重點的庫函式:
-
求字串長度
- strlen
-
長度不受限制的字串函式
- strcpy
- strcat
- strcmp
-
長度受限制的字串函式介紹
- strncpy
- strncat
- strncmp
-
字串查找
- strstr
- strtok
-
字符操作
-
記憶體操作函式
- memcpy
- memmove
- memcmp
strlen
size_t strlen(const char * str);
函式原理:
傳過去一個指標,回傳字串在字符’\0’之前的字符的個數,
注意事項:
注意事項:
- 字串必須要以’\0’結尾,否則會回傳一個隨機值(指標會一直讀取后面的記憶體直到出現’\0’為止)
- 注意函式回傳引數為size_t無符號型別,例如下面這種情況:
#include<stdio.h>
#include<string>
int main()
{
const char* str1 = "abcdef";
const char* str2 = "bbb";
if (strlen(str2) - strlen(str1)>0)
{
printf("str2>str1\n");
}
else
{
printf("str2<str1\n");
}
return 0;
}
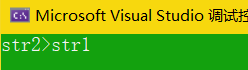
這里很明顯str1的長度大于str2的長度,但是列印的結果說明strlen(str2) - strlen(str1)的結果大于0,實際上這里回傳的型別是無符號型別,當運算式出現無符號數時會將所有有值轉換成無符號數進行運算,
模擬實作strlen函式
,一下用三種方法實作:
回圈實作
int my_strlen1(char* p) //正常的方法
{
int count = 0;
while (*p++)
{
count++;
}
return count;
}
回圈指標自增直到出現’\0’為止,
遞回實作
int my_strlen2(char* p) //遞回的方法
{
if (*p)
{
return my_strlen2(p + 1) + 1;
}
return 0;
}
遞回的方法不用使用創建臨時變數
指標減指標
int my_strlen3(char* p) //指標減指標的方法
{
char* cp = p;
while (*cp++)
{
;
}
return cp - p - 1;
}
這里利用的是指標的運算的性質,
strcpy
char * strcpy(char * destination, const char * source);
函式原理:
strcpy:將源頭指標(source)所指向的陣列包括’\0’(并且拷貝停止于此),拷貝到目標陣列(destination)中
注意事項:
- 源頭字串必須以’\0’結束
- 目標空間必須足夠大,以確保能放得下源字串
- 目標空間不能是常量!
模擬實作
char* my_strcpy(char* p1, const char* p2)
{
char* p = p1;
while (*p1++ = *p2++)
{
;
}
return p;
}
strcat
char * strcpy(char * destination,const char * source)
函式原理:
將source指標指向的字串(包括source結尾的’\0’字符)添加到destination指標所指向的字串后面,destination字串結尾的’\0’被source第一個字符替換,
注意事項:
- 源字串必須以’\0’結束
- 目標字串必須足夠的大,能容納下源字串的內容
- 目標空間不能是常量字串(可修改)
- 不可以字串給自己追加! (因為dest末尾的’\0’會被source的第一個字符替換掉,導致source的’\0’也被修改,最終strcat無法找到source末尾’\0’的結束標志,使其死回圈下去)
模擬實作
char* my_strcat(char *p1,char *p2)
{
char* p = p1; //記住起始地址
while (*p1)
{
*p1++;
}
while (*p1++ = *p2++)
{
;
}
return p;
}
分為兩步:
- 找到dest字串的’\0’
- 從dest的’\0‘開始向后面逐一拷貝
strcmp
int strcmp ( const char * str1,const char * str2 );
函式原理:
對str1和str2每個字符進行逐個比較,若相同,則繼續往下比,直到出現不同或遇到’\0’,
如果
- 第一個字串大于第二個字串,回傳大于0的數字
- 第一個字串小于第二個字串,回傳小于0的數字
- 第一個字串等于第二個字串,回傳0
模擬實作:
int strcmp(const char* str1, const char* str2)
{
while ((*str1++ == *str2++)&&*str1&&*str2)
{
;
}
if (*str1 > * str2)
{
return 1;
}
else if (*str1 < * str2)
{
return -1;
}
else
{
return 0;
}
}
strncpy
char * strncpy(char * destination,const char * source,size_t num);
函式原理:
拷貝num個字符從源字串到目標空間中,如果源字串長度小于num則拷貝完源字串之后,在目標的后邊追加0,直到num個,
函式實作:
char* my_strncpy(char* p1, const char* p2, int n)
{
char* p = p1;
for (int i = 0; i < n; i++)
{
if (*p2)
{
*p++ = *p2++;
}
else
{
*p++ = '\0';
}
}
return p1;
}
strncat
char * strncat(char * destination , const char *source , size_t num)
函式原理:
將num個source指向的字符拷貝到dest指向的字串,拷貝開始于dest的出現的第一個’\0’,結束于兩種情況:

#include<assert.h>
char* my_strncat(char* p1, const char* p2, int num)
{
assert(p2 && p1);
char* pc = p1;
while (*p1)
{
p1++;
}
for (int i = 0; i < num; i++)
{
if (*p1 = *p2)
{
p1++;
p2++;
}
else
return pc; //num>source 的情況
}
*p1 = '\0';
return pc;// num<source 的情況
}
strncmp:
int my_strncmp(char* p1, const char* p2, int num)
函式原理:
對str1和str2前num個字符進行逐個比較,若相同,則繼續往下比,直到出現不同或遇到’\0’,
如果
- 第一個字串大于第二個字串,回傳大于0的數字
- 第一個字串小于第二個字串,回傳小于0的數字
- 第一個字串等于第二個字串,回傳0
函式實作:
#incldue<assert.h>
int my_strncmp(char* p1, const char* p2, int num)
{
assert(p1 && p2);
for (int i = 0; i < num; i++)
{
if (*p1 && *p2 && (*p1++ == *p2++));
else
{
if (*p1 > * p2)
return 1;
else if (*p1 < *p2)
return -1;
return 0;
}
}return 0;
}
strstr
const char* my_strstr(const char* p1, const char* p2)
函式原理:
p1里是否包含p2,如果是則回傳p2在p1中第一個出現字符的地址,如果不包含則回傳空指標,
模擬實作:
#incldue<assert.h>
const char* my_strstr(const char* p1, const char* p2)
{
assert(p1 && p2);
while (*p1 && *p2)
{
if (*p1 == *p2)
{
const char* a = p1;
const char* b = p2;
while (*a++ && *b++)
{
if (*a != *b)
break;
if (*a == *b && *(b+1) == 0)
return p1;
}
}
p1++;
}
return NULL;
}
strtok
char* strtok(char* str, const char* sep)
函式原理:
- sep引數是個字串,定義了用作分隔的字符的集合
- 第一個引數指定一個字串,它包含了0個或者多個由sep字串中一個或者多個分隔符分割的標記,
- strtok函式找到str中的下一個標記,并將其用\0結尾,回傳一個指向這個標記的指標,(注:strtok函式會改變被操作的字串,所以在使用strtok函式切分的字串一般都是臨時拷貝的內容并且可修改,
- strtok函式的第一個引數不為NULL,函式將找到str中第一個標記,strtok函式將保存它在字串中的位置,
- strtok函式的第一個引數為NULL,函式將在同一個字串中被保存的位置開始,查找下一個標記,
- 如果字串中不存在更多的標記,則回傳NULL指標,
char* strtok(char* str, const char* sep)
{
static char* a = NULL; //這里要用到靜態變數,這樣函式結束變數就不會銷毀,a會記住上一次的地址
if (str != NULL) // 判斷是否為NULL
a = str;
else
a++;
char* first = a;//這個靜態變數也十分重要!當指標指向最后一個 字串str 出現的 sep字符分隔符,因為最后一段字串并不會再出現sep中任何一個分隔符,所以字串就不會列印,那我們如何區分這種情況和str中就從來沒有出現過sep字符的情況,我們設定一個靜態變數,如果靜態變數被修改過,就輸出字串,如果沒修改過就回傳空指標,
static int ret = 0;
while (*a)
{
const char* p = sep;
while (*p)
{
if (*p == *a)
{
*a = '\0';
ret = 1;
return first;
}
p++;
}
a++;
}
if(ret==0)
return NULL;
else
return first;
}
代碼示例:
char* strtok(char* str, const char* sep)
{
static char* a = NULL;
if (str != NULL)
a = str;
else
a++;
char* first = a;
static int ret = 0;
while (*a)
{
const char* p = sep;
while (*p)
{
if (*p == *a)
{
*a = '\0';
ret = 1;
return first;
}
p++;
}
a++;
}
if(ret==0)
return NULL;
else
return first;
}
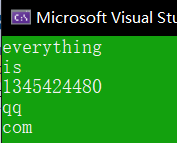
int main()
{
char a[] = "everything is simple";
char b[] = " ";
char c[] = "1345424480@qq.com";
char d[] = "@.";
printf("%s\n", strtok(a, b));
printf("%s\n", strtok(NULL, b));
printf("%s\n", strtok(c, d));
printf("%s\n", strtok(NULL, d));
printf("%s\n", strtok(NULL, d));
return 0;
}
結果:
strerror
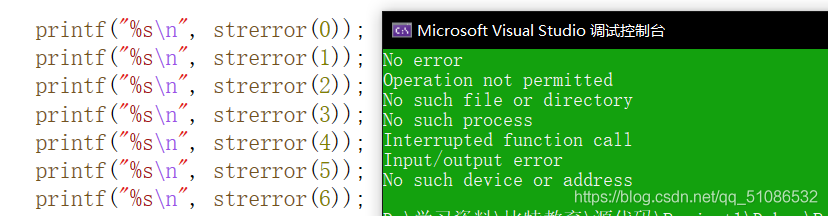
char * strerror ( int errnom );
函式原理:
- 回傳錯誤碼,所對應的錯誤資訊,
- 使用庫函式呼叫失敗的時候,都會設定錯誤碼,并存盤到errno中(errno是一個全域變數,在使用時必須參考頭檔案<errno.h>)
代碼運用:
#include<stdio.h>
#include<string.h>
#include<errno.h>
int main()
{
FILE* pFILE;
pFILE = fopen("unexist.ent", "r");
if (pFILE == NULL)
printf("Error opening file unexist.ent: %s\n", strerror(errno));
return 0;
}
字符操作函式:
字符分類函式
| 函式名 | 回傳值為真的回傳條件 |
|---|---|
| iscntrl | 任何控制字符, |
| isdigit | 十進制數字0~9 |
| isspace | 空白字符:空格’ ‘,換頁’\f’,換行’\n’,回車’\r’,制表符’\t’或者垂直制表符’\v’ |
| isxdigit | 十六進制數字,包括所有十進制數字,小寫字母a~f,大寫字母A ~ F, |
| islower | 小寫字母a~z |
| isupper | 大寫字母A~Z |
| isalpha | 字母a~z或A ~ Z |
| isalnum | 字母或數字,az,AZ,0~9, |
| ispunct | 標點符號,任何不屬于數字或者字母的圖形字符(可列印), |
| isgraph | 任何圖形字符 |
| isprint | 任何可列印字符,包括圖型字符和空白字符, |
注意:左邊為函式名,右邊是回傳值為真的回傳條件,字符函式一般都是有int型別的回傳值,且呼叫字符分類函式一定要引頭檔案ctype.h
字符轉換:
int tolower ( int c ); 把大寫轉換成小寫
int toupper ( int c ); 把小寫轉換成大寫
字符分類函式的應用:
這里列舉一個實體:大寫變小寫
#include<stdio.h>
#include<ctype.h>
int main()
{
char arr[] = "abBBsjJSBHdlDLKDjdef";
char c;
int i = 0;
while (arr[i])
{
c = arr[i];
if (isupper(arr[i]))
c = tolower(arr[i]);
putchar(c);
i++;
}
return 0;
}
memcpy
void* my_memcpy(void* destination, const void* source, size_t num)
函式原理:
- 函式memcpy從source的位置開始向后復制復制num個位元組的資料到destination的記憶體位置,
- 這個函式在遇到’\0’的時候并不會停下來
- 如果source和destination有任何的重疊,復制的結果都是未定義的,
- memmcpy對于strcpy的優點是可以拷貝任意型別的資料,
模擬實作:
void* my_memcpy(void* destination, const void* source, size_t num)
{
void* p = destination;
for (unsigned int i = 0; i < num; i++)
{
*(char*)destination = *(char*)source; //強制型別轉換成char *型別逐位元組拷貝
destination = (char*)destination + 1;
source = (char*)source + 1;
}
return p;
}
memmove
函式原理:
- 和memcpy的差別就是memmove函式處理的源記憶體塊和目標記憶體塊是可以重疊的,
- 如果源空間和目標空間出現重疊,就得使用memmove函式處理
函式實作:
因為memmove可以拷貝記憶體重疊的字串,所以我們主要考慮記憶體重疊的狀況:
情況一:source < dest
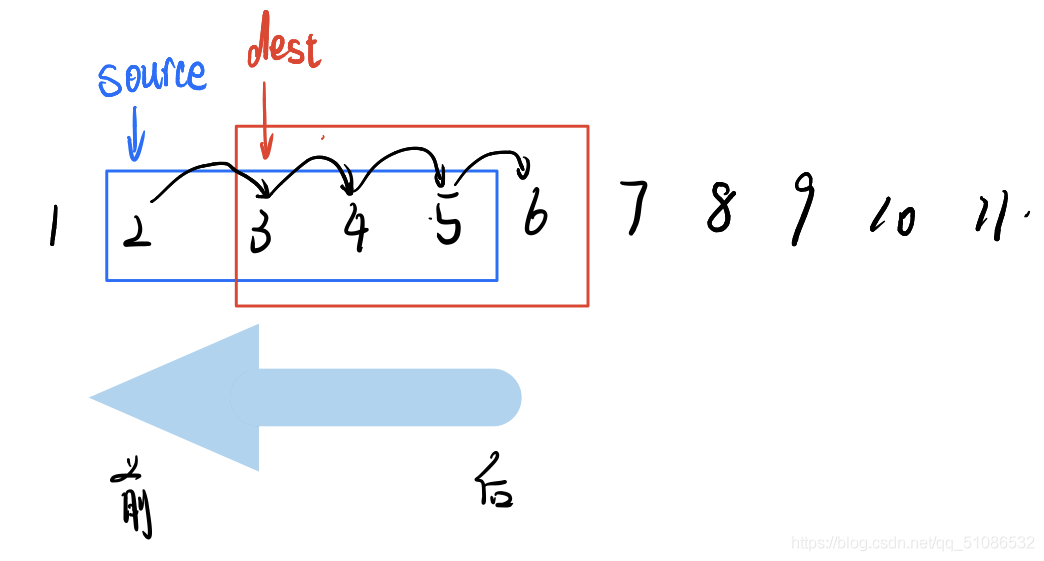
有圖可知拷貝方向應從source字串的后向前,
情況二 source > dest
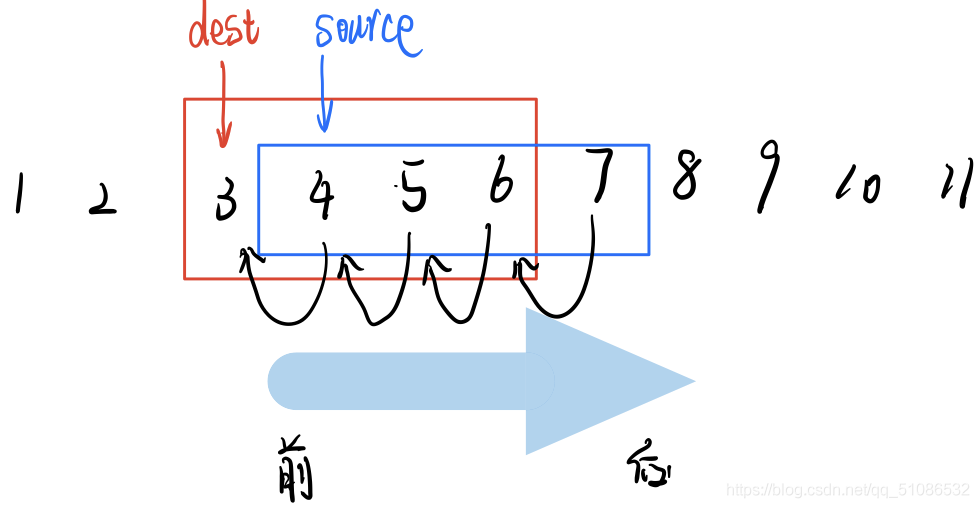
由圖可知拷貝方向是從source字串的前向后:
當source與dest沒有重疊部分的時候,source從左向右和從右向左并沒有什么區別,
void* my_memmove(void* destination, const void* source, size_t num)
{
void* p = destination;
if (destination > source) //從后向前拷貝
{
while (num--)
{
*((char*)destination + num) = *((char*)source + num);
}
}
else
{
for (int i = 0; i < num; i++) //從前向后拷貝
{
*(char*)destination = *(char*)source;
destination = (char*)destination + 1;
source = (char*)source + 1;
}
}
return p;
}
memmcmp
int my_memcmp(const void* ptr1, const void* ptr2, size_t num)
函式原理:
- 比較從ptr1和ptr2指標開始的num個位元組
- 回傳值與strcmp一樣
- 第一個字串大于第二個字串,回傳大于0的數字
- 第一個字串小于第二個字串,回傳小于0的數字
- 第一個字串等于第二個字串,回傳0
函式實作
int my_memcmp(const void* ptr1, const void* ptr2, size_t num)
{
int i = 0;
while (i++<num&&ptr1 && ptr2 && (*((char*)ptr1 + i) == *((char*)ptr2 + i)));
if (*((char*)ptr1 + i) > * ((char*)ptr2 + i))
return 1;
else if (*((char*)ptr1 + i) < *((char*)ptr2 + i))
return -1;
else
return 0;
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/287488.html
標籤:其他