今天是打卡面試題的第七天,最近沒有考試了,可以天天打卡了

1.ArrayList 與 Vector 區別
Vector類的所有方法都是同步的,可以由兩個執行緒安全地訪問一個Vector物件、但是一個執行緒訪問Vector的話代碼要在同步操作上耗費大量的時間,
Arraylist不是同步的,所以在不需要保證執行緒安全時時建議使用Arraylist,
2.HashMap 和 Hashtable 的區別
- 執行緒是否安全: HashMap 是非執行緒安全的,HashTable 是執行緒安全的;HashTable 內部的方法基本都經過synchronized 修飾,(如果你要保證執行緒安全的話就使用 ConcurrentHashMap 吧!);
- 效率: 因為執行緒安全的問題,HashMap 要比 HashTable 效率高一點,另外,HashTable 基本被淘汰,不要在代碼中使用它;
- 對Null key 和Null value的支持: HashMap 中,null 可以作為鍵,這樣的鍵只有一個,可以有一個或多個鍵所對應的值為 null,,但是在 HashTable 中 put 進的鍵值只要有一個 null,直接拋出 NullPointerException,
- 初始容量大小和每次擴充容量大小的不同 : ①創建時如果不指定容量初始值,Hashtable 默認的初始大小為11,之后每次擴充,容量變為原來的2n+1,HashMap 默認的初始化大小為16,之后每次擴充,容量變為原來的2倍,②創建時如果給定了容量初始值,那么 Hashtable 會直接使用你給定的大小,而 HashMap 會將其擴充為2的冪次方大小(HashMap 中的 tableSizeFor() 方法保證,下面給出了源代碼),也就是說 HashMap 總是使用2的冪作為哈希表的大小,后面會介紹到為什么是2的冪次方,
- 底層資料結構: JDK1.8 以后的 HashMap 在解決哈希沖突時有了較大的變化,當鏈表長度大于閾值(默認為8)時,將鏈表轉化為紅黑樹,以減少搜索時間,Hashtable 沒有這樣的機制,
3.HashMap 的長度為什么是2的冪次方
為了能讓 HashMap 存取高效,盡量較少碰撞,也就是要盡量把資料分配均勻,我們上面也講到了過了,Hash 值的范圍值-2147483648到2147483647,前后加起來大概40億的映射空間,只要哈希函式映射得比較均勻松散,一般應用是很難出現碰撞的,但問題是一個40億長度的陣列,記憶體是放不下的,所以這個散列值是不能直接拿來用的,用之前還要先做對陣列的長度取模運算,得到的余數才能用來要存放的位置也就是對應的陣列下標,這個陣列下標的計算方法是“ (n - 1) & hash ”,(n代表陣列長度),這也就解釋了 HashMap 的長度為什么是2的冪次方,
這個演算法應該如何設計呢?
我們首先可能會想到采用%取余的操作來實作,但是,重點來了:“取余(%)操作中如果除數是2的冪次則等價于與其除數減一的與(&)操作(也就是說 hash%length==hash&(length-1)的前提是 length 是2的 n 次方;),” 并且 采用二進制位操作 &,相對于%能夠提高運算效率,這就解釋了 HashMap 的長度為什么是2的冪次方,
4.HashMap 多執行緒操作導致死回圈問題
在多執行緒下,進行 put 操作會導致 HashMap 死回圈,原因在于 HashMap 的擴容 resize()方法,由于擴容是新建一個陣列,復制原資料到陣列,由于陣列下標掛有鏈表,所以需要復制鏈表,但是多執行緒操作有可能導致環形鏈表,復制鏈表程序如下:
以下模擬2個執行緒同時擴容,假設,當前 HashMap 的空間為2(臨界值為1),hashcode 分別為 0 和 1,在散列地址 0 處有元素 A 和 B,這時候要添加元素 C,C 經過 hash 運算,得到散列地址為 1,這時候由于超過了臨界值,空間不夠,需要呼叫 resize 方法進行擴容,那么在多執行緒條件下,會出現條件競爭,模擬程序如下:
執行緒一:讀取到當前的 HashMap 情況,在準備擴容時,執行緒二介入
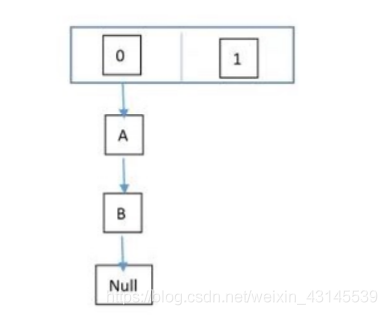
執行緒二:讀取 HashMap,進行擴容
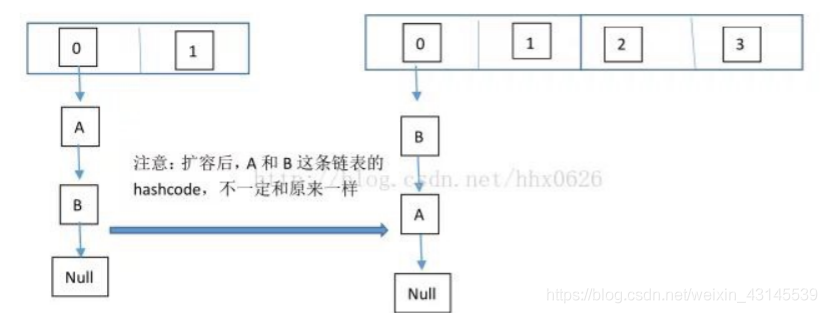
執行緒一:繼續執行
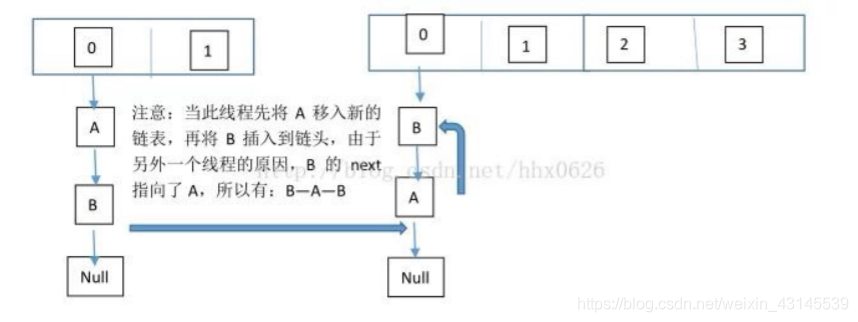
這個程序為,先將 A 復制到新的 hash 表中,然后接著復制 B 到鏈頭(A 的前邊:B.next=A),本來 B.next=null,到此也就結束了(跟執行緒二一樣的程序),但是,由于執行緒二擴容的原因,將 B.next=A,所以,這里繼續復制A,讓A.next=B,由此,環形鏈表出現:B.next=A; A.next=B
5.ConcurrentHashMap 和 Hashtable 的區別
ConcurrentHashMap 和 Hashtable 的區別主要體現在實作執行緒安全的方式上不同,
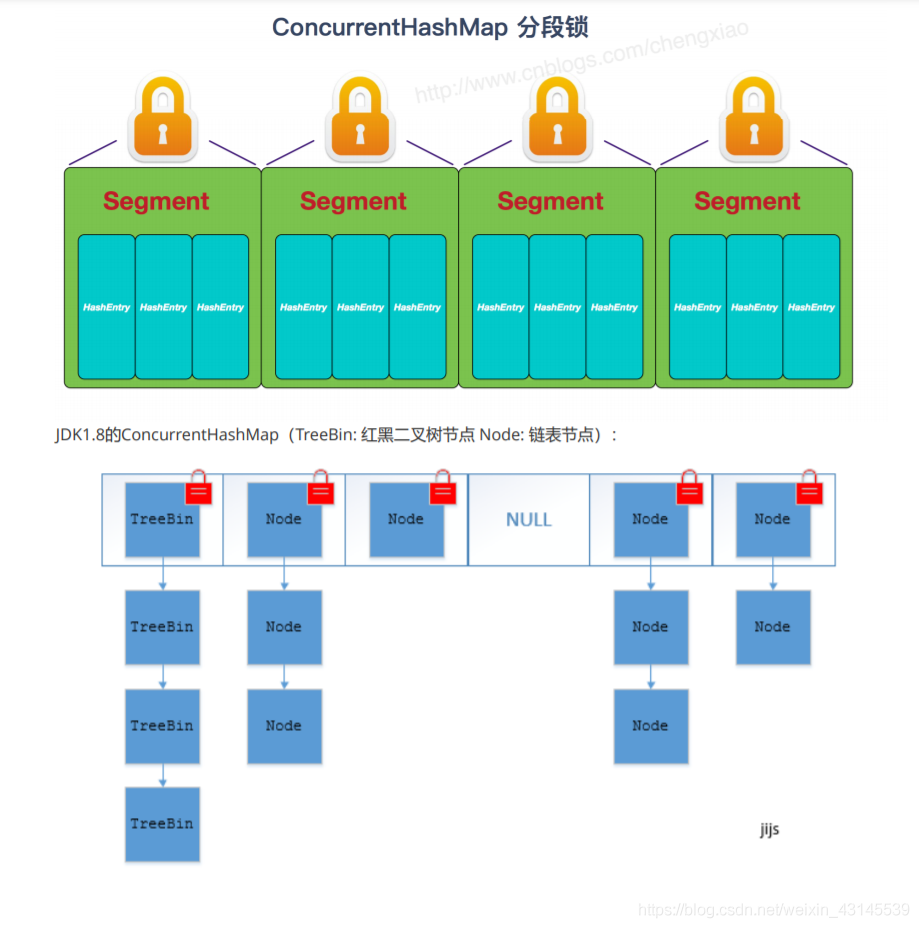
- 底層資料結構: JDK1.7的 ConcurrentHashMap 底層采用 分段的陣列+鏈表 實作,JDK1.8 采用的資料結構跟HashMap1.8的結構一樣,陣列+鏈表/紅黑二叉樹,Hashtable 和 JDK1.8 之前的 HashMap的底層資料結構類 似都是采用 陣列+鏈表 的形式,陣列是 HashMap 的主體,鏈表則是主要為了解決哈希沖突而存在的;
- 實作執行緒安全的方式(重要): ① 在JDK1.7的時候,ConcurrentHashMap(分段鎖)對整個桶陣列進行了分割分段(Segment),每一把鎖只鎖容器其中一部分資料,多執行緒訪問容器里不同資料段的資料,就不會存在鎖競爭,提高并發訪問率,到了 JDK1.8 的時候已經摒棄了Segment的概念,而是直接用 Node 陣列+鏈表+紅黑樹的資料結構來實作,并發控制使用synchronized 和 CAS 來操作,(JDK1.6以后 對 synchronized鎖做了很多優化)整個看起來就像是優化過且執行緒安全的 HashMap,雖然在JDK1.8中還能看到 Segment的資料結構,但是已經簡化了屬性,只是為了兼容舊版本;② Hashtable(同一把鎖) :使用 synchronized來保證執行緒安全,效率非常低下,當一個執行緒訪問同步方法時,其他執行緒也訪問同步方法,可能會進入阻塞或輪詢狀態,如使用pu添加元素,另一個執行緒不能使用 put 添加元素,也不能使用 get,競爭會越來越激烈效率越低,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/287104.html
標籤:其他