內容指引
- Part I、結構體對齊規則
- 對齊規則1
- 對齊規則2
- 對齊規則3
- 對齊規則4
- Part II、進階例題分析
- Part III、記憶體對齊有啥用?
- Part IV、系列文章索引

Part I、結構體對齊規則
對齊規則1
要想知道如何計算結構體的大小,必須先了解結構體的對齊規則
結構體對齊規則為:
1、第一個成員在與結構體變數偏移量為0的地址處
假設我們創建了一個結構體:
struct A
{
char a;
int b;
char c;
}A;
并由此創建了一個型別為結構體A的變數:
struct A s;
我們知道,一旦我們創建了一個變數,那么系統就會給它開辟一片空間,這片空間有一個起始地址0X…;
而偏移量的意思,簡單來說就是:某兩個地址之間的距離,這個距離可以用兩個十六進制的地址相減得到,
如0x000004與0x00001的地址偏移量就是3(0x000004-0x00001得到),
那么這里的第一個對齊規則就很好理解了:由于我們創建的結構體變數具有一個起始地址,那么我們的第一個成員就要從這個地址開始存放,也就是我們所說的:第一個成員在與結構體變數偏移量為0的地址處,
對齊規則2
2、其他成員變數要對齊到某個數(這里指對齊數)的整數倍地址處
注:對齊數=min{編譯器默認對齊數,該成員型別的大小}
我們常用的VS編譯器的默認對齊數為8,Linux系統下無默認對齊數
了解了默認對齊數的概念后,我們不妨畫一個圖:
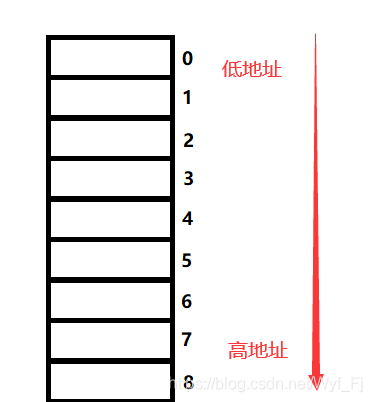
方格表示我們的記憶體單元,右邊的數字表示偏移量(0偏移量處就是我們假定的結構體變數起始地址)
我們這里所說的對齊數,本質上就是與起始地址的偏移量,而對齊數的確定與編譯器和成員的型別有關,具體公式:對齊數=min{編譯器默認對齊數,該成員型別的大小}
也就是說,我們取成員型別大小和默認對齊數二者的較小值作為對齊數,
這里用一個例題幫助講解:(為方便講解,我們選擇VS編譯器下的默認對齊數)
struct A
{
char a;
int b;
short c;
}A;
通過上述的兩個規則我們知道:第一個成員a從偏移量為0處開始存放,即:

而我們的第二個成員b,由于它是int型別,占4個位元組,那么取min{sizeof(int),默認對齊數8},于是我們得到:成員b的對齊數為4,那么它就要從偏移量為4的倍數處開始存放:
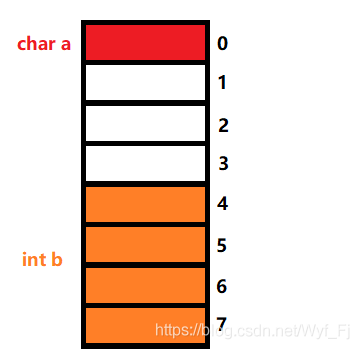
注:這里白色的部分,即偏移量為1~3的地址并不存放結構體成員資料,可以說是浪費掉了,但這是值得的,原因我們后面具體解釋,
我們繼續分析第三個成員c;
由于它是short型別,那么我們依然取min{sizeof(short),默認對齊數8},由此得到c的對齊數為2,那么它將從偏移量為2的整數倍處往后存放,即:
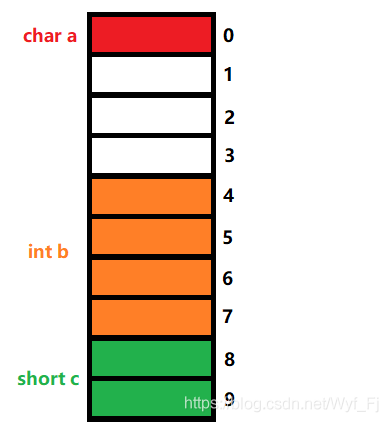
綜上我們可以得知:這個結構體的成員總共占了偏移量為0~9的這十個記憶體單元,那么這是否意味著它的大小為10呢?我們繼續看第三個對齊規則——
對齊規則3
3、結構體的總大小為最大對齊數(結構體的每個成員都有一個對齊數)的整數倍
這里又出現了一個新名詞:最大對齊數,什么意思呢?由上述的第二條規則和例題我們知道,結構體的每一個成員的型別大小與編譯器的默認對齊數比較后,都能得到一個對齊數,而我們需要取這些成員的對齊數中最大的那一個作為我們整個結構體的對齊數,最后我們的結構體大小要是這個結構體對齊數的最小整數倍,
我們接著上一道例題分析——
我們知道,a的對齊數為1,b的對齊數為4,c的對齊數為2,那么我們結構體的對齊數取這三者的最大值,也就是4,由于a,b,c三個成員占了0~9這十個記憶體單元,所以結構體最終的大小應該是大于等于10且是4的倍數,于是我們得到答案:12,
VS編譯器下運行:
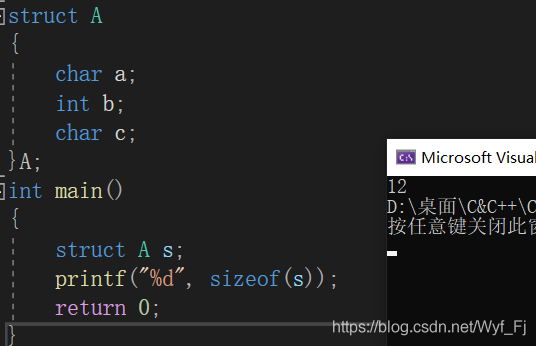
答案正確!
上面我們分析了一類簡單的結構體,但是較為復雜的結構體嵌套的情況該怎么解決對齊數的問題呢?對齊規則4為我們解釋了——
對齊規則4
4、如果嵌套了結構體的情況,嵌套的結構體對齊到自己的最大對齊數的整數倍處,結構體的整體大小就是所有最大對齊數(含嵌套結構體的對齊數)的整數倍,
意思就是說,結構體如果有嵌套,那么我們把他單獨地看作一個變數,對于它的最大對齊數的分析方法依據上述的三個對齊法則,那么這個結構體型別成員的大小就是它本身的大小,對齊數就是它本身的最大對齊數,
還是用例題說話:
struct A
{
char a;
int b;
char c;
}A;
struct B
{
int a;
struct A b;
char c;
};
我們算這個結構體B的大小(注意,它的成員中嵌套了一個結構體A)
我們看結構體B的第一個成員a,它直接對齊到0偏移量處:
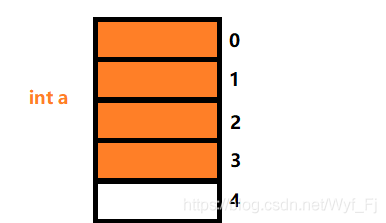
第二個成員b,它的型別為struct A,對齊數為4(4是它自己的最大對齊數),大小為12(這個是我們上面分析過的那個結構體,所以直接列出對齊數與大小),所以它的存放位置就是:
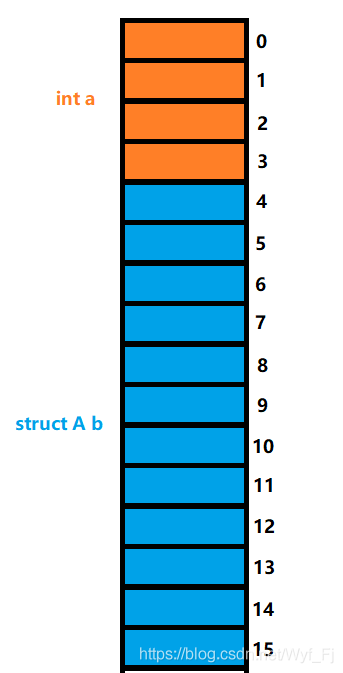
最后成員c,由于是char型別,所以對齊數=min{sizeof(char),默認對齊數8}=1,所以——
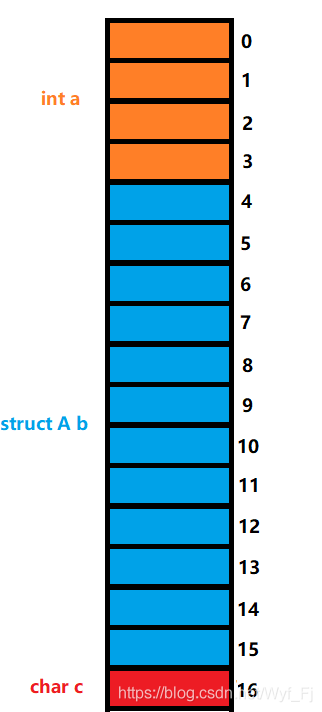
最終我們得到,這個結構體占據了偏移量為0~16的這17個記憶體單元,由于成員a,b,c的對齊數分別為4,4,1,所以取最大對齊數為三者的最大值:4,最終我們的結構體B的大小為大于等于17且為4的倍數的最小整數,即:20;
VS編譯器下運行:
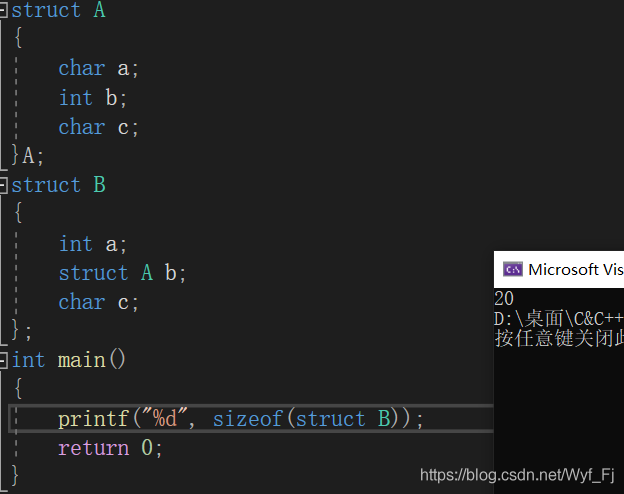
答案正確!
Part II、進階例題分析
struct A
{
char a;
short b;
}A;
struct B
{
long c;
char a[3];
struct A b;
};
這題融合了上述講解的四個對齊規則并且新添了一個陣列成員,
對于陣列而言,我們可以把它理解為n個連在一起的type型別的成員(其中n為陣列大小,type為陣列的成員型別),如這里的char a[3],就可以理解為3個連在一起的char型別成員,
篇幅起見,我們不再具體分析這道題了,讀者可以自行分析然后對照著下面這張圖來理解——

Part III、記憶體對齊有啥用?
這個問題,我想在剛剛做例題的時候你就已經發現了,記憶體對齊,算起來麻煩不說,還相當的浪費空間,按順序存放不行么,為什么偏要按照對齊數存盤呢?
大部分的參考資料都是如是說的:
- 平臺原因(移植原因): 不是所有的硬體平臺都能訪問任意地址上的任意資料的;某些硬體平臺只能在某些地址 處取某些特定型別的資料,否則拋出硬體例外,
意思就是說:有的硬體平臺能力達不到,只能在特定位置上訪問資料:如這里的對齊數的整數倍;
- 性能原因: 資料結構(尤其是堆疊)應該盡可能地在自然邊界上對齊, 原因在于,為了訪問未對齊的記憶體,處理器需要作兩次記憶體訪問;而對齊的記憶體訪問僅需要一次訪問
什么意思呢?
我們知道,CPU實際上是有尋址步長的,32位的CPU一次能處理4個位元組的資料,那么也就是尋址步長為4,只對編號為4的倍數的地址進行訪問;64位CPU一次能處理8個位元組的資料,尋址步長為8,只對編號為8的倍數的地址進行訪問,
如圖為64位下的示意圖——

那么假設我們的資料是按照對齊數排列的,即:
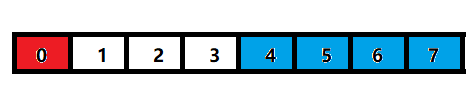
注:白色部分為浪費掉的記憶體
那么在32位系統下,通過一次訪問就可以訪問并獲取藍色方塊的資料
倘若沒有記憶體對齊:
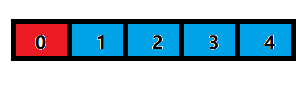
那么在32位系統下,我們需要先訪問一次編號0往后的4個位元組以獲取藍色方塊資料的前三個,然后再訪問編號4往后的4個位元組的記憶體獲取最后一份資料,這意味著,為了訪問一個資料,本來需要兩次解決的現在只要一次就可以搞定,
也許你還會疑問,說:為什么沒有記憶體對齊的情況下,我不能直接從編號1開始往后獲取資料呢?這樣也是一次就搞定了啊?
這又得回到我們的第一點原因上了:并非所有硬體平臺都能做到訪問任意編號的記憶體地址的!所以,為了在所有平臺上都能達到相對理想的訪問速度,計算機系統采取了這樣的一種以空間換取時間的做法!
Part IV、系列文章索引
【每天學一點系列~】字串左/右旋的本質,你真的認清了嘛?
【每天學一點系列~】這些記憶體函式你知道么?還記得么[\doge]
這篇文章帶你弄懂了結構體大小的計算了嘛?如果是的話,給個三連唄親!

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/287387.html
標籤:其他
上一篇:跟著阿倪一起學習C語言(2)使用vs2019開始自己的第一個代碼,零基礎入門新手可看。
下一篇:為什么有人勸別選計算機專業?