RDD編程初級實踐
一、資料來源描述
pyspark互動式編程
科任老師提供分析資料data.txt,該資料集包含了某大學計算機系的成績,資料格式如下所示:
Tom,DataBase,80
Tom,Algorithm,50
Tom,DataStructure,60
Jim,DataBase,90
Jim,Algorithm,60
Jim,DataStructure,80
……
撰寫獨立應用程式實作資料去重
對于兩個輸入檔案A和B,撰寫Spark獨立應用程式,對兩個檔案進行合并,并剔除其中重復的內容,得到一個新檔案C,本文給出門課的成績(A.txt、B.txt)下面是輸入檔案和輸出檔案的一個樣例,供參考,
輸入檔案A的樣例如下:
20200101 x
20200102 y
20200103 x
20200104 y
20200105 z
20200106 z
輸入檔案B的樣例如下:
20200101 y
20200102 y
20200103 x
20200104 z
20200105 y
根據輸入的檔案A和B合并得到的輸出檔案C的樣例如下:
20200101 x
20200101 y
20200102 y
20200103 x
20200104 y
20200104 z
20200105 y
20200105 z
20200106 z
撰寫獨立應用程式實作求平均值問題
每個輸入檔案表示班級學生某個學科的成績,每行內容由兩個欄位組成,第一個是學生名字,第二個是學生的成績;撰寫Spark獨立應用程式求出所有學生的平均成績,并輸出到一個新檔案中,本文給出門課的成績(Algorithm.txt、Database.txt、Python.txt),下面是輸入檔案和輸出檔案的一個樣例,供參考,
Algorithm成績:
小明 92
小紅 87
小新 82
小麗 90
Database成績:
小明 95
小紅 81
小新 89
小麗 85
Python成績:
小明 82
小紅 83
小新 94
小麗 91
平均成績如下:
(小紅,83.67)
(小新,88.33)
(小明,89.67)
(小麗,88.67)
二、資料上傳及上傳結果查看
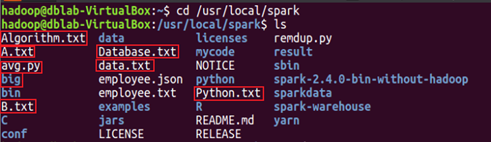
圖2.1 將所需的資料放進/usr/local/spark檔案中
pyspark互動式編程

圖2.2 查看data.txt中的資料
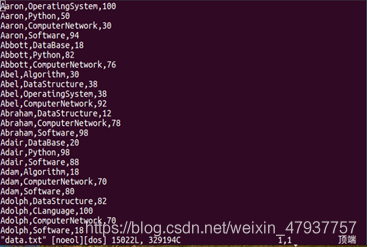
圖2.3 data.txt中的資料
撰寫獨立應用程式實作資料去重

圖2.4 將所需的資料放進/usr/local/spark/big
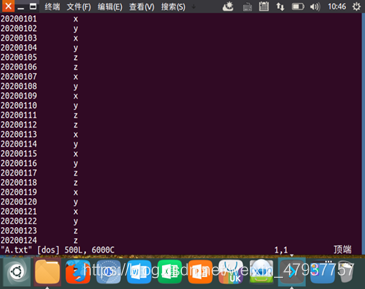
圖2.5 查看A.txt的資料
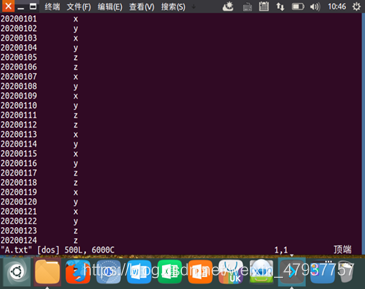
圖2.6 查看B.txt的資料
撰寫獨立應用程式實作求平均值問題

圖2.7 查看相關資料
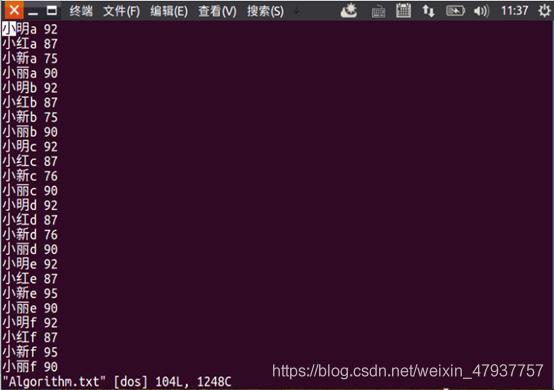
圖2.8 查看Algorithm.txt的資料
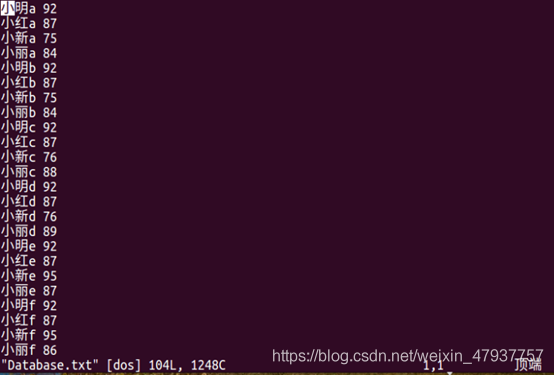
圖2.9 查看Database.txt的資料
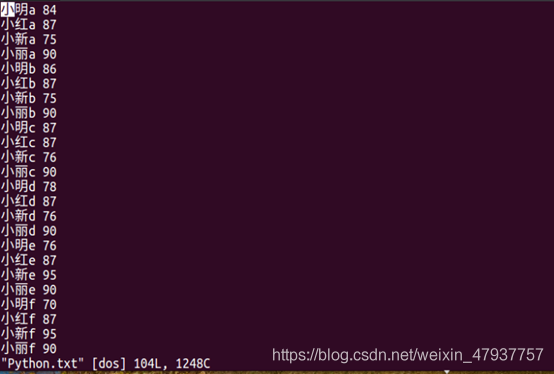
圖2.10 查看Python.txt的資料
三、資料處理程序描述
pyspark互動式編程
使用lines儲存讀取data.txt檔案里的內容
lines=sc.textFile(‘file:///usr/local/spark/data.txt’)
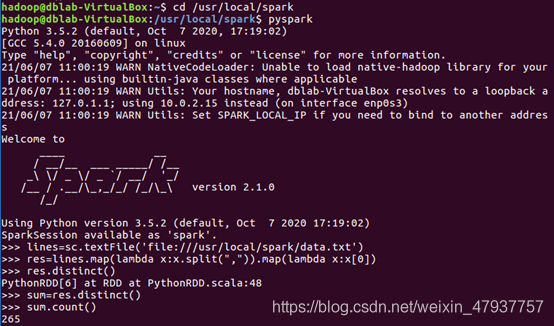
(1) 該系總共有多少學生;
lines存盤的是Row object型別
map()接收函式,把函式應用到RDD的每一個元素,回傳新的RDD
首先提取第一列的資料,第一列的資料是學生的姓名,通過累加和去重可以算出總人數
res = lines.map(lambda x:x.split(“,”)).map(lambda x:x[0])
使用spark的distinct進行去重
res.distinct()
用sum存盤去重后的資料
sum =res.distinct()
顯示sum數值,count():計數
sum.count()
(2) 該系共開設了多少門課程;
lines存盤的是Row object型別
map()接收函式,把函式應用到RDD的每一個元素,回傳新的RDD
提取第二列的資料,第二列的資料是科目,通過累加和去重可以算出科目的總數
res = lines.map(lambda x:x.split(“,”)).map(lambda x:x[1])
用dis_res存去重后的資料
dis_res =res.distinct()
顯示dis_res數值,count():計數
dis_res.count()

(3) Tom同學的總成績平均分是多少;
lines存盤的是Row object型別
map()接收函式,把函式應用到RDD的每一個元素,回傳新的RDD
filter()接收函式,回傳只包含滿足filter()函式的元素的新RDD
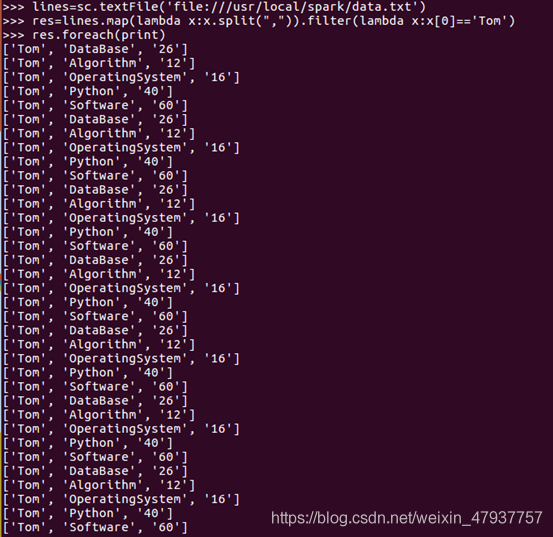
篩選出第一列的資料,對RDD中的元素進行過濾選擇名為Tom的列,回傳形成新的RDD,
res = lines.map(lambda x:x.split(“,”)).filter(lambda x:x[] == ’Tom’)
使用foreach算子顯示資料
res.foreach(print)
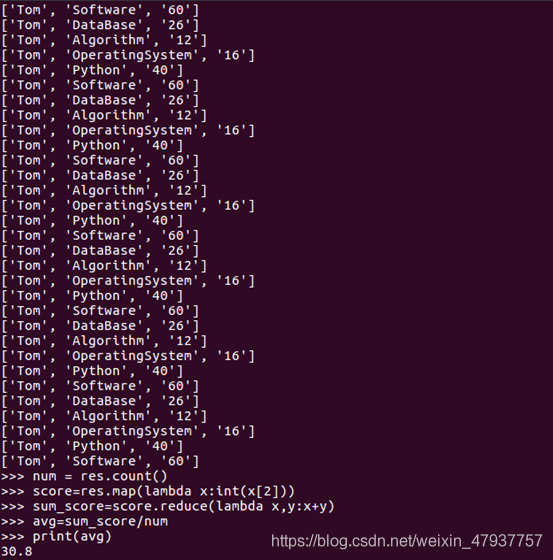
num保存Tom同學的學科總數
num=res.count()
提取各科成績
score = rep.map(lambda x:int(x[2]))
各科成績相加
sum_score = score.reduce(lambda x,y:x+y)
avg存盤總成績除以科目數的數值
avg = sum_score/num
顯示平均分數值
print(avg)
(4) 求每名同學的選修的課程門數;
lines存盤的是Row object型別
map()接收函式,把函式應用到RDD的每一個元素,回傳新的RDD
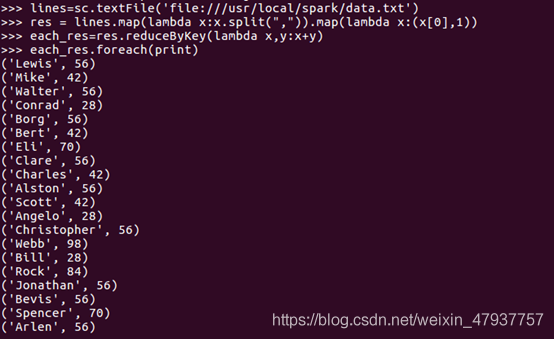
提取出第二列的資料,并對第一列相同的資料進行累加,算出每位同學所選的選修課門數,
res = lines.map(lambda x:x.split(“,”)).map(lambda x:(x[0],1))
對相同key的資料進行處理,最終每個key只保留一條記錄,
each_res=res.reduceByKey(lambda x,y:x+y)
使用foreach算子顯示資料
each_res.foreach(print)
(5) 該系DataBase課程共有多少人選修;
lines存盤的是Row object型別
map()接收函式,把函式應用到RDD的每一個元素,回傳新的RDD
filter()接收函式,回傳只包含滿足filter()函式的元素的新RDD
篩選出第二列的資料,是對RDD中的元素進行過濾選擇名為DataBase的列,回傳形成新的RDD,
res = lines.map(lambda x:x.split(“,”)).filter(lambda x:x[1] == ’DataBase’)
顯示res數值
res.count()

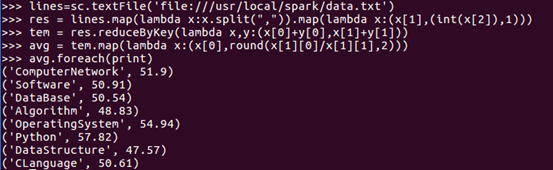
(6) 各門課程的平均分是多少;
lines存盤的是Row object型別
map()接收函式,把函式應用到RDD的每一個元素,回傳新的RDD
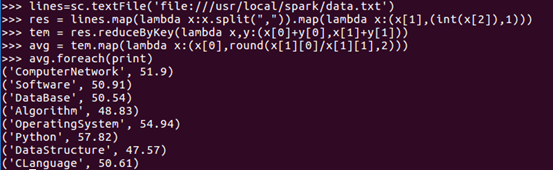
篩選出第二列和第三列的資料,并對資料進行過濾,累加,算出相關的資料之和,再進行平均分的算數,
res = lines.map(lambda x:x.split(“,”)).map(lambda x:(x[1],(int(x[2])),1))
對相同key的資料進行處理,最終每個key只保留一條記錄,tem儲存每科對應人數與每科總分
tem = res.reducByKey(ambda x,y(x[0]+y[0],x[1]+y[1]))
把資料以rdd的形式計算出每科平均分
avg = tem.map(lambda x(x[0],round(x[1][0]/x[1][1],2)))
使用foreach算子顯示資料
avg.foreach(print)
(7) 使用累加器計算共有多少人選了DataBase這門課,
lines存盤的是Row object型別
map()接收函式,把函式應用到RDD的每一個元素,回傳新的RDD
filter()接收函式,回傳只包含滿足filter()函式的元素的新RDD
提取出第二列的資料,并對資料進行過濾,是對RDD中的元素進行過濾選擇名為DataBase的列,回傳形成新的RDD,
res = lines.map(lambda x:x.split(“,”)).filter(lambda x:x[1]==’DataBase’)
使用累加器
accum=sc.accumulator()
在foreach算子里使用累加器計算
res.foreach(lambda x:accum.add(1))
顯示累加資料
accum.value
撰寫獨立應用程式實作資料去重
進入cd/usr/local/spark/big查看相關檔案是否存在
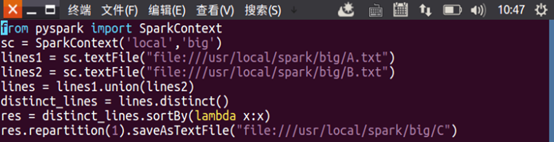
輸入vim A.txt和vim B.txt,查看相關資料是否存在,再接著輸入vim remdup.py,創建remdup.py檔案,再接著對py檔案進行編輯,
sc.textFile()讀取本地檔案,括號內輸入檔案的路徑;
union()兩個資料的并集
lines = lines1.union(lines2)
distinct()對相關資料進行去重,去重后將相關資料存到distinct_lines
distinct_lines=lines.distinct()
repartition(1)重新建立一個磁區,并將生成的檔案保存到C
res.repartition(1).saveAsTextFile(“file:///usr/local/spark/big/C”)
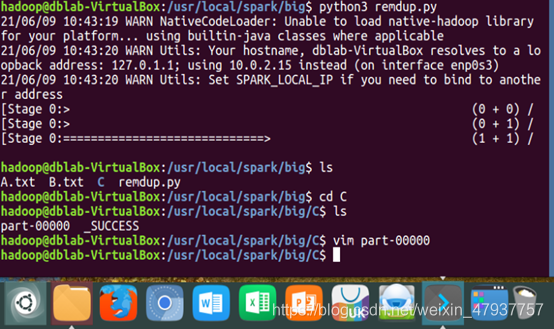
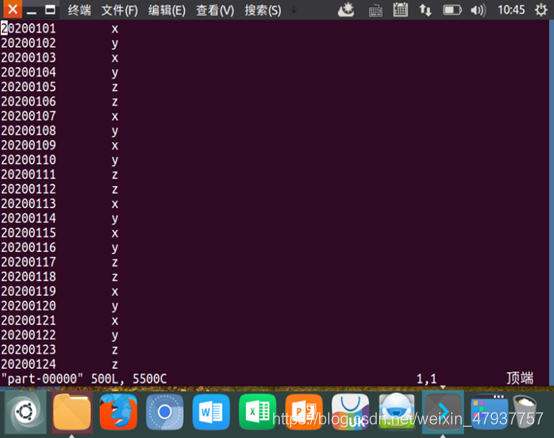
編輯完成后輸入:wq!保存退出后再輸入python3 remdup.py運行檔案,運行完成后,輸入命令:ls,查看是否生成C檔案夾;進入C檔案夾,再輸入命令:ls,查看結果是否生成,輸入命令:vim part-00000,查看資料是否進行合并,并進行去重,
撰寫獨立應用程式實作求平均值問題
輸入cd /usr/local/spark進入目錄,輸入命令:vim avg.py,創立py檔案,并對檔案進行編輯,

SortBy()按照處理后的資料比較結果排序,默認為正序,
reduceByKey()把RDD中的key相同的一組資料拿出來處理,形成一個新的RDD里面放的是元組
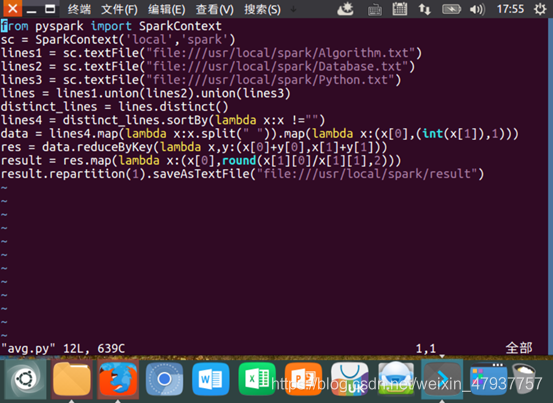
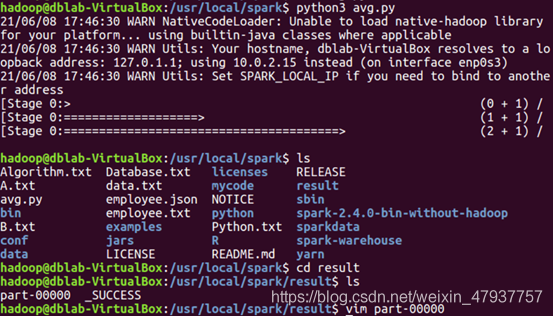
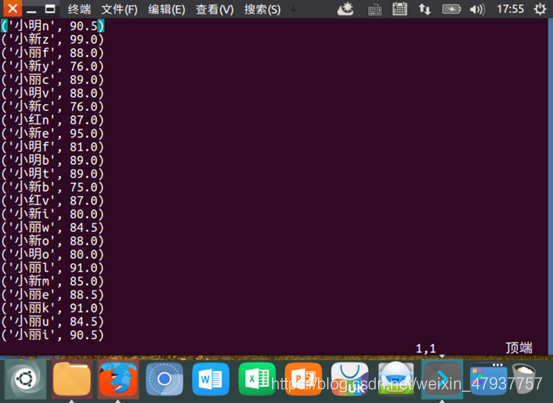
撰寫完成后,輸入wq!保存并退出,輸入命令:ls,查看是否生成result檔案夾;輸入命令:cd result,進入result檔案夾;輸入命令:ls,查看資料是否生成;輸入命令:vim part-00000,查看資料是否生成,
在Spark中,不同的RDD之間具有依賴的關系,RDD與它所依賴的RDD的依賴關系有兩種型別,分別是窄依賴(narrow dependency)和寬依賴(wide dependency),當RDD執行map、filter及union和join操作時,都會產生窄依賴,RDD做map、filter和union算子操作時,是屬于窄依賴的第一類表現;而RDD做join算子操作(對輸入進行協同劃分)時,是屬于窄依賴表現的第二類,當RDD做groupByKey和join操作時,會產生寬依賴,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/286560.html
標籤:其他
上一篇:再次學習vue的識訓(基礎篇)