生成對抗網路(GAN)詳細介紹及生成數字手寫體仿真(附代碼)
- 生成對抗網路簡介
- 深度學習基礎介紹
- 損失函式與梯度下降
- 反向傳播演算法推導
- 批量標準化介紹
- Dropout介紹
- GAN原始論文理解
- 生成對抗網路基本介紹
- 生成對抗網路理論推導
- 資料生成
- 生成器——制造資料
- 計算差異
- 判別器——學習資料差異性
- 最大化差異推導
- 優化程序
- GAN原始論文演算法步驟詳述
- 判別器訓練演算法
- 生成器訓練演算法
- GAN存在的問題
- 可解釋性非常差
- 訓練不穩定
- 優化震蕩現象
- 生成器容易產生模式崩潰(Mode collapse)
- 數字手寫體生成應用
- 數字影像生成介紹
- 生成器網路結構初始化代碼
- 判別器網路結構初始化代碼
- 仿真結果
- 其他
生成對抗網路簡介
深度學習基礎介紹

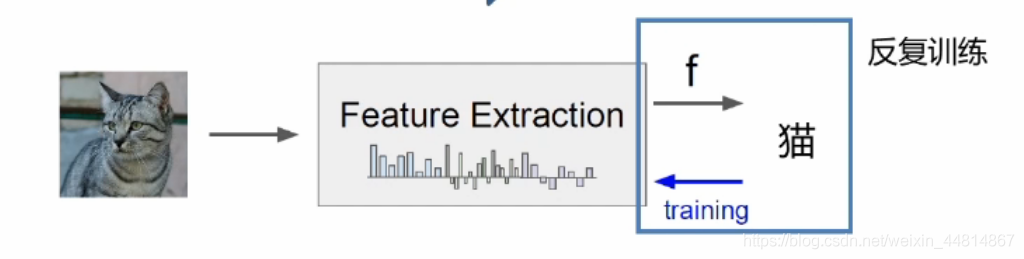
以上圖舉例子,假如要識別這只貓,在這里貓是一張圖片,里面全是一些像素點,因此我們首先要對它進行一些特征提取,提取出貓的眼睛、鼻子、耳朵、花紋等特征,然后對這些提取出的這些特征進行學習,然后去識別這到底是不是一只貓,通過學習不停反復進行訓練提取后的特征,然而會導致資訊嚴重的丟失等問題,
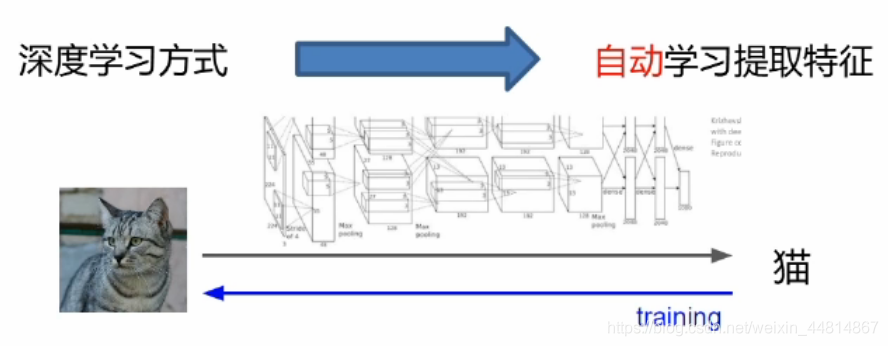
我們可以通過深度學習模型進行自動特征提取,直接從像素進行特征提取,然后去學習,學習之后然后再反向傳播后去修正各個模塊和提取的方式,這就相當于從頭到尾它是一個聯通的,不想傳統的機器學習那樣提取特征后,特征可能是好的也可能是壞的,對后面的學習無法進行修正,因此能夠自學習自修正是深度學習的一個非常大的優勢之一,深度學習最核心的在于分工與合作,以下圖舉例說明:
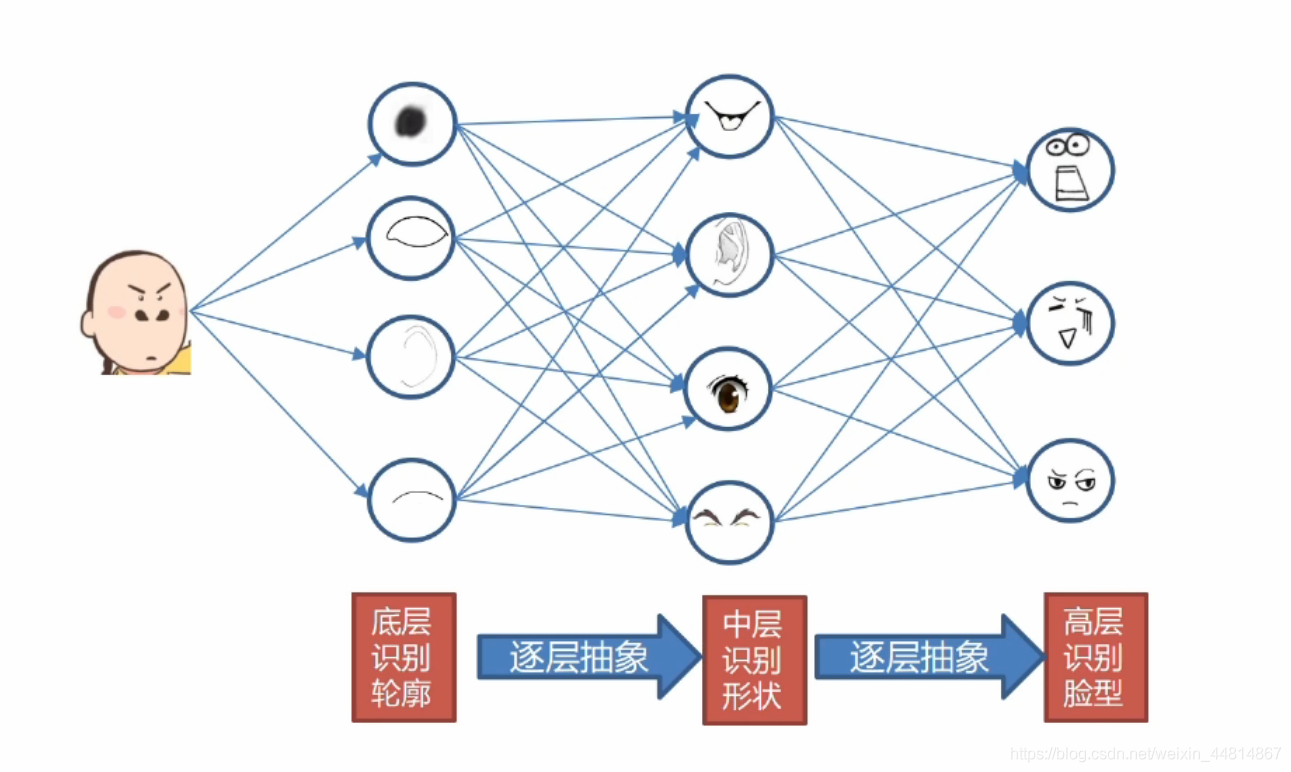
對于這樣一個人臉影像,首先我們進行底層的輪廓識別,得到這些最基本特征,然后逐層抽象之后可能得到耳朵,鼻子,眼睛等這些中層識別形狀特征,然后再進行逐層的抽象就會變成高級的臉部特征,比如笑臉和哭臉等特征,這就是深度學習最重要的分工和合作,逐層提取出不同的特征,然后重新組合得到更高級更抽象的特征,
損失函式與梯度下降

比如我們經常用到的均方誤差分析法(最小二乘法)和交叉熵損失法(對數極大似然):
均方誤差損失(最小二乘法) :該損失函式用于度量輸出值范圍為實數的回歸任務,
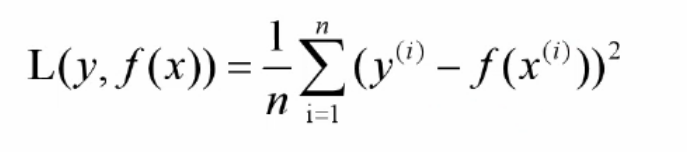
交叉熵損失(對數極大似然):該損失函式用于度量輸出值范圍為(0, 1)概率的分類任務,
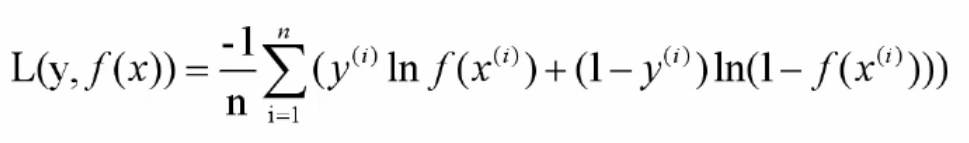
綜上所述:我們損失函式的核心目的就是降低損失,那么如何降低損失函式?我們需要用到梯度下降法等來降低損失函式,
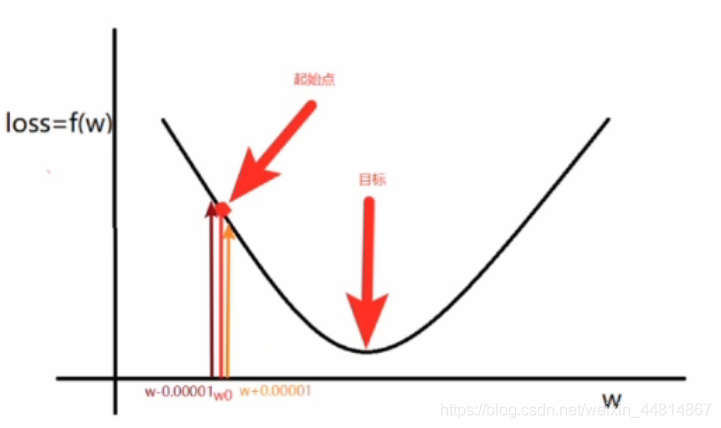
對于上述圖中的損失函式(均方誤差函式),如圖中所示的起始點與目標點,那么我們如何去降低它呢?我們可以在起始點處進行試探,如以下梯度公式:
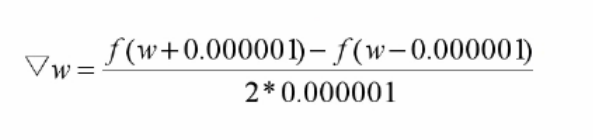
所謂梯度就是下降最快的方向,根據正負確定向左還是向右,最終在目標值處附近徘徊震蕩并趨向于最優值,說白了其實就是就是確定損失函式降低的方向(增加還是減少引數),至于一次要走多少距離,一般用α表示,也就是學習率,一般由認為設定,
反向傳播演算法推導
下圖為一個簡單的數學鏈式求導的一個問題:J(a,b,c)=3(a+bc),u=a+v,v=bc,求a,b,c 各自的偏導數,求得結果如下圖所示:
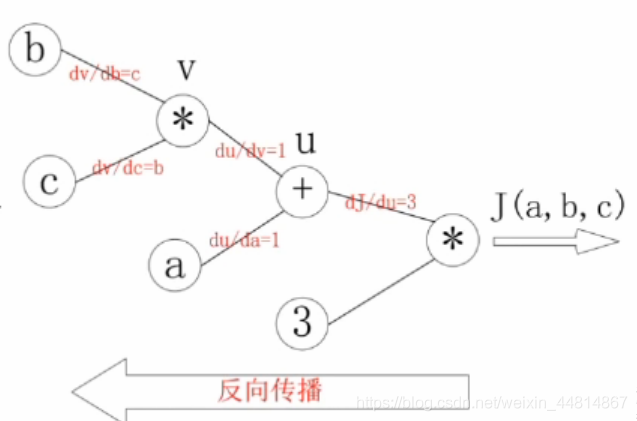
a,b,c 各自的偏導數就等于反向的梯度連接線相乘
dJ\da= 31 dJ\db= 31c dJ\dc=b1*3
總結:反向傳播就是復合函式的鏈式求導法則的應用,
批量標準化介紹
為什么要進行批量標準化?
對于量綱不一致的資料,按照一定的規則,進行一個批量處理,這樣的好處就是可以加快神經網路的訓練速度,提高模型的精度,
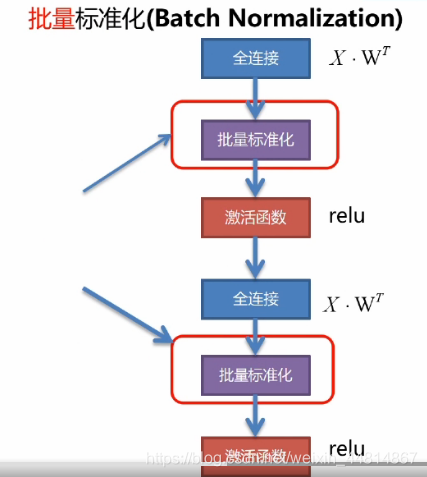
上圖為深度學習網路的一個基本框架,全連接層實質上就是一個映射變換,然后放入激活函式中進行激活,再進入到下一個連接層,這樣一層一層的進行傳播,每一個連接層就是轉化后的特征,也都需要去進行批量標準化,為了配合隨機梯度下降,我們使用批量采樣資料的均值與標準差,該方法極大的降低了深度學習訓練的難度!
Dropout介紹
Dropout(最常用的深度學習正則化措施)
下圖分別為深度學習的全連接模型和經過Dropout后的深度學習模型
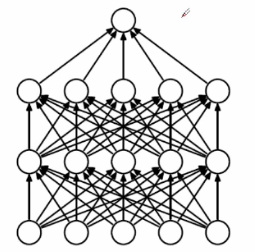
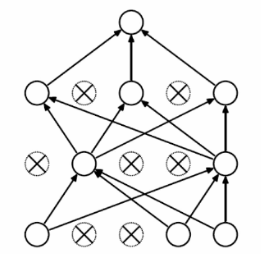
如第二個圖所:Dropout實質上就是每一次選取部分神經元進行傳播計算,
Dropout:訓練時:每次迭代只隨機激活一定數量的神經元進行計算,
測驗時:激活所有神經元進行計算,
計算程序:
1.生成掩碼
訓練程序:
以p的概率隨機產生0,1數;
mask={0 1 0 0 1 0 0 1 0};其中0表示抑制,1表示激活,
測驗程序:
mask={1 1 1 1 1 1 1 1 1};
計算程序:
out = mask*ReLu
GAN原始論文理解
生成對抗網路基本介紹
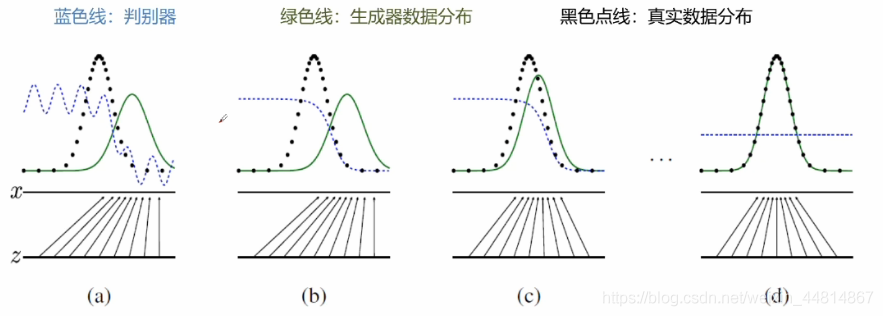
生成對抗網路由GoodFellow在2014年首次提出,是未來深度學習最具潛力與突破性的想法,在數字手寫體生成,影像風格轉換,影像修復等領域具有很廣闊的前景,GAN的核心思想就是最小最大游戲(零和博弈),游戲雙方為判別器跟生成器,生成器就是學習偽造資料,判別器就是判別資料的真實性,判別資料是生成器生成的還是原本真實的資料,為了勝利,它們不斷優化自我不斷提高各自的生成能力和判別能力,最終生成器可以以假亂真生成真實的資料,
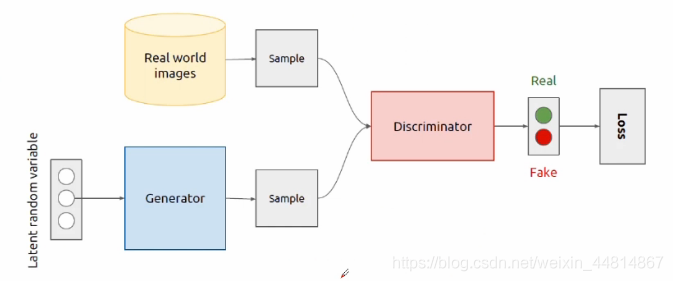
生成器跟判別器為兩個分開獨立的神經網路,生成器用來學習生成資料,隨機的噪聲作為生成器一開始的輸入資料,經過生成器的傳播形成一定的采樣資料,判別器用來判別資料的好壞與真實性,資料的來源一部分來自對真實資料的采樣,另一部分來自于生成器生成的資料,對真實的資料標記為”1“,代表資料是真實的,然后進行一個前向傳播,然后選取同等數量的生成器生成的資料標記為”0“,然后交給判別器進行一個前向傳播,就可以計算到一些損失值,然后再進行反向傳播,特別注意的是:在訓練判別器的時候應鎖住生成器,反之亦然,在訓練生成器的時候,不訓練判別器,判別器僅僅提供梯度,不提供權重的更新,
生成對抗網路理論推導
資料生成
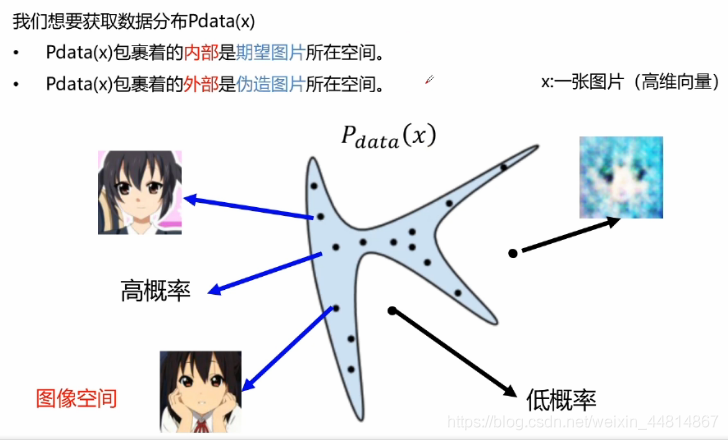
Pdata(x)外部的空間是一些偽造的圖片,由對抗網路所生成的一些資料,GAN的目標其實就是找到Pdata(x)這樣一個資料空間,在它的內部生成一些足夠真實的資料,

我們并不知道資料分布Pdata(x)是什么樣子,但是我們可以確信我們的資料來源于Pdata(x),

PG(x)是我們生成模型生成的資料分布,我們期望它生成的資料和Pdata(x)盡可能的相似,
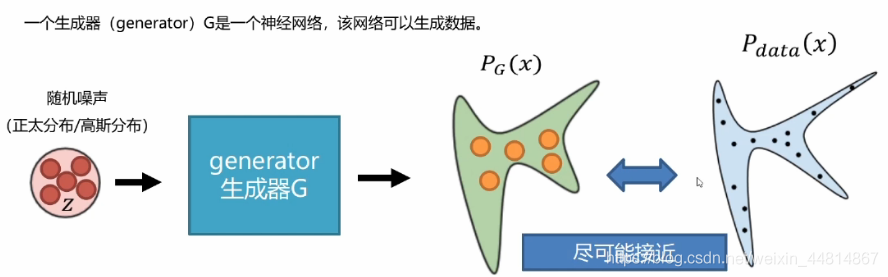
生成器——制造資料
生成器(generator)G是一個神經網路,該網路可以生成資料,
計算差異
生成器生成的資料PG(x)盡可能要與Pdata(x)相近,接近之后才能仿造真實的資料,但是問題是如何去衡量和計算它們之間的差異呢?
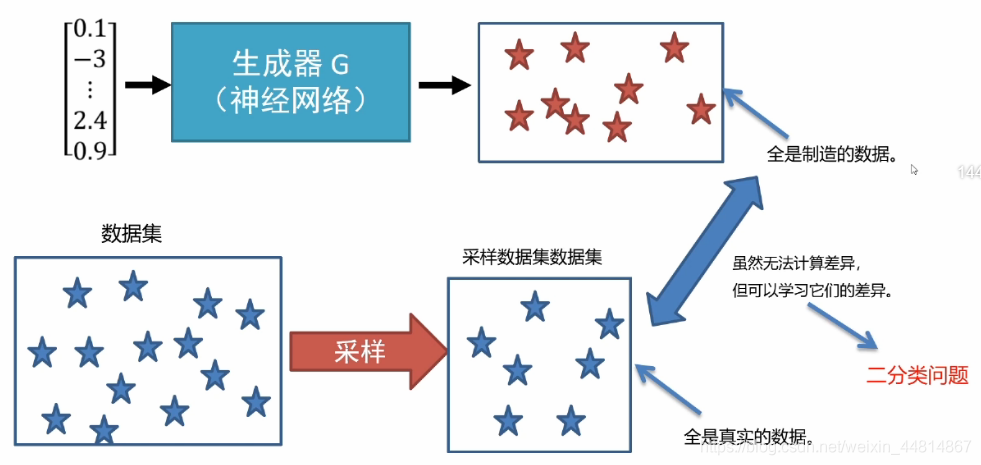
第一部分生成器對隨機噪聲進行傳播計算得到偽造的資料,這是我們已知的,真實的資料也就是已經存在的資料集,對其進行采樣后一部分資料得到真實的資料集,對于兩個資料之間的差異我們可以進行學習,可以歸為一個簡單的二分類問題,
判別器——學習資料差異性
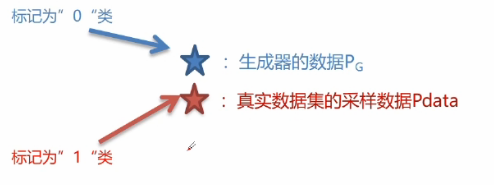
將生成器制造的資料跟采樣資料合在一起,組合成了一個二分類資料集,然后放入判別器的神經網路中進行訓練從而達成目的,我們可以使用極大似然估計這樣的損失函式用來學習二分類學習任務,

上述公式中,紅色部分來源于真實的資料,所以我們的損失值logD(x),D(x)期望輸出1,生成器標記為”0“類,因此損失值用log(1-D(x))來表示,將二分類資料集送給判別器,如果這個資料集差異性較小,那么判別器將難以判別,訓練完后還是損失值較大,很難降低,如果這個資料集本身差異性就很大,即使通過判別器簡單的訓練后就非常容易判別,那么就是最終判別器的損失值較小,所以就是說,訓練到最優的時候,損失值越小,資料的差異性就越大,接下來用公式舉例說明:
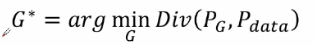
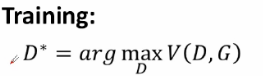
我們的目標是學習一個生成器G*,它的目的是最小化Pg和Pdata之間的差異性,那么最小化G的話,我們就需要訓練一個最佳的D*,D的任務就是要最大化真實書記和偽造資料之間的差異性,對于判別器所提供的一個差異然后再進行一個生成器的訓練,
最大化差異推導
判別器的目標就是最大化資料的差異,我們可以使用以下交叉熵損失函式:
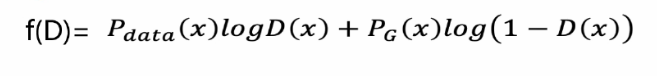
對此公式進行簡化后可得:
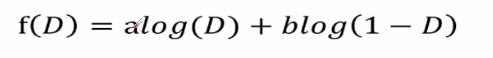
我們的目的是求最大化差異也就是求f(D)的極值,那么可得f(D)函式的梯度就等于0,
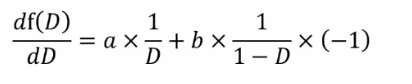
整體后可得:
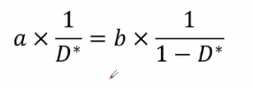
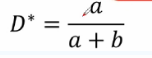
可得最佳的判別器D*(x)的運算式如下:
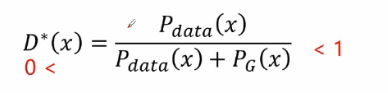
然后將D*(x)帶入判別器的一個交叉熵損失函式中:
交叉熵損失函式:
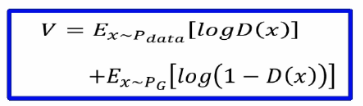
帶入后可得以下等式并推導可得GAN用JS散度描述的一個損失函式(Jensen-Shannon divergence):
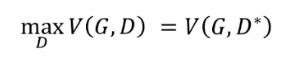
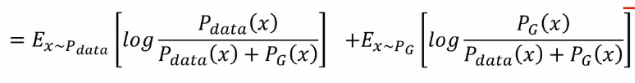
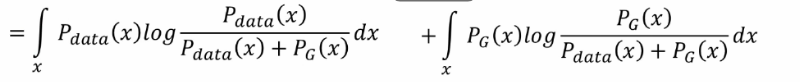
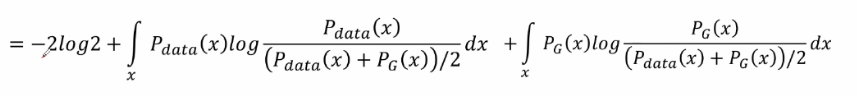
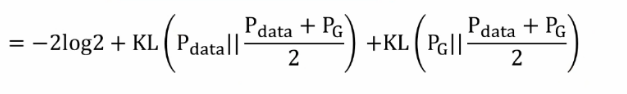
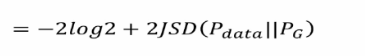
優化程序
生成對抗網路的代價函式:
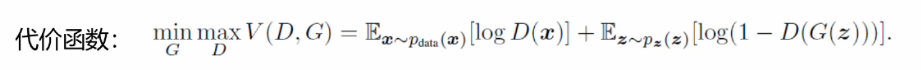
它是一個最大化最小化的程序,首先要最大化判別器的差異性,他要去判別生成資料跟真實資料之間的差異,在訓練較好的情況之后,接下來就最下化生成器的損失,生成器生成的資料要和真實資料盡可能的高度相似,然而判別器要盡可能的進行區分真實資料和生成資料,因此兩者之間就產生了一個對抗的關系,

GAN原始論文演算法步驟詳述
判別器訓練演算法

生成器訓練演算法

GAN存在的問題
可解釋性非常差
所學到的資料分布Pg(G),沒有顯示的運算式,它只是一個黑盒子一樣的映射函式: 輸入是一個隨機變數,輸出想要的一個資料分布,
訓練不穩定
難以保持生成器與判別器的平衡
優化震蕩現象
生成器容易產生模式崩潰(Mode collapse)
舉個生成數字影像的例子:生成器要生成0-9之間的數字,而判別器只是要判斷生成器生成的資料像不像真實資料,比如”1“是非常容易生成的一個數字,那么生成器可能就會拼命的去生成更多的真實的”1“,從而判別器就難以判別,對于其他的復雜一點的數字比如”8“,”9“,生成器可能就干脆不生成了,從而避免犯錯,這就是生成器的一個大問題,我們的希望是生成0-9的數字,然而最終就會導致這些問題出現,
數字手寫體生成應用
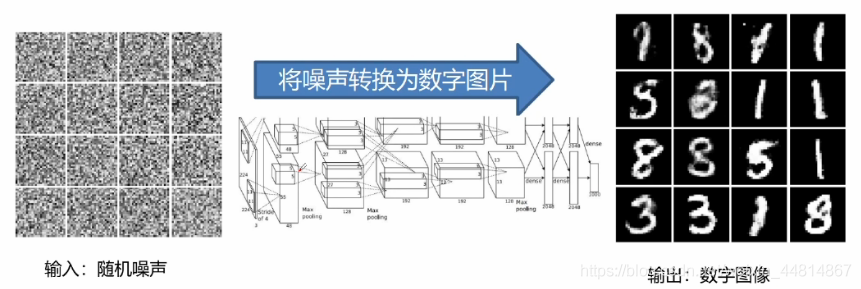
數字影像生成介紹
生成器網路結構初始化代碼
def _init_gen(self):
"""
初始化生成器網路結構
網路結構 例如[noise_dim,100]*[100,100]*[100,gen_dim]
:return: 生成資料op
"""
self.gen_x = tf.placeholder(dtype=tf.float32, shape=[None, self.noise_dim], name="gen_x")
# 構造生成器輸入層
active = tf.nn.relu(tf.matmul(self.gen_x, self.w_g_list[0]) + self.b_g_list[0])
# 構造生成器隱藏層
for i in range(len(self.gen_hidden) - 1):
active = tf.nn.relu(tf.matmul(active, self.w_g_list[i + 1]) + self.b_g_list[i + 1])
# 構造輸出層
out_logis = tf.matmul(active, self.w_g_list[-1]) + self.b_g_list[-1]
g_out = tf.nn.sigmoid(out_logis)
return g_out
判別器網路結構初始化代碼
def _init_dicriminator(self, input_op):
"""
初始化判別器網路結構
網路結構 例如:[gen_dim,100]*[100,100]*[100,1]
:param input_op: 輸入op
:return: 判別器op
"""
# 構造判別器輸入層
active = tf.nn.relu(tf.matmul(input_op, self.w_d_list[0]) + self.b_d_list[0])
# 構造判別器隱藏層
for i in range(len(self.d_hidden) - 1):
active = tf.nn.relu(tf.matmul(active, self.w_d_list[i + 1]) + self.b_d_list[i + 1])
# 構造判別器輸出層
out_logis = tf.matmul(active, self.w_d_list[-1]) + self.b_d_list[-1]
return out_logis
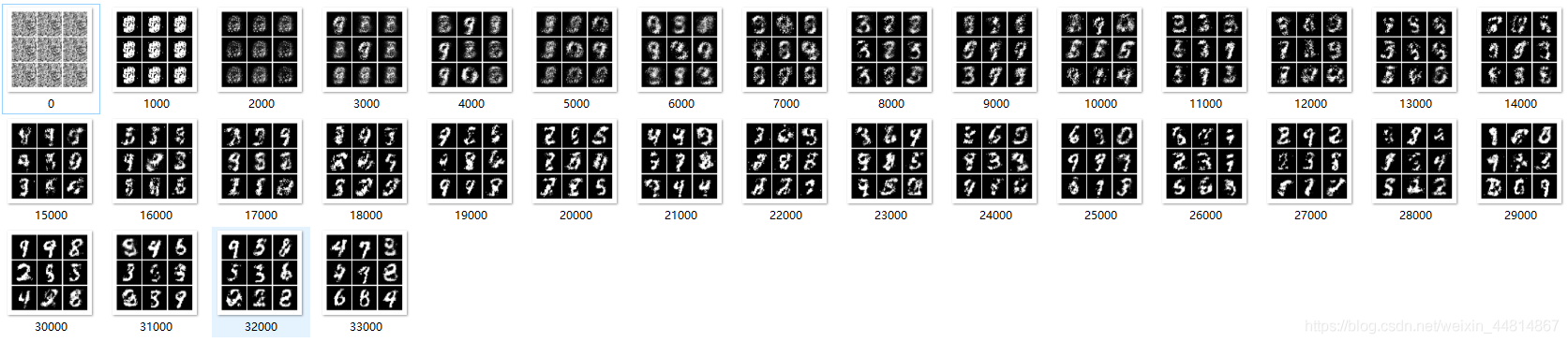
仿真結果
其他
本文是建立在第一篇GAN的原始論文——《GenerativeAdversarialNets》的基礎之上進行的一個總結,并借鑒別人的代碼對原文的演算法進行一個簡單的復現,接下來會繼續學習并整理深度卷積生成對抗網路(DCGAN),Wasserstein GAN(WGAN),LSGAN,Improved Training of Wasserstein GAN,CGAN,CycleGAN等GAN的各種變形,
本文代碼:鏈接:https://pan.baidu.com/s/19C68rjnOxUkEEJxnKkYo7w
提取碼:o9vp
關注!關注!關注!關注!關注!關注!關注!關注!關注!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/286392.html
標籤:其他