作者
何鵬飛,騰訊云專家產品經理,曾作為容器私有云、TKEStack的產品經理兼架構師,參與騰訊云內部業務、外部客戶容器化改造方案設計,目前負責云原生混合云產品方案設計作業,
胡曉亮,騰訊云專家工程師,專注云原生領域,目前負責開源社區TKEStack和混合云專案的設計和開發作業,
前言
混合云是一種部署形態,一方面企業可從資產利舊、成本控制、控制風險減少鎖定等角度選擇混合云,另一方面企業也可以通過混合業務部署獲得不同云服務商的相對優勢能力,以及讓不同云服務商的能力差異形成互補, 而容器和混合云是天作之合,基于容器標準化封裝,大大降低了應用運行環境與混合云異構基礎設施的耦合性,企業更易于實作多云/混合云敏捷開發和持續交付,使應用多地域標準管理化成為可能,
TKE 容器團隊提供了一系列的產品能力來滿足混合云場景,本文介紹其中針對突發流量場景的產品特性——第三方集群彈 EKS,
低成本擴容
IDC 的資源是有限的,當有業務突發流量需要應對時,IDC 內的算力資源可能不足以應對,選擇使用公有云資源應對臨時流量是不錯的選擇,常見的部署架構為:在公有云新建一個集群,將部分作業負載部署到云上,通過 DNS 規則或負載均衡策略將流量路由到不同的集群:
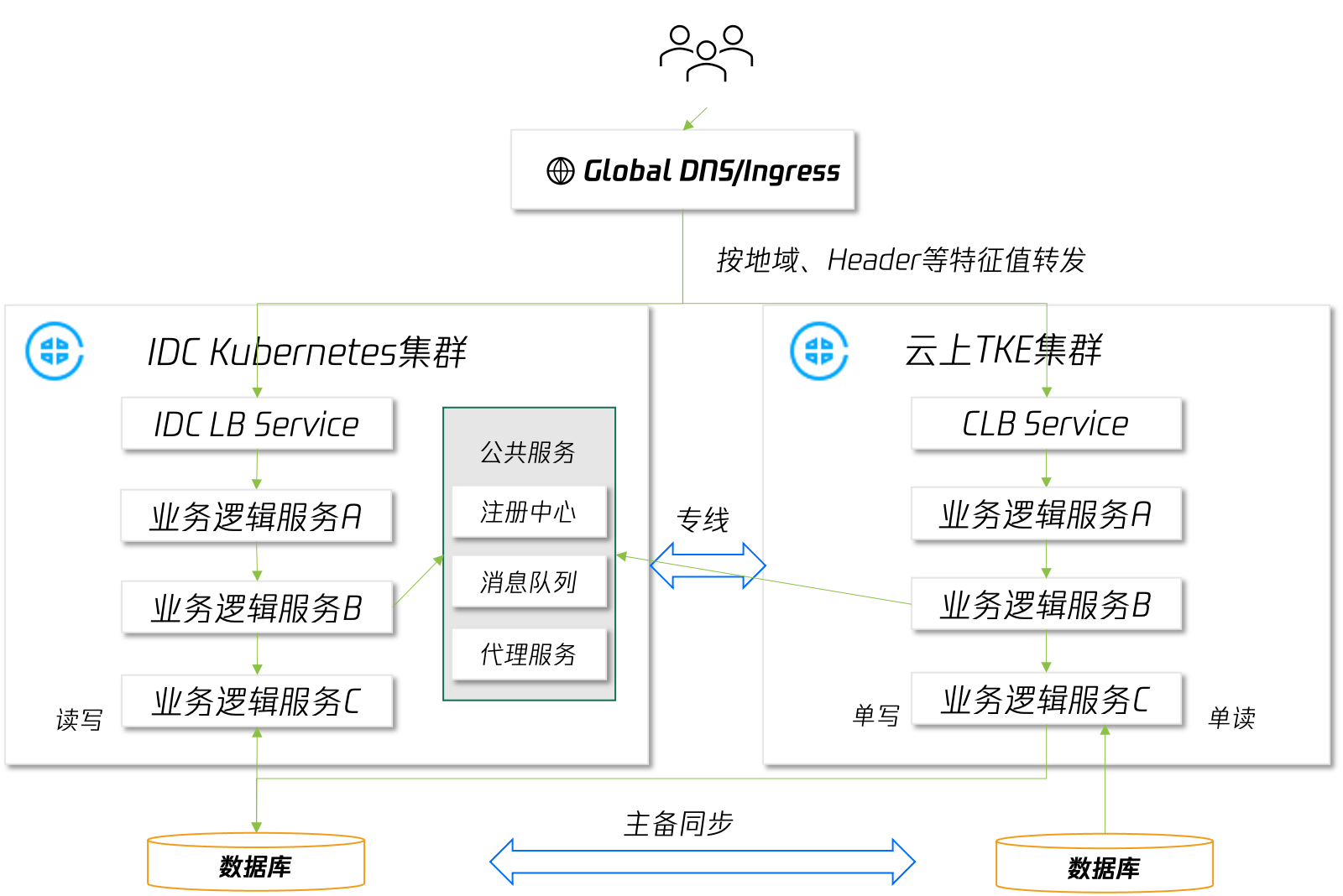
此種模式下,業務的部署架構發生了變化,因此在使用前需要充分評估:
- 哪些業務作業負載需要在云上部署,是全部還是部分;
- 云上部署的業務是否有環境依賴,例如 IDC 內網 DNS、DB、公共服務等;
- 云上、云下業務日志、監控資料如何統一展示;
- 云上、云下業務流量調度規則;
- CD 工具如何適配多集群業務部署;
這樣的改造投入對于需要長期維持多地域接入的業務場景來說是值得的,但對于突發流量業務場景來說成本較高,因此我們針對這種場景推出了便捷在單集群內利用公有云資源應對突發業務流量的能力:第三方集群彈 EKS,EKS是騰訊云彈性容器服務,可以秒級創建和銷毀大量 POD 資源,用戶僅需提出 POD 資源需求即可,無需維護集群節點可用性,對于彈性的場景來說是非常合適的,僅需要在集群中安裝相關插件包即可快速獲得擴容到 EKS 的能力,
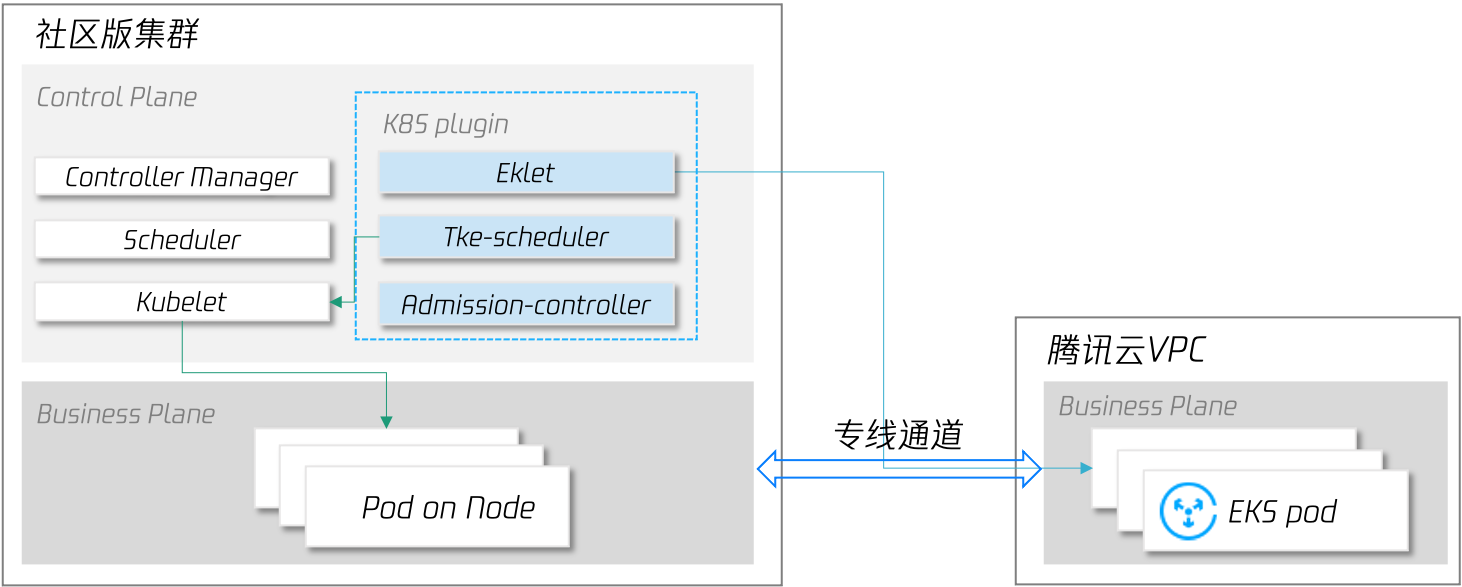
與直接使用云上虛擬機節點相比,此種方式擴縮容更快,并且我們還提供了2種調度機制來滿足客戶的調度優先級需求:
全域開關: 在集群層面,當集群資源不足時,任何需要新創建Pod的作業負載都可以將副本創建到騰訊云 EKS 上;
區域開關: 在作業負載層面,用戶可指定單個作業負載在本集群保留N個副本后,其他副本在騰訊云 EKS 中創建;
為了確保所有作業負載在本地 IDC 均有足夠的副本數,當突發流量過去,觸發縮容時,支持優先縮容騰訊云上 EKS 副本(需要使用 TKE 發行版集群,關于 TKE 發行版的詳細介紹,請期待后續發布的該系列文章),
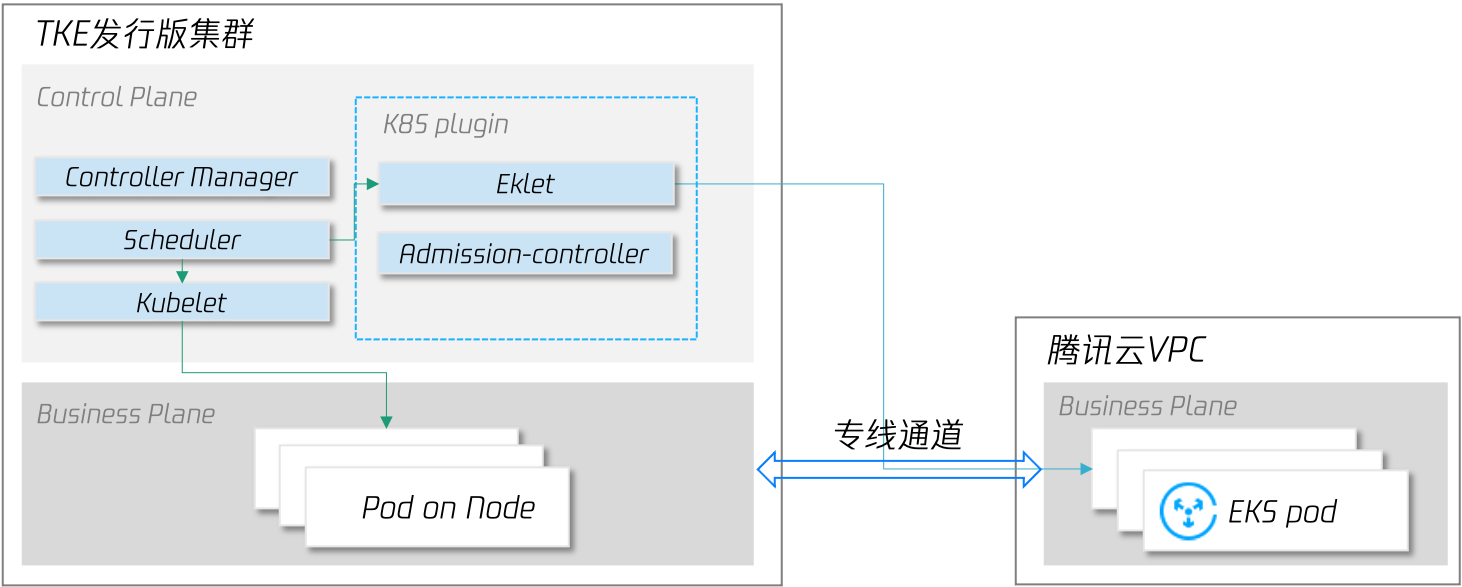
這種模式下,業務部署架構沒有發生變化,在單集群中即可彈性使用云上資源,避免了引入業務架構改造、CD流水線改造、多集群管理、監控日志統等一系列衍生問題,并且云上資源的使用是按需使用,按需計費,大大降低了用戶使用成本,但為了保障作業負載的安全性和穩定性,我們要求用戶的 IDC 與騰訊云公有云 VPC 專線互通,并且用戶也需要從存盤依賴、延時容忍度等多方面評估適用性,
EKS pod 可與 underlay 網路模式的本地集群 pod、node 互通(需要在騰訊云VPC中添加本地pod cidr的路由,參考路由配置),第三方集群彈 EKS 已在 TKEStack中開源,詳細使用方式和示例見 使用檔案
實戰演示
步驟
獲取 tke-resilience helm chart
git clone https://github.com/tkestack/charts.git
配置 VPC 資訊:
編輯 charts/incubator/tke-resilience/values.yaml,填寫以下資訊:
cloud:
appID: "{騰訊云賬號APPID}"
ownerUIN: "{騰訊云用戶賬號ID}"
secretID: "{騰訊云賬號secretID}"
secretKey: "{騰訊云賬號secretKey}"
vpcID: "{EKS POD放置的VPC ID}"
regionShort: {EKS POD 放置的region簡稱}
regionLong: {EKS POD 放置的region全稱}
subnets:
- id: "{EKS POD 放置的子網ID}"
zone: "{EKS POD 放置的可用區}"
eklet:
podUsedApiserver: {當前集群的API Server地址}
安裝 tke-resilience helm chart
helm install tke-resilience --namespace kube-system ./charts/incubator/tke-resilience/
確認 chart pod 作業正常

創建 demo 應用 nginx:ngx1
效果演示:
全域調度
由于此特性默認已開啟,我們先將kube-system 中 的 AUTO_SCALE_EKS 設定為 false
默認情況下,ngx1 副本數為1

將ngx1副本數調整為50
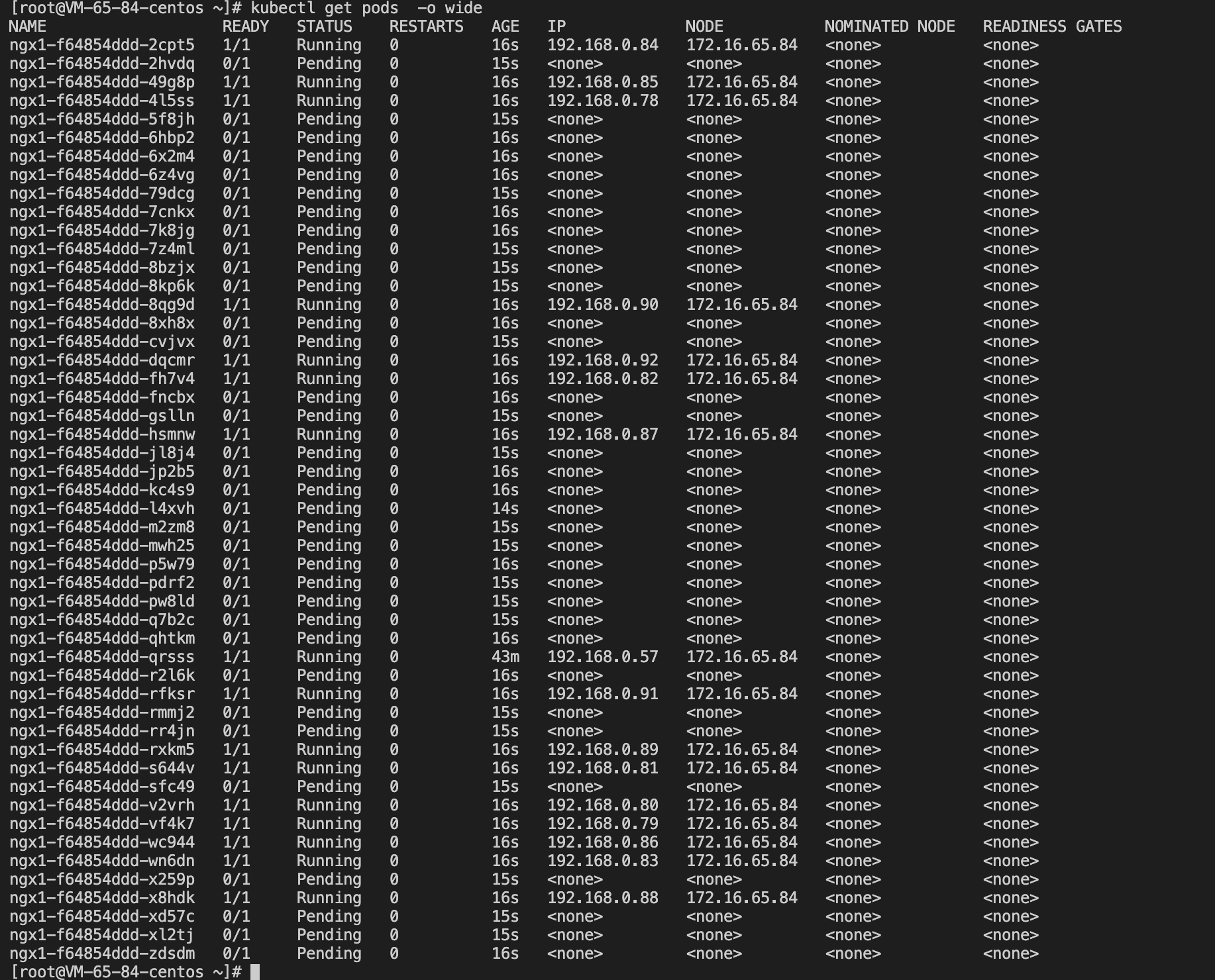
可以看到有大量 POD 因為資源不足,處于 pending 狀態
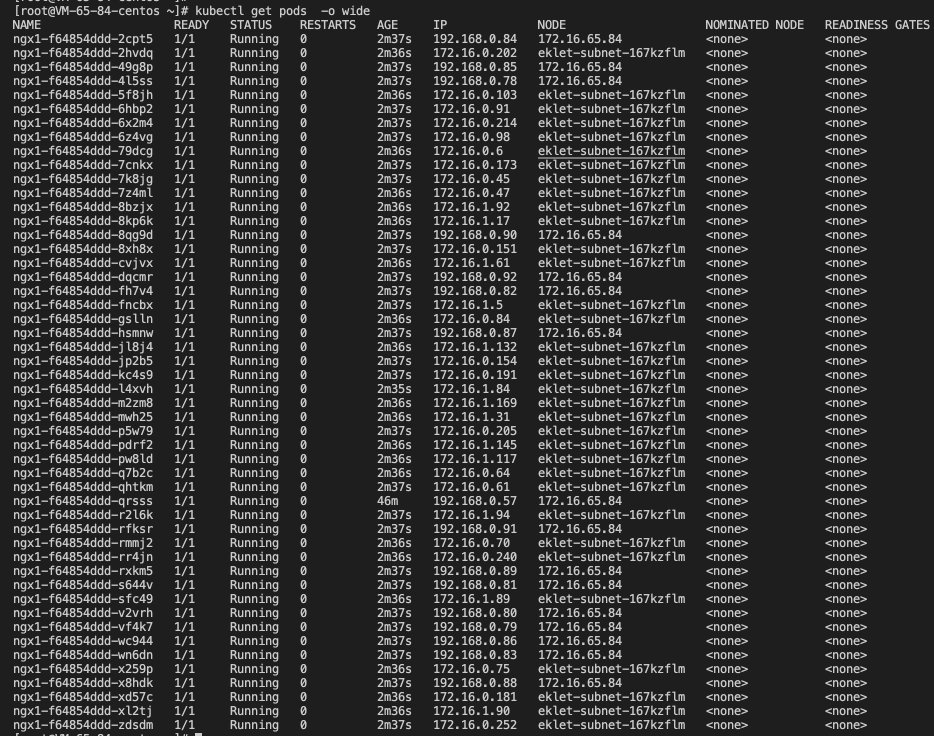
將 kube-system 中 的 AUTO_SCALE_EKS 設定為 true 后,短暫等待后,觀察pod狀態,原本處于 pend的pod,被調度到了 EKS 虛擬節點:eklet-subnet-167kzflm 上,
指定調度
我們再次將 ngx1 的副本數調整為1

編輯 ngx1 yaml,設定開啟區域開關
spec:
template:
metadata:
annotations:
# 打開區域開關
AUTO_SCALE_EKS: "true"
# 設定需要在本地集群創建的副本個數
LOCAL_REPLICAS: "2""
spec:
# 使用tke調度器
schedulerName: tke-scheduler
將 ngx1 副本數改為3,盡管本地集群沒有出現資源不足,但可以看到,超過2個本地副本后,第三個副本被調度到了EKS上

卸載 tke-resilience 插件
helm uninstall tke-resilience -n=kube-system
此外 TKEStack 已集成 tke-resilience,用戶可以在 TKEStack 的應用市場中界面化安裝 tke-resilience
應用場景
云爆發
電商促銷、直播等需要在短時間擴容大量臨時作業負載的場景,這種場景下,資源需求時間非常短,為了應對這種短周期需求而在日常儲備大量資源,勢必會有比較大的資源浪費,且資源需求量隨每次活動變化難以準確評估,使用此功能,您無需關注于資源籌備,僅需依靠K8S的自動伸縮功能,即可快速為業務創建出大量作業負載為業務保駕護航,流量峰值過去后,云上POD會可優先銷毀,確保無資源浪費的情況,
離線計算
大資料、AI業務場景下,計算任務對算力亦有高彈性要求,為保障任務快速計算完成,需要在短時間能有大量算力支撐,而計算完成后,算力同樣處于低負載狀態,計算資源利用率呈高波動型,形成了資源浪費,并且由于GPU資源的稀缺性,用戶自己囤積大量GPU設備不僅成本非常高,還會面臨資源利用率提升,新卡適配,老卡利舊,異構計算等多種資源管理問題,而云上豐富的GPU卡型可為用戶提供更多樣的選擇,即用即還的特性也確保了資源零浪費,每一分錢都真正化在真實的業務需求上,
未來演進
- 多地域支持,支持應用部署到云上多個區域,應用與地域關聯部署等特性
- 云邊結合,結合 TKE-Edge,針對弱網路場景提供應用部署、調度策略,擺脫專線依賴
【騰訊云原生】云說新品、云研新術、云游新活、云賞資訊,掃碼關注同名公眾號,及時獲取更多干貨!!

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/285793.html
標籤:其他
下一篇:API設計