第4章 表示學習
在第2章的時候提到了機器學習的第一步就是提取特征,而表示學習就是自動地從資料中學習特征,并直接用于后續的任務,
4.1 表示學習
4.1.1 表示學習的意義
表示學習要回答3個問題:
- 如何判斷一個表示比另一個表示更好?
- 如何挖掘這些表示?
- 使用什么樣的目標去得到一個好的表示?
舉一個例子就是一個影像,計算機能夠得到的知識一個個像素點這樣的原始資料,只關注像素點是無法得到一些具體資訊的;而人在看到一個影像的時候自然會通過高層的抽象語意來判斷,一個好的表示就應該盡可能提供高層次的有價值的特征,
4.1.2 離散表示與分布式表示
機器學習中對一個物件的表示有兩種常見的方式:獨熱編碼(one-hot)和分布式表示,
獨熱碼就是表示成一個響亮,只在某個維度上為1,其余全為0,
分布式表示就是得到一個低維稠密的向量來表示研究物件,典型的例子就是顏色,可以用RGB值的三元組來表示,
獨熱碼表示起來非常簡單,但它會使得所有不同的表示都是相互獨立(正交)的,這會讓它表示起來丟失大量的語意資訊,而分布式表示就能夠保留這些語意資訊,當然相應的也會比獨熱碼實作起來更復雜一點,
4.1.3 端到端學習
所謂端到端學習就是以原始輸入作為輸入,并直接輸出想要得到結果(比如分類),相應的,傳統的機器學習模型中,一些作業都是先處理輸入,通過特征工程提取出特征,之后再交由分類器進行判斷,
由此端到端學習可以看作是表示學習與任務學習的結合(提取特征+分類),它們不是完全分裂的,而是聯合優化的,一次反向傳播更新的不只是基于特征給出分類結果的引數,還更新了提取特征的引數使得整個模型的效果會更好,這體現了深度學習模型的優越性,
深度學習模型另一個優勢是能夠學習到資料的層次化表達,低層次的特征更加通用,高層次的特征則更貼近具體任務,所以對于一些比較相近的任務,其實是可以使用相同的低層次特征的,這讓深度學習可以進行遷移學習,
4.2 自編碼器:基于重構損失的方法
自編碼器是一種無監督的學習模型,可以用于資料降維和特征提取,
4.2.1 自編碼器
自編碼器的思路是:將輸入映射到某個特征空間,再從這個特征空間映射回輸入空間進行重構,結構上看它由編碼器和解碼器組成,編碼器用于從輸入中提取特征,解碼器則用于從特征重構出輸入資料,
考慮一個最簡單的自編碼器:1個輸入層、1個隱藏層、1個輸出層,那么從輸入到隱藏層就是編碼器,從隱藏層到輸出層就是解碼器,
對于輸入\(x\in R^n\),輸入層到隱藏層的變換矩陣為\(W_{enc}\in R^{n\times d}\),\(d\)是隱藏層神經元數目,
經過變換\(h=\sigma(W_{enc}x+b_{enc})\)得到編碼后的特征\(h\in R^d\),
解碼器將特征\(h\)映射回輸入空間,隱藏層的輸出層的變換矩陣為\(W_{dec}\in R^{d\times n}\),經過變換\(\widetilde x=\sigma(W_{dec}h+b_{dec})\)得到重構的輸入\(\widetilde x\),
自編碼器不需要標簽進行監督學習,其是通過不斷最小化輸入和輸出之間的重構誤差來進行訓練的,利用損失函式\(L=\frac{1}{N}\Sigma_i||x_i=\widetilde x_i||_2^2\),通過反向傳播計算梯度,再通過梯度下降優化\(W_{enc},W_{dec},b_{enc},b_{dec}\),
一般來說編碼器和解碼器會用更復雜的模型,用函式\(f,g\)來表示,那么損失就變為\(L=\frac{1}{N}\Sigma_i||x_i=g(f(x_i))||_2^2\),
關于這個判斷\(x_i\)是否相等的二范數損失我有點不知道具體是怎么算的,稍微查了查資料沒找到什么有用的,有朋友知道的話歡迎評論區指教!
比較容易混淆的一點是:這個自編碼器先編碼再解碼,最后得到的不還是原始輸入或者逼近原始輸入的東西嗎?所以要特別注意,自編碼器訓練完后,是直接拿輸入過一個編碼器進行特征提取再放到后面的神經網路里去的,解碼器就用不到了,有種GAN的思想,
實際使用中,通常有\(d<n\),因為要進行降維嘛,符合這種條件的編碼器被稱為欠完備自編碼器,
4.2.2 正則自編碼器
如果編碼器的維度大于等于輸入的維度\(d\ge n\),那么就被稱為過完備自編碼器,如果不對過完備自編碼器進行一些限制,那么其可能會更傾向于將輸入拷貝到輸出,從而得不到特征,因此通常會對模型進行一些正則化的約束,
去噪自編碼器
去噪自編碼器在原始輸入的基礎上加入了一些噪聲作為輸入,這使得解碼器需要重構出不加入噪聲的原始輸入,這迫使編碼器不能簡單地進行一個恒等變換,而必須能夠從含噪聲的輸入中提取出原始輸入,
加入噪聲的具體方法是隨機將輸入\(x\)中的一部分置為0,得到\(x_\delta\)作為輸入,解碼器則需要得到原始的輸入\(x\),那么有損失函式:\(L=\frac{1}{N}\Sigma_i||x=g(f(x_\delta))||^2_2\),
稀疏自編碼器
在損失函式上加入正則項使得模型學習到有用的特征,比如隱藏層使用Sigmoid激活函式,我們認為神經元的輸出接近1時是活躍的,而接近0時是不活躍的,稀疏自編碼器就是限制神經元的活躍度來約束模型,盡可能使大多數神經元處于不活躍的狀態,
定義神經元的活躍度為它在所有樣本上的平均值,用\(\hat\rho_i\),限制\(\hat\rho_i=\rho_i\),\(\rho_i\)是一個超引數,表示期望的活躍度,通常是接近于0的值,對偏離超引數較大的神經元進行懲罰就可以得到稀疏的編碼特征,用相對熵作為正則項有\(L_{sparse}=\Sigma^d_{j=1}\rho log\frac{\rho}{\hat\rho_j}+(1-\rho)log\frac{1-\rho}{1-\hat\rho_j}\),
相對熵可以量化表示兩個概率分布之間的差異,當兩個分布相差越大時相對熵值越大;兩個分布完全相同時相對熵值為0,
最后的損失函式為\(L=L(x_i,g(f(x_i))+\lambda L_{sparse}\),其中\(\lambda\)是調節重構項與稀疏正則項的權重,
4.2.3 變分自編碼器
變分自編碼器可以用于生成新的樣本資料,
變分自編碼器的原理
變分自編碼器的本質是生成模型,其假設樣本都是服從某個分布\(P(x)\),通過建模\(P(X)\),就可以從分布中進行采樣得到新的樣本資料,
一般來說每個樣本都可能受到一些因素的控制,稱為隱變數,假設有多個隱變數,用向量\(z\)表示,概率密度函式為\(p(z)\),同時有一個函式\(f(z:\theta)\)可以吧\(p(z)\)中采樣的資料\(z\)映射為與\(X\)比較相似的資料樣本,即\(p(X|z)\)的概率更高,
(再后續的介紹超級數學而且推導的也不是很詳細,我也沒太看明白就暫且先跳過,這一部分權當是對變分自編碼器的簡單了解)
變分自編碼器 vs 自編碼器
傳統的自編碼器的隱藏層空間是不連續的,其由樣本點編碼構成,如果輸入樣本中沒有那么在隱藏層中也就沒有對應的特征,解碼器也就不能給出有意義的輸出,而變分自編碼器則是要建模樣本的分布\(p(x)\),所以之后解碼器可以生成樣本,
4.3 word2vec:基于對比損失的方法
Word2vec模型將詞嵌入到一個向量空間中,用低維的向量表達每個詞,并且語意相關的詞距離更近,
Skip-gram詞向量模型
Word2vec的核心思想是用一個詞的背景關系去刻畫這個詞,對應的有兩種模型:給定某個中心詞的背景關系去預測中心詞,CBow模型;給定一個中心詞預測其背景關系詞,Skip-gram模型,
給定一個表示長度為N的語料庫的序列\(C=\{w_1,...,w_N\}\),單詞詞表為V,有\(w_i\in V\),Skip-gram模型使用中心詞預測背景關系,定義背景關系詞為以中心詞為中心的某個視窗內的詞,視窗大小為\(2m+1\),我們希望的事給定某個中心詞,輸出詞為背景關系的概率最大,
看下圖,對于一個文本,選擇中心詞“網路”,取\(m=2\),以中心詞及其背景關系詞構成的單詞為正樣本\(D\),否則構成負樣本\(\bar D\),
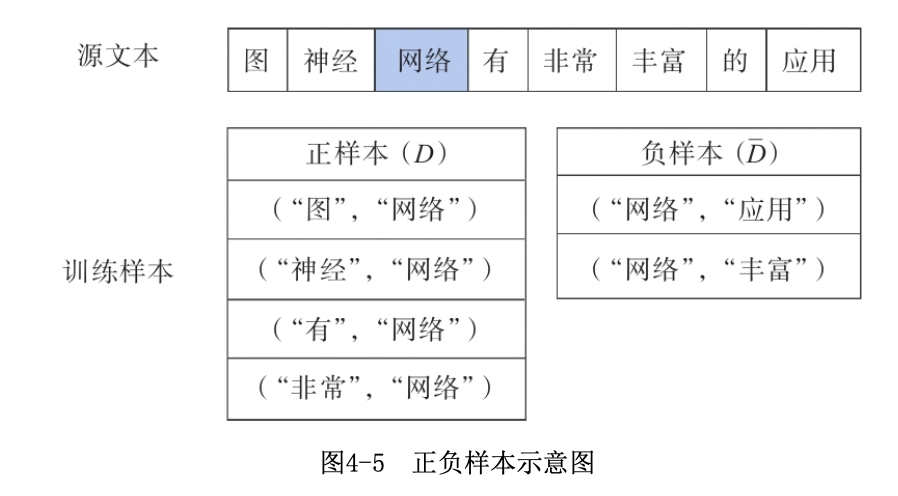
對正負樣本定義標簽\(\text{label}=\begin{cases}y=1 & \text{if }(w_c,w)\in D\\ y=0 & \text{if }(w_c,w)\in \bar D \end{cases}\),
我們的目的是找到條件概率\(p(y=1|(w_c,w))\)和\(p(y=0|(w_c,w))\)最大化的引數\(\theta\):\(\theta'=argmax\prod_{(w_c,w)\in D}p(y=1|(w_c,w);\theta)\prod_{(w_c,w)\in \bar D}p(y=0|(w_c,w);\theta)\),
這樣就得到了一個二分類的問題,任意給定兩個詞判斷是否是背景關系詞,可以用邏輯回歸來建模這個問題,引入矩陣\(U\in R^{|D|\times d},V\in R^{|D|\times d}\),每一行代表著一個詞,前者代表詞作為中心詞的表達,而后者代表詞作為背景關系詞的表達,那么可以得到\(p(y|(w_c,w))=\begin{cases}\sigma(U_{w_c}·V_w)&\text{if }y=1 \\ 1-\sigma(U_{w_c}·V_w)&\text{if }y=0 \end{cases}\),其中\(\sigma\)為Sigmoid函式,
聯合前面的得到的公式,最后有Skip-gram的目標函式:
\(\begin{aligned}L&=-\Sigma_{(w_c,w)\in D}\text{log}\sigma(U_{w_c}V_w)-\Sigma_{(w_c,w)\in \bar D}\text{log}(1-\sigma(U_{w_c}V_w))\\&=-\Sigma_{(w_c,w)\in D}\text{log}\sigma(U_{w_c}V_w)-\Sigma_{(w_c,w)\in \bar D}\text{log}\sigma(-U_{w_c}V_w)\end{aligned}\)
這個式子一方面在增大正樣本的概率,另一方面在減少負樣本的概率,實際上增大正樣本的概率就是在增大\(U_{w_c}V_w\),即中心詞語背景關系詞的內積,這種方式作為監督信號指導模型進行學習,模型收斂之后\(U,V\)就是我們需要的詞向量,通常我們取\(U\)作為最終的詞向量,
構建正樣本最大化正樣本最小化負樣本之間的相似度的方式是表示學習中構建損失函式一種常用的思路,這類損失被稱為對比損失,資料及其鄰居在輸入空間中的關系仍然能夠被保留,不同任務中資料的鄰居關系可能是不同的,這里鄰居關系是背景關系詞,
負采樣
通常情況下負樣本的數量遠比正樣本多,這使得對負樣本的計算會成為整體計算的瓶頸,容易想到的解決方案就是在對負樣本進行采樣來降低計算復雜度,采樣時一般不使用均勻采樣,而是采用以詞頻為權重的帶權采樣,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/285814.html
標籤:其他