文章目錄
- 引言
- 第一劍「總決式」功能概述(三句話左右概況,簡明扼要)
- 第二劍「破劍式」、專案周期(開發時長和人員配置)
- 開發時長:
- 人員配置
- 第三劍「破刀式」、技術架構(技術選項及框架版本)
- 第四劍「破槍式」、集群規模(業務資料量及服務器配置和數量)
- 如何確認集群規模?(假設:每臺服務器8T磁盤,128G記憶體)
- 服務器使用物理機還是云主機?
- 第五劍「破鞭式」、資料來源及資料采集
- 第六劍「破索式」、資料ETL(可能離線、可能實時)
- 第七劍「破掌式」、業務報表分析(離線報表、實時報表)
- 第八劍「破箭式」、資料分析引擎(Hive、Impala、Es、Spark、Flink等)
- 第九劍「破氣式」、專案問題(資料傾斜、OOM或性能優化等)
- 總結
引言
大家好,我是ChinaManor,直譯過來就是中國碼農的意思,俺希望自己能成為國家復興道路的鋪路人,大資料領域的耕耘者,平凡但不甘于平庸的人,
在萌新準備出去面試之前,需要針對每個大資料專案,
需整理一套屬于自己基礎知識,必須熟記于心,招式爛熟于心,方能無劍勝有劍!
(敲黑板) 面經源于真實10年開發經驗的講師所授,筆者只是將其寫成了博客

=== 下面以某智慧物流大資料平臺專案為例: ===
第一劍「總決式」功能概述(三句話左右概況,簡明扼要)
本專案涉及的業務資料包括訂單、運輸、倉儲、搬運裝卸等物流環節中涉及的資料、資訊,由于多年的積累、龐大的用戶群,每日的訂單數上千萬,傳統的資料處理技術已無法滿足企業需求,因此通過大資料分析可以提高運輸配送效率、減少物流成本,更有效地滿足客戶服務要求,并對資料結果分析,提出具有中觀指導意義的解決方案,
第二劍「破劍式」、專案周期(開發時長和人員配置)
開發時長:
六個月左右
階段劃分
需求調研、評審(4周)
設計架構(1周)
編碼、集成(12周)
測驗(2周)
上線部署,試運行,調優(3周)
人員配置
開發人員: 6人
職責劃分:
前端(JavaWeb+前端 2人)
大資料開發(3人)
運維(1人)

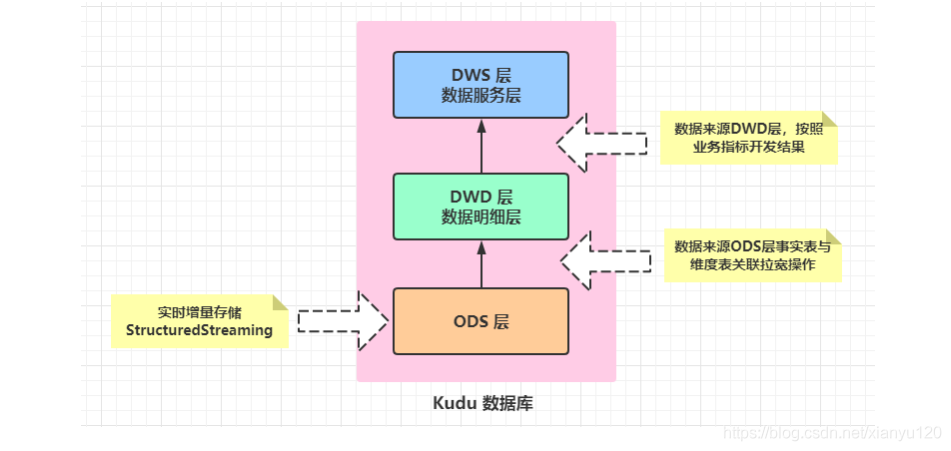
第三劍「破刀式」、技術架構(技術選項及框架版本)
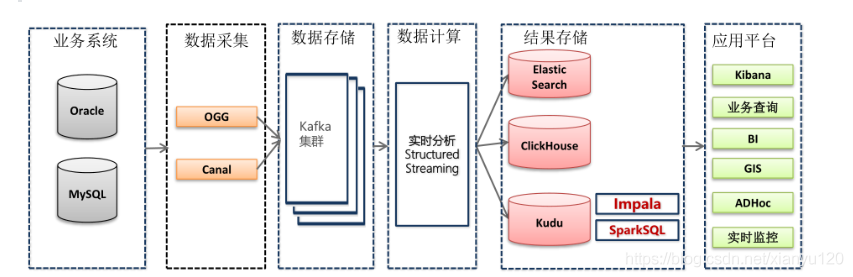
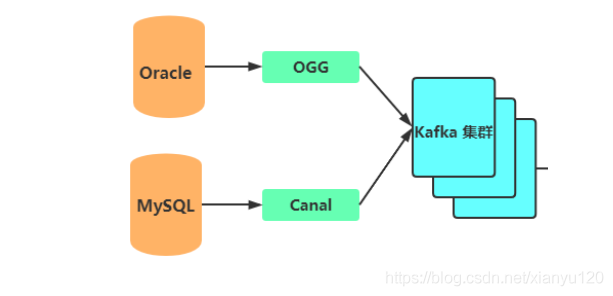
- 業務系統資料主要存放到Oracle和MySQL資料庫中,比如CRM系統資料在MySQL,OMS系統資料存放在Oracle中;
- OGG增量同步Oracle資料庫的資料,Canal增量同步MySQL資料庫的資料;
- OGG及Canal增量抽取的資料會寫入到Kafka集群,供實時分析計算程式消費;
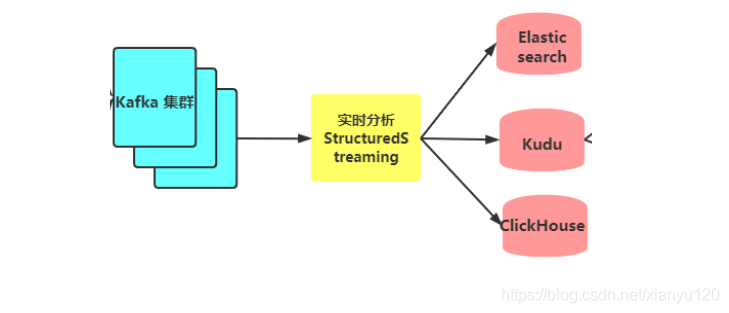
實時分析 - 實時分析計算程式消費kafka的資料,將消費出來的資料進行ETL操作;
- 為了方便業務部門對各類單據的查詢,StructuredStreaming流式處理系統將資料經過ETL處理后,將資料寫入到Elasticsearch索引中;
- StructuredStreaming流處理會將資料寫入到ClickHouse,Java Web后端直接將資料查詢出來進行展示,例如:將運輸車輛的GPS位置資料實時展示到GIS地圖;
- StructuredStreaming將實時ETL處理后的資料同步更新到Kudu中,方便進行資料的準實時分析、查詢,Impala對Kudu資料進行即席分析查詢;
- 前端應用對資料進行可視化展示,比如資料服務介面或大屏實時重繪;

第四劍「破槍式」、集群規模(業務資料量及服務器配置和數量)
此處資料量,需參考實際需要酌情考慮
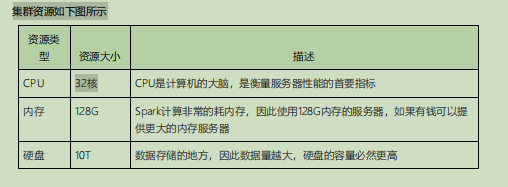
如何確認集群規模?(假設:每臺服務器8T磁盤,128G記憶體)
每天榷訓躍用戶100萬,每人一天平均100條:100萬*100條=10000萬條(1億)
每條日志1K左右,每天1億條:100000000/1024/1024=約100G
半年內不擴容服務器來算:100G*180天=約18T
保存3副本:18T3=54T
預留20%-30%Buf=54T/0.7=77T
因此:約8T10臺服務器
? 如果考慮數倉分層?
服務器將近在擴容1-2倍
服務器使用物理機還是云主機?
? 機器成本考慮:
? 物理機:以128G記憶體,20核物理CPU,40執行緒,8THDD和2TSSD硬碟,單臺報價4W出頭,需考慮托管服務器費用,一般物理機壽命5年左右
? 云主機,以阿里云為例,差不多相同配置,每年5W
? 運維成本考慮:
? 物理機:需要有專業的運維人員
? 云主機:很多運維作業都由阿里云已經完成,運維相對較輕松

第五劍「破鞭式」、資料來源及資料采集
第六劍「破索式」、資料ETL(可能離線、可能實時)
第七劍「破掌式」、業務報表分析(離線報表、實時報表)
- 第一點:傳統報表分析,各個主題報表
- 資料傾斜、大表與大表關聯、OOM記憶體溢位等等
- 第二點:Impala 即席查詢,SQL陳述句
- 第三點:ClickHouse 實時OLAP分析
第八劍「破箭式」、資料分析引擎(Hive、Impala、Es、Spark、Flink等)
- Hive:底層MapReduce框架,“穩”
- SparkSQL:集成Hive或集成Kudu,分析資料,當然也是用StructuredStreaming
- Impala、ClickHouse:實時OLAP分析框架

第九劍「破氣式」、專案問題(資料傾斜、OOM或性能優化等)
- 拋出問題,如何解決(自己解決)
- 常見性能優化,背下來:Hive性能優化、Spark性能優化(原理性東西)
例:如何避免Spark資料傾斜?
避免Spark資料傾斜,一般是要選用合適的 key,或者自己定義相關的 partitioner,通 過加鹽或者哈希值來拆分這些 key,從而將這些資料分散到不同的 partition 去執 行,如下算子會導致 shuffle 操作,是導致資料傾斜可能發生的關鍵點所在: groupByKey;reduceByKey;aggregaByKey;join;cogroup;
總結
以上便是十年專案經驗面試官親傳大資料面試獨孤九劍~
愿你讀過之后有自己的識訓,如果有識訓不妨一鍵三連一下~

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/286927.html
標籤:其他
上一篇:資料結構之資料、資料元素、資料項、資料物件之間的關系
下一篇:Apache DolphinScheduler征稿 — Apache DolphinScheduler 快速入門與部署