch) << timestampLeftShift) | (workerId << workerIdShift) | sequence 或運算,將時間戳和 workerID和sequence 的bit位進行計算、整合;
- 最后64個bit都整合完畢,為64個bit,8個byte
這個程序一定要搞明白,如果搞不明白先去復習下二進制運算,這個搞明白后可以幫你在業務上做一些別的事情的,比如 Zookeeper客戶端的 auth位、redis的 bitmap等等,
6、生成的 id是單調遞增、趨勢遞增的,會出現第2次拿到的比第1次拿到的id小嗎?
基本不用考慮這個問題,生成的id是單調遞增、趨勢遞增的,在極高并發的情況下,比如有兩個workerID,1和2,前提是同一毫秒,先去2拿到的是大值,再去1拿到的是小值,這樣計算的話,我們的并發至少得有2000了,
而且,如果出現了這種情況,不會影響業務使用的,可能會受影響的只有 InnoDB中 B+tree出現先小后大的效率差問題,不過有這個時間還是想想如何優化業務代碼吧,如果單論技術的話,業務從我這里拿走的id,不一定怎么處理呢,可能會因為業務的原因,導致大的先進表了,小的后進去,所以不要假裝在這里鉆研技術,實際上業務代碼寫的一團糟,
為什么會影響 InnoDB的 B+tree?
比如葉子節點的某一個頁中放了1000個主鍵id,首先,葉子節點中這些id是有序遞增排列的,如果你后邊來了一個小的,那就有可能之前的頁中放不下了,需要重排列和分頁,
7、生成 id的長度有多長?
最長19位!一定不會超!表中的主鍵id bigint(20)足夠用!19位就是百億億了!
id的大小區間是:[1, 9223372036854775807]
最小的id是:1(twepoch為當前時間,并且workerId是0,序列號為1)
最大的id是:9223372036854775807(64個bit,第1個bit是0不變,其余位都占滿,即是最大數,為9223372036854775807,也就是java Long型別的 MAX_VALUE)8、這個 id的位數分配規則,自己能調整嗎?
當然可以,根據自己的業務情況調整,我們這兒將 bit位數分配調整為:1+42+5+16
- 1個bit 用來表示0,正數;
- 42個bit 用來表示毫秒時間戳;42個bit,最大是4398046511103,4398046511103個毫秒值,換算大約是 139年,也就是說從開始投入使用,可以使用 139年;
- 5個bit 用來表示workerID;最大31,也就是目前支持最多31個worker,一般小單位沒有這個量級,如果有這種體量了,再調整也可以的,不用怕重復,因為時間戳是在高位,并且時間戳肯定是遞增的,高位的大小決定了數字的大小;
- 16個bit 用來表示sequence,自增值;同一毫秒,同一 worker上,最多生成 65536個,也就是不考慮外界條件的話,單純的這塊,純理論每秒可以出 65536000個id,大約是 6553萬個,
9、workerId怎么計算的?
美團代碼中,依賴 zookeeper + 本地檔案快取 雙機制來生成 workerId,詳細參考美團文章(https://github.com/Meituan-Dianping/Leaf),講的很清楚,這里不再贅述,
三、安全問題
上邊的搞清楚之后再來看安全問題,1和2 的問題都可以參考美團文章(https://github.com/Meituan-Dianping/Leaf),上邊講的很清晰了,這里不再贅述,
1、時鐘回撥,即時間走著走著卻倒回去了,如何解決?
2、新起的節點中,機器時間不對,那就壓根不能提供服務,如何校正?
3、業務上,通過 getById 介面遍歷能拿走多少越權資料?
首先雪花演算法生成的id不是+1遞增的,比依賴資料庫的自增id要安全很多,另外還要看你的業務設計上,資料權限的控制是否存在漏洞,
4、友商是否可以決議你的 id大概計算出你的業務量?
不存在,首先有 twepoch存在,我不是時間戳,你決議出來只是數字,無法知道具體時間的;另外,后面的自增 sequence,不同的ms內,是隨機生成的,不是都從0開始的,無法知道我的業務量;這兩個條件加起來,足以保證 id的安全性,
【總結】本文我們主要聊了雪花演算法到底是怎么算出來一個 id的,其實基本功是二進制運算,基礎扎實的話,很快就可以 get到它的設計思想,但是,一定要清楚,所有的技術都是為了解決業務問題,也不存在一種技術設計完全適用所有公司的所有業務場景,具體使用的時候根據自己的情況進行調整,但就意味著你必須清楚原理,別瞎改,否則 3.25甚至更慘,哈哈,對自己的每一行代碼負責是技術人的默認選項,
努力改變自己和身邊人的生活,
特別希望本文可以對你有所幫助,原創不易,感謝你留個贊和關注,道阻且長,我們并肩前行!
轉載請注明出處,感謝大家留言討論交流,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/283202.html
標籤:其他
上一篇:2021年大資料常用語言Scala(十一):基礎語法學習 方法引數
下一篇:Hadoop之Hive函式