0x01 價值迭代演算法基礎概念
0x01.1 獎勵
若要實作價值迭代,首先要定義價值,在迷宮任務中,到達目標將獲得獎勵,
- 特定時間t給出獎勵Rt稱為即時獎勵
- 未來獲得的獎勵總和Gt被稱為總獎勵
- Gt=R(t+1)+R(t+2)+R(t+3)
- 考慮時間因素,需要引入折扣率,這樣可以在最后擬合時獲得時間最短的策略,
- Gt=R(t+1)+yR(t+2)+y^2R(t+3)....
0x02 動作價值與狀態價值
在迷宮中,當我們的智能體走到終點時設定獎勵R(t+1)=1
0x02.1 動作價值
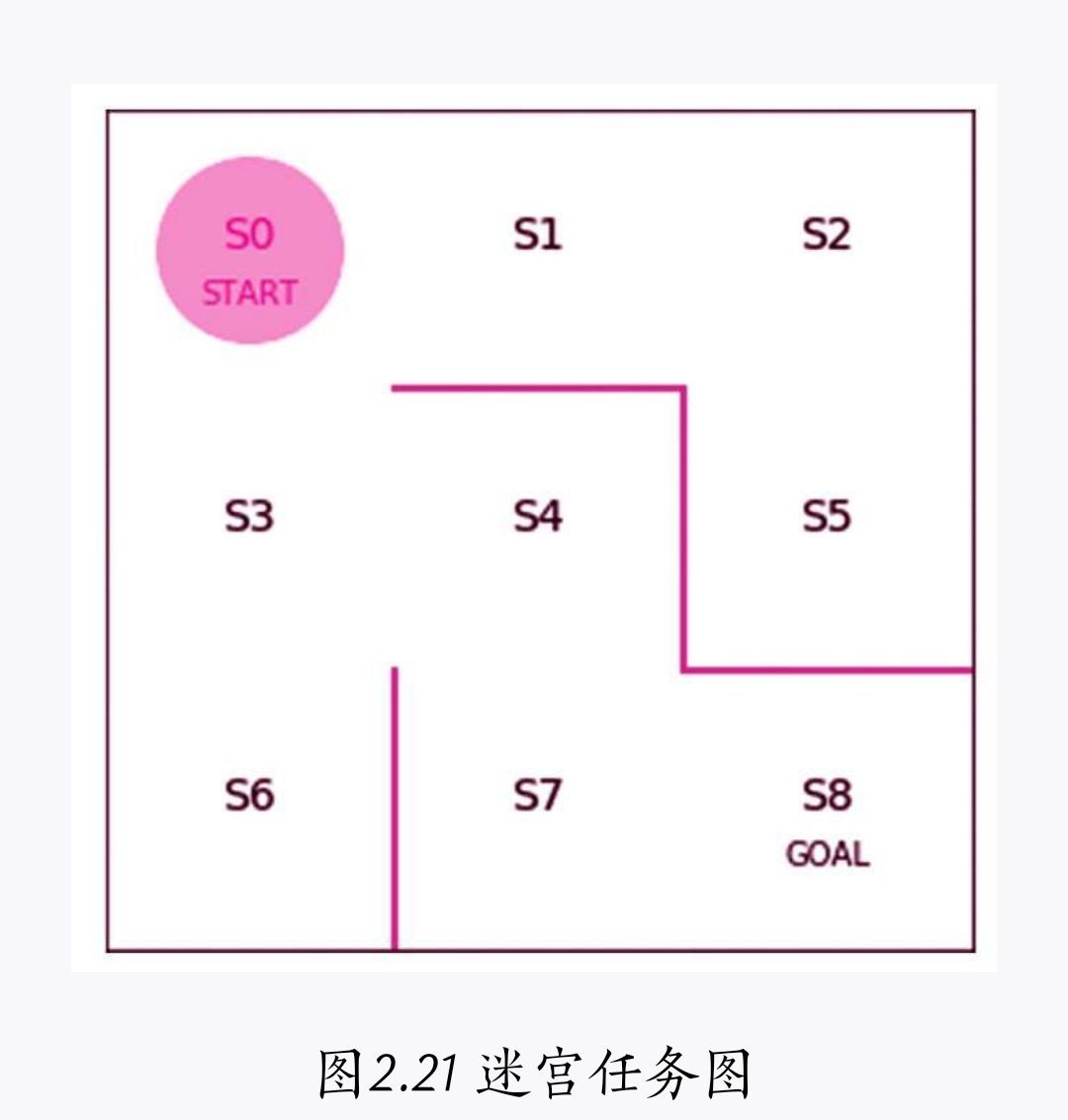
如果狀態s=S7且動作a=向右,則意味著S7→S8移動,這樣就可以在下一步中達到目標并獲得獎勵Rt+1=1,
動作價值可以用動作價值函式Qπ(s,a)表示,有4種型別的動作(向上、向右、向下、向左),在動作索引為a=1時向右移動,所以有:
Qπ(s=7,a=1)=Rt+1=1
若此時在S7的智能體下一步動作是向上,那么S7->S4 遠離了目標,這樣要想最快到達終點需要啊 S7->S4->S7->S8 可以看到S7會重復2次
此時獲得的獎勵就被打了折扣
Qπ(s=7,a=0)=γ2*1
依此類推,如果方向一直不對,那么獎勵就一直被打折扣,也就越來越少,
這里因為獎勵是根據智能體的動作變化而變化的,所以被稱為動作價值,
0x02.2 狀態價值
狀態價值是指在狀態s下遵從策略π行動時,預計在將來獲得的總獎勵Gt,將狀態s的狀態價值函式寫為Vπ(s)
若智能體在S7狀態,向右移動即可獲得獎勵 存在 Vπ(s=7)=1
若智能體在S4,向下移動到S7,再向右移動到S8, 存在 Vπ(s=4)=y1
也可表示為 Vπ(s=4)=R(t+1)+yVπ(s=7)=0+y*1=y
0x03 貝爾曼方程和馬爾可夫決策程序
狀態價值函式最后可通過這個方程表達 -》 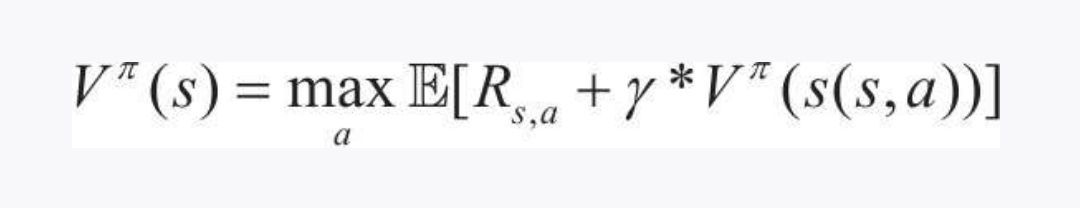
這個方程被稱為貝爾曼方程
-
VΠ(s) 表示在狀態s時的狀態價值V
-
該狀態價值是通過右側具有最大值動作的期望的價值,如果我們想要擬合一個最大的價值狀態,那么在迷宮中,最短路徑就能實作最大價值期望,
-
R(s'a) 是在狀態s下采用動作a移動后的新狀態的即時獎勵R(t+1)
-
VΠ()中的s(s,a)表示在狀態s下采用動作a移動后的新狀態s+1
-
方程表達的是 新狀態的狀態價值V時間折扣率加上現在的即使獎勵的和的最大值就是當前的狀態價值,
舉個例子,比如在S8的時候設定了即時獎勵 1 ,所以根據公式,在S7的時候 狀態價值就是 1
而在S4時 狀態價值是 0+1y
在S3時, 狀態價值是 0+1yy
方向用概率表示, 從S3->S4->S7->S8 假設方向為a 上右下左隨機的概率 a11y^2+a21y+a31 可以得到最大價值期望,
**如果我們可以通過一個函式使得 a11y^2+a21y+a31 收斂于一個最大值, 就能不斷改變a的概率, 使的a1中向右概率大大增加,a2中向下概率大大增加,a3中向右概率大大增加,**
作為貝爾曼方程成立的前提條件,學習物件必須是滿足馬爾可夫決策程序的,即下一步的狀態由當前狀態和采用的動作決定,
0x04 使用Sarsa演算法與epsilon貪婪法實作策略
epsilon貪婪法 簡單理解就是 以 一定概率p隨機行動, 以剩下的1-p的概率采用動作價值Q最大的行動, 隨著實驗次數的增加,p的概率會減小,原因是不管怎么走都會走一條固定的最短路徑到達終點,
由于初始狀態不清楚每個狀態的動作價值 所以需要隨機定義
[a,b]=theta_0.shape # 獲取行,列數
Q=np.random.rand(a,b)*theta_0 # 將theta_0乘到各個元素上,使Q墻壁方向為nan
然后定義隨機方向策略
def simple_convert_into_pi_from_theta(theta):
''' 簡單計算比率'''
[m,n]=theta.shape # 讀取theta矩陣
pi=np.zeros((m,n))
for i in range(0,m):
pi[i,:]=theta[i,:]/np.nansum(theta[i,:]) # 計算比率
pi=np.nan_to_num(pi) # 將nan轉換為0
return pi
定義epsilon貪婪演算法,使得一部分隨機走,一部分按照求最大價值函式Q的方向去走
# 實作epsilon貪婪演算法
def get_action(s,Q,epsilon,pi_0):
direction=["up","right","down","left"]
# 確定行動
if np.random.rand()<epsilon:
next_direction=np.random.choice()
else:
# 采用讓Q獲得最大值的動作
next_direction=direction[np.nanargmax(Q[s,:])]
# 為每個動作設定索引
if next_direction=="up":
action=0
if next_direction=="right":
action=1
if next_direction=="down":
adcion=2
if next_direction=="left":
action=3
return action
# 設定狀態索引
def get_s_next(s,a,Q,epsilon,pi_0):
direction = ["up", "right", "down", "left"]
next_direction=direction[a] # 動作a的方向
# 根據動作確定下一步狀態
if next_direction=='up':
s_next=s-3 # 向上移動 狀態數-3
if next_direction=="right":
s_next = s + 1
if next_direction=="down":
s_next = s + 3
if next_direction=="left":
s_next = s - 1
return s_next
如果獲得動作價值函式Q(s,a)的正確值,則貝爾曼方程
Q(st,at)=Rt+1+γQ(st+1,at+1)
所表示的關系成立,
然而,由于在學習程序中尚未正確求得動作價值函式,因此該等式是不成立的,
此時,上述等式兩邊之間的差Rt+1+γQ(st+1,at+1)-Q(st,at)是TD誤差(時間差,Temporal Difference error),如果此時TD誤差為0,則表示已正確學習到了動作價值函式,Q的更新公式是:
Q(st,at)=Q(st,at)+η*(Rt+1+γQ(st+1,at+1)-Q(st,at)
其中η是學習率,η后面是TD誤差,遵循此更新公式的演算法稱為Sarsa演算法
基于Sarsa演算法去更新策略
def Sarsa(s,a,r,s_next,a_next,Q,eta,gamma):
if s_next==8:
Q[s,a]=Q[s,a]+eta*(r-Q[s,a])
else:
Q[s,a]=Q[s,a]+eta*(r+gamma*Q[s_next,a_next]-Q[s,a])
return Q
通過該演算法去求解
def goal_maze_ret_s_a_Q(Q,epsilon,eta,gamma,pi):
s=0
a=a_next=get_action(s,Q,epsilon,pi)
s_a_history=[[0,np.nan]] # 記錄移動體序列
while (1):
a=a_next # 動作更新
s_a_history[-1][-1]=a
# 將動作放在當前狀態
s_next=get_s_next(s,a,Q,epsilon,pi)
# 有效的下一個狀態
s_a_history.append([s_next,np.nan])
# 代入下一個狀態 動作未知則為nan
if s_next==8:
r=1 # 給獎勵
a_next=np.nan
else:
r=0
a_next=get_action(s_next,Q,epsilon,pi)
# 求得下一個動作
# 更新價值函式
Q=Sarsa(s,a,r,s_next,a_next,Q,eta,gamma)
# 終止判斷
if s_next==8:
break
else:
s=s_next
return [s_a_history,Q]
設定初始值
# 求解
eta=0.1 # 學習率
gamma=0.9 # 時間折扣率
epsilon=0.5 # epsilon貪婪演算法
v=np.nanargmax(Q,axis=1) # 根據 狀態求最大價值
is_continue=True
episode=1
while is_continue:
print("當前回合:",str(episode))
# epsilon貪婪法的值變小
epsilon=epsilon/2
# 通過Sarsa求解迷宮問題
[s_a_history,Q]=goal_maze_ret_s_a_Q(Q,epsilon,eta,gamma,pi_0)
# 狀態價值變化
new_v=np.nanmax(Q,axis=1) # 各狀態求最大價值
print(np.sum(np.abs(new_v-v))) # 輸出狀態價值變化
v=new_v
print("求解迷宮問題所需步驟:",str(len(s_a_history)-1))
episode=episode+1
if episode>50:
break
完整代碼
# 引入庫函式
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import animation
# 畫圖
def plot():
fig=plt.figure(figsize=(5,5))
ax=plt.gca()
# 畫墻壁
plt.plot([1,1],[0,1],color='red',linewidth=3)
plt.plot([1,2],[2,2],color='red',linewidth=2)
plt.plot([2,2],[2,1],color='red',linewidth=2)
plt.plot([2,3],[1,1],color='red',linewidth=2)
# 畫狀態
plt.text(0.5,2.5,'S0',size=14,ha='center')
plt.text(1.5,2.5,'S1',size=14,ha='center')
plt.text(2.5,2.5,'S2',size=14,ha='center')
plt.text(0.5,1.5,'S3',size=14,ha='center')
plt.text(1.5,1.5,'S4',size=14,ha='center')
plt.text(2.5,1.5,'S5',size=14,ha='center')
plt.text(0.5,0.5,'S6',size=14,ha='center')
plt.text(1.5,0.5,'S7',size=14,ha='center')
plt.text(2.5,0.5,'S8',size=14,ha='center')
plt.text(0.5,2.5,'S0',size=14,ha='center')
plt.text(0.5,2.3,'START',ha='center')
plt.text(2.5,0.3,'END',ha='center')
# 設定畫圖范圍
ax.set_xlim(0,3)
ax.set_ylim(0,3)
plt.tick_params(axis='both',which='both',bottom='off',top='off',labelbottom='off',right='off',left='off',labelleft='off')
# 當前位置S0用綠色圓圈
line,=ax.plot([0.5],[2.5],marker="o",color='g',markersize=60)
# 顯示圖
plt.show()
def simple_convert_into_pi_from_theta(theta):
''' 簡單計算比率'''
[m,n]=theta.shape # 讀取theta矩陣
pi=np.zeros((m,n))
for i in range(0,m):
pi[i,:]=theta[i,:]/np.nansum(theta[i,:]) # 計算比率
pi=np.nan_to_num(pi) # 將nan轉換為0
return pi
# 實作epsilon貪婪演算法
def get_action(s,Q,epsilon,pi_0):
direction=["up","right","down","left"]
# 確定行動
if np.random.rand()<epsilon:
next_direction=np.random.choice(direction,p=pi_0[s,:])
else:
# 采用讓Q獲得最大值的動作
next_direction=direction[np.nanargmax(Q[s,:])]
# 為每個動作設定索引
if next_direction=="up":
action=0
if next_direction=="right":
action=1
if next_direction=="down":
action=2
if next_direction=="left":
action=3
return action
# 設定狀態索引
def get_s_next(s,a,Q,epsilon,pi_0):
direction = ["up", "right", "down", "left"]
next_direction=direction[a] # 動作a的方向
# 根據動作確定下一步狀態
if next_direction=='up':
s_next=s-3 # 向上移動 狀態數-3
if next_direction=="right":
s_next = s + 1
if next_direction=="down":
s_next = s + 3
if next_direction=="left":
s_next = s - 1
return s_next
# Sarsa演算法更新策略
def Sarsa(s,a,r,s_next,a_next,Q,eta,gamma):
if s_next==8:
Q[s,a]=Q[s,a]+eta*(r-Q[s,a])
else:
Q[s,a]=Q[s,a]+eta*(r+gamma*Q[s_next,a_next]-Q[s,a])
return Q
# 使用Sarsa演算法求解迷宮問題
def goal_maze_ret_s_a_Q(Q,epsilon,eta,gamma,pi):
s=0
a=a_next=get_action(s,Q,epsilon,pi)
s_a_history=[[0,np.nan]] # 記錄移動體序列
while (1):
a=a_next # 動作更新
s_a_history[-1][-1]=a
# 將動作放在當前狀態
s_next=get_s_next(s,a,Q,epsilon,pi)
# 有效的下一個狀態
s_a_history.append([s_next,np.nan])
# 代入下一個狀態 動作未知則為nan
if s_next==8:
r=1 # 給獎勵
a_next=np.nan
else:
r=0
a_next=get_action(s_next,Q,epsilon,pi)
# 求得下一個動作
# 更新價值函式
Q=Sarsa(s,a,r,s_next,a_next,Q,eta,gamma)
# 終止判斷
if s_next==8:
break
else:
s=s_next
return [s_a_history,Q]
if __name__=="__main__":
theta_0=np.array([[np.nan,1,1,np.nan], #S0
[np.nan,1,np.nan,1], #S1
[np.nan,np.nan,1,1], #S2
[1,1,1,np.nan], #S3
[np.nan,np.nan,1,1], #S4
[1,np.nan,np.nan,np.nan], #S5
[1,np.nan,np.nan,np.nan], #S6
[1,1,np.nan,np.nan], #S7
]) # S8位目標 不需要策略
print(theta_0)
#plot()
# 設定初始的動作價值函式
[a,b]=theta_0.shape # 獲取行,列數
Q=np.random.rand(a,b)*theta_0 # 將theta_0乘到各個元素上,使Q墻壁方向為nan
pi_0=simple_convert_into_pi_from_theta(theta_0) # 設定移動方向初始策略
# 求解
eta=0.1 # 學習率
gamma=0.9 # 時間折扣率
epsilon=0.5 # epsilon貪婪演算法
v=np.nanargmax(Q,axis=1) # 根據 狀態求最大價值
is_continue=True
episode=1
while is_continue:
print("當前回合:",str(episode))
# epsilon貪婪法的值變小
epsilon=epsilon/2
# 通過Sarsa求解迷宮問題
[s_a_history,Q]=goal_maze_ret_s_a_Q(Q,epsilon,eta,gamma,pi_0)
# 狀態價值變化
new_v=np.nanmax(Q,axis=1) # 各狀態求最大價值
print(np.sum(np.abs(new_v-v))) # 輸出狀態價值變化
v=new_v
print("求解迷宮問題所需步驟:",str(len(s_a_history)-1))
episode=episode+1
if episode>50:
break
運行效果

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/285828.html
標籤:其他
下一篇:通訊總線總結