日志原理與開發分析這篇完全指南就夠了!適應各種規模!
為啥公司業務上不去?要么程式沒有輸出日志到位,缺少價值資料,要么列印日志到位了,沒有高效的分析工具!
為啥程式會崩潰?日志處理沒到位唄,線上故障就得加班,浪費了時間還找不到問題根源!
別想為啥了,跟上來學習吧,本篇解決此類問題,
什么是日志(log)
想想,我們為什么要做筆記,翻看筆記?
或者說,每天寫日記,
我們做了筆記是為了加強記憶,如果忘記了后面還能翻看,
日志就是類似筆記一樣的東西,
小白問:那么日志能幫助開發者提高記憶,輕松學會寫代碼了?
這倒不是的,日志就想日記一樣可以隨時翻看,查看過去發生的事情,
好,下面來看雷學委的開發日常:
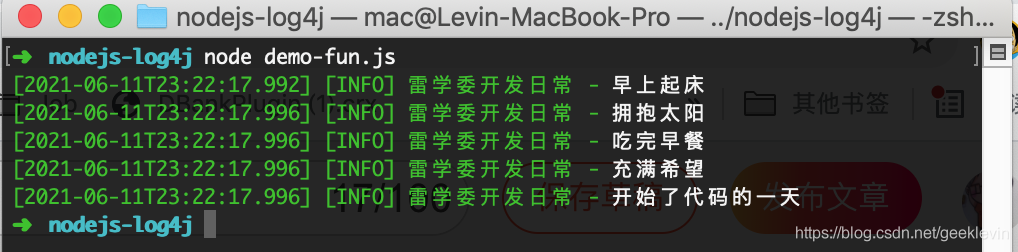
沒錯,像記日記一樣,用程式記錄了每個時刻做的事情,輸出到檔案,還能經常查看,這就是日志,
當我們把這些零散的日志歸集起來,資料量大了,就能發現日志資料的規律和價值,
本文會使用log4js來進行日志使用的展示,Java開發是使用Log4J或者Slf4J,但是核心思想是一樣的,
本文適用于任何語言,而且覆寫了單應用到大規模平臺的處理,前面已經掌握了基本概念,下面繼續看,
- 日志的簡單應用
- 多種日志格式的使用和含義
- 實際專案如何管理和配置日志
- 大規模平臺的日志管理與資料價值分析
學習的第一步都是先知道啥,怎么用,下面先使用,
先安裝
我們這里先安裝一個日志的模快,
打開終端執行下面命令:
npm install log4js
使用
看看雷學委的日記
const log4js = require('log4js')
var logger = log4js.getLogger('雷學委開發日常')
logger.level = 'info'
logger.info('早上起床')
logger.info('擁抱太陽')
logger.info('吃完早餐')
logger.info('充滿希望')
logger.info('開始了代碼的一天')
保存上面代碼為demo-fun.js ,然后運行:
node demo-fun.js
可以得到跟上面日志圖片的效果,讀完可以試試,
下面正式開發
這里會有三個例子,展示日志列印和日志輸出控制,
最簡單的例子
復制下面代碼為demo.js
var log4js = require("log4js"); // 加載log4js庫
var logger = log4js.getLogger();//獲取默認的logger
logger.level = "debug";
logger.debug("一些除錯資訊");
直接運行:node demo.js,效果如下:

很像console.log,不過多了一些東西,看起來像下面的格式:
[日期] [DEBUG] default - 日志訊息詳情,
這里的DEBUG為,一個日志級別,就像檔案級別一樣(有公開,內部可讀,保密,絕密檔案)
這只是一條日志記錄,我們再看下面的,找找規律
再看一個例子:
//demo1.js
var log4js = require("log4js");
var logger = log4js.getLogger();
logger.level = "debug";
logger.debug("一些除錯資訊");
logger.info(" 普通日志");
logger.debug("又是除錯資訊了");
復制上面的6行代碼保存為demo1.js,運行列印如下資訊:

這里列印了3行日志,看到規律了嗎?
每一行都是:[日期] [日志級別] default - 具體的日志內容
好,這里稍微做一下解釋,
logger物件提供了不同方法,像debug,info等表示不同的日志級別!
不同的日志級別又代表什么呢?
看下面一個稍微復雜的例子,就能明白,
避免新人寫代碼出錯,雷學委這里又貼心的為小白/懶人,提供了直接可以復制運行的代碼,
先花30秒耐心看一下,保存為demo2.js
//demo2.js
const log4js = require("log4js");
//這里配置log4js使用fileAppender來輸出“error”級別的日志,
//然后fileAppender是一個檔案型別的日志累加器,輸出日志到檔案demo2.log
log4js.configure({
appenders: { fileAppender: { type: "file", filename: "demo2.log" } },
categories: { default: { appenders: ["fileAppender"], level: "error" } }
});
const logger = log4js.getLogger("demo");
//下面呼叫logger物件來列印一些日志,
logger.trace("一些程式跟蹤資訊");
logger.debug("這里輸出除錯資訊.");
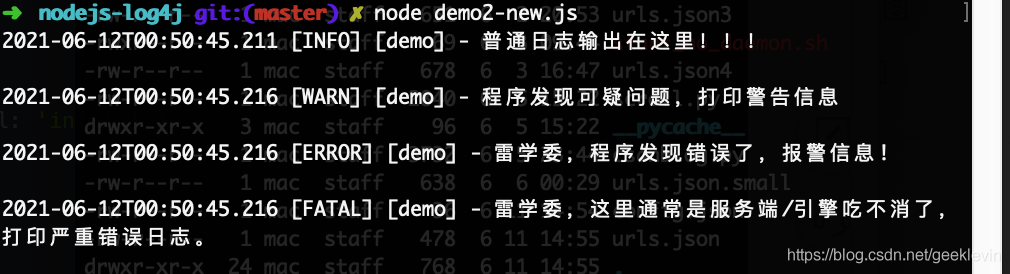
logger.info("普通日志輸出在這里!!!");
logger.warn("程式發現可疑問題,列印警告資訊");
logger.error("雷學委,程式發現錯誤了,報警資訊!");
logger.fatal("雷學委,這里通常是服務端/引擎吃不消了,列印嚴重錯誤日志,");
看懂了嗎?
上面的代碼分為兩個部分
- 第一段加載并配置log4js物件,日志輸出保存到哪里,輸出的日志級別是什么,這里是‘error’級別
- 第二段為創建logger物件,并用它的不同方法來列印不同級別的日志,
運行效果如下:
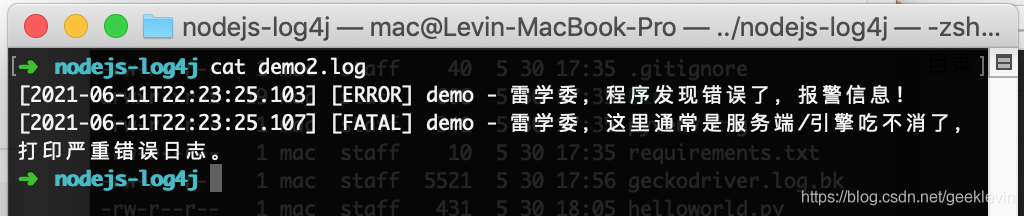
node demo2.js, 如上所說,日志列印到檔案demo2.log里面,
另外demo2.log內容只有 [ERROR] 和[FATAL]這兩個級別的日志,也就是,只有logger.error和logger.fatal兩個函式的日志詳情被輸出到檔案中,
如果把ERROR比喻為公開級別,那么像DEBUG/TRACE等就是保密級別了,指定了輸出公開資訊等話,保密資料是絕對不能列印出來的,
理解一下日志分級
先說級別,不同級別日志會有級別的關鍵詞,像日志中的‘ERROR’, ’DEBUG’ 這些,
既然是級別了就有高低級別之分,
可以用下面的運算式進行級別低到高排列:
TRACE < DEBUG < INFO < WARN < ERROR < FATAL
所以這解釋了demo2.js代碼中指定了‘error‘級別之后, 只有
logger.error 和 logger.fatal 兩行日志被列印了,
看懂了嗎?就像日常的資訊保護級別,指定級別越高越不能暴露更多資訊,在程式中級別指定越高,輸出的資訊越少,同一個道理,
資訊量慢慢加大 - 全部日志級別
下圖是log4js模塊提供的方法和日志級別,
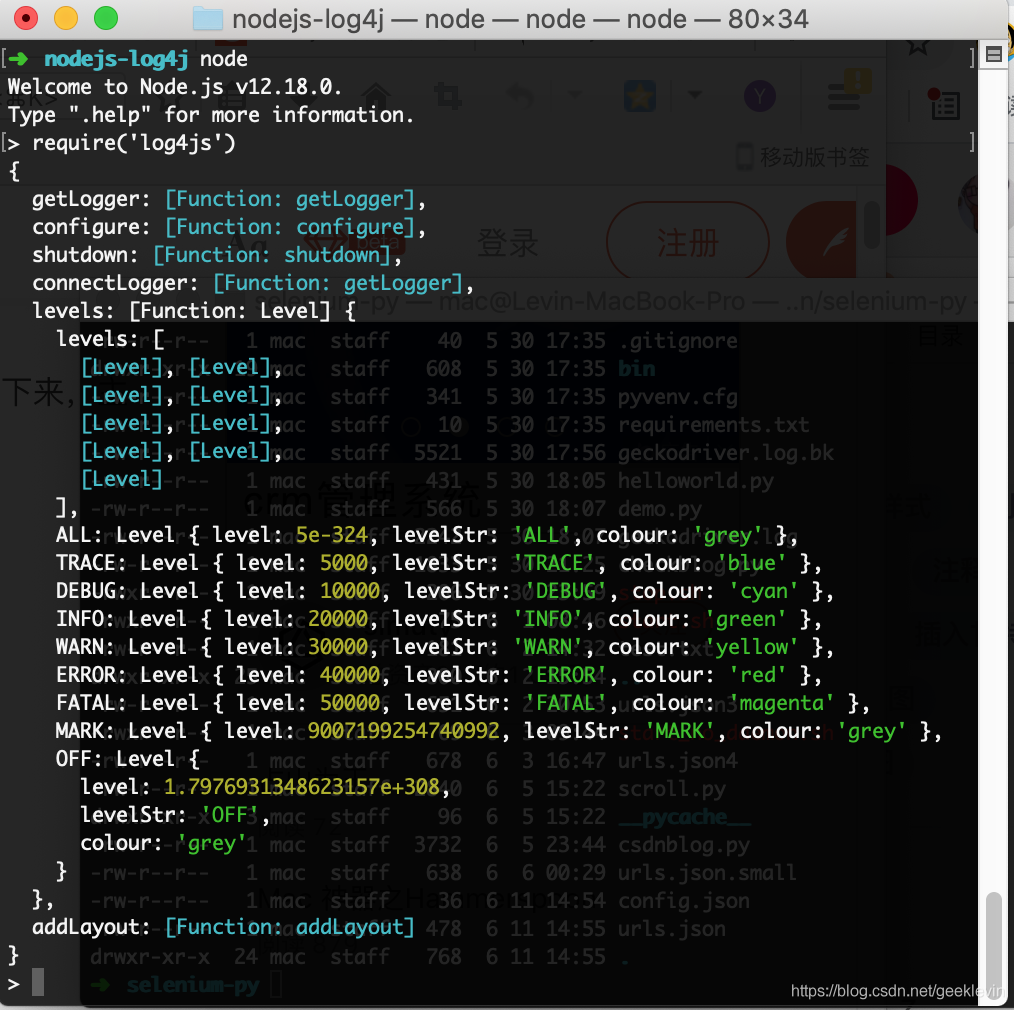
log4js 提供了getLogger方法,開發者可以呼叫這個獲取一個logger物件,用來輸出不同級別日志,
然后,這里是最全面的log4js的提供的日志級別,
重新整理整個日志級別的排列變更如下:
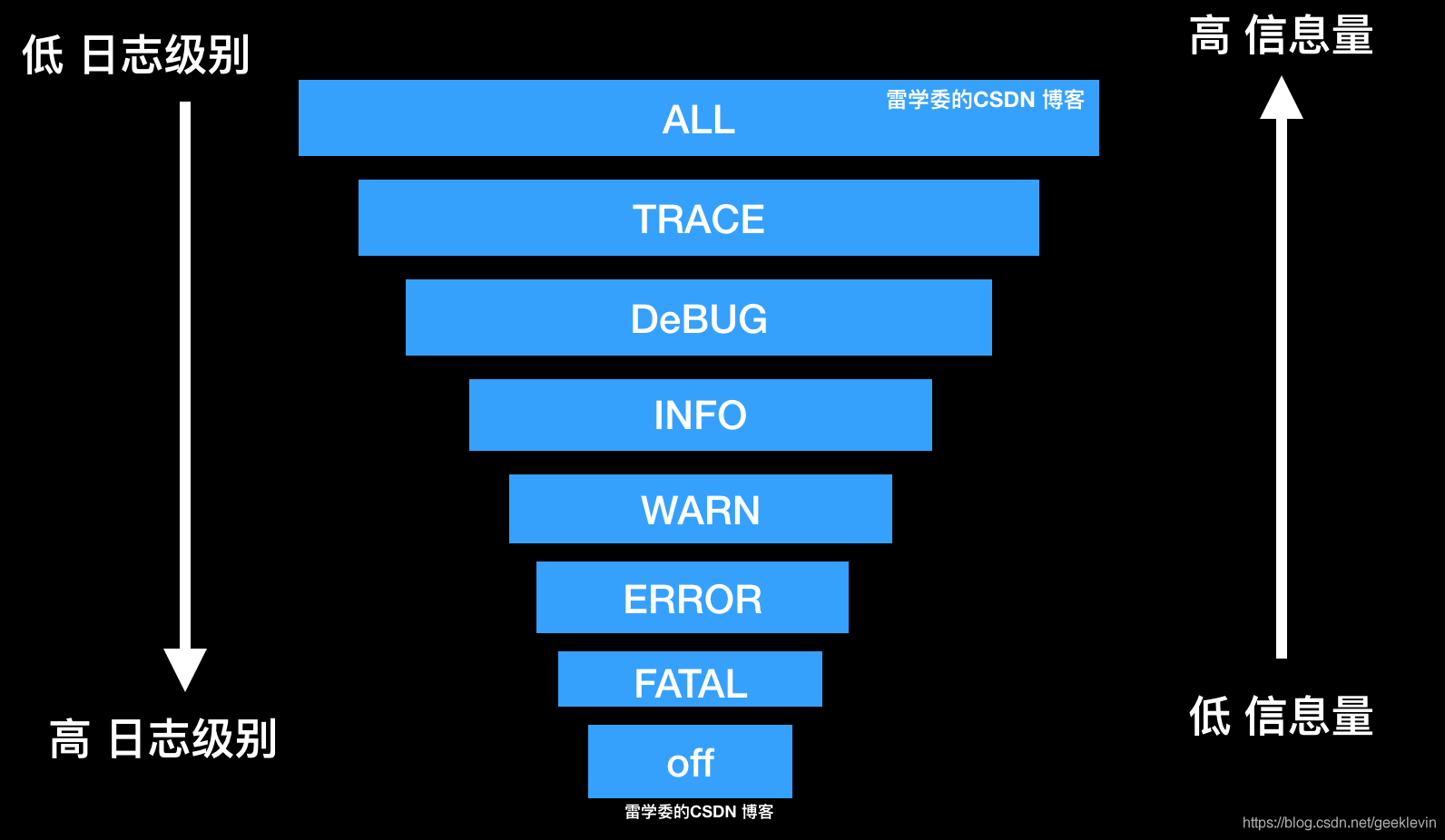
ALL <TRACE < DEBUG < INFO < WARN < ERROR < FATAL < OFF
上面這個公式務必背誦默寫!
這里讀者可自行運行文末實體代碼,
這里ALL級別相當于整個日志資訊都列印,暴露的資訊量最多,OFF暴露的資訊量是極少的,
雷學委也準備了代碼,讀者稍后可從文末下載執行,
到這里還不懂,雷學委精心準備了下圖,看到這個圖已經值了!
至此,整個日志框架的核心,您已掌握了,
喝杯水,下面繼續看實際應用,
實際專案中如何應用日志
配置化日志管理
上面的demo2的代碼配置,應該提取日志模塊的配置到檔案,
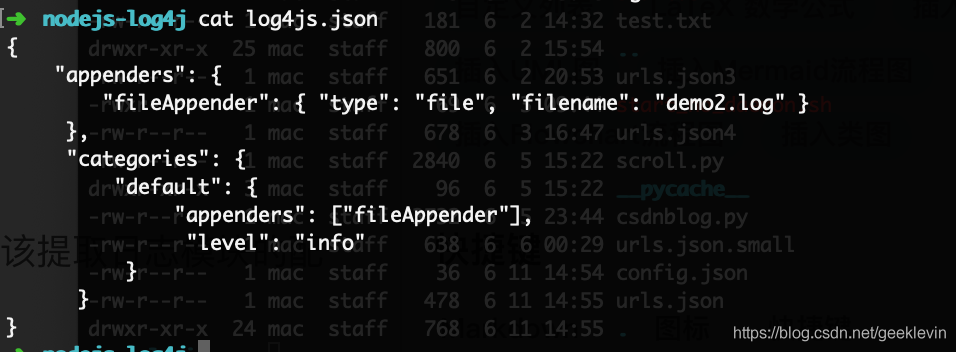
配置放在檔案中,可以修改配置不改代碼切換日志,
但是應用需要重啟,可以代理logger物件實作不重啟動態加載,
日志級別的使用建議
通常我們列印‘info’級別日志,記得常規用戶行為,如登錄/查看更新資料/其他業務訪問的log等,
- info級別以下的使用
在開發程序中可以使用logger.debug函式去列印程式內部資訊,比如列印一些中間變數的值,列印中間處理狀態等等,
對于trace級別的日志,這個比較低級別,通常用來本地跟蹤代碼的執行的詳細資訊!在服務端,服務器上運行的程式通常不會開啟,因為日志量會很大,
對于all級別很少使用,可以根據情況自己定義,很多時候用到trace級別就很夠資訊量了,
- 對于info以上的高日志級別
warn級別:列印警告資訊,就是可能是錯誤,或者是忽略的已知錯誤,
比如系統在呼叫一個不穩定的介面,有時候別人不穩定只能多次重試,這時候會使用logger.warn方法來列印日志內容”忽略第三方程式呼叫錯誤,準備重試“error級別:顧名思義就是,程式錯誤,這個可以用來列印錯誤資料,錯誤請求的事件資訊,比如java中拋出一些CheckedException的時候經常會在catch代碼快中呼叫logger.error來記錄此類例外,
這類成為錯誤記錄,更多是程式內部處理,業務方面的錯誤記錄,fatal級別更多是在NodeJS引擎出現故障,或者JVM(java
虛擬機)這種引擎級別的故障可以用這個級別來列印,針對web應用,像訪問底層資料庫的失敗的時候,也可以用這個fatal級別來記錄,
出現這種問題一般是本應用的故障,或者因為網路,作業系統的故障導致的程式故障,
日志格式化問題
如下面的log4js配置一樣,加了一個標準輸出來展示,
這里的patern: “%d [%p] [%c] - %m%n” 就是我們列印日志的格式,%d是一個占位符,最簡單可以理解,就是表示一個時間戳,代表列印日志的時間,
%p %c這些就是占位符,也就是代表了日志級別,日志物件(特定的logger)等,
%m 代表當前如logger.info方法傳入的訊息,
%n 為換行,
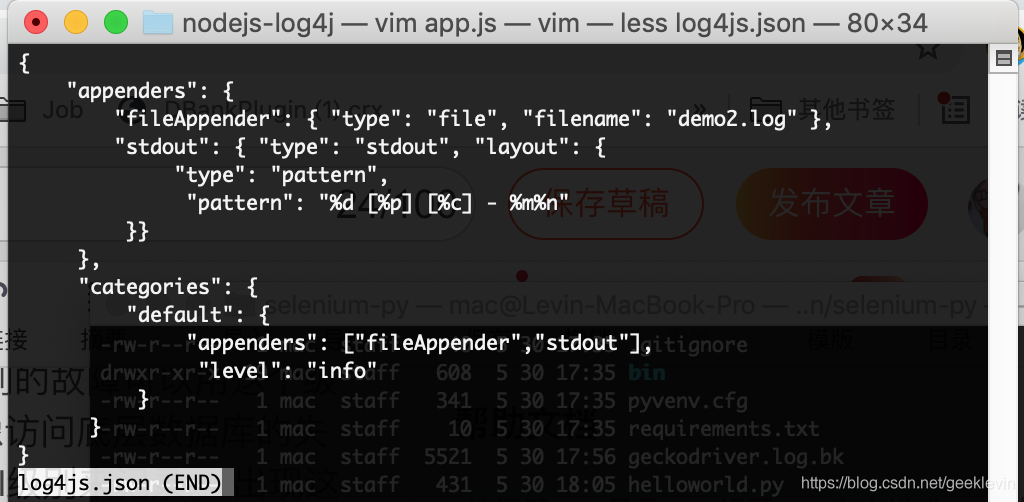
效果如下:
所有格式定義參考:https://github.com/log4js-node/log4js-node/blob/master/docs/layouts.md
log4js還可以支持將日志寫到多個檔案中參考:https://github.com/log4js-node/log4js-node/blob/master/docs/multiFile.md
重點說一下,日志格式其實不用過度糾結,但必須在輸出準確日志資訊的情況下,同時保證整個系統或者多個服務的配置達到統一標準,
統一標準,比如說格式上的輸出標準,代碼日志輸出標準,路徑的標準等等,不然容易失控,這需要在架構上達成一致,
日志檔案滾動策略
開發的應用通常都是長期運行的,會不停的產生日志,
隨著時間推移,把日志寫在一個檔案也不現實,
而且不利于復查問題,占用大量存盤資源,另外,在大檔案中搜索關鍵字速度也降低,
所以需要滾動(Rotate/Rolling)日志,也就是把日志設定一個固定規模,比如寫日志到 LeixueweiDemoApp.log 檔案,設定最大尺寸,當檔案超過最大尺寸自動的創建新檔案,同時可以設定最大的日志檔案備份,比如保留一個月,半年,甚至更長期的日志,
這是log4js官網的:
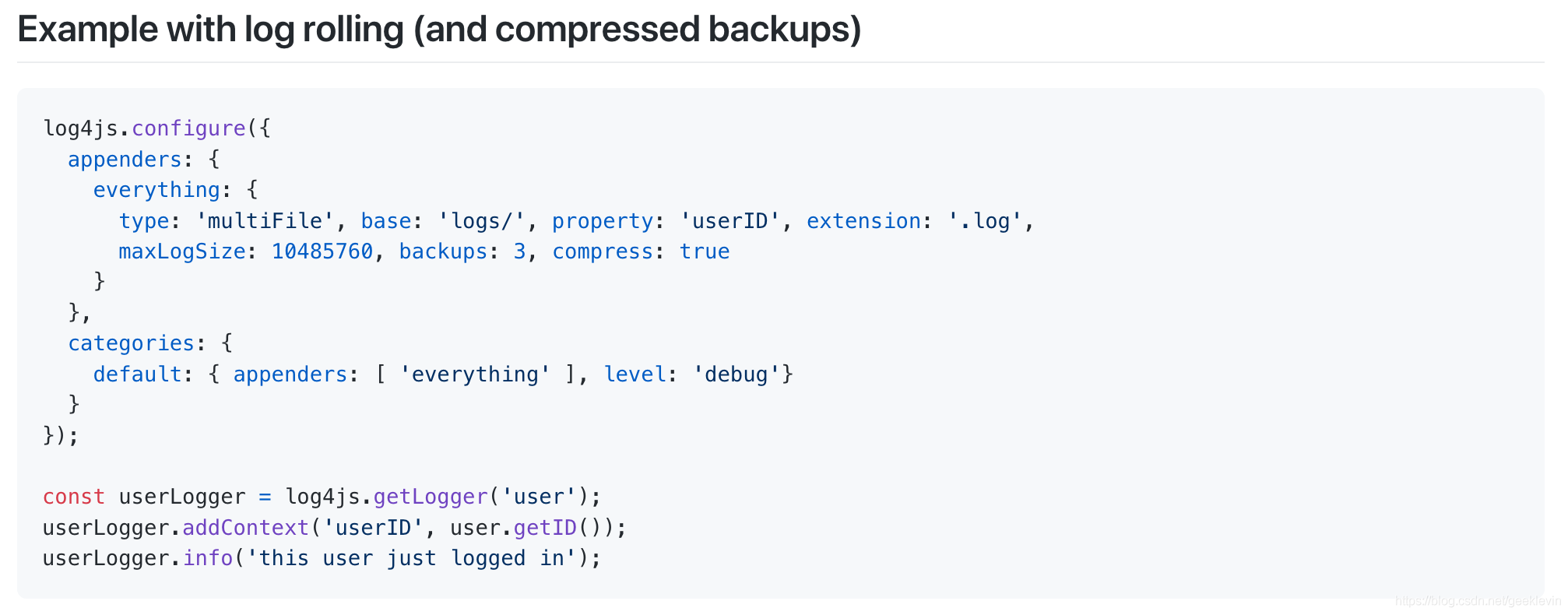
JS的日志配置使用了JSON來呈現是非常直觀的,
Java則更多使用logback或者SLF4J + logback/log4j ,配置的內容很像,但是呈現格式不一樣,很多是xml檔案或者properties檔案,
這里可以拿一個XML檔案(類似html標簽化語意)來看看,如下:
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property resource="application.properties" />
<!-- application.name在application.properties中定義 -->
<contextName>${application.name}</contextName>
<!-- 日志級別 -->
<property name="logLevel" value="INFO" />
<!-- 日志檔案名 -->
<property name="logFileName" value="LeixueweiDemoApp"/>
<!-- 保存60天 -->
<property name="maxHistory" value="60"/>
<!-- application.logHome在application.properties中定義 -->
<property name="logPath" value="${application.logHome}/logs/${projectName}"/>
<!--格式化輸出:%d{yyyy-MM-dd HH:mm:ss.SSS} 表示特定時間格式日期,%thread表示執行緒名,%-5level:級別從左顯示5個字符寬度,%msg:日志訊息,%n是換行符-->
<property name = "LOG_PATTERN" value="%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{35} - %msg%n"></property>
<!-- 控制臺輸出 -->
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>${LOG_PATTERN}</pattern>
</encoder>
</appender>
<!-- 日志記錄器,日期滾動記錄 -->
<appender name="FILEAppender" class="ch.qos.logback.core.rolling.RollingFileAppender">
<!--日志檔案路徑及檔案名 -->
<file>${logPath}/${logFileName}.log</file>
<!-- 日志滾動策略,按日期記錄 -->
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!-- 歸檔日志檔案路徑-->
<fileNamePattern>${logPath}/${logFileName}.%d{yyyy-MM-dd}.log</fileNamePattern>
<maxHistory>${maxHistory}</maxHistory>
</rollingPolicy>
<!-- 追加記錄日志 -->
<append>true</append>
<!-- 日志檔案格式 -->
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>${LOG_PATTERN}</pattern>
</encoder>
<!-- 記錄info及其以上級別 -->
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>info</level>
</filter>
</appender>
<!--適用上面兩個appender-->
<root level="${logLevel}">
<appender-ref ref="STDOUT"/>
<appender-ref ref="FILEAppender"/>
</root>
</configuration>
上面定義了兩個log appender 和 root根logger來配置全域logLevel,
其實配置的屬性兩個技術很相似,
到這里已經變得非常復雜了,但是一個完整的應用日志也就是上面的,文末的代碼倉庫鏈接有實體配置,
讀到這里,基本可以解決單個應用的日志管理,而且能夠做的成熟專業的應用日志處理了,
大規模分布式場景的日志管理與分析
高性能的處理
這里稍微提一下,在應用中列印日志不宜過多,會影響程式性能,比如訪問了一個靜態頁面,服務器直接列印1G的log出來,這就很離譜,
但有時候比如一些重點資訊很多,比如在很大請求量的情況下,要保證性能,又想要留住重要的資訊跟蹤,怎么處理?
這時候可以使用日志佇列的方式來解決,
在使用NodeJS情況下,這里又得提到pm2了,使用集群模式運行,把多個worker節點日志發布到master進行統一化處理,減輕寫同個日志或者輪轉日志的負擔,
Java中也有類似的方法,異步處理大量日志,可以查看logback的配置,AsyncAppender,
<appender name="ASYNC_LOG_INFO" class="ch.qos.logback.classic.AsyncAppender">
<!-- 設定為:不丟失日志 -->
<discardingThreshold>0</discardingThreshold>
<!-- 更改默認的佇列的深度,該值會影響性能.默認值為256 -->
<queueSize>${queueSize}</queueSize>
<appender-ref ref="FILE_INFO"/>
</appender>
這個配置的queueSize變數,得跟據應用的實際QPS日志流量來分析,其他參考:http://logback.qos.ch/manual/appenders.html#AsyncAppender
統一日志處理與分析
上面說的很多直接用來做一個應用的日志處理都可以,
統一日志處理說的是把一個大型系統的日志,統一的集中化管理,
重點是:分布式日志集中化管理,
這一點很重要,在運維大型平臺的時候,有幾百上千臺服務器,上面很多服務,很多日志不可能一個一個登錄上去看,
所以我們需要使用工具進行集中化,而且做一個大規模的統一分析,
思想是把本服務日志傳輸到一個中央分析主機,使用高效的分析工具,分析資料的規律
下面是一個簡化的日志集中收集處理的架構,應用服務器多,日志收集終端可以把日志放到訊息佇列,緩沖處理日志,
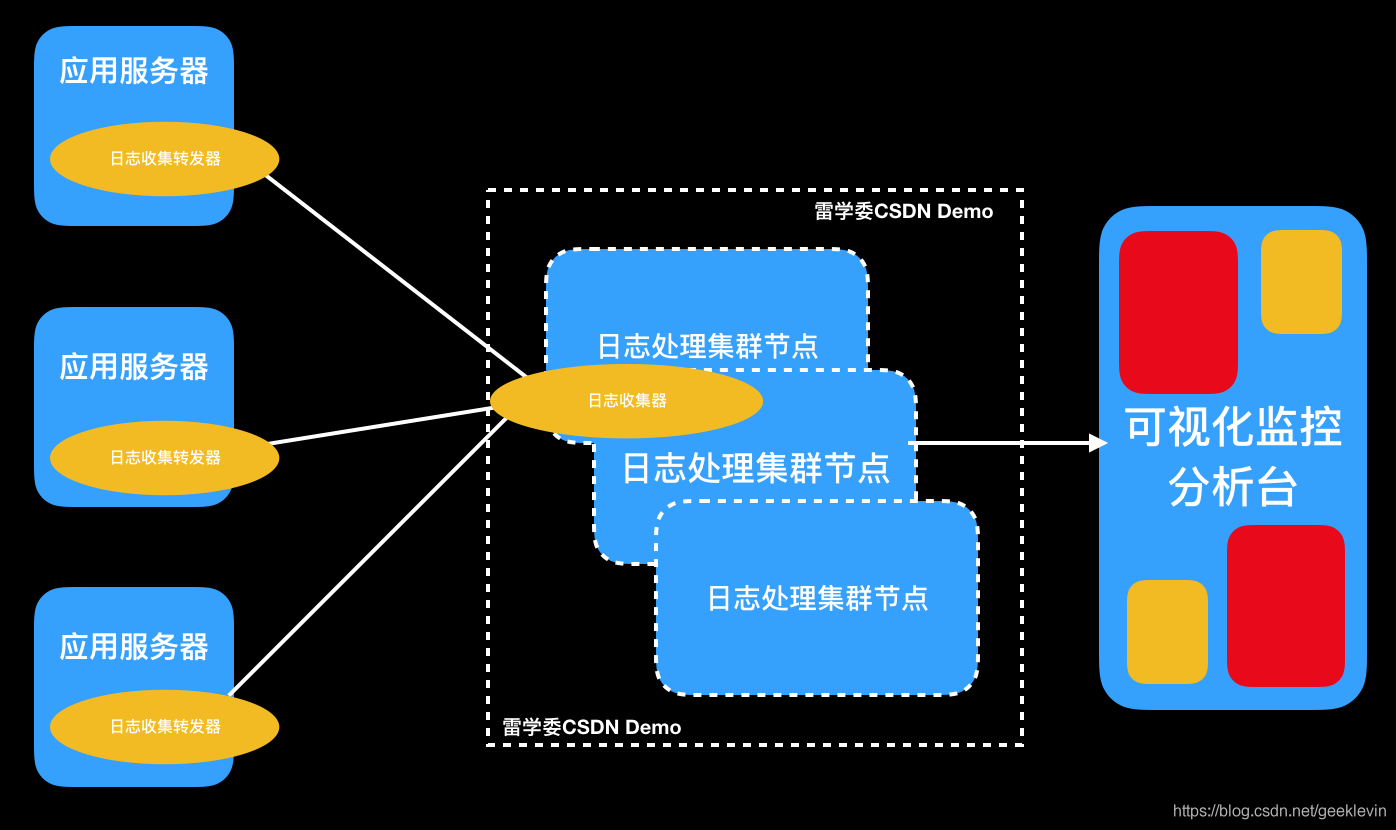
這一塊可以拓展的解決方案很多,是一個開放問題,后面可以寫一篇專門Elastic技術棧的,
快速過一下elastic stack技術組件:
- FileBeat: 一個收集日志的程式
- Logstash: 接收網路端資料,有Pipeline進行日志解構與重組,格式化為結構化資料,方便分析
- ElasticSearch: 一個高效的存盤框架,支持快速資料存盤查詢
- Kibana:一個資料可視化工具,支持快速對接elasticsearch的資料,快速的圖表面板制作,
映射到上面的架構圖,我們使用elastic stack的組件流程如下:
終端應用服務器日志收集(FileBeat) -> 統一日志處理(Logstash) -> 統一日志存盤(ElasticSearch) -> 統一的資料展示面板(Kibana)
這里簡單提一下,使用這些組件更多是繼續配置整合,參考官網配置和文本的代碼REPO即可,
小團隊或者小公司可以使用/開發日志收集器(功能類似logstash+filebeat來傳輸處理日志),然后存盤到elastic search來統一分析,最后使用Kibana做很多分析面板,這里就要求所有應用日志的格式統一,列印足夠有效資訊,
日志資料分析與價值揭示
不給有效資料,再怎么分析也是徒勞,資料采集的量也得足夠,不能只來一兩條,那是很零散的分布,
下面來看看Kibanan制作的一些資料分析面板
比如監控Nginx 的訪問請求情況
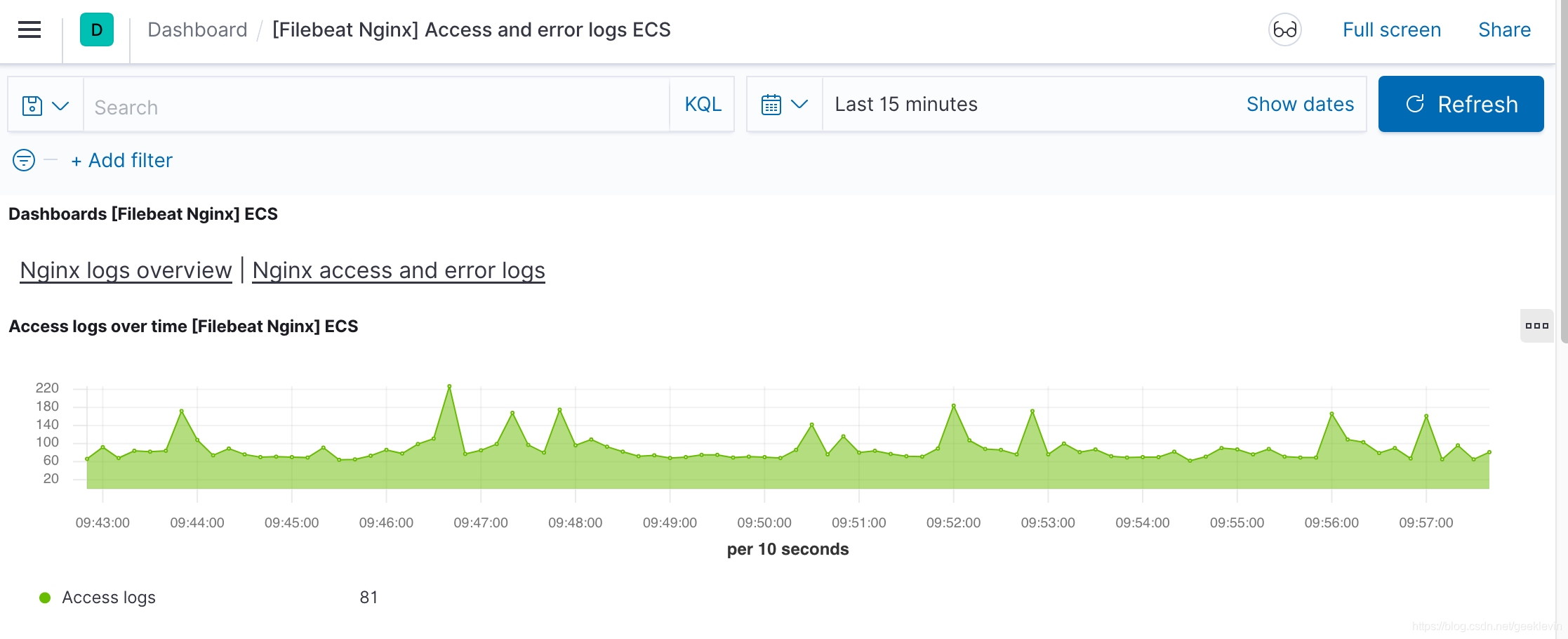
然后還能細致分析到每一個用戶請求的回應情況:
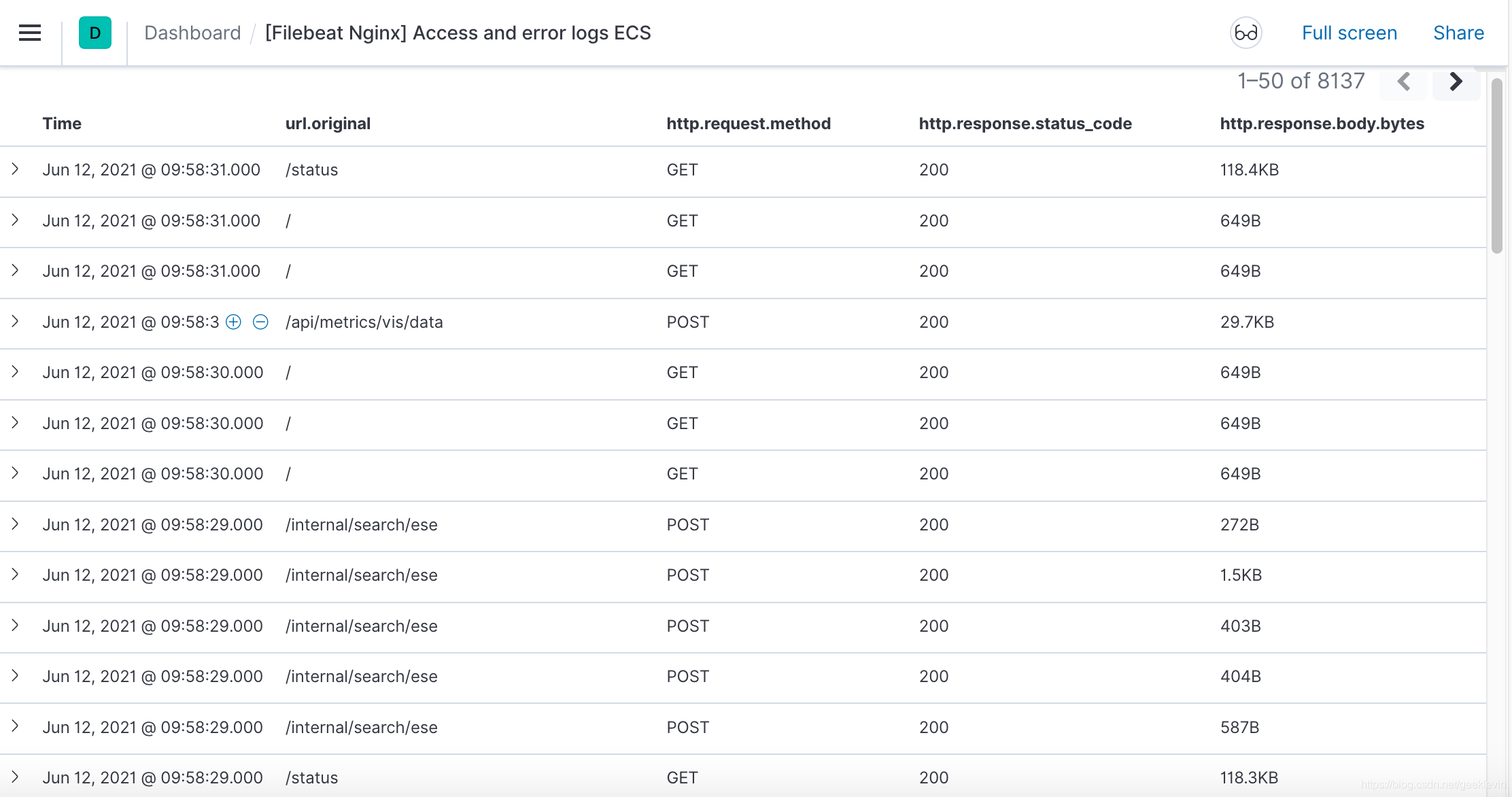
這兩個圖表的資料來源是Nginx組件產生的log(日志)檔案,一天的用戶請求訪問日志的分析,
或者像MITRE 公司展示的各種黑客攻擊的活動分析面板
它是一個資料安全領域的組織,下面面板資料來自:https://attackevals.mitre.org/evaluations.html?round=APT29
下面是一周的網路攻擊活動統計,有高到低,左邊為攻擊手段排名,中間為具體技術總量排名,右邊為策略排名,
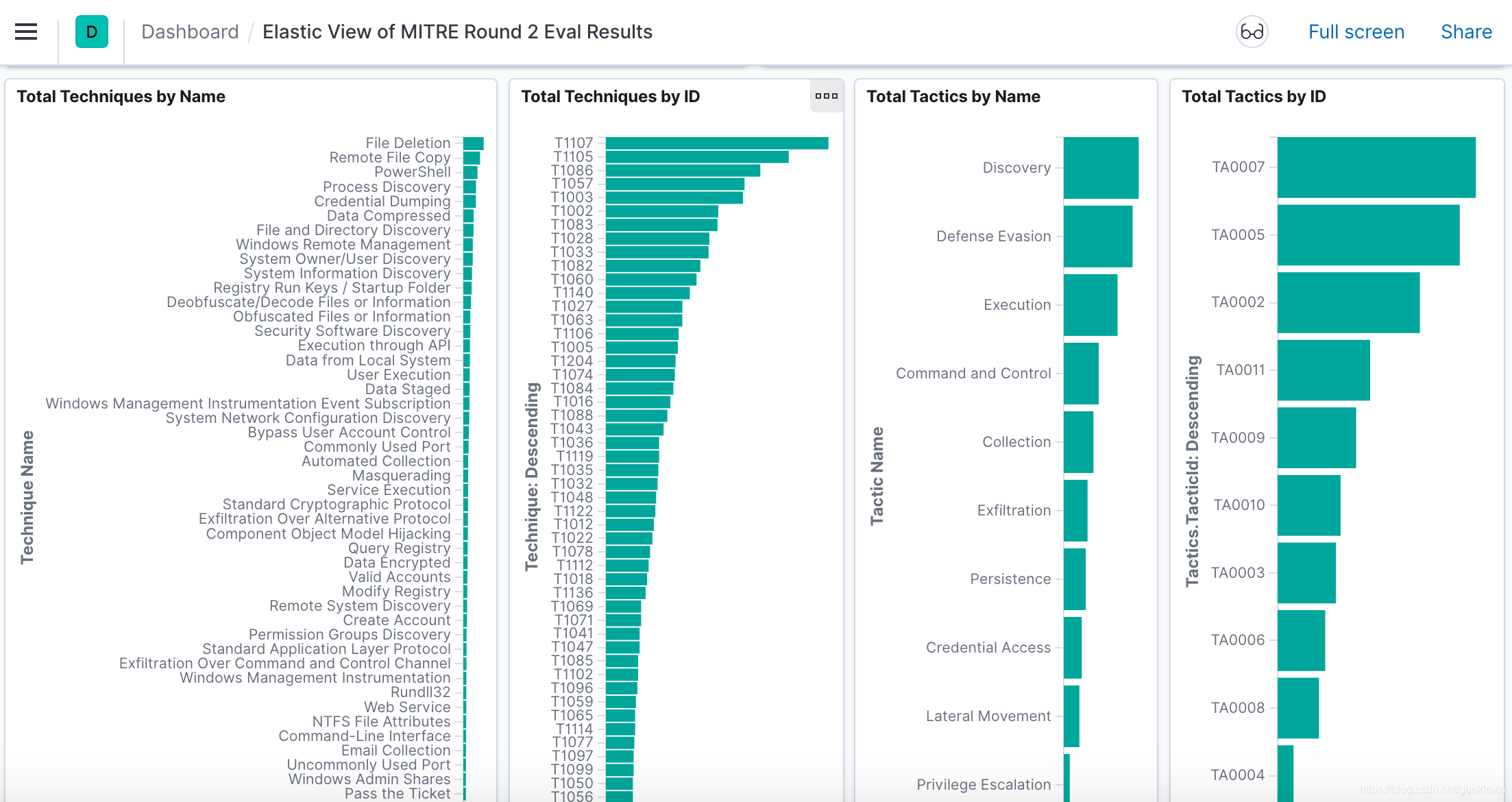
如上圖,把零散的資料匯入作出面板,作出圖表顯現了資料的規律,上面揭示了各種安全攻擊的分布,以及使用的主要技術,
這里可以感受到日志資料分析的價值了吧,
自研發平臺也可以參考Kibana或者Grafana技術棧,實施日志收集分析方案,
讀者可以去elastic網站看demo深度了解一下,
再回顧一下
日志處理與分析跟我們寫程式思考是一樣的,先把思路捋清楚,找去定標準,找合適的工具,還能挖掘出很多業務規律發現價值,創造營收
本文講述了下面這些
- 日志的概念
- 日志的作用
- 日志的簡單應用
- 多種日志格式的使用和含義
- 實際專案如何管理和配置日志
- 大平臺/高并發場景的日志處理與價值分析
內容有點多,看到這里,十分感謝,
持續學習持續開發,我是雷學委
請收藏起來,絕對用的上,可以拿參考示例的配置作業中用,以后應用規模增大也能在把握好大規模場景的處理,
參考鏈接:
| 技術 | 鏈接 |
|---|---|
| 示例代碼和配置 | https://gitee.com/levin6/logging-practics-all-in-one/ |
| log4js | https://www.npmjs.com/package/log4js |
| logback | http://logback.qos.ch/demo.html |
| log4j | http://logging.apache.org/log4j/2.x/guidelines.html |
| pm2 cluster logging | https://github.com/log4js-node/log4js-node/blob/master/docs/clustering.md |
| elastic stack | https://www.elastic.co/cn/elastic-stack |
| 資料分析的 demo | [https://demo.elastic.co/](https://demo.elastic.co/app/dashboards |
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/287266.html
標籤:其他