目錄
- 0. 背景知識補充
- 1. 雞尾酒會問題
- 2. Speaker Separation
- 2.1 兩人的單通道語音分離
- 2.2 評估指標
- 2.2.1 信噪比(signal-to-noise ratio, SNR)
- 2.2.2 SI-SNR/SI-SDR
- 2.2.3 SI-SDR improvement
- 2.2.4 其它
- 3. Permutation Issue
- 4. Deep Clustering
- 4.1 Mask
- 4.2 Ideal Binary Mask
- 4.3 訓練程序
- 5. Permutation Invariant Training(PIT)
- 6. TasNet
- 7. 更新的研究
- 參考資料
0. 背景知識補充
對語音方向了解甚少,只是簡單地把查到的資料做個記錄
主要參考:語音識別的技術原理是什么? - 張俊博的回答 - 知乎
聲音實際上是一種波,
在開始語音識別之前,有時需要把首尾端的靜音切除,降低對后續步驟造成的干擾,這個靜音切除的操作一般稱為VAD,需要用到信號處理的一些技術,
要對聲音進行分析,需要對聲音分幀,也就是把聲音切開成一小段一小段,每小段稱為一幀,分幀操作一般不是簡單的切開,而是使用移動窗函式來實作,這里不詳述,幀與幀之間一般是有交疊的,就像下圖這樣:
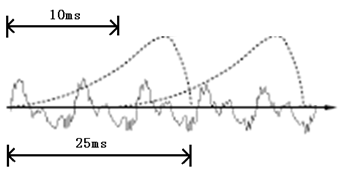
圖中,每幀的長度為25毫秒,每兩幀之間有25-10=15毫秒的交疊,我們稱為以幀長25ms、幀移10ms分幀,
分幀后,語音就變成了很多小段,但波形在時域上幾乎沒有描述能力,因此必須將波形作變換,常見的一種變換方法是提取MFCC特征,根據人耳的生理特性,把每一幀波形變成一個多維向量,可以簡單地理解為這個向量包含了這幀語音的內容資訊,這個程序叫做聲學特征提取,
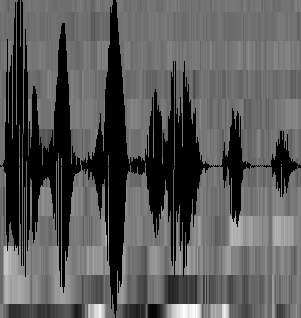
至此,聲音就成了一個12行(假設聲學特征是12維)、N列的一個矩陣,稱之為觀程式列,這里N為總幀數,
觀程式列如下圖所示,圖中,每一幀都用一個12維的向量表示,色塊的顏色深淺表示向量值的大小,
MFCCs中文名為“ 梅爾倒頻譜系數 ”(Mel Frequency Cepstral Coefficents)是一種在自動語音和說話人識別中廣泛使用的特征,
MFCC提取程序包括預處理、快速傅里葉變換、Mei濾波器組、對數運算、離散余弦變換、動態特征提取等步驟,
短時傅里葉變換(STFT)是最經典的時頻域分析方法,所謂短時傅里葉變換,是對短時的信號做傅里葉變化,
把一段長信號分幀、加窗,再對每一幀做傅里葉變換(FFT),最后把每一幀的結果沿另一個維度堆疊起來,得到類似于一幅圖的二維信號形式,如果我們原始信號是聲音信號,那么通過STFT展開得到的二維信號就是所謂的聲譜圖(Spectrogram),
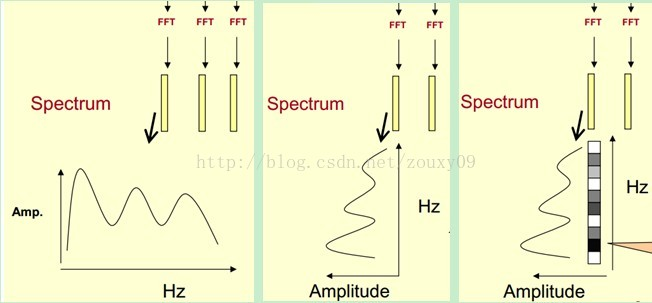
圖中用顏色表示不同頻率對應的分量大小,
1. 雞尾酒會問題
1953年,Colin Cherry提出了著名的”雞尾酒會”問題:在嘈雜的室內環境中,比如在雞尾酒會中,同時存在著許多不同的聲源:多個人同時說話的聲音、餐具的碰撞聲、音樂聲以及這些聲音經墻壁和室內的物體反射所產生的反射聲等,在聲波的傳遞程序中,不同聲源所發出的聲波之間(不同人說話的聲音以及其他物體振動發出的聲音)以及直達聲和反射聲之間會在傳播介質(通常是空氣)中相疊加而 形成復雜的混合聲波,因此,在到達聽者外耳道的混合聲波中已經不存在獨立的與各個聲源相對應的聲波了,然而,在這種聲學環境下,聽者卻能夠在相當的程度上聽懂所注意的目標陳述句,
“語音分離”(Speech Separation)來自于“雞尾酒會問題”,采集的音頻信號中除了主說話人之外,還有其他人說話聲的干擾和噪音干擾,語音分離的目標就是從這些干擾中分離出主說話人的語音,
由于麥克風采集到的聲音中可能包括噪聲、其他人說話的聲音、混響等干擾,不做語音分離、直接進行識別的話,會影響到識別的準確率,因此在語音識別的前端加上語音分離技術,把目標說話人的聲音和其它干擾分開就可以提高語音識別系統的魯棒性,
根據干擾的不同,語音分離任務可以分為三類:
-
當干擾為噪聲信號時,可以稱為“語音增強”(Speech Enhancement)
-
當干擾為其他說話人時,可以稱為“多說話人分離”(Speaker Separation)
-
當干擾為目標說話人自己聲音的反射波時,可以稱為“解混響”(De-reverberation)
2. Speaker Separation
這一節課李老師主要講的是“多說話人分離”(Speaker Separation)問題,
2.1 兩人的單通道語音分離
這節課主要講的是兩人的單通道語音分離
最基本的情況,將兩端音頻信號混合而成的信號分開,
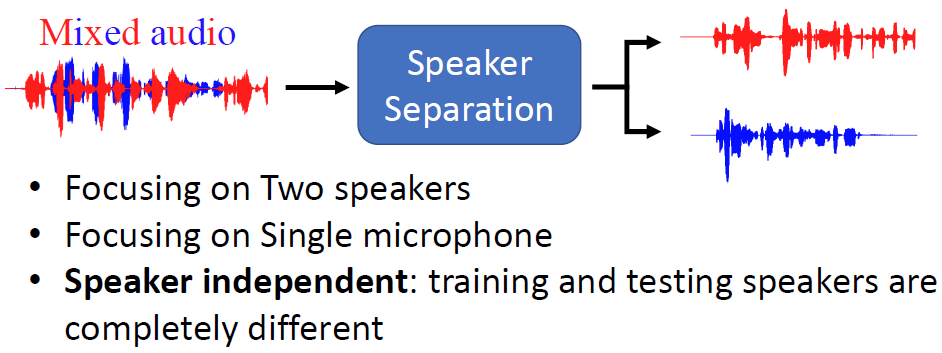
模型的輸出是分離出的兩個說話人的語音信號,輸入輸出維度是一致的,
訓練資料是比較好獲得的
可以自己用兩段聲音信號產生混合聲音信號做訓練資料,這兩段原本的聲音信號就是ground truth,
2.2 評估指標
2.2.1 信噪比(signal-to-noise ratio, SNR)
假設模型輸出的生成向量為
X
?
X^*
X?,真實向量為
X
^
\hat{X}
X^,
使用SNR作為評估指標存在如下問題:
- 當真實向量與生成向量的向量方向相同時(意味著只是聲音響度的大小不同),這時候的分離效果無疑是理想的,但根據SNR計算出的結果仍會表示存在較大誤差,
- 當真實向量與生成向量的向量方向不同時,不改變
X
?
X^*
X?的方向,只是增大向量的長度,就可以產生更小的誤差,顯然這樣是不合理的,模型可能會學會產生輸出信號音量更大的模型,但不一定能提升語音分離的效果,
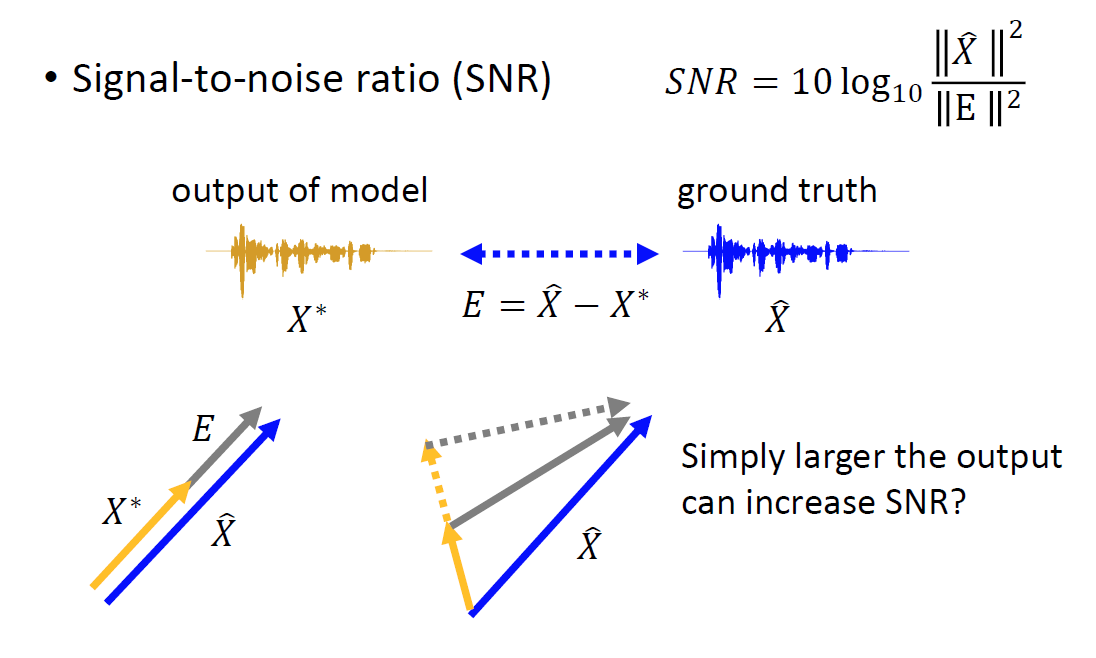
簡單地說,有理不在聲高,
試想,如果我們成功分離出了某人的聲音信號,其說話的音量大小不應該成為分離結果的正確性的判斷標準,
2.2.2 SI-SNR/SI-SDR
改進的指標SI-SNR或者叫SI-SDR,也是文獻中常用的評估方法
將生成向量
X
?
X^*
X?投影到真實向量
X
^
\hat{X}
X^的垂直方向,稱為
X
E
X_E
XE?,投影到
X
^
\hat{X}
X^的方向,稱為
X
T
X_T
XT?
在生成向量與真實向量平行的時候(分離結果最理想),SI-SDR是無限大的
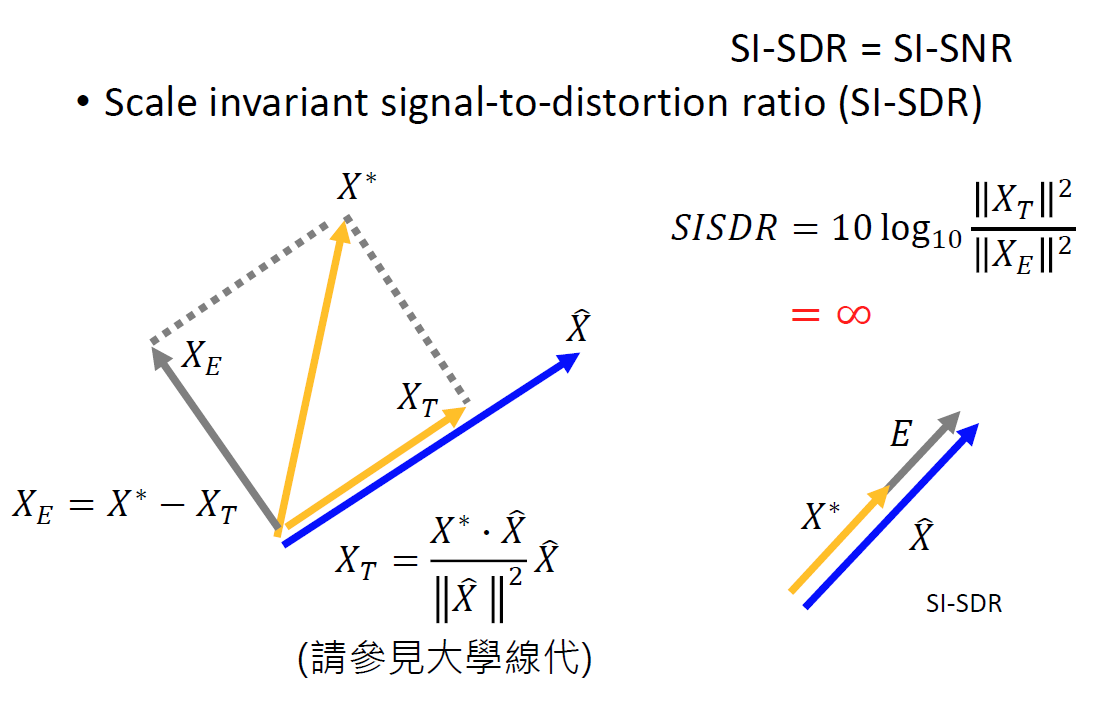
生成向量方向與真實向量的偏差越大,
X
E
X_E
XE?的值就越大,SI-SDR的值就越小,
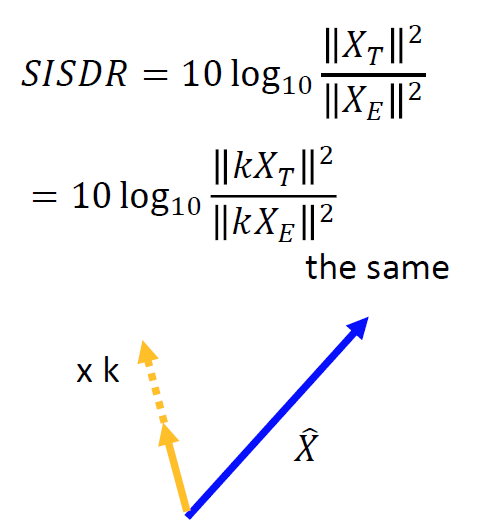
同時,生成向量的模值也不會影響評估指標,
2.2.3 SI-SDR improvement
該方法作為SI-SDR的升級版,
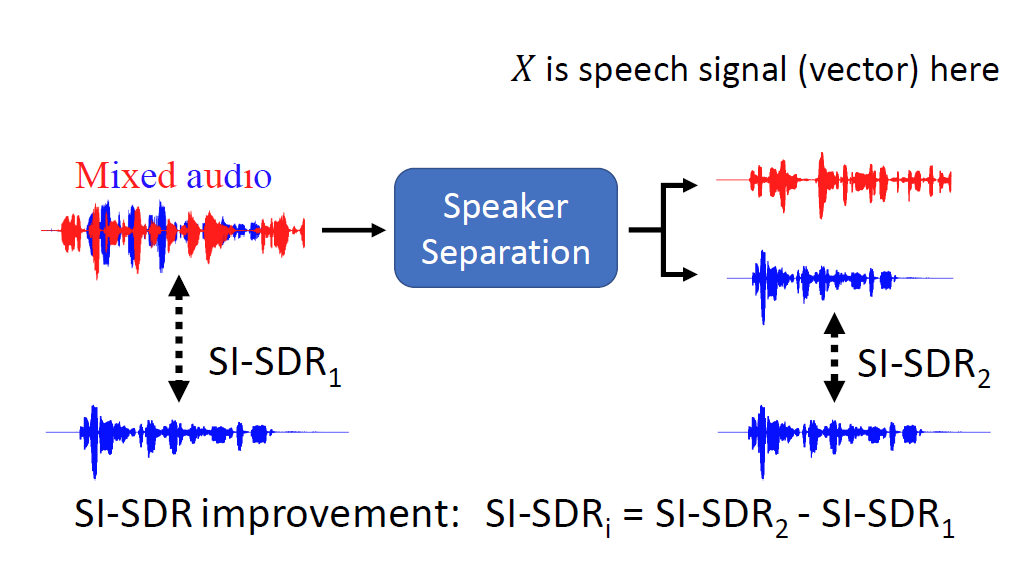
分別用混合的語音信號和分離出來的語音信號和真實信號做SI-SDR運算,然后用后者減去前者(信號越相似,SI-SDR值越大),因為噪音信號可能很小,我們更看重SI-SDR的improvment而不是絕對值,
2.2.4 其它
此外評價指標還包括PESQ(聽感質量)、STOI(易懂度)等,

3. Permutation Issue
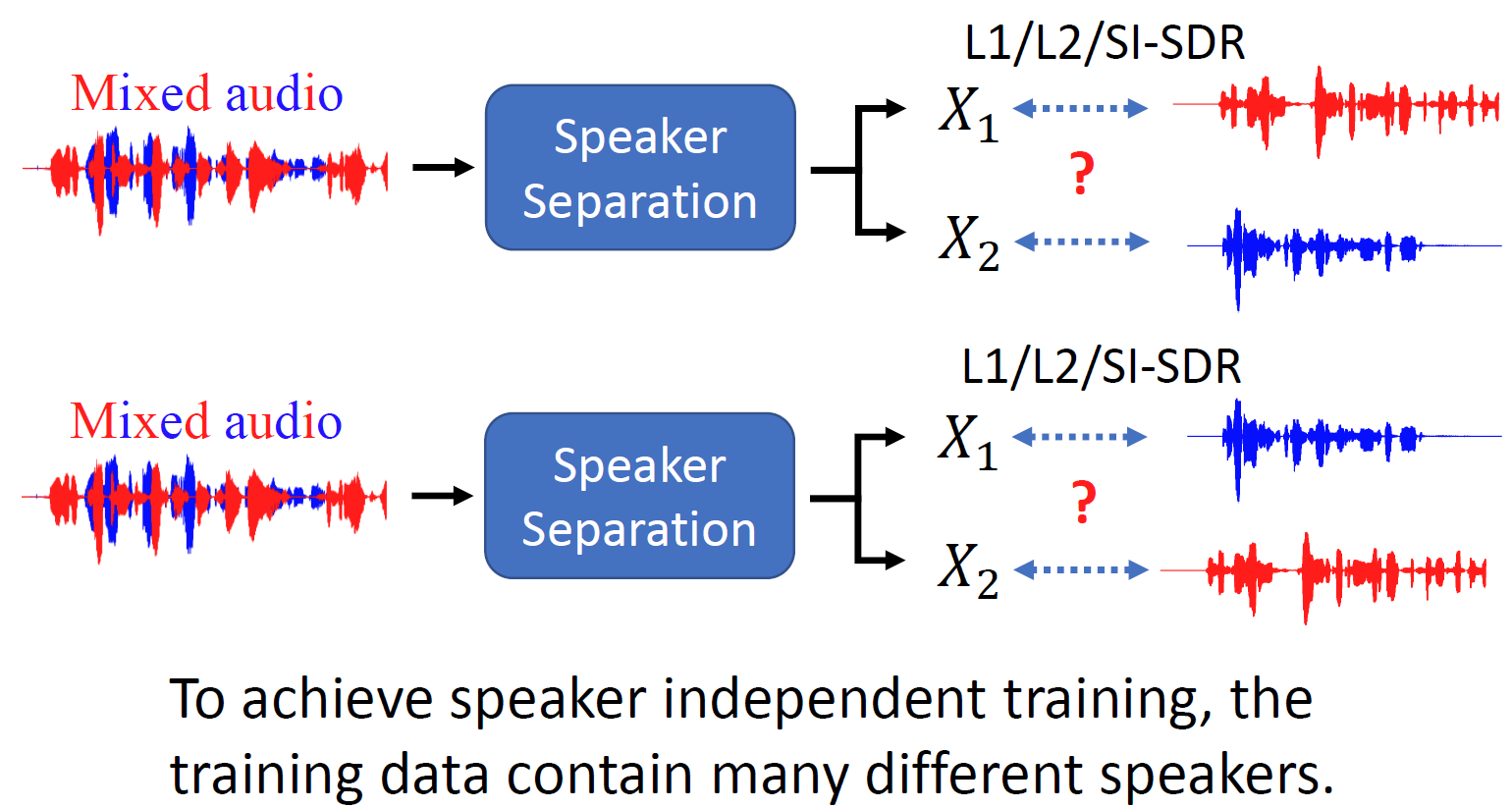
在訓練集資料中speaker是獨立的時候,無法確定輸出的兩路信號,誰對應哪個原信號,
假設我們有下面這樣兩條訓練資料:
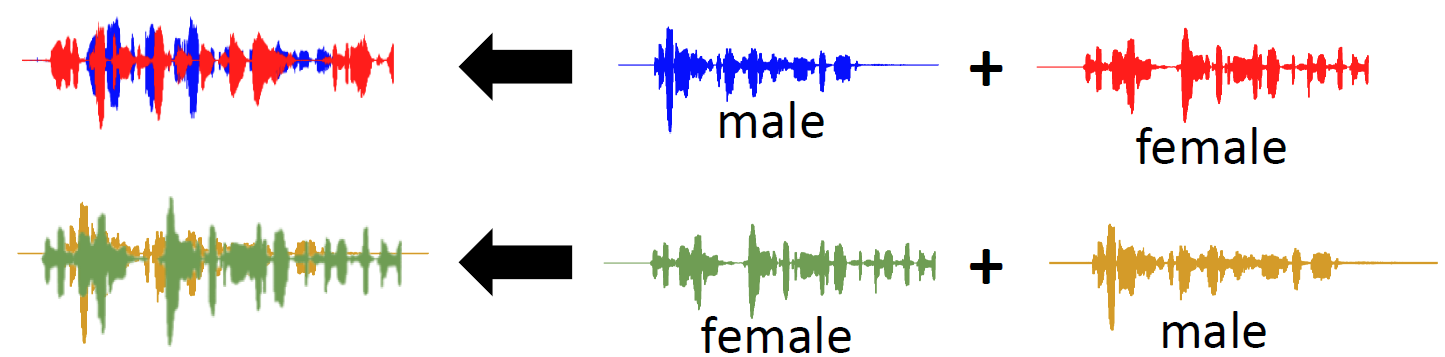
會有兩種對齊網路輸出與label的方式
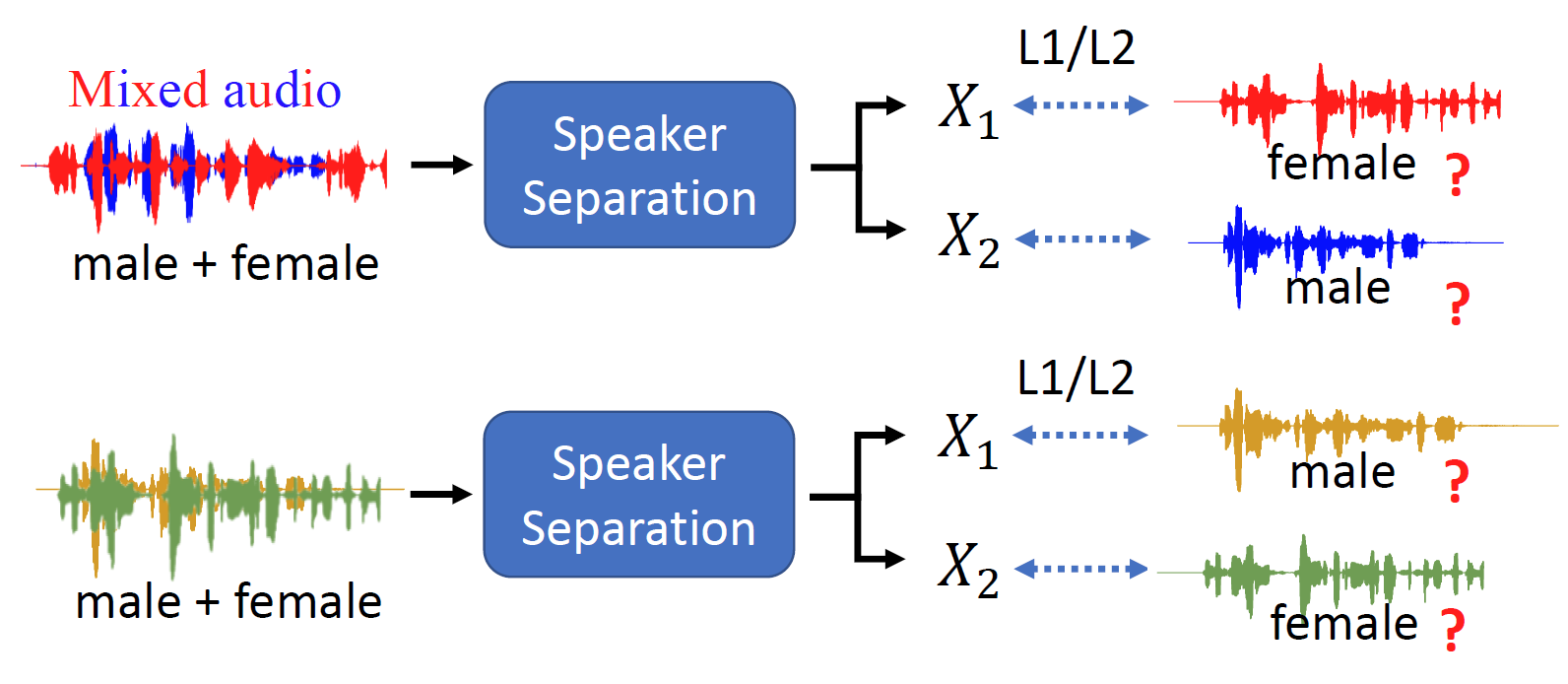
我們不知道把
X
1
X_1
X1?對應female,
X
2
X_2
X2?對應male這種方式,來計算損失函式訓練網路的效果是不是好過另一種擺放,
4. Deep Clustering
4.1 Mask
不是訓練一個網路,生成兩個矩陣(將語音信號看作一個矩陣),而是生成兩個Mask矩陣,去和原信號做運算,得到分離出的兩個矩陣,
每個時頻單元只屬于一個人,因此可把掩模Mask估計看成時頻單元聚類(分類)的問題,
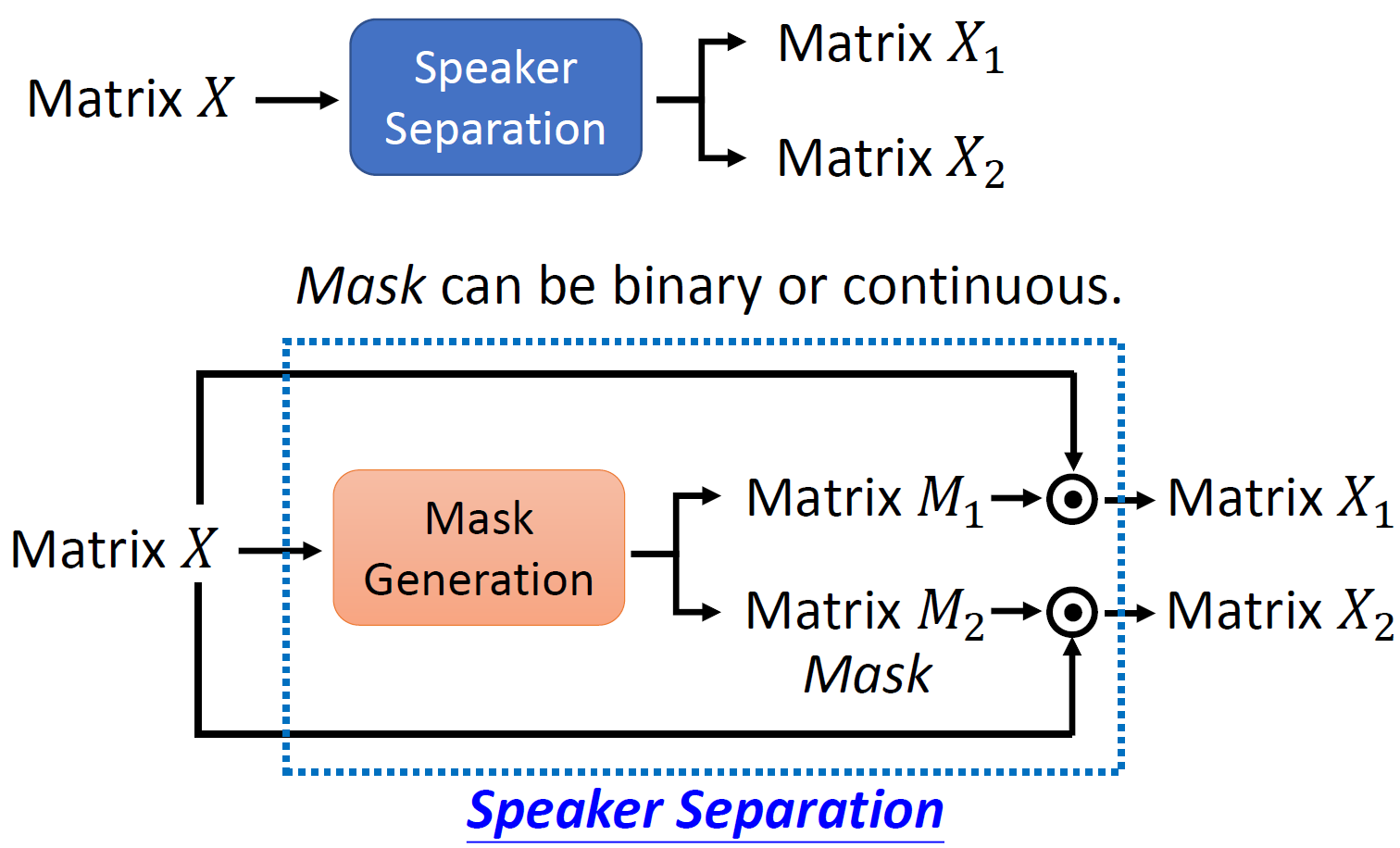
4.2 Ideal Binary Mask
將語音信號A,B和混合信號C變換到頻域(MFCC),用矩陣表示,
怎么得到Mask矩陣呢?
在每個位置上做大小比較,假如藍色信號的值更大,那藍色信號的Mask矩陣在這個位置的值為1,
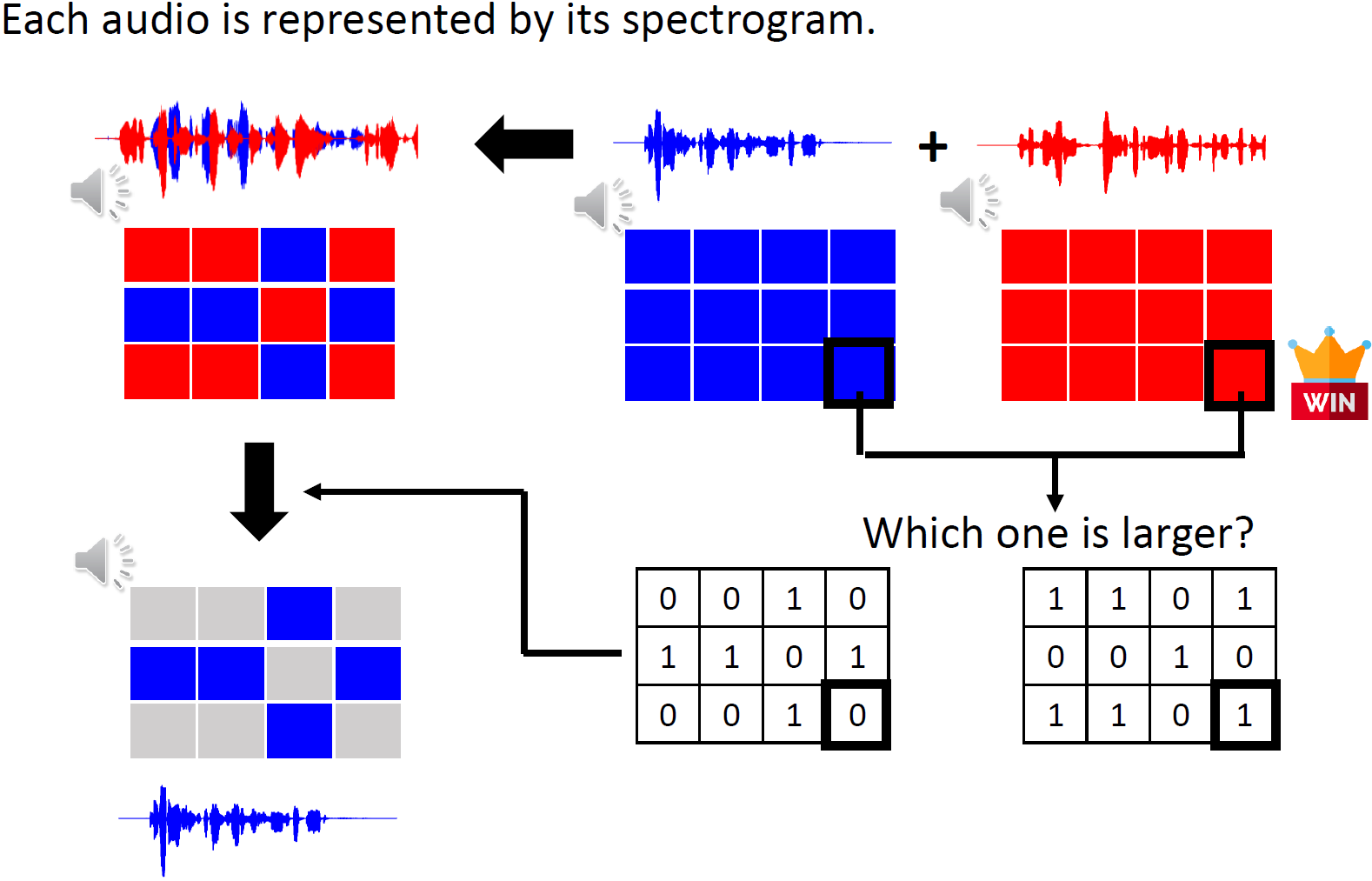
將(藍色信號的)Mask矩陣與混合信號做同位置相乘,得到的信號結果是不錯的,
在人耳聽來,和原始藍色信號非常接近,
對于ground truth資料,我們很容易能獲取到IBM,然后訓練模型產生這樣的Mask矩陣,以便在test階段實作語音分離,
注意兩個Mask矩陣之間是有數學關系的(加起來為全1),
4.3 訓練程序
[1] Hershey J R , Chen Z , Roux J L , et al. Deep clustering: Discriminative embeddings for segmentation and separation[C]// 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2016.
深度聚類方法如下圖,輸入為混合語音的時頻表示,通過一個嵌入向量生成網路來計算每個時頻單元的嵌入向量,接著通過kmeans聚類方法完成分類,
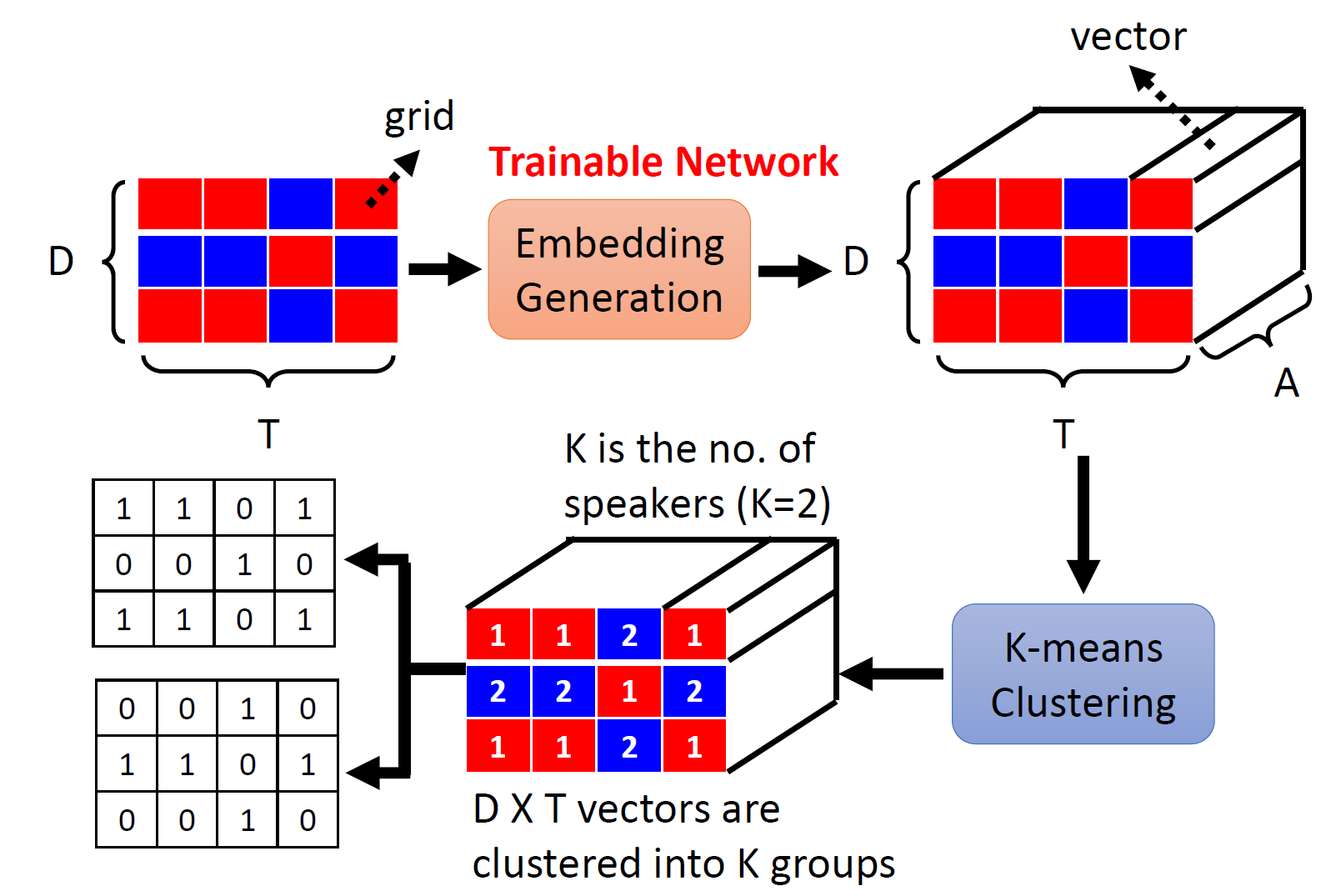
聚類程序是無法訓練的,我們能訓練的是生成Embedding的神經網路,
同一個位置,在一個Mask矩陣中值為1,在另一個Mask矩陣中值為0
我們希望同一個Mask矩陣中有相同的值的位置對應的嵌入向量越接近,有不同的值的位置對應的嵌入向量越不相近,
這樣在進行聚類計算時,就越可能得到和IBM一致的結果,
通俗地說,如果兩個grid進行Mask以后屬于同一個speaker,就把它們對應的嵌入向量拉近,反之則拉遠,
根據原論文,用2個speaker的資料做訓練,在測驗的時候將k-means的k設為3,它可以識別出3個speaker,
但是Deep Clustering不是真正的端到端的網路結構,
5. Permutation Invariant Training(PIT)
[2] Yu D , Kolbk M , Tan Z H , et al. Permutation invariant training of deep models for speaker-independent multi-talker speech separation[C]// IEEE International Conference on Acoustics. IEEE, 2017.
PIT模型的設計思想是當模型給定,就可以給出一個確定的排列(選擇可以使得損失函式最小的那一種排列方式),反之當排列給定可以訓練模型,因此最初隨機初始化一個分離模型,得到一個排列,接著更新模型,反復迭代至收斂,
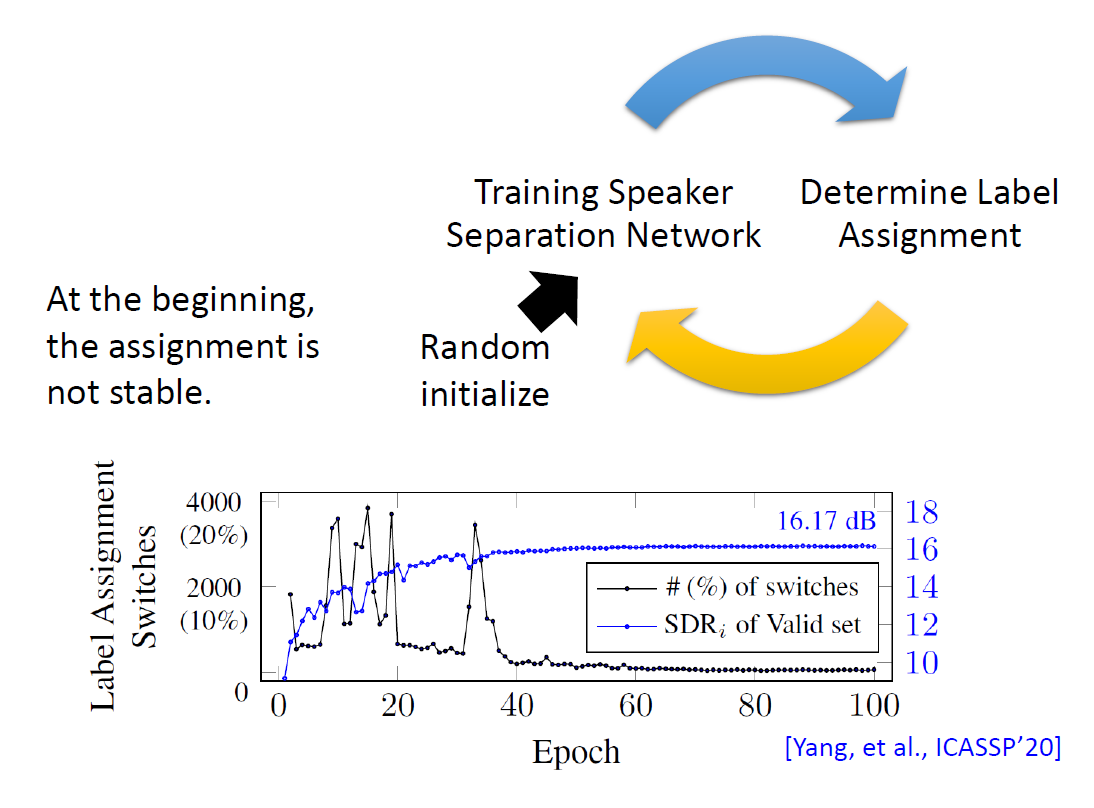
可以用PIT先訓練出一個標簽的擺放方式,再假設這個是正確的擺放方式,再去訓練,

6. TasNet
相關論文為:
[3] Luo Y , Mesgarani N . TasNet: time-domain audio separation network for real-time, single-channel speech separation[C]// 2018:696-700.
[4] Luo Y , Mesgarani N . Conv-TasNet: Surpassing Ideal Time–Frequency Magnitude Masking for Speech Separation[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2019, PP(99):1-1.
TasNet全稱為Time-domain Audio Separation Network
TasNet主要架構有兩種,起初是使用Bi-LSTM作為主體[3],但礙于LSTM的特性Time step時間步數過長,導致模型引數規模及訓練時間長久,在19年這篇文章[4]中改為使用卷積神經網路,
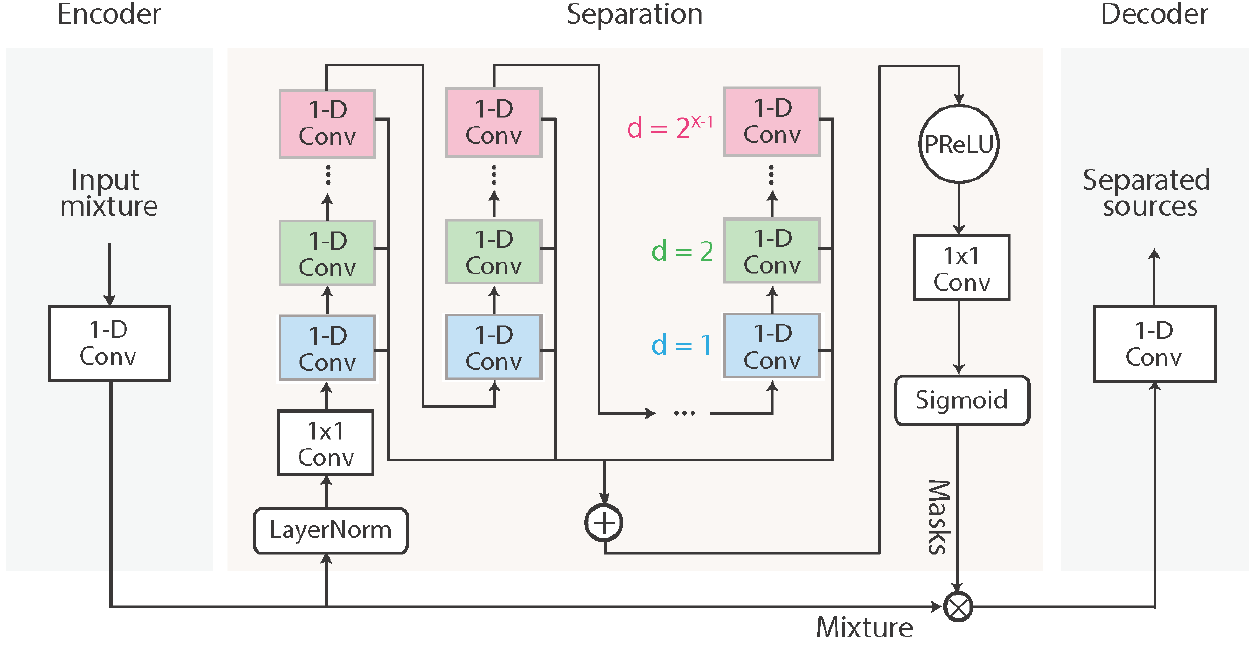
整體網路結構如下圖所示:
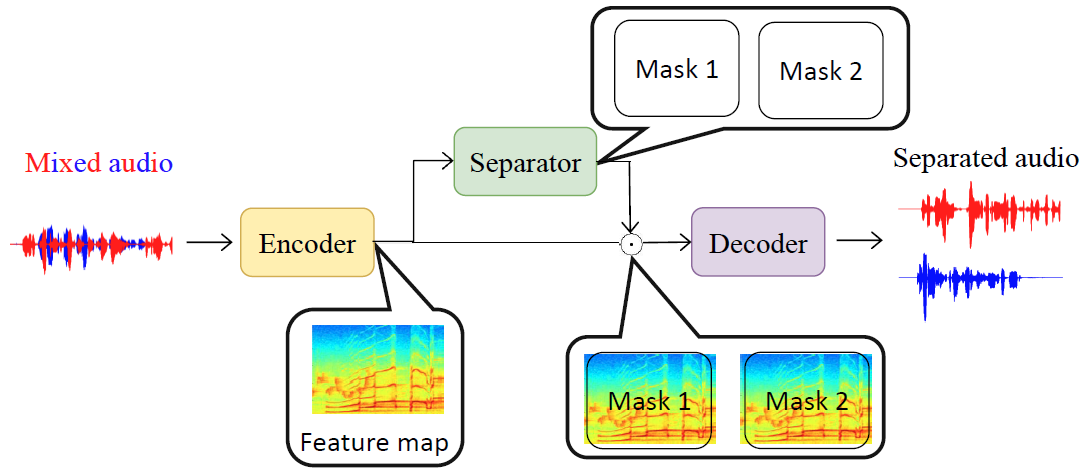
tasnet是一個時域的source separation model,輸入不是聲譜圖(Spectrogram) 而是Mixture raw waveform signal,
- Encoder將一小段聲音信號變為512維的向量,
Encoder通過conv1D 的特性,類似于將原始raw waveform進行傅里葉變換得到我們要的feature, - Decoder則是在做de convolution,將中間層的東西還原成聲音訊號,
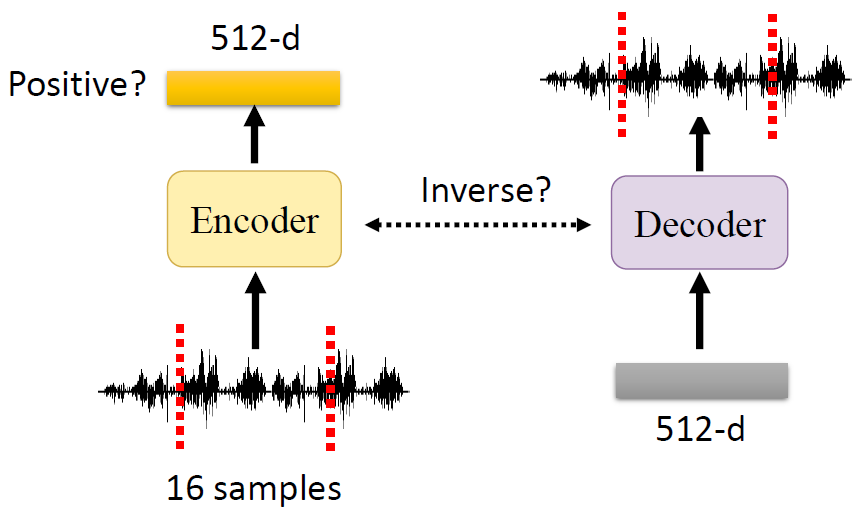
separator部分
原論文的描述為"Speaker separation is achieved by applying a set of weighting functions (masks) to the encoder output. "
假設由encoder編碼的混合信號w中有C個speaker,每一幀信號的分離是通過C個mask向量來實作的,
mask向量的維度與編碼器輸出向量維度相同,
下圖為一個示意圖,TasNet通過一個TCN(時序卷積網路)的結構產生masks,
將每個位置的輸出信號做變換再通過sigmoid函式,每個位置的mask1和mask2都是0~1的標量,
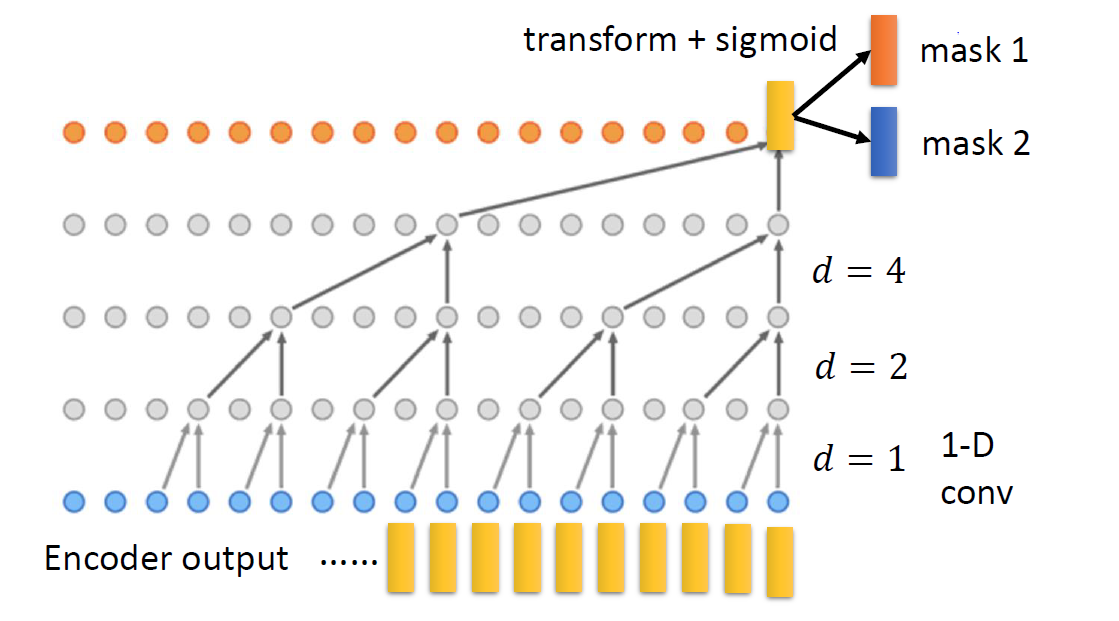
(注意圖里只是顯示了和最后一個輸出向量相關的卷積計算程序)
卷積程序會重復多次,卷積程序越多,“看到的”音頻信號時長就越長,
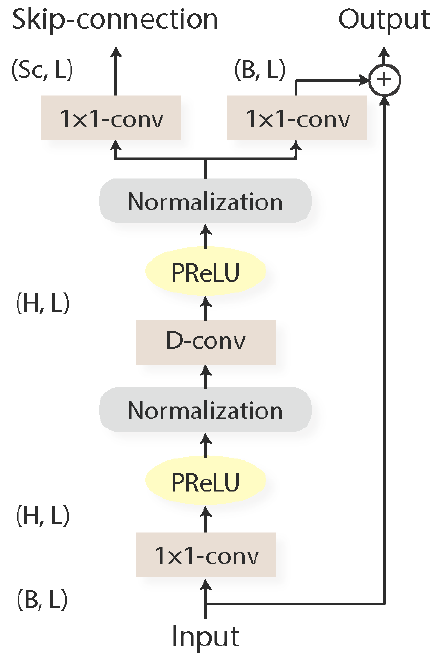
每個1-D Conv block的結構
每個模塊由1×1 conv運算和depthwise convolution(D-convolution)運算組成,在兩次卷積運算之間增加了非線性激活函式和歸一化,
相關知識參閱我的博客卷積相關:Depthwise Separable Convolution
D-convolution壓縮整個模型所需的引數,從GxPxH變成GxP+GxH
兩個線性1×1 conv模塊分別用作剩余路徑和跳過連接路徑,
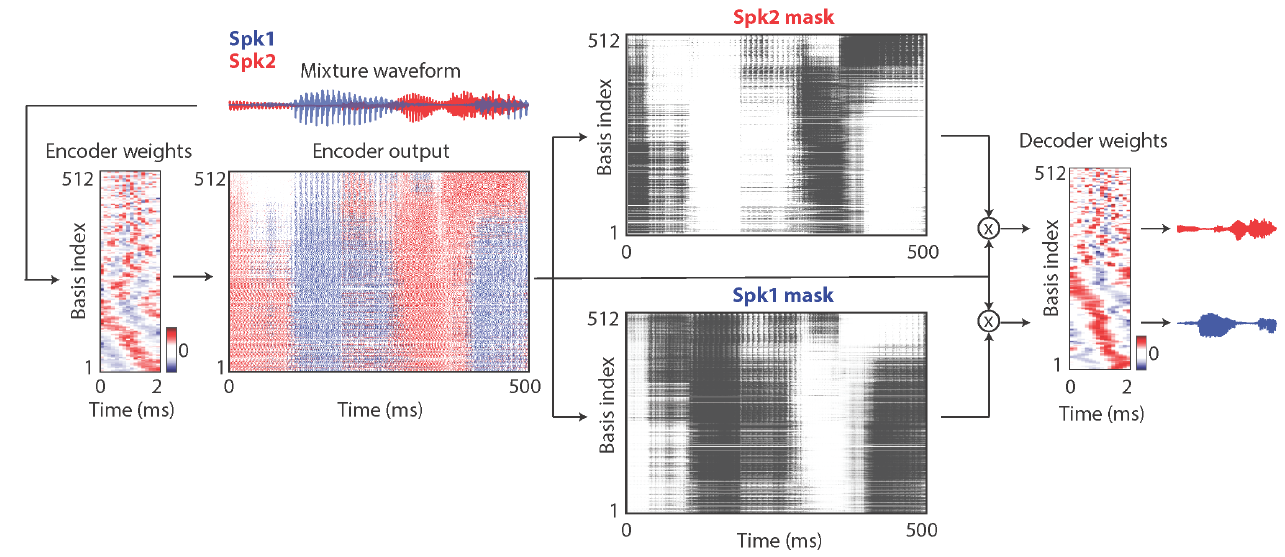
整個計算程序的可視化:
7. 更新的研究
目前其他做source separation也做得很好的paper:
wavesplit: https://arxiv.org/pdf/2002.08933.pdf
dual path rnn: https://arxiv.org/pdf/1910.06379.pdf
參考資料
從雞尾酒會問題入門語音分離
DLHLP20
端到端聲源分離研究:現狀、進展和未來
在github上發現了一份非常好的語音分離相關研究總結,清華大佬出品,包括論文,代碼復現等,
https://github.com/JusperLee/Speech-Separation-Paper-Tutorial
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/287250.html
標籤:其他