前面我們介紹了 WebRTC 音頻 3A 中的聲學回聲消除(AEC:Acoustic Echo Cancellation)的基本原理與優化方向,這一章我們接著聊另外一個 "A" -- 自動增益控制(AGC:Auto Gain Control),本文將結合實體全面決議 WebRTC AGC 的基本框架,一起探索其基本原理、模式的差異、存在的問題以及優化方向,
作者|珞神
審校|泰一
前言
自動增益控制(AGC:Auto Gain Control)是我認為鏈路最長,最影響音質和主觀聽感的音頻演算法模塊,一方面是 AGC 必須作用于發送端來應對移動端與 PC 端多樣的采集設備,另一方面 AGC 也常被作為壓限器作用于接收端,均衡混音信號防止爆音,設備的多樣性最直接的體現就是音頻采集的差異,一般表現為音量過大導致爆音,采集音量過小對端聽起來很吃力,
在音視頻通話的現實場景中,不同的參會人說話音量各有不同,參會用戶需要頻繁的調整播放音量來滿足聽感的需要,戴耳機的用戶隨時承受著大音量對耳朵的 “暴擊”,因此,對發送端音量的均衡在上述場景中顯得尤為重要,優秀的自動增益控制演算法能夠統一音頻音量大小,極大地緩解了由設備采集差異、說話人音量大小、距離遠近等因素導致的音量的差異,
AGC 在 WebRTC 中的位置
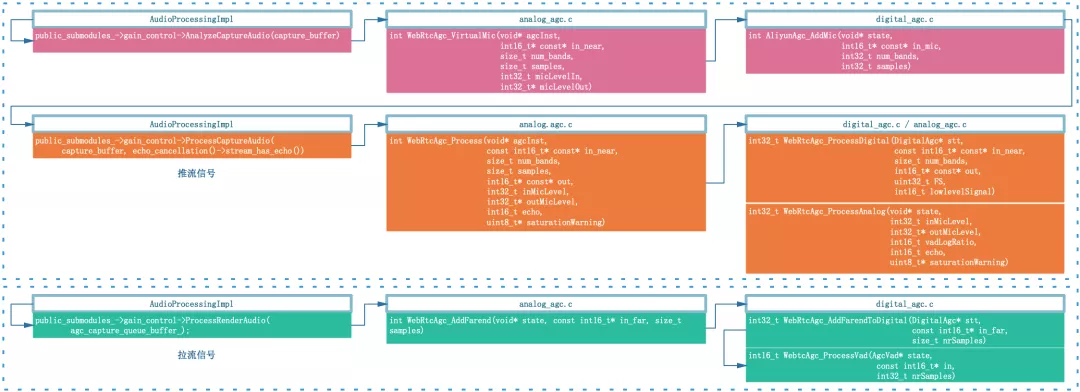
在講 AGC 音頻流處理框架之前,我們先看看 AGC 在音視頻實時通信中的位置,如圖 1 展示了同一設備作為發送端音頻資料從采集到編碼,以及作為接收端音頻資料從解碼到播放的程序,AGC 在發送端作為均衡器和壓限器調整推流音量,在接收端僅作為壓限器防止混音之后播放的音頻資料爆音,理論上推流端 AGC 做的足夠魯棒之后,拉流端僅作為壓限器是足夠的,有的廠家為了進一步減小混音之后不同人聲的音量差異也會再做一次 AGC,
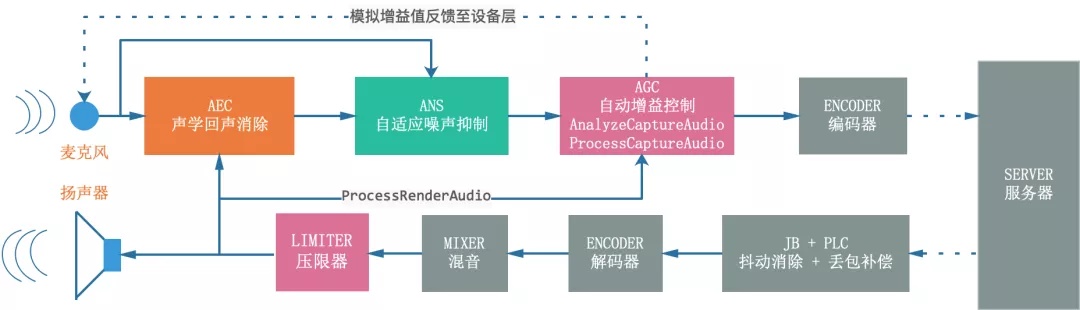
圖 1 WebRTC 中音頻信號上下行處理流程框圖
AGC 的核心引數
先科普一下樣本點幅度值 Sample 與分貝 dB 之間的關系,以 16bit 量化的音頻采樣點為例:dB = 20 * log10(Sample / 32768.0),與 Adobe Audition 右側縱坐標刻度一致,
幅度值表示:16bit 采樣最小值為 0,最大值絕對值為 32768(幅度值如下圖右邊欄縱坐標),
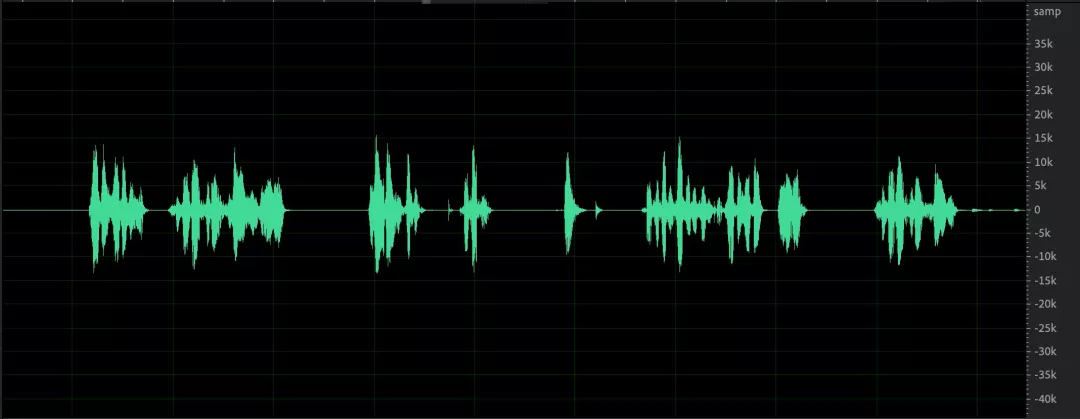
分貝表示:最大值為 0 分貝(分貝值如下圖右邊欄縱坐標),一般音量到達 -3dB 已經比較大了,3 也經常設定為 AGC 目標音量,
核心引數有:
typedef struct {
int16_t targetLevelDbfs; // 目標音量
int16_t compressionGaindB; // 增益能力
uint8_t limiterEnable; // 壓限器開關
} AliyunAgcConfig;
目標音量 - targetLevelDbfs:表示音量均衡結果的目標值,如設定為 1 表示輸出音量的目標值為 - 1dB;
增益能力 - compressionGaindB:表示音頻最大的增益能力,如設定為 12dB,最大可以被提升 12dB;
壓限器開關 - limiterEnable:一般與 targetLevelDbfs 配合使用,compressionGaindB 是調節小音量的增益范圍,limiter 則是對超過 targetLevelDbfs 的部分進行限制,避免資料爆音,
AGC 的核心模式
除了以上三個核心的引數外,針對不同的接入設備 WebRTC AGC 提供了以下三種模式:
enum {
kAgcModeUnchanged,
kAgcModeAdaptiveAnalog, // 自適應模擬模式
kAgcModeAdaptiveDigital, // 自適應數字增益模式
kAgcModeFixedDigital // 固定數字增益模式
};
以下我們會結合實體從基本功能,適用場景,信號流圖以及存在的問題等方面闡述這三個模式,
固定數字增益 - FixedDigital
固定數字增益模式最基礎的增益模式也是 AGC 的核心,其他兩種模式都是在此基礎上擴展得到,主要是對信號進行固定增益的放大,最大增益不超過設定的增益能力 compressionGaindB,結合 limiter 使用的時候上限不超過設定的目標音量 targetLevelDbfs,
固定數字增益模式下僅依靠核心函式 WebRtcAgc_ProcessDigital 對輸入信號音量進行均衡,由于沒有反饋機制,其信號處理流程也是極其簡單,設定好引數之后信號會經過如下流程:
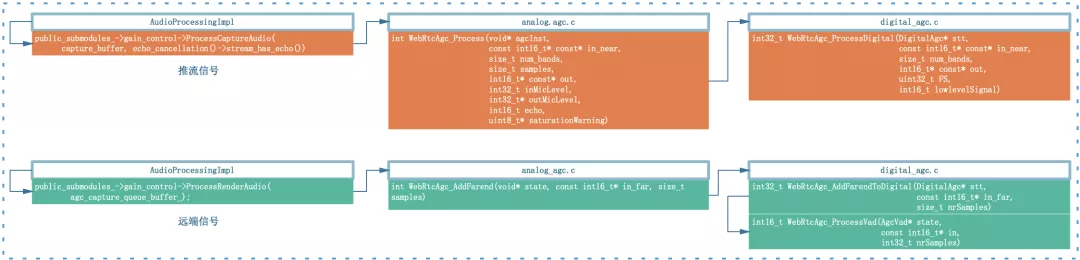
固定數字增益模式是最核心的模式,主要有如下兩個方面值得我們深入學習:
語音檢測模塊 WebRtcAgc_ProcessVad 的基本思想
在實時通信的場景中,麥克風采集的近端信號中會存在遠端的信號的成分,流程中會先通過 WebRtcAgc_ProcessVad 函式對遠端信號進行分析,在探測實際近端信號包絡的時候需要剔除遠端信號這個干擾項,避免因殘留的回聲信號影響了近端信號包絡等引數的統計,最傳統的 VAD 會基于能量,過零率和噪聲門限等指標區分語音段和無話段,WebRTC AGC 中為粗略的區分語音段提供了新的思路:
- 計算短時均值和方差,描述語音包絡瞬時變化,能夠準確反映語音的包絡,如圖 2 左紅色曲線;
// update short-term estimate of mean energy level (Q10)
tmp32 = state->meanShortTerm * 15 + dB;
state->meanShortTerm = (int16_t)(tmp32 >> 4);
// update short-term estimate of variance in energy level (Q8)
tmp32 = (dB * dB) >> 12;
tmp32 += state->varianceShortTerm * 15;
state->varianceShortTerm = tmp32 / 16;
// update short-term estimate of standard deviation in energy level (Q10)
tmp32 = state->meanShortTerm * state->meanShortTerm;
tmp32 = (state->varianceShortTerm << 12) - tmp32;
state->stdShortTerm = (int16_t)WebRtcSpl_Sqrt(tmp32);
- 計算長時均值和方差,描述信號整體緩慢的變化趨勢,勾勒信號的 “重心線”,比較平滑有利于利用門限值作為檢測條件,如圖 2 左藍色曲線;
// update long-term estimate of mean energy level (Q10)
tmp32 = state->meanLongTerm * state->counter + dB;
state->meanLongTerm = WebRtcSpl_DivW32W16ResW16(tmp32, WebRtcSpl_AddSatW16(state->counter, 1));
// update long-term estimate of variance in energy level (Q8)
tmp32 += state->varianceLongTerm * state->counter;
state->varianceLongTerm = WebRtcSpl_DivW32W16(tmp32, WebRtcSpl_AddSatW16(state->counter, 1));
- 計算標準分數,描述短時均值與 “重心線” 的偏差,位于中心之上的部分可以認為發生語音活動的可能性極大;
tmp32 = tmp16 * (int16_t)(dB - state->meanLongTerm);
tmp32 = WebRtcSpl_DivW32W16(tmp32, state->stdLongTerm);
state->logRatio = (int16_t)(tmp32 >> 6);
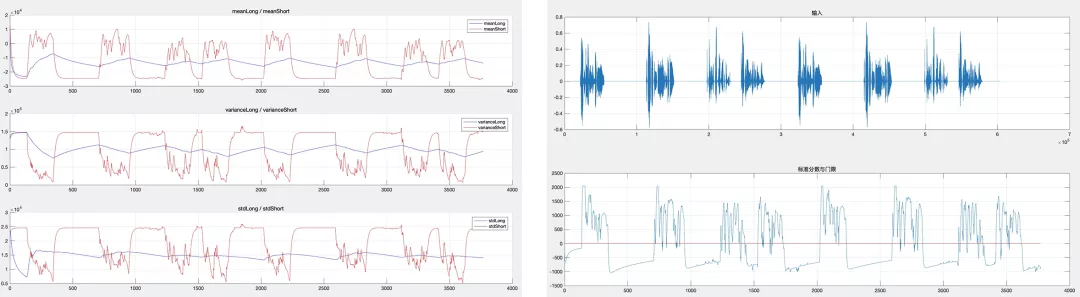
圖 2 左:長短時均值與方差 右:輸入與 vad 檢測門限
WebRtcAgc_ProcessDigital 如何對音頻資料進行增益
3 個核心引數都是圍繞固定數字增益模式展開的,我們需要搞清楚的是 WebRTC AGC 中核心函式 - WebRtcAgc_ProcessDigital 是如何對音頻資料進行增益的,
- 根據指定的 targetLevelDbfs 和 compressionGaindB,計算增益表 gainTable;
/* 根據設定的目標增益與增益能力,計算增益表gainTable */
if (WebRtcAgc_CalculateGainTable(&(stt->digitalAgc.gainTable[0]), stt->compressionGaindB, stt->targetLevelDbfs, stt->limiterEnable, stt->analogTarget) == -1) {
return -1;
}
這一步中增益表 gainTable 可以理解為對信號能量值(幅值的平方)的量化,我們先固定 targetLevelDbfs,分別設定 compressionGaindB 為 3dB~15dB,所對應的增益表曲線如下,可以看到增益能力設定越大,曲線越高,如下圖,
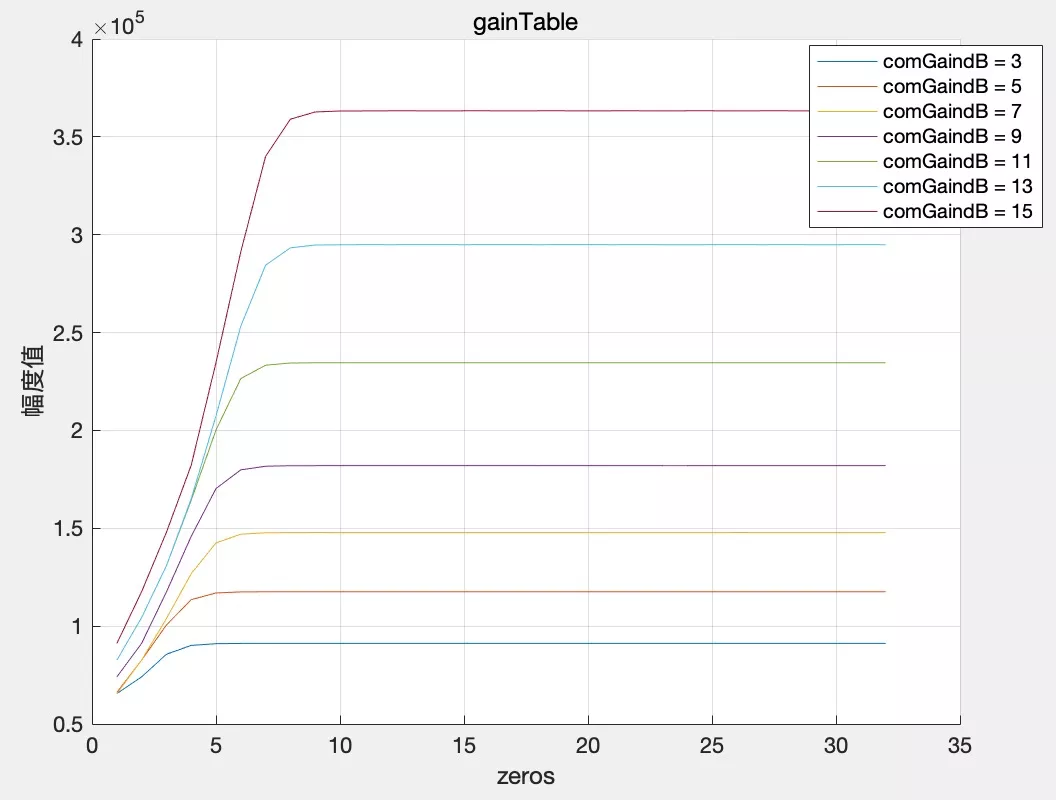
大家可能會好奇增益表 gainTable 的長度為什么只有 32 呢?32 其實表示的是一個 int 型資料的 32 位(short 型資料的能量值范圍為 [0, 32768^2] 可以用無符號 int 型資料表示),從高位到低位,為 1 的最高位具有最大的數量級稱為整數部分 - intpart,后續數位組成小數部分稱為 fracpart,因此 [0, 32768] 之間的任意一個數都對應數字增益表中的一個增益值,接下來我們講講如何查表并應用增益值完成音量均衡,
/** 部分關鍵原始碼 */
/** 提取整數部分和小數部分 */
intPart = (uint16_t)(absInLevel >> 14); // extract the integral part
fracPart = (uint16_t)(absInLevel & 0x00003FFF); // extract the fractional part
......
/** 根據整數部分和小數部分生成數字增益表 */
gainTable[i] = (1 << intPart) + WEBRTC_SPL_SHIFT_W32(fracPart, intPart - 14);
- 根據輸入信號包絡在增益表 gainTable 中查找增益值,并應用增益到輸入信號;
基于人耳的聽覺曲線,AGC 中在應用增益是是分段的,一幀 160 個樣本點會分為 10 段,每段 16 個樣本點,因此會引入分段增益陣列 gains,下述代碼中描述了數字增益表與增益陣列的關系,直接體現了查表的程序,其思想與計算增益表時相似,也是先計算整數部分與小數部分,再通過增益表組合計算出新的增益值,其中就包含了小數部分的補償,
// Translate signal level into gain, using a piecewise linear approximation
// find number of leading zeros
zeros = WebRtcSpl_NormU32((uint32_t)cur_level);
if (cur_level == 0) {
zeros = 31;
}
tmp32 = (cur_level << zeros) & 0x7FFFFFFF;
frac = (int16_t)(tmp32 >> 19); // Q12.
tmp32 = (stt->gainTable[zeros - 1] - stt->gainTable[zeros]) * frac;
gains[k + 1] = stt->gainTable[zeros] + (tmp32 >> 12);
下述代碼是根據分段增益陣列 gains,右移 16 位后獲得實際的增益值(之前計算增益表和增益陣列都是基于樣本點能量,這里右移 16 位可以理解成找到一個整數 α,使得信號幅度值 sample 乘以 α 最接近 32768),直接乘到輸出信號上(這里的輸出信號在函式開始已經被拷貝了輸入信號),
/** 增益陣列gains作用到輸出信號,完成音量均衡 */
for (k = 1; k < 10; k++) {
delta = (gains[k + 1] - gains[k]) * (1 << (4 - L2));
gain32 = gains[k] * (1 << 4);
// iterate over samples
for (n = 0; n < L; n++) {
for (i = 0; i < num_bands; ++i) {
tmp32 = out[i][k * L + n] * (gain32 >> 4);
out[i][k * L + n] = (int16_t)(tmp32 >> 16);
}
gain32 += delta;
}
}
我們以 compressionGaindB = 12dB 的曲線為例,上圖為計算的數字增益表 gainTable 的實際值,下圖為右移 16 位之后得到的實際增益倍數,可以看到 compressionGaindB = 12dB 時,整數部分最大增益為 3,理論上增益 12dB 實際上是放大了 4 倍,這里整數部分最大可以乘上 3 倍,后續再由小數部分補充剩余的 0~1.0 倍,從而可以防止爆音,簡單舉兩個例子:
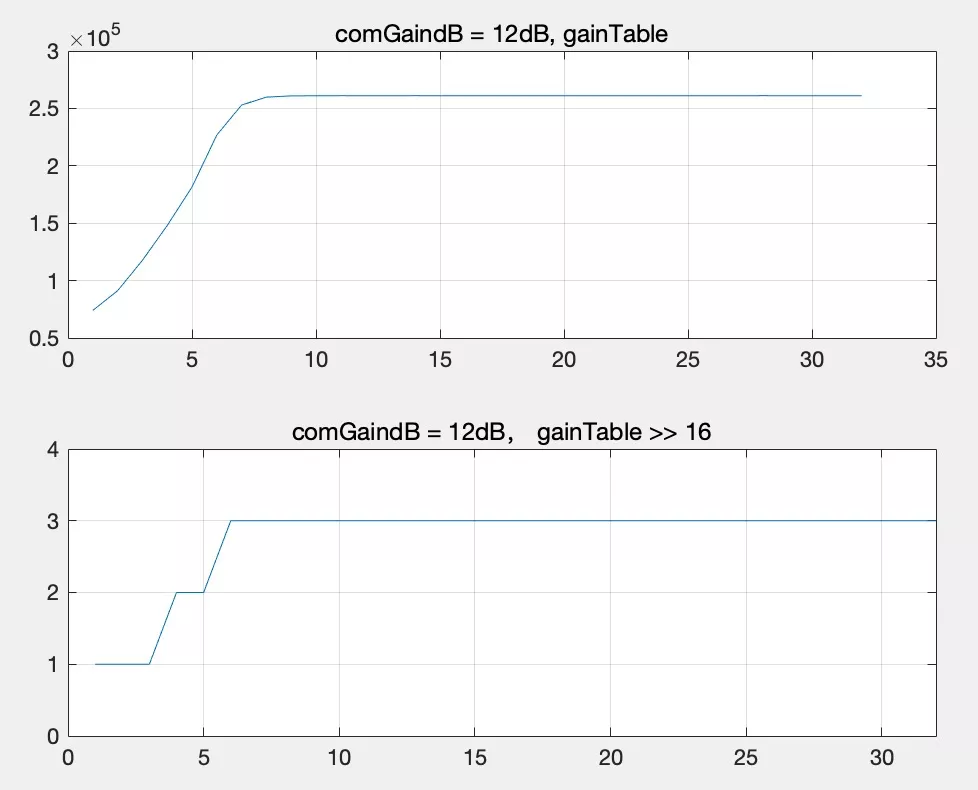
A. 幅度值為 8000 的資料,包絡 cur_level = 8000^2 = 0x3D09000,通過 WebRtcSpl_NormU32 ((uint32_t) cur_level); 計算得到前置 0 有 6 個,查表得到整數部分增益為 stt->gainTable [6] = 3,即 8000 可以大膽乘以 3 倍,之后增益倍數小于 1.0 的部分由 fracpart 決定;
B. 幅度值為 16000 的資料,包絡 cur_level = 16000^2 = 0xF424000,通過 WebRtcSpl_NormU32 ((uint32_t) cur_level); 計算得到前置 0 有 4 個,查表得到整數部分增益為 stt->gainTable [4] = 2,此時會發現 16000 * 2 = 32000,之后均衡到目標音量的程序由 limiter 決定,細節這里不展開,
簡單說就是,[0, 32768] 中的任何一個數想要增益指定的分貝且結果又不超過 32768,都能在數字增益表 gainTable 中找到確定的元素滿足這個要求,
關于目標增益 targetLevelDbfs 和 Limiter 的應用在 WebRtcAgc_ProcessDigital 以及相關函式中均有體現,這里就不展開闡述,大家可以走讀原始碼深入學習,
下面我們用幾個 case 來看看固定數字增益模式的效果和存在的問題,先固定設定 targetLevelDbfs = 1, compressionGaindB = 12,
1. 采集音量較小,均衡后改善不明顯;
設備采集音量 - 24dB, 均衡后音量只有 - 12dB,整體音量聽感上會覺得偏小;
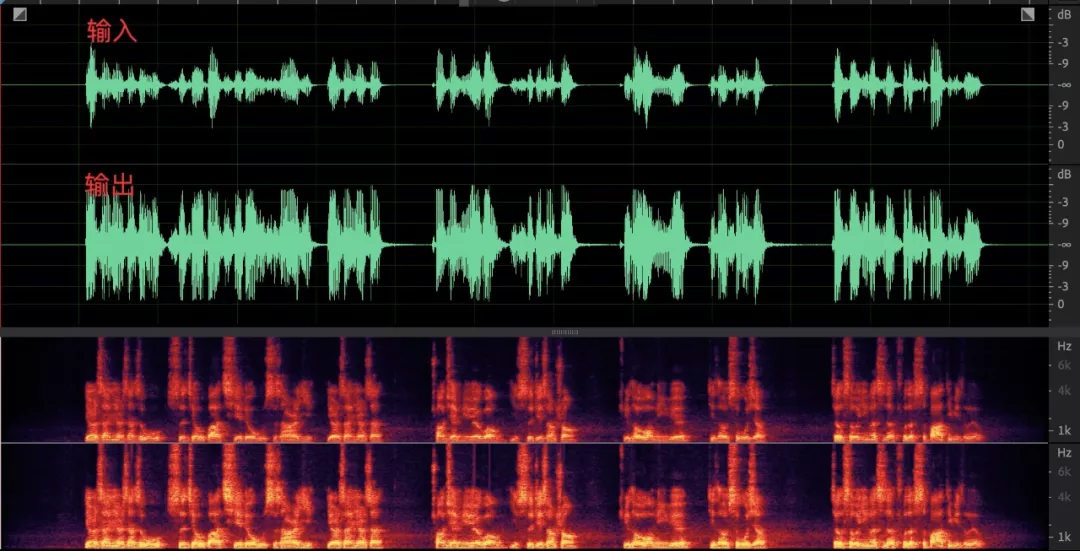
2. 采集音量較大,底噪明顯增強;
設備采集音量 - 9dB, 均衡后音量達到 - 1dB,整體音量聽感上正常,但語音幀間起伏減小,主要是無話段的噪聲部分得到較大提升,這個情況下主要的問題就是當采集音量本身就比較大時,如果環境噪聲較大,且降噪能力不強時,一旦 compressionGaindB 設定較大,那么語音部分會被限制在 targetLevelDbfs,但是無話段部分底噪會得到全量的提升,對端參會人可以聽到明顯的噪聲,
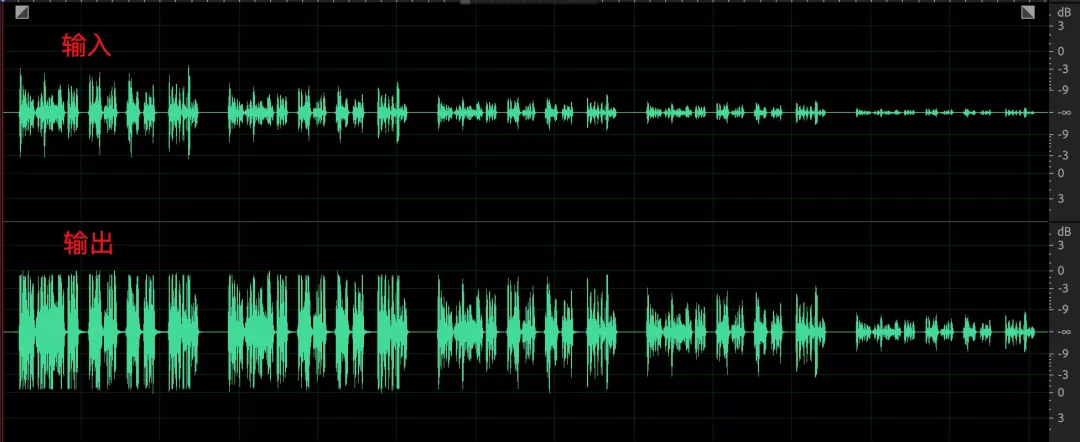
3. 采集聲音起伏較大(以人為拼接的由大到小的音頻為例),均衡后依然無法改善;
自適應模擬增益 - AdaptiveAnalog
在講自適應模擬增益之前,我們需要明確 PC 端影響采集音量的功能:
- PC 端支持調節采集音量,調節范圍為 0~1.0,WebRTC 客戶端代碼內部映射到了 0~255;
/** 以mac為例,麥克風靈敏度被轉成了0~255 */
int32_t AudioMixerManagerMac::MicrophoneVolume(uint32_t& volume) const {
......
// vol 0.0 to 1.0 -> convert to 0 - 255
volume = static_cast<uint32_t>(volFloat32 * 255 + 0.5);
......
return 0;
}
- 絕大多數 windows 筆記本設備內置了麥克風陣列,并提供麥克風陣列增強演算法,降噪的同時還會額外提供 0~10dB 的增益(不同機型范圍不同,聯想的設備增益高達 36dB),如圖 3;
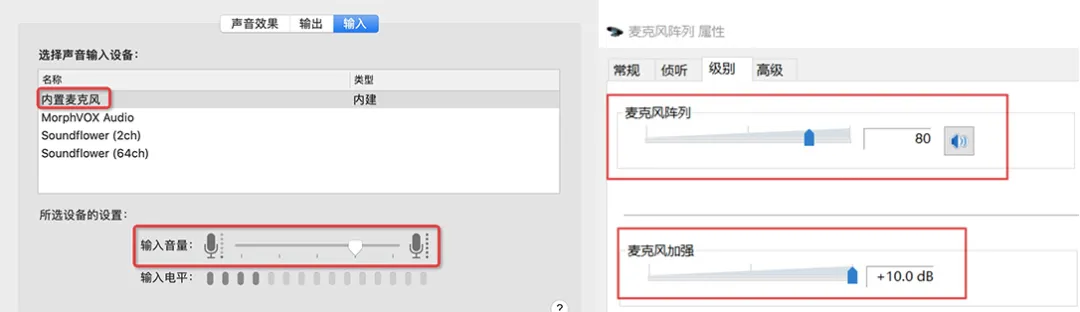
圖 3 左:MAC 端模擬增益調節 右:Windows 端麥克風陣列自帶的增益能力
由于控制音量的模塊過多,導致 PC 端 AGC 演算法更加敏感,線上很多客戶設定的默認值并不合理,這會直接影響音視頻通話的體驗:
- 采集音量過大會導致噪聲被明顯提升,人聲爆音;
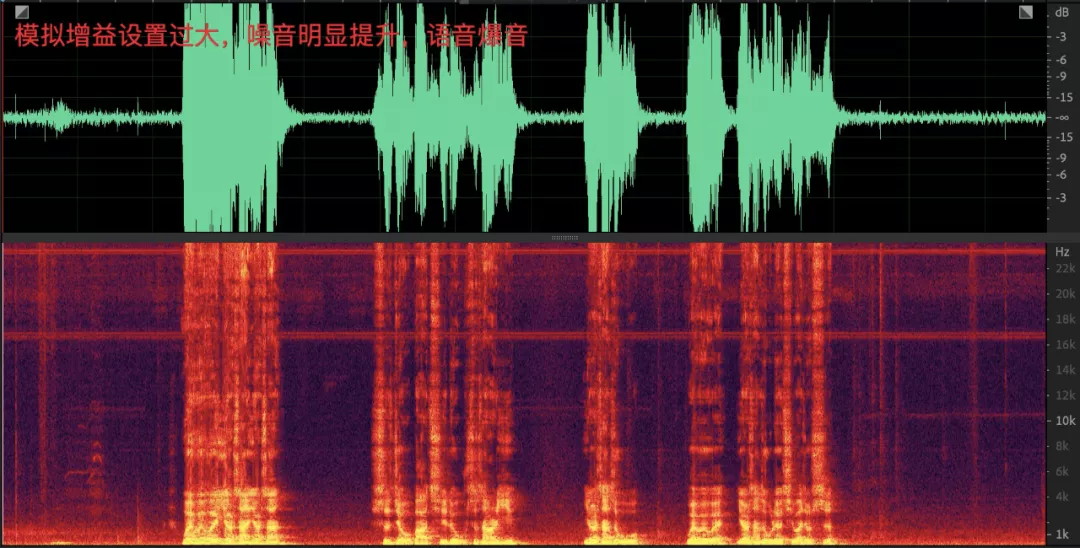
- 采集音量過大會導致播放的信號回采到麥克風之后有較大的非線性失真,對回聲消除演算法是不小的挑戰;
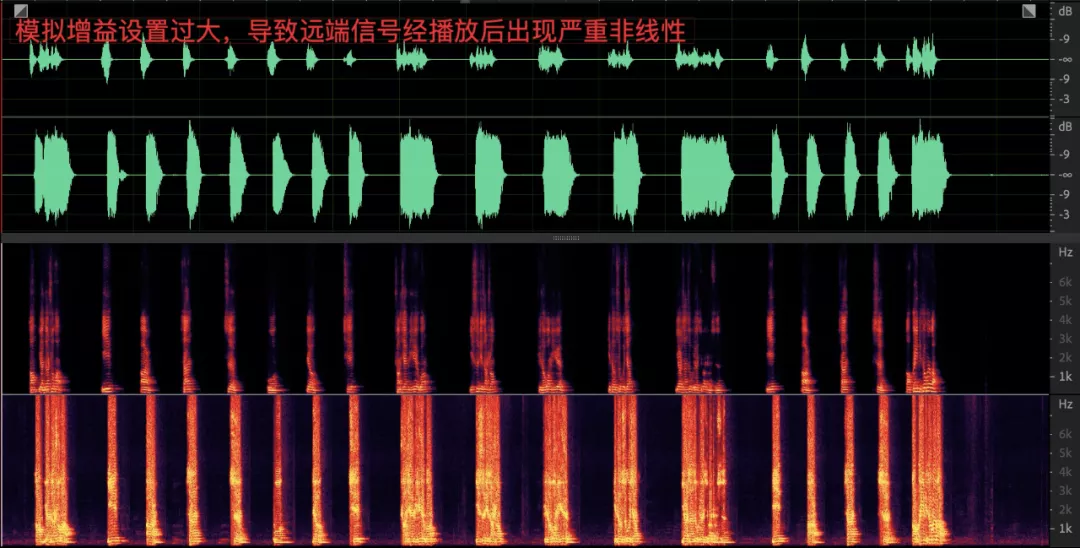
- 采集音量過小,數字增益能力有限導致對端聽不清;
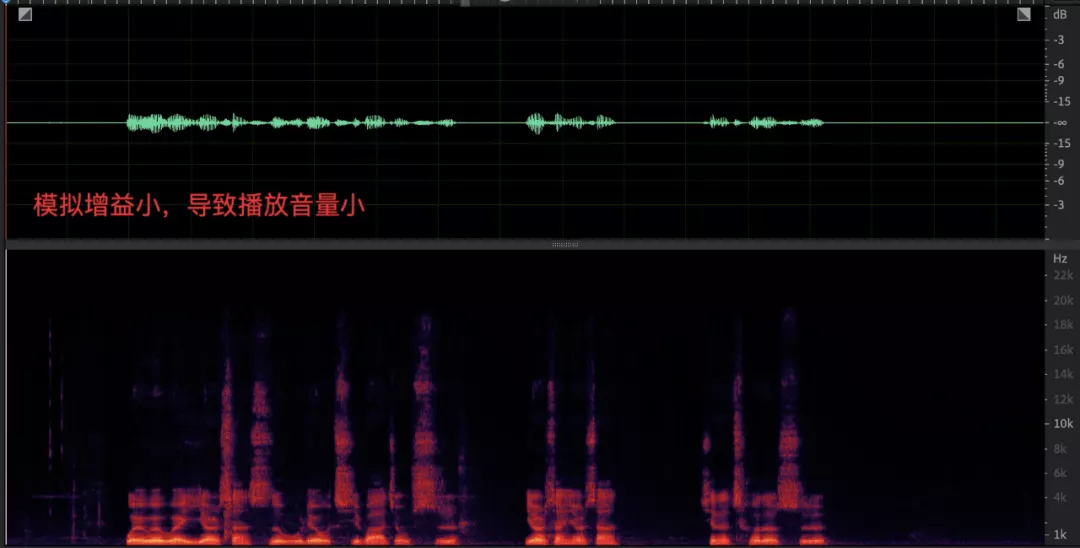
絕大多數用戶在察覺到聲音例外后并不知道 PC 設備還具備手動調節采集增益的功能,依賴于線上用戶(尤其是教育場景很多是小學生)自己去調節模擬增益值幾乎不可能,將模擬增益值動態調節的功能做到 AGC 演算法內部更可行,配合數字增益部分將近端信號均衡到理想的位置,因此,WebRTC 科學家開發設計了自適應模擬增益模式,通過反饋機制來調節原始采集音量,目標就是與數字增益模塊相互配合,找到最合適的麥克風增益值并反饋給設備層,使得近端資料再經過數字增益之后達到目標增益,音頻資料流框圖如下:
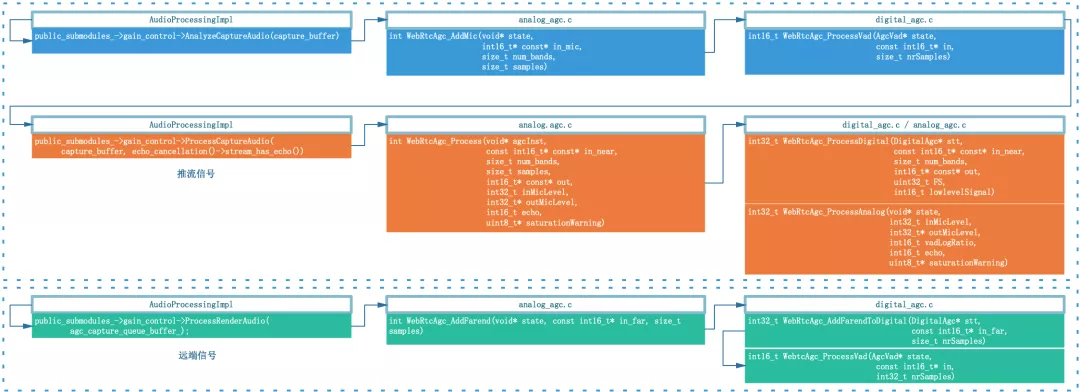
在固定數字增益的基礎上主要有兩處新增:
- 在數字增益之后,新增了模擬增益更新模塊:WebRtcAgc_ProcessAnalog,會根據當前模擬增益值 inMicLevel(WebRTC 中將尺度映射到 0~255)等中間引數,計算下一次需要調節的模擬增益值 outMicLevel,并反饋給設備層,
// Scale from VoE to ADM level range.
uint32_t new_voe_mic_level = shared_->transmit_mixer()->CaptureLevel();
if (new_voe_mic_level != voe_mic_level) {
// Return the new volume if AGC has changed the volume.
new_mic_volume = static_cast<int>((new_voe_mic_level * max_volume +static_cast<int>(kMaxVolumeLevel / 2)) / kMaxVolumeLevel);
return new_mic_volume;
}
- 有些設備商麥克風陣列默認設定比較小,即使將模擬增益調滿采集依然很小,此時就需要數字增益補償部分來改善:WebRtcAgc_AddMic,可以在原始采集的基礎上再放大 1.0~3.16 倍,如圖 4,那么,如何判斷放大不夠呢?上一步中模擬增益更新模塊最終輸出實際為 micVol 與最大值 maxAnalog(255) 之間較小的那個:
*outMicLevel = WEBRTC_SPL_MIN(stt->micVol, stt->maxAnalog) >> stt->scale;
即根據相關的規則計算得到的實際值 micVol 是有可能大于規定的最大值 maxAnalog 的,也就意味著將模擬增益調整到最大也無法達到目標音量,WebRtcAgc_AddMic 會監控這種事件的發生,并會通過查表的方式給予額外的補償,
增益表 kGainTableAnalog:
static const uint16_t kGainTableAnalog[GAIN_TBL_LEN] = {
4096, 4251, 4412, 4579, 4752, 4932, 5118, 5312, 5513, 5722, 5938,
6163, 6396, 6638, 6889, 7150, 7420, 7701, 7992, 8295, 8609, 8934,
9273, 9623, 9987, 10365, 10758, 11165, 11587, 12025, 12480, 12953};
// apply gain
sample = (in_mic[j][i] * gain) >> 12; // 經過右移之后,陣列被量化到0~3.16.
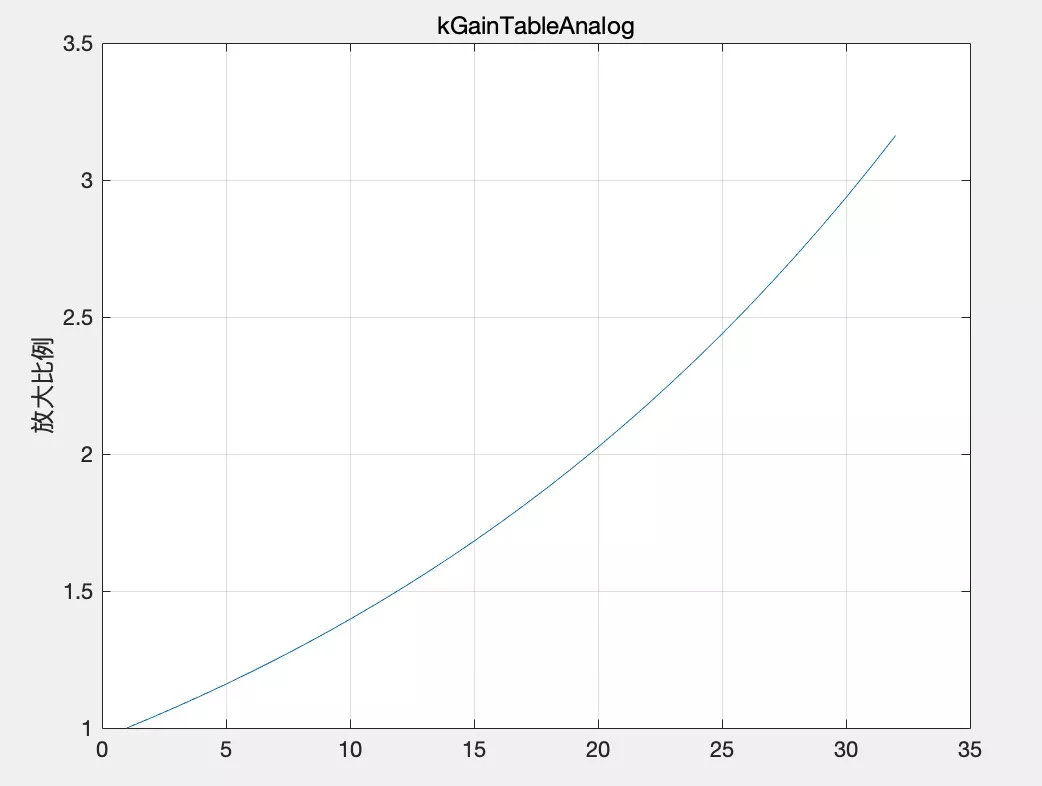
圖 4 增益表的增益曲線
每次以 1 的固定步長補償輸入信號,gainTableIdx = 0 表示放大倍數為 1 倍,即什么也不做,
/* Increment through the table towards the target gain.
* If micVol drops below maxAnalog, we allow the gain
* to be dropped immediately. */
if (stt->gainTableIdx < targetGainIdx) {
stt->gainTableIdx++;
} else if (stt->gainTableIdx > targetGainIdx) {
stt->gainTableIdx--;
}
gain = kGainTableAnalog[stt->gainTableIdx];
// apply gain
sample = (in_mic[j][i] * gain) >> 12;
存在的問題:
- 無語音狀態下的模擬值上調行為;
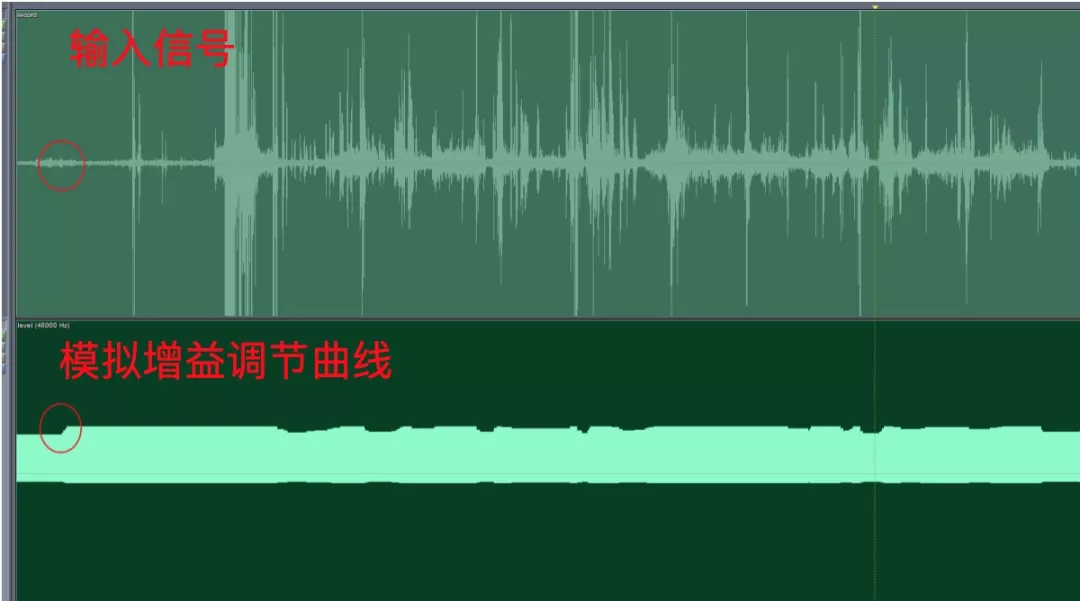
- 調整幅度過大,造成明顯的聲音起伏;

- 頻繁調整作業系統 API,帶來不必要的性能消耗,嚴重的會導致執行緒阻塞;
- 數字部分增益能力有限,無法與模擬增益形成互補;
- 爆音檢測不是很敏感,不能及時下調模擬增益;
- AddMic 模塊精度不夠,補償程序中存在爆音的風險爆音,
自適應數字增益 - AdaptiveDigital
基于音頻視頻通信的娛樂、社交、在線教育等領域離不開多種多樣的智能手機和平板設備,然而這些移動端并沒有類似 PC 端調節模擬增益的介面,聲源與設備的距離,聲源音量以及硬體采集能力等因素都會影響采集音量,單純依賴固定數字增益效果十分有限,尤其是多人會議的時候會明顯感受到不同說話人的音量并不一致,聽感上音量起伏較大,
為了解決這個問題,WebRTC 科學家仿照了 PC 端模擬增益調節的能力,基于模擬增益框架新增了虛擬麥克風調節模塊:WebRtcAgc_VirtualMic,利用兩個長度為 128 的陣列:增益曲線 - kGainTableVirtualMic 和抑制曲線 - kSuppressionTableVirtualMic 來模擬 PC 端模擬增益(增益部分為單調遞增的直線,抑制部分為單調遞減的凹曲線),前者提供 1.0~3.0 倍的增益能力,后者提供 1.0~0.1 的下壓能力,
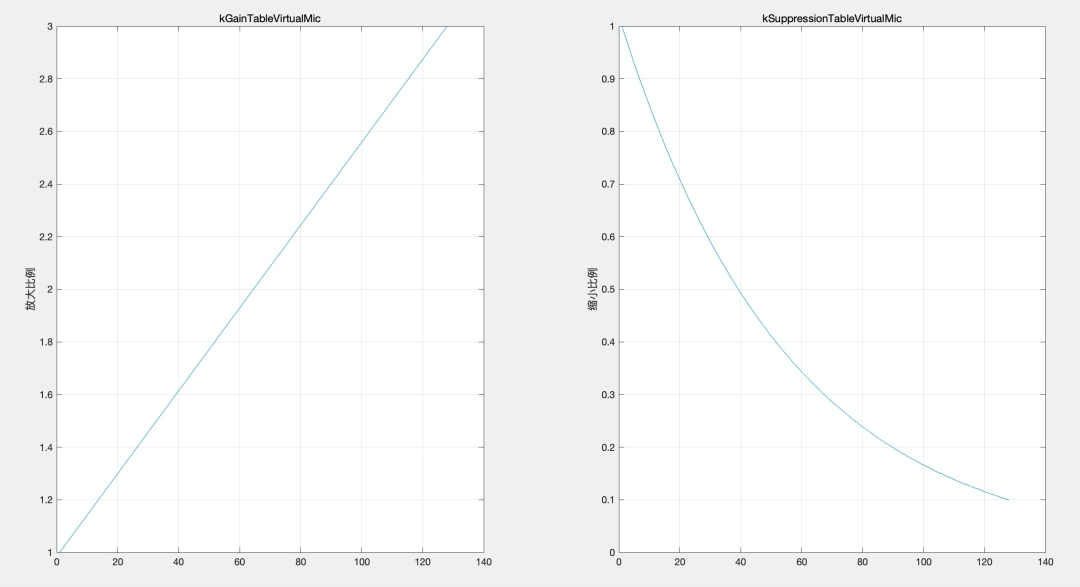
圖 5 增益曲線與抑制曲線
核心邏輯邏輯與自適應模擬增益一致,
- 與自適應模式增益模式一樣,依然利用 WebRtcAgc_ProcessAnalog 更新 micVol;
- 根據 micVol 在 WebRtcAgc_VirtualMic 模塊中更新增益下標 gainIdx,并查表得到新的增益 gain;
/* 設定期望的音量水平 */
gainIdx = stt->micVol;
if (gainIdx > 127) {
gain = kGainTableVirtualMic[gainIdx - 128];
} else {
gain = kSuppressionTableVirtualMic[127 - gainIdx];
}
- 應用增益 gain,期間一旦檢測到飽和,會逐步遞減 gainIdx;
/* 飽和檢測更新增益 */
if (tmpFlt > 32767) {
tmpFlt = 32767;
gainIdx--;
if (gainIdx >= 127) {
gain = kGainTableVirtualMic[gainIdx - 127];
} else {
gain = kSuppressionTableVirtualMic[127 - gainIdx];
}
}
if (tmpFlt < -32768) {
tmpFlt = -32768;
gainIdx--;
if (gainIdx >= 127) {
gain = kGainTableVirtualMic[gainIdx - 127];
} else {
gain = kSuppressionTableVirtualMic[127 - gainIdx];
}
}
- 增益后的資料傳入 WebRtcAgc_AddMic,檢查 micVol 是否大于最大值 maxAnalog 決定是否需要激活額外的補償,
音頻資料流框圖如下:
存在的問題與自適應模式增益相似,這里需要明確說的一個問題是數字增益自適應調節靈敏度不高,當輸入音量起伏時容易出現塊狀拉升或壓縮,用一個比較明顯的例子說明:遇到大音量時需要呼叫壓縮曲線,如果后面緊跟較小音量,會導致小音量進一步壓縮,接著會調大增益,此時小音量后續如果接著跟大音量,會導致大音量爆音,需要 limiter 參與壓限,對音質是存在失真的,

總結與優化方向
為了更好的聽感體驗,AGC 演算法的目標就是忽略設備采集差異,依然能夠將推流端音頻音量均衡到理想位置,杜絕音量小、杜絕爆音、解決多人混音后不同人聲音量起伏等核心問題,
針對上述章節提到的各個模式存在的問題,有如下幾點啟示:
- 模擬增益調節,必須修復調節頻繁,步長過大等問題;
- AddMic 部分精度不夠,可以提前預判,不要等到檢測到爆音再回呼;
- PC 端數字增益和模擬增益模塊上是相互獨立的,但是效果上應該是相互補償的;
- AGC 對音量的均衡不應該影響 MOS,不能因為追求靈敏度放棄了 MOS,
另外,代碼中很多位運算初讀起來比較容易勸退,希望大家抓核心代碼,形成整體框架后多實踐,再吸收消化,
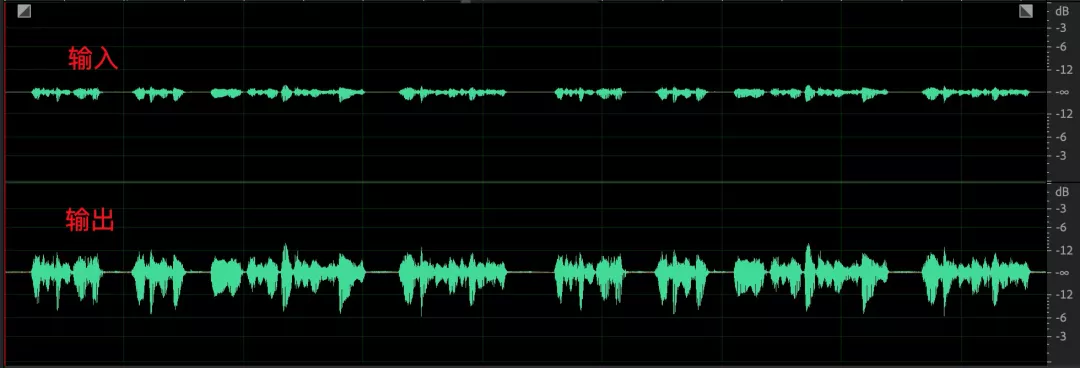
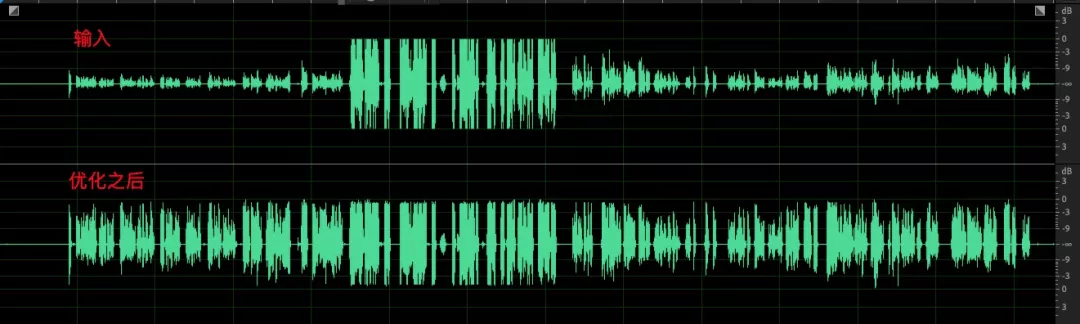
最后,讓我們看看優化后的效果:
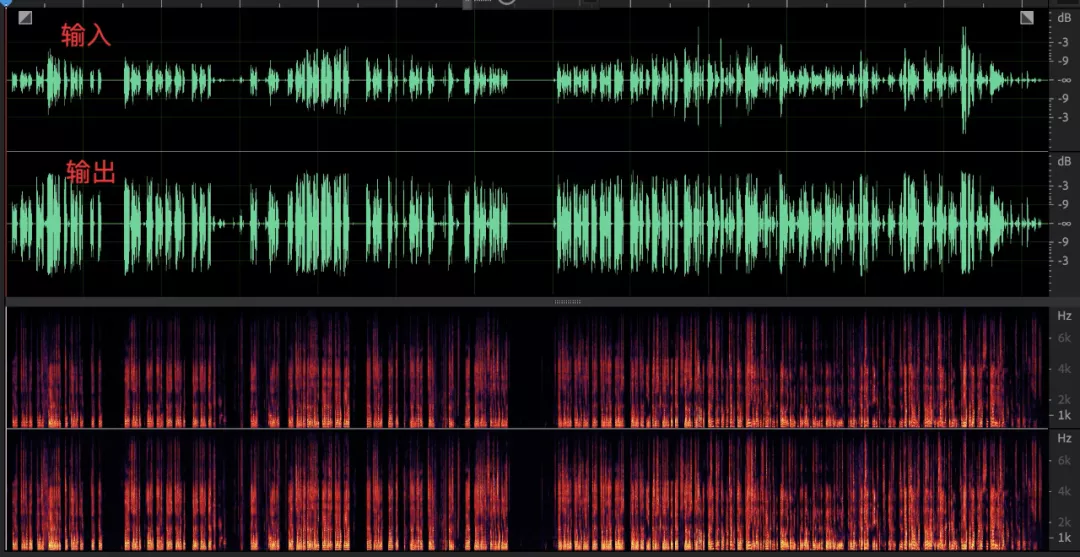
- 模擬增益調節之后,采集的音頻信號音量存在起伏,經過數字部分均衡后音頻包絡保持較好,音量整體一致;
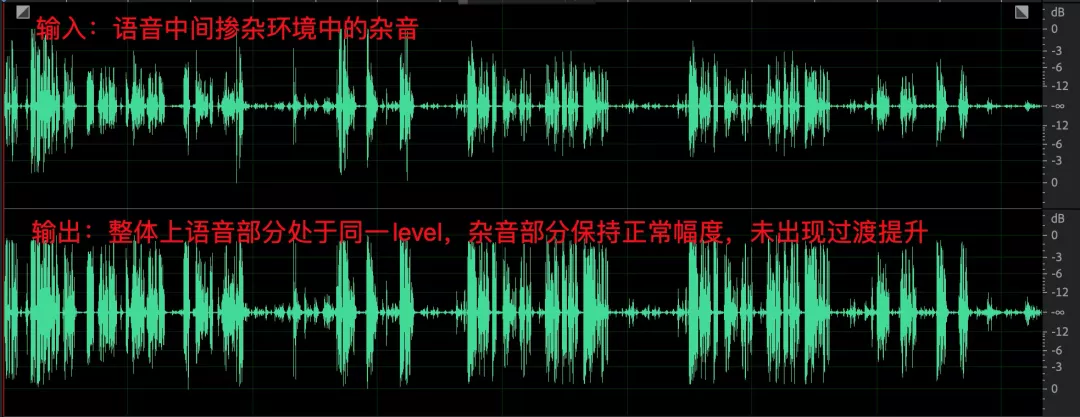
- 語音和環境中的雜音,經過 AGC 之后語音部分音量起伏減小,雜音部分未見明顯提升;
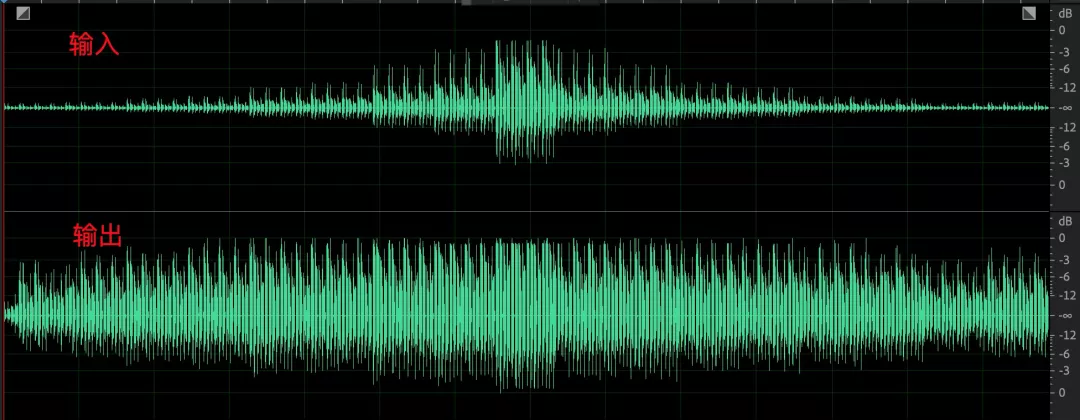
- 一個比較極端的 case,小語音部分最大提升了 35dB,收斂時間保持在 10s 以內,
「視頻云技術」你最值得關注的音視頻技術公眾號,每周推送來自阿里云一線的實踐技術文章,在這里與音視頻領域一流工程師交流切磋,公眾號后臺回復【技術】可加入阿里云視頻云技術交流群,和作者一起探討音視頻技術,獲取更多行業最新資訊,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/285722.html
標籤:其他