這里是目錄喲~
- 一、回呼函式的實用案例
- 1.0 回呼函式簡要介紹
- 1.1 簡易計算器改良
- 1.2 qsort快排函式應用回呼函式
- 1.2.1 冒泡排序核心思想
- 1.2.2 qsort函式簡單介紹
- 1.2.2.1 qsort函式對浮點型陣列排序實體
- 1.2.2.2 qsort函式對結構體陣列排序實體
- 1.2.3 利用冒泡排序演算法實作qsort函式的模擬
一、回呼函式的實用案例
1.0 回呼函式簡要介紹
回呼函式是一個通過函式指標呼叫的函式,
意思是定義一個指標,這個指標指向一個函式,然后用這個指標來呼叫這個指標所指向的函式,
看上去十分容易,那只是你的腦子在欺騙你,你的手完全不會,[doge]
1.1 簡易計算器改良
大多數初學者剛接觸函式的時候一定寫過簡易的計算器,來實作加減乘除四則運算 , 雖然寫得很繁瑣 ,但依舊無法阻止我們產生學習編程的熱情,
#include<stdio.h>
void menu()
{
printf("*********************\n");
printf("****1.Add 2.Sub****\n");
printf("****3.Mul 4.Div****\n");
printf("****** 0.Exit *******\n");
printf("*********************\n");
}
int Add(int x, int y)
{
return x + y;
}
int Sub(int x, int y)
{
return x - y;
}
int Mul(int x, int y)
{
return x * y;
}
int Div(int x, int y)
{
return x / y;
}
int main()
{
int input = 0;
int x = 0;
int y = 0;
int ret = 0;
do
{
menu();
scanf("%d", &input);
switch (input)
{
case 1:
printf("input two numbers\n");
scanf("%d %d", &x, &y);
ret = Add(x, y);
printf("%d\n", ret);
break;
case 2:
printf("input two numbers\n");
scanf("%d %d", &x, &y);
ret = Sub(x, y);
printf("%d\n", ret);
break;
case 3:
printf("input two numbers\n");
scanf("%d %d", &x, &y);
ret = Mul(x, y);
printf("%d\n", ret);
break;
case 4:
printf("input two numbers\n");
scanf("%d %d", &x, &y);
ret = Div(x, y);
printf("%d\n", ret);
break;
case 0:
printf("Exit\n");
break;
default:
printf("再亂輸我就要生氣咯!\n");
break;
}
} while (input);
return 0;
}
但這樣冗余的代碼就像老太太的裹腳布又臭又長 ,
我在寫的時候發現了有多個地方一直在重復一個操作,就是在case子句中一直重復著讓讓用戶輸入兩個運算元,并且列印出來,
(雖然這個操作可以復制粘貼 )但是節約是一種美德,節約記憶體空間也是[doge]
- 懶,才能推動進步
我要嘗試簡化這個部分的代碼,我發現case子句中只有函式的呼叫不同,所以我將不同函式作為一個引數傳給我的一個自定義函式,于是case子句中的內容就變為如下形式
ret = Calc(Add);
printf("%d\n", ret);
那么問題來了,函式名代表什么呢?
眾所周知,陣列名代表陣列的首元素地址,那函式名也應該如此,代表函式的地址
那么,我們的自定義函式中的引數應該設計成一個函式指標
int Cal((*fun)(int, int));
這么長一串的東西應該怎么來分析呢?
首先看引數部分,引數是一個函式指標,即一個指標,所以其變數名應該先于‘ * ’結合,并且被括號括起來,因為‘ * ’的優先級特別低,
然后其右邊與()結合,代表這是個指向函式的指標,這個()是引數串列,串列內有兩個整形引數,
最后再看回傳值,實行計算后回傳一個整形資料,
簡易改良版如下:
#include<stdio.h>
int Add(int x, int y)
{
return x + y;
}
int Sub(int x, int y)
{
return x - y;
}
int Mul(int x, int y)
{
return x * y;
}
int Div(int x, int y)
{
return x / y;
}
void menu()
{
printf("*********************\n");
printf("****1.Add 2.Sub****\n");
printf("****3.Mul 4.Div****\n");
printf("****** 0.Exit *******\n");
printf("*********************\n");
}
int Cal(int(*fun)(int, int))
{
int x = 0;
int y = 0;
printf("input two numbers\n");
scanf("%d %d", &x, &y);
return fun(x, y);
}
int main()
{
int input = 0;
int x = 0;
int y = 0;
int ret = 0;
do
{
menu();
scanf("%d", &input);
switch (input)
{
case 1:
ret = Cal(Add);
printf("%d\n", ret);
break;
case 2:
ret = Cal(Sub);
printf("%d\n", ret);
break;
case 3:
ret = Cal(Mul);
printf("%d\n", ret);
break;
case 4:
ret = Cal(Div);
printf("%d\n", ret);
break;
case 0:
printf("Exit\n");
break;
default:
printf("再亂輸我就要生氣咯!\n");
break;
}
} while (input);
return 0;
}
1.2 qsort快排函式應用回呼函式
眾所周知,排序是很重要的,初學者一般就接觸過選擇排序和冒泡排序,其中冒泡排序估計是強行硬是把代碼背下來了,
下面還是希望能用通俗易懂的圖文帶大家深入理解一下冒泡排序的核心思想,
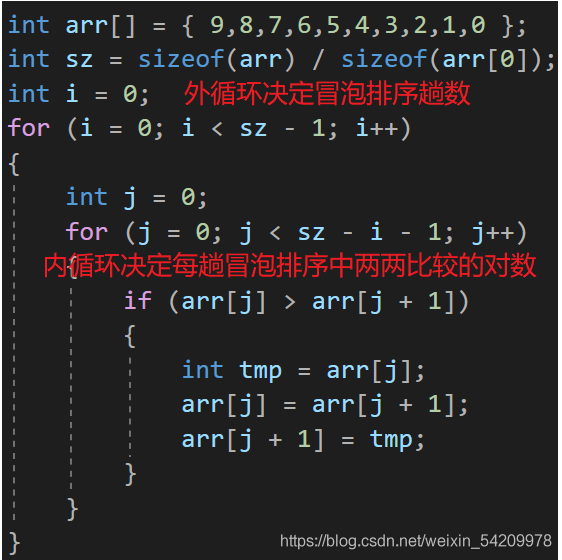
1.2.1 冒泡排序核心思想
相鄰兩數比較,大數往后挪,就像是重的石頭沉入水底,輕的氣泡往上浮,
把每一次最重的石頭沉入它應該到的位置時的這個程序稱作一趟冒泡排序,那么多少趟下來才能將所有元素放在各自應該到的位置呢?很顯然,如果10個元素,只需要把九個元素放在其應該所在的位置即可,那么剩下的一個元素當然只有唯一的位置放了,而那個位置恰好就是該剩下的元素的最終位置,10個元素完成升序也就需要9趟冒泡排序,
再來細說每一趟冒泡排序是如何實作的,從第一個元素開始,相鄰的兩元素兩兩比較,如果前面元素大于后面元素,則兩元素交換位置,如果前面元素小于后面元素,則不交換位置,一直比較到最后一個元素,這就是第一趟冒泡排序,
而緊接著下一趟冒泡排序略微有些不同,一開始還是依次兩兩比較,但是不需要比較陣列中的最后一個元素,因為在第一趟的冒泡排序中,我們已經將一個最大的數放在最后了,所以它已經到自己最終的位置,我們就不再管它了,
1.2.2 qsort函式簡單介紹
qsort函式是C的一個庫函式,頭檔案為#include<stdlib.h>
這里推薦一個程式員必備的庫函式查詢網址
鏈接: http://www.cplusplus.com/
可以查詢C\C++的庫函式的用法,非常方便,值得放進收藏夾,
如下是qsort函式的函式宣告:


qsort函式的第四個引數是一個函式指標,指向的是一個程式員根據需要排序的陣列型別來寫的函式,
正因為如此,qsort才能實作對不同的資料型別進行靈活排序
1.2.2.1 qsort函式對浮點型陣列排序實體
#include<stdio.h>
#include<stdlib.h>
int SortByDouble(const void* e1, const void* e2)
{
return *(double*)e1 - *(double*)e2;
}
int main()
{
double arr[] = { 9.0,8.0,7.0,6.0,5.0,4.0,3.0,2.0,1.0 };
int sz = sizeof(arr) / sizeof(arr[0]);
qsort(arr, sz, sizeof(arr[0]), SortByDouble);
return 0;
}
注意:void*可以接受任何指標型別,但是不可以對其進行解參考操作,但是可以對其接受到的指標型別進行強制型別轉換,即如上自定義函式SortByDouble中的return部分,
1.2.2.2 qsort函式對結構體陣列排序實體
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
struct stu
{
char name[8];
int age;
};
int SortByAge(const void* e1, const void* e2)
{
return ((struct stu*)e1)->age - ((struct stu*)e2)->age;
}
int SortByName(const void* e1, const void* e2)
{
return strcmp(((struct stu*)e1)->name, ((struct stu*)e2)->name);
}
int main()
{
struct stu s[] = { {"zhangsan",20},{"lisi",19},{"wangwu",18} };
int sz = sizeof(s) / sizeof(s[0]);
qsort(s, sz, sizeof(s[0]), SortByAge);
qsort(s, sz, sizeof(s[0]), SortByName);
return 0;
}
結構體就更加復雜了,而且需要小心算結構體陣列元素個數和每個元素大小的時候都是不管結構體的成員變數,
所以千萬不要以為自己是在對結構體中的年齡進行排序,而計算陣列大小的時候用了:
int sz = sizeof(s)/sizeof(s[0].age);//錯誤實體
不應該去讓s[0]訪問到age
還有一點是結構體定義一定要放在最前面,放錯位置了,都會導致自定義函式顯示未定義的錯誤
1.2.3 利用冒泡排序演算法實作qsort函式的模擬

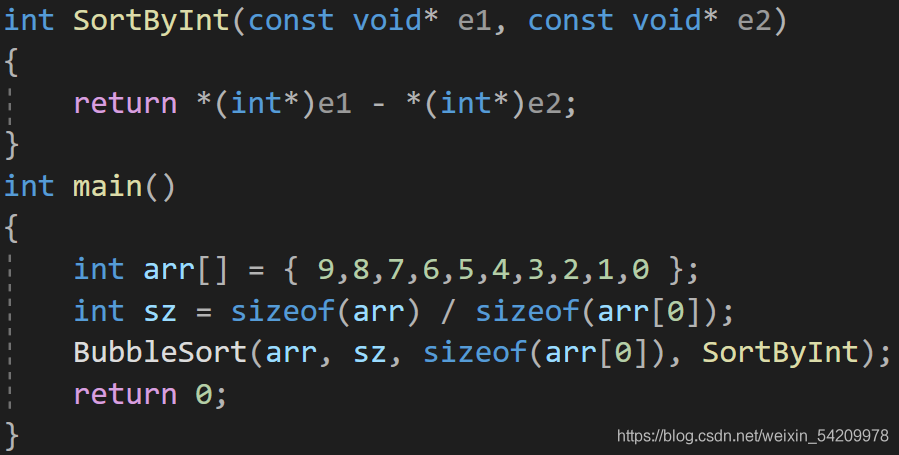
其實qsort函式的演算法并不是冒泡排序,但我為什么說是模擬實作qsort呢?
請看下圖:
發現了嗎?我寫的這個函式的引數簡直就是和qsort函式的引數異曲同工之妙啊~
所以接下來我需要實作的就是對BubbleSort函式進行定義了,
如下是大體的框架:
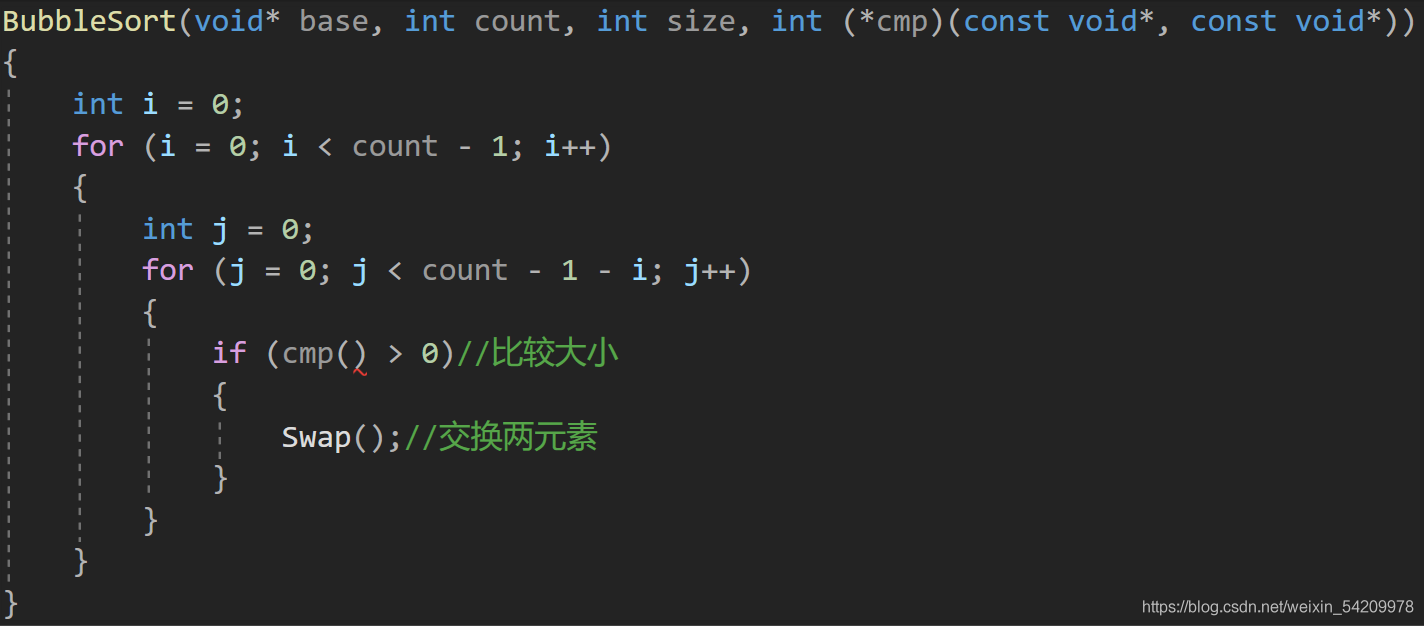
比較難的是如何設定cmp函式和swap函式內的引數,
cmp函式接收的是兩個相鄰元素的地址,但是元素的型別可以有很多種,且所占位元組大小也不同,這就為我們設下了一個難題,
但是我們知道char型別所占位元組是最小的,我們是不是可以用它來表示所有變數呢?
所以先將首元素地址強制型別轉換成char*,再對其加某個值,可以讓其向后移動而指向不同的元素,
那么加上什么值才合適呢?
這是位于內部回圈,j一直在發生變換,我們又知道每個元素所占位元組大小,所以根據上述推論,我們有以下結果,
if(cmp((char*)base + j * size, (char*)base + (j + 1) * size)>0
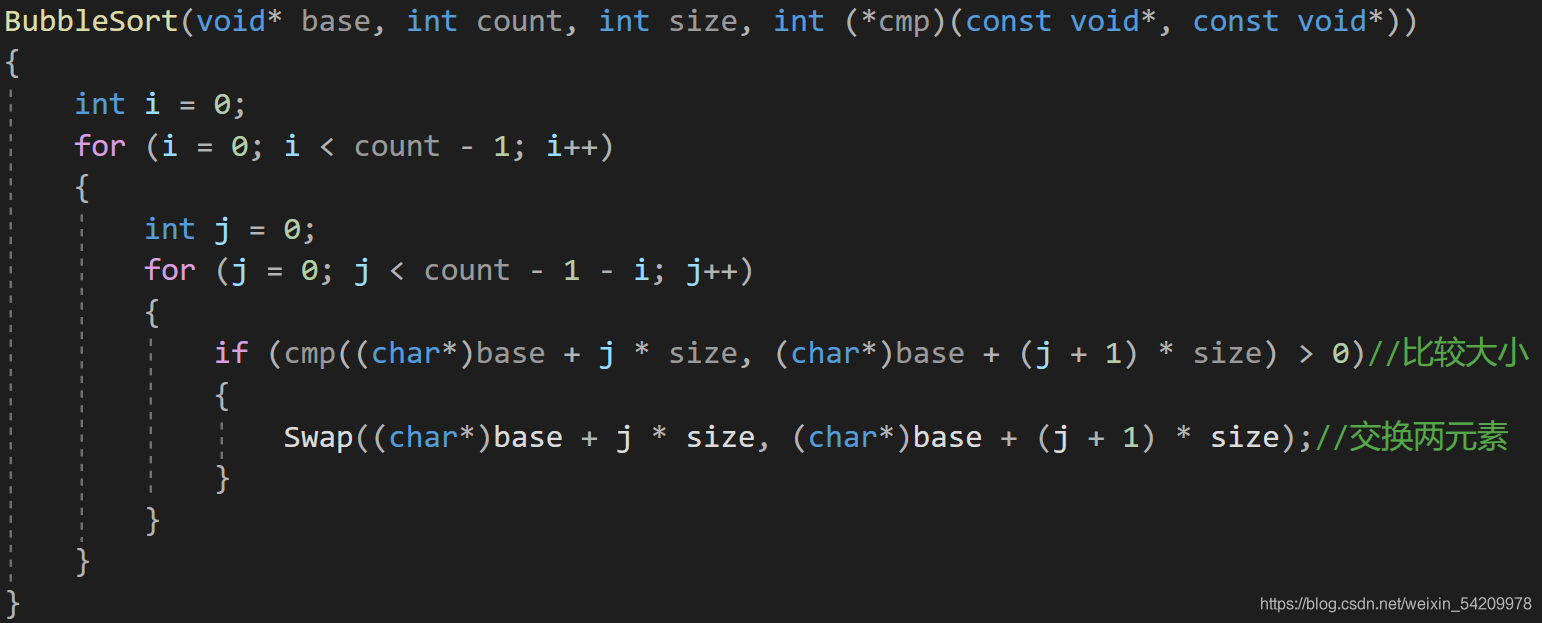
接下來是swap函式內部的引數
swap函式是滿足了前者大于后者,就對這兩個數進行交換,
swap函式的引數應該是兩個元素的地址,并且是和cmp()函式中的引數一樣,所以有如下結果:
swap((char*)base + j * size, (char*)base + (j + 1) * size)
大體搭構好了,接下來就是實作Swap函式了
等一下,這樣的Swap函式真的對嗎?如果傳過去的是兩個元素的地址,我們真的能成功交換他們嗎?
答案是否定的,因為我們平常寫的交換兩元素的函式是這樣的
Swap(char* buf1, char* buf2)
{
while((*buf1)&&(*buf2))
{
int tmp = *buf1;
*buf1 = *buf2;
*buf2 = tmp;
buf1++;
buf2++;
}
}
發現問題了嗎?我們每次++的時候都已經確定這個指標會跳過幾個位元組,而現在我們寫的Swap函式可并不知道自己引數的型別,所以不能保證每次++后跳過的位元組都正確,
講了半天,我們最需要的是知道我們交換的元素所占位元組大小是多少
所以需要給Swap函式增加一個引數size
修改后:
BubbleSort(void* base, int count, int size, int (*cmp)(const void*, const void*))
{
int i = 0;
for (i = 0; i < count - 1; i++)
{
int j = 0;
for (j = 0; j < count - 1 - i; j++)
{
if (cmp((char*)base + j * size, (char*)base + (j + 1) * size) > 0)//比較大小
{
Swap((char*)base + j * size, (char*)base + (j + 1) * size, size);//交換兩元素
}
}
}
}
Swap函式的實作
void Swap(void* buf1, void* buf2, int size)
{
int i = 0;
for (i = 0; i < size; i++)//每次回圈交換兩個元素的一個位元組
{
char tmp = *((char*)buf1 + i);
*((char*)buf1 + i) = *((char*)buf2 + i);
*((char*)buf2 + i) = tmp;
}
}
每次回圈交換兩個元素的一個位元組,
直至把一個元素所占的位元組全部交換完成,
這樣我們就把整個qsort函式的模擬實作了!
最后附上原始碼:
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
int SortByInt(const void* e1, const void* e2)
{
return *(int*)e1 - *(int*)e2;
}
void Swap(void* buf1, void* buf2, int size)
{
int i = 0;
for (i = 0; i < size; i++)
{
char tmp = *((char*)buf1 + i);
*((char*)buf1 + i) = *((char*)buf2 + i);
*((char*)buf2 + i) = tmp;
}
}
BubbleSort(void* base, int count, int size, int (*cmp)(const void*, const void*))
{
int i = 0;
for (i = 0; i < count - 1; i++)
{
int j = 0;
for (j = 0; j < count - 1 - i; j++)
{
if (cmp((char*)base + j * size, (char*)base + (j + 1) * size) > 0)//比較大小
{
Swap((char*)base + j * size, (char*)base + (j + 1) * size, size);//交換兩元素
}
}
}
}
int main()
{
int arr[] = { 9,8,7,6,5,4,3,2,1,0 };
int sz = sizeof(arr) / sizeof(arr[0]);
BubbleSort(arr, sz, sizeof(arr[0]), SortByInt);
return 0;
}
妹有開源精神是不行的![doge]
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/286234.html
標籤:其他