文章目錄
- 01 - 極大極小值演算法
- 02 - 電腦和人類所有走棋路徑
- 03 - 走一步看兩步
- 04 - 走一步看多步
- 04 - 總結
01 - 極大極小值演算法
??上一期博客介紹了最為簡單的人機博弈演算法,包括獲取所有合法路徑,簡單的估值以及電腦走棋,本期博客在介紹估值演算法上增加極大極小值演算法(Minmax演算法),讓電腦走棋更加智能化,
??極大極小值演算法是一種找出失敗的最大可能性中的最小值的演算法,即最小化對手的最大收益,舉個栗子,電腦為A,人類為B,A在走棋之前需要考慮A走了某一步之后,看看B有哪些走法,B又不傻,所以B肯定是要選擇讓A得分最小的走法走棋,而A就是在A的所有走法中選擇B給出讓A得分最小的走法中得分最多的走法,聽起來比較抽象,試著多讀幾遍就理解了,
??電腦匯入極大極小值演算法分以下3步:
??(1)在當前局面下獲取電腦所有走棋路徑,并試著走一下;
??(2)在電腦試著走完一步基礎上獲取人類所有走棋路徑,并以人類的視角試著走一下,然后評估局面分(局面分是以電腦角度計算的,即電腦總分 - 人類總分),遍歷完人類所有走棋路徑后回傳這些局面中的最小值(對電腦最不利而對人類最優利的情況);
??(3)在上一步回傳的局面分的最小值中,找到最大值,并且鎖定與該最大值對應的走棋路徑作為“步”回傳值回傳,
02 - 電腦和人類所有走棋路徑
??實作演算法第一步是要獲取電腦和人類的所有走棋路徑,所以對getAllPossibleMove函式稍微做出以下修改:
/**
*
* @brief : 獲取所有棋子可行走的步驟
*
* @param : steps : 保存移動棋子資訊的屬性(原坐標、目標坐標、ID、目標ID)
*
* @return: 無
*
**/
void ChessArea::getAllPossibleMove(QVector<Step *> &steps)
{
int min = 16, max = 32;
if(this->bRedTurn)
{
min = 0;
max = 16;
}
//遍歷所有黑方棋子
for(int i = min; i < max; i++)
{
//如果棋子已死則直接跳過
if(myChess[i].isDead)
continue;
// 遍歷所有行坐標
for(int x=0; x<9; x++)
{
// 遍歷所有列坐標
for(int y=0; y<10; y++)
{
//獲取想要殺死的棋子的id
int killid = this->getChessID(x, y);
//若想要殺死的棋子與行走的棋子顏色相同則跳過
if(sameColor(i, killid))
continue;
//判斷某一棋子能不能行走
if(canMove(i, killid, x, y))
{
//將可以行走的“步”存放到steps中
saveStep(i, killid, x, y, steps);
}
}
}
}
}
03 - 走一步看兩步
??跟上一期博客相比,我們不再呼叫calcScore估值函式直接計算出對電腦最有利的分值而實施走棋,而是先代用getMinScore函式計算出對電腦最不利而對人類最優利的分值,并在局面分的最小值中,找到最大值,實作“走一步看兩步”,
/**
*
* @brief :獲取電腦最優移動路徑
*
* @param : 無
*
* @return: 最優棋子資訊的屬性(原坐標、目標坐標、ID、目標ID)
*
**/
Step *ChessArea::getBestMove()
{
QVector<Step *> steps;
// 獲取電腦的所有走棋路徑
getAllPossibleMove(steps);
// 初始化比重
int maxScore = -100000;
Step* ret;
for(QVector<Step*>::iterator it=steps.begin(); it!=steps.end(); ++it)
{
Step* step= *it;
//試著走一下
fakeMove(step);
//獲取電腦當前走法下對自己最不利的分值
int score = getMinScore(level-1);
//再走回來
unfakeMove(step);
//取最高的分數
if(score > maxScore)
{
maxScore = score;
ret = step;
}
}
return ret;
}
/**
*
* @brief : 獲取人類下一步走法對電腦最不利的分數
*
* @param : 無
*
* @return: 對電腦最不利的分數值
*
**/
int ChessArea::getMinScore()
{
QVector<Step*> steps;
bRedTurn = true;
// 獲取人類的所有走棋路徑
getAllPossibleMove(steps);
bRedTurn = false;
int minScore = 100000;
for(QVector<Step*>::iterator it=steps.begin(); it!=steps.end(); ++it)
{
Step* step=*it;
// 以人類的視角試著走一下
fakeMove(step);
//評估局面分
int score = calcScore();
qDebug() << QString("紅旗評分: %1").arg(score);
// 再走回來
unfakeMove(step);
// 找到對電腦最不利的分數作為回傳值回傳
if(score < minScore)
{
minScore=score;
}
}
return minScore;
}
??到目前為止,電腦下棋已經變得更加智能了,大概效果如下:
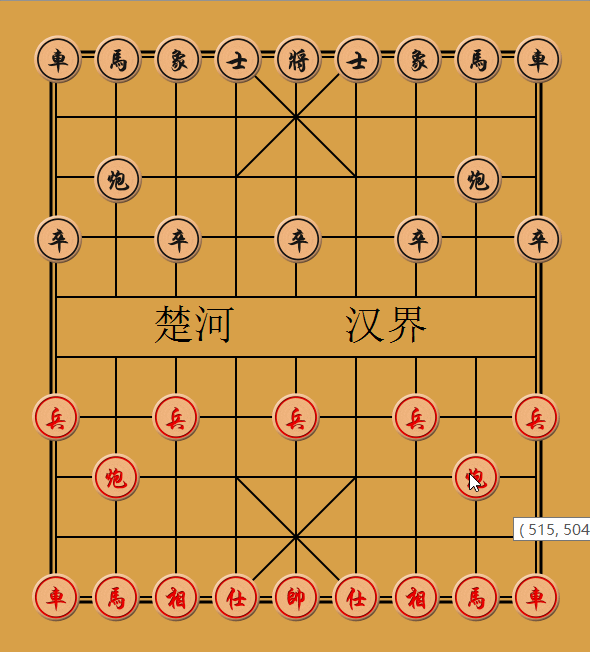
??從運行效果可以看出,我吃掉電腦的炮后,它出了車,我把炮放在它眼前,它反而不吃,因為它知道我在拿炮釣它的車,這個便是實作了“走一步看兩步”的博弈演算法智能,
04 - 走一步看多步
??既然能實作“走一步看兩步”,那么是不是能實作“走一步看三步”乃至更多步的人工智能呢?答案是肯定的,我們可以用遞回的思想改寫前面介紹的getBestMove函式和getMinScore函式,然后在家一個遞回的getMaxScore函式,用Level表示遞回深度,Level越大,電腦越聰明,這樣就能實作“走一步看多步”,
level = 3; // widget初始化時,設定優化等級3
/**
*
* @brief : 呼叫回呼函式getMinScore獲得局面最大分數
*
* @param : 無
*
* @return: 最大分數值
*
**/
int ChessArea::getMaxScore(int level)
{
if(level == 0)
return calcScore();
QVector<Step*> steps;
getAllPossibleMove(steps);
int maxScore = -100000;
for(QVector<Step*>::iterator it=steps.begin();it!=steps.end(); ++it)
{
Step* step=*it;
fakeMove(step);
int score = getMinScore(level-1);
unfakeMove(step);
if(score>maxScore)
{
maxScore=score;
}
}
return maxScore;
}
/**
*
* @brief : 獲取人類下一步走法對電腦最不利的分數(可回呼)
*
* @param : 無
*
* @return: 對電腦最不利的分數值
*
**/
int ChessArea::getMinScore(int level)
{
if(level == 0)
return calcScore();
QVector<Step*> steps;
bRedTurn = true;
// 獲取人類的所有走棋路徑
getAllPossibleMove(steps);
bRedTurn = false;
int minScore = 100000;
for(QVector<Step*>::iterator it=steps.begin();it!=steps.end();++it)
{
Step* step=*it;
fakeMove(step);
int score = getMaxScore(level-1);
unfakeMove(step);
if(score<minScore)
{
minScore=score;
}
}
return minScore;
}
/**
*
* @brief :獲取電腦最優移動路徑
*
* @param : 無
*
* @return: 最優棋子資訊的屬性(原坐標、目標坐標、ID、目標ID)
*
**/
Step *ChessArea::getBestMove()
{
QVector<Step *> steps;
// 獲取電腦的所有走棋路徑
getAllPossibleMove(steps);
int maxScore = -100000;
Step* ret;
for(QVector<Step*>::iterator it=steps.begin(); it!=steps.end(); ++it)
{
Step* step= *it;
fakeMove(step);
int score = getMinScore(level-1);
unfakeMove(step);
if(score > maxScore)
{
maxScore = score;
ret = step;
}
}
return ret;
}
??下面看看電腦實作“走一步看三步”的下棋效果:
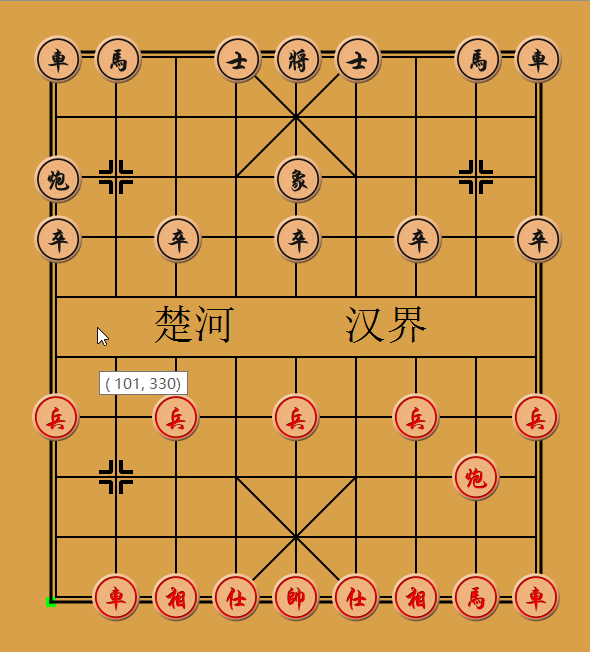
04 - 總結
??注意Level值不要設定太大,回呼深度越大消耗記憶體越嚴重,我電腦是4G記憶體,Level值設定為4,走棋就非常卡頓,后期基本卡死了,原因是后期棋子變少,活著的棋子行走的選擇會越多,因此占用記憶體會越大,直到程式崩潰,
??到目前為止,整個象棋的人工博弈演算法算是講完了,實際的效果不錯,可以自己搭建電腦端玩一玩,
- 01_開發象棋游戲簡介
- 02_繪畫象棋棋盤
- 03_象棋棋子擺放
- 04_象棋走棋規則——車、炮、士
- 05_象棋走棋規則——象、馬、將、兵
- 06_象棋游戲法則
- 07_人機博弈演算法開端
- 08_人機博弈高階演算法
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/287470.html
標籤:其他
下一篇:貪心演算法總結