微服務架構,是分層架構演程序序中很重要的一環,那微服務是不是越早越好呢?今天和大家一起聊聊這一個問題,
什么時候進行DAO層的分層抽象?
最開始,分層架構長什么樣?
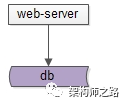
一個業務系統最初的分層架構如上:
(1)web-server層從db層獲取資料并進行加工處理;
(2)db層存盤資料;
此時,web-server層如何獲取底層的資料呢?

web-server層獲取資料的一段偽代碼如上,不用糾結代碼的細節,也不用糾結不同編程語言與不同資料庫驅動的差異,其獲取資料的程序大致為:
(1)創建一個與資料庫的連接,初始化資源;
(2)根據業務拼裝一個SQL陳述句;
(3)通過連接執行SQL陳述句,并獲得結果集;
(4)通過游標遍歷結果集,取出每行資料,亦可從每行資料中取出屬性資料;
(5)關閉資料庫連接,回收資源;
如果業務不復雜,這段代碼寫1次2次還可以,但如果業務越來越復雜,每次都這么獲取資料,就略顯低效了,有大量冗余、重復、每次必寫的代碼,
如何讓資料的獲取更加高效快捷呢?

通過技術手段能夠實作:
(1)表與類的映射;
(2)屬性與成員的映射;
(3)SQL與函式的映射;
絕大部分公司正在用的ORM,DAO等技術,就是一種分層抽象,可以提高資料獲取的效率,屏蔽連接,游標,結果集這些復雜性,
于是,分層架構就演進了,
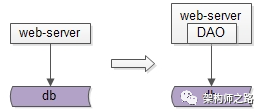
當手寫代碼從DB中獲取資料,成為通用痛點的時候,就應該分層抽象出DAO層,簡化資料獲取程序,提高資料獲取效率,向上游屏蔽底層的復雜性,
然后呢?
抽象出DAO層之后,系統架構并不會一成不變:
(1)隨著業務越來越復雜,業務系統會不斷進行垂直拆分;
(2)隨著資料量越來越大,資料庫會進行水平切分;
(3)隨著讀并發的越來越大,會增加快取降低資料庫的壓力;
于是系統架構變成了這個樣子:
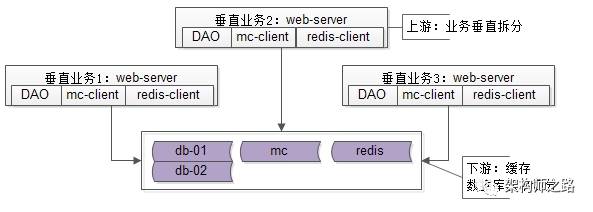
業務系統垂直拆分,資料庫水平切分,快取這些都是常見的架構優化手段,
此時,web-server層如何獲取底層的資料呢?
根據樓主的經驗,以用戶資料為例,流程一般是這樣的:
(1)先查快取:先用uid嘗試從快取獲取資料,如果cache hit,資料獲取成功,回傳User物體,流程結束;
(2)確定路由:如果cache miss,先查詢路由配置,確定uid落在哪個資料庫實體的哪個庫上;
(3)查詢DB:通過DAO從對應庫獲取uid對應的資料物體User;
(4)插入快取:將kv(uid, User)放入快取,以便下次快取查詢資料能夠命中快取;
如果業務不復雜,這段代碼寫1次2次還可以,但如果業務越來越復雜,每次都這么獲取資料,就略顯低效了,有大量冗余、重復、每次必寫的代碼,
特別的,業務垂直拆分成非常多的子系統之后:
(1)一旦底層有稍許變化,所有上游的系統都需要升級修改;
(2)子系統之間很可能出現代碼拷貝;
(3)一旦拷貝代碼,出現一個bug,多個子系統都需要升級修改;
不相信業務會垂直拆分成多個子系統?舉兩個例子:
(1)58同城有招聘、房產、二手、二手車、黃頁等5大頭部業務,都需要訪問用戶資料;
(2)到家集團有月嫂、保姆、快狗打車、藍服等多個業務,也都需要訪問用戶資料;
如果每個子系統都需要關注快取,分庫,讀寫分離的復雜性,呼叫層會瘋掉的,
如何讓資料的獲取更加高效快捷呢?
服務化,資料服務層的抽象勢在必行,
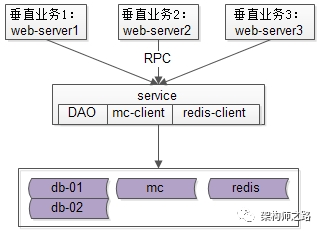
通過抽象資料服務層:
(1)web-server層可以通過RPC介面,像呼叫本地函式一樣呼叫遠端的資料;
(2)資料服務層,只有這一處需要關注快取,分庫,讀寫分離這些復雜性;
于是,分層架構就又演進了,
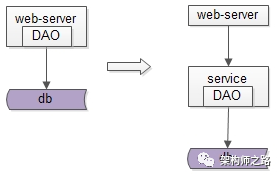
當業務越來越復雜,垂直拆分的系統越來越多,資料庫實施了水平切分,資料層實施了快取加速之后,底層資料獲取復雜性成為通用痛點的時候,就應該抽象出資料服務層,簡化資料獲取程序,提高資料獲取效率,向上游屏蔽底層的復雜性,
那微服務是不是越早越好呢?
互聯網分層架構是一個很有意思的問題,服務化的引入,并不是越早越好:
(1)請求處理時間可能會增加;
(2)運維可能會更加復雜;
(3)定位問題可能會更加麻煩;
千萬別魯莽的在“微服務”大流之下,草率的進行微服務改造,看似“高大上架構”的背后,隱藏著更多并未接觸過的“大坑”,還是那句話,架構和業務的特點和階段有關:一切脫離業務的架構設計,都是耍流氓,
相關推薦:
《InnoDB并發如此高,原因竟然在這?》
《InnoDB索引,終于懂了》
《InnoDB,除錯死鎖的方法!》
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/287092.html
標籤:AI
下一篇:洋蔥omall是什么