我們曾在四年前對于Unity的主流模塊的性能優化知識點逐一做過講解,俗稱“小白版”,隨著這幾年引擎本身、硬體設備、制作標準等等的升級,UWA也不斷更新優化規則和方法并持續輸出給廣大開發者,作為"升級版"的性能優化手冊,【Unity性能優化系列】將力圖以淺顯易懂的表達,讓更多開發者可以受用,本期我們來分享Lua相關的知識點,
Lua可以說是現在商業游戲中的標配,隨著大家Lua用得越來越重度,一些性能問題也開始浮出水面,無論是GPM、GOT Online還是真人真機測驗報告中,我們經常會在一些邏輯代碼的Top20的開銷串列中看到Lua開銷的相關函式,這就是要引起我們重視的,

有什么辦法可以快速抓到Lua的瓶頸呢?讓我們打開GOT Online的Lua報告看看它有什么很棒的feature吧:
這里小編先分別解釋下報告頁面中的幾個標簽,如下所示,我們依次來看下:
1、代碼效率>>解決Lua CPU耗時較高的問題
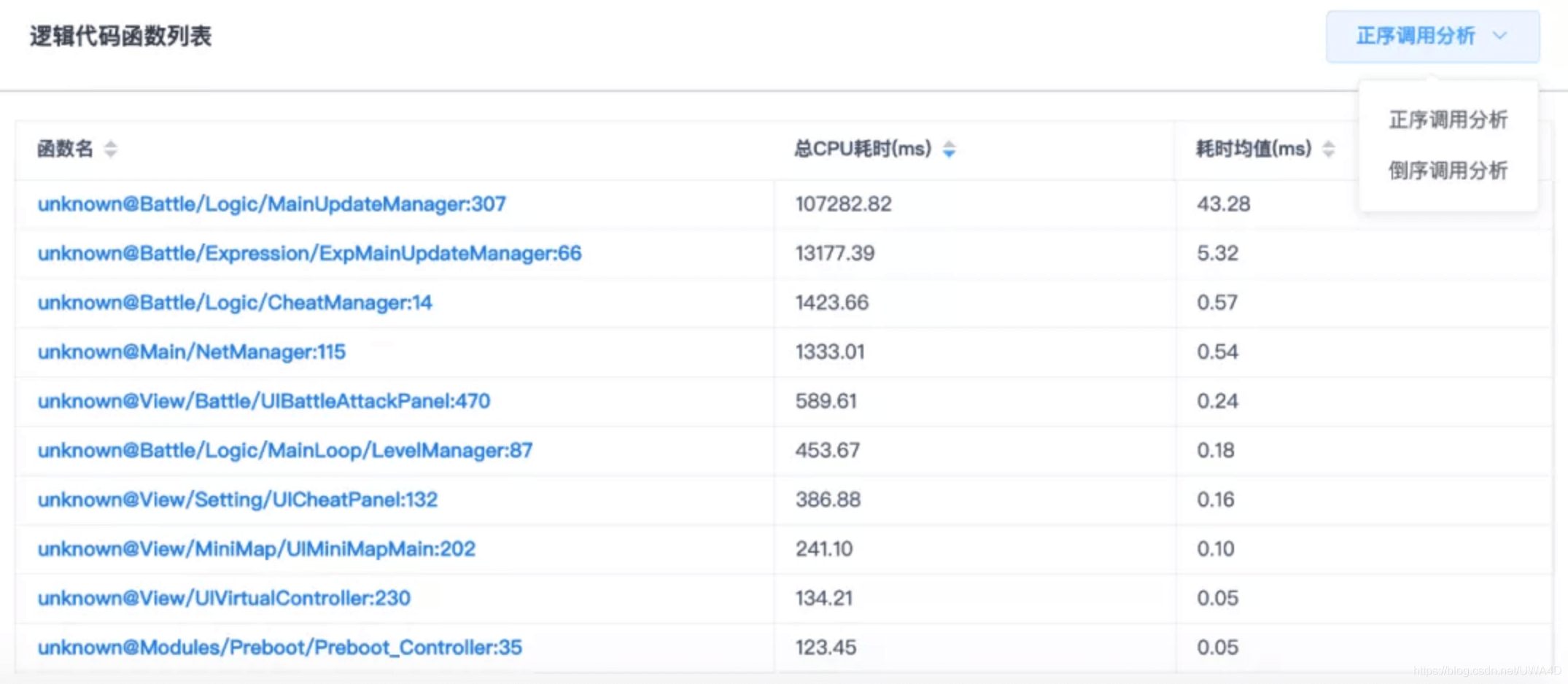
在代碼效率-CPU時間占用頁面,可以看到Lua端的耗時,
點開這些函式,我們就可以查看這些函式的總體耗時堆疊、指定場景堆疊以及在任意一幀的具體耗時堆疊,迅速定位瓶頸函式,
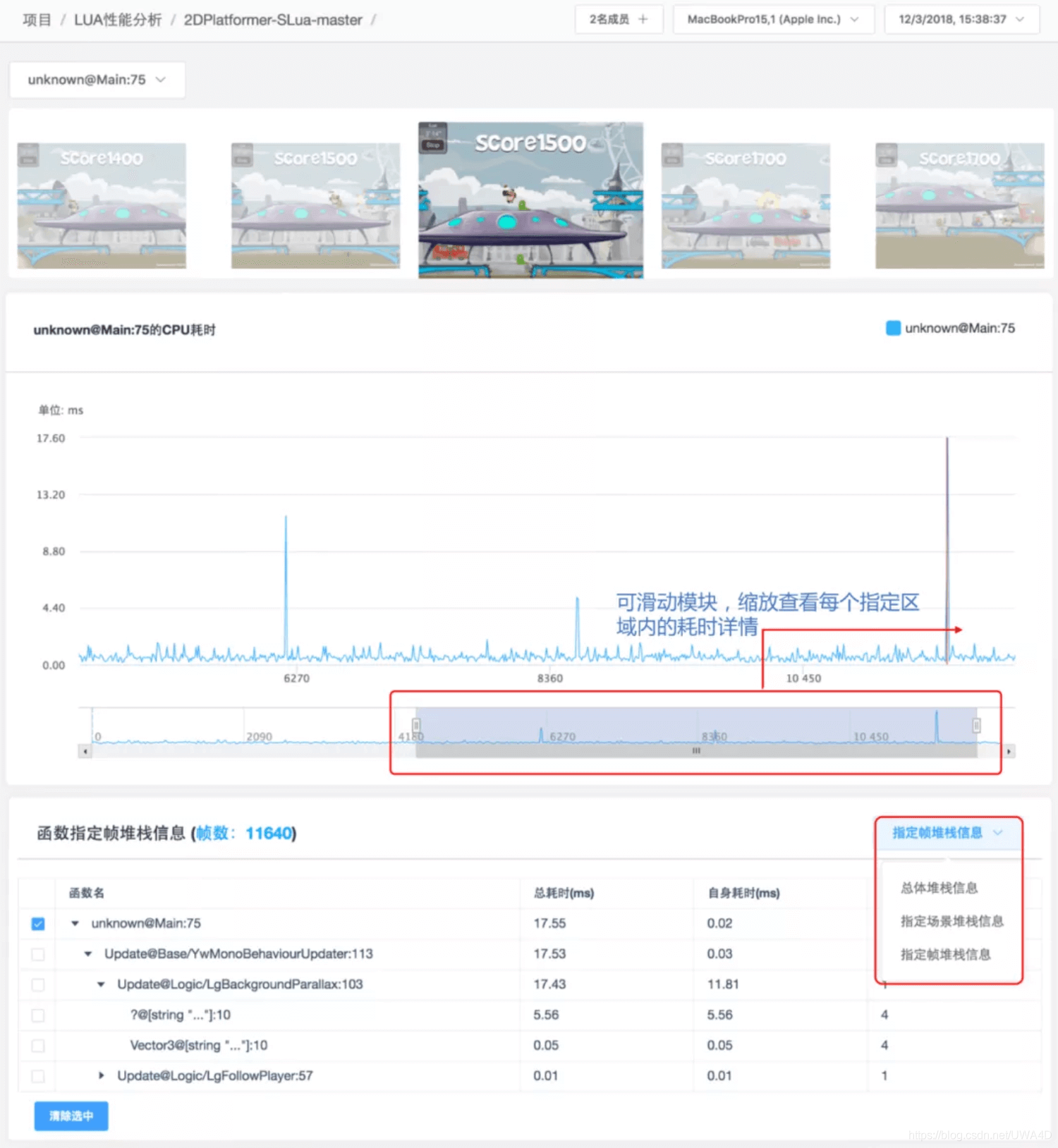
說明:可以通過這里提供的Lua檔案名/行號/函式名來定位CPU耗時的瓶頸函式和CPU耗時峰值的具體原因,
Lua函式的命名格式為X@Y:Z,其中X是其函式名,在無法獲取時,X會變為默認的unknown;Y是該函式定義的檔案位置;Z則是該函式被定義的行號,需要注意的是,當Lua腳本以位元組碼運行時,該值將始終為0,因此建議在測驗時盡可能使用Lua原始碼來運行,
特別地,堆疊的分析支持倒序查看,很多時候我們需要展開堆疊點個幾十層,看得頭暈眼花,但如果我們切換成倒序分析,即將原始的CPU耗時堆疊進行倒序排列,從而將真正開銷最大的深層子函式直接突顯,研發團隊就能很快定位開銷的瓶頸,
以某個專案為例,下圖為正序排序的高耗時函式串列:
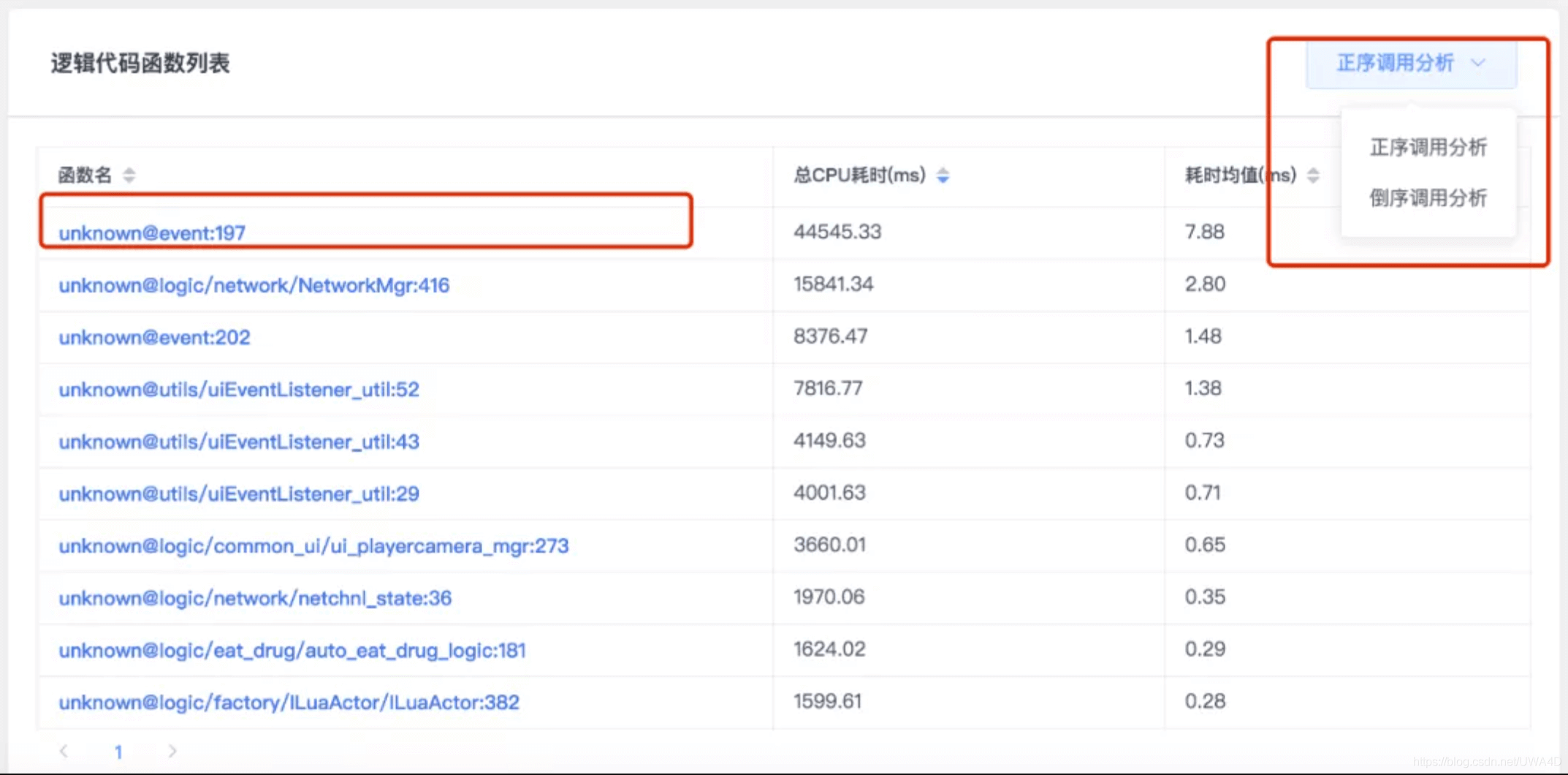
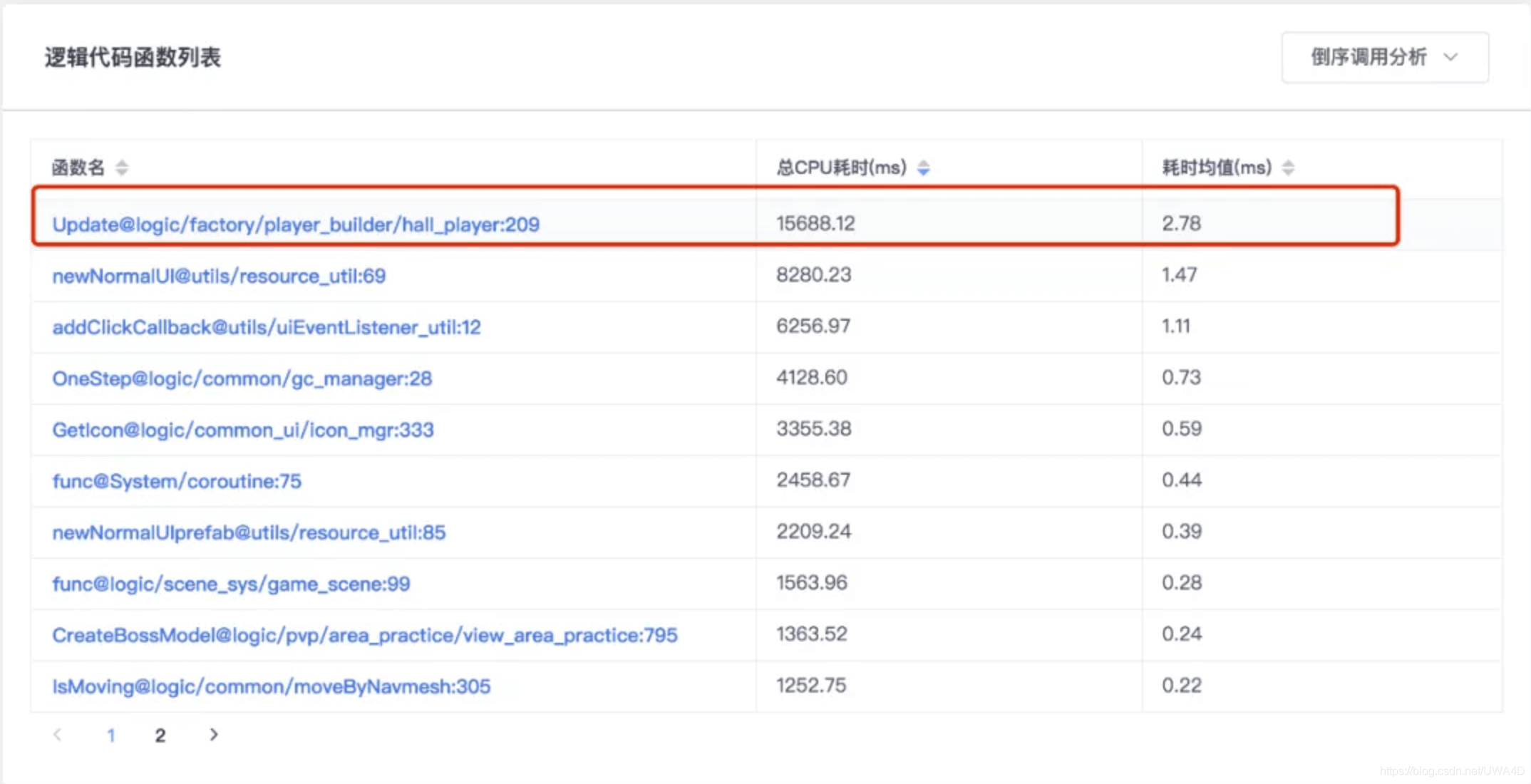
點開幾層堆疊后我們發現這里有個大頭子函式“Update@logic/factory/player_builder/hall_player:209”,但如果我們直接用倒序查看的話會怎么樣呢?
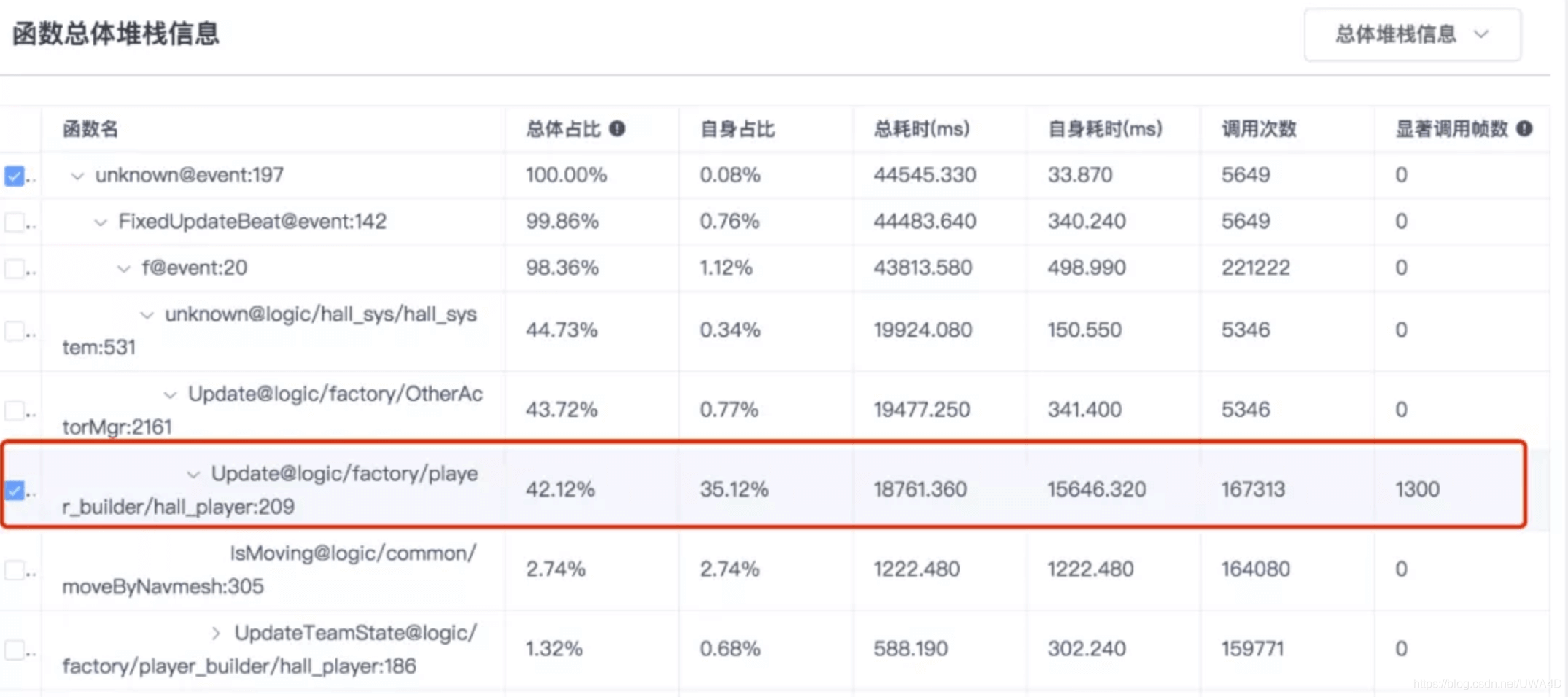
這個大頭函式直接被排上了首位,那我們就直接拿這個函式開刀就可以啦~
2、堆記憶體分配>>解決Lua堆記憶體分配較多的問題
Lua的堆記憶體分配同樣是需要我們關注的,用來降低Lua GC的觸發頻率和觸發時的開銷,在報告中我們也是通過堆記憶體累計分配曲線+函式堆疊來定位造成堆記憶體分配的函式,
分析的思路如下:
1、關注堆記憶體分配的峰值
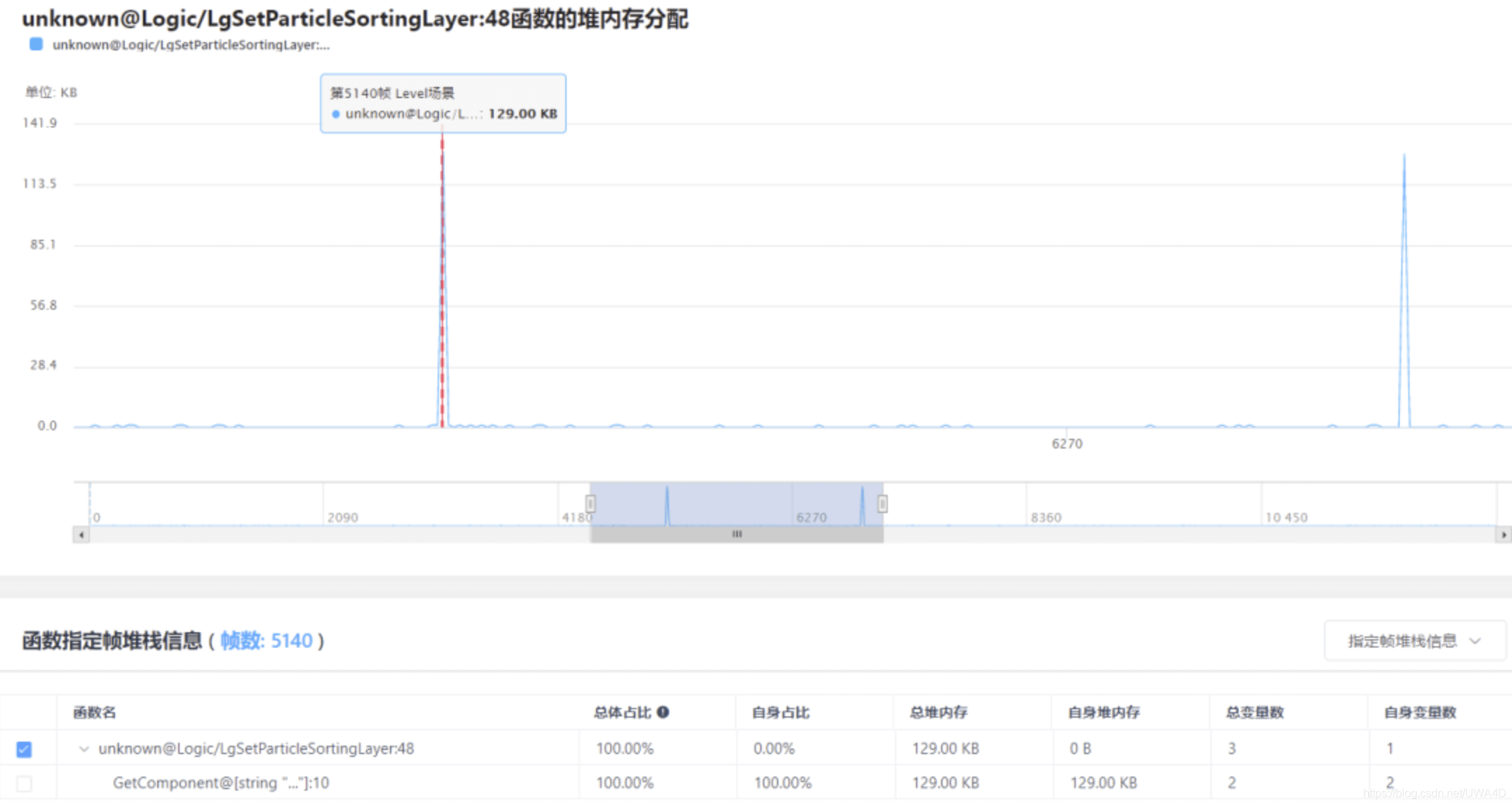
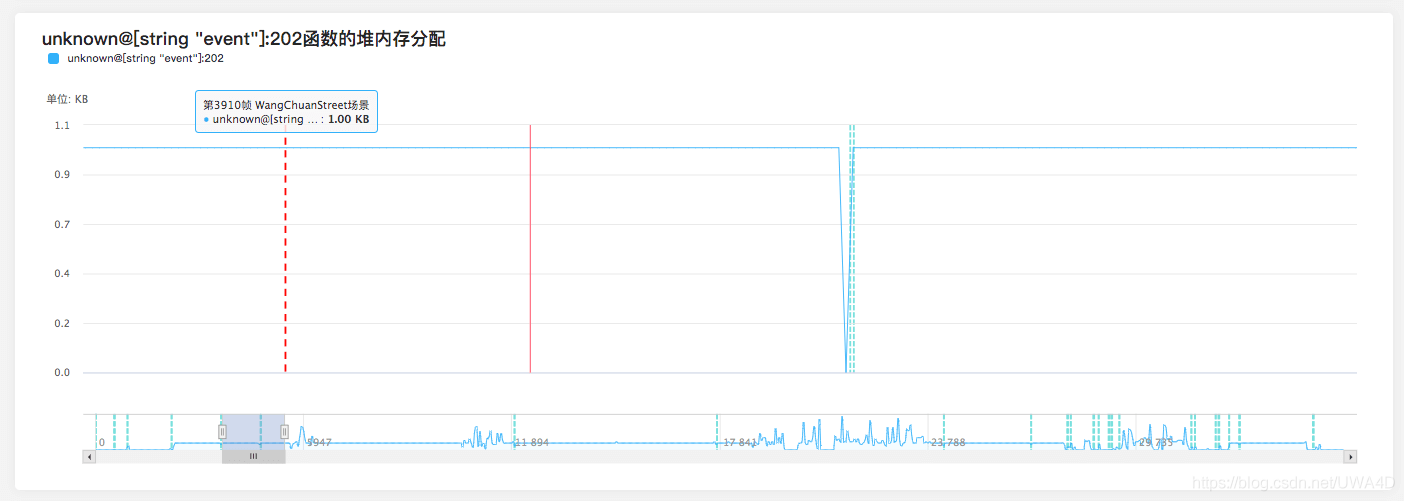
2、關注持續性的分配
如果每幀都有持續的開銷,那一定需要特別關注,持續性的分配容易觸發GC,
3、堆記憶體分配倒序分析
在總體堆疊資訊中關注倒序堆疊分配占比較高的父節點進行針對性優化:
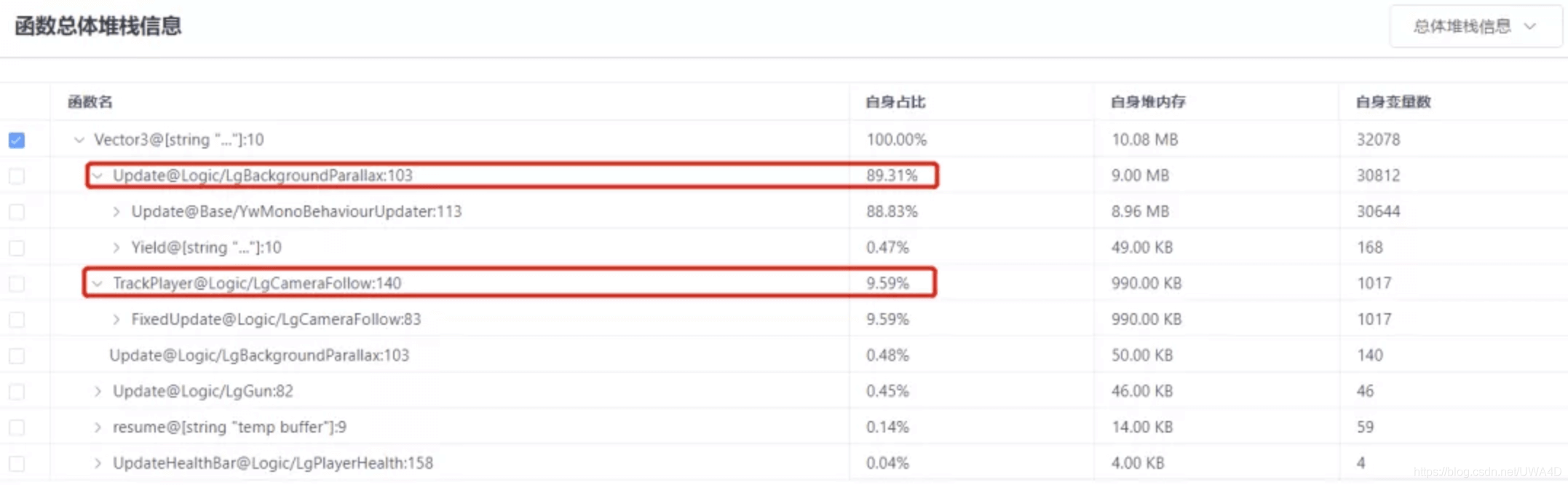
如上圖,在Lua的堆記憶體中我們同樣可以這樣切換成“倒序”:只需要切換查看方式,我們就可以直觀地定位到底哪一個Lua腳本中的哪一行代碼在分配大量堆記憶體,這樣,研發團隊就能直接打開對應的Lua腳本,找到那一行和函式直接修改,
3、Mono物件參考>> 解決讓你禿頭的泄露問題
在任意一種Lua插件中,都存在類似的機制:在C#層維護一個Cache來參考那些被Lua訪問過的C#層物件,防止出現以下的問題:當Lua中再次訪問該C#物件時,該物件可能已經被C#層的GC回收掉了,從而導致邏輯錯誤,所以,在Lua中始終保留某個C#層物件的參考,將會導致其無法被釋放,當這樣的參考越來越多,就會導致C#層的記憶體泄漏,
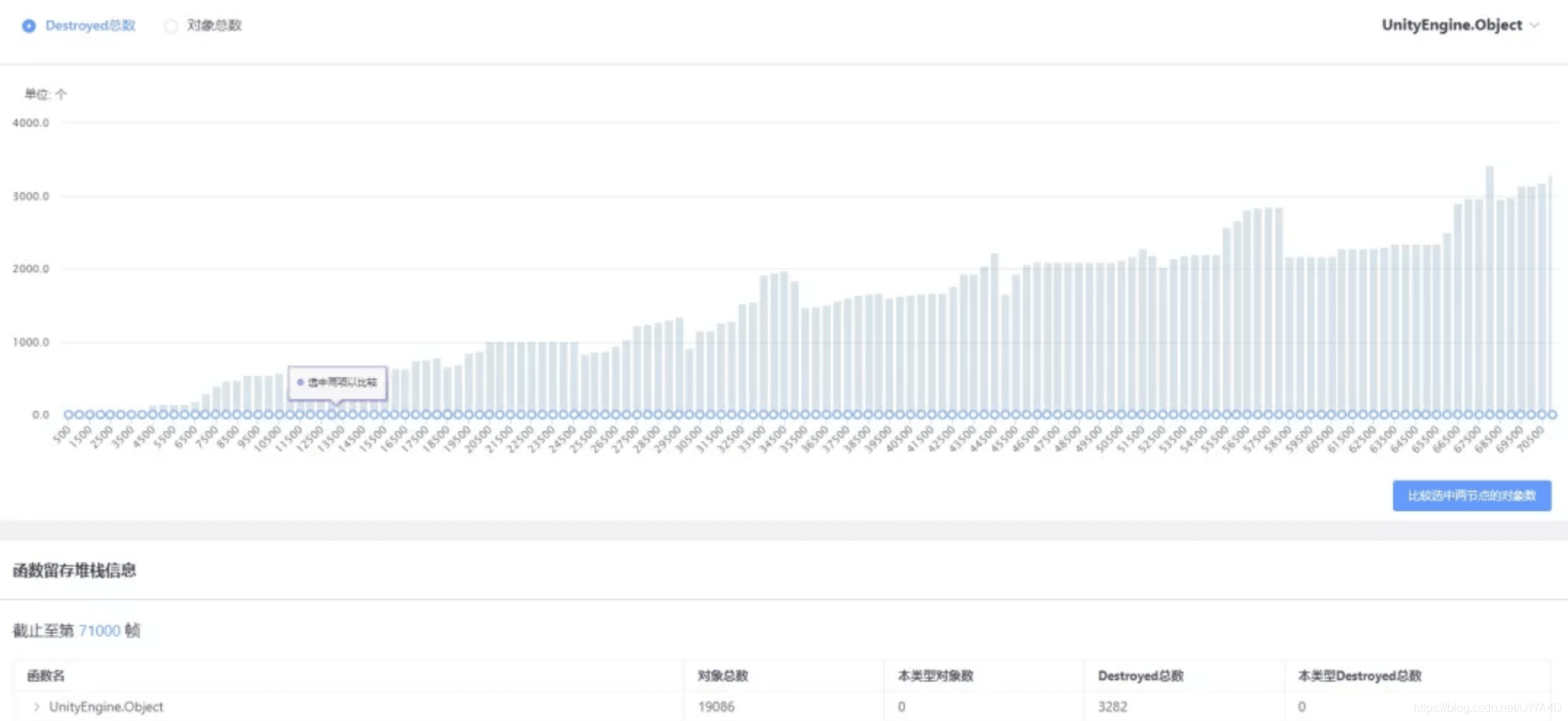
為了便于用戶排查這種情況,我們在Mono物件參考的報告頁面中對上述的Cache中C#層物件進行了匯總,統計了Cache中出現的物件型別和各個型別的物件總數,當該物件繼承自UnityEngine.Object時,還將統計該型別中已經被Destroy的物件數量,如下圖所示:
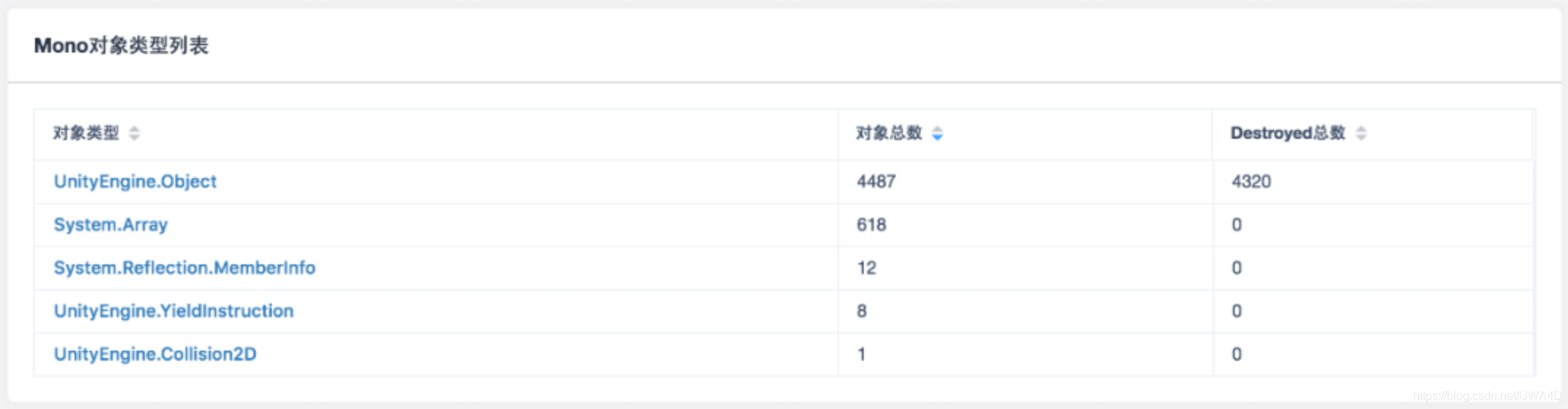
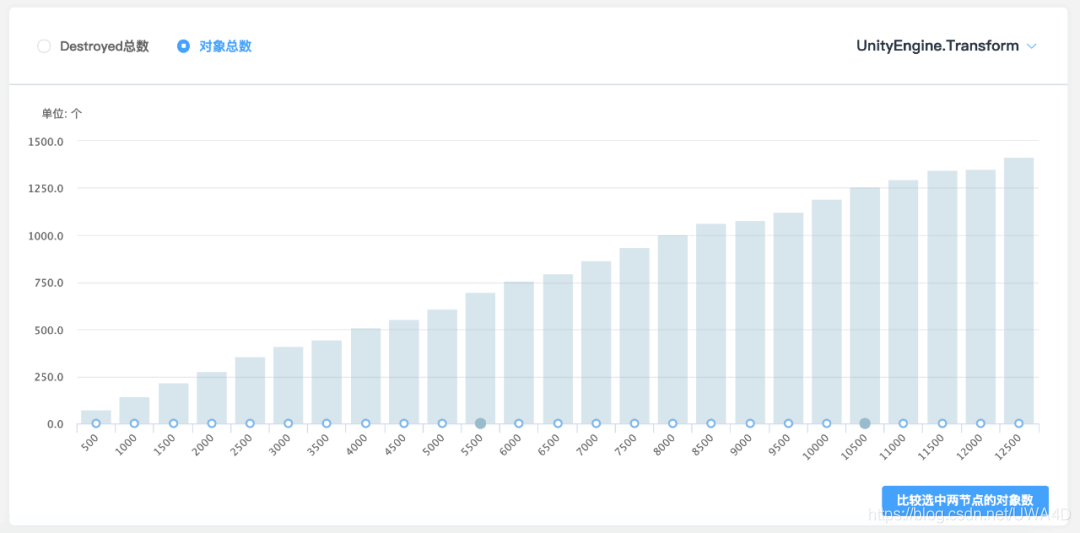
所以,對于判斷Lua參考導致Mono泄露的一個簡單的方法就是查看Destroyed總數是否為零,因為它表示的是Mono端已經被Destroy但Lua端卻依然被索引的變數總數,理論上應該是趨向于0的,如果它持續很高,甚至還有不斷走高的趨勢,那么很大概率是泄露了,如下圖所示:
對于某些數量持續上漲的物件型別,還可以在圖表下通過對比兩個不同采樣點的物件參考,從而進一步定位Lua中不合理的參考,
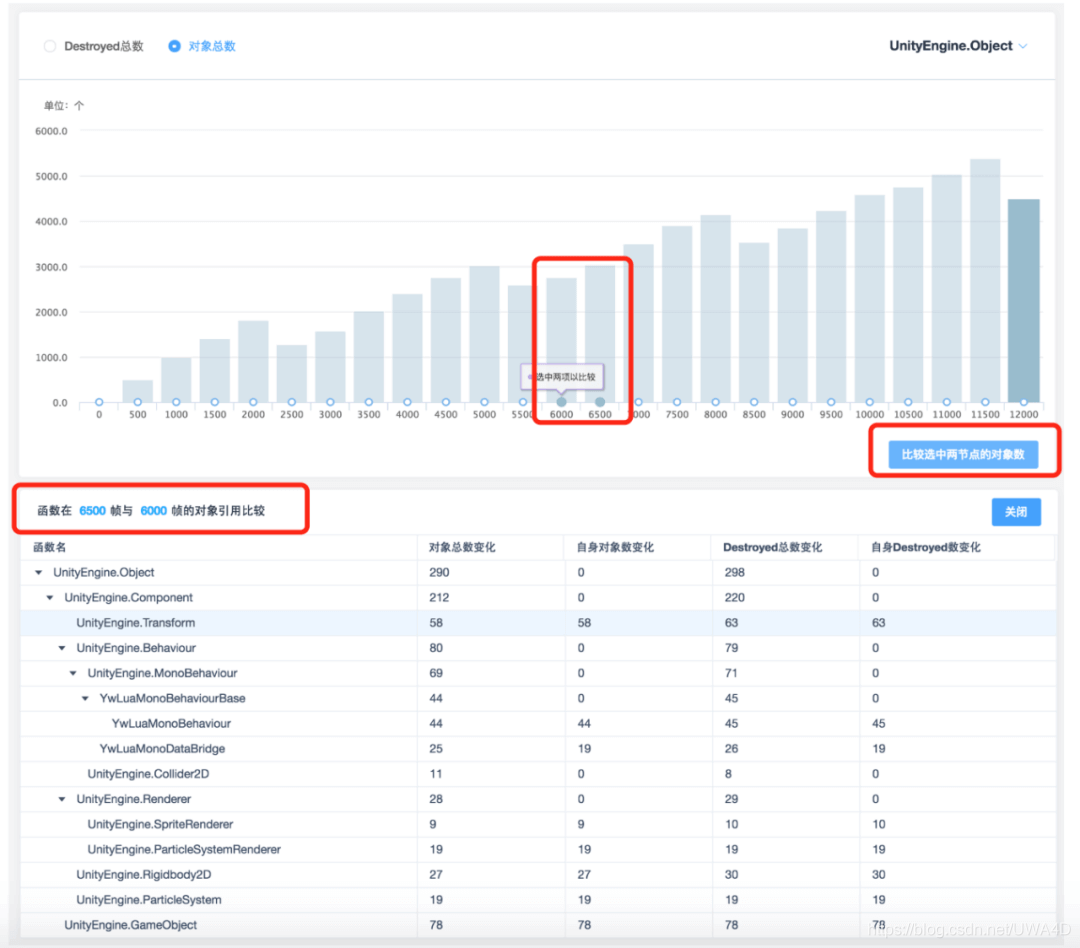
補充說明:但凡是排查泄露的需求,建議長時間測驗,畢竟泄露問題一旦發生,聚沙成塔就很快了,
以上就是在優化Lua性能時需要關注的一些問題和對應的方法,如何操作還需要大家結合專案實際情況,當然我們UWA已經開發的GOT Online和本地資源檢測都已經提供了很豐富的檢測功能,希望能成為大家優化Lua的神助攻,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/286491.html
標籤:其他
上一篇:Linux相關復習