一、計算機網路
1、網路層次劃分
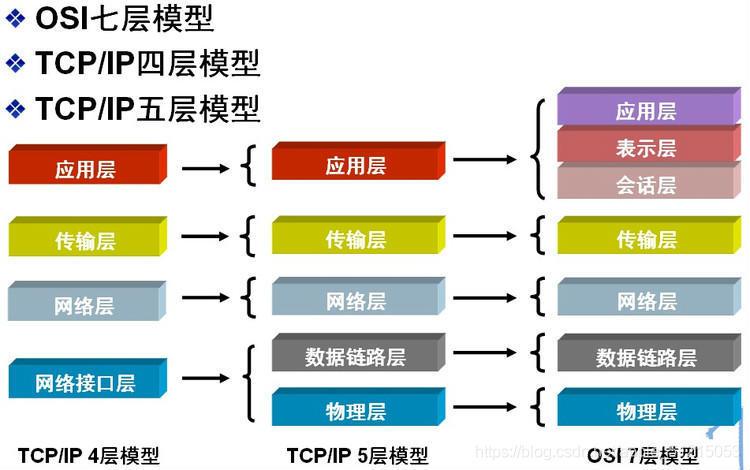
1)OSI模型(七層)
物–>數–>網–>傳–>會–>表–>應
2)TCP/IP模型(五層)
物–>數–>網–>傳–>應
3)TCP/IP模型(四層)
網–>網–>傳–>應
2、七層介紹
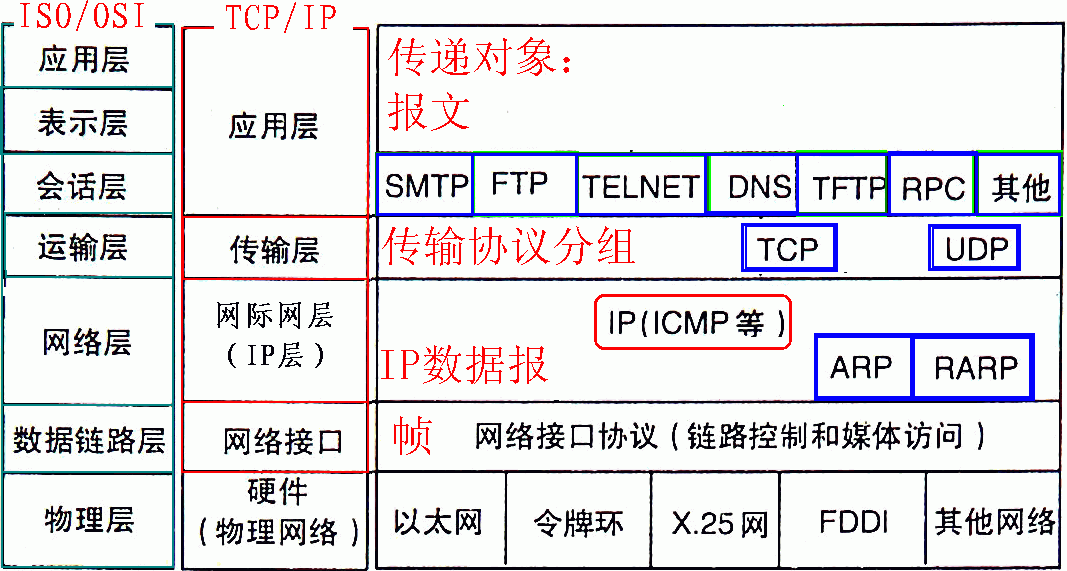
1)物理層
- 簡單的說,物理層確保原始的資料可在各種物理媒體上傳輸,
2)資料鏈路層
- 物理地址尋址、資料的成幀、流量控制、資料的檢錯、重發
- 基本資料單位為幀
3)網路層
- 網路層負責對子網間的資料包進行路由選擇,此外,網路層還可以實作擁塞控制、網際互連等功能;
- 基本資料單位為IP資料報
- 路由器
4)傳輸層
- 負責將資料可靠地傳送到相應的埠
5)會話層
- 負責建立、管理、終止行程之間的會話
6)表現層
- 對資料的加密、壓縮、格式轉換等
7)應用層
- 為作業系統或網路應用程式提供訪問網路服務的介面
- 資料傳輸基本單位為報文;
3、TCP/IP協議
TCP/IP協議是Internet最基本的協議、Internet國際互聯網路的基礎,由網路層的IP協議和傳輸層的TCP協議組成,通俗而言:TCP負責發現傳輸的問題,一有問題就發出信號,要求重新傳輸,直到所有資料安全正確地傳輸到目的地,而IP是給因特網的每一臺聯網設備規定一個地址,
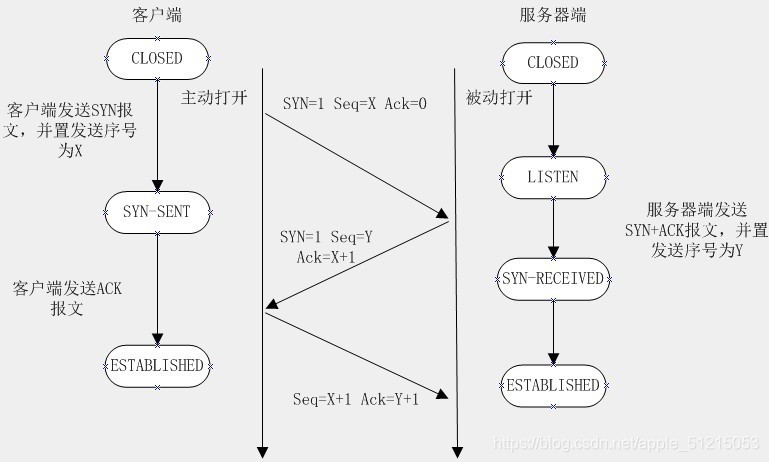
1)三次握手
首先Client端發送連接請求SYN報文,Server段接受連接后回復SYN+ACK報文,并為這次連接分配資源,Client端接收到ACK報文后也向Server段發生ACK報文,并分配資源,這樣TCP連接就建立了,
2)四次揮手
假設Client 端發起中斷連接請求,也就是發送FIN 報文,Server 端接到FIN報文后,意思是說"我Client 端沒有資料要發給你了",但是如果你還有資料沒有發送完成,則不必急著關閉Socket,可以繼續發送資料,所以你先發送ACK,“告訴Client 端,你的請求我收到了,但是我還沒準備好,請繼續你等我的訊息”,這個時候Client 端就進入FIN_WAIT 狀態,繼續等待Server 端的FIN 報文,當Server 端確定資料已發送完成,則向Client 端發送FIN報文,“告訴Client 端,好了,我這邊資料發完了,準備好關閉連接了”,Client 端收到FIN 報文后,“就知道可以關閉連接了,但是他還是不相信網路,怕Server 端不知道要關閉,所以發送ACK 后進入TIME_WAIT狀態,如果Server 端沒有收到ACK 則可以重傳,”,Server 端收到ACK 后,“就知道可以斷開連接了”,Client 端等待了2MSL 后依然沒有收到回復,則證明Server 端已正常關閉,那好,我Client 端也可以關閉連接了,OK,TCP連接就這樣關閉了!
3)為什么要三次握手
在只有兩次"握手"的情形下,假設Client 想跟Server 建立連接,但是卻因為中途連接請求的資料報丟失了,故Client 端不得不重新發送一遍;這個時候Server 端僅收到一個連接請求,因此可以正常的建立連接,但是,有時候Client 端重新發送請求不是因為資料報丟失了,而是有可能資料傳輸程序因為網路并發量很大在某結點被阻塞了,這種情形下Server 端將先后收到2次請求,并持續等待兩個Client 請求向他發送資料…問題就在這里,Client 端實際上只有一次請求,而Server 端卻有2個回應,極端的情況可能由于Client 端多次重新發送請求資料而導致Server 端最后建立了N多個回應在等待,因而造成極大的資源浪費!所以,"三次握手"很有必要!
4)為什么要四次揮手
試想一下,假如現在你是客戶端你想斷開跟Server 的所有連接該怎么做?第一步,你自己先停止向Server 端發送資料,并等待Server 的回復,但事情還沒有完,雖然你自身不往Server 發送資料了,但是因為你們之前已經建立好平等的連接了,所以此時他也有主動權向你發送資料;故Server 端還得終止主動向你發送資料,并等待你的確認,其實,說白了就是保證雙方的一個合約的完整執行!
使用TCP 的協議:FTP(檔案傳輸協議)、Telnet(遠程登錄協議)、SMTP(簡單郵件傳輸協議)、POP3(和SMTP相對,用于接收郵件)、HTTP 協議等,
4、UDP協議
-
UDP 用戶資料報協議,是面向無連接的通訊協議,
-
UDP 資料包括目的埠號和源埠號資訊,由于通訊不需要連接,所以可以實作廣播發送,
1)TCP與UDP的區別
- TCP 是面向連接的,可靠的位元組流服務;
- UDP 是面向無連接的,不可靠的資料報服務,
5、HTTP協議
超文本傳輸協議(HTTP,HyperText Transfer Protocol)是互聯網上應用最為廣泛的一種網路協議,所有的WWW檔案都必須遵守這個標準,
1)HTTP 協議包括哪些請求
-
GET:請求讀取由URL 所標志的資訊,
-
POST:給服務器添加資訊(如注釋),
-
PUT:在給定的URL 下存盤一個檔案,
-
DELETE:洗掉給定的URL 所標志的資源,
2)POST 與 GET 的區別
- Get 是從服務器上獲取資料,Post 是向服務器傳送資料,
- Get 是把引數資料佇列加到提交表單的Action 屬性所指向的URL 中,值和表單內各個欄位一一對應,在URL 中可以看到,
- Get 傳送的資料量小,不能大于2KB;Post 傳送的資料量較大,一般被默認為不受限制,
- 根據HTTP 規范,GET 用于資訊獲取,而且應該是安全的和冪等的,
3)HTTP 與 HTTPS 區別
- HTTP 明文傳輸,資料都是未加密的,安全性較差,HTTPS(SSL+HTTP) 資料傳輸程序是加密的,安全性較好,
- HTTP 頁面回應速度比 HTTPS 快,主要是因為 HTTP 使用 TCP 三次握手建立連接,客戶端和服務器需要交換 3 個包,而 HTTPS除了 TCP 的三個包,還要加上 SSL 握手需要的 9 個包,所以一共是 12 個包,
- HTTP 和 HTTPS 使用的是完全不同的連接方式,用的埠也不一樣,前者是 80,后者是 443,
- HTTPS 其實就是建構在 SSL/TLS 之上的 HTTP 協議,所以,要比較 HTTPS 比 HTTP 要更耗費服務器資源,
二、Java基礎
1、集合
1)Iterator
所有的集合類,都實作了Iterator 介面,這是一個用于遍歷集合中元素的介面,主要包含以下三種方法:
- hasNext() 是否還有下一個元素,
- next() 回傳下一個元素,
- remove() 洗掉當前元素,
2)collection
Collection 介面是集合類的根介面,Java中沒有提供這個介面的直接的實作類,但是卻讓其被繼承產生了兩個介面,就是Set和List,
Set 中不能包含重復的元素,
List 是一個有序的集合,可以包含重復的元素,提供了按索引訪問的方式,
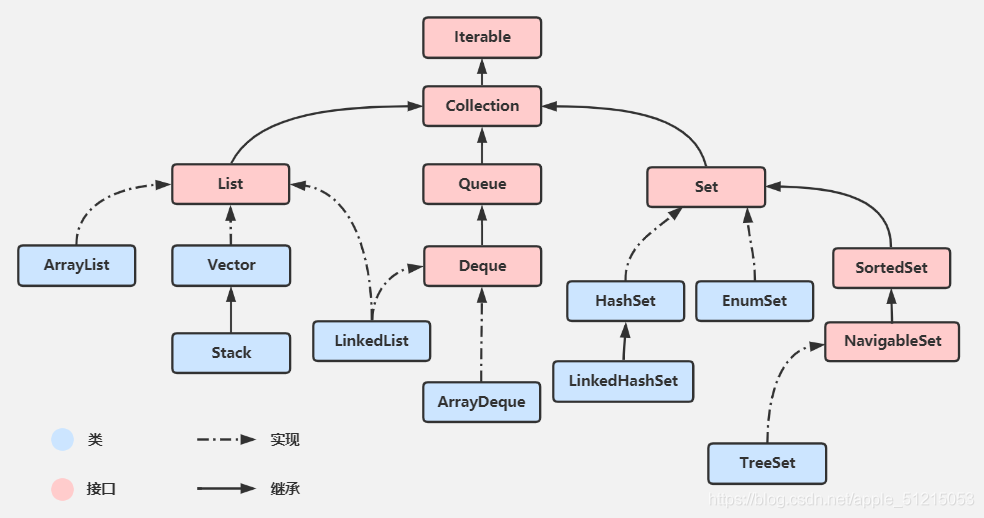
A、List
有序 可以重復
List 里存放的物件是有序的,同時也是可以重復的,
List 關注的是索引,擁有一系列和索引相關的方法,查詢速度快,
因為往list 集合里插入或洗掉資料時,會伴隨著后面資料的移動,所有插入洗掉資料速度慢,
Ⅰ、ArrayList*
- 查詢快 增刪慢
- 底層是動態陣列
- 集合和陣列的相互轉換
- 集合–>陣列:toArray()
- 陣列–>集合:Array. asList(T t)
- 構造方法
- JDK7:底層創建了長度為10的Object[] 陣列
- JDK8:底層Object[] elementData 初始化為{},在使用時才會通過grow() 方法創建一個大小為10的陣列
- 擴容機制(1.5倍)
- JDK7: int newCapacity = (oldCapacity * 3) / 2 + 1
- JDK8: int newCapacity = oldCapacity + (oldCapacity >> 1)
- 執行緒不安全
Ⅱ、LinkedList
- 查詢慢 增刪快
- 底層是雙向鏈表
- 執行緒不安全
Ⅲ、Vector
- 執行緒安全
- 有Synchronized 鎖,效率比ArrayList 低
- 擴容(2倍)
B、Set
無序 不能重復
Set 里存放的物件是無序(即插入順序與取出順序不一致),
不能重復的,集合中的物件不按特定的方式排序,只是簡單地把物件加入集合中,
Ⅰ、HashSet
- 底層是HashMap,value 使用PRESENT 占位
- JDK7:(哈希表結構)陣列+鏈表
- JDK8:(哈希表結構)陣列+鏈表+紅黑樹(鏈表長度大于8之后,使用紅黑樹)
- 需要重寫equals() 和hashCode() 方法,以保證放入物件的一致性
- 不能使用普通for 進行遍歷
- 擴容機制(2倍)
- 加載因子 0.75
- 陣列默認長度16 (2的冪)
Ⅱ、LinkedHashSet
- 有序、不可重復
- 遍歷可以按照添加的順序遍歷
- 對于頻繁遍歷的操作,效率高于HashSet
Ⅲ、TreeSet
- 排序
- 自然排序(元素具備比較性)
讓元素所屬的類實作Comparable 介面,重寫其中的compareTo() 方法 - 比較器排序(集合具備比較性)
讓集合構造方法接收Comparator 的實作類物件,在實作類中重寫compare() 方法
- 自然排序(元素具備比較性)
- 底層是紅黑樹
3)Map
鍵值對 鍵唯一 值不唯一
Map 集合中存盤的是鍵值對,鍵不能重復,值可以重復,
根據鍵得到值,對Map 集合遍歷時先得到鍵的Set集合,再對Set集合進行遍歷,得到相應的值,
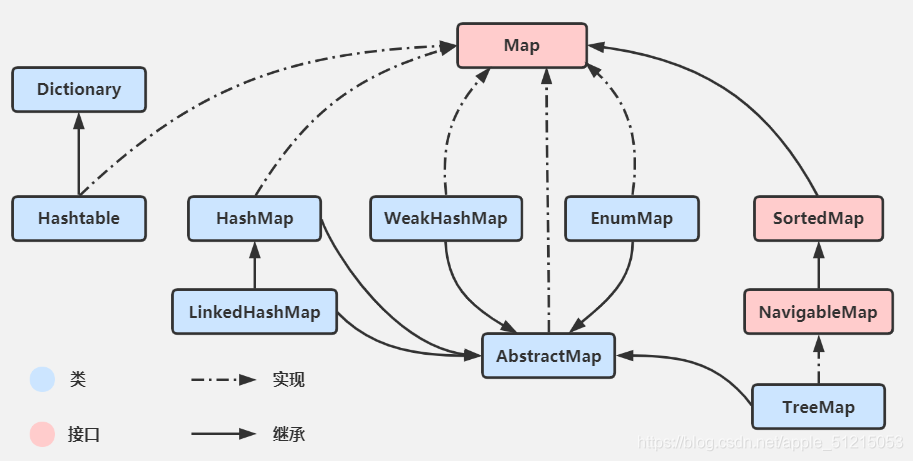
A、HashMap*
-
初始化
- 無參構造(默認長度:16;加載因子:0.75)
- JDK7:呼叫構造器時產生默認長度、加載因子的哈希表,while 方式產生
- JDK8:默認為空,第一次添加資料時進行初始化,位運算方式產生
- 有參構造
- 傳入值為k,初始化為大于k 的2的正數次方,如傳入10,初始化為16
- 無參構造(默認長度:16;加載因子:0.75)
-
底層實作
- JDK7:哈希表(陣列+鏈表)
- 形成鏈表時,采用頭插法,新元素指向舊元素
- 并發環境下,可能產生死鏈(環)
- JDK8:哈希表(陣列+鏈表+紅黑樹)
- 形成鏈表時,采用尾插法,舊元素指向新元素
- 并發環境下,可能產生資料丟失問題
- JDK7:哈希表(陣列+鏈表)
-
加載因子:鍵值對與哈希表長度的比值,超過容量×加載因子的值時進行2倍擴容,會產生復制,頻繁擴容性能下降,
- 加載因子大:哈希表所能容納的資料更多,查找效率會降低,
- 加載因子小:哈希表空間不能充分利用,造成空間上的浪費;
-
允許存在一個為null的鍵或多個為null的value
-
補充
^:二進制異或運算,同零異一
&:與運算,有零為零
“<<”:向左位移,2<<3=16
“>>”:向右位移
“>>>”:無符號右移

B、TreeMap
- 排序
- 自然排序(元素具備比較性)
讓元素所屬的類實作Comparable 介面,重寫其中的compareTo() 方法 - 比較器排序(集合具備比較性)
讓集合構造方法接收Comparator 的實作類物件,在實作類中重寫compare() 方法
- 自然排序(元素具備比較性)
- 底層是紅黑樹
C、HashTable
- 執行緒安全,效率低
- 不能存盤null 的key 和value
- 直接在操作方法上添加synchronized 關鍵字,鎖住整個陣列,顆粒度較大
Ⅰ、 Properties
- 通常用來處理檔案
- key 和value 都是String 型別
D、ConcurrentHashMap*
執行緒安全,并且鎖分離,
ConcurrentHashMap 內部使用段(Segment) 來表示這些不同的部分,每個段其實就是一個小的HashTable,它們有自己的鎖,
只要多個修改操作發生在不同的段上,它們就可以并發進行,
-
解決問題
- 解決了JDK7 中HashMap 由頭插法引起的多執行緒死鏈(環)問題
- 解決了JDK8 中HashMap 有尾插法引起的多執行緒下資料丟失問題
- 提高了HashMap的并發安全性
-
初始化:由餓漢式改為懶漢式(餓漢式創建非常消耗資源)
-
在JDK8 中拋棄了原有的 Segment 分段鎖,而采用了
CAS + synchronized來保證并發安全性, -
Node 屬性是用 volatile 關鍵詞修飾的,保證了記憶體可見性,所以每次獲取時都是最新值,
4)小結
1、equals() 和hashCode()
- 如果兩個物件相等,則hashCode() 一定相同
- 如果兩個物件相等,兩個equals() 回傳true
- 如果兩個物件有相同的hashCode() 值,它們也不一定相等
- equals() 方法被重寫,則hashCode() 方法也必須被重寫
- 若不重寫hashCode() 方法,則兩個物件無論如何都不會相等
2、== 和 equals() 的區別
- == :
- 基本資料型別 比較的是"值"是否相等
- 參考資料型別 比較的是所指物件的地址是否相等
- equals() :
- 基本資料型別 不能比較
- 參考資料型別
- 沒有重寫的話,比較的是所指物件的地址是否相等
- 重寫了的話,如String、Date 等,比較的是所指物件的內容是否相等
3、Vector 和ArrayList
- Vector 是執行緒同步的,所以它也是執行緒安全的,而ArrayList 是執行緒異步的,是不安全的,如果不考慮到執行緒的安全因素,一般用ArrayList 效率比較高,
- 如果集合中的元素的數目大于目前集合陣列的長度時,vector增長率為目前陣列長度的100%(即擴容為原來的兩倍),而ArrayList 增長率為目前陣列長度的50%(即擴容為原來的1.5倍),如果在集合中使用資料量比較大的資料時,用Vector 有一定的優勢,
4、ArrayList 和LinkedList
-
ArrayList 是實作了基于動態陣列的資料結構,LinkedList 基于鏈表的資料結構,
-
對于隨機訪問get和set,ArrayList 優于LinkedList,因為LinkedList 要移動指標,
-
對于新增和洗掉操作add 和remove,LinkedList 比較占優勢,因為ArrayList 要移動資料,
這一點要看實際情況的,若只對單條資料插入或洗掉,ArrayList 的速度反而優于LinkedList,但若是批量隨機的插入洗掉資料,LinkedList的速度大大優于ArrayList,因為ArrayList 每插入一條資料,要移動插入點及之后的所有資料,
5、HashMap 與TreeMap
-
HashMap 通過hashCode 對其內容進行快速查找,而TreeMap 中所有的元素都保持著某種固定的順序,如果你需要得到一個有序的結果你就應該使用TreeMap(HashMap 中元素的排列順序是不固定的),
-
在Map 中插入、洗掉和定位元素,HashMap 是最好的選擇,但如果您要按自然順序或自定義順序遍歷鍵,那么TreeMap 會更好,使用HashMap要求添加的鍵類明確定義了hashCode() 和equals() 的實作,
-
兩個Map 中的元素一樣,但順序不一樣,導致hashCode() 不一樣,
同樣做測驗:
在HashMap 中,同樣的值的Map,順序不同,equals 時,回傳false;而在TreeMap 中,同樣的值的Map,順序不同,equals 時,回傳true,
說明,TreeMap 在equals() 時是整理了順序了的,
6、HashTable 與HashMap
-
同步性:HashTable 是執行緒安全的,也就是說是同步的,而HashMap 是執行緒式不安全的,不是同步的,
-
HashMap 允許存在一個為null 的key,多個為null 的value ;而HashTable 的key 和value 都不允許為null,
-
在Java 1.4中引入了LinkedHashMap,HashMap 的一個子類,假如你想要遍歷順序,你很容易從HashMap轉向LinkedHashMap,但是HashTable不是這樣的,它的順序是不可預知的,
-
HashMap提供對key的Set進行遍歷,因此它是fail-fast 的,但HashTable 提供對key 的Enumeration 進行遍歷,它不支持fail-fast,
-
HashTable 被認為是個遺留的類,如果你尋求在迭代的時候修改Map,你應該使用ConcurrentHashMap,
7、ConcurrentHashMap 與HashMap
- ConcurrentHashMap 的核心資料如 value ,以及鏈表都是 volatile 修飾的,保證了獲取時的可見性,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/286949.html
標籤:其他