目錄
文章目錄
- 目錄
- USE 分析法
- 60s USE 檢查分析法
- OS Error
- 1、dmesg | tail — 檢查作業系統的明顯錯誤
- CPU 負載
- 2、uptime — 檢查 CPU 負載平均值趨勢
- 3、vmstat 1 — 檢查虛擬記憶體、CPU 的狀態情況
- 4、mpstat -P ALL 1 — 檢查系統所有 CPU 的負載情況
- 5、pidstat 1 — 檢查行程的 CPU 資源占用情況
- 磁盤 I/O 負載
- 6、iostat -xz 1 — 檢查磁盤的 I/O 負載情況
- 記憶體負載
- 7、free -m — 檢查磁盤、記憶體的用量情況
- 網路 I/O 負載
- 8、sar -n DEV 1 — 檢查網路介面的吞吐量狀態
- 9、sar -n TCP,ETCP 1 — 檢查 TCP 協議的流量情況
USE 分析法
該方法的核心是對于所有的資源,查看它的使用率、飽和度和錯誤,這里的 “資源” 指:服務器所有的物理元器件(e.g. CPU、總線、…),某些軟體資源也能算在內,
- Utilization(資源使用率):指在規定的時間間隔內,某個資源(e.g. CPU、記憶體、磁盤)用于服務作業的時間百分比,
- Satuation(資源飽和度):指某個資源(e.g. CPU、記憶體、磁盤)的負載超過了它所能夠處理的能力,資源不能再服務更多額外作業的程度,通常的,此時可以觀察到有等待佇列開始堆積,或者請求等待的時間變長,
- Error(錯誤):指作業系統及應用程式層面的明顯錯誤,
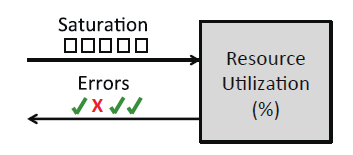
USE 分析法會將分析引導到一定數量的關鍵指標上,這樣可以盡快地核實所有的系統資源,實操步驟如下:
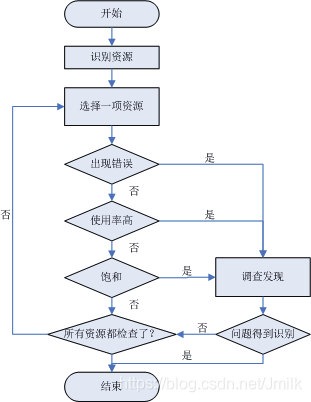
可見,USE 法的第一步是要建一張資源串列,要盡可能完整,例如:
- CPU:Socket、Core、Thread,
- 記憶體:DRAM,
- 網路介面:以太網埠,
- 存盤設備:磁盤,
- 控制器:存盤、網路,
- 互聯:CPU、記憶體、IO,
一旦掌握了資源的串列,就可以開始采集資源的 USE 指標了,例如:
- CPU 使用率:vmstat 1
- CPU 飽和度:vmstat 1,運行佇列長度 ,
- 記憶體使用率:free -m,
- 記憶體飽和度:free -m,匿名換頁、或者執行緒換出、再或者 OOM,
- 存盤使用率:iostat –d –x 1,
- 存盤飽和度:iostat –d –x 1,等待佇列長度,
- 存盤設備 IO:dmesg smartctl,
- 網路介面使用率:sar –n DEV 1,
60s USE 檢查分析法

OS Error
1、dmesg | tail — 檢查作業系統的明顯錯誤
顯示了最新的幾條系統日志,如果系統出現了明顯錯誤,那么輸出的日志中應該可以一目了然,
$ dmesg | tail
[690774.079619] docker0: port 2(vethf7f1560) entered disabled state
[690774.080647] veth588fe58: renamed from eth0
[690774.119506] docker0: port 2(vethf7f1560) entered disabled state
[690774.121148] device vethf7f1560 left promiscuous mode
[690774.121151] docker0: port 2(vethf7f1560) entered disabled state
[701940.158358] docker0: port 1(veth95cae04) entered disabled state
[701940.159054] vetha2fb6e0: renamed from eth0
[701940.222239] docker0: port 1(veth95cae04) entered disabled state
[701940.223930] device veth95cae04 left promiscuous mode
[701940.223933] docker0: port 1(veth95cae04) entered disabled state
CPU 負載
2、uptime — 檢查 CPU 負載平均值趨勢
所謂 Load Average(平均負載),指示的是有多少任務在等待運行,包含了想要或者正在使用 CPU 的任務,以及在 I/O 上被阻塞的任務,這個命令能使我們對系統的全域狀態有一個大致的了解,
$ uptime
23:51:26 up 21:31, 1 user, load average: 30.02, 26.43, 19.02
上述 3 個值分別是 1 分鐘、5 分鐘、15 分鐘時間段內的負載平均值,根據這 3 個值,我們可以了解到 Linux 負載隨時間的變化,例如:假設你從中發現 1 分鐘的負載平均值比 15 分鐘的值要小很多,那么你很有可能已經錯過了系統出問題的時間點,
上述例子中,1 分鐘的負載平均值為 30,比 15 分鐘的 19 增長較多,也就是說系統目前的情況比較糟糕,也許是 CPU 不夠用了,需要繼續排查定位問題,
3、vmstat 1 — 檢查虛擬記憶體、CPU 的狀態情況
$ vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
5 0 0 6208768 201332 5887580 0 0 0 1 2 1 50 0 49 1 0
4 0 0 6208784 201332 5887616 0 0 0 0 1083 122 50 0 50 0 0
4 0 0 6208816 201332 5887616 0 0 0 0 1059 117 50 0 50 0 0
...
需要關注的指標:
-
r:處在 runnable 狀態的任務,包括正在運行的任務和等待運行的任務,這個值比 uptime 的 Load Average 更能看出 CPU 是否飽和,但不包含等待 I/O 相關的任務,當 r 的值比當前 CPU 數量還要大的時候,系統就處于飽和狀態了,
-
free:以 KB 計算的空閑記憶體大小,
-
si,so:換入換出的記憶體頁,如果這兩個值非零,表示記憶體不夠了,正在使用 Swap 交換空間,
-
us(用戶態時間),sy(內核態時間),id(空閑時間),wa(等待 I/O 時間),st(偷取時間,在虛擬化環境下系統在其它租戶上的開銷):CPU 時間的各項指標(對所有 CPU 取均值),分別表示:
- 可以通過 us + sy 來確認 CPU 是否繁忙,如果 us 高的話,表示應用程式在使用 CPU;如果 sy 高的話,需要進一步分析,也許是系統處理 I/O 的效率低,
- wa 和 id 高的話表示 CPU 空閑了,此時磁盤可能是瓶頸,
4、mpstat -P ALL 1 — 檢查系統所有 CPU 的負載情況
這個命令會把每個 CPU 的執行時間都列印出來,可以看看 CPU 負載是否均衡,如果某一單個 CPU 使用率很高的話,說明正運行著一個單執行緒應用,
$ mpstat -P ALL 1
Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU)
07:38:49 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
07:38:50 PM all 98.47 0.00 0.75 0.00 0.00 0.00 0.00 0.00 0.00 0.78
07:38:50 PM 0 96.04 0.00 2.97 0.00 0.00 0.00 0.00 0.00 0.00 0.99
07:38:50 PM 1 97.00 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 2.00
07:38:50 PM 2 98.00 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 1.00
07:38:50 PM 3 96.97 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 3.03
[...]
5、pidstat 1 — 檢查行程的 CPU 資源占用情況
這個命令用于持續地查看行程的行為模式,可以方便地記錄隨著時間的變化,各個行程運行狀況的變化,
其中,%CPU 表示的是所有 CPU 的總值,例如:1591% 表示某個行程幾乎消耗了 16 個 CPU,
$ pidstat 1
Linux 4.15.0-143-generic (vpp-1) 06/08/21 _x86_64_ (4 CPU)
16:28:59 UID PID %usr %system %guest %wait %CPU CPU Command
16:29:00 0 2557 0.99 0.00 0.00 0.00 0.99 0 dockerd
16:29:00 0 22607 0.00 0.99 0.00 0.00 0.99 1 pidstat
16:29:00 UID PID %usr %system %guest %wait %CPU CPU Command
16:29:01 UID PID %usr %system %guest %wait %CPU CPU Command
16:29:02 0 22607 0.00 1.00 0.00 0.00 1.00 1 pidstat
磁盤 I/O 負載
6、iostat -xz 1 — 檢查磁盤的 I/O 負載情況
$ iostat -xz 1
Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 x86_64 (32 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
73.96 0.00 3.73 0.03 0.06 22.21
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
xvda 0.00 0.23 0.21 0.18 4.52 2.08 34.37 0.00 9.98 13.80 5.42 2.44 0.09
xvdb 0.01 0.00 1.02 8.94 127.97 598.53 145.79 0.00 0.43 1.78 0.28 0.25 0.25
xvdc 0.01 0.00 1.02 8.86 127.79 595.94 146.50 0.00 0.45 1.82 0.30 0.27 0.26
dm-0 0.00 0.00 0.69 2.32 10.47 31.69 28.01 0.01 3.23 0.71 3.98 0.13 0.04
dm-1 0.00 0.00 0.00 0.94 0.01 3.78 8.00 0.33 345.84 0.04 346.81 0.01 0.00
dm-2 0.00 0.00 0.09 0.07 1.35 0.36 22.50 0.00 2.55 0.23 5.62 1.78 0.03
...
iostat 是理解塊設備(磁盤)的當前負載和性能的重要工具,幾個指標的含義:
- r/s,w/s,rkB/s,wkB/s:磁盤的讀速率,寫速率,讀資料量、寫資料量,這幾個指標反映了磁盤的作業負載,系統的性能問題很有可能就是磁盤負載太大,
- await:磁盤 I/O 的平均回應時間,包括請求排隊的時間,以及請求處理的時間,如果超過了經驗值的平均回應時間,則表明磁盤負載處于飽和狀態,或者磁盤有問題,
- avgqu-sz:磁盤請求佇列的平均長度,佇列長度大于 1 時,則表示磁盤處于飽和狀態,
- %util:磁盤的利用率,磁盤每秒處理 I/O 的時間占比,表示磁盤繁忙的程度,大于 60% 的利用率通常會導致性能問題(可以通過 await 看到),
注意,每種磁盤也會有有所不同,如果這個磁盤是一個邏輯塊設備,這個邏輯快設備后面有很多物理磁盤的話,100% 利用率只能表明有些 I/O 的處理時間達到了 100%;后端的物理磁盤可能遠遠沒有達到飽和狀態,可以處理更多的負載,
還有一點需要注意的是,較差的磁盤 I/O 性能并不一定意味著會導致應用程式出現性能問題,應用程式可以有許多方法執行異步 I/O,而不會阻塞在 I/O 上面;應用程式也可以使用諸如預讀取,寫緩沖等技術降低 I/O 延遲對自身的影響,
記憶體負載
7、free -m — 檢查磁盤、記憶體的用量情況
$ free -m
total used free shared buffers cached
Mem: 245998 24545 221453 83 59 541
-/+ buffers/cache: 23944 222053
Swap: 0 0 0
Linux 會把暫時用不上的記憶體用作快取,一旦應用需要的時候就立刻重新分配給它,
- buffers:用于磁盤 I/O 的緩沖區快取,
- cached:用于檔案系統的頁面快取,
- -/+ buffers/cache:更準確的記憶體使用量,
注意,ZFS 有自己的檔案系統快取,在 free -m 里面是看不到的,雖然系統看起來空閑記憶體不多了,但是有可能 ZFS 有很多的快取可用,
網路 I/O 負載
8、sar -n DEV 1 — 檢查網路介面的吞吐量狀態
$ sar -n DEV 1
Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU)
12:16:48 AM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
12:16:49 AM eth0 18763.00 5032.00 20686.42 478.30 0.00 0.00 0.00 0.00
12:16:49 AM lo 14.00 14.00 1.36 1.36 0.00 0.00 0.00 0.00
12:16:49 AM docker0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
12:16:49 AM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
12:16:50 AM eth0 19763.00 5101.00 21999.10 482.56 0.00 0.00 0.00 0.00
12:16:50 AM lo 20.00 20.00 3.25 3.25 0.00 0.00 0.00 0.00
12:16:50 AM docker0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
- rxkB/s,txkB/s:用于查看網路介面的 I/O 負載,也可以看見是否達到了網路流量的限制,例如:上述 eth0 的吞吐量達到了大約 22 Mbytes/s,差不多 176 Mbits/sec ,比 1 Gbit/sec 還要少很多,
- %ifutil:標識網卡的利用率,
9、sar -n TCP,ETCP 1 — 檢查 TCP 協議的流量情況
$ sar -n TCP,ETCP 1
Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU)
12:17:19 AM active/s passive/s iseg/s oseg/s
12:17:20 AM 1.00 0.00 10233.00 18846.00
12:17:19 AM atmptf/s estres/s retrans/s isegerr/s orsts/s
12:17:20 AM 0.00 0.00 0.00 0.00 0.00
12:17:20 AM active/s passive/s iseg/s oseg/s
12:17:21 AM 1.00 0.00 8359.00 6039.00
12:17:20 AM atmptf/s estres/s retrans/s isegerr/s orsts/s
12:17:21 AM 0.00 0.00 0.00 0.00 0.00
這是對 TCP 重要指標的一些概括,包括:
- active/s:每秒鐘本地主動開啟的 TCP 連接,通常為出主機的連接,也就是本地程式使用 connect() 系統呼叫,
- passive/s:每秒鐘從源端發起的 TCP 連接,通常為入主機的連接,也就是本地程式使用 accept() 所接受的連接,
- retrans/s:每秒鐘的 TCP 重傳次數,也許是網路不穩定,也許是服務器網卡負載過重開始丟包了,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/286731.html
標籤:其他