前一篇博客利用Pytorch手動實作了LeNet-5,因為在訓練的時候,機器上的兩張卡只用到了一張,所以就想怎么同時利用起兩張顯卡來訓練我們的網路,當然LeNet這種層數比較低而且用到的資料集比較少的神經網路是沒有必要兩張卡來訓練的,這里只是研究怎么呼叫兩張卡,
現有方法
在網路上查找了多卡訓練的方法,總結起來就是三種:
- nn.DataParallel
- pytorch-encoding
- distributedDataparallel
第一種方法是pytorch自帶的多卡訓練的方法,但是從方法的名字也可以看出,它并不是完全的并行計算,只是資料在兩張卡上并行計算,模型的保存和Loss的計算都是集中在幾張卡中的一張上面,這也導致了用這種方法兩張卡的顯存占用會不一致,
第二種方法是別人開發的第三方包,它解決了Loss的計算不并行的問題,除此之外還包含了很多其他好用的方法,這里放出它的GitHub鏈接有興趣的同學可以去看看,
第三種方法是這幾種方法最復雜的一種,對于該方法來說,每個GPU都會對自己分配到的資料進行求導計算,然后將結果傳遞給下一個GPU,這與DataParallel將所有資料匯聚到一個GPU求導,計算Loss和更新引數不同,
這里我先選擇了第一個方法進行并行的計算
并行計算相關代碼
首先需要檢測機器上是否有多張顯卡
USE_MULTI_GPU = True
# 檢測機器是否有多張顯卡
if USE_MULTI_GPU and torch.cuda.device_count() > 1:
MULTI_GPU = True
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"] = "0, 1"
device_ids = [0, 1]
else:
MULTI_GPU = False
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
其中os.environ["CUDA_VISIBLE_DEVICES"] = "0, 1"是將機器中的GPU進行編號
接下來就是讀取模型了
net = LeNet()
if MULTI_GPU:
net = nn.DataParallel(net,device_ids=device_ids)
net.to(device)
這里與單卡的區別就是多了nn.DataParallel這一步操作
接下來是optimizer和scheduler的定義
optimizer=optim.Adam(net.parameters(), lr=1e-3)
scheduler = StepLR(optimizer, step_size=100, gamma=0.1)
if MULTI_GPU:
optimizer = nn.DataParallel(optimizer, device_ids=device_ids)
scheduler = nn.DataParallel(scheduler, device_ids=device_ids)
因為optimizer和scheduler的定義發送了變化,所以在后期呼叫的時候也有所不同
比如讀取learning rate的一段代碼:
optimizer.state_dict()['param_groups'][0]['lr']
現在就變成了
optimizer.module.state_dict()['param_groups'][0]['lr']
詳細的代碼可以在我的GitHub倉庫看到
開始訓練
訓練程序與單卡一樣,這里就展示兩張卡的占用情況
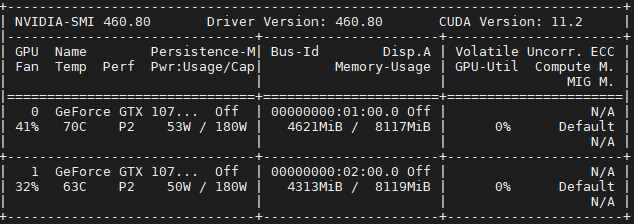
可以看到兩張卡都有占用,這說明我們的代碼起了作用,但是也可以看到,兩張卡的占用有明顯的區別,這就是前面說到的DataParallel只是在資料上并行了,在loss計算等操作上并沒有并行
最后
如果文章那里有錯誤和建議,都可以向往指出??
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/285816.html
標籤:其他