引言
其實最近挺糾結的,有一點點焦慮,因為自己一直都期望往自然語言處理的方向發展,夢想成為一名NLP演算法工程師,也正是我喜歡的事,而不是為了生存而作業,我覺得這也是我這輩子為數不多的剩下的可以自己去追求自己喜歡的東西的機會了,然而現實很殘酷,大部分的公司演算法工程師一般都是名牌大學,碩士起招,如同一個跨不過的門檻,讓人望而卻步,即使我覺得可能這個方向以后的路并不如其他的唾手可得的路輕松,但我的心中卻一直有一股信念讓我義無反顧,不管怎樣,夢還是要有的,萬一實作了呢~ 
扯得有點遠了hhh,回到文章,因為目前有在做涉及到文本分析(情感分析)的專案,也想為以后的相關專案做下知識儲備,最近開始入坑Tensorflow的一些深度學習的NLP相關實踐,同時學習了文本分類領域中基于深度學習的模型的一些應用知識(然而還是個菜鳥,半懂不懂的哈哈哈),這里對相關知識進行了總結,鞏固個人知識體系,同時分享給大家~
(提前宣告:菜雞觀點,非大佬觀點,歡迎糾正,也會不斷修正的)
持續更新........
基于深度學習的文本分類
文本分類領域,目前主要可分為:
- 情感分析
- 新聞分析
- 主題分類
- 問答系統
- 自然語言推理(NLI)
五大領域(當然也有一些其他細分領域,這里不進行討論),近幾年隨著深度學習在自然語言處理領域的應用,文本分類也進入了由深度學習模型所導引的第三個階段,逐漸超越了基于傳統機器學習的方法,
目前,學術界針對文本分類所提出的深度學習模型大致有150多種,根據結構可分為11大類:
- 前饋網路:將文本視為詞袋
- 基于RNN的模型:將文本視為一系列單詞,旨在捕獲文本單詞依存關系和文本結構
- 基于CNN的模型:經過訓練,可以識別文本分類的文本模式(例如關鍵短語),
- 膠囊網路(Capsule networks):解決了CNN在池化操作時所帶來的資訊丟失問題,
- 注意力機制:可有效識別文本中的相關單詞,并已成為開發DL模型的有用工具,
- 記憶體增強網路:將神經網路與某種外部存盤器結合在一起,該模型可以讀取和寫入,
- 圖神經網路:旨在捕獲自然語言的內部圖結構,例如句法和語意決議樹,
- 暹羅神經網路(Siamese):專門用于文本匹配,這是文本分類的特殊情況,
- 混合模型(Hybrid models):結合了注意力,RNN,CNN等以捕獲句子和檔案的區域和全域特征,
- Transformers:比RNN擁有更多并行處理,從而可以使用GPU高效的(預)訓練非常大的語言模型,
- 監督學習之外的建模技術:包括使用自動編碼器和對抗訓練的無監督學習,以及強化學習,
阿巴阿巴,如果看不太懂也沒關系,我也只認識比較經典的幾個hhh,但是可以了解下做儲備嘛,也許哪一天就接觸到了呢~下面這張圖是2013年至2020年發布的一些很經典的深度學習文本嵌入和分類模型,我們可以看到入門的word2vec在2013年就已經提出來了,還有當下比較熱門的Tree-LSTM、BERT也是前幾年提出來的,的確是更新很快啊emmmm...
如何選擇合適的神經網路模型
我們在針對文本分類任務選擇最佳的神經網路結構時,常常會很迷茫,像我這種菜鳥就是百度下哪個模型社區比較火就用大佬們的代碼來復現hhh(當然使用比較多也說明這個模型的性能和適用性不會太差),老師常說,其實要多試,采用精度最高的,嗚嗚嗚,然而現實是前期用來做精度驗證的資料集的標注就是一個很大的工程量了,然后每一個模型的實作也.....很!復!雜!啊!超級燒腦,畢竟神經網路的構建可不是傳統機器學習演算法那樣調一兩個引數就好了~
當然,多試肯定是要多試的,但是我們應該有選擇性的試,那么,初步的篩選、確定模型的類別就很重要了,這一點其實很靠經驗,我這個菜雞就不教壞大家了,我們來看下大佬的官方思路:
神經網路結構的選擇取決于目標任務和領域,領域內標簽的可用性,應用程式的延遲和容量限制等,這些導致選擇差異會很大,盡管毫無疑問,開發一個文本分類器是反復試錯的程序,但通過在公共基準(例如GLUE )上分析最近的結果,我們提出了以下方法來簡化該程序,該程序包括五個步驟:
- 選擇PLM(PLM,pretraining language model預訓練語言模型):使用PLM可以顯著改善所有流行的文本分類任務,并且自動編碼的PLM(例如BERT或RoBERTa)通常比自回歸PLM(例如OpenAI GPT)更好,Hugging face擁有為各種任務開發的豐富的PLM倉庫,
- 領域適應性:大多數PLM在通用領域的文本語料庫(例如Web)上訓練,如果目標領域與通用的領域有很大的不同,我們可以考慮使用領域內的資料,不斷地預訓練該PLM來調整PLM,對于具有大量未標記文本的領域資料,例如生物醫學,從頭開始進行語言模型的預先訓練也可能是一個不錯的選擇,
- 特定于任務的模型設計:給定輸入文本,PLM在背景關系表示中產生向量序列,然后,在頂部添加一個或多個特定任務的層,以生成目標任務的最終輸出,特定任務層的體系結構的選擇取決于任務的性質,例如,需要捕獲文本的語言結構,比如,前饋神經網路將文本視為詞袋,RNN可以捕獲單詞順序,CNN擅長識別諸如關鍵短語之類的模式,注意力機制可以有效地識別文本中的相關單詞,而暹羅神經網路則可以用于文本匹配任務,如果自然語言的圖形結構(例如,分析樹)對目標任務有用,那么GNN可能是一個不錯的選擇,
- 特定于任務的微調整:根據領域內標簽的可用性,可以使用固定的PLM單獨訓練特定任務的層,也可以與PLM一起訓練特定任務的層,如果需要構建多個相似的文本分類器(例如,針對不同領域的新聞分類器),則多任務微調是利用相似領域的標記資料的好選擇,
- 模型壓縮:PLM成本很高,它們通常需要通過例如知識蒸餾進行壓縮,以滿足實際應用中的延遲和容量限制,
是不是看不懂了,我攤牌了,第一遍讀完我整個人都是懵的,然后又仔細讀了兩遍,好像懂了一點點,又百度了一些專業名詞,又懂了一丟丟了,但還是懂一半啊哈哈哈哈,估計要真正走一遍流程之后采用完全解讀吧!等之后有時間實踐一遍我再重新更新解讀一下!
模型性能分析
當下常用的用于評估文本分類模型性能的指標,以下介紹4種:
-
準確率和錯誤率(Accuracy and Error Rate):評估分類模型質量的主要指標,是從整體角度出發的,假設TP,FP,TN,FN分別表示真積極,假積極,真消極和假消極,??為樣本總數,分類精度和錯誤率在等式中定義如下:
- Accuracy=(TP+TN)/N
- Error Rate=(FP+FN)/N
- Error Rate= 1-Accuracy
-
精度/召回率/ F1分數(Precision / Recall / F1 score):也是主要指標,針對于預測結果而言的,F1分數是精度和查全率的調和平均值,一般情況下用于單個分類類別樣本的驗證,對于多類別分類問題,也可以為每個類別標簽計算精度和召回率,并分析類別標簽上的各個性能,或者對這些值取平均值以獲取整體精度和召回率,F1較高說明模型比較理想,
- Precision = TP/(TP+FP)
- Recall = TP/(TP+TN)
- F1 score = 2Precision*Recall/(Precision+Recall)
-
Exact Match(EM):精確匹配度量標準是問答系統的一種流行度量標準,它可以測量與任何一個基本事實答案均精確匹配的預測百分比,EM是用于SQuAD的主要指標之一,
-
Mean Reciprocal Rank(MRR):MRR通常用于評估NLP任務中的排名演算法的性能,例如查詢檔案排名和QA,??是所有可能答案的集合,ranki是真相答案的排名位置,
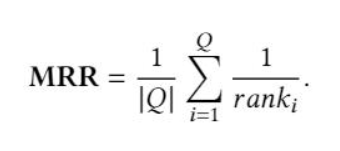
- 其他廣泛使用的指標包括平均精度Mean Average Precision(MAP),曲線下面積 Area Under Curve(AUC),錯誤發現率False DiscoveryRate,錯誤遺漏率False Omission Rate,僅舉幾例,
相關的定義百度很多hhh,這里有幾個點是我在學習程序中注意到的:
- 很多人會把Accuracy和Precision搞混,雖然中文轉換過來經常回混用,但切記這是兩個不同的東西,一個時相對整體的指標,一個是相對于預測結果的,
- 一般情況下,查準率(精度)和查全率(召回率)不能同時提高,這是很多人都不太會注意的點,所以解釋一下,一般當查準率比較低時,我們會提高閾值,即減少輸入的測驗樣本,從而保證模型預測出的正例都是真實的正例,很明顯這個時候雖然查準率提高了,但我輸入的總測驗樣本減少了,導致有些樣本你本來可以正確預測的,但你并沒有輸入,這個就是提高 Precision 而導致 Recall 降低的程序,你也可以反過來,得到的就是提高 Recall 而導致 Precision 降低的程序,所以,一般Precision高,Recall低;Recall低高,Precision低
- P-R曲線問題,這里貼一張在網上淘到的某位大佬的筆記hhh,所以就截圖放進來了,講的很透徹:

當然深度學習模型性能分析除了使用常用的評估文本分類模型性能的指標進行評估外,還可以與傳統的機器學習演算法或其他非深度學習模型指標進行一個對比,進一步來凸顯性能的提升,
看法:機遇與挑戰
深度學習其實是一個很早前提出來的東西,卻在近幾年火得一塌糊涂,不僅源于相關理論、硬體條件的發展,當然也源于其強大的應用成效,借助深度學習模型,CV和NLP的相關領域也取得了很大的進步,前沿、先進的新穎思路也層出不窮,如神經嵌入,注意力機制,自我注意力,Transformer,BERT和XLNet,這些思想導致了過去十年的快速發展,在這方面,國內其實做的還不夠完善,相比于國外大量成熟的落地專案和開源工具,然而,由于中文語言的特殊性,我們也看到中文自然語言處理,中文文本分析還具有很大的發展改善空間,很多公司也開拓了中文文本分析的一站式業務,并致力于 提升其適用性和精確度,
缺少大規模的中文領域資料集,這是我在中文自然語言探索時所發現的一個國內學術的重大缺失,這在一定程度上也抑制了一些相關領域的發展,同時也難以形成一個微細分通用領域的模型評測度量,這也導致了很多小型團隊的研究成果也難以推廣,在這個基礎上,針對更具挑戰性的文本分類任務構建新的資料集,例如具有多步推理的QA,針對多語言檔案的文本分類,用于極長的檔案的文本分類也將成為下一個中文文本分析領域飛速發展的突破口,(僅代表個人觀點hhh)
除此之外,因為目前大多數的深度學習模型是受監督型別,所以需要大量的領域標注文本,需要大量人力和時間成本的投入,雖然目前已經有了少量學習和零學習Few-Shot and Zero-Shot Learning概念的提出,但仍不夠成熟,如何更好地、較為平衡地降低模型的輸入成本是一個下一個待解決的問題,
增加對常識知識進行建模的探索,在這一點上,領域知識圖譜的構建是一個重要的分支,結合知識圖譜進行深度學習,進而提高模型性能的能力,在提高解釋性的同時,無疑也增加了機器對語意的理解,這和人的思維是很接近的,而不只是一個不可預測的黑箱模型,在此基礎上,實作以人們類似的思維方式基于對未知數的“默認”假設進行推理,而不只是依賴于數字模型,目前,知識圖譜構建的研究在國內已經有了大量的探索,趨向一個較為成熟的階段,而結合知識圖譜進行深度學習的研究卻鮮有團隊進行探索,或者說在萌芽階段(如果沒記錯大部分是基于圖資料庫的深度學習),至少還沒有較為著名的開源專案(可能是我沒發現哈哈哈),
黑箱模型的深層探索,雖然深度學習模型在具有挑戰性的基準上取得了可喜的性能,但是其中大多數模型都是無法解釋的,例如,為什么一個模型在一個資料集上勝過另一個模型,而在其他資料集上卻表現不佳?深度學習模型究竟學到了什么?能在給定的資料集上達到一定精度的最小神經網路架構是什么?盡管注意力和自我注意力機制為回答這些問題提供了一些見識,但仍缺乏對這些模型的基本行為和動力學的詳細研究,更好地了解這些模型的理論方面可以幫助開發針對各種文本分析場景的更好的模型,
博客首發于:https://www.wujunchao.top/?p=121
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/285818.html
標籤:其他
上一篇:基于1588PTP精密時鐘同步(時間同步服務)技術介紹
下一篇:好文推薦 | 自然語言處理簡介