Scala基礎(三) 模式匹配、樣例類與Actor編程
- 模式匹配
- 內容匹配
- 資料型別匹配
- 陣列與集合匹配
- 宣告變數時匹配
- 樣例類
- 補充
- apply方法
- unapply方法
- Option型別
- 偏函式Partial Function
- 正則
- Scala例外處理
- 泛型
- Scala Actor并發編程
- 準備作業
- 并發編程對比
- Java的并發編程
- Scala的并發編程
- 簡單使用
- 死回圈收發訊息
- React收發訊息
- Actor的3種訊息發送方式
- Actor并發WordCount
Scala語法
Scala函式式編程與面向物件編程
模式匹配
之前有寫過Scala中也可以模擬出Java和C#的switch/case功能,
內容匹配
package com.aa.matchDEMO
import scala.io.StdIn
object MatchCase1 {
def main(args: Array[String]): Unit = {
//從控制臺stdin(標準輸入)接收用戶輸入的內容,根據內容進行模式匹配
val result: String = StdIn.readLine() // 死等,這是阻塞方法
result match {
case "hadoop" => println("hadoop>>>")
case "spark" => println("spark>>>")
case "flink" => println("flink>>>")
case _=>println("*********hehe*********")
}
}
}
多運行幾次:
flink
flink>>>
hadoop
hadoop>>>
哈哈
*********hehe*********
spark
spark>>>
Process finished with exit code 0
資料型別匹配
package com.aa.matchDEMO
import scala.util.Random
object MatchCase2 {
def main(args: Array[String]): Unit = {
val array = Array(11, 22, "hello", "bye", true, false, 3.14, 6.33)
val result: Any = array(Random.nextInt(array.length)) //隨機抽取陣列元素
result match {
//case x: Int => println(x)
case x: Int if x > 15 => println(x) //匹配時+守衛條件,提前過濾
case y: String => println(y)
case z: Double => println(z)
case w: Boolean => println(w)
case _ => println("-----呵呵-----") //不滿足上方的任一條件就會落入這里,相當于default
}
}
}
隨機獲取元素并進行型別匹配,使用守衛條件在隨機到11時會落入最后的_中,
陣列與集合匹配
package com.aa.matchDEMO
import scala.util.Random
//匹配陣列、集合
object MatchCase3 {
def main(args: Array[String]): Unit = {
var array = Array(1, 3, 5)
array match {
case Array(1, x, y) => println(x + " " + y)
case Array(1, 3, 5) => println("精準匹配")
case Array(1, _*) => println("1...")
case _ => println("else")
}
//val list = List(0)
//val list = List(0, "a", 2)
val list = List(0, "a")
//val list = List(0, "a")
//val list = List(1,"a",1)
list match {
case 0 :: Nil => println("只有0的串列")
//case 0::_ =>println("0開頭的串列")
case x :: y :: Nil => println(s"只有2個元素${x},${y}的串列")
case _ => println("else串列")
}
}
}
宣告變數時匹配
package com.aa.matchDEMO
//變數宣告時進行模式匹配
object MatchCase4 {
def main(args: Array[String]): Unit = {
val result: Array[Int] = (1 to 5).toArray
val Array(_,x,y,_*) = result //變數宣告時進行模式匹配
println(s"x=${x},y=${y},x+y=${x+y}")
}
}
x=2,y=3,x+y=5
Process finished with exit code 0
在宣告變數時可以直接進行模式匹配,將匹配的結果作為新宣告變數的初值,
樣例類
樣例類是Scala中的特殊類(case修飾的),用于封裝資料,參與模式匹配、傳遞資料,顯然樣例類有2種:
- case class:多例,需要構造器和引數串列,
- case object:單例,不需要構造器(也就不需要引數串列),
類+case變成樣例類后底層發生了改變:
- 樣例類自動實作了apply方法,不需要new,
- 樣例類自動實作了toString方法,不再是列印記憶體地址,而是直接輸出屬性,
- 樣例類自動實作了hashcode和equals方法,物件實體不再是比較記憶體地址,而是直接比較內容,
舉個栗子:
package com.aa.caseDEMO
object Case1 {
def main(args: Array[String]): Unit = {
val cat1 = new Cat("哈哈") //普通類需要先new才能創建實體物件
val cat2 = new Cat("哈哈")
println(cat1) //輸出com.aa.caseDEMO.Cat@4cdbe50f 普通類直接輸出的是記憶體地址
println(cat1 == cat2) //輸出false 直接比較的是記憶體地址
val dog1 = new Dog("呵呵") //idea自動提示new是多余的,new關鍵字發灰說明可以不寫
val dog2 = Dog("呵呵")//不寫new也可以創建實體物件
println(dog1) //Dog(呵呵) 說明自動寫好了toString
println(dog1 == dog2) //true 說明自動寫好了equals和hashCode方法
}
}
class Cat(var name: String) {
//override def toString: String = super.toString 默認的toString方法
override def toString: String = s"Cat[$name]"
//override def equals(obj: Any): Boolean = super.equals(obj) 默認的equals方法
def canEqual(other: Any): Boolean = other.isInstanceOf[Cat]
override def equals(that: Any): Boolean = that match {
case that: Cat => (that canEqual this) && name == that.name //是同一類的實體物件才能比較物件的內容
case _ => false
}
override def hashCode(): Int = { //重寫hashCode方法
//先比較hashCode,如果不同肯定內容不同,如果hashCode相同內容可能不同,再去equals比較內容,速度快
val state = Seq(name)
state.map(_.hashCode).foldLeft(0)((a, b) => 31 * a + b) //隨便瞎寫的演算法
}
}
//樣例類
case class Dog(var name: String) {}
樣例類的核心功能是封裝資料+傳輸資料+模式匹配:
package com.aa.caseDEMO
import scala.util.Random
object Case2 {
def main(args: Array[String]): Unit = {
val array1: Array[Object] = Array(new Student("李四"), Teacher("王五"), Teacher("馬六"), Zhangsan)
val array2: Array[Object] = Array(Student("李四"), Teacher("王五"), Teacher("馬六"), Zhangsan)
val result: Object = array2(Random.nextInt(array2.length)) //Object是Java的Object,頂級父類
result match {
case Teacher(name) => println(name) //直接提取屬性
case Student(name) => println(name)
case s: Student => println(s.name) //先匹配物件,在呼叫物件.屬性
case Zhangsan => println("這貨是張三")
case _ => println("其它情況")
}
}
}
class Student(var name: String)
case class Teacher(var name: String)
case object Zhangsan
object Student { //伴生物件內定義apply方法和unapply方法
def apply(name: String): Student = new Student(name)
def unapply(s: Student): Option[String] = {
Some(s.name)
}
}
補充
apply方法
package com.aa.others
//測驗apply方法
object ApplyCase {
def main(args: Array[String]): Unit = {
val array1 = new Array[Int](10) //沒有初始值,需要new
val array2:Array[Int] = Array(11,22,33) //有初始值,不需要new
}
}
之前在命令列就發現了創建集合時,有初始值就可以不用new,嘗試定位:
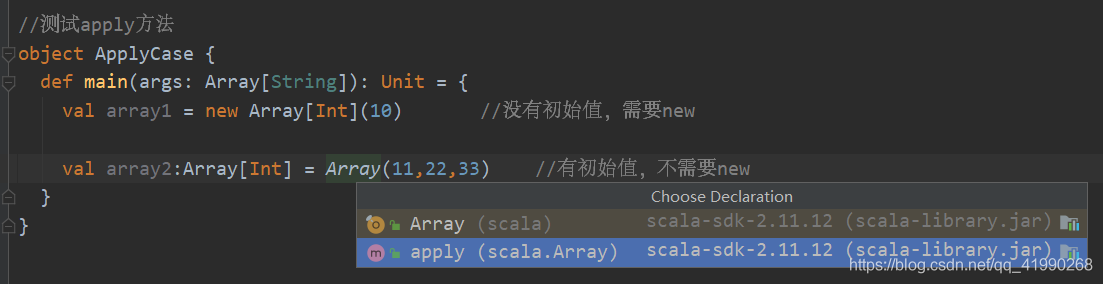
在Array.class第27行看到:
def apply(x : scala.Int, xs : scala.Int*) : scala.Array[scala.Int] = { /* compiled code */ }
Apply其實也是一種構造方法,在創建物件時,如果不+new,編譯器就會嘗試尋找是否有apply方法,如果有就呼叫apply方法實作物件的創建,
package com.aa.others
//測驗apply方法創建類的實體物件
object ApplyCase1 {
def main(args: Array[String]): Unit = {
val student = Student //object是全域唯一的實體(靜態加載,單例)
val zhangsan = new Person("張三")//普通類創建實體物件時必須new
val lisi:Person = Person("李四")//呼叫apply方法完成new
}
}
object Student //object是靜態加載的單例
class Person(var name: String)
object Person { //apply方法必須定義在類的伴生物件中
//idea自動提示并補全apply方法
def apply(name: String): Person = new Person(name)
}
在類的伴生物件中定義apply方法后,就可以直接呼叫伴生物件的apply方法,不用new,
unapply方法
從字面上也知道先得有apply方法,才能有unapply方法:
object Student{
def unapply(s: unapplyStudent): Option[String] = {
Some(s.name)}
}
case Student(name) => println(name)
unapply方法中可以使用Some方法,定位到Some.class:
package scala
@scala.SerialVersionUID(value = 1234815782226070388)
final case class Some[+A](val x : A) extends scala.Option[A] with scala.Product with scala.Serializable {
def isEmpty : scala.Boolean = { /* compiled code */ }
def get : A = { /* compiled code */ }
}
可以看到Some內部有get方法,其實unapply方法就是從物件中提取屬性,相當于提取器,
Option型別
量子疊加型別,表示可有可無的2種狀態,分為2個類:有(Some)、無(None),
package com.aa.others
object OptionCase {
def main(args: Array[String]): Unit = {
val map1 = Map("name"->"張三","age"->"13")
//根據Key去Map中取值,有值顯式,無值為None
val result1:Option[String] = map1.get("name")
val result2:Option[String] = map1.get("age1")
println(result1) //Some(張三) 有值
println(result2) //None
}
}
再看看Option型別多么“薛定諤”:
package com.aa.others
object OptionCase1 {
def main(args: Array[String]): Unit = {
def method1(x: Int, y: Int) = x / y
println(method1(5, 2))
//println(method1(5, 0)) 會報錯
/*
Exception in thread "main" java.lang.ArithmeticException: / by zero
at com.aa.others.OptionCase1$.method1$1(OptionCase1.scala:5)
at com.aa.others.OptionCase1$.main(OptionCase1.scala:6)
at com.aa.others.OptionCase1.main(OptionCase1.scala)
Process finished with exit code 1
*/
def method2(x: Int, y: Int): Option[Int] = {
if (y != 0) Some(x/y)
else None
}
val result = method2(5, 3)
println(result)
val maybeInt = method2(5, 0)
maybeInt match {
case Some(s) =>println(s)
case None =>println("除數=0,出錯")
}
}
}
偏函式Partial Function
這個“偏”類似“偏導數”的“偏”,Partial Function字面意思是部分的、不完全的函式,
表面上沒有match,實際上卻有一組case陳述句:
偏函式是Partial Function[A,B]的一個實體,A代表輸入引數型別,B代表回傳結果型別,
舉個栗子:
package com.aa.others
object PF1 {
def main(args: Array[String]): Unit = {
val array1: Array[Int] = Array(11, 22, 33)
//println(array1.map(_*10))//[I@48140564 需要轉化才能列印
println(array1.map(_ * 10).toBuffer) //ArrayBuffer(110, 220, 330)
val array2: Array[Any] = Array(11, 22, "哈哈", 33)
//println(array2.map(_*10)) 為了保證安全,默認不允許這么做
println(array2.filter(_.isInstanceOf[Int])//先按資料型別進行合法性過濾
.map(_.asInstanceOf[Int])//鏈式編程,對合法資料進行型別轉化
.map(_*10).toBuffer)
val pf1:PartialFunction[Any,Int]={
case i:Int=>i*10
}
println(array2.collect(pf1).toBuffer)//collect方法接收偏函式作為引數
}
}
可以看出偏函式相比鏈式編程的過濾→型別轉換→函式運算的三步走,只需要定義輸入、輸出型別與函式邏輯就可以直接出結果,還是很簡潔的,
package com.aa.others
object PF2 {
def main(args: Array[String]): Unit = {
def method1(i:Int) = i match {
case 1 => println("一")
case 2 => println("二")
case 3 => println("三")
}
method1(2)
val pf2:PartialFunction[Int,String] ={
case 1 =>"一"
case 2 =>"二"
case 3 =>"三"
}
println(pf2(1))
}
}
使用偏函式進行模式匹配和運算顯然也很簡潔,
正則
正則(學名Regular Expression),又名規則運算式,用于對字串內容進行匹配,在文本處理、上位機資料提取、ETL等操作中都需要正則,Scala中的正則類就叫RegEx類,直接new即可使用,當然也可以String.r→RegEx類,
package com.aa.others
import scala.util.matching.Regex
object RegExTest {
def main(args: Array[String]): Unit = {
val email1 = "1009057838@QQ.com"
val email2 = "haha@com"
//正常情況使用三對雙引號可以跨行
//正則不行(出現了多余的標記)
// val regex: Regex =
// """
// |.+@.+\..+
// |""".r
/*結果不正確
List(, , , , , , , , , , , , , , , , , )
List(, , , , , , , , )
*/
val regex: Regex =
""".+@.+\..+""".r
println(regex.findAllMatchIn(email1).toList)
println(regex.findAllMatchIn(email2).toList)
/*
List(1009057838@QQ.com)
List()
*/
}
}
Scala例外處理
和Java差不多,也可以使用idea的ctrl+art+t來抽取并封裝到try/catch/finally中:
package com.aa.others
object ExceptionCase1 {
def main(args: Array[String]): Unit = {
try {//idea使用ctrl+art+t抽取并封裝在try中
val error = 5 / 0
/*常見的分母0報錯
Exception in thread "main" java.lang.ArithmeticException: / by zero
at com.aa.others.ExceptionCase1$.main(ExceptionCase1.scala:5)
at com.aa.others.ExceptionCase1.main(ExceptionCase1.scala)
*/
} catch {//捕獲例外后對例外進行處理
case e1:ArithmeticException => println("數值例外"+e1.getMessage)
case e2:NullPointerException => println("空指標例外")
} finally {//無論如何都會執行
println("一定會執行")
}
}
}
當然偷懶的辦法是throw拋例外:
package com.aa.others
object ExceptionCase2 {
def main(args: Array[String]): Unit = {
println("開始執行")
throw new Exception("拋出例外")
/*執行后出現
開始執行
Exception in thread "main" java.lang.Exception: 拋出例外
at com.aa.others.ExceptionCase2$.main(ExceptionCase2.scala:7)
at com.aa.others.ExceptionCase2.main(ExceptionCase2.scala)
Process finished with exit code 1
*/
println("永遠不會執行")//idea中變灰,說明是無效代碼,沒有執行機會
}
}
但是Scala不需要在方法上拋例外,,,
泛型
泛型是引數化型別, 泛型程式設計(generic programming),Scala中的泛型在使用時,通常用26個英文字母表示,常用T、A、B,套路一般是:
def 方法名[泛型名稱](..) = {
//...
}
舉個栗子:
package com.aa.genDEMO;
import java.util.ArrayList;
public class TestA {
public static void main(String[] args) {
Student1 student1 = new Student1();
Person1 person1 = new Student1();//類的多型性,向上轉型
ArrayList<Student1> arrayList1 = new ArrayList<Student1>();
//ArrayList<Person1> arrayList2 = new ArrayList<Student1>();
//Java中類的繼承關系不能延伸到集合,非變
}
}
//定義Java類和繼承類
class Person1{}
class Student1 extends Person1{}
會報錯:
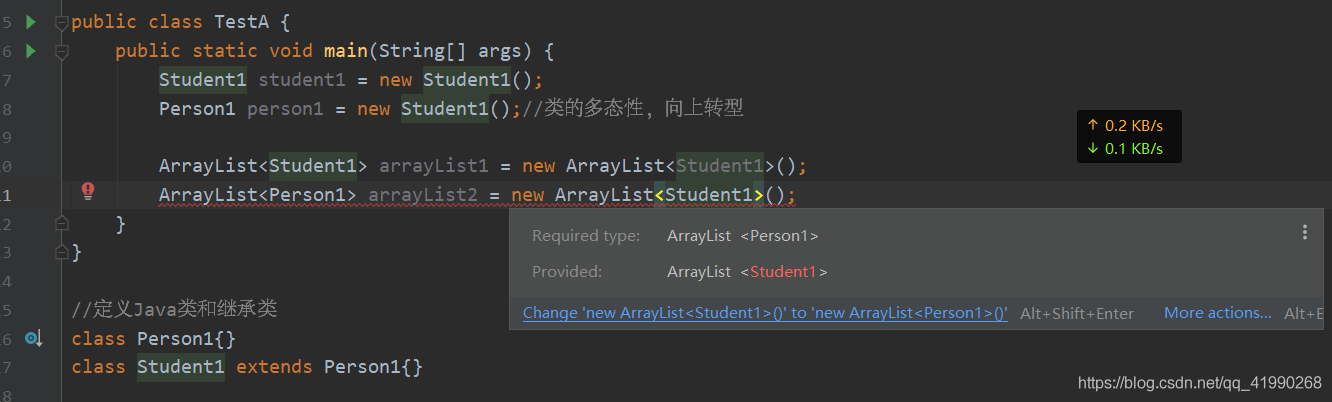
因為Java支持的是非變,
package com.aa.genDEMO
object TestGen{
def main(args: Array[String]): Unit = {
val array1 =new Array[String](4) //T箭頭String
val array2 = new Array[Int](2) //T→Int
//需要定義多個方法,,,很麻煩
def method1(x:Array[String]) = x(x.length/2)
def method2(x:Array[Int]) = x(x.length/2)
println(method1(Array("11","哈哈","呵呵","嗷嗷嗷")))
println(method2(Array(11,22,33)))
//使用泛型,指代一個引數,泛指多數型別,只需要定義一個方法
def method3[A](x:Array[A])=x(x.length/2)
println(method3(Array("11","哈哈","呵呵","嗷嗷嗷")))
println(method3(Array(11,22,33)))
println(method3(Array(11.11,22.22,33.33)))
}
}
還可以定義泛型類:
package com.aa.genDEMO
object TestGen1 {
def main(args: Array[String]): Unit = {
val cat1:Cat1 = Cat1("哈哈")
//val cat2 = Cat1(11)//報錯Type mismatch
val cat3 = Cat2("呵呵")
val cat4 = Cat2(14)
val cat5 = Cat2(true)
}
}
case class Cat1(var name:String)
case class Cat2[T](var name:T)//定義泛型類
泛型還有上下界的問題:
[T <: 型別] T <=型別 上界 T型別必須是后面指定的型別及其子類
[T >: 型別] T >=型別 下界 T型別必須是后面值的型別及其父類
如果類既有上界、又有下界,下界寫在前面,上界寫在后面
泛型還存在泛型延伸問題(Scala除了支持Java支持的非變外,還支持協變和逆變):
class Super
class Sub extends Super
class Temp1[T] //非變
class Temp2[+T] //保持一致 繼續延伸
class Temp3[-T] //逆轉過來 延伸
def main(args: Array[String]): Unit = {
val a:Temp1[Sub] = new Temp1[Sub]
// 編譯報錯
// 非變
//val b:Temp1[Super] = a
// 協變
val c: Temp2[Sub] = new Temp2[Sub]
val d: Temp2[Super] = c
// 逆變
val e: Temp3[Super] = new Temp3[Super]
val f: Temp3[Sub] = e
}
Scala Actor并發編程
準備作業
如果導包時沒有需要的類別庫:
這是∵類別庫路徑有誤(安裝Scala時默認有該類),需要在idea的左上角點file→Project Structure→Global Libraries中設定Scala SDK的路徑:
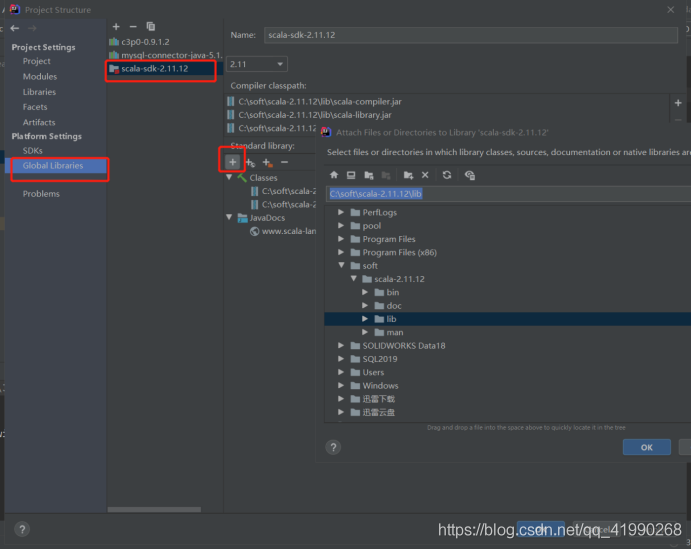
這里點+號,選擇安裝路徑的lib包,確認后即可導包,
并發編程對比
Java的并發編程
模型是基于多執行緒+共享資料:執行緒越多,并發能力越強,當然不易維護,容易產生死鎖,
package com.aa.lock;
//jps -l 查看java行程 jstack + 行程號 查看死鎖的情況
public class DeadLock {
private Object lock1 = new Object();
private Object lock2 = new Object();
public void method1() throws InterruptedException {
synchronized(lock1){
System.out.println(Thread.currentThread().getName() + "獲取到lock1,請求獲取lock2....");
Thread.sleep(1000);
synchronized (lock2){
System.out.println("獲取到lock2....");
}
}
}
public void method2() throws InterruptedException {
synchronized(lock2){
System.out.println(Thread.currentThread().getName() + "獲取到lock2,請求獲取lock1....");
Thread.sleep(1000);
synchronized (lock1){
System.out.println("獲取到lock1....");
}
}
}
public static void main(String[] args) {
DeadLock deadLock = new DeadLock();
new Thread(()-> {
try {
deadLock.method1();
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
new Thread(()-> {
try {
deadLock.method2();
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
}
}
Scala的并發編程
模型是基于actor事件+訊息發送和接收:actor越多并發能力越強,由于不共享資料,當然不存在鎖的問題,
簡單使用
package com.aa.actorDEMO
import scala.actors.Actor
class Actor1 extends Actor{
override def act(): Unit = {
for(i <- 1 to 10){
println("Actor1:"+i)
Thread.sleep(2000)
}
}
}
class Actor2 extends Actor{
override def act(): Unit = {
for(i <- 1 to 10){
println("Actor2:"+i)
Thread.sleep(2000)
}
}
}
object Test1{
def main(args: Array[String]): Unit = {
//創建actor實體
val actor = new Actor1
val actor2 = new Actor2
//啟動actor
actor.start()
actor2.start()
}
}
執行后看起來還是很像多執行緒的:
Actor2:1
Actor1:1
Actor1:2
Actor2:2
Actor1:3
Actor2:3
Process finished with exit code -1
死回圈收發訊息
Scala容易報錯,為了防止不必要的麻煩,盡量不同名(不使用class Actor2):
package com.aa.actorDEMO
import scala.actors.Actor
class Actor3 extends Actor{
override def act(): Unit = {
while (true){
receive{
case "hello" => println("\\(@^0^@)/")
case "bye" => println("ヾ(?ω?`)o")
case "stop" => System.exit(0)
}
}
}
}
object Actor3{
def main(args: Array[String]): Unit = {
val actor = new Actor3
actor.start()
//自己給自己發送訊息
actor!"hello"
actor!"hello"
actor!"hello"
actor!"bye"
actor!"stop"
actor!"hello"
}
}
\(@^0^@)/
\(@^0^@)/
\(@^0^@)/
ヾ(?ω?`)o
Process finished with exit code 0
其中:
| 標記 | 說明 |
|---|---|
| ! | 發送異步訊息,沒有回傳值 |
| !? | 發送同步訊息,等待回傳值 |
| !! | 發送異步訊息,回傳值是Future[Any] |
while(true)是阻塞式,效率低下,也不能復用執行緒,
由于構造了伴生關系,idea左側的圖表都變了,,,很智能的玩意兒,,,
React收發訊息
react方法配合loop可以復用執行緒,更高效:
package com.aa.actorDEMO
import scala.actors.Actor
class Actor4 extends Actor{
override def act(): Unit = {
loop{
react{
case "hello" => println("\\(@^0^@)/")
case "bye" => println("ヾ(?ω?`)o")
case "stop" => System.exit(0)
}
}
}
}
object Actor4{
def main(args: Array[String]): Unit = {
val actor = new Actor4
actor.start()
//自己給自己發送訊息
actor!"hello"
actor!"hello"
actor!"hello"
actor!"bye"
actor!"stop"
actor!"hello"
}
}
Actor的3種訊息發送方式
package com.aa.actorDEMO
import scala.actors.Actor
import scala.actors.Future
case class AsyncMessage(id: Int, msg: String)
case class Reply(msg: String)
case class SyncMessage(id: Int, msg: String)
class Actor5 extends Actor {
override def act(): Unit = {
loop {
react {
case AsyncMessage(id, msg) => { //異步
println(s"id:${id},msg:${msg}")
sender ! Reply("回傳訊息")
}
case SyncMessage(id, msg) => { //同步
println(s"id:${id},msg:${msg}")
}
}
}
}
}
object Actor5 {
def main(args: Array[String]): Unit = {
val actor = new Actor5
actor.start()
//Actor有3種發送訊息的方式
actor ! AsyncMessage(1, "異步發送,不需要回傳值")
actor !? SyncMessage(2, "同步發送,阻塞等待回傳值")
val future: Future[Any] = actor !! AsyncMessage(3, "異步發送,需要回傳值")
val result: Reply = future.apply().asInstanceOf[Reply]
println(result)
}
}
同步發送一定會阻塞和死等,由于是單執行緒運行,直接卡在這一步:
id:1,msg:異步發送,不需要回傳值
id:2,msg:同步發送,阻塞等待回傳值
暫時屏蔽同步發送:
id:1,msg:異步發送,不需要回傳值
id:3,msg:異步發送,需要回傳值
Reply(回傳訊息)
顯然異步可以介紹到訊息,,,
Actor并發WordCount
比起之前在MapReduce中寫的WordCount還是簡單不少的:
原理是將分散在多個檔案的資料,利用actor異步處理,將回傳值先置于futureSet中,再運算到resultList中,最后整合到FinalResult中,
package com.aa.actorDEMO
import scala.actors.{Actor, Future}
import scala.collection.mutable
import scala.collection.mutable.ListBuffer
import scala.io.Source
//定義個樣例類 用于封裝提交的任務
case class SubmitTask(filePath: String)
//定義樣例類 用于封裝task處理的結果
case class ReplyResult(result: Map[String, Int])
class Task extends Actor {
override def act(): Unit = {
loop {
react {
//接收的task任務 處理資料 進行wc
case SubmitTask(filePath) => {
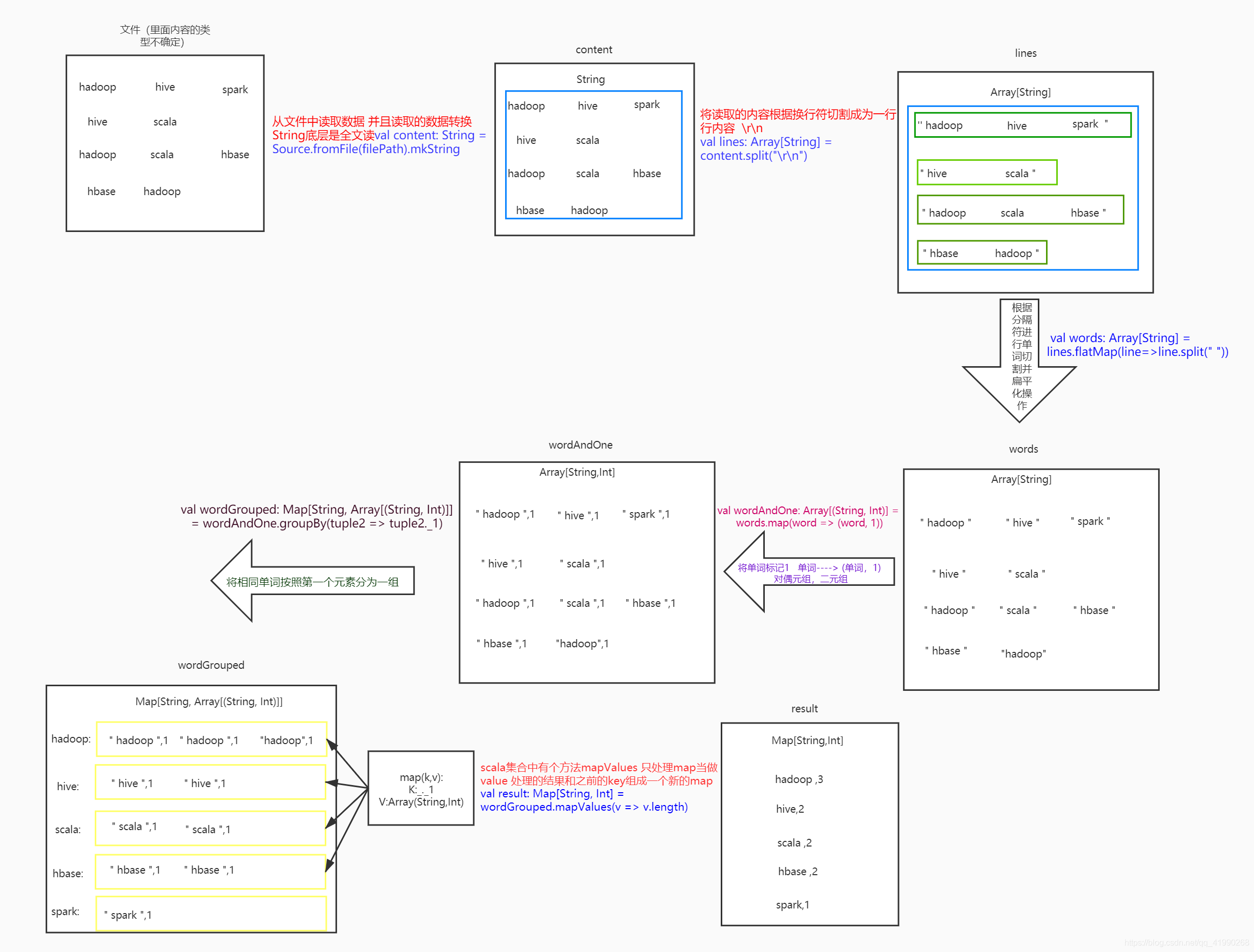
//從檔案中讀取資料 并且讀取的資料轉換為String,底層是全文讀取
val content: String = Source.fromFile(filePath).mkString
//將讀取的內容根據換行符切割成為一行行內容,\r\n就是分隔符
val lines: Array[String] = content.split("\r\n")
//根據分隔符進行單詞切割,并扁平化操作(將零散的單詞壓入一個集合中)
val words: Array[String] = lines.flatMap(line => line.split(" "))
//將單詞標記為鍵值對,單詞→(單詞,1) 的對偶元組(二元組)
val wordAndOne: Array[(String, Int)] = words.map(word => (word, 1))
//將單詞相同的分為一組
val wordGrouped: Map[String, Array[(String, Int)]] = wordAndOne.groupBy(tuple2 => tuple2._1)
//scala集合中有個方法mapValues,將value位置的map處理為新的value,并將處理的結果和之前的key組成一個新的map
val result: Map[String, Int] = wordGrouped.mapValues(v => v.length)
//for( (k,v)<- result) println(s"${k}---->${v}")
//task處理完的結果進行回傳
sender ! ReplyResult(result)
}
}
}
}
}
object WordCount {
def main(args: Array[String]): Unit = {
//創建一個集合 用于保存每個任務Future
val futureSet = new mutable.HashSet[Future[Any]]()
//創建一個集合 用于保存最終的每個task處理結果
val resultList = new ListBuffer[ReplyResult]
//待處理資料路徑
val files = Array("D:\\datasets\\scala\\1.txt", "D:\\datasets\\scala\\2.txt", "D:\\datasets\\scala\\3.txt")
//val filePath ="D:\\datasets\\scala\\1.txt"
//遍歷待處理檔案檔案,分別啟動task處理各個檔案
for (f <- files) {
//創建啟動TaskActor
val task = new Task
task.start()
//把待處理的資料路徑(任務)發送給task處理
//因為需要對最終的結果進行合并,使用異步有回傳值的訊息
val future: Future[Any] = task !! SubmitTask(f)
//把future保存至集合中
futureSet += future
}
//判斷future是否已經完成有結果,如果有結果就提取結果,future.isSet用于判斷結果是否有結果
while (futureSet.nonEmpty) {
//過濾出已經有結果的future
val completed: mutable.HashSet[Future[Any]] = futureSet.filter(f => f.isSet)
//遍歷已經完成的 提取結果
for (c <- completed) {
//提取結果
val result: ReplyResult = c.apply().asInstanceOf[ReplyResult]
//將結果添加至resultList
resultList += result
//把提取完結果的future從futureSet給剔除
futureSet.remove(c)
}
}
println(resultList.flatMap(r => r.result)
.groupBy(_._1)
.mapValues(values => values.map(x => x._2).sum))
}
}
按照函式式編程的做法,可以精簡大量代碼:
package com.aa.actorDEMO
import scala.actors.Actor
import scala.io.Source
//優化后的簡化版本
//定義個樣例類 用于封裝提交的任務
case class SubmitTask(filePath:String)
class Task extends Actor {
override def act(): Unit ={
loop{
react{
//接收的task任務 處理資料 進行wc
case SubmitTask(filePath) =>{
//從檔案中讀取資料,并且讀取的資料轉換為String,底層是全文讀
val content: String = Source.fromFile(filePath).mkString
val result: Map[String, Int] = content.split("\r\n")
.flatMap(_.split(" "))
.map((_, 1))
.groupBy(_._1)
.mapValues(_.length)
println(result)
}
}
}
}
}
object WordCount {
def main(args: Array[String]): Unit = {
//待處理資料路徑
val filePath ="D:\\datasets\\scala\\1.txt"
//創建啟動TaskActor
val task = new Task
task.start()
//把待處理的資料路徑(任務)異步提交給task處理
task ! SubmitTask(filePath)
}
}
簡化后可讀性變差,但代碼很簡潔,
這里有個小細節:
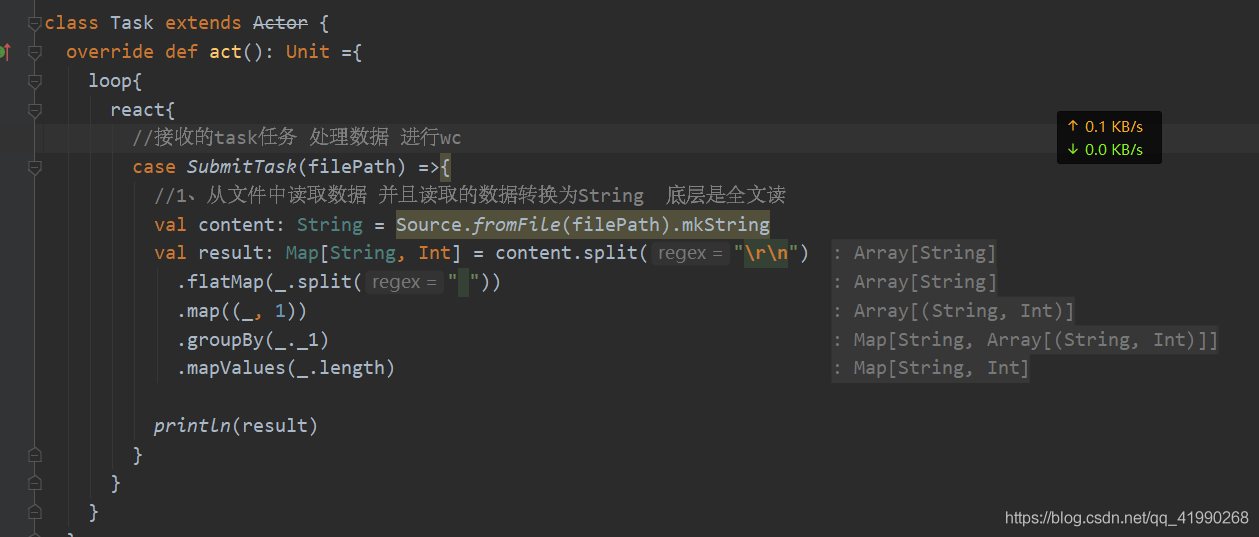
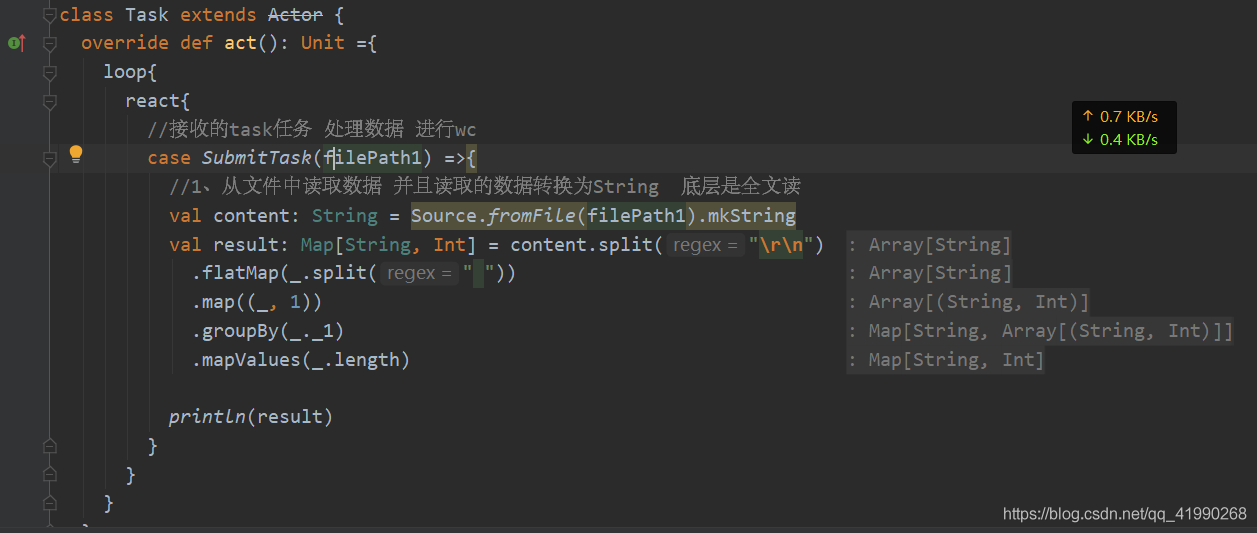
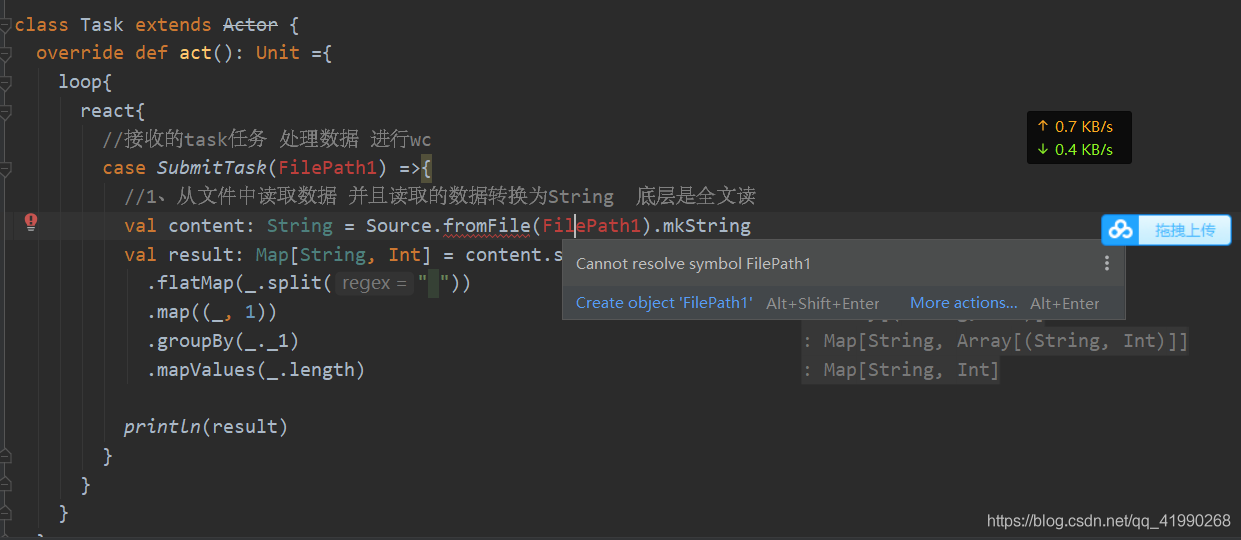
傳的引數必須是小寫字母開頭,不能大寫字母開頭,否則會報錯:Cannot resolve symbol,Scala這點做的很奇怪,,,
對命令列的輸入進行WordCount事實證明也是可行的:
package com.aa
import scala.collection.mutable.ListBuffer
import scala.io.StdIn
import scala.io.Source
object WordCount_Simple {
def main(args: Array[String]): Unit = {
var input = ListBuffer("哈 哈 哈 哈", "哈 哈 呵 呵 呵呵 哈哈")
val inputPath = "E:\\study\\TopN\\origin.txt"
var inputStr:String = "哈 哈 哈 哈"
println("輸入路徑:"+inputPath)
val context:String = Source.fromFile(inputPath).mkString
var wordcount_In = context.split("\r\n")
.flatMap(_.split(" "))
.map((_, 1))
.groupBy(_._1)
.map(x => (x._1, x._2.size))
.toList.sortBy(_._2)
println(wordcount_In) //路徑檔案的WC
val output = input.flatMap(_.split(" "))
.map((_, 1))
.groupBy(_._1)
.map(x => (x._1, x._2.size))
.toList.sortBy(_._2)
println("測驗資料:"+output)
while (true) {
inputStr =StdIn.readLine()
println("輸入的內容:"+inputStr)
val input_WC: List[(String, Int)] = inputStr.split("\r\n")
.flatMap(_.split(" "))
.map((_, 1))
.groupBy(_._1)
.map(x => (x._1, x._2.size))
.toList.sortBy(_._2)
println(input_WC)
}
}
}
Scala是個好東西,但是并沒有多少人用這種冷門語言,也是很神奇,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/286923.html
標籤:其他