前言:
Apache Spark 是專為大資料處理而設計的快速的計算引擎,Spark擁有Hadoop MapReduce所具有的優點;但不同于MapReduce的是—spark的輸出結果可以保存在記憶體中,不用再進行HDFS的讀寫,因此Spark被廣泛用于機器學習跟需要迭代計算類的演算法,但是面對大量需要處理的資料,要讓Spark穩定快速的運行,這就需要對Spark進行全方位的調優,從而在作業中擁有更高的處理效率,本篇文章主要對Spark如何進行全方位的調優進行闡述
主要從下面幾點對Spark進行調優:
1.避免RDD重復創建
RDD是一個編程模型,是一種容錯的,并行的資料結構,可以讓用戶顯示的將資料儲存在磁盤與記憶體中,并且可以控制資料的磁區,RDD一個很重要的特性就是可以相互依賴,如果RDD的每個磁區只可以被一個子RDD磁區使用,則稱之為窄依賴,可以被多個RDD磁區使用則稱之為寬依賴,我們在進行一個Spark作業的時候,一般會讀取一個資料源作為一個初始的RDD,之后以此RDD為開始得到后面需要的RDD,形成一個RDD關系鏈,
在進行RDD創建的時候要避免RDD的重復創建,也就是不要對一份資料進行創建多個相同的RDD,重復創建RDD會對Spark帶來更大的性能開銷,如下:
//錯誤的創建RDD的方式
val rdd1 = sc.textFile("hdfs://localhost:9000/test.txt")
rdd1.map()
val rdd2 = sc.textFile("hdfs://localhost:9000/test.txt")
rdd2.reduce()
//正確的RDD創建方式形成一條RDD鏈
val rdd1 = sc.textFile("hdfs://localhost:9000/test.txt")
val rdd2=rdd1.map()
rdd2.reduce()
2.日志收集:
在執行作業的時候報錯可以說是每一個技術人員都會遇到的事情,Spark提供的作業日志就可以很好的幫助我們對出現的問題進行定位,Spark日志通常是排錯的唯一根據,一般的報錯我們可以從Spark的Driver日志中進行定位,也可以通過yarn-client的模式執行,將日志輸出到客戶端,方便我們進行查看,如下:
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
--executor-memory 20G \
--num-executors 50 \
/app/spark-2.2/examples/jars/xx.jar //這里指定自己路徑的jar包

根據運行的ID號可以查看到日志
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-HSr1zXxF-1623510078322)(C:\Users\MI\AppData\Roaming\Typora\typora-user-images\image-20210609093544933.png)]](https://img.uj5u.com/2021/06/14/244226140654243.png)
使用這種方式進行報錯日志的定位往往是最有效的解決問題的辦法,
3.提高Shuffle性能
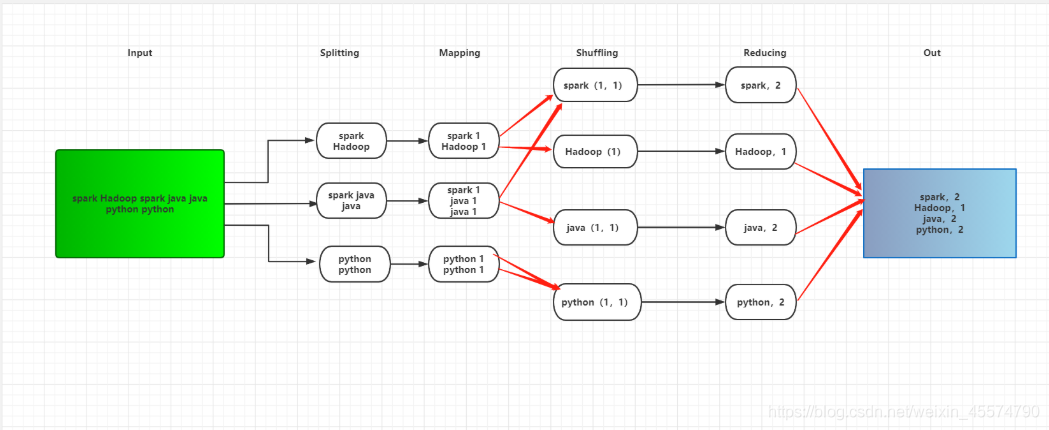
Shuffle表示資料從Map Task輸出到Reduce Task輸入的這段程序,shuffle是連接Map和Reduce之間的橋梁,Map的輸出要用到Reduce中必須經過shuffle這個環節,shuffle的性能高低直接影響了整個程式的性能和吞吐量,同時,Shuffle也是Spark進行作業的時候很關鍵的一個環節,也是對Spark進行性能調優的一個重點,下面是Spark進行詞頻統計作業時候的Map Reduce的程序
Spark中與Shuffle性能有關的引數:
spark.shuffle.file.buffer
spark.reducer.maxSizeInFlight
spark.shuffle.compress
1.第一個配置是Map端輸出結果的緩沖區大小,
2.第二個配置是Map端輸出結果檔案的大小,
3.第三個配置是Map端是否開啟壓縮
第一個配置當然是越高越好,緩沖區越大,資料寫入的性能可想而知也是會越高的,所以如果機器條件優越的情況下,這個可以盡可能的調大,來提高Shuffle性能,在Reduce的程序中Reduce的Task所在的位置會按照spark.reducer.maxSizeInFlight的配置大小去拉取檔案,之后用記憶體緩沖區來接收,所以提高spark.reducer.maxSizeInFlight的引數大小也是可以提高Shuffle的效率的,第三個配置一般都是默認開啟的,默認對Map端的輸出進行壓縮操作,
4.Spark作業并行程度
在Spark作業進行的時候,提高Spark作業的并行程度是提高運行效率的最有效的辦法,那么我們應該要明確spark中的并行度是指什么?spark中的并行度指的就是各個stage里面task的數量,
spark.default.parallelism
textfile()
可以根據地2個引數來設定該作業的并行度,Spark任務的RDD一開始的磁區數量時與HDFS上的資料塊數量保持一致的,通過coalesce 與 repartition 算子可以進行重磁區,但是這個操作并不可以改變Rdeduce的磁區數,改變的只是Map端的磁區數量,想要對Reduce端的磁區數量進行修改,就可以對spark.default.parallelism配置進行修改,通過在官網的描述中,設定的并行度為這個application 中cpu-core數量的2到3倍為最優,
5.記憶體管理
Spark作業中記憶體的主要用途就是計算跟儲存,Spark在執行程式的時候,集群就會啟動Driver和Executor兩種JVM行程,Driver為主控行程,Executor負責執行具體的計算任務, spark的行程是JVM行程,所以Executor的記憶體管理是建立在 JVM 的記憶體管理之上,所以還涉及到了堆的概念,記憶體受到 JVM 統一管理這一點就導致spark釋放記憶體的時候收到限制,所以Spark引入了堆外記憶體,
只要是在Executor內運行的任務一律共享 JVM 堆記憶體,按照用途主要可以分為三大類:Storage負責快取資料和廣播變數資料,Execution負責執行Shuffle程序中占用的記憶體,剩下空間則是儲存Spark內部的物件實體,Spark雖然不可以精準的對堆記憶體進行控制,但是通過決定是否要在儲存的記憶體里面快取新的RDD,是否為新的任務分配執行記憶體,也可以提高記憶體的利用率,相關的引數配置如下:
spark.memory.fraction
spark.memory.storageFraction
更改引數配置spark.memory.fraction可調整storage+executor總共占記憶體的百分比,更改配置spark.memory.storageFraction可調整storage占二者記憶體和的百分比,這兩個引數一般使用默認值就可以滿足我們絕大部分的作業的要求了,
再說說Spark的堆外記憶體,為了提高Spark記憶體的使用以及提高Shuffle時的效率,Spark引入了堆外(Off-heap)記憶體,在默認的情況下堆外記憶體是不會啟用的,可以通過如下引數進行開啟:
spark.memory.offHeap.enabled
Spark Executor可以通過引數spark.yarn.executor.memoryoverhead 進行配置,最小為 384MB,默認為 Executor 記憶體的 10%,配置堆外記憶體大小的引數為spark.memory.offHeap.size,堆外記憶體與堆記憶體的劃分方式其實是相同的,用戶需要知道每個部分的大小如何調節,才能針對場景進行調優,這個對于普通用戶來說其實不是特別的友好,
6.Spark資料快取
Spark速度非常快的原因之一,就是在不同操作中可以在記憶體中持久化或快取資料集,RDD通過persist方法或cache方法可以將前面的計算結果進行快取,但是要注意的是并不會馬上進行快取,而是觸發后面的action動作的時候,RDD才會被快取在計算節點的記憶體中,如果某一份資料要被重復使用的時候,就可以使用cache算子進行快取,可以達到很不錯的效果
7.對filter產生的磁區進行聚合
Spark 的filter算子主要用于資料過濾,回傳一個新的RDD,該RDD由經過func函式計算后回傳值為true的輸入元素組成,在執行這個算子的時候資料一般會被拆分成多個磁區,這些磁區也會影響到后面的計算,所以在執行這個算子的時候用 coalesce 算子進行一次合并,也可以對作業的執行速度達到提升,
8.處理資料傾斜
資料傾斜是資料處理作業中一個很常見的問題, 正常情況下,資料通常都會出現資料傾斜的問題,只不過嚴重程度不一,資料傾斜的癥狀是大量資料集中到一個或者幾個任務里,導致這幾個任務計算大量資料,拖慢整個作業的執行速度,這里給大家詳細分析一下資料傾斜是怎么出現的,
我們都知道在執行shuffle操作的時候,程式是按照key進行統計聚合,來進行values的資料的輸出、拉取和聚合的,同一個key的values,會被程式分配到一個Reduce task進行處理,但是這個時候如果你處理的是大量的資料,問題可能就要出現了,大量資料必定有多個Key,多個Key對應的values,舉個例子假如一共100萬資料,可能程式執行后,某個聚合的key對應了98萬資料,這些資料全部被分配到一個task上去面去執行,另外兩個task,可能各分配到了1萬資料,也可能是幾百個key被對應到了剩余的兩萬條資料,這個時候資料傾斜的問題就出現了,而且對于Spark作業的整體性能來說是及其不樂觀的,場景如下:
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-xu5r83Bk-1623510078325)(C:\Users\MI\AppData\Roaming\Typora\typora-user-images\image-20210612224028282.png)]](https://img.uj5u.com/2021/06/14/244226140654245.png)
對應資料發生傾斜的情況,可以采用如下幾種解決辦法:
1.對源資料進行聚合
Spark中一些用于聚合操作的算子,比如groupByKey、reduceByKey,這些算子都是要去拿到每個key對應的values進行計算的,在一些大資料量的計算中,我們可以找到資料的一些維度進行一步聚合,比如說是時間維度的年月日,城市的地區等等,聚合了第一個維度之火再進行下一步的聚合
2.對臟資料進行首先過濾
對應源資料處理中,必定是會存在很多臟資料,這個也是導致資料傾斜的重要原因之一,這個時候我們需要第一步將臟資料進行過濾
3.使用廣播變數
在作業進行連接操作的時候,我們可以將小表通過廣播變數進行廣播,這樣可以避免Shuffle程序,讓資料相對比較均勻的分布在Map任務,
4.提高作業的并行度
這個方式在前面我們也說到過如何進行引數配置,但是要注意的是,這個配置只是提高瀏覽作業的運行速度,但是并不能從根本上解決資料傾斜的問題,
5.使用隨機Key進行雙重聚合
groupByKey、reduceByKey比較適合使用這種方式,join操作通常不會這樣來做,
到這里,相信大家對與Spark如何進行調優也有了全新的認識!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/287127.html
標籤:其他
上一篇:阿里巴巴如何面試?網友分享出你不知道的真實面試流程(轉發給有需要的人)
下一篇:華科LaTeX模板使用指北