😻前面我們介紹了一些pyspark的基礎指令集,但是對spark的核心架構了解還不夠透徹,今天我們就來介紹一些spark的核心架構,以及一些基本概念,對以前內容感興趣的小伙伴可以查看👇:
- 鏈接: Spark之處理布爾、數值和字串型別的資料.
- 鏈接: Spark之Dataframe基本操作.
- 鏈接: Spark之處理布爾、數值和字串型別的資料.
今天我們來介紹一下spark的一些運行原理、架構、組成部分,
1.spark運行架構
spark框架的核心是一個計算引擎,整體來說,它采用了標準的master——slave的結構,如圖所示,它展示了一個 Spark 執行時的基本結構,圖形中的 Driver 表示 master,負責管理整個集群中的作業任務調度,圖形中的 Executor 則是 slave,負責實際執行任務,
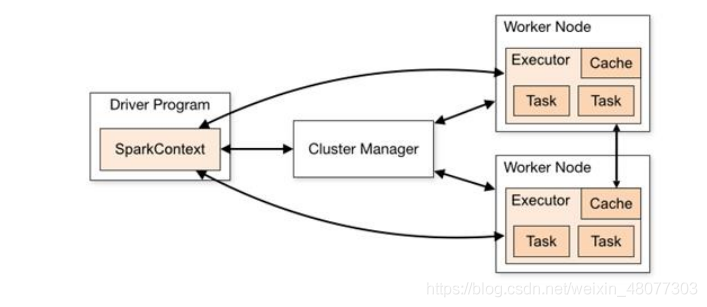
1.1 Driver
Driver是spark的驅動節點,用于執行spark任務中的main方法,負責實際代碼的執行作業,主要負責以下任務:
- 將用戶程式轉化為作業(job)
- 在Executor之間調度任務
- 跟蹤Executor的執行情況
- 通過 UI 展示查詢運行情況
通俗理解Driver就是驅使整個應用運行起來的程式,也稱之為
Driver 類
1.2 Executor
Spark Executor 是集群中作業節點(Worker)中的一個 JVM 行程,負責在 Spark 作業中運行具體任務(Task),任務彼此之間相互獨立,Spark 應用啟動時,Executor 節點被同時啟動,并且始終伴隨著整個 Spark 應用的生命周期而存在,如果有 Executor 節點發生了故障或崩潰,Spark 應用也可以繼續執行,會將出錯節點上的任務調度到其他 Executor 節點上繼續運行,
- 負責運行組成 Spark 應用的任務,并將結果回傳給驅動器行程
- 它們通過自身的塊管理器(Block Manager)為用戶程式中要求快取的RDD 提供記憶體式存盤,RDD 是直接快取在 Executor 行程內的,因此任務可以在運行時充分利用快取資料加速運算,
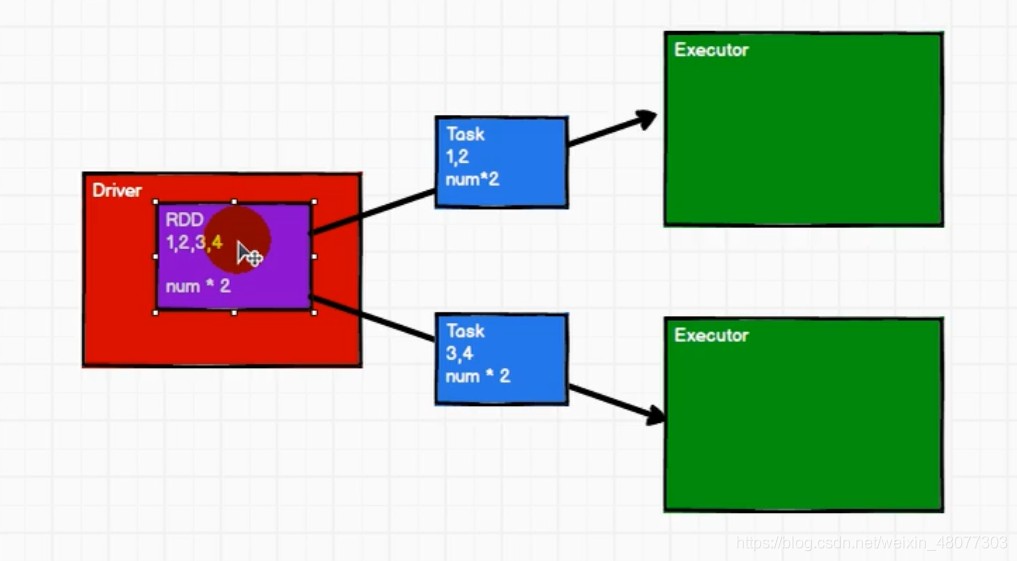
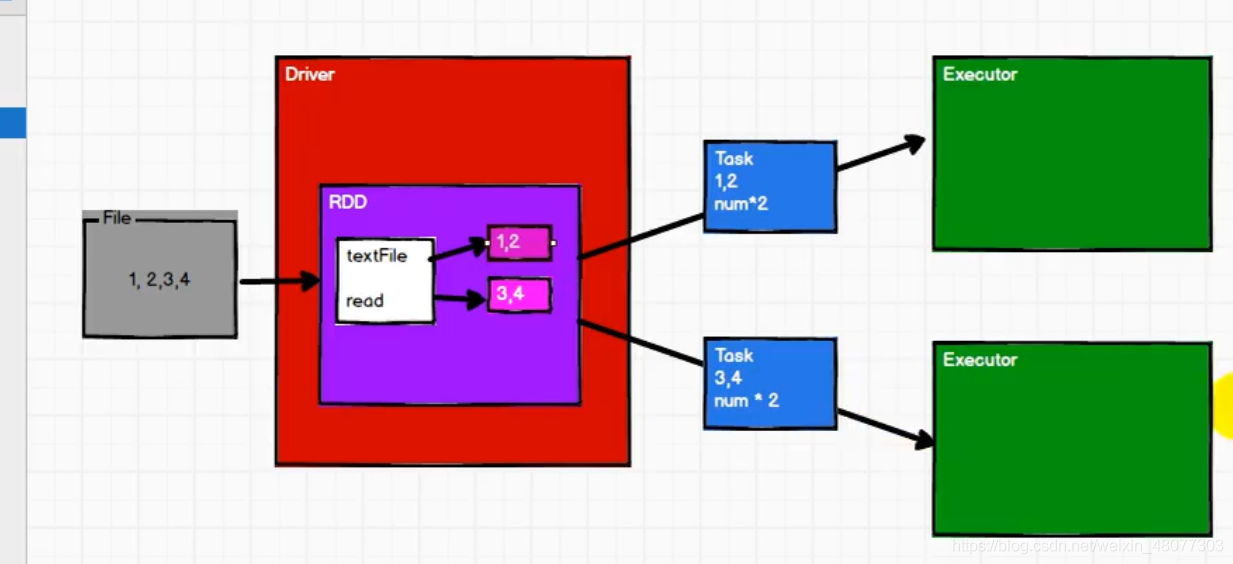
2.RDD
RDD(Resilient Distributed Dataset)叫做彈性分布式資料集,是 Spark 中最基本的資料處理模型,
- 存盤的彈性:記憶體與磁盤的自動切換;
- 容錯的彈性:資料丟失可以自動恢復;
- 計算的彈性:計算出錯重試機制;
- 分片的彈性:可根據需要重新分片,
- 分布式:資料存盤在大資料集群不同節點上
- 資料集:RDD 封裝了計算邏輯,并不保存資料
- 資料抽象:RDD 是一個抽象類,需要子類具體實作
- 不可變:RDD 封裝了計算邏輯,是不可以改變的,想要改變,只能產生新的 RDD,在新的 RDD 里面封裝計算邏輯
- 可磁區、并行計算
我們應該如何去理解這個RDD,如何理解是是最基本的資料處理單元,解釋RDD之前先說一下java的IO操作,這里之所以要說java的IO是因為RDD的處理方式和java的IO操作很像,
2.1 IO操作的字符流
在字符流中,我們并不是將A、B、C字符讀一個然后輸出一個,而是將字符讀到緩沖區中,等緩沖區的資料占滿了之后,一并輸出,
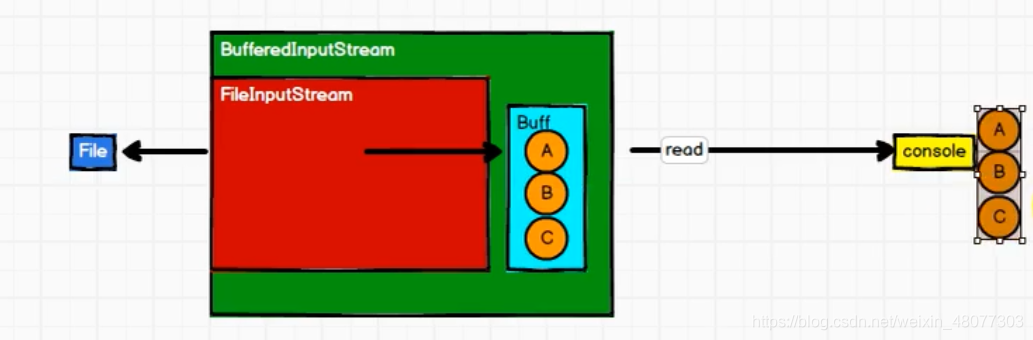
2.2 IO操作的位元組流
在位元組流中,我們并沒有重新定義位元組流的IO模式,只是在字符流的基礎上增加了一些邏輯程序,我們在字符流的基礎上增加了utf-8方式轉關換流,將字符轉化為位元組,然后再存入緩沖區,等到緩沖區占滿后,再輸出結果,這種利用字符流的基礎來構建位元組流的方式叫做裝飾者設計模式,
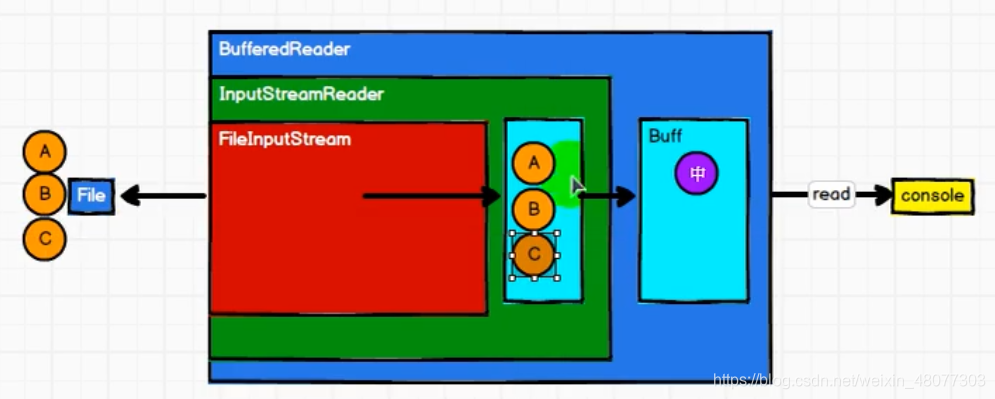
2.3 RDD
我們需要處理個檔案,將檔案按行讀入hadoopRDD,然后mappartitionRDD將資料進行磁區,然后再用mappartitionRDD轉化為key-value形式,然后再用shuffleRDD進行聚合,輸出最后的結果,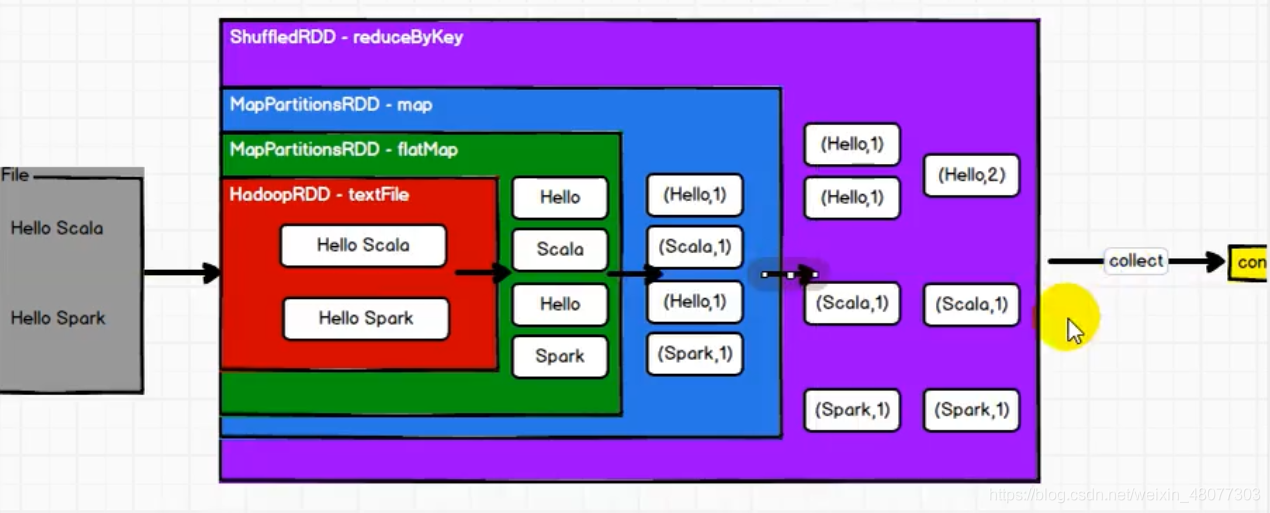
大家看到RDD的處理方式和IO很像,讓我們來總結一下:
- RDD處理方式類似于IO,也是裝飾者設計模式
- 這里一層一層的RDD只是定義了資料的處理邏輯,并不會真正執行,只有當觸發collect方法時才會觸發真正的執行程序,
- IO中有緩沖區;RDD是沒有緩沖區的,不保存資料,
參考資料
《尚硅谷spark3.0》
《Spark權威指南》
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/286930.html
標籤:其他