資料挖掘與生活
前言
寫這篇文章的目的是想給公司同事介紹一下資料挖掘的入門知識,旨在增強大家對資料挖掘了解與興趣,并將這門技術應用到作業和生活中,發揮集體智慧為公司產品增加資料挖掘應用場景,另外對于我自己,以教代學,也可以更好發現自己知識盲點,讓輸出倒逼輸入,
本來是計劃寫成ppt的,但準備程序中發現ppt實在太花時間了:要找圖畫圖,要做互動,要考慮頁面布局,要背演講稿,最侄訓是決定寫成文章,相對來說容易點,參考性也強一些,
市面上的資料挖掘資料很多,但有些專業性很強,但講得太抽象,太深奧,有些雖然淺顯易懂,但實戰意義不強,當然,也有寫得比較好的,但相比起來比例還是比較少,
這篇文章我打算按我理解的角度來介紹資料挖掘,重點介紹資料挖掘在生活中的應用,以及非專業人士如何使用資料挖掘解決生活問題,文章中介紹了資料挖掘的一些演算法,但很多只是羅列了名詞,因為我也沒搞清楚這些演算法或者沒精力詳細講解,只是寫出來作為關鍵字,有興趣的同學可以自行百度,
寫作程序中參考了很多資料文章,無法一一注明了,在此一并做感謝,
文章概述
本文先舉了一些生活中使用資料挖掘的案例,讓讀者對資料挖掘有感性認識,接著介紹了常用的資料挖掘方法,并分別介紹了這些方法的定義和應用場景,
對于每種資料挖掘方法,我都舉了一個生活中的小場景作為例子,說明怎么用這個方法來解決這個場景中的問題,例如使用線性回歸指導我們買房選房,使用關聯分析來輔助彩票選號,用決策樹輔助我們閱讀體檢資料,
另外,我將一些資料處理技巧,例如非數值資料處理方法,文本資料處理方法,演算法原理等知識穿插在文章里面,大家在實踐時可以參考,
資料挖掘案例
資料挖掘技術在我們生活中隨處可見,下面給大家介紹幾個案例,讓大家對資料挖掘技術有直觀感受,
? 
沃爾瑪通過資料挖掘發現啤酒與尿布銷售關系
20世紀90年代的美國沃爾瑪超市中,沃爾瑪的超市管理人員分析銷售資料時發現了一個令人難于理解的現象:在某些特定的情況下,“啤酒”與“尿布”兩件看上去毫無關系的商品會經常出現在同一個購物籃中,
為了搞清楚具體原因,沃爾瑪對這些同時購買啤酒和尿布的顧客展開了調研,最后他們發現,原來購買大部分客戶是嬰兒父親,他們在下班回家的路上為孩子買尿布,然后又會順手購買自己愛喝的啤酒,
在知道這個規律后沃爾瑪將這兩樣商品擺放在一起進行銷售、并獲得了很好的銷售收益,這種現象就是賣場中商品之間的關聯性,研究“啤酒與尿布”關聯的方法就是購物籃分析,
現在很多購物網站會有推薦商品的功能,在你把某些商品加入購物車后,系統會提示你“購買此商品的人多數會同時購買XXX”,其背后原理,也是依靠“購物籃分析”,
某打車平臺通過大資料發現司機與乘客私下交易
某打車平臺經過資料挖掘,發現系統中存在大量司機存在相同的操作順序:“接到訂單”->"移動到乘客附近"->"取消訂單"->"重新上線",
經過運營人員分析,這些司機是在借助導航接到乘客后,取消訂單,繞過平臺與乘客私下交易,這種行為會給乘客出行安全帶來安全隱患,
于是該平臺新增規定,如果司機上線接單地點與前次取消的訂單目的地相近時,就判定司機與乘客私下交易,對其發出警告或者限制其接單,
某購物平臺使用資料挖掘提高優惠券營銷能力
以優惠券盤活老用戶或吸引新用戶進店消費是一種重要營銷方式,然而隨機投放的優惠券對多數用戶造成無意義的干擾,對商家而言,濫發的優惠券可能降低品牌聲譽,同時難以估算營銷成本, 個性化投放是提高優惠券核銷率的重要技術,它可以讓具有一定偏好的消費者得到真正的實惠,同時賦予商家更強的營銷能力,
該購物平臺分析通過分析系統消費資料,根據得到優惠券后是否會購買商品的概率,將系統用戶劃分為幾類,針對其中獲取到優惠券后大概率會使用的顧客進行集中投放,大大提升了優惠券活動營銷效果,
某微博網友質疑天貓雙十一銷售額資料造假
2019年天貓雙十一資料公布后,有網友指出這個數字與4月份一條微博預測的資料十分接近,該博主據此懷疑天貓每年銷售額資料是根據公式捏造的,


但其實知道資料挖掘的人會知道,世界上有很多資料都是可以用資料公式預測的,小到公司的業績,大到全球航空客運量,甚至世界經濟總額,人口數量變化,都是可以預測的,
某人使用yolo3輔助自己整理照片
某人為了存盤了大量家庭成員生活照片,為了將這些照片按家庭成員分類存盤(區分自己夫妻,父母,孩子的照片),他使用labelImg工具對其中一些照片做了標記(父親,母親,自己,妻子,孩子,總共5類),并在darknet環境下用yolo3來訓練,最終訓練出一個模型用于識別照片上家人資訊,通過使用這個模型,他就可以很輕易地將照片分類存盤,
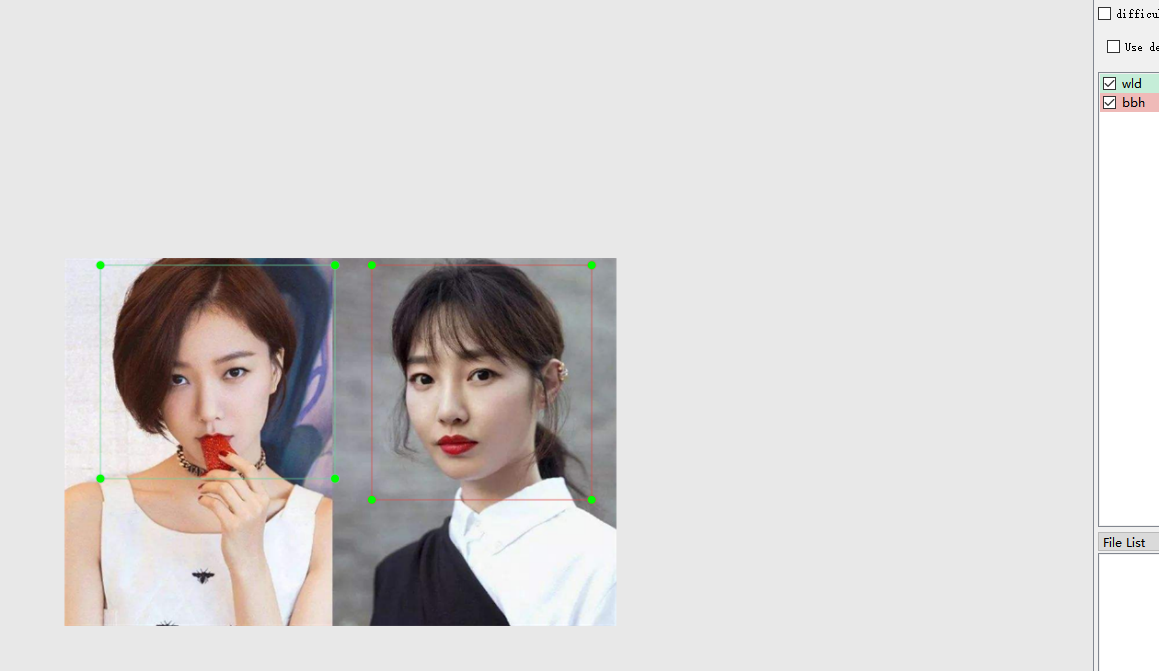
? 圖:訓練識別王珞丹和白百何模型的圖片打標示例
資料挖掘定義
資料挖掘是指從大量的資料中通過演算法找出隱藏于其中有價值的資訊的程序,從宏觀價值上來說,資料挖掘的價值體現在描述和預測上,
描述:以簡潔概要方式描述資料之間規律,例如從房產中介資料中分析影響各種因素對房價的影響,(如房子大小,位置,裝修情況等)
預測:是通過對所提供資料集應用特定方法分析所獲得的一個或一組資料模型,并將該模型用于預測未來新資料的有關性質,例如根據歷史房價資訊,預測房價未來幾年漲幅,
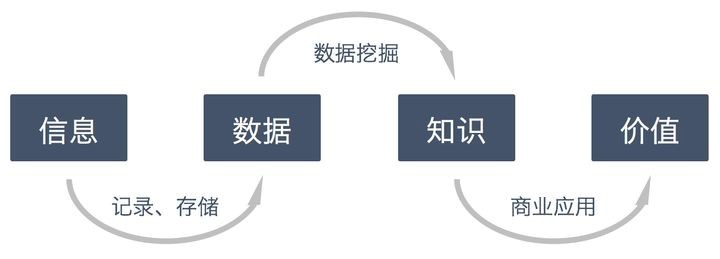
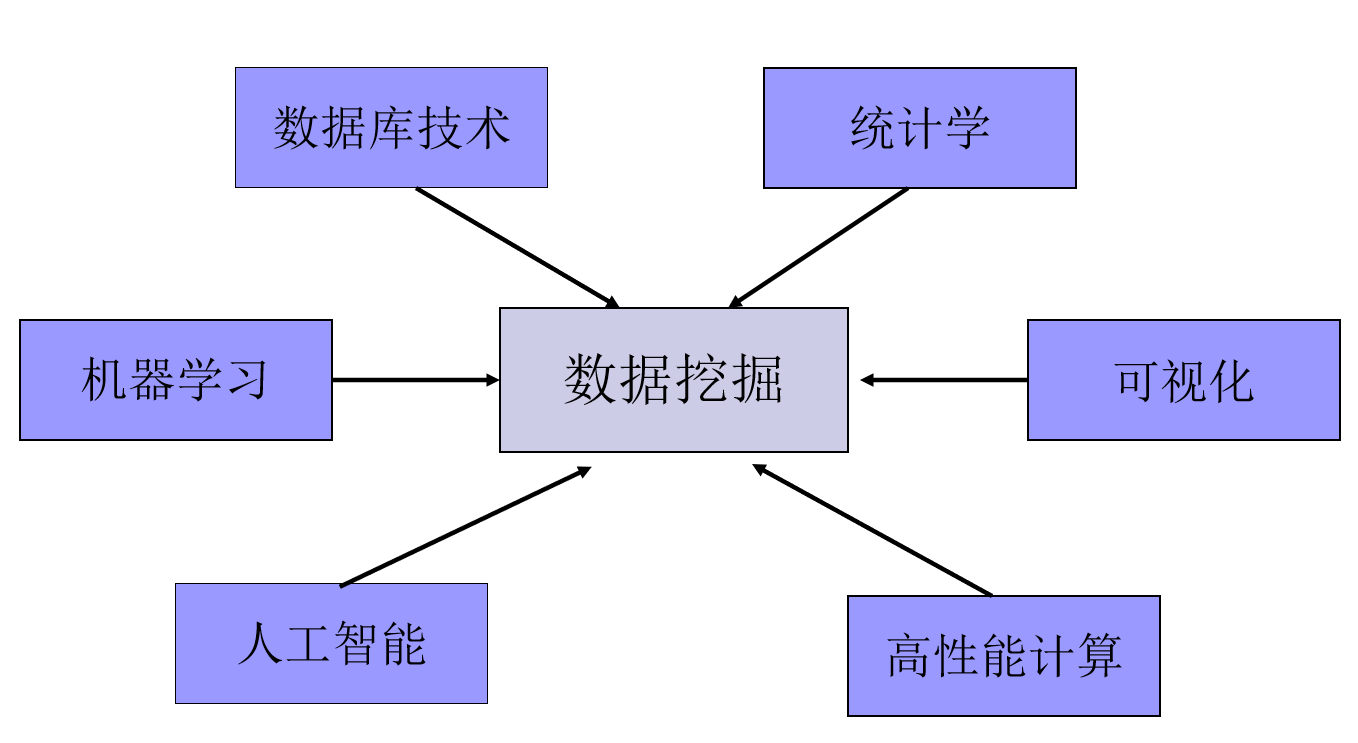
資料挖掘通常與計算機科學有關,并通過統計、在線分析處理、情報檢索、機器學習、專家系統(依靠過去的經驗法則)和模式識別等諸多方法來實作上述目標,
對資料挖掘的錯誤認識:
1 挖掘出的結果都是正確的
實際:挖掘演算法并不保證結果的完全正確,挖掘出的結果只具有概率上的意義,只具有參考價值,
2有資料挖掘就能自動找出系統有價值的資訊
實際:資料挖掘只是幫助專業人士更深入、更容易的分析資料,資料挖掘技術可以提供很多模型對資料進行挖掘,但無法告知某個模型對企業的實際價值,
即使得到有用的模型,也要將其與實際生產活動結合才可以體現價值,
?
常用資料挖掘方法簡介
資料挖掘的方法非常多,不過總的來說可以將它們歸成幾大類,以下是一種歸類方法(資料挖掘歸類方法有多種,不過大同小異)
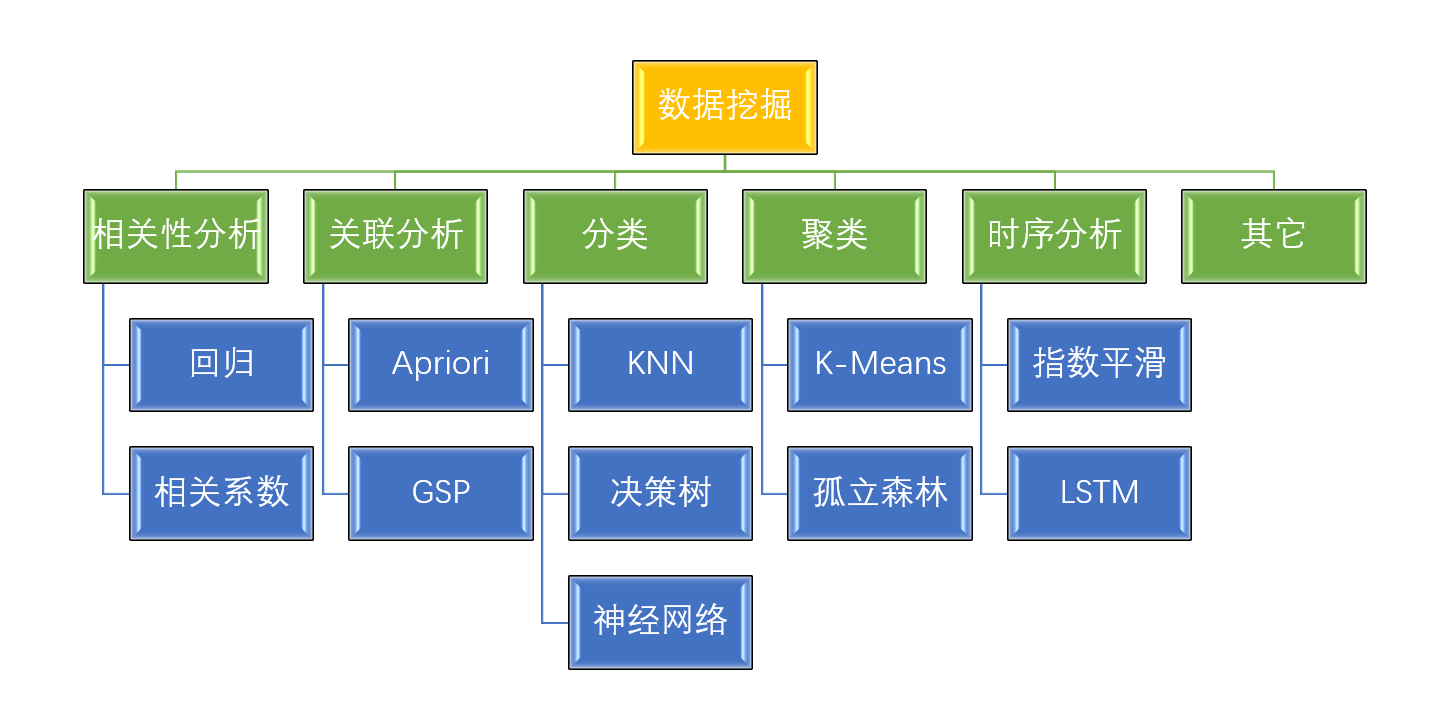
綠色的就是資料挖掘的方法,常見的方法共有五個:相關性分析、關聯分析、分類、聚類、時序分析,
每種方法都有多種演算法,不同演算法適用于不同型別資料,實踐時我們可以多嘗試幾種演算法,看哪種演算法最適合當前場景,
相關性分析
定義與應用場景
相關性分析是指對兩個或多個具備相關性的變數元素進行分析,從而衡量兩個變數因素的相關密切程度,
常用演算法:
回歸
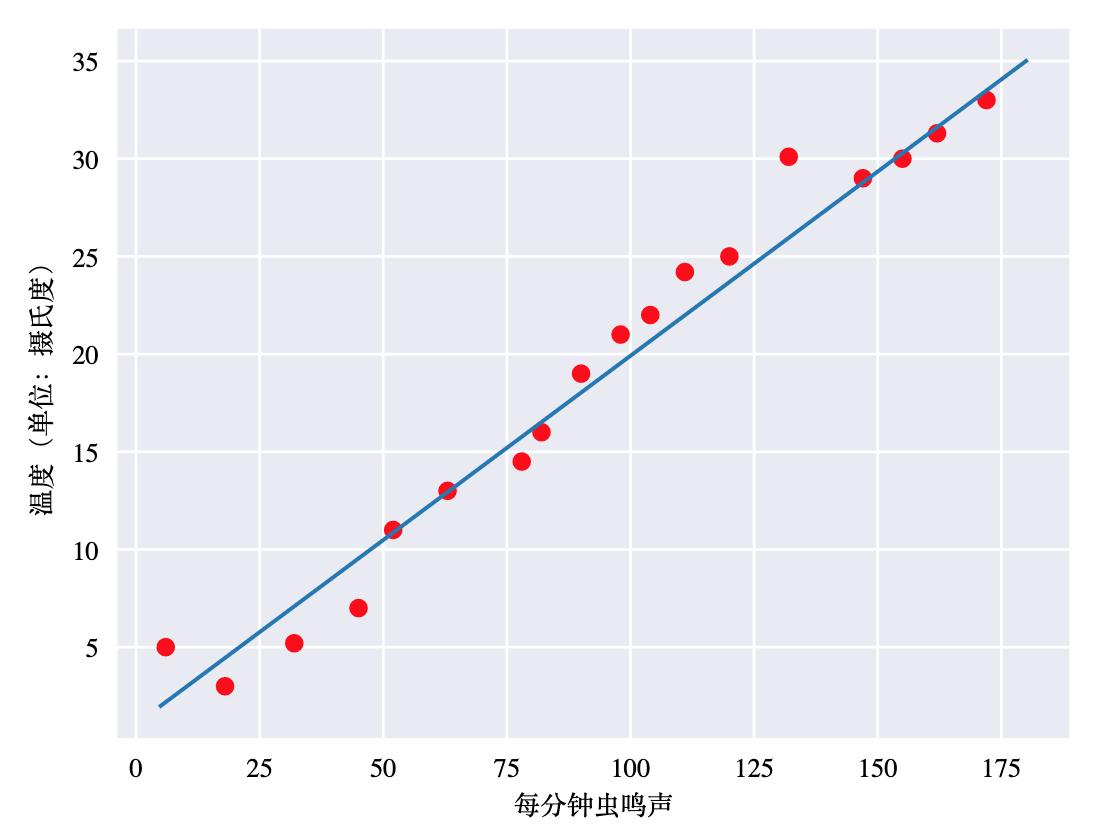
回歸分析是處理多變數間相關關系的一種數學方法,它是指研究一組隨機變數(Y1 ,Y2 ,…,Yi)和另一組(X1,X2,…,Xk)變數之間關系的統計分析方法,
通常Y1,Y2,…,Yi是因變數,X1、X2,…,Xk是自變數,一般我們會使用數學方程式來表示因變數和自變數之間的關系,用以描述自變數的變化會對因變數產生什么樣的影響,
根據回歸分析建立的變數間的數學運算式,稱為回歸方程,
一元線性回歸與多元線性回歸
線性回歸假設輸出變數是若干變數的線性組合,并根據這一關系求解線性組合的最優系數,
一個多變數線性回歸模型表示為以下的形式:
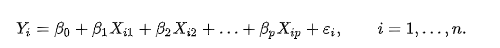
這種模型也稱為多元線性回歸方程式,如果變數只有一個,那多元線性回歸,就會退化成為一元線性回歸,回歸方程就是我們熟悉的中學知識:直線方程式y = b x + a
方程式中的b,即直線斜率,代表自變數x對y的影響程式,它的絕對值越高,說明x對y的影響越大,
歷史上第一個線性回歸運算式是用于描述人類子代與父代身高的關系的:
y = 0.516x + 33.73,式中的y和x分別代表子代和父代身高,單位是英寸(一英寸= 2.54厘米)
這個式子表明父代身高比較高時,子代身高大概率會低于父代,反之父代身高較矮時,子代身高有較大可能高于父代,
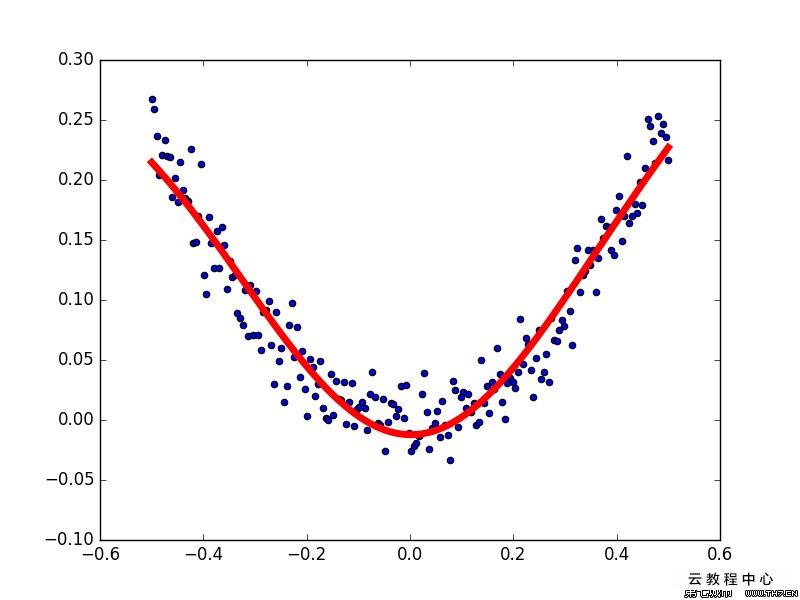
從幾何圖形上理解,一元線性回歸就是找到一條直線,使得每一個y值到直線的距離之和最小,(多元則是找到一個超平面)
線性回歸模型簡約而不簡單,它即能體現回歸方法的基本思想,而且又能構造出功能更強大的非線性模型,
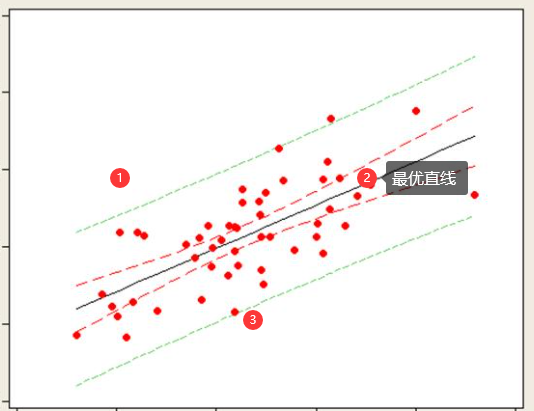
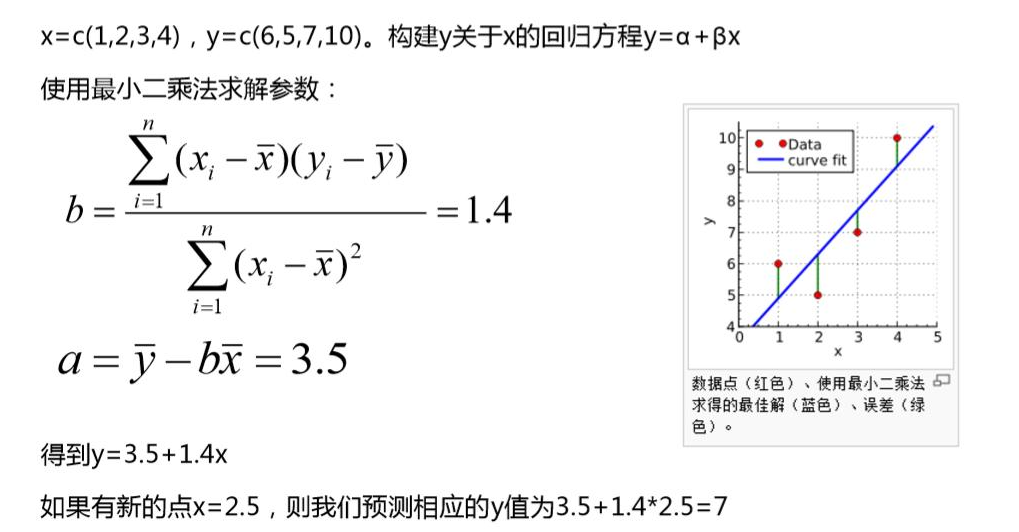
圖:一個線性回歸計算程序
應用
回歸方程式,我們可以預測電影票房,計算王者排名,給法官做刑期建議,
也可以根據公式系數,研究各種變數因素對結果影響大小,例如分析載重和路徑分別對油耗影響,
或者根據公式計算結果,尋找與結果差異較大的資料做分析,例如做房地產撿漏,之前我在網上看過一個人使用百度和高德提供的資料,分析開店選址的,也是用到回歸的方法,
非線性回歸
假設自變數與因變數之間關系是非線性函式的回歸分析方法稱為非線性回歸,
例如拋物線,雙曲線,指數增長曲線,
可以使用衍生變數的方法,借助線性回歸的方法來計算非線性函式,
衍生變數就是對戶現有變數做組合加工,從而生成一個新的變數,通過計算出這個新變數與其它變數的線性關系,從而得出非線性函式,
常見的衍生變數構造方法有分箱、相乘、平方、開方、算比例等,
有了衍生變數后,一元二次回歸可以看成是對因變數y與自變數x,衍生變數x*x的線性回歸,
舉例:我們知道功率(W),電壓(U),電流(I)之間有一個關系:功率 = 電流 乘以 電壓,
現在假設我們不知道這個規律,只是拿到了一組功率,電壓,電流的資料,看一下怎么用衍生變數和線性回歸的方法來發現這個規律,
原始資料如下:
| U | I | W |
|---|---|---|
| 220 | 1 | 220 |
| 220 | 2 | 440 |
| 220 | 6 | 1320 |
| 220 | 6 | 1320 |
| 220 | 8 | 1760 |
| 220 | 2 | 440 |
| 5 | 1 | 5 |
| 5 | 2 | 10 |
| 25 | 0.8 | 20 |
| 25 | 0.6 | 15 |
| 360 | 34 | 12240 |
| 360 | 7 | 2520 |
| 360 | 23 | 8280 |
構造衍生變數后變數(嘗試加了電流平方,電壓平方,電壓乘以電流三個變數)如下:
| U | I | UI | I2 | U2 | W |
|---|---|---|---|---|---|
| 220 | 1 | 220 | 1 | 48400 | 220 |
| 220 | 2 | 440 | 4 | 48400 | 440 |
| 220 | 6 | 1320 | 36 | 48400 | 1320 |
| 220 | 6 | 1320 | 36 | 48400 | 1320 |
| 220 | 8 | 1760 | 64 | 48400 | 1760 |
| 220 | 2 | 440 | 4 | 48400 | 440 |
| 5 | 1 | 5 | 1 | 25 | 5 |
| 5 | 2 | 10 | 4 | 25 | 10 |
| 25 | 0.8 | 20 | 0.64 | 625 | 20 |
| 25 | 0.6 | 15 | 0.36 | 625 | 15 |
| 360 | 34 | 12240 | 1156 | 129600 | 12240 |
| 360 | 7 | 2520 | 49 | 129600 | 2520 |
| 360 | 23 | 8280 | 529 | 129600 | 8280 |
接下來我們使用weka進行線性回歸,
weka是一個簡易的java語言開發的資料挖掘軟體,它提供了界面和API,分別方便普通用戶和java程式員進行資料挖掘,在百度學術可以搜索到很多使用weka進行商業資料挖掘的論文(見下圖),它的使用簡介見后面附錄,
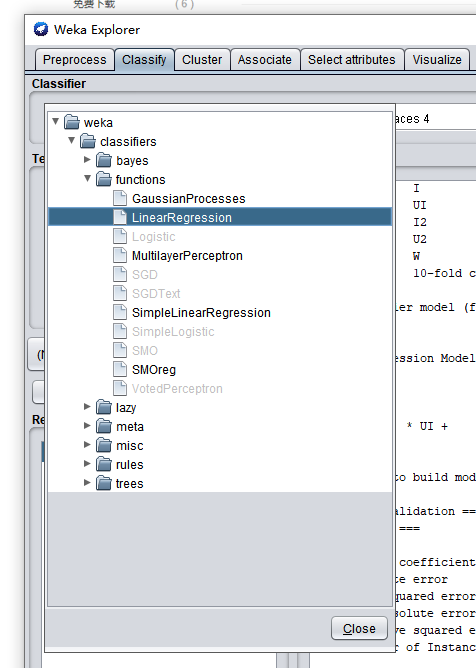
將這些資料輸入到weka,選擇“Classify”(分類)下面的線性回歸演算法,
點擊執行,程式即輸出一個公式
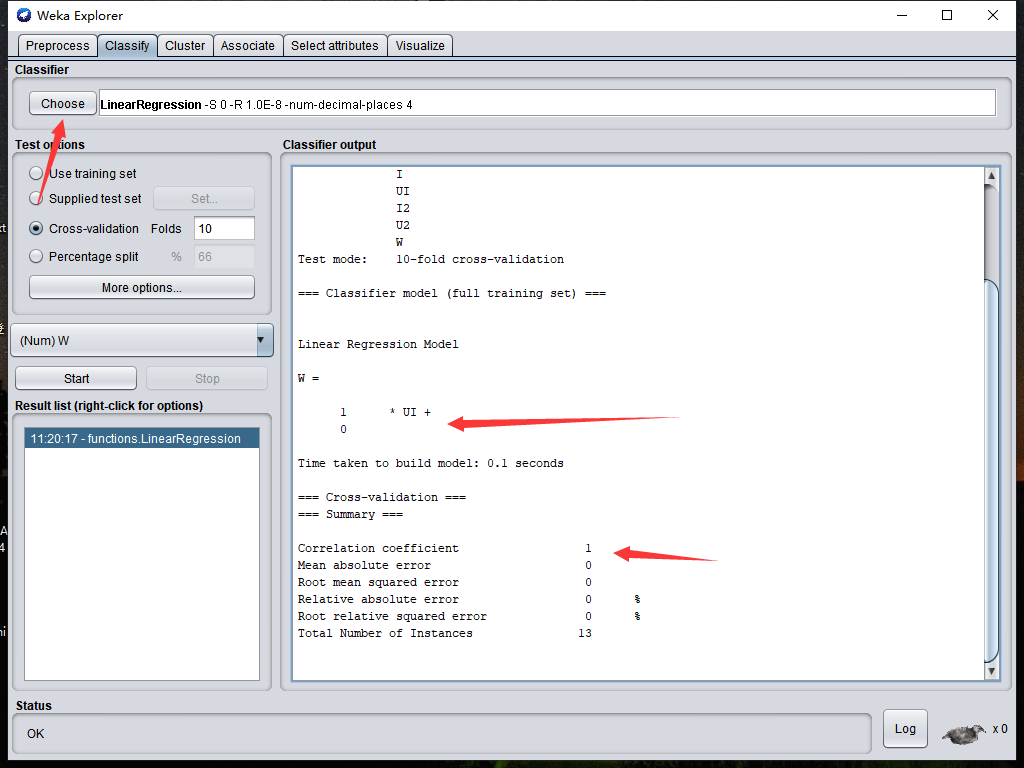
根據這個方程式,我們可以知道功率與衍生變數UI有線性關系,w = 1 * UI
而UI變數我們構造時是使用電壓乘以電流,
所以我們發現了功率,電壓,電流之間存在關系:功率 = 電流 乘以 電壓
知道這個關系后,我們就知道電流跟電壓分別對功率的影響,如果后面發現有一些資料,功率與電流和電壓之間關系不滿足這個方程,那很有可能是資料出了錯,
圖表相關分析
將資料轉換成圖表,方便業務人員分析,常見的方法是將資料輸出成散點圖,并且畫出趨勢線,
協方差及協方差矩陣

相關系數
相關系數是最早由統計學家卡爾·皮爾遜設計的統計指標,是研究變數之間線性相關程度的量,一般用字母 r 表示,由于研究物件的不同,相關系數有多種定義方式,較為常用的是皮爾遜相關系數,
相關系數是用以反映變數之間相關關系密切程度的統計指標,相關系數是按積差方法計算,同樣以兩變數與各自平均值的離差為基礎,通過兩個離差相乘來反映兩變數之間相關程度;著重研究線性的單相關系數,

實踐—使用weka分析影響房產價格因素
https://blog.csdn.net/Shellerine/article/details/53200500?utm_source=blogxgwz4
https://blog.csdn.net/kestory/article/details/90521981


數值資料處理技巧
標準化
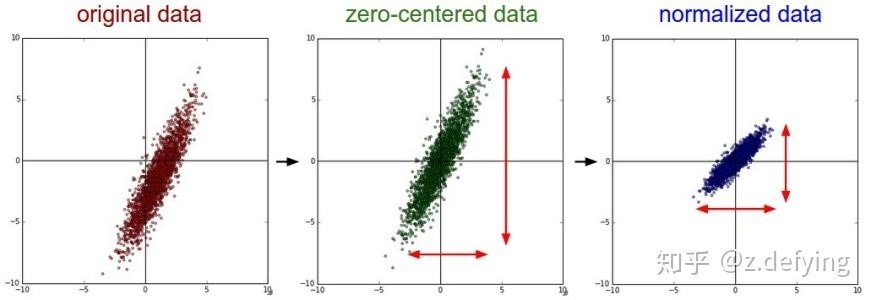
資料的標準化(normalization)是將資料按比例縮放,使之落入一個小的特定區間,
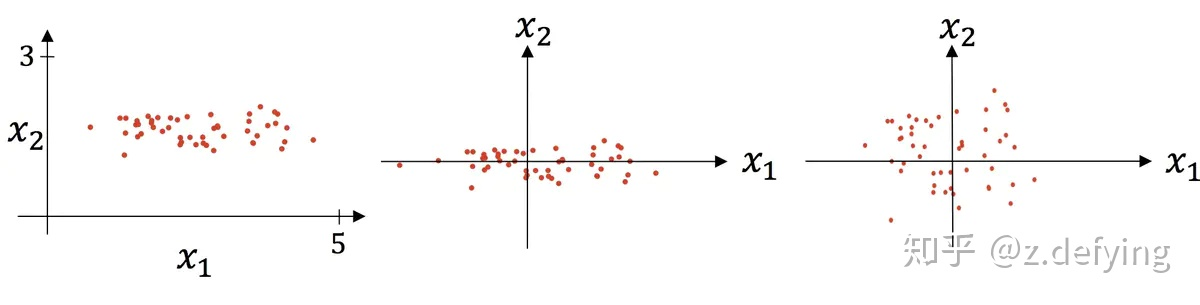
歸一化
歸一化是一種簡化計算的方式,即將有量綱的運算式,經過變換,化為無量綱的運算式,成為標量, 在多種計算中都經常用到這種方法, 例如將身高和體重都歸一成比例小數資料,
缺失值
實際生產中業務資料往往有缺失,此時我們需要通過各種演算法補齊缺失值,例如取眾數,取平均值,取近鄰值等,
非數值資料處理技巧
有序類別
一些有序的類別高中低,胖瘦,可以直接使用數字代替,
無序類別(使用啞變數,即虛擬變數)
沒有大小關系的類別,例如東南西北,男人女人,可以使用啞變數處理,
文本資料
有時候模型的輸入是文本資料,例如新聞,社交媒體,我們需要把文本轉化為數值矩陣,
有時候模型的輸入是文本資料,例如新聞,社交媒體發言等,需要把文本轉化為數值矩陣,
常用處理方法有兩種:
單詞統計(word counts): 統計每個單詞出現的次數,
TF-IDF(Term Frequency-Inverse Document Frequency): 統計單詞出現的“頻率”,
網上有通過資料挖掘分析紅樓夢作者的例子,有興趣的同學可以自行百度,
關聯分析
定義與應用場景
關聯分析是一種簡單、實用的分析技術,就是發現存在于大量資料集中的關聯性或相關性,從而描述了一個事物中某些屬性同時出現的規律和模式,
關聯分析是從大量資料中發現項集之間有趣的關聯和相關聯系,
關聯分析的一個典型例子是購物籃分析,該程序通過發現顧客放入其購物籃中的不同商品之間的聯系,分析顧客的購買習慣,通過了解哪些商品頻繁地被顧客同時購買,這種關聯的發現可以幫助零售商制定營銷策略,其他的應用還包括價目表設計、商品促銷、商品的排放和基于購買模式的顧客劃分,
可從資料庫中關聯分析出形如“由于某些事件的發生而引起另外一些事件的發生”之類的規則,如“67%的顧客在購買啤酒的同時也會購買尿布”,因此通過合理的啤酒和尿布的貨架擺放或捆綁銷售可提高超市的服務質量和效益,又如“‘C語言’課程優秀的同學,在學習‘資料結構’時為優秀的可能性達88%”,那么就可以通過強化“C語言”的學習來提高教學效果,
常用演算法
窮舉法
窮舉法不是業務常用的演算法,只是我覺得使用窮舉的方法來解決“購物籃問題”,比較直觀,對于理解其它演算法也有幫助,所以把它列出來,
舉個例子,假設我們經營一家小超市,里面提供了以下幾種商品:面包,牛奶,奶粉,尿布,可樂,雞蛋,我們想分析一下顧客的購物清單,看里面是否有高關聯度的商品,
那我們可以先對商品組合做窮舉(例如面包和牛奶,面包和奶粉,面包和尿布,面包和牛奶及雞蛋等),并分別計算出同時購買了該商品組合的清單數量,
例如我們可能會得出以下資料:
| 商品組合 | 清單數量 | 占比 |
|---|---|---|
| 面包 | 10 | 有購買面包的清單數量/總數量 |
| 面包和牛奶 | 6 | 6 / 10 |
| 面包和尿布 | 3 | 3 / 10 |
| 面包和奶粉 | 0 | 0 / 10 |
| 面包和牛奶及雞蛋 | 3 | 3 / 6 |
(資料是我為說明演算法隨手造的,勿當真)
從這個表格資料我們可以分析得出結論:購買了面包的人,有60%機率會同時買牛奶,但只有30%的人會同時買尿布,同時購買了面包和牛奶的人中,有50%的人會再買雞蛋,
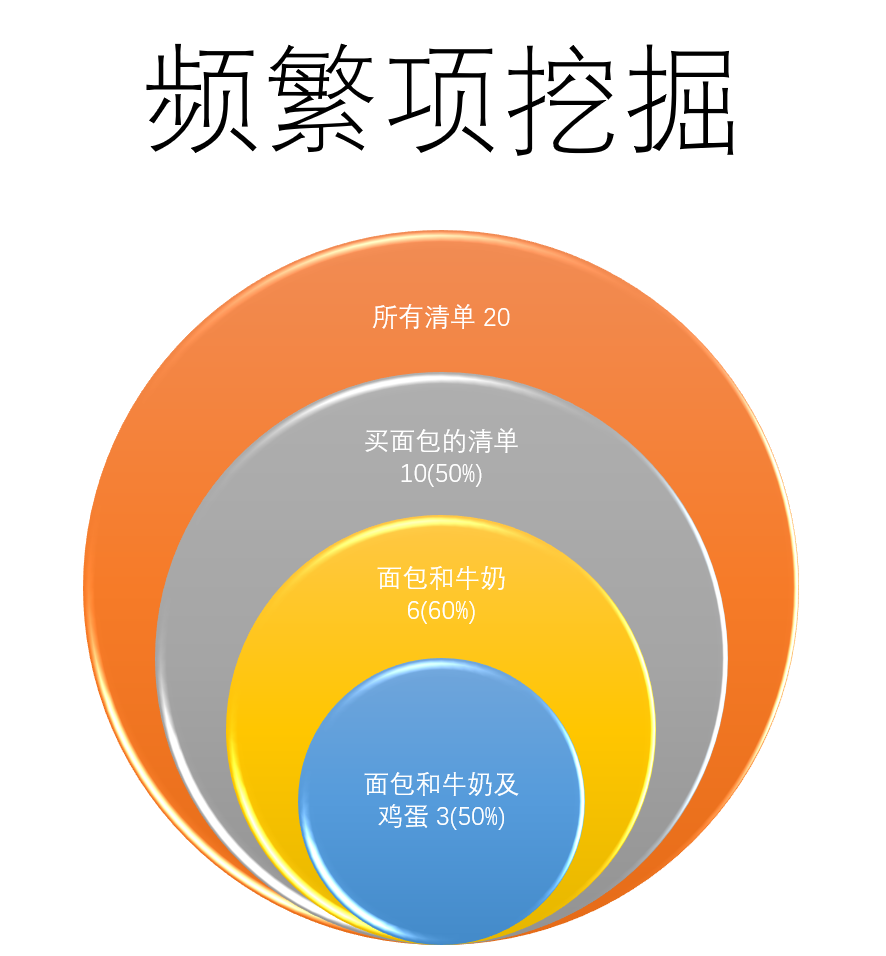
所以我們如果要做促銷,那把面包,牛奶,雞蛋打包成一個商品打折,可能會取到不錯的效果,
Apriori(先驗)演算法
在窮舉法的基礎上,提出了根據截枝,大大減少組合計算次數,加快計算速度,(舉例:如果買牛奶面包的商品人很少,那就不需要統計同時購買了牛奶面包可樂的人有多少,因為沒有意義,)
GSP演算法
在Apriori演算法,增加考慮頻繁項順序,可用于時序(有先后順序的)頻繁項挖掘,
SPADE演算法
我也沒搞懂,
實踐—使用weka發現總是一起出現的彩票號碼組合
經常研究彩票的彩民,可以會發現一些號碼經常一起出現,(例如出現2同時出現5概率比較高)找出這些組合,有利于提高中獎機率,但由于彩票開獎資料比較大,想找出這些號碼組合比較困難,我們可以使用資料挖掘的關聯分析演算法來解決此類問題,
這里我們使用weka提供的Apriori(中文意思,先驗的,推測的)演算法進行資料挖掘,
我從福利彩票網站抓取了最近100期的彩票記錄資料,處理了一下,轉換成Apriori演算法需要的矩陣并使用它分析里面是否有頻繁項,
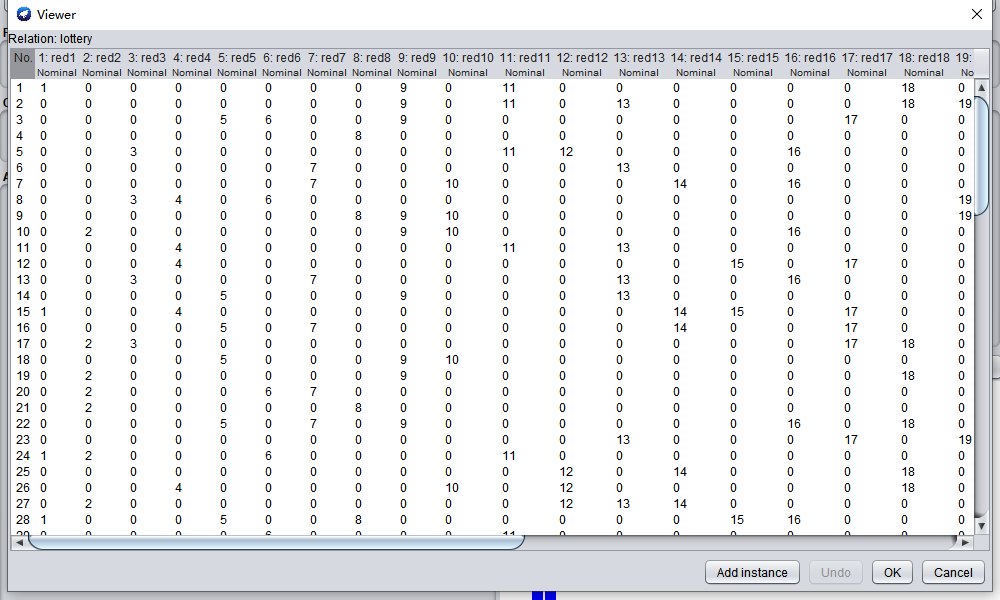
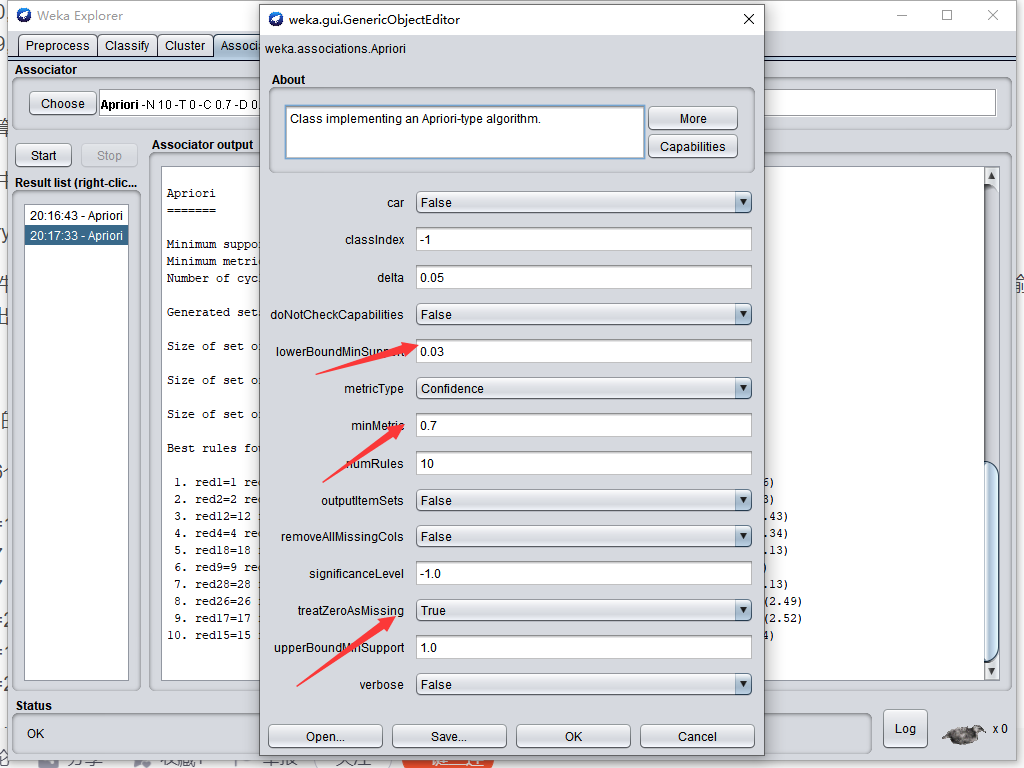
出現概率超過3%,并且支持度超過70%
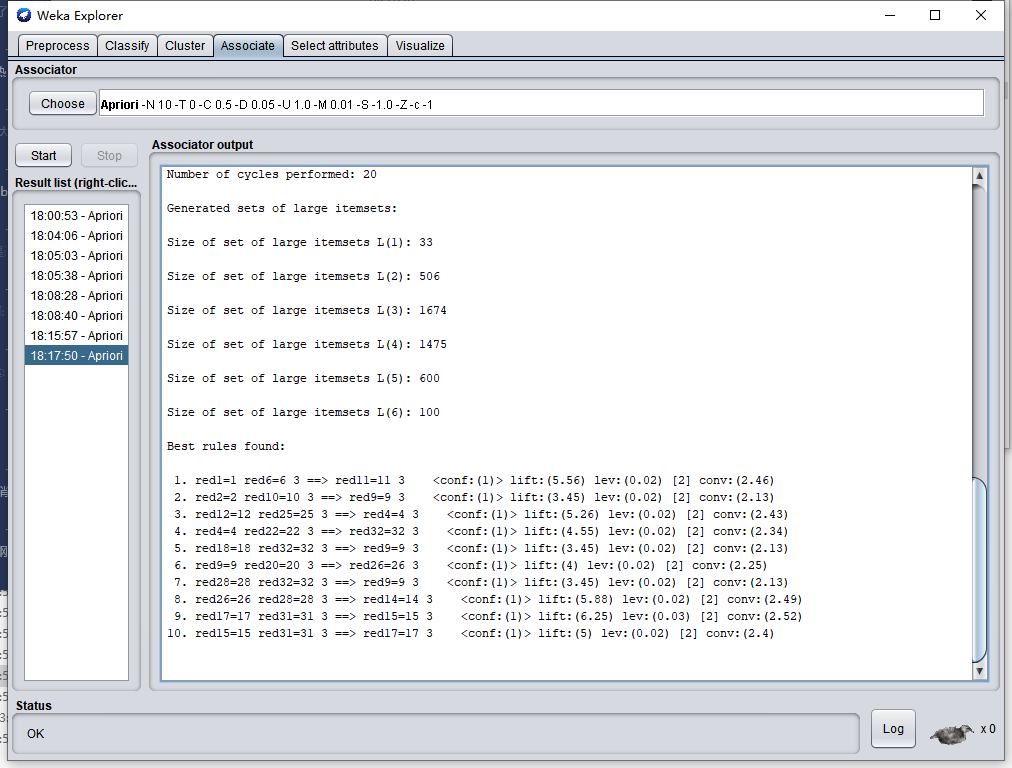
結果說明:過去100期雙色球開獎結果中,1、6、11同時出現的次數是3次,并且每次出現1和6的時候,肯定會出現11, 2、10、9也是同理,我們買彩票時可以根據這個挖掘結果來指導選號,以期提高中獎率,
分類
定義與應用場景
分類是基于包含其類別成員資格已知的觀察(或實體)的訓練資料集來識別新觀察所屬的一組類別(子群體)中的哪一個的問題,例如,將給定的電子郵件分配給“垃圾郵件”或“非垃圾郵件”類,并根據觀察到的患者特征(性別,血壓,某些癥狀的存在或不存在等)為給定患者分配診斷,分類分析,簡單地說就是把資料分成不同類別,
分類演算法一般使用機器學習里面屬性有監督學習演算法,即需要輸入一些樣本,根據樣本確定演算法引數,從而生成一個適合業務的演算法模型,
常用演算法
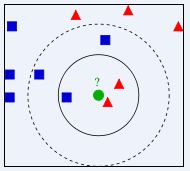
k最近鄰分類(即KNN)
有句話說:“想知道自己是什么樣的人,那看看自己經常交往的十個人就知道”,KNN分類的原理就是這樣,通過觀察與新資料距離最近的N個資料的分類標簽,數量最多的標簽就是新資料的分類,(N需要根據業務人員經驗確定,不宜太大)
例如以下圖:圓圈是新資料,假設規定根據與它最相鄰的3個資料來分類,因為其中兩個是三角形,一個是正方形,則會認為該資料是三角形,
當N值取5時,最近的5個資料里面有3個是正方形,2個是三角形,則新資料會被認為是正方形,
距離:
資料挖掘有一個的重要概念,就是資料距離:就是,如果是單維資料,要確定距離十分方便,例如有三個人體身高資料,分別是1.6、1.7、1.8,那這三個資料相互的距離直接用資料值相減就可以計算出來,
但我們實際業務資料經常是有多種維度的,例如有三個西瓜,它們資料如下:
| 甜度 | 重量 | 體積 |
|---|---|---|
| 0.8 | 1kg | 8 |
| 0.7 | 1.5kg | 5 |
| 0.5 | 2kg | 12 |
所以我們一般需要使用距離公式來評判資料距離,選擇不同公式對分類結果可能產生不同影響,需要根據實際業務需要選擇,
常見距離公式有:
歐式距離:
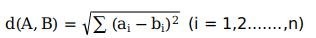
余弦距離:
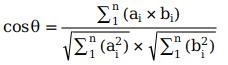
馬氏距離:
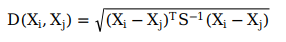
杰卡德距離:
獨熱編碼:
如果資料不是數值型,而是標簽型,例如西瓜產地有本地,新疆,云南,西瓜顏色有紅色、藍色、綠色,則需要獨熱編碼對資料進行處理,
決策樹
決策樹分類是用屬性值對樣本集逐級劃分,直到一個節點僅含有同一類的樣本為止,
決策樹演算法的模型最直觀,最易于解釋,甚至可以做為普通業務人員指導,下圖是判斷一個瓜是好瓜還是壞瓜的決策樹,其判斷程序十分接近人類思維,
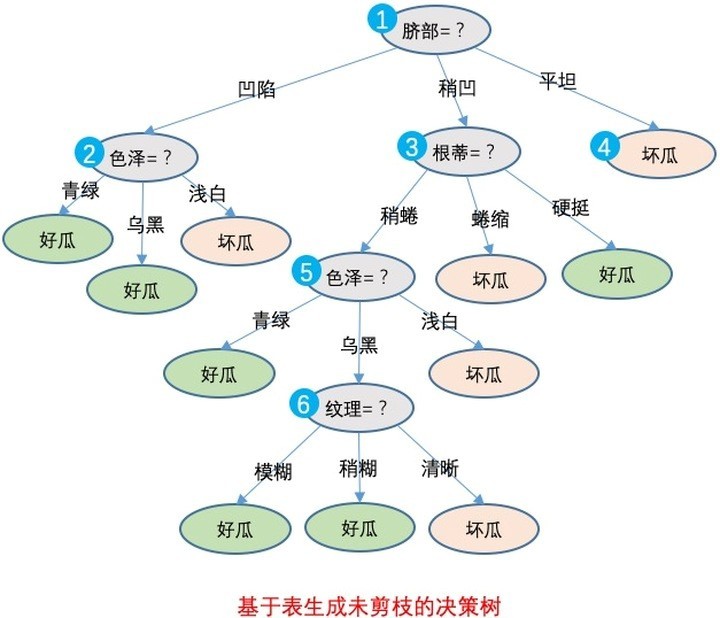
? 圖:使用C45演算法生成的決策樹
神經網路
神經網路可以認為是大量復雜的演算法單元,利用仿生學知識,模擬人類神經傳導機制連接起來形成的一種演算法,每個演算法單元里面有很多不同引數,通過調整引數,可以處理任意分類問題,我們平常總是聽到的訓練模型,就是在給這些演算法單元找合適的引數,

? 圖:使用神經網路識別影像
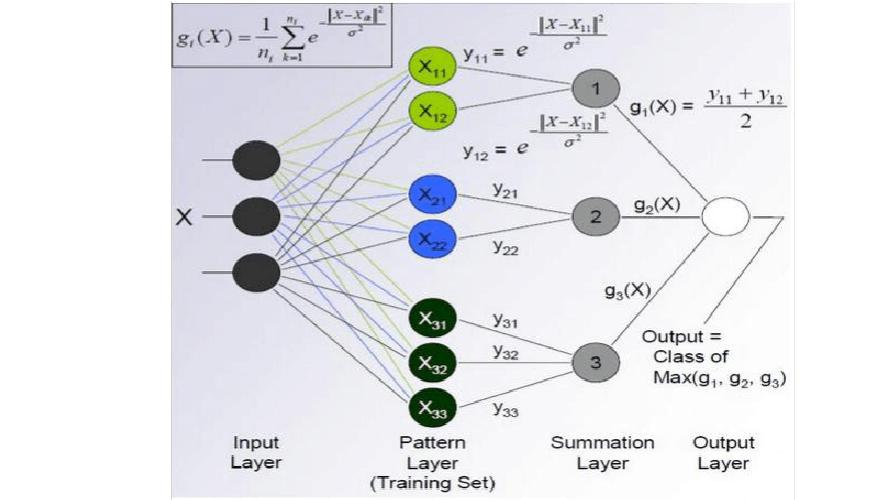
圖:使用神經網路實作公式計算
如果神經網路里面的感知器使用的演算法是線性演算法(類似前面介紹的多元線性回歸),則稱為線性神經網路,如果使用了卷積演算法,則稱為卷積神經網路,
阿爾法狗就是使用卷積神經網路的分類應用,它把棋盤當成一個19*19的影像,把下子當成一個分類問題,即輸入現在棋盤影像,輸出一個與人類高手下子后最接近的棋盤影像,(當然,它還加了其它輔助演算法,例如蒙特卡洛樹搜索樹提高贏棋概率)
貝葉斯分類
支持向量機分類(Support Vector Machine, SVM)
將資料映射到高維度,并尋找一個高維平面將資料分割開來
邏輯回歸(logistic回歸)
在線性回歸的基礎上,使用函式將連續輸出轉換成離散輸出
實踐—使用weka鑒別病人是否得了糖尿病
這里我們使用weka自帶的疑似糖尿病人身體指標資料和檢測結果做為訓練資料,使用決策樹分類演算法randomtree來訓練模型并用于根據新的病人身體指標預測其是否患糖尿病,
訓練資料在data/diabetes.arff這個檔案里面,我簡單介紹一下:
檔案里面包含了一些病人身體指標,例如懷孕次數(preg),飯后2小時血糖濃度(plas),年齡(age)等,對于每個病例,最后都會標記檢測結果為陰性或者陽性(tested_negative/ tested_positive),如果為陽性說明得了糖尿病,

我們先使用weka匯入這個檔案并在Classify這個界面,點擊“choose”按鈕,選擇演算法“RandomForest”
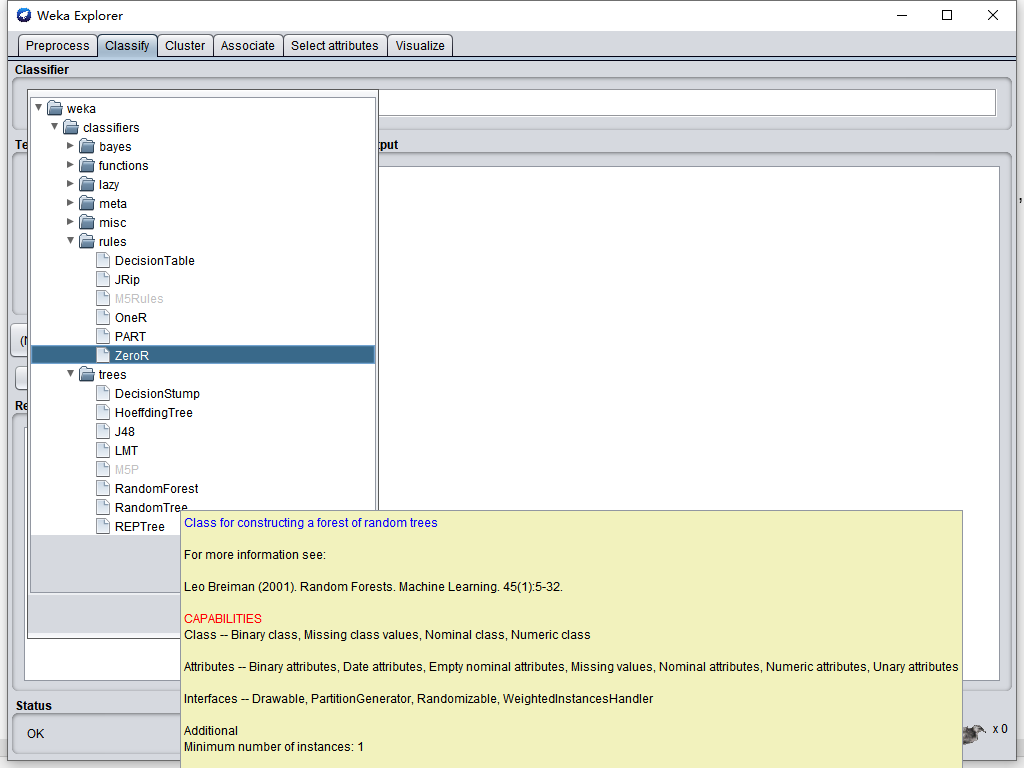
點擊"Start",訓練出模型,從輸出看,模型分類準確率有75%,效果勉強還行(50%即代表瞎猜的)
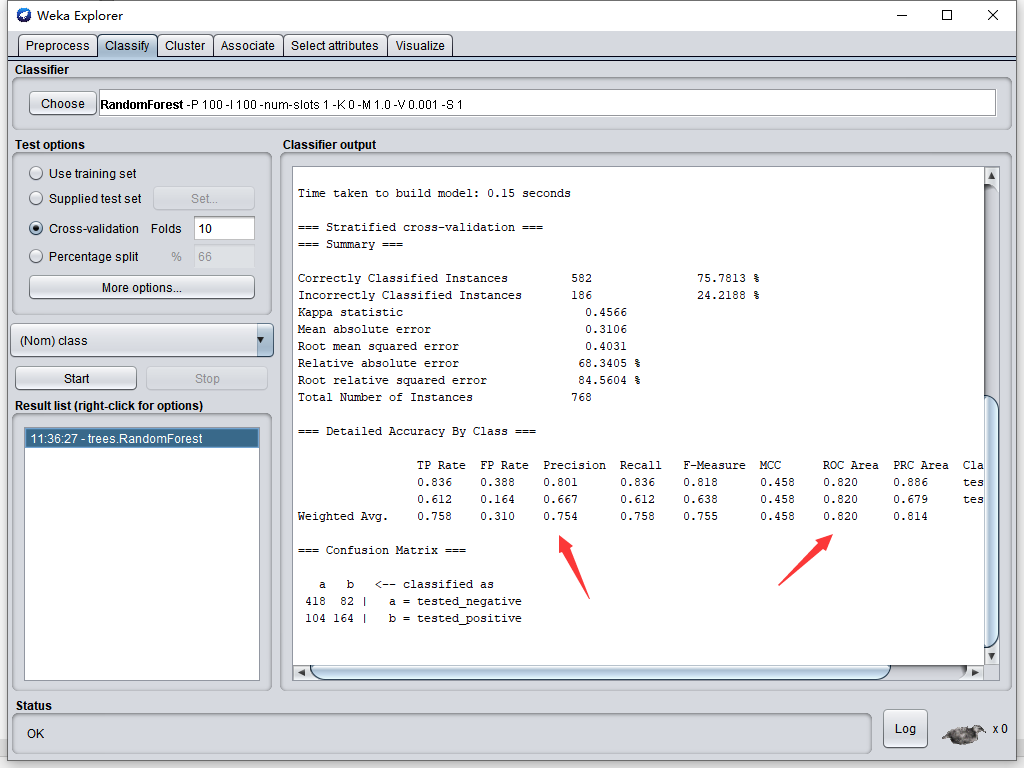
接著準備測驗檔案,將data/diabetes.arff復制一份,變成diabetes - test.arff
只保留前兩行,并把分類結果改為?,我們用這個來做為測驗資料,看模型是否能正確分出結果(實際作業時不應該拿模型資料,而是拿實際未打標資料)
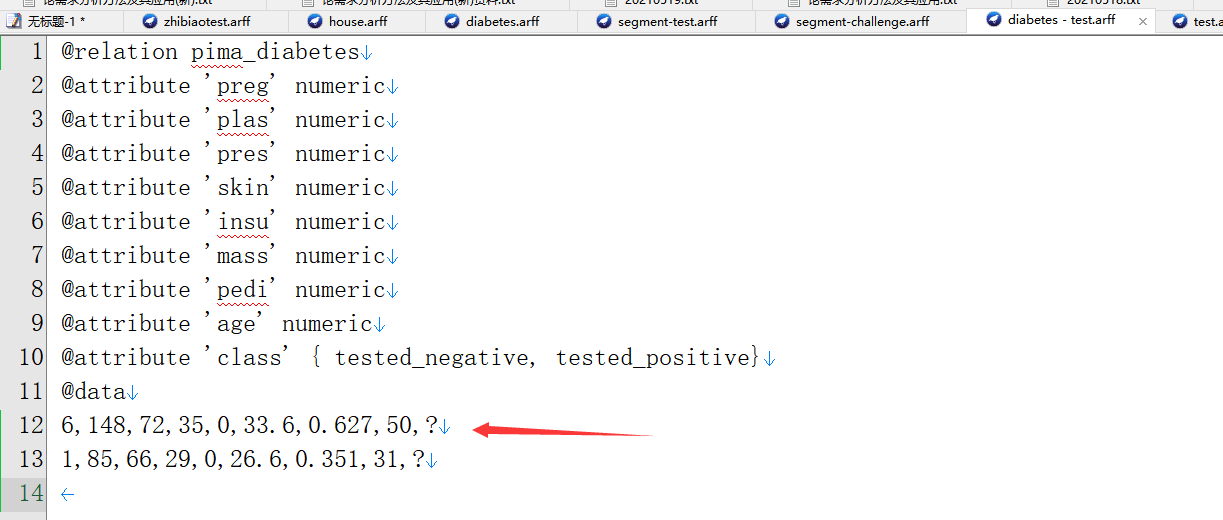
點擊"Set…"按鈕,選擇diabetes - test.arff做為測驗集,
在ResultList視窗串列項右擊,執行
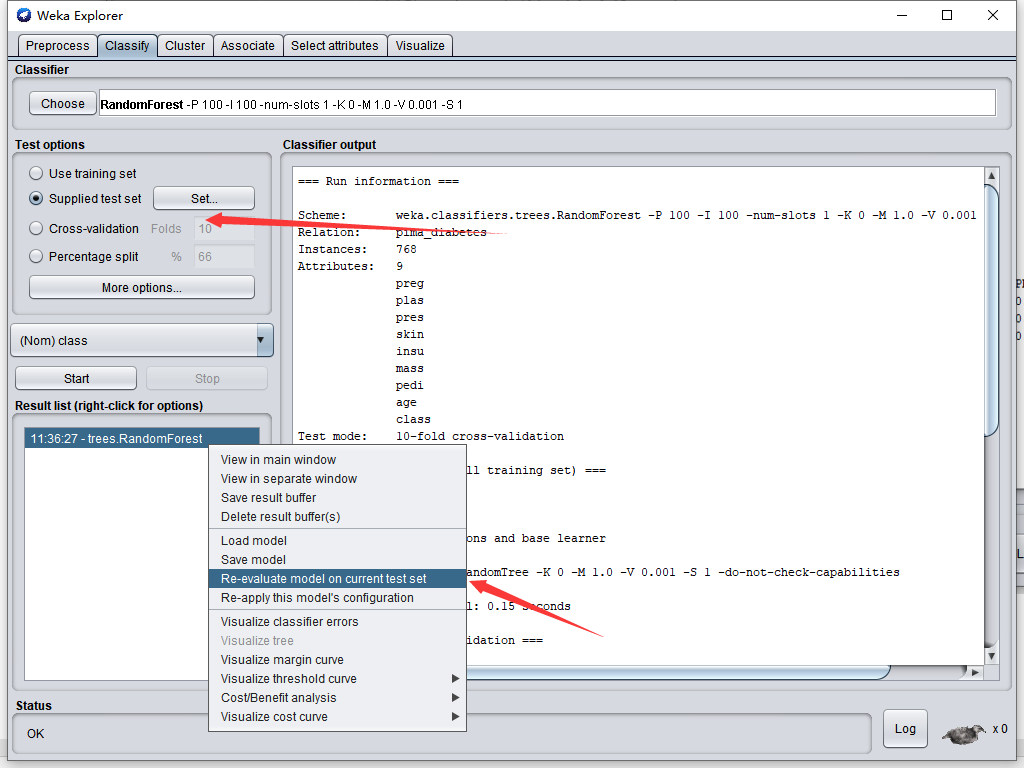
運行后輸出界面會重繪,此時再右擊Result List視窗
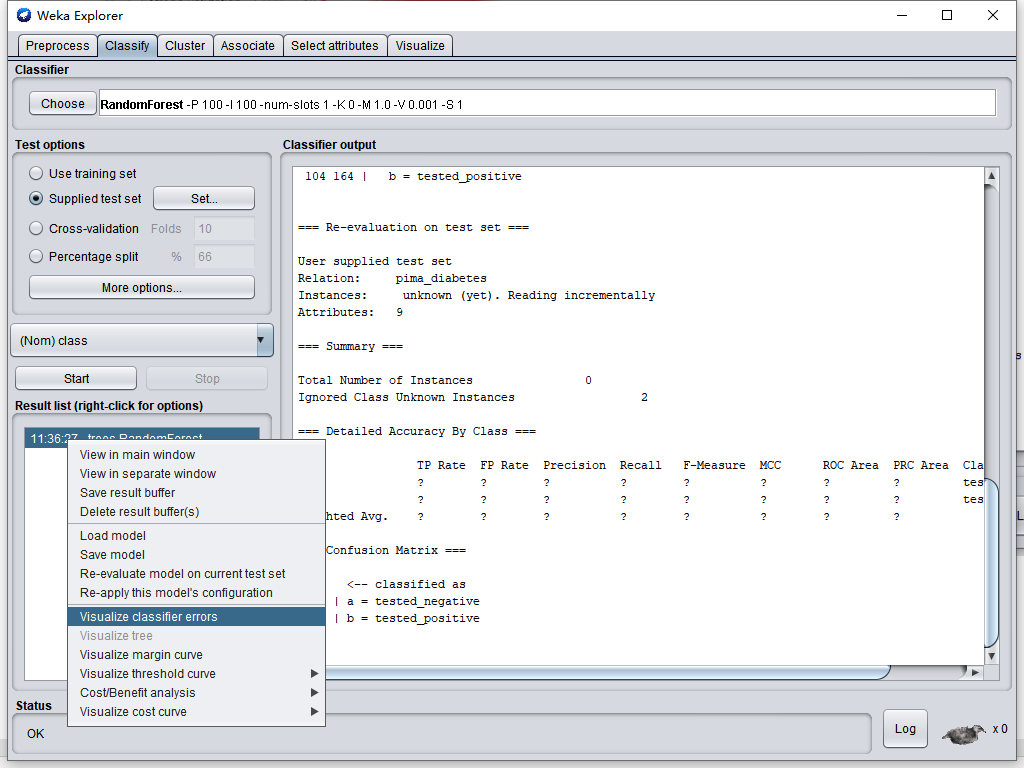
選擇Save,將檔案保存為
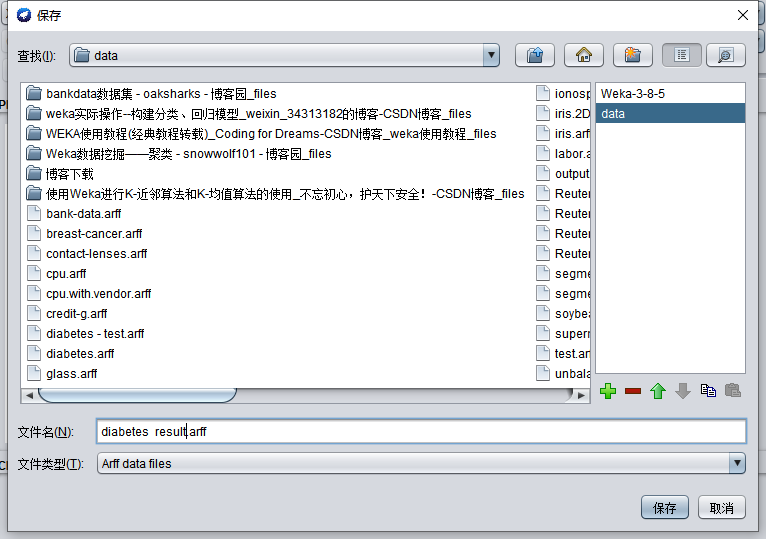
打開檔案,會發現結果多了兩列,最右邊一列是模型分類結果,符合我們預期,一個陽性一個陰性,

聚類
定義與應用場景
聚類是將資料分類到不同的類或者簇這樣的一個程序,所以同一個簇中的物件有很大的相似性,而不同簇間的物件有很大的相異性,
聚類分析是一種探索性的分析,在分類的程序中,人們不必事先給出一個分類的標準,聚類分析能夠從樣本資料出發,自動進行分類,聚類分析所使用方法的不同,常常會得到不同的結論,不同研究者對于同一組資料進行聚類分析,所得到的聚類數未必一致,
聚類演算法一般使用機器學習里面的非監督學習演算法,
常用演算法
隨機森林
使用多個弱分類演算法組合成一個強分類演算法,(類似于民主投票,選誰適合當總統)
孤立森林
孤立森林演算法是周志華教授(機器學習經典--西瓜書的作者)提出來的,用于發現例外資料的演算法,
使用隨機方法將資料集進行多輪切分,在多輪切分中,經常在比較早完全分離出來的資料則認為是例外資料,
下面是一個使用孤立森林演算法來發現圖片中例外的樹木的例子:

第1輪切分,第1次就發現了特別樣例,(上方圖片只有一棵樹,無法再分割)

第二輪切分,第2次就發現了特別樣例,(第一次切分出來的圖片上下兩部分都有樹,第二次分出來的4個圖片區域,有一塊只有一棵樹)
這棵“樹”實在太奇怪了,導致它總是能很快地跟其它樹分離開來,實際上,它是聯通的5G基站,偽裝成樹型,方便部署,
k-均值(k-means)
尋找k個中心點,將離中心點最近的資料歸到一類,跟KNN有點像,特別依賴資料距離公式,
EM最大期望演算法
DBSCAN
根據資料密度來劃分資料,

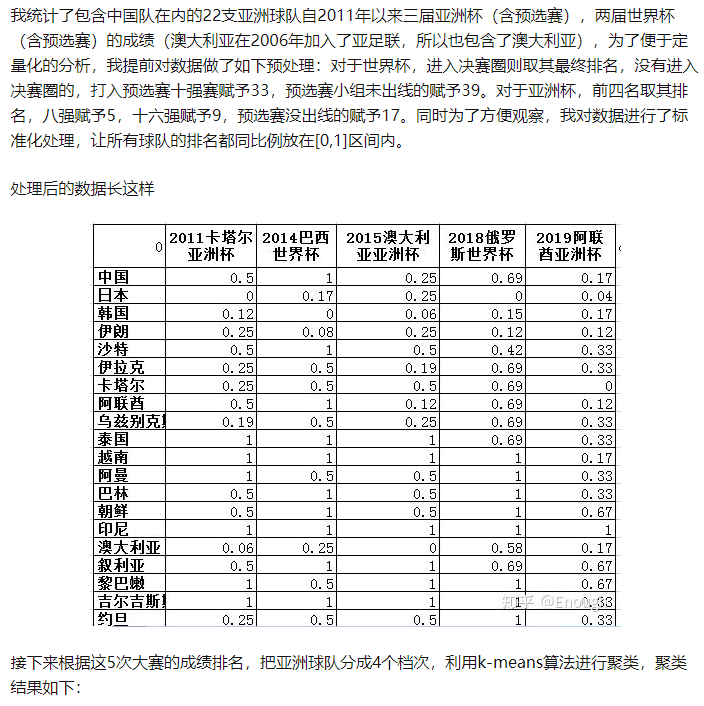
實踐—使用kmeans分析中國足球隊是亞洲幾流球隊
https://zhuanlan.zhihu.com/p/62535727 我分析了過去十年五屆大賽的成績,中國男足到底是亞洲幾流?

聚類和分類區別聯系
聚類分析跟分類分析區別是分類分析需要有已有標簽的資料,而聚類分析則不需要,
實踐中經常先使用聚類對資料進行探索,之后對有價值的資料開發分類模型用于商業應用,
時序分析
定義與應用場景
時間序列是一系列資料點,使用時間戳進行排序,例如水果的每日價格到電路提供的電壓輸出的讀數,股票每分鐘報價等,
雖然在某一給定時刻預測目標的觀測值是隨機的,但從整個觀測序列看,卻呈現出某種隨機程序(如平穩隨機程序)的特性,
隨機時間序列方法正是依據這一規律性來建立和估計產生實際序列的隨機程序的模型,然后用這些模型進行預測未來資料,
像氣溫,股票,客流等這些時序資料都適合用時序序列預測技術,
例如我們公司做的動態閾值組件就使用了時序分析的技術
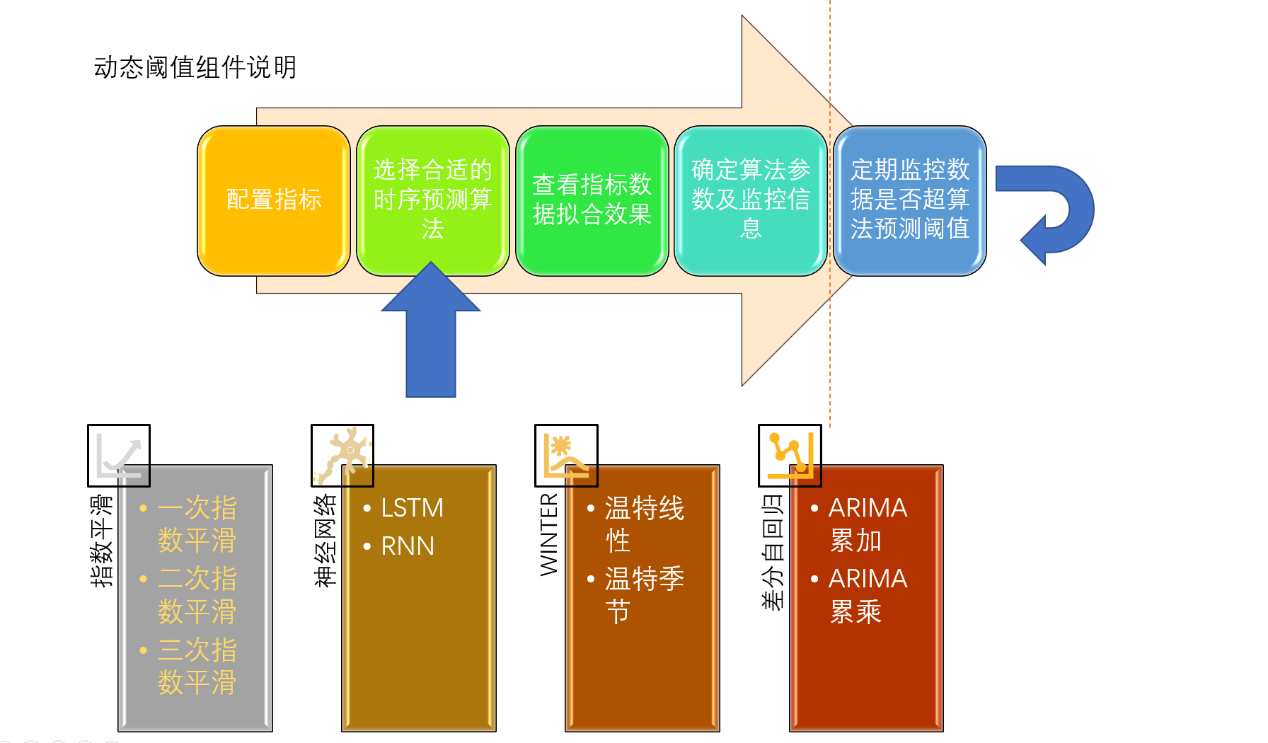
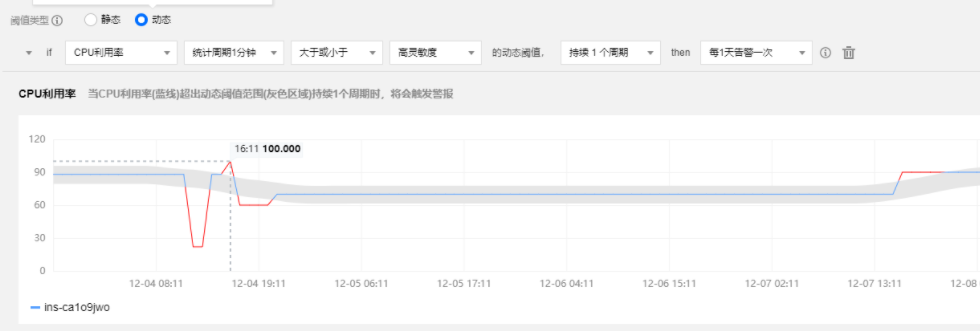
圖:通過時序分析模型結合歷史資料預測出當前時刻資料上下限,超出閾值的資料認為是例外資料,觸發告警,
常用演算法:
指數平滑
溫特霍特曲線
移動差分自回歸
神經網路(RNN和LSTM)
RNN和LSTM是深度學習神經網路演算法,深度意思是有多個中間層,
小結練習
1 請分析文章開始的資料挖掘案例,分別使用的是哪種資料挖掘方法
| 案例 | 使用技術 |
|---|---|
| 沃爾瑪通過資料挖掘發現啤酒與尿布銷售關系 | 關聯分析 |
| 某打車平臺通過大資料發現司機與乘客私下交易 | |
| 某購物平臺使用資料挖掘提高優惠券營銷能力 | |
| 某微博網友質疑天貓雙十一銷售額資料造假 | |
| 某人使用yolo3輔助自己整理照片 |
2 使用今天學習的資料挖掘知識,開發一款類似今日頭條的資訊流軟體,實作高準確率資訊推薦
一點雞湯:
資料挖掘的場景多種多樣,但核心的挖掘演算法卻相對有限,這跟我們以前學的數學,物理有點類似,很多題目看起來十分復雜,但都是通過一些基本的定理,定律可以解決,其實在職場中,想做好作業,也有類似這樣的“定理”,“定律”這樣的東西,例如《高效能人士的七個習慣》里面提到的:主動積極、以終為始、要事第一、雙贏思維、知彼知己、統合綜效、不斷更新,
說明:
本文大部分資料抄自網上,我自己做了點加工整理,僅供學習交流用,由于來源太多,并且資料整理時間太長,無法一一注明,請作者見諒,歡迎轉載,如果有侵權地方請聯系我修改,
資料挖掘的知識范圍很廣,本文雖然只是介紹了入門知識,但限于作者水平,文章中難免出現有錯漏地方,歡迎各位留言指正,
資料挖掘在網上資料非常豐富,如果各位對本文介紹的知識有興趣,可以到百度輸入關鍵字,查找相關資料,
這里介紹幾個:
資料挖掘技術及應用(我見過的最全面的理論+最佳案.ppt
資料挖掘技術在電網企業中的應用需求分析.pdf
基于資料挖掘的電力設備狀態檢修技術研究綜述.doc
面向智能電網大資料的資料挖掘演算法概述.pdf
資料挖掘技術及其在電力系統中的應用.pdf
電力行業資料挖掘.pptx
不過學技術,關鍵不在于掌握資料的多與少,而在于你是否去運用它,希望大家在個平時生活中多想一下,哪些例子是使用了資料挖掘,自己能用資料挖掘來解決什么問題,
附錄1:練習題答案
1
| 案例 | 使用技術 |
|---|---|
| 沃爾瑪通過資料挖掘發現啤酒與尿布銷售關系 | 關聯分析 |
| 某打車平臺通過大資料發現司機與乘客私下交易 | 關聯分析 |
| 某購物平臺使用資料挖掘提高優惠券營銷能力 | 聚類 |
| 某微博網友質疑天貓雙十一銷售額資料造假 | 相關性分析 |
| 某人使用yolo3輔助自己整理照片 | 分類 |
2
網上還有很多練習題,涉及到了很多知識點(不包括本文介紹的):
資料挖掘150道試題 測測你的專業能力過關嗎?
https://blog.csdn.net/u010022051/article/details/44153421?utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-1.control&dist_request_id=&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-1.control
附錄2:weka使用
WEKA資料挖掘工具操作實驗.ppt
https://max.book118.com/html/2017/0127/87028147.shtm
WEKA使用教程
https://blog.csdn.net/yangliuy/article/details/7589306
CC中英字幕 - Weka在資料挖掘中的運用(Data Mining with Weka)
https://www.bilibili.com/video/BV1Hb411q7Bf?from=search&seid=17226336668903912022
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/287301.html
標籤:其他