一、MapReduce 核心編程思想
主要為map階段和reduce階段,如圖
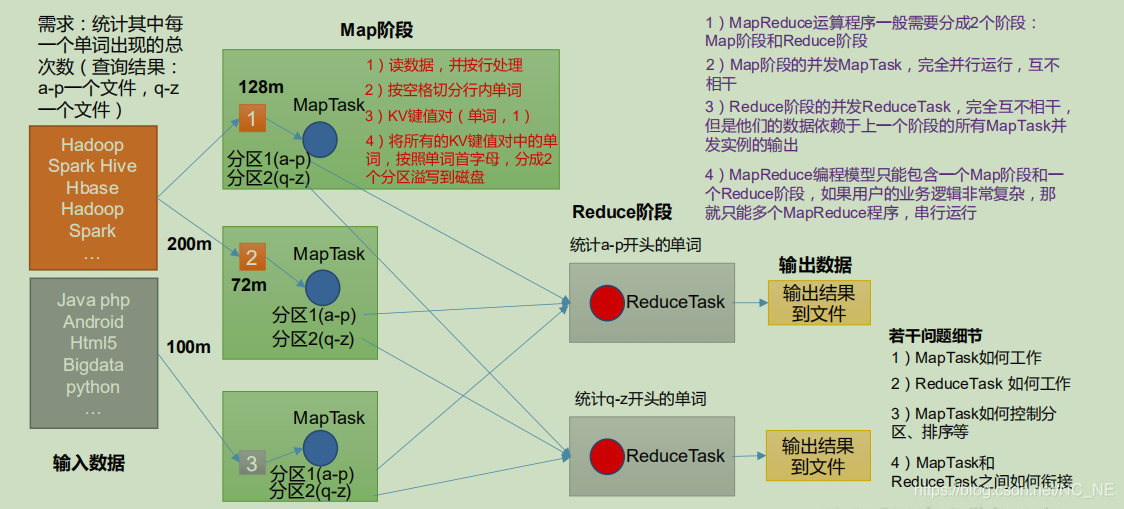
二、MapReduce 行程
(1)MrAppMaster:負責整個程式的程序調度及狀態協調,
(2)MapTask:負責 Map 階段的整個資料處理流程,
(3)ReduceTask:負責 Reduce 階段的整個資料處理流程,
三、MapReduce 編程規范
用戶撰寫的程式分成三個部分:Mapper、Reducer 和 Driver,
1.Mapper階段
(1)用戶自定義的類要繼承Mapper類
(2)Mapper的輸入資料是KV對的形式(KV的型別可自定義)
(3)Mapper中的業務邏輯寫在map()方法中
(4)Mapper的輸出資料是KV對的形式(KV的型別可自定義)
(5)map()方法(MapTask行程)對每一個<K,V>呼叫一次
2.Reducer階段
(1)用戶自定義的類要繼承Reducer類
(2)Reducer的輸入資料型別對應Mapper的輸出資料型別,也是KV
(3)Reducer的業務邏輯寫在reduce()方法中
(4)ReduceTask行程對每一組相同k的<k,v>組呼叫一次reduce()方法
3.Driver階段
相當于YARN集群的客戶端,用于提交我們整個程式到YARN集群,提交的是
封裝了MapReduce程式相關運行引數的job物件
四、WordCount測驗
1、本地測驗
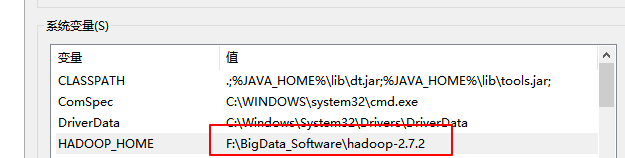
需要首先配置好 HADOOP_HOME 變數以及 Windows 運行依賴
配置 HADOOP_HOME 環境變數
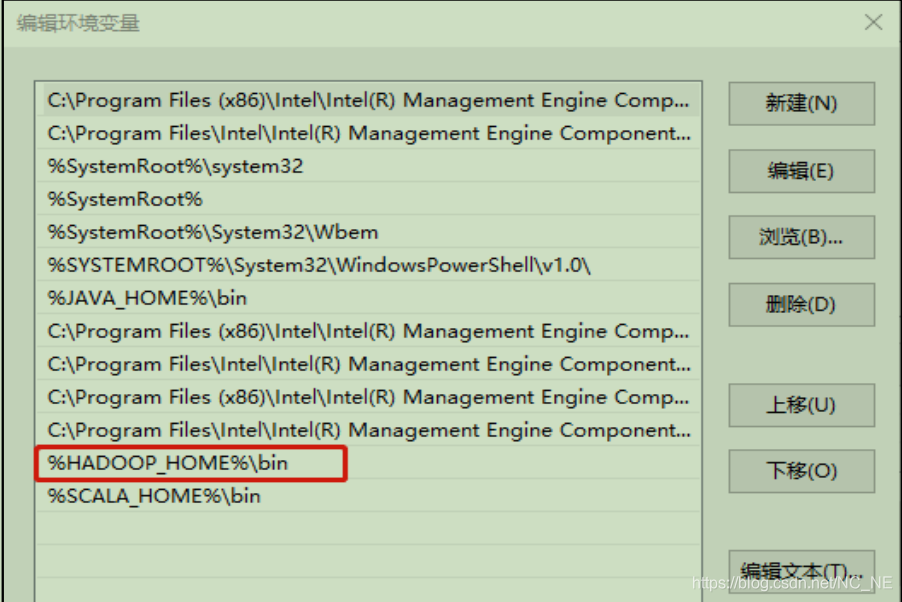
配置 Path 環境變數
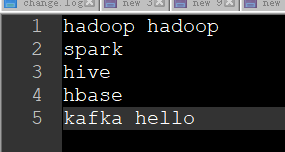
資料準備(inpuword.txt)
代碼環境準備
(1)在 pom.xml 檔案中添加如下依賴
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.2</version>
</dependency>
</dependencies>(2)在專案的 src/main/resources 目錄下,新建一個檔案,命名為“log4j.properties”,在檔案中填入
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n(3)撰寫 Mapper 類
package com.ouyangl.mapreduce.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* @author oyl
* @create 2021-06-03 22:06
* @Description 引數:
* KEYIN, map階段輸入的key的型別:LongWritable
* VALUEIN map階段輸入value的型別:Text
* KEYOUT map階段輸出的key型別:Text
* VALUEOUT map階段輸出的value型別,IntWritable
*/
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private Text outK = new Text();
private IntWritable outv = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//獲取第一行資料
String line = value.toString();
//截取
String[] words = line.split(" ");
//輸出
for (String word : words) {
outK.set(word);
context.write(outK,outv);
}
}
}(4)編寫reducer類
package com.ouyangl.mapreduce.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* @author oyl
* @create 2021-06-03 22:07
* @Description
* * KEYIN, map階段輸入的key的型別:Text
* * VALUEIN map階段輸入value的型別:IntWritable
* * KEYOUT map階段輸出的key型別:Text
* * VALUEOUT map階段輸出的value型別,IntWritable
*/
public class WordCountReducer extends Reducer<Text, IntWritable,Text,IntWritable> {
private int sum;
private IntWritable outv = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
sum=0;
//累加求和
for (IntWritable count : values) {
sum += count.get();
}
//封裝 k v
outv.set(sum);
//輸出 k v
context.write(key,outv);
}
}(5)撰寫 Driver 驅動類
package com.ouyangl.mapreduce.wordcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* @author oyl
* @create 2021-06-03 22:07
* @Description
*
*/
public class WordCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//1、獲取job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//2、設定jar包路徑
job.setJarByClass(WordCountDriver.class);
//3、關聯mapper和reducer
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
//4、設定map輸出的key型別
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//5、設定最終輸出的KV型別
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//6、設定輸入路徑和輸出路徑
FileInputFormat.setInputPaths(job,new Path("C:\\Users\\oyl\\Desktop\\HADOOP\\inputword.txt"));
FileOutputFormat.setOutputPath(job,new Path("C:\\Users\\oyl\\Desktop\\HADOOP\\output1"));
//7、提交 job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}注意:一定注意不要引錯了包 ,輸出路徑一定不能存在,不然會報錯,
運行結果
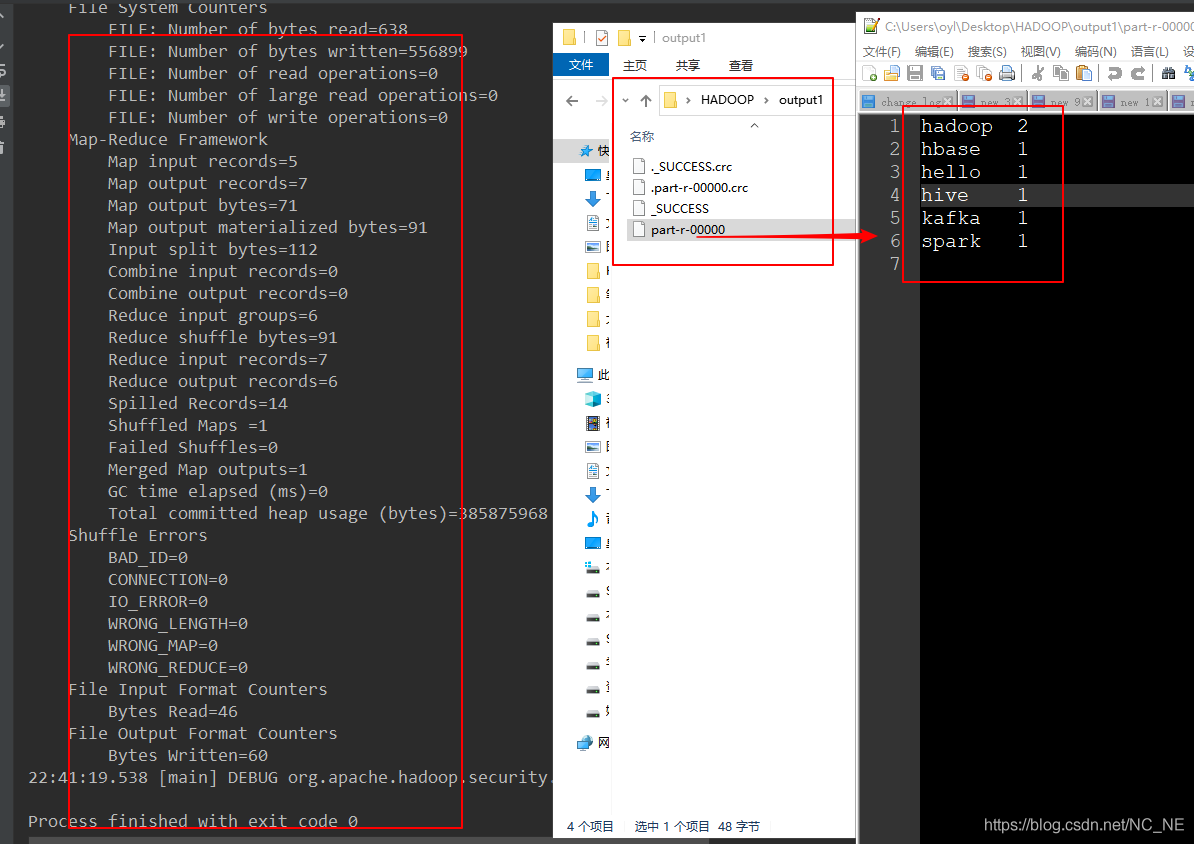
2、提交集群測驗
在pox添加打包插件,將程式打成 jar 包
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>修改Dirver類的輸入輸出路徑(通過傳參傳進來)
//6、設定輸入路徑和輸出路徑
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));打包
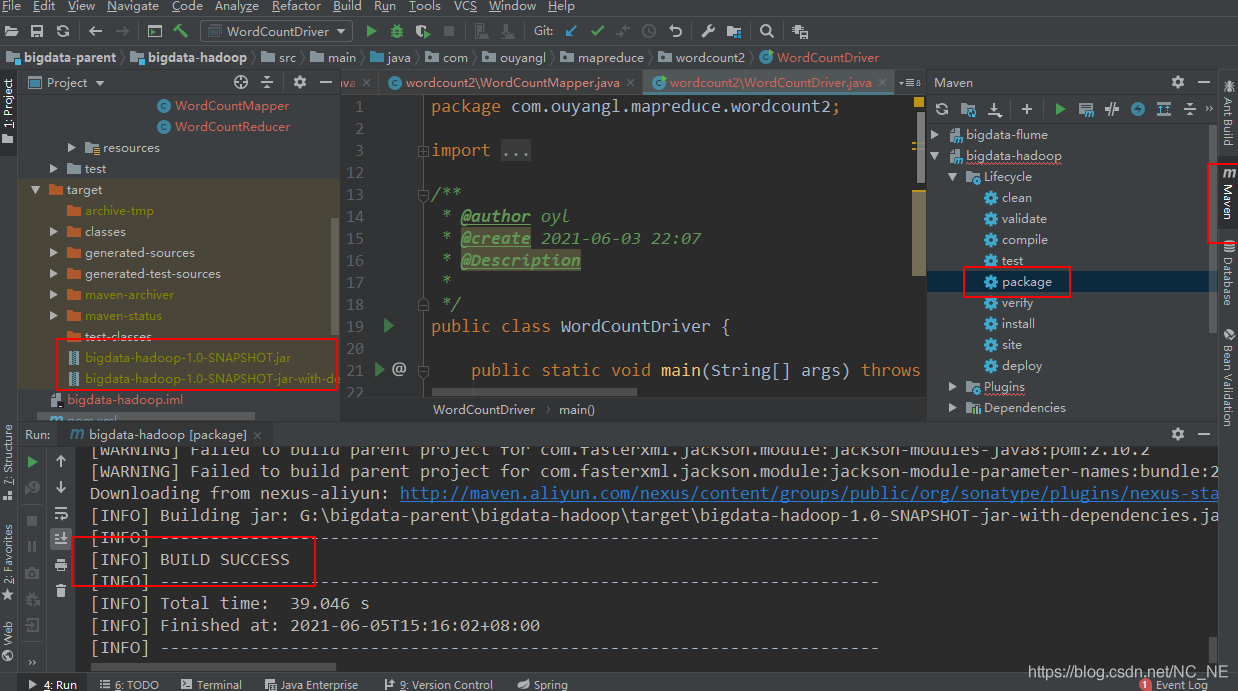
我們將不帶依賴的jar包(bigdata-hadoop-1.0-SNAPSHOT.jar)放到hadoop集群上執行
hadoop jar bigdata-hadoop-1.0-SNAPSHOT.jar com.ouyangl.mapreduce.wordcount2.WordCountDriver /word.txt /output/word.txt 和 /output都是hdfs上的路徑
![]()
運行日志:
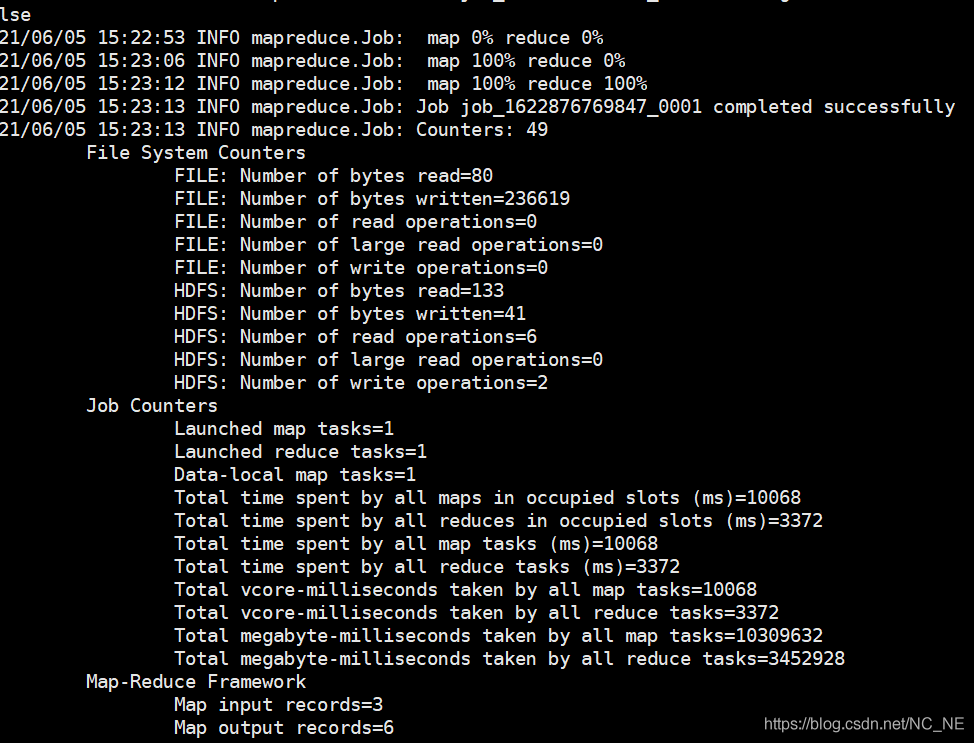
計算結果:
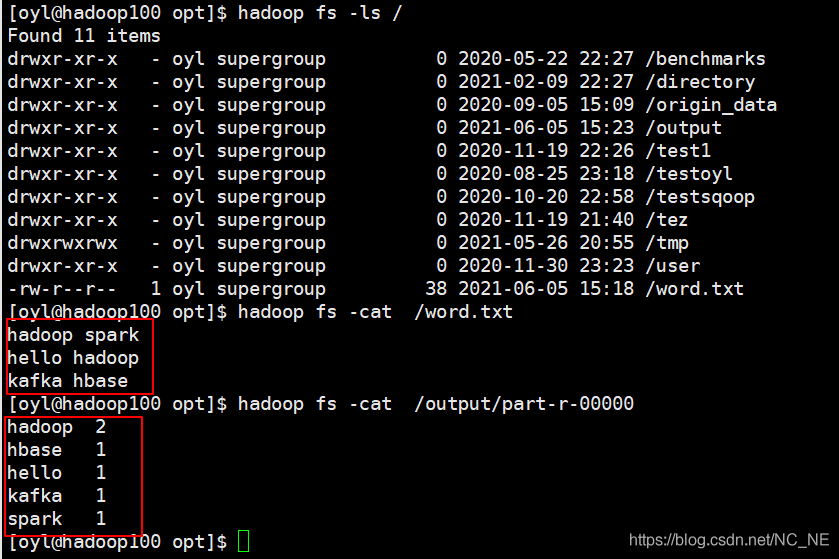
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/286246.html
標籤:其他