目錄
TCP 三次握手的程序
三次握手的原因:
TCP 建立連接為什么要三次握手而不是四次?
有一種網路攻擊是利用了 TCP 建立連接機制的漏洞,你了解嗎?這個問題怎么解決?
四次揮手
為什么 TCP 關閉連接為什么要四次而不是三次?
客戶端為什么需要在 TIME-WAIT 狀態等待 2MSL 時間才能進入 CLOSED 狀態?
擁塞控制和流量控制
流量控制
擁塞控制和流量控制的差別
擁塞控制的四種演算法,
擁塞視窗 (congestion window,簡寫為 cwnd)的概念:
慢開始演算法思路:
擁塞避免演算法思路:
快重傳演算法
TCP 滑動視窗
滑動視窗是如何滑動的?
TCP 粘包和拆包的原因
TCP 粘包和拆包出現的原因:
TCP 粘包和拆包的解決方案
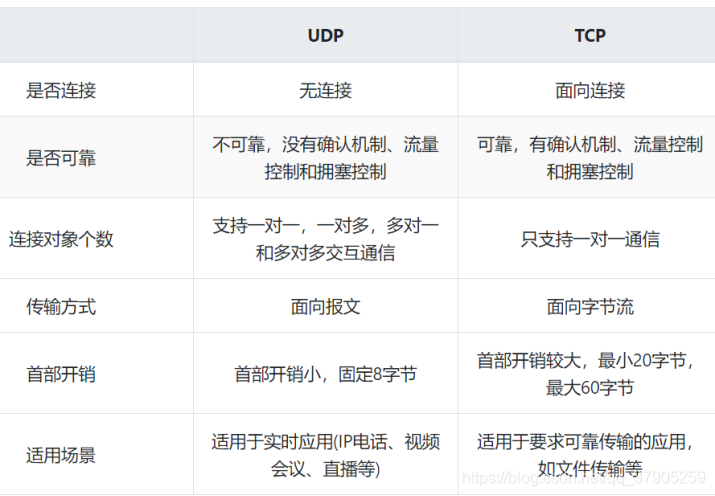
TCP
TCP 的三個重要特性——
OSI七層模型和TCP五層模型
TCP對應的應用層協議
UDP對應的應用層協議
HTTP和HTTPS
請求報文:
請求頭常見屬性:
回應報文
回應頭常見屬性
HTTPS程序:
HTTPS 和 HTTP 的區別:
http協議的缺點:
針對以上問題,https的改進措施:
HTTPS 的缺點:
SSL / TLS 握手詳細程序:
常見的http動詞?HTTP常見的請求方法有哪些?
URI和URL的區別?
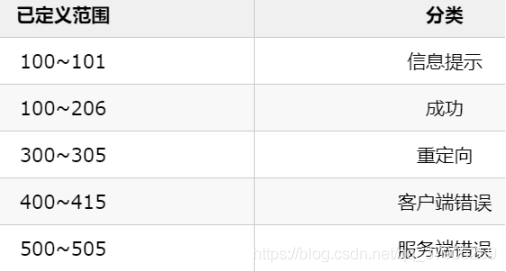
常見的http回傳碼有哪些?HTTP的狀態碼分為哪幾類?
get與post請求的區別
跨域
跨域問題的解決方法:
一次完整的HTTP請求所經歷的7個步驟
1. 建立TCP連接
2. Web瀏覽器向Web服務器發送請求命令
3. Web瀏覽器發送請求頭資訊
4. Web服務器應答
5. Web服務器發送回應頭資訊
6. Web服務器向瀏覽器發送資料
7. Web服務器關閉TCP連接
TCP 三次握手的程序
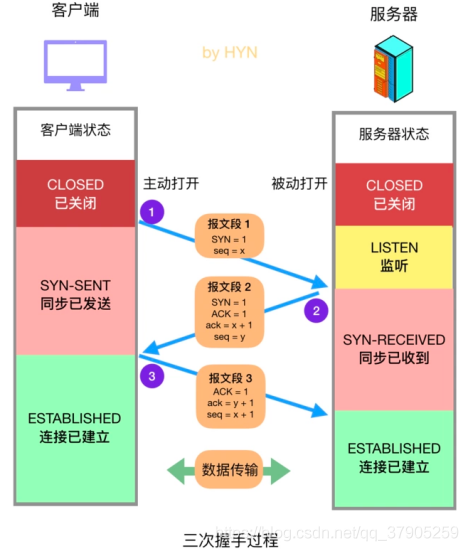
①初始 A 和 B 均處于 CLOSED 狀態,B 創建傳輸控制塊 TCB 并進入 LISTEN 狀態,等待客戶的連接請求,
②A 向 B 發送連接請求報文,首部的同部位SYN=1,ACK=0,隨機選擇一個初始序號seq=x,TCP規定,SYN報文段(SYN=1的報文段)不能攜帶資料,但要消耗一個序號,發送后TCP客戶行程進入 SYN-SENT 同步已發送狀態,====A向B說:讓我們建立連接吧,我發送的資訊序號會從x開始,
③B 收到 A 的連接請求報文后,如果同意建立連接,就會向A發送確認,確認報文段中SYN=1,ACK=1,確認號ack=x+1,同時為自己隨機選擇一個初始序號seq=y,這個報文段也不能攜帶資料,但同樣要消耗一個序號,TCP服務器行程進入 SYN-RCVD 同步收到狀態,====B向A說:收到,我已經準備好接受序號為x+1的資訊了,我發送的資訊序號會從y開始,
④A 收到 B 的確認后,還要對該確認再進行一次確認,確認報文段ACK=1,確認序號ack=y+1,自己的序號seq=x+1,ACK報文段可以攜帶資料,但不攜帶資料則不消耗序號,這時,TCP連接已經建立,A 進入 ESTABLISHED 已建立連接狀態,B 接收到該報文后也進入 ESTABLISHED 狀態,客戶端會稍早于服務器端建立連接,====A向B說:好的,我也收到了你的序號了,你可以想問我發送序號為y+1的資訊了,
以上連接建立的程序叫三報文握手,
確認號的作用是向對方表示,我期待收到的下一個報文段中的第一個資料位元組的序號, 如果你向對方回復了 ack = 31, 代表著你已經收到了序號截止到30的資料,期待的下一個資料起點是 31 ,
若確認號=N,則表明到序號N-1為止的所有資料都已經正確收到了,
三次握手的原因:
①為了防止已失效的連接請求報文段突然又傳送到了B,因而產生錯誤,
②三次握手是通信雙方相互告知并確認對方已經收到了自己的初始序號值的步驟,TCP 實作了可靠的資料傳輸,原因之一就是 TCP 報文段中維護了序號欄位和確認序號欄位,也就是seq 和 ack,通過這兩個欄位雙方都可以知道在自己發出的資料中,哪些是已經被對方確認接收的,如果是兩次握手,只有發起方的初始序號可以得到確認,而另一方的初始序號則得不到確認,
③三次握手才能讓雙方均確認自己和對方的發送和接收能力都正常,
第一次握手:客戶端只是發送出請求報文段,什么都無法確認,而服務器可以確認自己的接收能力和對方的發送能力正常;
第二次握手:客戶端可以確認自己發送能力和接收能力正常,對方發送能力和接收能力正常;
第三次握手:服務器可以確認自己發送能力和接收能力正常,對方發送能力和接收能力正常;
可見三次握手才能讓雙方都確認自己和對方的發送和接收能力全部正常,這樣就可以愉快地進行通信了,
TCP 建立連接為什么要三次握手而不是四次?
因為三次握手已經可以確認雙方的發送接收能力正常,雙方都知道彼此已經準備好,而且也可以完成對雙方初始序號值得確認,也就無需再第四次握手了,
有一種網路攻擊是利用了 TCP 建立連接機制的漏洞,你了解嗎?這個問題怎么解決?
答:在三次握手程序中,服務器在收到了客戶端的 SYN 報文段后,會分配并初始化連接變數和快取,并向客戶端發送 SYN + ACK 報文段,這相當于是打開了一個“半開連接 (half-open connection)”,會消耗服務器資源,如果客戶端正常回傳了 ACK 報文段,那么雙方可以正常建立連接,否則,服務器在等待一分鐘后會終止這個“半開連接”并回收資源,這樣的機制為 SYN洪泛攻擊 (SYN flood attack)提供了機會,這是一種經典的 DoS攻擊 (Denial of Service,拒絕服務攻擊),所謂的拒絕服務攻擊就是通過進行攻擊,使受害主機或網路不能提供良好的服務,從而間接達到攻擊的目的,在 SYN 洪泛攻擊中,攻擊者發送大量的 SYN 報文段到服務器請求建立連接,但是卻不進行第三次握手,這會導致服務器打開大量的半開連接,消耗大量的資源,最終無法進行正常的服務,
解決方法:SYN Cookies,現在大多數主流作業系統都有這種防御系統,SYN Cookies 是對 TCP 服務器端的三次握手做一些修改,專門用來防范 SYN 洪泛攻擊的一種手段,它的原理是,在服務器接收到 SYN 報文段并回傳 SYN + ACK 報文段時,不再打開一個半開連接,也不分配資源,而是根據這個 SYN 報文段的重要資訊 (包括源和目的 IP 地址,埠號可一個秘密數),利用特定散列函式計算出一個 cookie 值,這個 cookie 作為將要回傳的SYN + ACK 報文段的初始序列號(ISN),當客戶端回傳一個 ACK 報文段時,服務器根據首部欄位資訊計算 cookie,與回傳的確認序號(初始序列號 + 1)進行對比,如果相同,則是一個正常連接,然后分配資源并建立連接,否則拒絕建立連接,
四次揮手
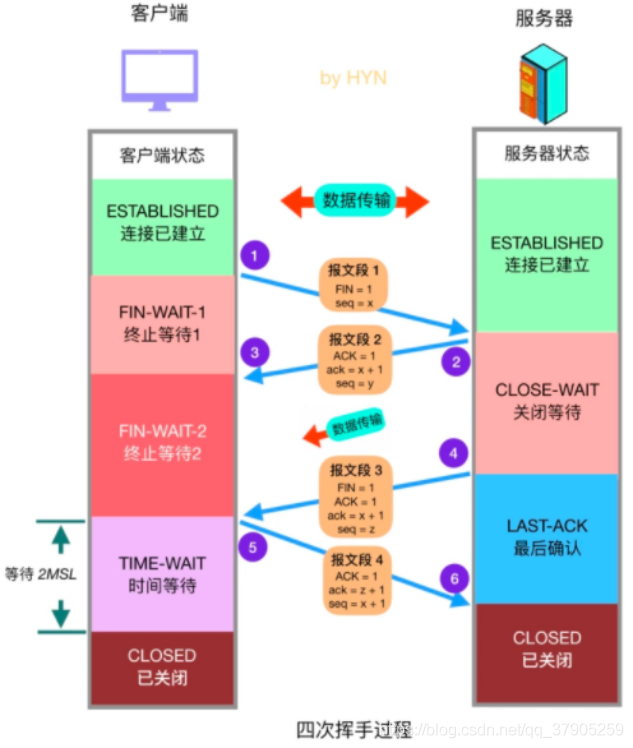
四次揮手詳細程序如下:
- 客戶端發送連接釋放報文段,終止控制位FIN置1,請求關閉連接,并停止發送資料,序號欄位 seq = x (它等于之前已發送過的所有資料的最后一個位元組的序號加1),然后客戶端會進入終止等待1(FIN-WAIT-1)狀態,等待服務器的確認報文,TCP規定,FIN報文段即使不攜帶資料,它也要消耗一個序號,
- 服務器收到 連接釋放報文段后,發出確認報文,ACK = 1, 確認號ack = x + 1,并帶上自己的序號 seq = y,然后服務器就進入關閉等待(CLOSE-WAIT)狀態,TCP服務器行程還會通知上層的應用程式:對方已經釋放連接,此時TCP連接處于半關閉狀態,也就是說客戶端已經沒有資料要發送了,但是服務器還可以發送資料,客戶端也還能夠接收,
- 客戶端收到服務器的 ACK 報文段后隨即進入終止等待2(FIN-WAIT-2)狀態,此時還能收到來自服務器的資料,直到收到服務器的連接釋放報文段,
- 服務器發送完所有資料后,會向客戶端發送連接釋放報文段,FIN=1,服務器必須重復上次已發送過的確認號ack=x+1,seq=z,隨后服務器進入 最后確認(LAST-ACK)狀態,等待客戶端的確認報文段,
- 客戶端收到來自服務器的連接釋放報文段后,向服務器發送確認報文段,ACK=1,確認號ack=z+1,序號seq=x+1,隨后進入時間等待(TIME-WAIT)狀態,此時,TCP連接還沒有釋放掉,必須經過2MSL(2 * Maximum Segment Lifetime,兩倍的最大報文段壽命)后,客戶端才進入CLOSED狀態,
- 服務器在接收到客戶端的確認報文段后,就進入 CLOSED 狀態,服務器撤銷傳輸控制塊TCB后,就結束了這次TCP連接,由于沒有等待時間,一般而言,服務器比客戶端更早進入 CLOSED 狀態,
為什么 TCP 關閉連接為什么要四次而不是三次?
答:服務器在收到客戶端的 FIN 報文段后,可能還有一些資料要傳輸,所以不能馬上關閉連接,但是會做出應答,回傳 ACK 報文段,接下來可能會繼續發送資料,在資料發送完后,服務器會向客戶端發送 FIN 報文,表示資料已經發送完畢,請求關閉連接,然后客戶端再做出應答,因此一共需要四次揮手,
客戶端為什么需要在 TIME-WAIT 狀態等待 2MSL 時間才能進入 CLOSED 狀態?
答:
①為了保證客戶端發送的最后一個ACK報文段能夠到達服務器,這個ACK報文段可能丟失,使處于最后確認狀態的服務器收不到對已發送的FIN+ACK報文段的確認,服務器就會超時重傳這個FIN+ACK報文段,客戶端如果在2MSL時間內收到這個重傳的FIN+ACK報文段,就會重傳一次確認,重新啟動2MSL計時器,MSL是任何報文段在網路上存在的最長時間,超過這個時間的報文將被丟棄,如果在2MSL這段時間內沒有收到來自服務器的 FIN+ACK報文段,那就說明服務器已經成功收到了 ACK 報文段,最后,客戶端和服務器都正常進入到CLOSED狀態,如果客戶端在發送完ACK報文段后立即釋放連接,那么就無法收到服務器重傳的FIN+ACK報文段,因而也不會再發送一次確認報文段,這樣服務器就無法正常進入CLOSED狀態,
②為了讓本連接持續時間內所產生的所有報文段都從網路中消失,使得下一個新的連接中不會出現舊的連接請求報文段,
擁塞控制和流量控制
流量控制
流量控制就是讓發送方的發送速率不要太快,讓接收方來得及接收,利用滑動視窗機制可以很方便的在TCP連接上實作對發送方的流量控制,TCP的視窗單位是位元組,不是報文段,發送方的發送視窗不能超過接收方給出的接收視窗的數值,
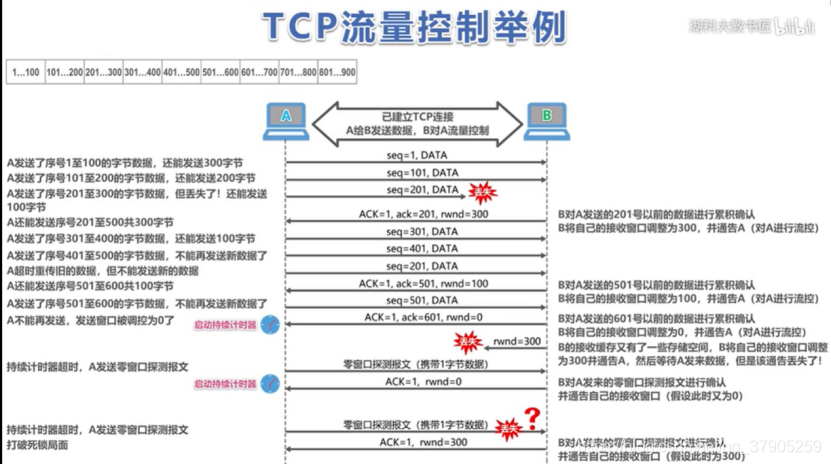
TCP報文段發送時機的三種控制機制:
①TCP維持一個變數,它等于最大報文段長度MSS,只要快取中存放的資料達到MSS位元組時,就組裝成一個TCP報文段發送出去,
②由發送方的應用行程指明要求發送報文段,即TCP支持的推送操作
③發送方的一個計時器期限到了,這時就把當前已有的快取資料裝入報文段發送出去,
擁塞控制的原理
在某段時間,若對網路中的某一資源的需求超過了該資源所能提供的可用部分,網路的性能就要變壞,這種情況叫做擁塞,擁塞問題的實質往往是整個系統的各個部分不匹配,只有所有的部分都平衡了,問題才會得到解決,
擁塞控制和流量控制的差別
所謂擁塞控制就是防止過多的資料注入到網路中,這樣可以使網路中的路由器或鏈路不致過載,擁塞控制所要做的都有一個前提,就是網路能承受現有的網路負荷,擁塞問題是一個全域性的問題,涉及到所有的主機、所有的路由器、以及與降低網路傳輸性能有關的所有因素,流量控制往往指的是點對點通信量的控制,是個端到端的問題,流量控制所要做的就是抑制發送端發送資料的速率,以便使接收端來得及接收,
擁塞控制的四種演算法,
即慢開始(Slow-start)、擁塞避免(Congestion Avoidance)、快重傳(Fast Restrangsmit)和快回復(Fast Recovery),我們假定:1)資料是單方向傳送,而另外一個方向只傳送確認,2)接收方總是有足夠大的快取空間,因而發送視窗的大小由網路的擁塞程度來決定,
發送方維持一個叫做擁塞視窗cwnd(congestion window)的狀態變數,擁塞視窗的大小取決于網路的擁塞程度,并且動態地在變化,發送方讓自己的發送視窗等于擁塞視窗,發送方控制擁塞視窗的原則是:只要網路沒有出現擁塞,擁塞視窗就再增大一些,以便把更多的分組發送出去,提高網路利用率,但是只要網路出現擁塞,擁塞視窗就必須減小一些,以減少注入到網路的分組數,
擁塞視窗 (congestion window,簡寫為 cwnd)的概念:
擁塞視窗是由發送方根據網路狀況維護的一個變數,用于控制自己的資料發送速率,前文提到了發送方的發送視窗受兩個變數約束,一是接收方通告的視窗大小值,二就是發送方自身的擁塞視窗,實際的發送視窗大小取二者最小值,
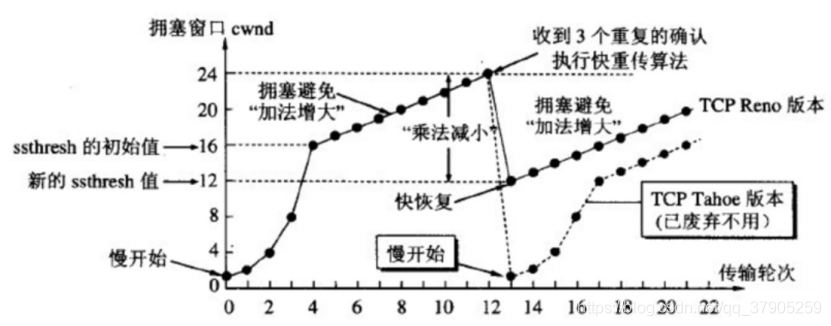
慢開始演算法思路:
由小到大逐漸增大發送視窗(擁塞視窗數值),具體是,當新建連接時,cwnd初始化為1個最大報文段(MSS),發送端開始按照擁塞視窗大小發送資料,每當有一個報文段被確認,cwnd就增加1個MSS,用這樣的方法來逐步增大擁塞視窗,“慢”指在TCP開始發送報文段時先設定cwnd=1,使發送方在開始時只發送一個報文段(試探網路擁塞情況),然后逐漸增大cwnd,
擁塞避免演算法思路:
讓擁塞視窗緩慢增大,即每經過一個往返時間RTT就把發送方的擁塞視窗cwnd加1,這樣擁塞視窗按線性規律緩慢增大,具有加法增大的特點,擁塞避免并非完全能夠避免擁塞,是指將擁塞視窗控制為按線性規律增長,使網路比較不容易出現擁塞,
為了防止 cwnd 增長過大引起網路擁塞,設定一個慢開始門限(slow start threshold,簡寫為 ssthresh),初始值為16 ,
當cnwd < ssthresh,使用慢開始演算法
當 cnwd = ssthresh,既可使用慢開始演算法,也可以使用擁塞避免演算法
當 cnwd > ssthresh,使用擁塞避免演算法
快重傳演算法
可以讓發送方盡早知道發生了個別報文段的丟失,該演算法要求接收方立即發送確認,即使收到了失序的報文段也要立即發出對已收到的報文段的重復確認,規定,發送方只要一連收到3個重復確認,就知道接收方確實沒有收到某個報文段,因而應當立即進行重傳,這樣就不會出現超時,發送方就不會誤認為出現了網路擁塞,
快重傳和快恢復配套使用,執行快恢復演算法后,調整門限值ssthresh=cwnd/2,設定擁塞視窗cwnd= ssthresh,并開始執行擁塞避免演算法,
AIMD演算法:AI指在擁塞避免階段,擁塞視窗按線性規律增大,MD是指一旦出現超時或3個重復確認,就把門限值設定為當前擁塞視窗值的一半,并大大減小擁塞視窗的數值,
TCP 滑動視窗
利用滑動視窗機制可以很方便的在TCP連接上實作對發送方的流量控制,
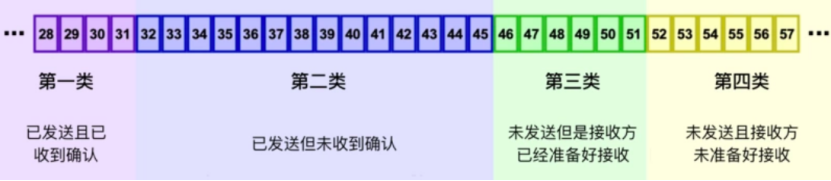
我們可以把發送方的發送快取中的位元組分為以下四類,每個編號對應一個位元組:
第一類:已發送且已確認,這些資料已經發送成功并已經被確認的資料,比如圖中的前31個bytes,這些資料其實的位置是在視窗之外了,下一步將被移出發送快取,視窗內順序最低的位元組被確認之后,視窗左邊界會向右移動,稱為視窗合攏,
第二類:已發送但未收到確認,這部分資料已經被發送出去,但是還沒有收到接收端的 ACK,認為并沒有完成發送,這部分資料屬于視窗內的資料,
第三類:未發送但是接收方已經準備好接收,這部分是盡快發送的資料,這部分資料已經被加載到快取中,也在發送視窗中,正在等待發送,其實這個視窗是完全有接收方告知的,接收方告知當前可以接受這些資料,所以發送方需要盡快的發送,
第四類:未發送且接收方未準備好接收,這些資料屬于未發送,同時接收端也不允許發送的,因為這些資料已經超出了發送端所接收的范圍,
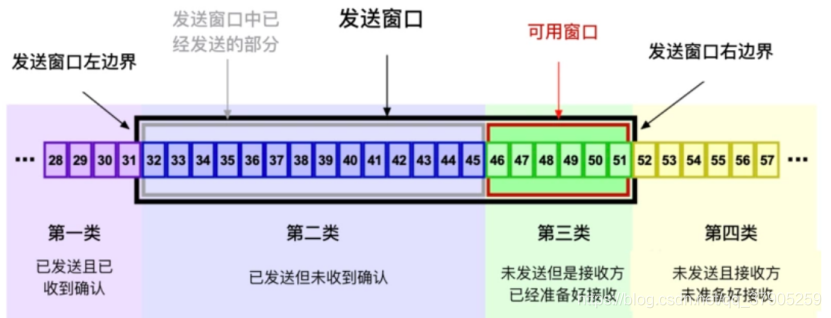
發送視窗:圖中的黑色框就是發送方的發送視窗,其大小由兩個因素決定:1、接收方的提供的視窗大小 (TCP 報文段首部中的 window 欄位),發送方在三次握手階段首次得到這個值,之后的通信程序中接收方會根據自己的可用快取對這個值進行動態調整;2、發送方會根據網路情況維護一個擁塞視窗變數 (后文介紹),發送視窗的大小取這兩個值的最小值,對于發送方來說,發送視窗分為兩部分,分別是已經發送的部分(已經發送了,但是沒有收到ACK)和可用視窗,接收端允許發送但是沒有發送的那部分稱為可用視窗,
接收視窗:對于接收端也是有一個接收視窗的,類似發送端,接收端的資料有3個分類,因為接收端并不需要等待ACK所以它沒有類似的接收并確認了的分類,情況如下
- Received and ACK Not Send to Process:這部分資料屬于接收了資料但是還沒有被上層的應用程式接收;
- Received Not ACK: 已經接收,但是還沒有回復 ACK;
- Not Received:有空位,還沒有被接收的資料,
滑動視窗是如何滑動的?
滑動視窗的滑動程序
累積確認概念:TCP 并不是每一個報文段都會回復一個 ACK ,可能會對兩個報文段發送一個ACK,也可能會對多個報文段發送 1 個 ACK,這稱為累積確認,比如說發送方有 1/2/3 3 個報文段,先發送了2,3 兩個報文段,但是接收方期望收到1報文段,這個時候 2/3 報文段就只能放在快取中等待報文1的空洞被填上,如果報文段1一直不來,報文2/3也將被丟棄,如果報文1來了,那么會發送一個 ACK 對第3個報文段進行確認,就代表對這三個報文段全部進行了確認,
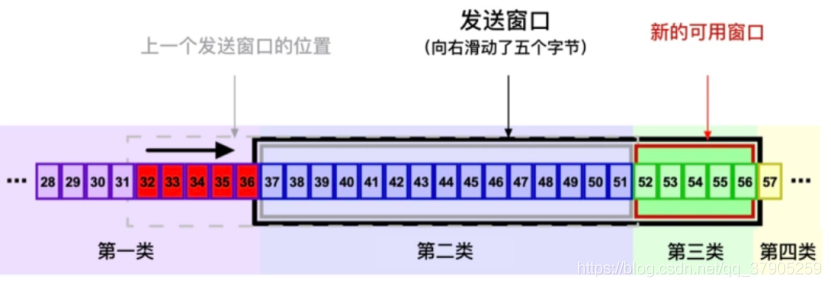
下面舉例說明一下視窗滑動的程序:
- 在握手程序中,接收方通告的視窗大小為20位元組,所以發送方將發送視窗大小設定為20位元組,
- 從圖中的"上一個發送視窗的位置"(灰色虛線框)說起, 32-51號位元組恰好處于發送視窗中,恰好20個位元組,假設 TCP 將其分為 4 個報文段進行發送,每個報文段 5 個位元組資料,分別記為 seg1 32-36, seg2 37-41, seg3 42-46, seg4 47-51,
- TCP 將有序發送 seg1、seg2、seg3和seg4四個報文段,如果這四個報文段都順利到達接收方 (圖中并不是這樣),接收方將發回一個累積確認的 ACK 報文段,其中 ack = 52,代表希望收到下一個報文段的起始位元組編號,報文段中也會繼續通告視窗大小,如果還是20位元組,那么發送方的視窗將整體向右移動20位元組,如果通告的視窗值變小,比如變成15,那么發送視窗左邊界移動20位元組,右邊界移動15位元組,
- 如果在發送程序中 seg2 報文段丟失,而其他三個報文段正常到達接收方,那么接收方會先接受這三個報文段,然后回傳 ACK 報文段,ack = 37,表示希望收到的下一個報文段的起始位元組號為37,也就是seg2報文段,如果通告視窗值未發生變化,發送方在收到 ACK 后會將視窗整體右移5個位元組,也就變成了圖中的位置,
- 由于 seg2 還未收到 ACK,當重傳計時器超時后,發送方會重新發送 seg2,此時52-56號位元組又落到了發送視窗中,TCP 將其封裝成 報文段進行發送,如果接收方全部順利收到,會回傳一個累積確認的 ACK,ack = 57,表示希望收到的下一個報文段的起始位元組號為57,
接下來就是重復上述程序,直到 TCP 位元組流的所有資料發送完畢,在這個程序中,接收方會根據自己接收快取的剩余空間動態調整視窗值,對發送方進行流量控制,
TCP 粘包和拆包的原因
TCP 是以位元組流的方式傳輸資料,傳輸的最小單位為一個報文段(segment),TCP 首部 中有個選項 (Options)的欄位,常見的選項為 MSS (Maximum Segment Size最大訊息長度),它是收發雙方協商通信時每一個報文段所能承載的最大有效資料的長度,資料鏈路層每次傳輸的資料有個最大限制MTU (Maximum Transmission Unit),一般是1500位元組,超過這個量要分成多個報文段,MSS 則是這個最大限制減去 TCP 的首部,光是要傳輸的資料的大小,一般為1460位元組,
MSS = MTU - Header
TCP 為提高性能,發送端會將需要發送的資料發送到發送快取,等待快取滿了之后,再將快取中的資料發送到接收方,同理,接收方也有接收快取這樣的機制,來接收資料,
TCP 粘包和拆包出現的原因:
TCP是基于位元組流的,雖然應用層和TCP傳輸層之間的資料互動是大小不等的資料塊,但是TCP把這些資料塊僅僅看成一連串無結構的位元組流,沒有邊界;另外從TCP的幀結構也可以看出,在TCP的首部沒有表示資料長度的欄位,基于上面兩點,在使用TCP傳輸資料時,才有粘包或者拆包現象發生的可能,
發生TCP粘包或拆包有很多原因,現列出常見的幾點:
- 要發送的資料大于TCP發送緩沖區剩余空間大小,將會發生拆包,
- 待發送資料大于MSS(最大報文長度),TCP在傳輸前將進行拆包,
- 應用程式寫入資料小于剩余快取大小,網卡將應用多次寫入的資料先快取起來,然后一起發送到網路上,這將會發生粘包,
- 接收資料端的應用層沒有及時讀取接收快取中的資料,將發生粘包,
TCP 粘包和拆包的解決方案
解決問題的關鍵在于如何給每個資料包添加邊界資訊,
1、發送端在每個資料包的包首部中添加資料包的長度資訊,這樣接收端在接收到資料包后,通過讀取包首部的長度欄位,便知道每一個資料包的實際長度了,
2、發送端將每個資料包封裝為固定長度(不夠的可以通過補0填充),這樣接收端每次從接識訓沖區中讀取固定長度的資料,就自然而然的把每個資料包拆分開來,
3、可以在資料包之間設定邊界,如添加特殊符號,這樣,接收端通過這個邊界就可以將不同的資料包拆分開,
TCP
TCP 的三個重要特性——
1. 面向連接;面向連接意味著兩個使用 TCP 的應用 (通常是一個客戶端和一個服務器) 在彼此交換資料之前必須先建立一個 TCP 連接,
2. 基于位元組流;TCP 連接雙方的資料交換格式是以位元組 (byte,1byte = 8 bit)構成的有序但無結構的位元組流,
3. 可靠性,它主要通過以下方式確保可靠性,
- 合理的資料大小:TCP 發送的資料并不是固定的大小,而是會根據實際情況調整報文段的大小,
- 檢驗和:發送端按照特定演算法計算出 TCP 報文段的檢驗和并存盤在 TCP 首部中的對應欄位上,接收端在接收時會以同樣的方式計算校驗和,如果不一致,說明報文段出現錯誤,會將其丟棄,
- 序號與確認序號:對亂序的資料進行排序后發給應用層,并丟棄重復的資料,
- 超時重傳機制:當 TCP 發出一個報文段后,它會啟動一個定時器,等待目的端確認收到這個報文段,如果不能及時收到一個確認,將重發這個報文段,
- 連接管理:也就是三次握手和四次揮手,連接的可靠性是整體可靠性的前提,本文第二部分將會詳細介紹連接管理的內容,
- 流量控制:TCP 雙方都有固定大小的緩沖區,流量控制的原理是利用滑動視窗控制資料發送速度,避免緩沖區溢位導致資料丟失,
- 擁塞控制:TCP 利用慢啟動和擁塞避免等演算法實作了擁塞控制,
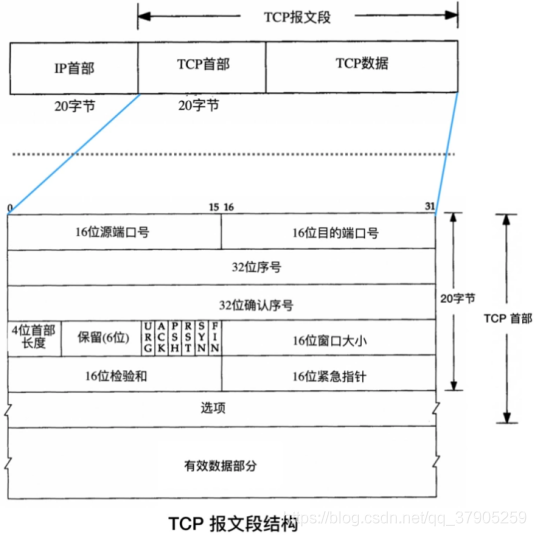
TCP報文段的組成:
- 序號 (Sequence Number):這個欄位的主要作用是用于將失序的資料重新排列,TCP 會隱式地對位元組流中的每個位元組進行編號,而 TCP 報文段的序號被設定為其資料部分的第一個位元組的編號,序號是 32 bit 的無符號數,取值范圍是0到 232 - 1,
- 確認序號 (Acknowledgment Number):接收方在接受到資料后,會回復確認報文,其中包含確認序號,作用就是告訴發送方自己接收到了哪些資料,下一次資料從哪里開始發,假設ack=201,表示序號為201之前的資料已經收到,現在期望接收序號為201及之后的資料,因此,確認序號應當是上次已成功收到資料位元組序號加 1,只有 ACK 標志為 1 時確認序號欄位才有效,
- 控制位 (Control Bits):在三次握手和四次揮手中會經常看到 SYN、ACK 和 FIN 的身影,一共有 6 個標志位,它們表示的意義如下:①ACK (Acknowledgment Bit):值為 1 時,確認序號生效,②PSH (Push Bit):接收方應盡快將這個報文段交給應用層,③SYN (Synchronize Bit):同步序號,用于發起一個連接,④FIN (Finish Bit):發送端要求關閉連接,⑤URG (Urgent Bit):值為 1 時,緊急指標生效,⑥RST (Reset Bit):發送端遇到問題,想要重建連接,
- 視窗大小 (Window): TCP的流量控制由連接的每一端通過宣告的視窗大小來提供,視窗大小為位元組數,起始于確認序號欄位指明的值,這個值是接收端正期望接收的位元組,視窗大小是一個 16 bit 欄位,單位是位元組, 因而視窗大小最大為 65535 位元組,
- 檢驗和 (Checksum):功能類似于數字簽名,用于驗證資料完整性,也就是確保資料未被修改,檢驗和覆寫了整個 TCP 報文段,包括 TCP 首部和 TCP 資料,發送端根據特定演算法對整個報文段計算出一個檢驗和,接收端會進行計算并驗證,
- 有效資料部分 (Data):這部分也不是必須的,比如在建立和關閉 TCP 連接的階段,雙方交換的報文段就只包含 TCP 首部,
OSI七層模型和TCP五層模型


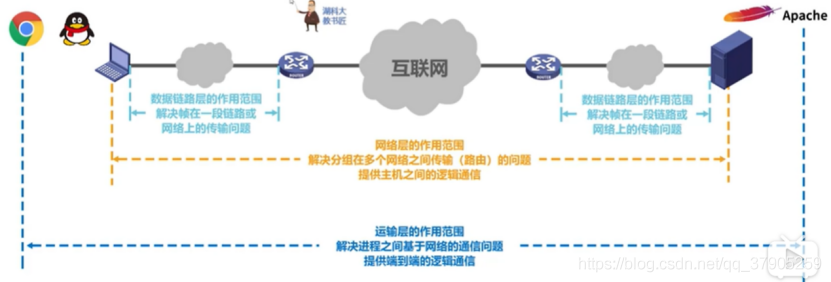
OSI定義了網路互連的七層框架(物理層、資料鏈路層、網路層、傳輸層、會話層、表示層、應用層),
應用層是最靠近用戶的一層,是為計算機用戶提供應用介面,也為用戶直接提供各種網路服務,它解決了通過應用行程間的互動來實作特定網路應用的問題,常見應用層的協議有:HTTP,HTTPS,FTP,POP3、SMTP等,所有能和用戶互動產生網路流量的程式,
表示層:該層的功能為資料格式轉換、資料壓縮和恢復、資料加密解密,它解決了通信雙方交換資訊的表示問題,
會話層:該層的功能為①建立、管理、終止會話,②使用校驗點可使會話在通信失效時從校驗點繼續恢復通信,實作資料同步,它解決了行程之間進行會話的問題,
傳輸層(運輸層):負責向兩個主機中行程之間的通信提供通用的資料傳輸服務,該層的功能為①提供可靠傳輸、不可靠傳輸,②差錯控制,③流量控制,④復用分用,復用:多個應用層行程可同時使用運輸層的服務,分用:運輸層把收到的資訊分別交付上面應用層中的相應行程,它解決了行程之間基于網路的通信問題,
網路層(IP層、網際層):負責選擇合適的路由,把分組從源端傳到目的端,為分組交換網上的不同主機提供通信服務,該層的功能為路由控制、流量控制、差錯控制、擁塞控制,它解決了分組在多個網路之間傳輸的問題,
資料鏈路層:負責把網路層傳下來的資料報組成幀,它解決了幀在一個網路上傳輸的問題,它的功能:成幀、差錯控制、流量控制、訪問控制,
物理層:負責在物理媒體上實作位元流的透明傳輸,它解決了使用何種信號來傳輸位元0和1的問題,它的功能有定義介面特性、定義傳輸模式、定義傳輸速率、位元同步、位元編碼,
TCP對應的應用層協議
FTP:檔案傳輸協議,使用21埠,常說某某計算機開了FTP服務便是啟動了檔案傳輸服務,下載檔案,上傳主頁,都要用到FTP服務,
Telnet:遠程終端協議,用戶可以以自己的身份遠程連接到計算機上,通過這種埠可以提供一種基于DOS模式下的通信服務,如以前的BBS是-純字符界面的,支持BBS的服務器將23埠打開,對外提供服務,
SMTP:定義了簡單郵件傳送協議,現在很多郵件服務器都用的是這個協議,用于發送郵件,如常見的免費郵件服務中用的就是這個郵件服務埠,所以在電子郵件設定-中常看到有這么SMTP埠設定這個欄,服務器開放的是25號埠,
POP3:它是和SMTP對應,POP3用于接收郵件,通常情況下,POP3協議所用的是110埠,也是說,只要你有相應的使用POP3協議的程式(例如Fo-xmail或Outlook),就可以不以Web方式登陸進郵箱界面,直接用郵件程式就可以收到郵件(如是163郵箱就沒有必要先進入網易網站,再進入自己的郵-箱來收信),
HTTP:超文本傳輸協議,負責服務器與瀏覽器之間的通信,
UDP對應的應用層協議
DNS:用于域名決議服務,將域名地址轉換為IP地址,DNS用的是53號埠,
SNMP:簡單網路管理協議,使用161號埠,是用來管理網路設備的,由于網路設備很多,無連接的服務就體現出其優勢,
TFTP(Trival File Transfer Protocal):簡單檔案傳輸協議,該協議在熟知埠69上使用UDP服務,
HTTP和HTTPS
http協議全稱是HyperTest Transfer Protocol,超文本傳輸協議,對客戶端和服務器端之間資料傳輸的格式規范,超文本傳輸??協議(HTTP)是一個用于傳輸超媒體檔案(例如 HTML)的應用層協議,它是為 Web 瀏覽器與 Web 服務器之間的通信而設計的,但也可以用于其他目的,HTTP 遵循經典的客戶端-服務端模型,客戶端打開一個連接以發出請求,然后等待直到收到服務器端回應,
HTTP 是無狀態協議,無狀態是指協議對于事務處理沒有記憶能力,服務器不知道客戶端是什么狀態,每個請求都是獨立的,這一次請求和上一次請求是沒有任何關系的,互不認識的,沒有關聯的,
HTTP協議的無狀態性帶來的問題:①用戶登錄后,切換到其他界面,進行操作,服務器端是無法判斷是哪個用戶登錄的, 每次進行頁面跳轉的時候,得重新登錄,②如在一個電商網站里,用戶把某個商品加入到購物車,切換一個頁面后再次添加了商品,這兩次添加商品的請求之間沒有關聯,瀏覽器無法知道用戶最終選擇了哪些商品,
解決方案:Cookie和session,cookie機制采用的是在客戶端保持狀態的方案,而session機制采用的是在服務器端保持狀態的方案,
http報文就是client和server通信時依據http協議,將傳輸的資訊以文本的形式呈現,這個文本就是http報文,http報文分為請求報文和訊息報文,這兩類報文有著相同的結構組成,

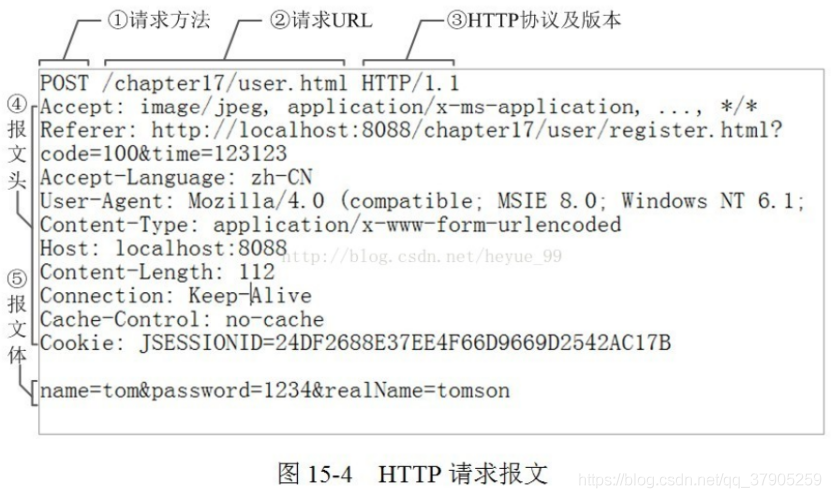
請求報文:
請求行=請求方法+URL+HTTP協議版本,3個欄位組成,它們用空格分隔,例如,GET /index.html HTTP/1.1,
請求頭部由鍵值對組成,每行一對,格式為“屬性名:屬性值”,請求頭部通知服務器有關于客戶端請求的資訊,
請求頭之后是一個空行,發送回車符和換行符,通知服務器以下不再有請求頭,
請求體是報文體,它將頁面表單中的資料通過param1=value1?m2=value2的鍵值對形式編碼成一個格式化串,承載多個請求引數的資料,
https://blog.csdn.net/lzghxjt/article/details/99233637
請求頭常見屬性:
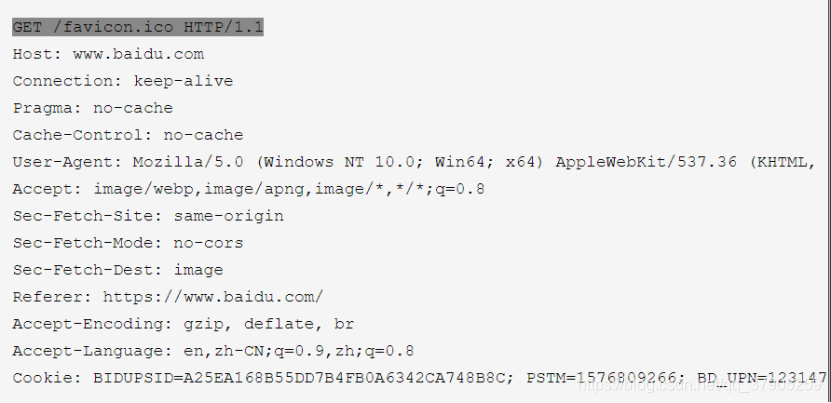
1) HOST
請求頭指明了請求將要發送到的服務器主機名和埠號,
如果沒有包含埠號,會自動使用被請求服務的默認埠(比如HTTPS URL使用443埠,HTTP URL使用80埠),
HTTP、HTTPS等常用的默認埠號
2) Connection
客戶端或服務端用來告訴對方當前tcp連接的狀態,表示是否需要持續連接,
Connection:keep-alive 網路連接就是持久的,不會關閉,使得對同一個服務器的請求可以繼續在該連接上完成,Connection:close 在回應結束后關閉連接,這是HTTP/1.0請求的默認值
3) pragma
Pragma 是一個在 HTTP/1.0 中規定的通用首部,這個首部的效果依賴于不同的實作,所以在“請求-回應”鏈中可能會有不同的效果,它用來向后兼容只支持 HTTP/1.0 協議的快取服務器,那時候 HTTP/1.1 協議中的 Cache-Control 還沒有出來,
注意:由于 Pragma 在 HTTP 回應中的行為沒有確切規范,所以不能可靠替代 HTTP/1.1 中通用首部 Cache-Control,盡管在請求中,假如 Cache-Control 不存在的話,它的行為與 Cache-Control: no-cache 一致,建議只在需要兼容 HTTP/1.0 客戶端的場合下應用 Pragma 首部,
4) Cache-Control
對快取進行控制,如一個請求希望回應回傳的內容在客戶端要被快取一年,或不希望被快取就可以通過這個屬性達到目的,
Cache-Control: no-cache 在發布快取副本之前,強制要求快取把請求提交給原始服務器進行驗證(協商快取驗證),
6) User-Agent
用戶代理:簡稱UA,內容是發出請求的用戶資訊,使得服務器能夠識別客戶端使用的作業系統及版本、CPU型別、瀏覽器及版本、瀏覽器渲染引擎、瀏覽器語言、插件等,服務器端和客戶端腳本都能訪問它,它是瀏覽器型別檢測邏輯的重要基礎.該資訊由你的瀏覽器來定義,并且在每個請求中自動發送,
7)Accept
請求報文可通過一個“Accept”報文頭屬性告訴服務端,客戶端接受什么型別的回應,
如下報文頭相當于告訴服務端,客戶端能夠接受的回應型別僅為純文本資料
Accept:text/plain
通配符 * 代表任意型別,如下代表瀏覽器可以處理所有型別
Accept: */*
Accept屬性的值可以為一個或多個MIME型別的值(描述訊息內容型別的因特網標準, 訊息能包含文本、影像、音頻、視頻以及其他應用程式專用的資料)
常用的Accept屬性
8) Referer
表示這個請求是從哪個URL發過來的,假如你通過百度搜索出一個商家的廣告頁面,你對這個廣告頁面感興趣,滑鼠一點發送一個請求報文到商家的網站,這個請求報文的Referer報文頭屬性值就是 https://www.baidu.com/
Referer的作用:1.防盜鏈,2.防止惡意請求,
空 Referer 的定義為, Referer 頭部的內容為空,或者,一個 HTTP 請求中根本不包含 Referer 頭部,當一個請求并不是由鏈接觸發產生的,那么就不需要指定這個請求的鏈接來源,比如,直接在瀏覽器的地址欄中輸入一個資源的URL地址,那么這種請求是不會包含 Referer 欄位的,因為這是一個“憑空產生”的 HTTP 請求,并不是從一個地方鏈接過去的,
9) Accept-Encoding
客戶端用來告訴服務器,瀏覽器能夠進行解碼的資料編碼格式,包括字符編碼、壓縮方式等
例如:Accept-Encoding:gzip, deflate
10) Accept-Language
客戶端用來告訴服務器,瀏覽器所希望的語言種類,
例如:Accept-Language:zh-CN,zh;q=0.9
11) cookie
客戶端的Cookie就是通過這個報文頭屬性傳給服務端的,如下所示:
Cookie: $Version=1; jsessionid=5F4771183629C9834F8382E23
jsessionid就是用來判斷當前用戶對應于哪個session,換句話說服務器識別session的方法是通過jsessionid來告訴服務器該客戶端的session在記憶體的什么地方,(當然也可以通過重寫URL的方式將會話ID附帶在每個URL的后面,在禁用cookie的時候可以用這個方法),
Jsessionid只是tomcat的對sessionid的叫法,其實就是sessionid;在其它的容器也許就不叫jsessionid了,
回應報文
狀態行=服務器HTTP協議的版本+回應狀態代碼+狀態代碼的文本描述,
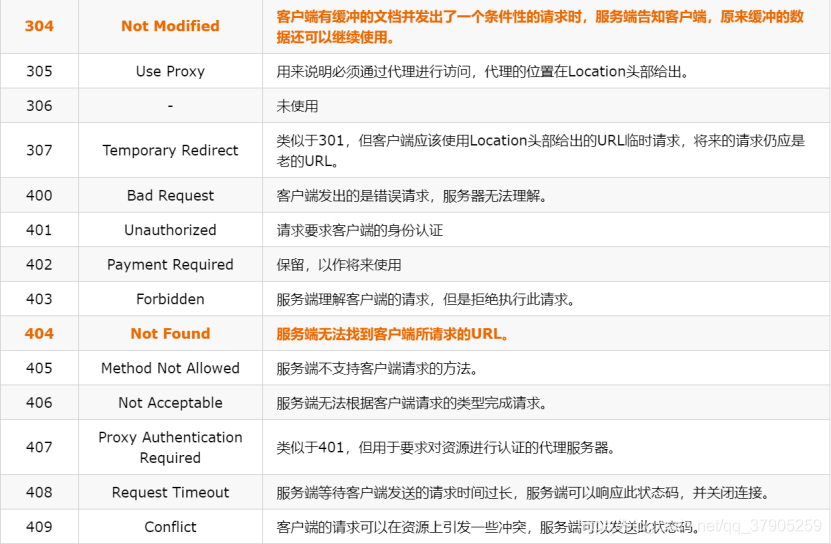
200 OK:客戶端請求成功,
400 Bad Request:客戶端請求有語法錯誤,不能被服務器所理解,
401 Unauthorized:請求未經授權,
403 Forbidden:服務器收到請求,但是拒絕提供服務,
404 Not Found:請求資源不存在,舉個例子:輸入了錯誤的URL,
500 Internal Server Error:服務器發生不可預期的錯誤,
503 Server Unavailable:服務器當前不能處理客戶端的請求,一段時間后可能恢復正常,
回應頭常見屬性
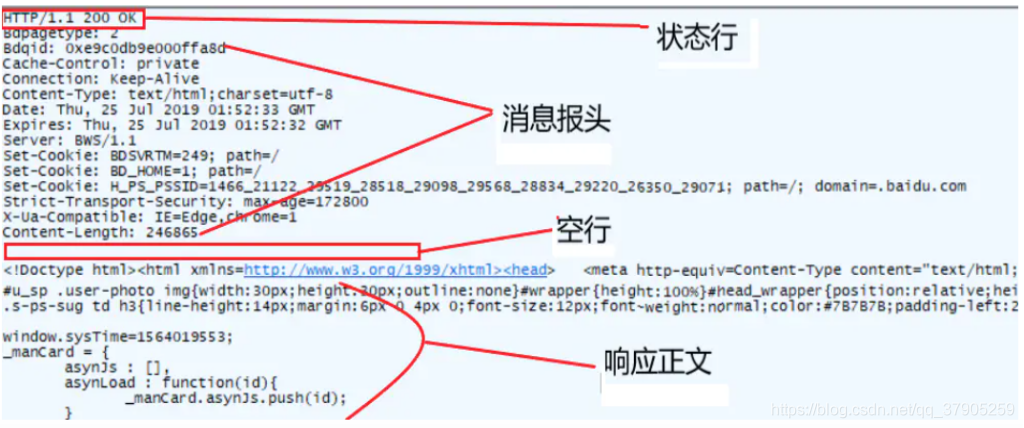
(1) Accept-Ranges
表明服務器是否支持指定范圍的請求,比如bytes,表明支持位元組請求
(2) Access-Control-Allow-Origin
在服務器回應客戶端的時候,如果設定Access-Control-Allow-Origin:* ,則允許所有域名的腳本訪問該資源,
Access-Control-Allow-Origin:http://www.ppt.com ,則表示值允許特定的域名訪問,
(3) Age
從原始服務器到代理快取形成的估算時間,單位為秒,
(4) Cache-Control
回應輸出到客戶端后,服務端通過該報文頭屬告訴客戶端如何控制回應內容的快取,
常見的取值有private、public、no-cache、max-age,no-store,默認為private,
private: 客戶端可以快取
public: 客戶端和代理服務器都可快取(前端的同學,可以認為public和private是一樣的)
max-age=xxx: 快取的內容將在 xxx 秒后失效
no-cache: 需要使用對比快取來驗證快取資料
no-store: 所有內容都不會快取
默認為private,快取時間為31536000秒(365天)也就是說,在365天內再次請求這條資料,都會直接獲取快取資料庫中的資料,直接使用,
(5) Connection
在http1.1中request和reponse header中都有可能出現一個connection頭欄位,此header的含義是當client和server通信時對于長鏈接如何進行處理,在http1.1中,client和server都是默認對方支持長鏈接的, 如果client使用http1.1協議,但又不希望使用長鏈接,則需要在header中指明connection的值為close;如果server方也不想支持長鏈接,則在response中也需要明確說明connection的值為close,
(6)Content-Length
回應體的長度,web服務器回傳訊息正文的長度
(7) Content-Type
回傳內容的MIME型別Content-Type : text/html;charset=utf-8
(8) Date 原始服務器訊息發出的時間
(9) Etag
一個代表回應服務端資源(如頁面)版本的報文頭屬性,如果某個服務端資源發生變化了,這個ETag就會相應發生變化,它是Cache-Control的有益補充,可以讓客戶端“更智能”地處理什么時候要從服務端取資源,什么時候可以直接從快取中回傳回應,
(10) Expires 回應過期的時間
(11) Last-Modified 請求資源的最后修改時間
(12) Server web服務器軟體名稱
(13)Set-Cookie
服務端可以設定客戶端的Cookie,其原理就是通過這個回應報文頭屬性實作的,
(14)Location
我們在JSP中讓頁面Redirect到一個某個A頁面中,其實是讓客戶端再發一個請求到A頁面,這個需要Redirect到的A頁面的URL,其實就是通過回應報文頭的Location屬性告知客戶端的,
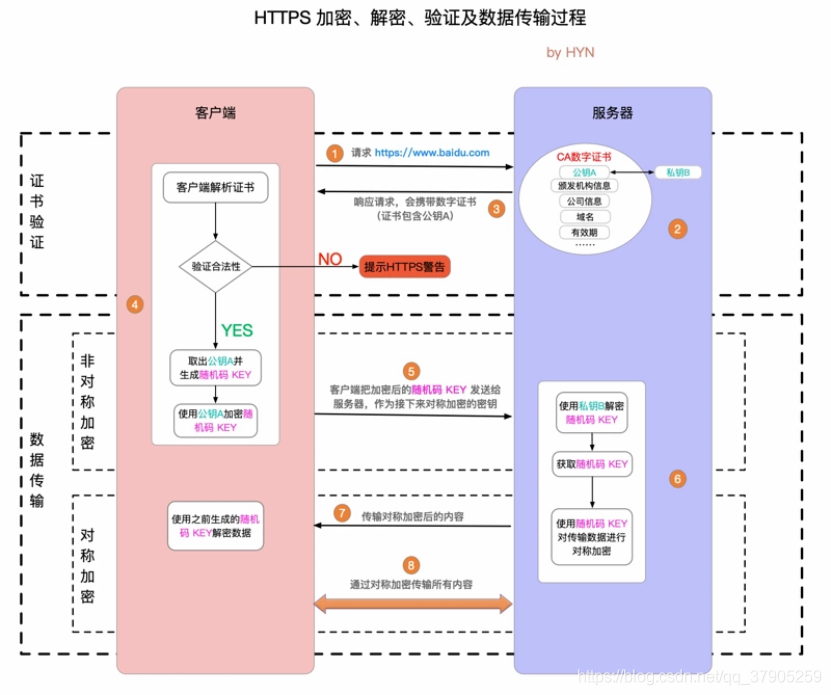
HTTPS = HTTP + SSL / TLS,
超文本傳輸協議安全(HTTPS)是 HTTP 的安全版本,是用于在 Web 瀏覽器和網站之間發送資料的主要協議,HTTPS 是加密的,可以提高資料傳輸的安全性,HTTPS 的整個通信程序可以分為兩大階段:證書驗證和資料傳輸階段,資料傳輸階段又可以分為非對稱加密和對稱加密兩個階段,
安全套接字層 (SSL) 是一種加密安全協議,它最初由 Netscape 于 1995 年開發,旨在確保 Internet 通信中的隱私、身份驗證和資料完整性,SSL 是如今使用的現代 TLS 加密的前身,
HTTPS程序:
1.客戶端請求 HTTPS 網址,然后連接到 server 的 443 埠 (HTTPS 默認埠,類似于 HTTP 的80埠),
2.采用 HTTPS 協議的服務器必須要有一套數字 CA (Certification Authority)證書,證書是需要申請的,并由專門的數字證書認證機構(CA)通過非常嚴格的審核之后頒發的電子證書,頒發證書的同時會產生一個私鑰和公鑰,私鑰由服務端自己保存,不可泄漏,公鑰則是附帶在證書的資訊中,可以公開的,證書本身也附帶一個證書電子簽名,這個簽名用來驗證證書的完整性和真實性,可以防止證書被篡改,
3.服務器回應客戶端請求,將證書傳遞給客戶端,證書包含公鑰和大量其他資訊,比如證書頒發機構資訊,公司資訊和證書有效期等,Chrome 瀏覽器點擊地址欄的鎖標志再點擊證書就可以看到證書詳細資訊,
4.客戶端決議證書并對其進行驗證,如果證書不是可信機構頒布,或者證書中的域名與實際域名不一致,或者證書已經過期,就會向訪問者顯示一個警告,由其選擇是否還要繼續通信,
如果證書沒有問題,客戶端就會從服務器證書中取出服務器的公鑰A,然后客戶端還會生成一個隨機碼 KEY,并使用公鑰A將其加密,
5.客戶端把加密后的隨機碼 KEY 發送給服務器,作為后面對稱加密的密鑰,
6.服務器在收到隨機碼 KEY 之后會使用私鑰B將其解密,經過以上這些步驟,客戶端和服務器終于建立了安全連接,完美解決了對稱加密的密鑰泄露問題,接下來就可以用對稱加密愉快地進行通信了,
7.服務器使用密鑰 (隨機碼 KEY)對資料進行對稱加密并發送給客戶端,客戶端使用相同的密鑰 (隨機碼 KEY)解密資料,
8.雙方使用對稱加密愉快地傳輸所有資料,
HTTPS 和 HTTP 的區別:
- 安全性,HTTP 明文傳輸,不對資料進行加密,安全性較差,HTTPS (HTTP + SSL / TLS)的資料傳輸程序是加密的,安全性較好,
- 使用 HTTPS 協議需要申請 CA 證書,一般免費證書較少,因而需要一定費用,證書頒發機構如:Symantec、Comodo、DigiCert 和 GlobalSign 等,HTTP無需證書,
- HTTP 頁面回應速度比 HTTPS 快,由于加了一層安全層,建立連接的程序更復雜,也要交換更多的資料,難免影響速度,
- 由于 HTTPS 是建構在 SSL / TLS 之上的 HTTP 協議,所以,要比 HTTP 更耗費服務器資源,
- HTTP 的埠是80 ,而 HTTPS 的埠是443
- HTTP 的URL 以http:// 開頭,而HTTPS 的URL 以https:// 開頭
- 在OSI 網路模型中,HTTP作業于應用層,而HTTPS 的安全傳輸機制作業在傳輸層
http協議的缺點:
- 通信使用明文,內容可能被竊聽,
- 通信雙方的身份無法得到認證,身份可能遭遇偽裝,
- 無法驗證報文的完整性,
針對以上問題,https的改進措施:
- 加密,https協議通過SSL或者TLS協議將報文內容進行加密,client端進行加密,server端進行解密,
- 認證,通過值得信賴的第三方機構頒布證書,即可確認通信雙方的身份,客戶端持有證書即可完成客戶端身份的確認,客戶端通信前會查看服務端的證書,
- 完整性保護,可以通過MD5等散列碼進行通信內容的校驗,
HTTPS 的缺點:
- 在相同網路環境中,HTTPS 相比 HTTP無論是回應時間還是耗電量都有大幅度上升,
- HTTPS 的安全是有范圍的,在黑客攻擊、服務器劫持等情況下幾乎起不到作用,
- 在現有的證書機制下,中間人攻擊依然有可能發生,
- HTTPS 需要更多的服務器資源,也會導致成本的升高,
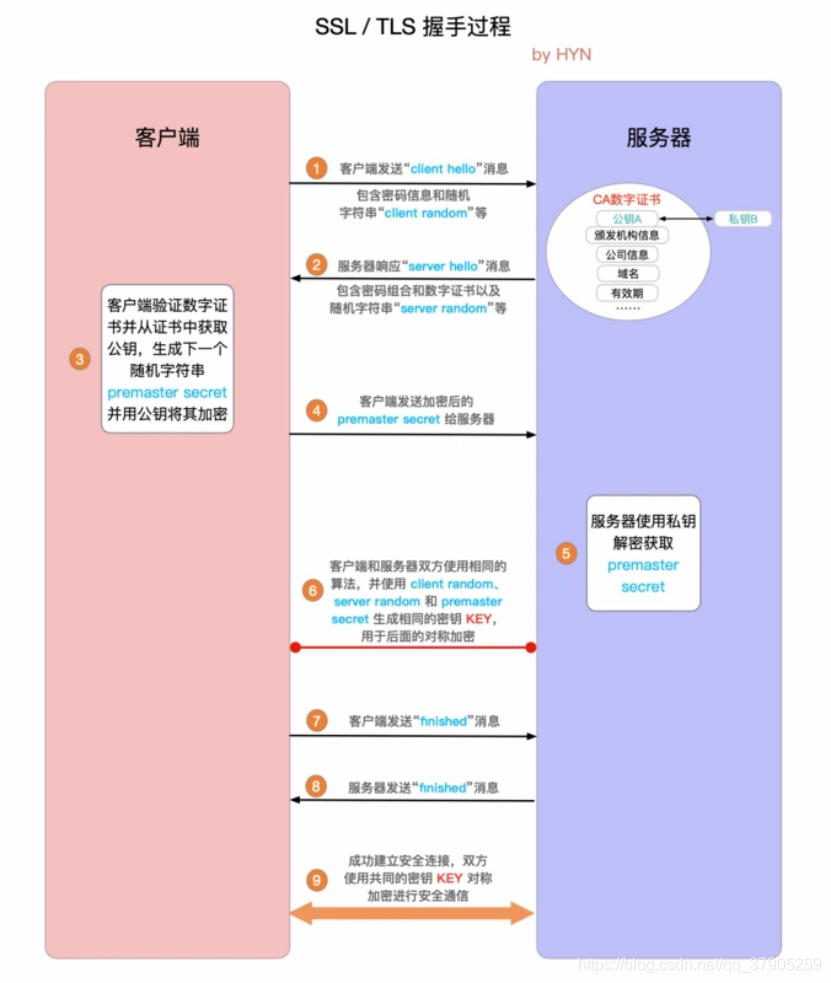
此圖與HTTPS詳解一中的 HTTPS 原理圖的流程大致相同,不同的是此圖把重點放在了TLS握手的相關概念上
SSL / TLS 握手詳細程序:
- "client hello"訊息:客戶端通過發送"client hello"訊息向服務器發起握手請求,該訊息包含了客戶端所支持的 TLS 版本和密碼組合以供服務器進行選擇,還有一個"client random"隨機字串,
- "server hello"訊息:服務器發送"server hello"訊息對客戶端進行回應,該訊息包含了數字證書,服務器選擇的密碼組合和"server random"隨機字串,
- 驗證:客戶端對服務器發來的證書進行驗證,確保對方的合法身份,驗證程序可以細化為以下幾個步驟:
- 檢查數字簽名
- 驗證證書鏈 (這個概念下面會進行說明)
- 檢查證書的有效期
- 檢查證書的撤回狀態 (撤回代表證書已失效)
- "premaster secret"字串:客戶端向服務器發送另一個隨機字串"premaster secret (預主密鑰)",這個字串是經過服務器的公鑰加密過的,只有對應的私鑰才能解密,
- 使用私鑰:服務器使用私鑰解密"premaster secret",
- 生成共享密鑰:客戶端和服務器均使用 client random,server random 和 premaster secret,并通過相同的演算法生成相同的共享密鑰 KEY,
- 客戶端就緒:客戶端發送經過共享密鑰 KEY加密過的"finished"信號,
- 服務器就緒:服務器發送經過共享密鑰 KEY加密過的"finished"信號,
- 達成安全通信:握手完成,雙方使用對稱加密進行安全通信,
常見的http動詞?HTTP常見的請求方法有哪些?
GET 從服務端獲取指定資訊
POST 向服務端發送待處理的資料
HEAD 從服務端獲取指定資訊的頭部
PUT 向服務端發送資料并替換服務端上指定的資料
OPTIONS 查詢針對請求URL指定的資源支持
DELETE 從服務端洗掉指定資料
TRACE 沿著目標資源的路徑執行訊息環回測驗
URI和URL的區別?
URI: Uniform Resource Identifier,統一資源識別符號,用來唯一標識互聯網中的一份資源,
URL: Uniform Resource Locator,統一資源定位符,我們訪問網站的網址就是URL,
URL是URI的子集,
URI的目的就是唯一標識互聯網中的一份資源,具體可以用資源名稱、資源地址等,但是資源地址是目前使用最廣泛的,因此URL就容易和URI混淆,URI相當于抽象類,URL就是這個抽象類的具體實作類,
常見的http回傳碼有哪些?HTTP的狀態碼分為哪幾類?



get與post請求的區別
HTTP定義了與服務器互動的不同方法,最基本的方法有4種,分別是GET,POST,PUT,DELETE,一個URL地址,它用于描述一個網路上的資源,而HTTP中的GET,POST,PUT,DELETE就對應著對這個資源的查,改,增,刪4個操作,到這里,大家應該有個大概的了解了,GET一般用于獲取/查詢資源資訊,而POST一般用于更新資源資訊,
二者的區別:
1、用途不同,GET一般用于請求,POST一般用于表單提交,
2、安全性不同,GET請求是不安全的,是明文傳輸,GET請求提交的資料會在地址欄顯示出來,資料會附在URL之后(就是把資料放置在HTTP協議頭中),以?分割URL和傳輸資料,多個引數用&連接;,POST比GET安全,POST把提交的資料放置在是HTTP包的Request body中,
3、傳輸資料的大小,GET:對傳輸的資料大小有限制,因為瀏覽器對URL長度有限制,POST:理論上對傳輸的資料大小沒有限制,因為資料都是放在Request body中的,但實際各個WEB服務器會規定對post提交資料大小進行限制,
4、是否會自動快取,GET請求會被瀏覽器自動快取,POST:要想快取需要手動設定,
5、反復操作,GET:GET請求在瀏覽器反復的回退/前進是無害的,POST:一旦回退則要重新提交表單,
6、TCP資料報,
GET:GET請求會在發送程序中產生一個TCP資料報,
瀏覽器會將http header和資料data一起發送出去,服務器回應200(回傳請求的資料),
POST:POST在提交程序中會產生兩個TCP資料報,
瀏覽器先發送header,等待服務器回應100 continue
瀏覽器再發送form,服務器回應200 OK
7、對引數的資料型別,GET只接受ASCII字符,而POST沒有限制,
它們的本質都是 TCP 鏈接,但是由于 HTTP 的規定以及瀏覽器/服務器的限制,導致它們在應用程序中會有所不同,
跨域
為什么會有跨域問題呢?
因為有瀏覽器的同源策略,同源策略限制了一個源加載的檔案或者腳本如何與另一個源的資源進行互動,這是用于隔離潛在惡意檔案的重要機制,受同源策略的影響,腳本不能操作非同源下面的物件,想要操作另一個源下的物件是就需要跨域,同源:協議,埠和域名都相同,就是同源,
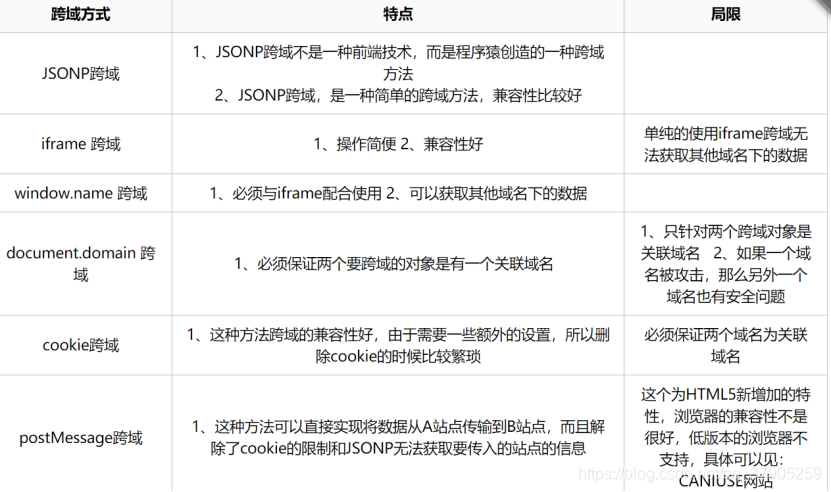
跨域問題的解決方法:
前端跨域解決方法:
后端跨域解決方法:
1、回傳一個新的CorsFilter Bean,并添加映射路徑和具體的CORS配置資訊,
2、在控制器(@Controller)、方法(@RequestMapping)上使用注解 @CrossOrigin
3、使用HttpServletResponse物件添加回應頭(Access-Control-Allow-Origin)來授權原始域,
ajax和jsonp這兩種技術在呼叫方式上看起來很像,目的也一樣,都是請求一個url,然后把服務器回傳的資料進行處理,因此,jQuery等框架都把jsonp作為ajax的一種形式進行了封裝(jsonp型別的ajax), 但ajax和jsonp其實本質上是不同的東西,ajax的核心是通過XmlHttpRequest獲取非本頁內容,而jsonp的核心則是動態創建<script>標簽,然后利用<script>的src不受同源策略約束的特性來跨域獲取資料,
一次完整的HTTP請求所經歷的7個步驟
1. 建立TCP連接
在HTTP作業開始之前,Web瀏覽器首先要通過網路與Web服務器建立連接,該連接是通過TCP來完成的, HTTP是比TCP更高層次的應用層協議,根據規則, 只有低層協議建立之后,才能進行更層協議的連接,因此,首先要建立TCP連接,一般TCP連接的埠號是80,
2. Web瀏覽器向Web服務器發送請求命令
一旦建立了TCP連接,Web瀏覽器就會向Web服務器發送請求命令,例如:GET/sample/hello.jsp HTTP/1.1,
3. Web瀏覽器發送請求頭資訊
瀏覽器發送其請求命令之后,還要以頭資訊的形式向Web服務器發送一些別的資訊,之后瀏覽器發送了一空白行來通知服務器,它已經結束了該頭資訊的發送,
4. Web服務器應答
客戶端向服務器發出請求后,服務器會客戶端發送回應, HTTP/1.1 200 OK ,回應的第一部分是協議的版本號和應答狀態碼,
5. Web服務器發送回應頭資訊
正如客戶端會隨同請求發送關于自身的資訊一樣,服務器也會隨同應答向用戶發送關于它自己的資料及被請求的檔案,
6. Web服務器向瀏覽器發送資料
Web服務器向瀏覽器發送頭資訊后,它會發送一個空白行來表示頭資訊的發送到此為結束,接著,它就以Content-Type回應頭資訊所描述的格式發送用戶所請求的實際資料,
7. Web服務器關閉TCP連接
一般情況下,一旦Web服務器向瀏覽器發送了請求資料,它就要關閉TCP連接,然后如果瀏覽器或者服務器在其頭資訊加入了這行代碼:
Connection:keep-alive
TCP連接在發送后將仍然保持打開狀態,于是,瀏覽器可以繼續通過相同的連接發送請求,保持連接節省了為每個請求建立新連接所需的時間,還節約了網路帶寬,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/287606.html
標籤:其他
上一篇:提高代碼效率的 20 個JavaScript 技巧和竅門
下一篇:-考研第十五周總結-