目錄
- 概述
- 產品架構
- 資料分片原理
- 資料同步原理
- 多版本并發控制
- 關鍵演算法介紹
- 參考文獻
概述
隨著5G、物聯網、人工智能的高速發展,企業所生產的資料會越來越多,其規模可能達到數百TB 甚至PB級別對于傳統的資料庫Oracle、MySQL 當單表的數量達到一定值后,系能問題逐漸出現瓶頸,很多企業為了解決這個問題,對資料庫進行分庫分表的操作,通過應用邏輯的調整以及路由中間件的使用來解決這個問題,但是這種操作必然給資料庫維護團隊以及應用開發團隊帶來巨大的作業量,此時分布式資料庫的使用就很好的契合了這個場景,
本文分析阿里云的OceanBase和PingCAP TiDB兩款分布式資料庫,主要從產品架構、資料分片原理、資料同步原理、MVCC多版本并發控制、相關底層的演算法分析的層面淺談兩款資料庫的特點,
| Ocean Base | TiDB | |
| 最小磁區單位 | Partion | Region |
| 磁區原理 | 自定義鍵值 | Hash+Range |
| 資料同步協議 | Paxos | Raft |
| MVCC | 索引結構+行操作鏈 | Key_version,Value |
| 存盤引擎 | LSM_Tree(存盤演算法) | RocksDB |
產品架構
Ocean Base:
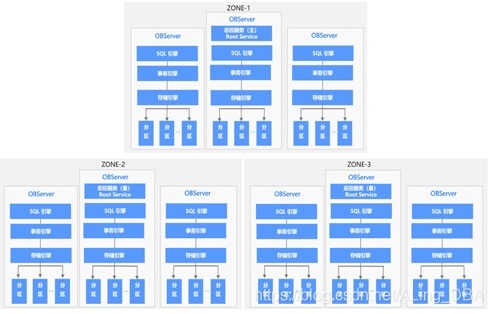
架構圖可知的內容:
- OB的資料高可用通過多Zone來實作(也可以Region),每個Zone保存著完成的資料副本;
- 同步的最小單位為磁區也叫做partion;
- 每個Zone下面對應的主機上都部署著Observer、SQL引擎、事物引擎、存盤引擎等
作業機制說明:
每個Zone上面存在兩個主要服務,一是總控服務,二是磁區服務
1. 總控服務:RootService
其中每個Zone 上都會存在一個總控服務,運行在某一個OBServer 上,整個集群中只存在一個主總控服務,其他的總控服務作為主總控服務的備用服務運行,總控服務負責整個集群的資源調度、資源分配、資料分布資訊管理以及Schema 管理等功能,
2. 磁區服務:PartitionService
用于負責每個OBServer 上各個磁區的管理和操作功能的模塊,這個模塊與事務引擎、存盤引擎存在很多呼叫關系,
TiDB:
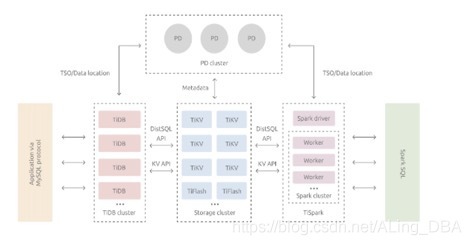
說句實話,咱真的沒看懂tiDB的架構圖,官網描述與圖片對不上,可能是我沒有理解,不過不影響我們對他的了解,資料庫跑不了三層架構,我們只需要知道核心組件的功能,
- TiDB Cluster: 客戶端的連接、SQL的決議到產生分布式執行計劃
- PD(Placement Driver) Server: 元資料管理、負責資料的分布、分布式事物的管理
- 存盤節點:負責資料的存盤、采用Key-Value的分布式存盤引擎,根據資料分布原則將資料分布在不通的region中,region是TiDB資料同步的最小單位,這里region和阿里云的region是不同的概念,
資料分片原理
對于分布式資料庫分片常見的幾種方案 List、Hash、Range或者按照tablet的大小超過就自動磁區
Ocean Base:
和傳統的Mysql以及Oracle的Partition功能類似,用戶建表的時候指定使用哪些欄位進行磁區,OB的負載均衡可以把不同磁區的主打散到多臺機器上(這里后續會研究底層的負載均衡原理);
TiDB:
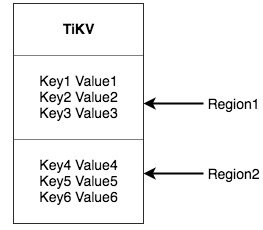
TiDB的資料磁區采用的Hash+Range的方式,將一段連續的 Key 都保存在一個存盤節點上,官方把這個節點叫做region
資料同步原理
Ocean Base
通過Paxos協議進行日志同步,每個磁區和他的副本構成一個獨立的paxos復制組,針對副本的寫的請求,都會自動路由到對應的主磁區上,對于不通副本寫的操作會很分布到不同的資料節點上,從而實作資料的多點寫入,提高性能,
TiDB:
通過Raft協議進行日志復制,每個資料變更都會產生一條Raft 日志,通過Raft 的日志復制功能,將資料安全可靠地同步到復制組的每一個節點中,實際寫入中,根據Raft 的協議,只需要同步復制到多數節點,即可安全地認為資料寫入成功,
后面會簡單介紹Paxos和Raft協議
多版本并發控制
對于傳統資料庫Oracle以及MySQL的多版本并發控制更多的是通過內部鎖機制實作多版本的控制,但對于資料上鎖,在分布式系統中可能會帶來嚴重的性能問題,對于TiDB和OB總體原則都是通過保留舊版本的資料來實作MVCC
Ocean Base:
OB的內部包含兩個部分:索引結構及行操作鏈,其中,索引結構存盤行頭資訊,采用記憶體B樹實作;行操作鏈表中存盤了不同版本的修改操作,索引結構記錄了事物的相關資訊,通過事物+多版本資料從而MVCC機制;
TiDB:
TiDB資料庫采用的Key-Value的方式進行資料的存盤,在并發下必然就會存在多個會話同時通過一個Key去修改資料的場景,TiDB通過控制Key的版本來解決MVCC的問題,如下;
傳統的Key-Value
Key1 -> Value
Key2 -> Value
……
KeyN -> Value
有了MVCC機制后,TiDB的Key如下圖
Key1_Version3 -> ValueKey1_Version2 -> ValueKey1_Version1 -> Value……Key2_Version4 -> ValueKey2_Version3 -> ValueKey2_Version2 -> Value
key是一個有序的排列,從大到小,當用戶通過一個Key + Version 來獲取Value 的時候,可以通過Key 和Version 構造出多版本的Key
關鍵演算法介紹
Paxos:
由技術大師Lamport在1990年提出的一種基于訊息傳遞的一致性演算法,這個演算法在過去10于年里面基本成為分布式領域內一致性協議的代名詞,最終實作的結果就是讓少數服從多數的方式,最后達成一致的建議......太深了 還在研究中;
Raft:
也是分布式一致性的協議,這個協議中提供幾個重要的特點 Leader 選舉、成員變更、日志復制 ;這里簡單說一下日志復制的程序:
首先整個集群中存在一個主節點,每次資料的變更都會被記錄到組節點的日志中,此時日志的狀態是未提交的,然后主節點會將這個日志分發到各個Follower節點,直到多數的Follwer節點應用了這個日志才會通知主節點,最后主節點完成commit操作,
LSM_Tree :
起源于谷歌1996年的 一篇論文The Log-Structured MergeTree(LSM_Tree) 專門為key-value存盤系統設計的,最大的特點就是利用了磁盤的順序寫,避免隨機寫入多層次的樹;C0層是在記憶體里面,保留最近寫入的(k,v) ,是有序的 ,剩下的c1 到ck層都是在磁盤上的.
寫入的操作: 一個put的寫入的操作,首先追加到當前日志(Write Ahead Log) 依然遵從日志先寫的的原則,接下來是C0層,單c0層的資料達到一定大小后,幾把c0和c1層合并,類似遞回的排序,這個程序叫做compaction,合并出來新的c1會順序的寫入磁盤,然后替換到原來的c1,c1達到一定的大小之后會和下層合并然后洗掉之前的老的,
讀取的操作:在寫入的流程中可以看到,最新的資料在c0層,最小的資料在ck層,所以查詢會先查c0層,如果沒有在查詢c1層,逐層往下.
參考文獻:
https://docs.pingcap.com/zh/tidb/v4.0/overview
https://help.aliyun.com/document_detail/134480.html?spm=a2c4g.11174283.6.543.679c2f011VlFfx
https://blog.csdn.net/u010454030/article/details/90414063
https://www.baidu.com/link?url=sKf4Qw66RCv1EP5rZcxeaa5jjZro7JlIxJc8Jx55yIAeWh6vGZfJOUusmM_yvP5k&wd=&eqid=e3a24ae10007fd610000000460bb1e56
https://xie.infoq.cn/article/c98432267e7b7038718d199e1
https://blog.csdn.net/weixin_40581617/article/details/80496594
https://www.zhihu.com/question/19787937
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/286556.html
標籤:其他