文章目錄
- 一些瞎扯的話
- 一、必備的有關 OpenCV 和 HOG 的前置知識
- 1.關于OpenCV模塊:圖片讀、寫和顯示操作,以及圖片屬性
- 2.關于OpenCV模塊:圖片縮放和仿射變換
- 3.有關 HSV 空間, Gramma變換, HOG 特征的知識,
- 二、用 OpenCV 的仿射變換實作圖片縮放
- 三、理解 HOG、ORC 程序,使用SVM 和 KNN 模型實作數字影像的識別
- 1.數字影像的型別
- 2.提取數字影像的HOG特征
- 3.訓練模型并測驗
- 四、使用 CNN 神經網路模型實作數字影像的識別
- 1.處理影像資料
- 2.設定模型,訓練模型
- 3.保存模型
- 4.測驗模型
- 五、代碼總和
- 1.圖片縮放
- 2.使用 SVM 和 KNN 模型實作數字影像識別
- 3.使用 CNN 模型實作數字影像識別
一些瞎扯的話
跟朋友們隨便瞎扯幾句
在學校過了個五一,也沒回家也沒出去玩,倍感無聊和寂寞,看著空間里大家曬出游,曬朋友,更加難受,我想,不能這樣了,于是我打開老師布置的作業開始研究,實驗搞了一天,寫檔案又寫了一天,寫完后感覺十分充實,快樂了許多,果然“學習使人快樂”所言非虛哈哈哈,
以上內容純屬瞎扯,寫著作業還是寂寞嗚嗚嗚,
這里推薦Todd Li翻唱的一首歌《最寂寞的時候》
離譜的是布置完實驗的第二天就有粉絲催更,我看明白了,你們根本不饞我身子,只饞我代碼,

一、必備的有關 OpenCV 和 HOG 的前置知識
想要看懂下面的實驗,這些知識必不可少,
1.關于OpenCV模塊:圖片讀、寫和顯示操作,以及圖片屬性
(1)讀入圖片:
讀入圖片時使用’cv.imread’函式,第一個引數是圖片位置,第二個引數是讀圖片的模式,‘1’為讀入為彩色影像,‘0’為讀入為灰度影像,’-1’為原始影像讀入,因此將彩色影像轉為灰度圖時,只需選擇引數為‘0’即可,
代碼如下(示例):
import cv2 as cv
if __name__ == '__main__':
# 讀圖片(有多種模式)
# Load an color image in grayscale
img = cv.imread('1.jpg', 0)
# 1 彩色 0 灰度影像 -1 原始影像
(2)寫圖片:
寫圖片時直接使用‘cv.imwrite’函式即可,第一個引數為寫入的位置,第二個引數即影像本身,如(1),筆者讀入’1.jpg’,讀入時轉為灰度影像,在寫入同一檔案夾下的’1_grey.jpg’檔案中,兩張圖片如下如所示:
代碼如下(示例):
cv.imwrite('1_grey.jpg', img)
兩張圖片如下:


↑我女朋友
沒錯我在想peach,圖源網路,侵刪
(3)顯示圖片:
顯示圖片是使用‘cv.imshow’函式,第二個引數是要顯示的影像,第一個引數是顯示時圖片視窗的名字,注意顯示圖片時要加上一行’cv.waitKey(0)’來讓視窗等待用戶按鍵,不然顯示的圖片會一閃而過,
代碼如下(示例):
# 顯示圖片
cv.imshow('picture1', img) # 第一個引數定義視窗名
cv.waitKey(0) #無限制的等待用戶的按鍵
cv.destroyAllWindows()
(4)圖片屬性:
圖片屬性包括高度、寬度、通道數、像素總數等資訊,示例如下圖:

2.關于OpenCV模塊:圖片縮放和仿射變換
(1)圖片縮放:
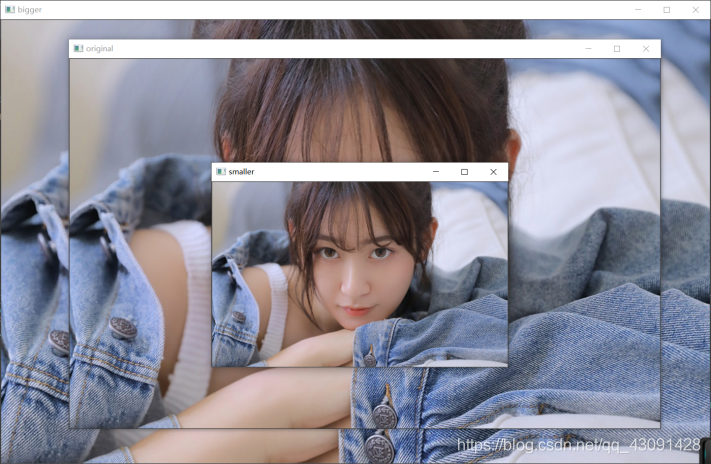
使用 OpenCV 模塊實作圖片縮放時主要使用 ‘cv2.resize’函式,注意是‘主要’,因為仿射變換也能實作圖片縮放,下面一個實驗即是,
函式可以使用引數 ‘fx’和‘fy’或者直接使用‘dsize’引數來控制縮放比例,十分方便,

代碼如下(示例):
smaller = cv.resize(img, None, fx=0.5, fy=0.5, interpolation=cv.INTER_CUBIC) # OR
height, width = img.shape[:2]
bigger = cv.resize(img, (int(1.2 * width), int(1.2 * height)), interpolation=cv.INTER_CUBIC)
結果示例如下,注意看視窗名字來辨別圖片:
(2)仿射變換:
一個任意的仿射變換都能表示為乘以一個矩陣(線性變換)接著再加上一個向量(平移),
旋轉(線性變換)
平移 (向量加)
縮放操作 (線性變換)
我們通常使用 2 x 3 矩陣來表示仿射變換.其中左邊的2×2子矩陣是線性變換矩陣,右邊的2×1的兩項是平移項:

對于影像上的任一位置(x,y),仿射變換執行的是如下的操作:
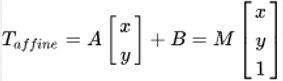
平移:將每一點移到到(x+t , y+t),變換矩陣為:
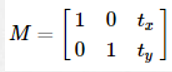
旋轉變換:目標圖形圍繞原點順時針旋轉Θ弧度,線性變換矩陣為:
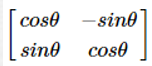
目標圖形以(x,y)為軸心順時針旋轉θ弧度,相當于兩次平移與一次原點旋轉變換的復合,即先將軸心(x,y) 移到到原點,然后做旋轉變換,最后將圖片的左上角置為圖片的原點,變換矩陣為:
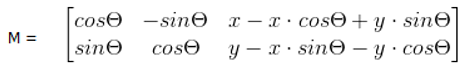
仿射函式‘cv2.warpAffine’:

用來獲得變換矩陣M的函式‘cv2.warpAffine’,方便我們在進行圖片旋轉時計算弧度:

仿射函式‘cv.getAffineTransform’:
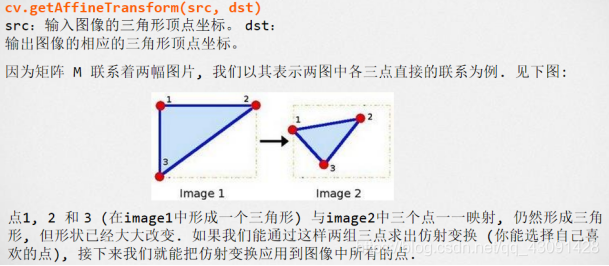
看懂了嗎,建議看不懂的童鞋重新研讀線性代數課本

3.有關 HSV 空間, Gramma變換, HOG 特征的知識,
(1)HSV 空間:
HSV空間是由美國的圖形學專家A. R. Smith提出的一種顏色空間,HSV分別是色調(Hue),飽和度(Saturation)和明度(Value),
在HSV空間中進行調節就避免了直接在RGB空間中調節是還需要考慮三個通道的相關性,OpenCV中H的取值是[0, 180),其他兩個通道的取值都是[0, 256),通過HSV空間對 影像進行調色更加方便:
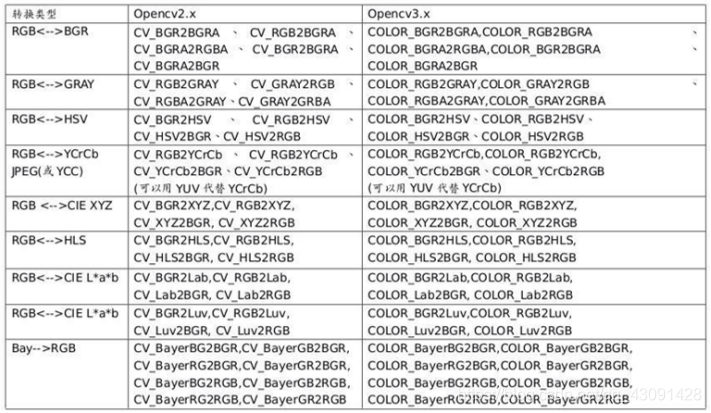
轉換圖片制式的函式‘cv2.cvtColor’:

轉換型別表:
(2)Gramma變換:
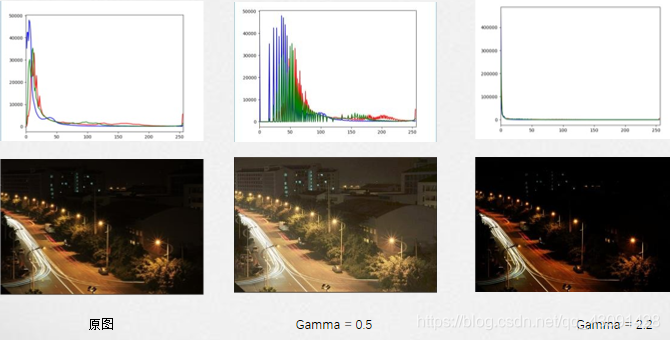
Gamma變換是矯正相機直接成像和人眼感受影像差別的一種常用手段,簡單來說就是通過非線性 變換(因為人眼對自然的感知是非線性的)讓影像從對曝光強度的線性回應變得更接近人眼感受到 的回應,Gamma壓縮公式:
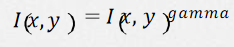
如果直方圖中的成分過于靠近0或者255,可能就出現了暗部細節不足或者亮部細節丟失的情況,一個常用方法是考慮用Gamma變換來提升/降低暗部細節,
示例圖如下:
(3)HOG 特征:
方向梯度直方圖(Histogram of Oriented Gradient, HOG)特征是一種在計算機視覺和 影像處理中用來進行物體檢測的特征描述子,它通過計算和統計影像區域區域的梯度方向直方 圖來構成特征,HOG特征結合SVM分類器已經被廣泛應用于影像識別中,尤其在行人檢測中獲 得了極大的成功,
HOG特征提取方法就是將一個image(你要檢測的目標或者掃描視窗):
1)灰度化(將影像看做一個x,y,z(灰度)的三維影像);
2)采用Gamma校正法對輸入影像進行顏色空間的標準化(歸一化);目的是調節圖 像的對比度,降低影像區域的陰影和光照變化所造成的影響,同時可以抑制噪音的干擾;
3)計算影像每個像素的梯度(包括大小和方向);主要是為了捕獲輪廓資訊,同時進一步榷訓光照的干擾,
4)將影像劃分成小cells(例如10X10像素/cell);
5)統計每個cell的梯度直方圖(不同梯度的個數),即可形成每個cell的descriptor;
6)將每幾個cell組成一個block(例如2*2個cell/block),一個block內所有cell的特征descriptor串聯起來便得到該block的HOG特征descriptor,
7)將影像image內的所有block的HOG特征descriptor串聯起來就可以得到該image(你要檢測的目標)的HOG特征descriptor了,這個就是最終的可供分類使用的特征向量了,
這里只是簡單講一下提取 HOG 特征的步驟,具體操作見下面實驗,
二、用 OpenCV 的仿射變換實作圖片縮放
我們通常使用 2 x 3 矩陣來表示仿射變換.其中左邊的2×2子矩陣是線性變換矩陣,右邊的2×1的兩項是平移項:

對于影像上的任一位置(x,y),仿射變換執行的是如下的操作:
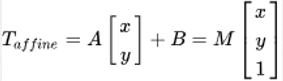
我們要實作縮放,并不需要對影像進行平移,B矩陣中的值取0即可,接下來我們考慮怎么使用A矩陣實作縮放,
根據線性代數的知識,我們可以取a00和a11為0,取a01和a10相等,這樣的話影像相當于沒有旋轉,而且每個像素點的橫縱坐標都乘以了一個相同的值,設a01和a10的值為rate,乘以A矩陣之后,每個像素點的位置由(x, y)移到了(x*'rate, y*rate),即實作了縮放,
代碼如下:
import numpy as np
import cv2 as cv
# Load an color image in grayscale
img = cv.imread('11.jpg')
rows, cols = img.shape[:2]
#縮放
rate = 0.5
np1 = np.float32([[rate, 0, 0], [0, rate, 0]])
dst4 = cv.warpAffine(img, np1, (int(cols*rate), int(rows*rate)))
rate = 2
np2 = np.float32([[rate, 0, 0], [0, rate, 0]])
dst5 = cv.warpAffine(img, np2, (int(cols*rate), int(rows*rate)))
cv.imshow('original',img)
cv.imshow('small',dst4)
cv.imshow('big',dst5)
cv.waitKey(0) # 無限制的等待用戶的按鍵
cv.destroyAllWindows()
結果如下:
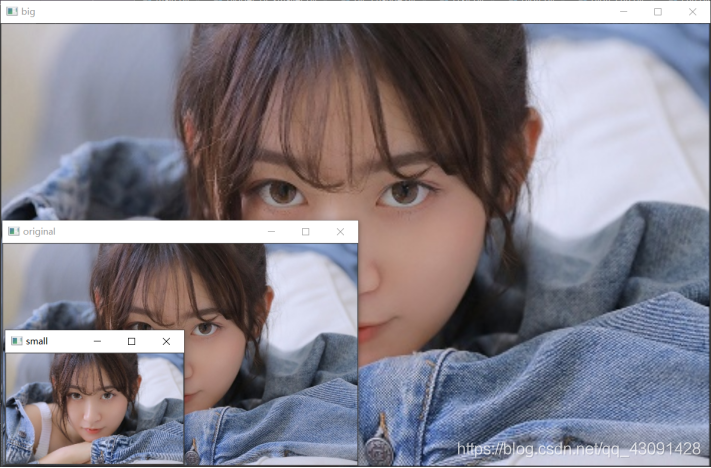
三、理解 HOG、ORC 程序,使用SVM 和 KNN 模型實作數字影像的識別
本實驗的難點到了,
本實驗的步驟十分簡單,可以分為兩個部分,提取數字影像的HOG特征,和放到分類器中進行訓練分類,
1.數字影像的型別
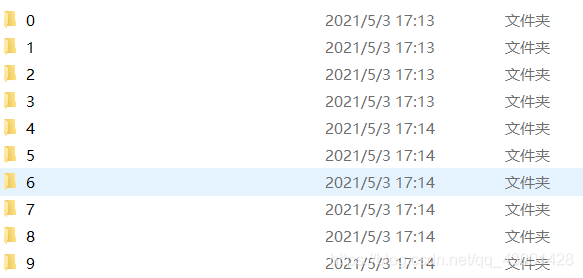
本次實驗的資料集分為訓練集和測驗集兩個部分,每一部分都包含十個檔案夾,分別存有一定數量的數字影像,檔案夾名稱即是儲存的數字影像中的數字,
訓練集共包含10000張圖片,測驗集共包含5000張圖片,每張圖片的大小是28*28,與MNIST資料集圖片相同,


2.提取數字影像的HOG特征
在前置知識中提到了提取影像 HOG 特征的步驟,下面是具體實作,
(1)讀入影像
讀取訓練集和測驗集中的每個影像,定義images串列存盤影像的HOG特征,lables串列存盤影像的分類,最后用numpy模塊將串列轉化為矩陣,以用于模型訓練,
在讀入影像時,首先要轉化為灰度影像,之后進行偏斜校正,提取HOG特征值,降維等操作,下面來一一詳解,
def data(path):
images = []
lables = []
indexs = os.listdir(path)
for index in indexs:
names = os.listdir(path + '\\' + index)
for name in names:
image_path = path + '\\' + index + '\\' + name
img = cv2.imread(image_path, 0)#灰度化
img_deskew = deskew(img)#偏斜校正
img_hsv = hog.compute(img_deskew)
images.append(np.squeeze(img_hsv))
lables.append(int(index))
return np.array(images), np.array(lables)
(2)偏斜校正
先解釋一下矩特征:
從影像中計算出來的矩通常描述了影像不同種類的幾何特征如:大小、灰度、方向、形狀等,影像矩廣泛應用于模式識別、目標分類、目標識別與防偽估計、影像編碼與重構等領域,矩是概率與統計中的一個概念,是隨機變數的一種數字特征,opencv中提供了moments()來計算影像中的中心矩(最高到三階),Opencv中的moments得到影像矩的字典,包括m00,m10,m01,m20,m11,m02,m30,m21,m12,m03,mu20,mu11,mu02,mu30,mu21,mu12,mu03,nu20,nu11,nu02,nu30,nu21,nu12,nu03,
也就是說呼叫‘cv.moments’函式,就能自動計算出圖片的中心距,這里數字影像我們視為矩形,我們主要使用圖片的二階矩(mu02)判斷影像中數字的方向,
代碼如下,SZ為圖片的長和寬,我們先利用‘cv2.threshold’函式對圖片(傳入函式的為灰度圖)進行二值化處理,將大于等于127的值全改為255,小于127的值全改為0,該函式回傳的第一個值就是輸入的thresh值,第二個就是處理后的影像,
再利用‘cv2.findContours’函式來查找影像的輪廓,函式第一個引數是尋找輪廓的影像;第二個引數表示輪廓的檢索模式,第三個引數method為輪廓的近似辦法,這里不再詳細說明,
‘cv2.findContours’函式回傳兩個值,一個是輪廓本身,還有一個是每條輪廓對應的屬性,
我們利用計算出的輪廓,運用‘cv2.moments’函式計算圖片的二階矩,再進行判斷,如果其小于0.01,認為影像沒有偏斜,直接回傳原影像,
否則利用仿射變換進行校正,
def deskew(img):
SZ = 28
ret, thresh = cv2.threshold(img, 127, 255, 0)
contours, hierarchy = cv2.findContours(thresh, 1, 2)
cnt = contours[0]
m = cv2.moments(cnt)
if abs(m['mu02']) < 1e-2:
# no deskewing needed.
return img.copy()
# Calculate skew based on central momemts.
skew = m['mu11']/m['mu02']
# Calculate affine transform to correct skewness.
M = np.float32([[1, skew, -0.5 * SZ * skew], [0, 1, 0]])
# Apply affine transform
img = cv2.warpAffine(img, M, (SZ, SZ), flags=cv2.WARP_INVERSE_MAP | cv2.INTER_LINEAR)
return img
(3)計算水平和垂直梯度
可以通過使用以下內核卷積影像來輕松實作,左下圖為大小為1的內核,mag為梯度大小,ang為梯度方向的角度的弧度值,

(4)計算梯度分布的直方圖,梯度被分為9等分
以一個8*’8的cell為例,下圖為RGB顏色向量的長度和方向的矩陣,我們將方向從0-180九等分,對于一個顏色向量的長度,我們根據其方向將其分在兩個最近的梯度值上,對于一個cell中的每個像素點執行此操作,即可得到該cell的梯度分布直方圖,
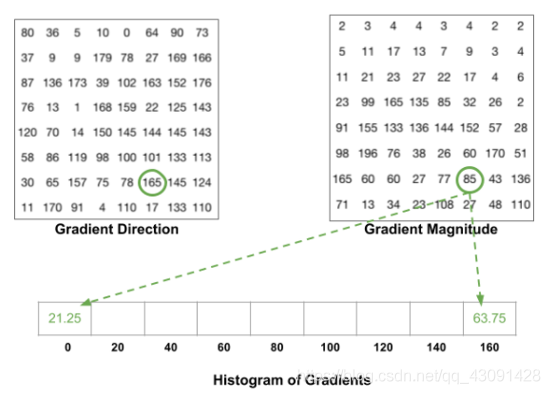
(5)向量歸一化
在上一步中,我們基于影像的梯度創建了一個直方圖, 影像的漸變對整體光照敏感, 如果通過將所有像素值除以2來使影像更暗,則梯度大小將改變一半,因此直方圖值將改變一半,
理想情況下,我們希望描述符與照明變化無關, 換句話說,我們想“標準化”直方圖,以使它們不受光照變化的影響,在解釋如何對直方圖進行歸一化之前,讓我們看看如何對長度為3的向量進行歸一化,
假設我們有RGB顏色向量[128,64,32], 此向量的長度為sqrt {128 ^ 2 + 64 ^ 2 + 32 ^ 2} = 146.64, 這也稱為向量的L2范數, 將該向量的每個元素除以146.64,得出的歸一化向量為[0.87,0.43,0.22],
現在考慮另一個向量,其中元素是第一個向量的值的兩倍2*[128,64,32] = [256,128,64], 標準化[256,128,64]將產生[0.87,0.43,0.22],這與原始RGB向量的標準化版本相同,光照大小將不影響向量值,
(6)將向量分布直方圖拼接并展開,得到最后的HOG特征值
(7)代碼實作:
下面以(20,20)大小的影像為例,以(10,10)大小計算梯度分布直方圖,Normalize大小也為(10,10),

除了上述代碼,我們也可以使用opencv自帶的HOGDescriptor計算HOG特征值,調節winSize,blockSize等引數獲得更好的效果,(本實驗中筆者用的這種方法)
winSize = (28, 28)
blockSize = (14, 14)
blockStride = (7, 7)
cellSize = (14, 14)
nbins = 9
derivAperture = 1
winSigma = -1
histogramNormType = 0
L2HysThreshold = 0.2
gammaCorrection = 1
nlevels = 64
signedGradients = True
hog = cv2.HOGDescriptor(winSize, blockSize, blockStride,
cellSize, nbins, derivAperture,
winSigma, histogramNormType, L2HysThreshold,
gammaCorrection, nlevels, signedGradients)
這里是對各種引數的描述:
winSize:數字影像的大小為28×28,此處為整個影像計算一個描述符,
cellSize:影像是28×28灰度影像,換句話說,影像由28×28 = 784個像素點表示,cellSize是根據對分類重要的特征的比例來選擇的,一個很小的cellSize會使特征向量的大小過大,而一個很大的cellSize可能無法捕獲相關資訊,這里我們選擇了14×14的cellSize,可以嘗試修改cellSize獲得更好的效果,
blockSize:用于解決亮度變化影響gradient分布,較大的塊大小會使本地像素變化的重要性降低,而較小的塊大小會使本地像素變化的權重更大,通常,blockSize設定為2 x cellSize,因為在我們的數字分類影像中,亮度并不是很大的干擾項,因此14×14的塊大小給出了最佳結果,
blockStride:blockStride確定相鄰塊之間的重疊并控制對比度歸一化的程度,通常,將blockStride設定為blockSize的50%,
nbins:nbins設定漸變直方圖中的bin數, HOG論文的作者建議值為9,以20度為增量捕獲0到180度之間的梯度,
signedGradients:通常,漸變可以具有0到360度之間的任何方向,這些梯度稱為“有符號”梯度,與“無符號”梯度相反,“無符號”梯度使符號下降并采用0到180度之間的值,
3.訓練模型并測驗
(1) 獲得訓練資料和測驗資料
直接使用上述data函式保存訓練資料和測驗資料,并列印出資料的大小,
這里要注意,訓練資料和測驗資料的維度應該均為2,且第一個維度為資料的數量,因此在data函式中加了一行降維代碼“np.squeeze(img_hsv)”,將81*1的二維矩陣降維為一維矩陣,
train_data, train_lable = data('digit_data\\train')
print(train_data.shape)
images_test, lables_test = data('digit_data\\test')
print(images_test.shape)

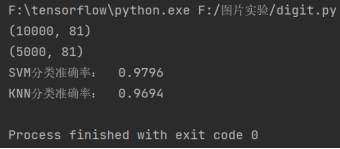
列印結果如下:

(2) 訓練SVM模型并進行測驗
直接帶入SVM模型訓練和測驗模板即可,
clf = make_pipeline(StandardScaler(), SVC(gamma='auto'))
clf.fit(train_data, train_lable)
result = clf.predict(images_test)
correct = np.sum(result == lables_test)
print('SVM分類準確率: ', correct/len(images_test))
(3) 訓練KNN模型并進行測驗
同上:
neigh = KNeighborsClassifier(n_neighbors=3)
neigh.fit(train_data, train_lable)
result = neigh.predict(images_test)
correct = np.sum(result == lables_test)
print('KNN分類準確率: ', correct/len(images_test))
(4) 分類結果如下,效果很好,
四、使用 CNN 神經網路模型實作數字影像的識別
1.處理影像資料
使用 CNN 模型時,我們不需要提取 HOG 特征,只需灰度化即可,
def data(path):
images = []
lables = []
indexs = os.listdir(path)
for index in indexs:
names = os.listdir(path + '\\' + index)
for name in names:
image_path = path + '\\' + index + '\\' + name
img = cv2.imread(image_path, 0)
images.append(np.array(img))
lables.append(index)
return np.array(images), np.array(lables)
將圖片讀入矩陣之后,進行歸一化操作,除于255,再對矩陣升維,由三維升為四維,
另外還要對分類標簽進行one-hot編碼,
if __name__ == "__main__":
x_train, y_train = data('digit_data\\train')
x_test, y_test = data('digit_data\\test')
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train = x_train / 255.0
x_test = x_test / 255.0
x_train = x_train.reshape(x_train.shape[0], 28, 28, 1)
y_train = keras.utils.to_categorical(y_train, 10)
x_test = x_test.reshape(x_test.shape[0], 28, 28, 1)
y_test = keras.utils.to_categorical(y_test, 10)
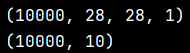
print (x_train.shape)
print (y_train.shape)
列印結果如下:
2.設定模型,訓練模型
CNN框架圖如下:
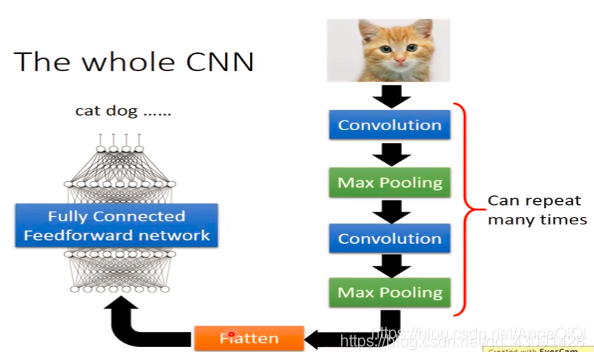
簡單來說,卷積層用來提取特征,而池化層可以減少引數數量,
pooling池化的作用則體現在降采樣:保留顯著特征、降低特征維度,增大kernel的感受野,另外一點值得注意:pooling也可以提供一些旋轉不變性,
實驗中我們使用兩對卷積、池化層,
我們設定卷積核為大小為5*5,第一層卷積層使用32個卷積核,第二層卷積層使用64個卷積核,
Padding選擇補0使得卷積后的激活映射尺寸不變,
激活函式我們使用‘relu’,
池化層我們使用最大池化(Max Pooling),取一個區域內所有神經元的最大值,
最后添加兩個全連接層,設定損失函式,評估標準后,模型設定完畢,
使用 ‘model.fit’進行模型訓練,
#build the model
model = Sequential()
model.add(Conv2D(32,(5,5),activation = 'relu',input_shape = (28,28,1),padding='same'))
model.add(MaxPooling2D(pool_size = (2,2)))
model.add(Conv2D(64,(5,5),activation = 'relu',padding='same'))
model.add(MaxPooling2D(pool_size = (2,2)))
model.add(Flatten())
model.add(Dense(1024,activation = 'relu'))
model.add(Dense(10,activation = 'softmax'))
sgd = optimizers.SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss=keras.losses.categorical_crossentropy,optimizer=sgd,metrics=['accuracy'])
model.fit(x_train, y_train, batch_size = 100, epochs = 14)
看不太懂的童鞋可以去找一些講cnn結構的博客來讀

3.保存模型
使用 ‘model.save_weights’ 保存模型的權重;使用’model.load_weight’加載模型的權重,
訓練模型時注釋掉加載模型的代碼;
加載模型時注釋掉‘model.fit’訓練模型和‘model.save’保存模型權重的代碼,
# save architecture
model.save_weights('CNN_model')
#load
#model.load_weights('cnn_model')
4.測驗模型
使用測驗集進行模型的測驗,輸出測驗結果,
score = model.evaluate(x_test, y_test)
print ("loss: "+str(score[0]))
print ("accuracy: "+str(score[1]))
列印結果如下,準確率為97.74%.

五、代碼總和
又到了大家最喜歡的代碼環節

1.圖片縮放
前面放過完整代碼了,大家動動手去前面翻一下
2.使用 SVM 和 KNN 模型實作數字影像識別
from sklearn.svm import SVC
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
import os
import cv2
import numpy as np
winSize = (28, 28)
blockSize = (14, 14)
blockStride = (7, 7)
cellSize = (14, 14)
nbins = 9
derivAperture = 1
winSigma = -1
histogramNormType = 0
L2HysThreshold = 0.2
gammaCorrection = 1
nlevels = 64
signedGradients = True
hog = cv2.HOGDescriptor(winSize, blockSize, blockStride,
cellSize, nbins, derivAperture,
winSigma, histogramNormType, L2HysThreshold,
gammaCorrection, nlevels, signedGradients)
#偏斜校正
def deskew(img):
SZ = 28
ret, thresh = cv2.threshold(img, 127, 255, 0)
contours, hierarchy = cv2.findContours(thresh, 1, 2)
cnt = contours[0]
m = cv2.moments(cnt)
if abs(m['mu02']) < 1e-2:
# no deskewing needed.
return img.copy()
# Calculate skew based on central momemts.
skew = m['mu11']/m['mu02']
# Calculate affine transform to correct skewness.
M = np.float32([[1, skew, -0.5 * SZ * skew], [0, 1, 0]])
# Apply affine transform
img = cv2.warpAffine(img, M, (SZ, SZ), flags=cv2.WARP_INVERSE_MAP | cv2.INTER_LINEAR)
return img
def data(path):
images = []
lables = []
indexs = os.listdir(path)
for index in indexs:
names = os.listdir(path + '\\' + index)
for name in names:
image_path = path + '\\' + index + '\\' + name
img = cv2.imread(image_path, 0)#灰度化
img_deskew = deskew(img)#偏斜校正
img_hsv = hog.compute(img_deskew)
images.append(np.squeeze(img_hsv))
lables.append(int(index))
return np.array(images), np.array(lables)
train_data, train_lable = data('digit_data\\train')
print(train_data.shape)
images_test, lables_test = data('digit_data\\test')
print(images_test.shape)
clf = make_pipeline(StandardScaler(), SVC(gamma='auto'))
clf.fit(train_data, train_lable)
result = clf.predict(images_test)
correct = np.sum(result == lables_test)
print('SVM分類準確率: ', correct/len(images_test))
neigh = KNeighborsClassifier(n_neighbors=3)
neigh.fit(train_data, train_lable)
result = neigh.predict(images_test)
correct = np.sum(result == lables_test)
print('KNN分類準確率: ', correct/len(images_test))
3.使用 CNN 模型實作數字影像識別
from tensorflow import keras
from keras.models import Sequential
from keras.layers import Dense, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras import optimizers
import os
import cv2
import numpy as np
def data(path):
images = []
lables = []
indexs = os.listdir(path)
for index in indexs:
names = os.listdir(path + '\\' + index)
for name in names:
image_path = path + '\\' + index + '\\' + name
img = cv2.imread(image_path, 0)
images.append(np.array(img))
lables.append(index)
return np.array(images), np.array(lables)
if __name__ == "__main__":
x_train, y_train = data('digit_data\\train')
x_test, y_test = data('digit_data\\test')
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train = x_train / 255.0
x_test = x_test / 255.0
x_train = x_train.reshape(x_train.shape[0], 28, 28, 1)
y_train = keras.utils.to_categorical(y_train, 10)
x_test = x_test.reshape(x_test.shape[0], 28, 28, 1)
y_test = keras.utils.to_categorical(y_test, 10)
print (x_train.shape)
print (y_train.shape)
#build the model
model = Sequential()
model.add(Conv2D(32,(5,5),activation = 'relu',input_shape = (28,28,1),padding='same'))
model.add(MaxPooling2D(pool_size = (2,2)))
model.add(Conv2D(64,(5,5),activation = 'relu',padding='same'))
model.add(MaxPooling2D(pool_size = (2,2)))
model.add(Flatten())
model.add(Dense(1024,activation = 'relu'))
model.add(Dense(10,activation = 'softmax'))
sgd = optimizers.SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss=keras.losses.categorical_crossentropy,optimizer=sgd,metrics=['accuracy'])
model.fit(x_train, y_train, batch_size = 100, epochs = 14)
# save architecture
model.save_weights('CNN_model')
#load
#model.load_weights('cnn_model')
score = model.evaluate(x_test, y_test)
print ("loss: "+str(score[0]))
print ("accuracy: "+str(score[1]))

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/283232.html
標籤:其他
上一篇:CPU與I/O設備的資料傳送方式