Removing the Background by Adding the Background: Towards Background Robust Self-supervised Video Representation Learning
【知乎的一篇介紹,寫的很詳細】
【代碼、論文】
- 概述:
CVPR2021的文章,也是自監督學習中pretext task的設計,其中的思考很值得咀嚼吸收,
通篇提到的background,應該既有背景的意思,也有場景的意思 - 上面的知乎鏈接介紹了
文章的動機:
【知乎原文】… 如果一個模型過多關注空間資訊,則很容易產生誤判 【比如只關注一幀影像】
Background是雙刃劍,過多或者過少關注都不好~
目前常用的資料集中含有大量類別其動作語意和物體及場景強相關,比如通過是否看到吉他來判斷是否為“彈吉他”動作,通過是否看到足球場地來判斷是否為 "踢足球"動作,這種運動類別和靜態物體以及靜態場景強相關的現象稱之為 Implicit Bias …
【下面是我的轉述】
在上述的資料集訓練 CNN 的時候,那些跟【場景/背景、物體】關聯性很高的類別(踢足球、彈吉他)就有比較好的分類效果,比較新奇或者要依靠時序資訊才能分辨的類別,就難整了;
針對這個問題,傳統的雙流法 (rgb + flow)有幫助,因為RGB流、Flow流本身就較好地利用了 spatial 和 temporal 資訊,但現在主流方法更多的使用 end-to-end 的3D網路,網路很容易陷入到 implict bias 中,
一、神奇的想法:通過添加background來去掉background
小標題可能不好理解,但其實就是上面提到的“文章的動機”:Background是雙刃劍,過多或者過少關注都不好,那我在視頻資料中加一些圖片背景多樣而相似的視頻(給圖片背景加噪),網路的泛化性就會更好,
作者提到用GAN、VAE去生成背景相似的圖片,我理解應該是當作/替換視頻幀去訓練,但太復雜了,轉而想到我給背景加噪,別的幀也完全能當作噪聲,比如當前視頻幀的像素分布可以認為是IID的,那么+上某幀生成的視頻就會有background perturbation,但motion規律基本不會變(對時間微分不會變)
BE:Background Erasing的公式就應運而生了,即第j幀圖片加spatial background noise作為新生成的視頻幀,自然有選擇這個noise的方法,在知乎上有比較,最終用的是當前視頻的某一幀
x
d
=
(
1
?
λ
)
?
x
(
j
)
+
λ
?
δ
,
j
∈
[
1
,
T
]
x^d = (1-\lambda)\cdot x^{(j)} + \lambda \cdot \delta,\ \ \ j\in [1,T]
xd=(1?λ)?x(j)+λ?δ, j∈[1,T]
看完應該就能回答這幾個問題:
- 視頻的背景在動作識別中有什么幫助?為什么要去掉視頻的背景?
- 怎么樣去除掉視頻的背景?
- 為什么這樣的想法叫
remove the background by adding the background?
我是理解成 remove the negative impact of background by adding the background noise
二、結合自監督學習、對比學習

1.網路的訓練思路就是上圖的拉近加噪、不加噪的視頻特征之間的距離,這樣確實會少些空間方面的資訊,但預訓練模型之后再到資料集微調,空間資訊就能找回來一些
2.文章的思路融合到自監督學習、對比學習中,我理解則是:
(1)自監督學習的loss,既有判斷是否對樣本進行了上述add background的操作的交叉熵loss,也有1中說的特征之間的L2 loss
(2)結合對比學習,則是從視頻樣本中抽取了正樣本、負樣本(相似樣本、不相似樣本),相應的增大、減小特征的相似度,用的是InfoNCE loss,名字唬人,公式不復雜,然后抽取負樣本,既能選擇別的視頻,也能從當前的視頻中選擇不同的clip,
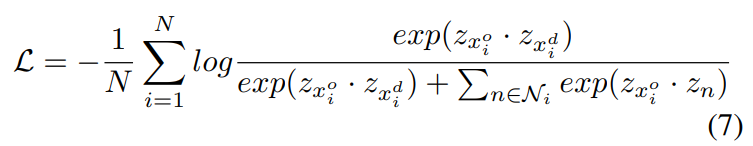
三、實驗、分析
論文在后面還有詳盡的分析自己的網路到底學到了什么,這里不贅述了,但確實干貨多
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/286852.html
標籤:其他
下一篇:unity學習筆記-特效篇