記錄一下實驗大作業,資訊較為詳盡,自己跳轉即可
PageRank是Google專有的演算法,用于衡量特定網頁相對于搜索引擎索引中的其他網頁而言的重要程度,實作了將鏈接價值概念作為排名因素,
本實驗基于Hadoop2.7的MapReduce和HDFS實作了簡單版的PageRank演算法【本質是矩陣的迭代運算】
PageRank
- 運行環境
- 演算法原理
- 主要步驟
- Hadoop平臺的配置和啟動
- 實驗資料準備
- Maven專案創建
- 專案依賴包配置pom.xml
- 代碼定義及流程圖
- 資料檔案
- 功能代碼
運行環境
1)Oracle Linux 7.4
2)Hadoop2.7.4
3)JDK-1.8
演算法原理
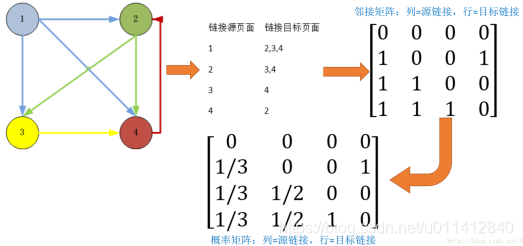
一個頁面的“得票數”由所有鏈向它的頁面的重要性來決定,到一個頁面的超鏈接相當于對該頁投一票,一個頁面的PageRank是由所有鏈向它的頁面(“鏈入頁面”)的重要性經過遞回演算法得到的,也就是從許多優質的網頁鏈接過來的網頁,必定還是優質網頁,
-
兩個假設
數量假設:如果一個頁面節點接收到的其他網頁指向的入鏈數量越多,那么這個頁面越重要,
質量假設:指向頁面A的入鏈質量不同,質量高的頁面會通過鏈接向其他頁面傳遞更多的權重,所以越是質量高的頁面指向頁面A,則頁面A越重要, -
計算公式
P R ( p i ) = 1 ? d n + d ∑ p j ∈ M ( i ) P R ( p j ) l ( j ) PR(p_i)=\frac{1-d}n+d\sum\limits_{p_j\isin M(i)}\frac{PR(p_j)}{l(j)} PR(pi?)=n1?d?+dpj?∈M(i)∑?l(j)PR(pj?)?
其中,n是所有頁面數, P R ( p i ) PR(p_i) PR(pi?)是指頁面 p i p_i pi?的PageRank值, L ( j ) L(j) L(j)是指頁面 p j p_j pj?的鏈出頁面數, M ( i ) M(i) M(i)是指頁面 p i p_i pi?的鏈入頁面數,d是阻尼系數,指用戶繼續向后瀏覽的概率(j->i),Google設為0.85,
-
兩大特征
PR值的傳遞性:網頁A指向網頁B時,A的PR值也部分傳遞給B
重要性的傳遞性:一個重要網頁比一個不重要網頁傳遞的權重要多 -
基本原理
- 初始階段,網頁通過鏈接關系構建起有向圖,每個頁面設定相同的PageRank值,
- 每輪更新計算中,每個頁面將其當前的PageRank值平均分配到本頁面包含的出鏈上(上式中的 P R L \frac{PR}{L} LPR?,代碼中標為pr),將所有指向本頁面的入鏈權值求和,即可得到新的PageRank得分,
- 當每個頁面都獲得了更新后的PageRank值,就完成了一輪PageRank計算,
主要步驟
Hadoop平臺的配置和啟動
hdfs-site.xml和core-site.xml,配置了備份系數dfs.replication為3,
HDFS的默認路徑:hdfs://master:9000
namenode的默認路徑:file:/opt/data/hadoop/dfs/name
datanode的默認路徑:file:/opt/data/hadoop/dfs/data
啟動Hadoop集群:start-all.sh
實驗資料準備
page.csv和pagerank.csv,分別表示網頁鏈入的資訊,網頁初始pr值
Hadoop dfs -put 資料源地址 HDFS目的地址(/root/pagerank/datas/)
Maven專案創建

專案依賴包配置pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>hadoopmr</groupId>
<artifactId>pagerank</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient
</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.2.6</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
</dependencies>
</project>
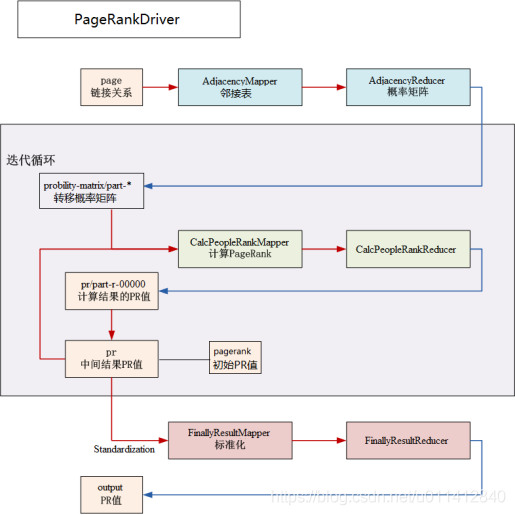
代碼定義及流程圖
- HadoopUtils.java和HDFSUtils.java,重寫函式,并快速呼叫
- PageRankDriver.java,呼叫主函式,設定迭代計算的次數(10)
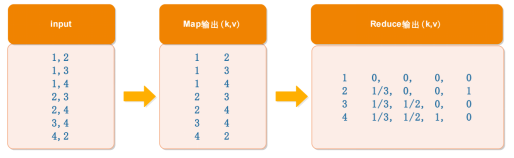
- AdjacencyMatrix.java,將用戶資料轉換成鄰接表和鄰接概率矩陣
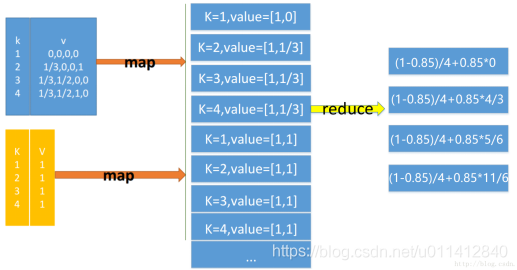
- CalcPageRank.java,將鄰接概率矩陣和pr矩陣進行計算并將得到的pr結果輸出
- Standardization.java,對pr值進行重計算,每個pr都除以pr總值
資料檔案
page.csv
1,2
1,3
1,4
2,3
2,4
3,4
4,2
pagerank.csv
1,1
2,1
3,1
4,1
功能代碼
- HadoopUtils
import java.util.HashMap;
import java.util.Iterator;
import java.util.TreeMap;
import java.util.regex.Pattern;
public class HadoopUtils {
/**
* 分隔符型別,使用正則運算式,表示分隔符為\t或者,
* 使用方法為SPARATOR.split(字串)
*/
public static final Pattern SPARATOR = Pattern.compile("[\t,]");
/**
* 計算unixtime兩兩之間的時間差
* @param timeSortMap key為unixtime,value為pos
* @return key為pos, value為該pos的停留時間
*/
public static HashMap<String, Float> calcStayTime(TreeMap<Long, String> timeSortMap) {
HashMap<String, Float> resMap = new HashMap<String, Float>();
Iterator<Long> iter = timeSortMap.keySet().iterator();
Long currentTimeflag = iter.next();
//遍歷treemap
while (iter.hasNext()) {
Long nextTimeflag = iter.next();
float diff = (nextTimeflag - currentTimeflag) / 60.0f;
//超過60分鐘過濾不計
if (diff <= 60.0) {
String currentPos = timeSortMap.get(currentTimeflag);
if (resMap.containsKey(currentPos)) {
resMap.put(currentPos, resMap.get(currentPos) + diff);
} else {
resMap.put(currentPos, diff);
}
}
currentTimeflag = nextTimeflag;
}
return resMap;
}
}
- HDFSUtils
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
public class HDFSUtils {
private FileSystem fs = null;
public HDFSUtils(Configuration conf){
try {
fs = FileSystem.newInstance(conf);
} catch (IOException e) {
e.printStackTrace();
}
}
public void deleteDir(String path) throws IOException {
Path p = new Path(path);
if(fs.exists(p)) {
fs.delete(p, true);
}
}
public void rename(String src, String dest) throws IOException {
Path p = new Path(src);
Path destPath = new Path(dest);
if(fs.exists(p)) {
this.deleteDir(dest);
fs.rename(p, destPath);
}
}
}
- PageRankDriver
import java.io.IOException;
public class PageRankDriver {
public static void main(String[] args) throws InterruptedException, IOException, ClassNotFoundException {
// 生成概率矩陣
AdjacencyMatrix.run(args);
for (int i = 0; i < 10; i++) {
// 2.迭代10次
CalcPageRank.run(args);
}
// 標準化
Standardization.run();
}
}
- AdjacencyMatrix
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
//將用戶原始資料集轉換成鄰接表->鄰接矩陣->鄰接概率矩陣的程序
public class AdjacencyMatrix {
//輸出鄰接表
public static class AdjacencyMapper extends Mapper<LongWritable, Text, Text, Text> {
Text k = new Text();
Text v = new Text();
@Override
protected void setup(Context context) throws IOException, InterruptedException {
super.setup(context);
System.out.println("AdjacencyMapper input:");
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//列印當前讀入的資料
System.out.println(value.toString());
String[] strArr = HadoopUtils.SPARATOR.split(value.toString());
//原始用戶id為key,目標用戶id為value
k.set(strArr[0]);
v.set(strArr[1]);
context.write(k, v);
}
}
//輸入鄰接表,輸出鄰接概率矩陣
public static class AdjacencyReducer extends Reducer<Text, Text, Text, Text> {
Text v = new Text();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
//初始化概率矩陣,概率矩陣只有一列,函式和總用戶數相同,totalsum=1
int nums = 4;//用戶數
float[] U = new float[nums];//構建用戶鄰接矩陣
int out = 0;//該用戶的鏈出數
StringBuilder printSb = new StringBuilder();
for (Text value : values) {
//從value中拿到目標用戶的id
int targetUserIndex = Integer.parseInt(value.toString());
//鄰接矩陣中每個目標用戶對應的值為1,其余為0
U[targetUserIndex-1] = 1;
out++;
printSb.append(",").append(value.toString());
}
//列印reducer的輸入
System.out.println("AdjacencyReducer input:\n" + key.toString() + ":" + printSb.toString().replaceFirst(",", ""));
//Probability Matrix
StringBuilder stringBuilder = new StringBuilder();
for (int i = 0; i < nums; i++) {
stringBuilder.append(",").append(U[i] / out);
}
v.set(stringBuilder.toString().replaceFirst(",", ""));
System.out.println("AdjacencyReducer output:\n" + key.toString() + ":" + v.toString());
System.out.println();
context.write(key, v);
}
}
public static void run(String[] args) throws InterruptedException, IOException, ClassNotFoundException {
Configuration conf = new Configuration();
args = new String[]{"/root/pagerank/datas/page.csv","/root/pagerank/datas/probility-matrix/"};
Job job = Job.getInstance(conf, "AdjacencyMatrix");
HDFSUtils hdfs = new HDFSUtils(conf);
String inPath = args[0];
String outPath = args[1];
hdfs.deleteDir(outPath);
//指定jar包所在Class檔案
job.setJarByClass(AdjacencyMatrix.class);
//設定map方法(AdjacencyMapper),統一map輸出和reduce輸入的資料型別
job.setMapperClass(AdjacencyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//設定reducer方法(AdjacencyReducer)
job.setReducerClass(AdjacencyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//設定輸入資料和輸出資料路徑
FileInputFormat.addInputPath(job, new Path(inPath));
FileOutputFormat.setOutputPath(job, new Path(outPath));
//輪詢檢查集群是否成功完成任務
job.waitForCompletion(true);
}
public static void main(String[] args) throws Exception {
AdjacencyMatrix.run(args);
}
}
- CalcPageRank
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
//將鄰接概率矩陣和pr矩陣進行計算并將得到的pr結果輸出
public class CalcPageRank {
//輸入鄰接概率矩陣和pr矩陣,按照矩陣相乘的公式,將對應的資料輸出到reduce進行計算
public static class CalcPeopleRankMapper extends Mapper<LongWritable, Text, Text, Text> {
Text k = new Text();
Text v = new Text();
String flag = "";
@Override
protected void setup(Context context) throws IOException, InterruptedException {
super.setup(context);
FileSplit fileSplit = (FileSplit) context.getInputSplit();
flag = fileSplit.getPath().getName();
System.out.println("CalcPeopleRankMapper input type:");
System.out.println(flag);
}
//k的作用是將pr矩陣的列和鄰接矩陣的行對應起來,如:pr矩陣的第一列要和鄰接矩陣的第一行相乘,所以需要同時輸入到reduce中
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
System.out.println(value.toString());//每次map處理的行向量(p1,p2,p3,p4)
int nums = 4;
//處理pr矩陣
if (flag.startsWith("pagerank")) {
//使用正則運算式分隔字串
String[] strArr = HadoopUtils.SPARATOR.split(value.toString());
//第一位為用戶id,輸入的每行內容都為pr矩陣中的一列,所以也可以看成是列數
for (int i = 1; i <= nums; i++) {
k.set(String.valueOf(i));
//pr為識別符號,i為該列中第i行,strArr[1]為值
v.set("pr:" + strArr[0] + "," + strArr[1]);
context.write(k, v);
}
}
//處理鄰接概率矩陣
else {
String[] strArr = HadoopUtils.SPARATOR.split(value.toString());
//k為用戶id,輸入的每行就是鄰接概率矩陣中的一行,所以也可以看成行號
//System.out.println("strArr.length " +strArr.length);
for (int i = 1; i < strArr.length; i++) {
k.set(String.valueOf(i));
//matrix為識別符號,i為該行中第i列(0->i),strArr[i]為值
v.set("matrix:" + strArr[0] + "," + strArr[i]);
context.write(k, v);
}
}
}
}
//每行輸入都是兩個矩陣相乘中對應的值,如:鄰接矩陣的第一行的值和pr矩陣第一列的值
public static class CalcPeopleRankReducer extends Reducer<Text, Text, Text, Text> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
System.out.println("CalcPeopleRankReducer input:");
StringBuilder printStr = new StringBuilder();
Text v = new Text();
int nums = 4;//網頁數量
float d = 0.85f;//阻尼系數
float pr = 0f;//pr統計
//存盤pr矩陣列的值,呼叫HadoopUtils類里的HashMap函式
Map<Integer,Float>prMap = new HashMap<Integer,Float>();
//存盤鄰接矩陣行的值,呼叫HadoopUtils類里的HashMap函式
Map<Integer,Float>matrixMap = new HashMap<Integer,Float>();
//將兩個矩陣對應的值存入對應的map中
for (Text value : values) {
String valueStr = value.toString();
String[] kv = HadoopUtils.SPARATOR.split(valueStr.split(":")[1]);
if (valueStr.startsWith("pr")) {
prMap.put(Integer.parseInt(kv[0]), Float.valueOf(kv[1]));
} else {
matrixMap.put(Integer.parseInt(kv[0]), Float.valueOf(kv[1]));
}
printStr.append(",").append(valueStr);
}
System.out.println(printStr.toString().replaceFirst(",", ""));
//根據map中的資料進行計算(向量內積)
for (Map.Entry<Integer, Float> entry : matrixMap.entrySet()) {
pr += entry.getValue()*prMap.get(entry.getKey());
}
pr = pr*d + (1-d)/nums;//帶阻尼系數的迭代公式
v.set(String.valueOf(pr));
System.out.println("CalcPeopleRankReducer output:");
System.out.println(key.toString() + ":" + v.toString());
System.out.println();
context.write(key, v);
}
}
public static void run(String[] args) throws InterruptedException, IOException, ClassNotFoundException {
//conf構造方法會默認加載hadoop中的兩個組態檔,分別是hdfs-site.xml以及core-site.xml
Configuration conf = new Configuration();
args = new String[]{"/root/pagerank/datas/probility-matrix/part-*","/root/pagerank/datas/pagerank.csv","/root/pagerank/datas/pr/"};
String inPath1 = args[0];//鄰接矩陣(轉移概率矩陣)
String inPath2 = args[1];//初始化PR值(默認為1的列向量)
String outPath = args[2];//未歸一化的PR值
//實體化物件,此物件是static的,可以跨堆疊區域使用
//通過Configuration物件獲取job物件,該job物件會組織所有的該mapreduce的所有各種組件
Job job = Job.getInstance(conf, "AdjacencyMatrix");
//快速操作HDFS,包括deleteDir和rename功能
HDFSUtils hdfs = new HDFSUtils(conf);
hdfs.deleteDir(outPath);//避免重名的檔案夾
//指定jar包所在路徑,本地模式需要這樣指定,
//如果不是本地,則使用setJarByClass指定所在class檔案即可
job.setJarByClass(CalcPageRank.class);
//設定繼承Mapper類的map方法(CalcPeopleRankMapper),統一map輸出和reduce輸入的資料型別
job.setMapperClass(CalcPeopleRankMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//設定繼承Reducer類的reducer方法(CalcPeopleRankReducer)
job.setReducerClass(CalcPeopleRankReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//從地址中讀取,將HDFS的輸入檔案加載給job處理
FileInputFormat.addInputPath(job, new Path(inPath1));
FileInputFormat.addInputPath(job, new Path(inPath2));
//指定HDFS中不存在的路徑作為job的輸出路徑
FileOutputFormat.setOutputPath(job, new Path(outPath));
//向集群提交檔案,輪詢檢查是否成功完成任務,并回傳結果_SUCCESS
job.waitForCompletion(true);
hdfs.deleteDir(inPath2);
hdfs.rename(outPath + "/part-r-00000", inPath2);
}
public static void main(String[] args) throws Exception{
CalcPageRank.run(args);
}
}
- Standardization
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
//對pr值進行重計算,每個pr都除以pr總值
public class Standardization {
public static class FinallyResultMapper extends org.apache.hadoop.mapreduce.Mapper<LongWritable, Text, Text, Text> {
Text k = new Text("finally");
@Override
protected void setup(Context context) throws IOException, InterruptedException {
super.setup(context);
System.out.println("Initial Standardization input:");
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
System.out.println(value.toString());
context.write(k,value);
}
}
public static class FinallyResultReducer extends org.apache.hadoop.mapreduce.Reducer<Text, Text, Text, Text> {
Text k = new Text();
Text v = new Text();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
System.out.println("Standardization input:");
//設定字串緩沖區,將給定的資料轉換成字串,方便添加或插入
StringBuilder printStr = new StringBuilder();
float totalPr = 0f;
//設定可動態修改的pr陣列list
List<String> list = new ArrayList<String>();
for (Text value : values) {
String valueStr = value.toString();
list.add(valueStr);
String[] strArr = HadoopUtils.SPARATOR.split(valueStr);
totalPr += Float.parseFloat(strArr[1]);
printStr.append(valueStr).append("\n");
}
System.out.println(printStr.toString().replace(",", ""));
for (String s : list) {
String[] strArr = HadoopUtils.SPARATOR.split(s);
k.set(strArr[0]);
//標準化公式是除以pr總和
v.set(String.valueOf(Float.parseFloat(strArr[1])/totalPr));
context.write(k, v);
System.out.println("Standardization output:");
System.out.println(k.toString() + ": " + v.toString());
System.out.println();
}
}
}
public static void run() throws InterruptedException, IOException, ClassNotFoundException {
Configuration conf = new Configuration();
String inPath = "/root/pagerank/datas/pagerank.csv";
String outPath = "/root/pagerank/output/";
Job job = Job.getInstance(conf, "AdjacencyMatrix");
HDFSUtils hdfs = new HDFSUtils(conf);
hdfs.deleteDir(outPath);
//指定jar包所在Class檔案
job.setJarByClass(Standardization.class);
//設定map方法(FinallyResultMapper),統一map輸出和reduce輸入的資料型別
job.setMapperClass(FinallyResultMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//設定reducer方法(FinallyResultReducer)
job.setReducerClass(FinallyResultReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//設定輸入資料和輸出資料路徑
FileInputFormat.addInputPath(job, new Path(inPath));
FileOutputFormat.setOutputPath(job, new Path(outPath));
//輪詢檢查集群是否成功完成任務
job.waitForCompletion(true);
}
public static void main(String[] args) throws Exception{
Standardization.run();
}
}
參考鏈接1
參考鏈接2
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/287120.html
標籤:其他