計算機視覺演算法——目標檢測網路總結
- 計算機視覺演算法——目標檢測網路總結
- 1. RCNN系列
- 1.1 RCNN
- 1.1.1 關鍵知識點——網路結構及特點
- 1.1.2 關鍵知識點——RCNN存在的問題
- 1.1.3 關鍵知識點——非極大值抑制演算法(NMS)
- 1.2 Fast RCNN
- 1.2.1 關鍵知識點——網路結構及特點
- 1.2.1 關鍵知識點——目標檢測多任務損失
- 1.2.3 關鍵知識點——訓練資料的采樣
- 1.3 Faster-RCNN
- 1.3.1 關鍵知識點——網路結構及特點
- 1.3.2 關鍵知識點——RPN網路
- 1.3.3 關鍵知識點——RPN Loss和Fast RCNN Loss聯合訓練
- 2. SSD系列
- 2.1 SSD
- 2.1.1 關鍵知識點——網路結構及特點
- 2.2.1 關鍵知識點——Default Box的設定
- 2.2.2 關鍵知識點——Predictor的實作
- 3. YOLO系列
- 3.1 YOLO v1
- 3.1.1 關鍵知識點——網路結構及特點
- 3.1.2 關鍵知識點——損失計算函式
- 3.1.3 關鍵知識點——YOLO v1存在的問題
- 3.2 YOLO v2
- 3.2.1 關鍵知識點——網路的結構及特點
- 3.2.1 關鍵知識點——提升mAP引數的方法
- 3.3 YOLO v3
- 3.3.1 關鍵知識點——網路結構及特點
- 3.3.2 關鍵知識點——損失計算函式
- 3.4 YOLO v3 SPP
- 3.4.1 關鍵知識點——Mosaic影像增強
- 3.4.2 關鍵知識點——SPP模塊
- 3.4.3 關鍵知識點——CloU Loss
- 4. FPN系列
- 4.1 FPN
- 4.1.1 關鍵知識點——網路結構與特點
- 4.2 RetinaNet
- 4.2.1 關鍵知識點——網路結構及特點
- 4.2.2 關鍵知識點——Focal Loss
計算機視覺演算法——目標檢測網路總結
由于后面作業方向的需要,也是自己的興趣,我決定補習下計算機視覺演算法相關的知識點,參考的學習資料主要是B站Up主霹靂吧啦Wz,強推一下,Up主的分享非常的細致認真,從他這里入門是個不錯的選擇,Up主也有自己的CSDN博客,我這里主要是作為課程的筆記,也會加入一些自己的理解,我也只是個入門的小白,如果有錯誤還請讀者指正,
目標檢測網路是計算機視覺一個重要的應用領域,主要分為One-Stage和Two-Stage兩類方法,下面開始逐個總結各個影像分類網路的特點,
1. RCNN系列
RCNN系列是由RCNN->Fast RCNN->Faster RCNN組成,三個網路的框架分別如下圖所示:
RCNN網路框架:
Fast RCNN網路框架:

Faster RCNN網路框架:

下面分別介紹這三個網路細節
1.1 RCNN
RCNN是2014年提出的,一經提出就將目標檢測準確率提升了30%
1.1.1 關鍵知識點——網路結構及特點
RCNN網路結構如下圖所示: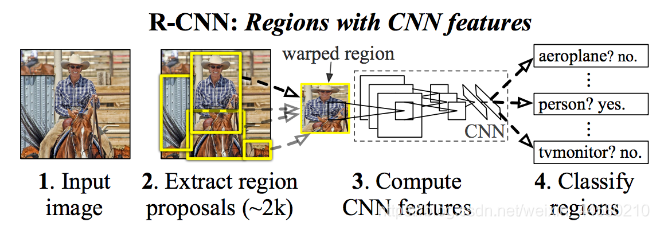
該演算法主要分為四個步驟:
- 使用Selective Search方法在影像上生成1000至2000個候選區域;
Selective Search演算法是通過影像分割的方法得到一些原始區域,然后使用合并策略將區域合并從而得到一個層次化的區域結構,而這些結構中就包含著可能需要檢測的物體, - 對每個候選區域使用深度網路(影像分類網路)提取特征;
將2000個候選區域縮放到 227 × 227 227\times227 227×227個像素大小,然后將候選區域輸入實作訓練好的AlexNet CNN網路獲得4096維的特征,即 2000 × 4096 2000 \times 4096 2000×4096維的矩陣, - 將特征送入每一類的SVM分類器,判斷該區域是否屬于該類;
將 2000 × 4096 2000 \times 4096 2000×4096維特征與20個SVM分類器組成的 4096 × 20 4096 \times 20 4096×20維權重矩陣相乘,獲得 2000 × 20 2000 \times 20 2000×20維矩陣,該矩陣表示每個建議框是某個目標分類的得分,如下圖所示: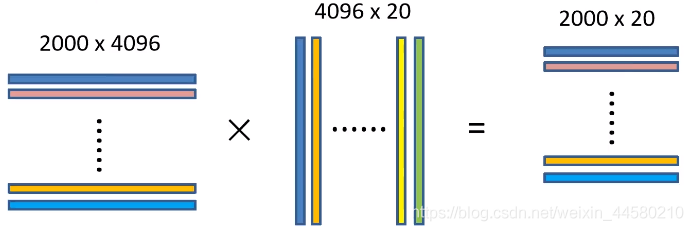
分別對上述 2000 × 20 2000 \times 20 2000×20維矩陣中每一列即每一列進行非極大值抑制剔除重疊建議框,得到該類中得分最好的建議框,非極大值抑制演算法在后文介紹, - 使用回歸器精細修正候選框位置;
對通過非極大值抑制處理后的剩余邊界框進行進一步篩選,接著分別用20個回歸器對上述20個類別的建議框進行回歸操作,最終得到每個類別修正后得分最高的邊界框,這個回歸操作在后面的Fast RCNN進行詳解,
1.1.2 關鍵知識點——RCNN存在的問題
- 測驗速度慢,測驗一張圖片在CPU上需要53S,使用Selective Search演算法提取候選框需要2S,一張影像內候選框之間存在大量重疊,提取特征操作存在大量冗余;
- 訓練速度慢,程序極其繁瑣,不僅需要訓練影像分類網路,還需要訓練SVM分類器、Bounding Box回歸器,訓練程序都是相互獨立的;
- 訓練所需空間大,對于SVM和Bounding Box回歸訓練,需要從每個影像中的每個目標候選框提取特征,并寫入磁盤,對于非常深的網路,訓練集上5K影像上提取的特征需要數百GB的存盤空間,
1.1.3 關鍵知識點——非極大值抑制演算法(NMS)
RCNN中應用的非極大值抑制演算法的步驟如下:
- 在當前類別的候選邊界框中尋找得分最高的邊界框;
- 計算其他邊界框與該邊界框的IOU值;
- 洗掉所有IOU值大于給定閾值的目邊界框;
經過上述步驟后就將最高得分的目標保存下來,再在剩下的邊界框中尋找得分最高的邊界框重復上述步驟,其中IOU值的計算即兩個邊界框交集的區域面積除以兩個邊界框并集區域面積,越大說明兩個邊界框重合區域越大,兩個邊界框越有可能檢測到同一物體,
1.2 Fast RCNN
Fast RCNN使用VGG16作為網路的Backbone,與RCNN相比訓練時間快了9倍,推理測驗時間快了213倍,準確率從62%提高到66%
1.2.1 關鍵知識點——網路結構及特點
Fast RCNN網路結構如下圖所示:
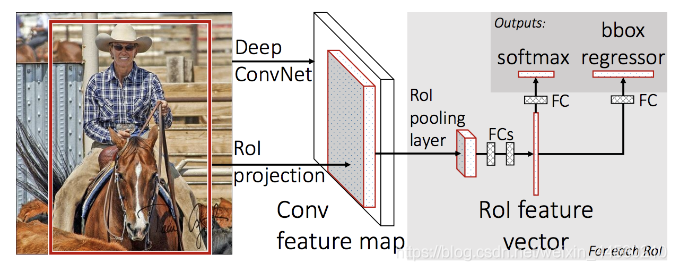
該演算法主要有如下幾個步驟:
- 使用Selective Search方法在影像上生成1000至2000個候選區域
該步驟與RCNN相同,在此不進行贅述, - 將影像輸入網路得到相應的特征圖,將Selective Search生成的候選框投影到特征圖上得到相應的特征矩陣
在RCNN中是將第一步獲得的2000個候選區域縮放到同一大小后如數到特征提取網路中,而FastRCNN是將整張影像送入網路,緊接著從特征圖上提取相應的候選區域,這樣做的好處是避免了候選區域的特征重復計算,下面這張圖就說明了RCNN和FastRCNN在這一關鍵步驟的不同之處
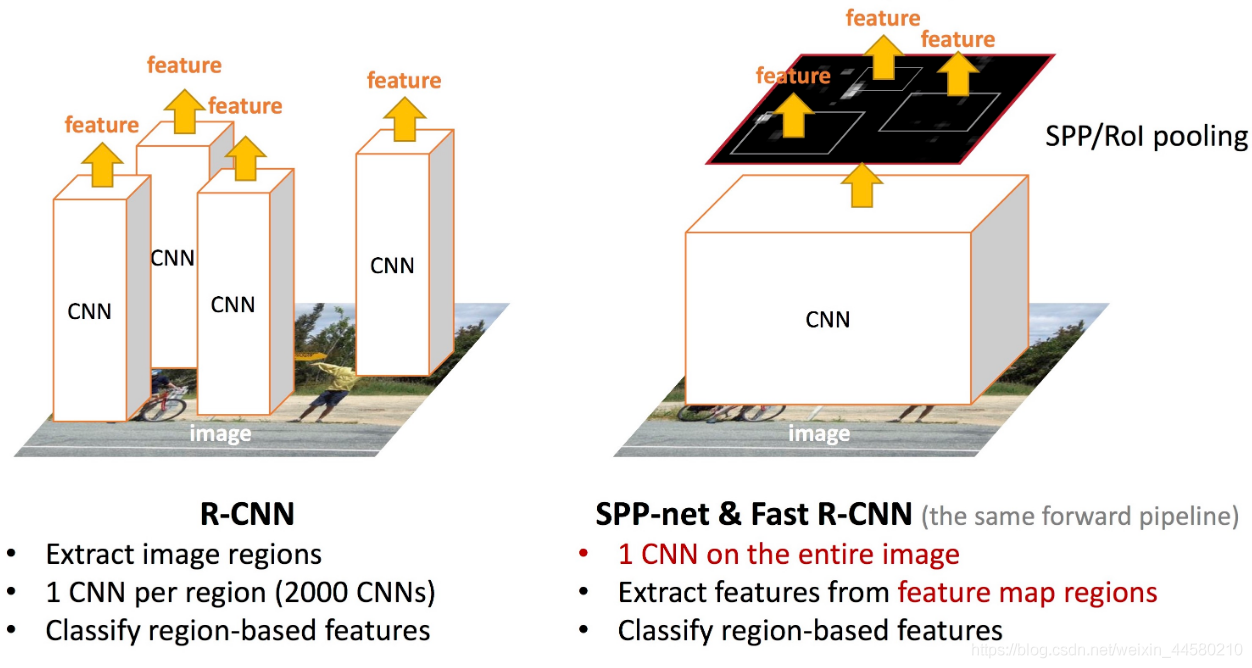
- 將每個特征矩陣通過ROI Pooling層縮放到
7
×
7
7 \times 7
7×7大小的特征圖,接著將特征圖展平通過一系列全連接成得到預測結果
所謂ROI pooling就是將輸出特征劃分為 7 × 7 7 \times 7 7×7的網格,每個網路輸出該網格數值最大的特征值,最后無論原特征矩陣多大最終都得到一個 7 × 7 7 \times 7 7×7大小的特征圖,接下來我們看一下最后全連接層的結構,如下圖所示:
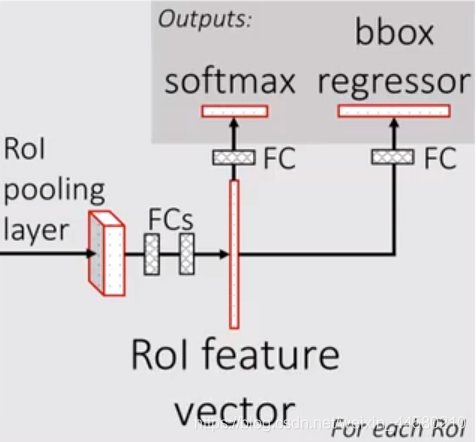
將 7 × 7 7 \times 7 7×7大小的特征圖進行展平處理后通過兩個全連接層后得到ROI feature vector,接下來并聯了兩個全連接層,最后就進行損失計算,
1.2.1 關鍵知識點——目標檢測多任務損失
前文提到ROI Feature Vector后面并聯了兩個全連接層,其中左側全連接層對接分類器,右側全連接層對接邊界框回歸器,兩個不同功能的模塊組成目標檢測中的多任務損失,在目標檢測網路中這是通用的一種損失構建方式,下面具體介紹:
- 分類器:分類器輸出
N
+
1
N+1
N+1個類別的概率(其中
N
N
N為檢測目標的種類,1為背景的概率),因此其對應的全連接層共
N
+
1
N+1
N+1個節點,其中
N
N
N個種類概率是通過softmax輸出的,因此這
N
N
N個種類的概率和為1,因此

- 邊界框回歸器:邊界框回歸器輸出對應
N
+
1
N+1
N+1個類別的候選邊界框回歸引數
d
x
,
d
y
,
d
w
,
d
h
d_x,d_y,d_w,d_h
dx?,dy?,dw?,dh?,因此其對應的全連接層共
(
N
+
1
)
×
4
(N+1)\times 4
(N+1)×4個節點
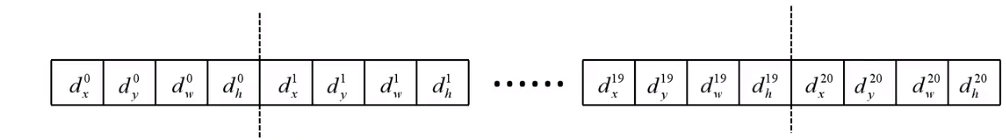
候選框相關的計算公式如下: G ^ x = P w d x ( P ) + P x \hat{G}_{x}=P_{w} d_{x}(P)+P_{x} G^x?=Pw?dx?(P)+Px? G ^ y = P h d y ( P ) + P y \hat{G}_{y}=P_{h} d_{y}(P)+P_{y} G^y?=Ph?dy?(P)+Py? G ^ w = P w exp ? ( d w ( P ) ) \hat{G}_{w}=P_{w} \exp \left(d_{w}(P)\right) G^w?=Pw?exp(dw?(P)) G ^ h = P h exp ? ( d h ( P ) ) \hat{G}_{h}=P_{h} \exp \left(d_{h}(P)\right) G^h?=Ph?exp(dh?(P))其中 P x , P y , P w , P h P_{x}, P_{y}, P_{w}, P_{h} Px?,Py?,Pw?,Ph?分別為候選框的中心 x , y x,y x,y坐標以及寬高, G ^ x , G ^ y , G ^ w , G ^ h \hat{G}_{x}, \hat{G}_{y}, \hat{G}_{w}, \hat{G}_{h} G^x?,G^y?,G^w?,G^h?分別為最終預測的邊界框中心 x , y x,y x,y坐標以及寬高,那么 d x , d y , d w , d h d_x,d_y,d_w,d_h dx?,dy?,dw?,dh?就分別是對候選框的中心和寬高調整的引數, - 基于以上分類器和回歸器計算的多任務損失如下:
L
(
p
,
u
,
t
u
,
v
)
=
L
c
l
s
(
p
,
u
)
+
λ
[
u
≥
1
]
L
l
o
c
(
t
u
,
v
)
L\left(p, u, t^{u}, v\right)= L_{c l s}(p, u)+ \lambda[u \geq 1] L_{l o c}\left(t^{u}, v\right)
L(p,u,tu,v)=Lcls?(p,u)+λ[u≥1]Lloc?(tu,v)其中
p
p
p是分類器預測的softmax概率分布
p
=
(
p
0
,
…
,
p
k
)
p=\left(p_{0}, \ldots, p_{k}\right)
p=(p0?,…,pk?),
u
u
u對應目標真實分類標簽,
t
u
t^u
tu對應邊界框回歸器預測的對應類別
(
t
x
u
,
t
y
u
,
t
w
u
,
t
h
u
)
\left(t_{x}^{u}, t_{y}^{u}, t_{w}^{u}, t_{h}^{u}\right)
(txu?,tyu?,twu?,thu?),
v
v
v對應真實目標的邊界框回歸引數
(
v
x
,
v
y
,
v
w
,
v
h
)
\left(v_{x}, v_{y}, v_{w}, v_{h}\right)
(vx?,vy?,vw?,vh?),
分類損失函式計算公式為: L c l s ( p , u ) = ? log ? p u L_{c l s}(p, u)=-\log p_{u} Lcls?(p,u)=?logpu?這里的 p u p_{u} pu?指的就是當前分類器預測結果為類別 u u u的概率,我們知道,于多分類問題,我們通常采用交叉熵損失(Cross Entropy Loss),計算公式如下: H = ? ∑ i p i ? log ? ( p i ) H=-\sum_{i} p_{i}^{*} \log \left(p_{i}\right) H=?i∑?pi??log(pi?)其中 p i ? p_{i}^{*} pi??為one-hot編碼的真實標簽值,也就是說,該標簽值只有在正確標簽值的位置才為1,其他位置都為0,因此 L c l s ( p , u ) L_{c l s}(p, u) Lcls?(p,u)實際就是交叉熵損失
邊界框回歸損失計算公式為: L l o c ( t u , v ) = ∑ i ∈ { x , y , w , h } smooth ? L 1 ( t i u ? v i ) L_{l o c}\left(t^{u}, v\right)=\sum_{i \in\{x, y, w, h\}} \operatorname{smooth}_{L_{1}}\left(t_{i}^{u}-v_{i}\right) Lloc?(tu,v)=i∈{x,y,w,h}∑?smoothL1??(tiu??vi?) smooth ? L 1 ( x ) = { 0.5 x 2 if ∣ x ∣ < 1 ∣ x ∣ ? 0.5 otherwise \operatorname{smooth}_{L_{1}}(x)=\left\{\begin{array}{ll} 0.5 x^{2} & \text { if }|x|<1 \\ |x|-0.5 & \text { otherwise } \end{array}\right. smoothL1??(x)={0.5x2∣x∣?0.5? if ∣x∣<1 otherwise ?此外 λ \lambda λ為兩類損失的權重系數, [ u ≤ 1 ] [u\leq1] [u≤1]是艾弗森括號,sunshi它的作用是控制確實有目標物體存在的正樣本才會計算邊界框回歸損失,
1.2.3 關鍵知識點——訓練資料的采樣
資料平衡在網路訓練中是非常重要的:
- 在FastRCNN的訓練中,采用的mini-batches的大小為128,但是使用的訓練資料并不是這128張圖通過Selective Search演算法中獲得的2000個候選框,而是從每張圖里面采樣64個候選框,其中25%的候選框為與GroundTruth的IOU大于0.5,我們可以將這些候選框視為正樣本,剩下的候選框與GroundTruth的IOU為0.1到0.5,這些候選框可以視為負樣本
- 通過這樣的資料采樣手段可以保證我們每次采樣程序中獲得的正負樣本基本都是均衡的,這樣對于最后的訓練結果的提升是有非常有幫助的,
1.3 Faster-RCNN
Faster R-CNN同樣使用的是VGG16作為網路的Backbone,推理速度在GPU上達到了5fps,達到了接近實時的水平
1.3.1 關鍵知識點——網路結構及特點
Faster-RCNN網路結構如下:
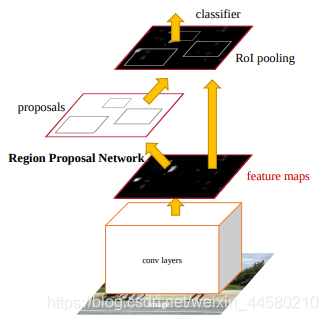
Faster-RCNN已經是一個端到端的網路了,該演算法主要有如下幾個步驟:
- 將影像輸入網路得到相應的特征圖
該步驟與Fast RCNN相同,在此就不再進行贅述, - 使用RPN結構生成候選框,將RPN生成的候選框投影到特征圖上后獲得相應的特征矩陣
這一步就是Faster RCNN的精華,前文我們提到,基于傳統分割方法的Selective Search演算法提取候選框需要2S,這相對網路的其他推理部分是非常耗時的,作者因此將這一部分也替換成網路結構,實作了端到端的網路推理,具體的RPN網路結構設計細節參考下文關鍵知識點, - 將每個特征矩陣通過ROI Poling層縮放到
7
×
7
7 \times 7
7×7大小的特征圖,接著將特征圖展平通過一系列全連接層得到預測結果;
該步驟與Fast RCNN相同,在此不再進行贅述,
1.3.2 關鍵知識點——RPN網路
RPN網路結構如下圖所示:
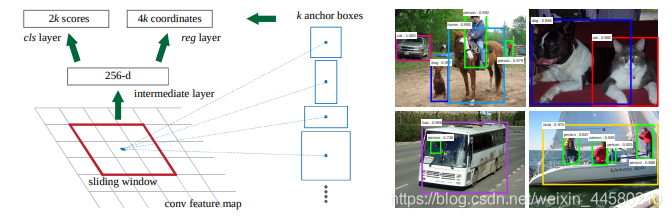
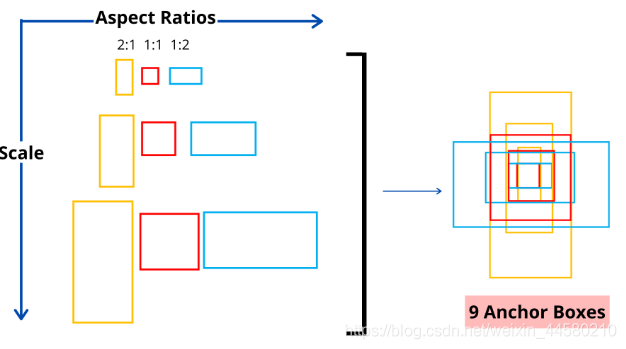
- 網路結構細節如下,RPN網路同Fast RCNN網路是通用的VGG16作為特征提取的backbone,因此上圖拿到的實際上就是VGG16提取的特征圖,對于特征圖上的每個
3
×
3
3 \times 3
3×3的滑動視窗,計算出特征圖中滑動視窗中心位置對應原始影像上的中心點坐標以及基于原始影像上的中心點坐標生成
k
k
k個Anchor Boxes,根據滑動視窗里的256維向量(ZF網路作為Backbone為256維,而VGG網路為512維),對于每個Anchor Box計算出2個概率(前景、背景的概率,這里不進行分類)以及4個坐標,也就是說,也就是說每個滑動視窗會輸出
2
k
2k
2k個概率以及
4
k
4k
4k個坐標,在論文中提到的Anchor Box一共有3種尺度(
12
8
2
,
25
6
2
,
51
2
2
128^{2}, 256^{2}, 512^2
1282,2562,5122)和3種比例(
1
:
1
,
1
:
2
,
2
:
1
1:1, 1:2, 2:1
1:1,1:2,2:1),也就是說這里的
k
=
9
k=9
k=9,如下圖所示:
 這里值得注意的一點是VGG的感受野是
228
228
228,而anchor的尺度最大的會達到
512
×
512
512 \times 512
512×512,這相當于是用一個小的感受野去預測一個大的物體,在論文中作者有提到這一點,并認為這是可行的,
這里值得注意的一點是VGG的感受野是
228
228
228,而anchor的尺度最大的會達到
512
×
512
512 \times 512
512×512,這相當于是用一個小的感受野去預測一個大的物體,在論文中作者有提到這一點,并認為這是可行的, - 多任務損失計算細節如下,RPN網路的的多任務損失定義如下:
L ( { p i } , { t i } ) = 1 N c l s ∑ i L c l s ( p i , p i ? ) + λ 1 N r e g ∑ i p i ? L reg ( t i , t i ? ) L\left(\left\{p_{i}\right\},\left\{t_{i}\right\}\right)=\frac{1}{N_{c l s}} \sum_{i} L_{c l s}\left(p_{i}, p_{i}^{*}\right)+\lambda \frac{1}{N_{reg}} \sum_{i} p_{i}^{*} L_{\text {reg }}\left(t_{i}, t_{i}^{*}\right) L({pi?},{ti?})=Ncls?1?i∑?Lcls?(pi?,pi??)+λNreg?1?i∑?pi??Lreg ?(ti?,ti??)其中:
p i p_i pi?表示第i個Anchor預測為真實標簽的概率;
p i ? p_i^* pi??為正樣本時為1,為負樣本時為0,這和Faster RCNN中的艾弗森括號的作用是相同的;
t i t_i ti?表示預測第 i i i個Anchor的邊界框回歸引數;
t i ? t_i^* ti??表示第 i i i個Anchor對應的Ground Truth Box;
N c l s N_{cls} Ncls?表示一個mini-batch中的所有樣本數量;
N r e g N_{reg} Nreg?表示Anchor位置的個數(注意不是Anchor的個數,Anchor的個數等于Anchor的位置個數乘以 k k k);
上述損失計算公式中前一部分為分類損失,如果使用多類別的Softmax交叉熵損失,因為此處的類別只有前景和背景兩類,如下,那么對于每個Anchor分別計算出屬于前景和背景的概率,對于 k k k個Anchor就需要計算出 2 k 2k 2k個值:

具體公式如下所示: L c l s = ? log ? ( p i ) L_{cls}=-\operatorname{log}(p_i) Lcls?=?log(pi?)如果使用的是二分類的交叉熵損失,那么此處對于每個Anchor就只計算出一個概率,如下,對于 k k k個Anchor就需要計算出 k k k個值:
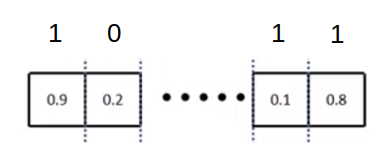
具體公式如下所示: L c l s = ? [ p i ? log ? ( p i ) + ( 1 ? p i ? ) log ? ( 1 ? p i ) ] L_{c l s}=-\left[p_{i}^{*} \log \left(p_{i}\right)+\left(1-p_{i}^{*}\right) \log \left(1-p_{i}\right)\right] Lcls?=?[pi??log(pi?)+(1?pi??)log(1?pi?)]損失計算公式中的后一部分為邊界框回歸損失,邊界框回歸損失的形式和Faster RCNN的形式是一樣的,使用的也是Smooth L1損失,在這里就不進行贅述了,
1.3.3 關鍵知識點——RPN Loss和Fast RCNN Loss聯合訓練
原論文中采用RPN Loss和Fast RCNN Loss聯合訓練的方法如下:
- 利用ImageNet預訓練分類模型初始化前置卷積網路層引數,并開始單獨訓練RPN網路引數;
- 固定RPN網路獨有的卷積以及全連接層引數,利用ImageNet預訓練分類模型初始化前置卷積網路引數,并利用RPN網路生成的目標建議框去訓練Fast RCNN網路引數;
- 固定利用Fast RCNN訓練好的前置卷積網路層引數,去微調RPN網路獨有的卷積層以及全連接層引數;
- 同樣保持固定前置卷積網路層引數,去微調Fast RCNN網路的全連接層引數,最后PRN網路與Fast RCNN網路共享前置軍妓網路層引數,構成一個統一網路,
2. SSD系列
SSD是2016年在ECCV上發表的論文,在 300 × 300 300\times 300 300×300的網路上達到了74.3%mAP以及59FPS,在 512 × 512 512\times512 512×512的網路上,以76.3%mAP超越了Faster RCNN的73.2%mAP
2.1 SSD
2.1.1 關鍵知識點——網路結構及特點
在前文提到的Faster RCNN中存在兩個問題分別是對
- 小目標檢測效果較差:Faster RCNN中采用的都是高層特征資訊,這部分資訊細節資訊保留少,因此對于小目標檢測效果差;
- 模型大、檢測速度慢:Faster RCNN采用的是Two Stage的結構,這是導致檢測速度慢的主要原因,
而SSD網路結構如下:
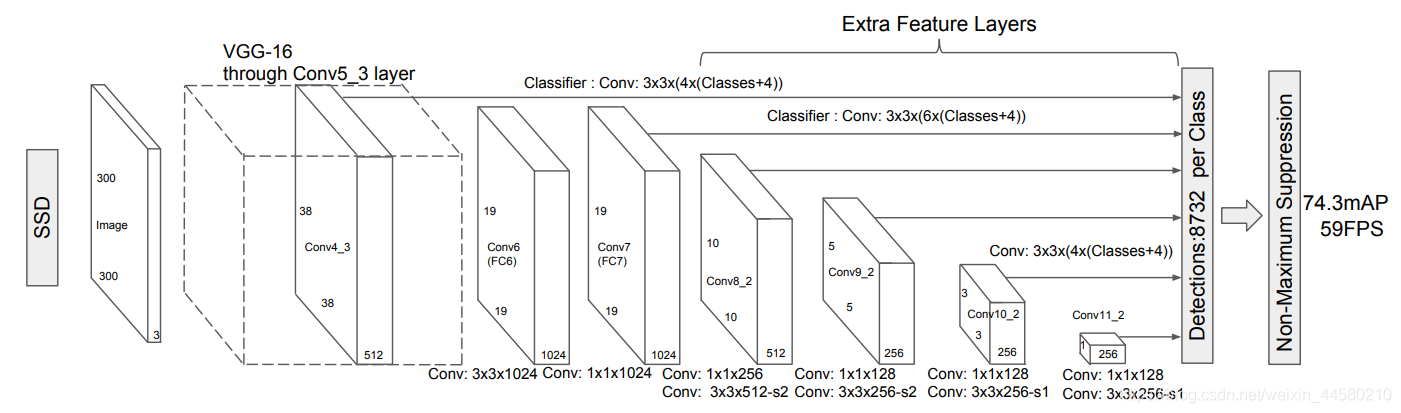
從上圖中可以看到,SSD的網路結構為One-Stage結構,并且在不同特征尺度上預測不同尺度的目標,下面我們具體來說,SSD網路是使用VGG16作為backbone,如下圖所示:
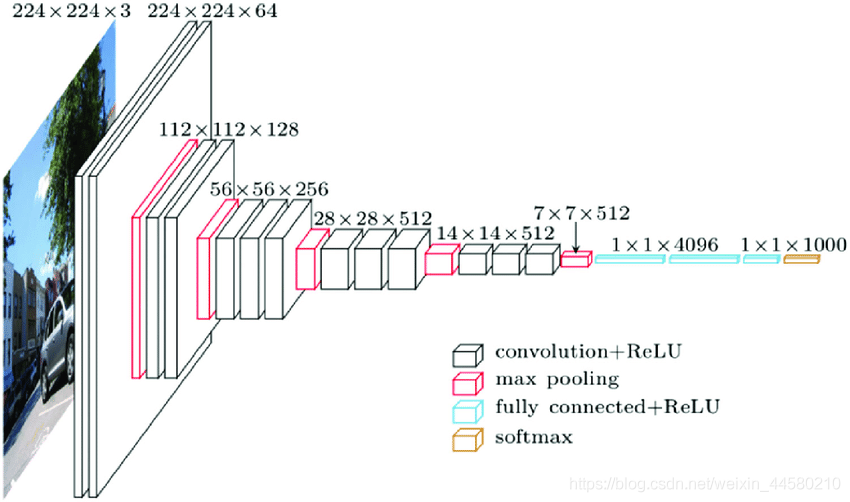
- . SSD網路中的Conv4_3就對應VGG網路中 28 × 28 × 512 28 \times 28 \times 512 28×28×512卷積模塊的第三個卷積層,輸出為 38 × 38 × 512 38 \times 38 \times 512 38×38×512的特征矩陣;
- SSD網路中的Conv5_3就對應VGG網路中 14 × 14 × 512 14 \times 14 \times 512 14×14×512卷積模塊的第三個卷積層位置,輸出為 19 × 19 × 1024 19 \times 19 \times 1024 19×19×1024的特征矩陣;
- SSD網路中的Conv6就對應VGG網路中的第一個全連接層,由于SSD網路對VGG網路中的 7 × 7 × 512 7 \times 7 \times 512 7×7×512的池化層進行了修改,因此輸出仍然為 19 × 19 × 1024 19 \times 19 \times 1024 19×19×1024的特征矩陣;
- SSD網路中的Conv7就對應VGG網路中的第二個全連接層,輸出為 19 × 19 × 512 19 \times 19 \times 512 19×19×512的特征矩陣;
- 緊接著SSD網路中還跟著四個卷積層,輸出分別是 10 × 10 × 512 10 \times 10 \times 512 10×10×512, 5 × 5 × 256 5 \times 5 \times 256 5×5×256, 3 × 3 × 256 3 \times 3 \times 256 3×3×256, 1 × 1 × 256 1 \times 1 \times 256 1×1×256的特征矩陣,特征矩陣的尺寸越來越小,說明所提取的特征也越來越高級,我們會用大尺寸的特征矩陣預測較小的目標,用小尺寸的特征矩陣預測較大的目標,因此以上提到的所有輸出特征矩陣都會輸出到Prediction層進行預測,
2.2.1 關鍵知識點——Default Box的設定
SSD中Default Box和前文Faster RCNN中提到的RPN網路的中Anchor Box是同一個概念,但是RPN網路的特征層就一層,而SSD網路用于預測的特征層是多層,因此Defaul Box的設定會更為復雜,具體規則如下:
- 對與SSD中每一個預測特征層的Default Box都會有不同的尺度(Scale)和長寬比(Aspect),論文中規定,對于Aspect,不同的特征層都只有 { 1 , 2 , 3 , 1 / 2 , 1 / 3 } \left\{1,2,3, {1}/{2}, {1}/{3}\right\} {1,2,3,1/2,1/3}這五種型別,而對于Scale,不同特征層則不相同,第 k k k個預測特征層的Default Box的Scale的公式如下: s k = s min ? + s max ? ? s min ? m ? 1 ( k ? 1 ) , k ∈ [ 1 , m ] s_{k}=s_{\min }+\frac{s_{\max }-s_{\min }}{m-1}(k-1), \quad k \in[1, m] sk?=smin?+m?1smax??smin??(k?1),k∈[1,m]其中, s m i n s_{min} smin?為最小的尺度, s m a x s_{max} smax?為最大的尺度,最后還有一個規則是,對于Aspect為1的Default Box,還有一個額外的 s k s k + 1 \sqrt{s_ks_{k+1}} sk?sk+1? ?的尺寸,因此綜上所屬對于每一個特征層一共有6中不同的Default Box,
- 在學習視頻中作者總結了如下一張表格,說明了SSD中具體的Default Box的設定
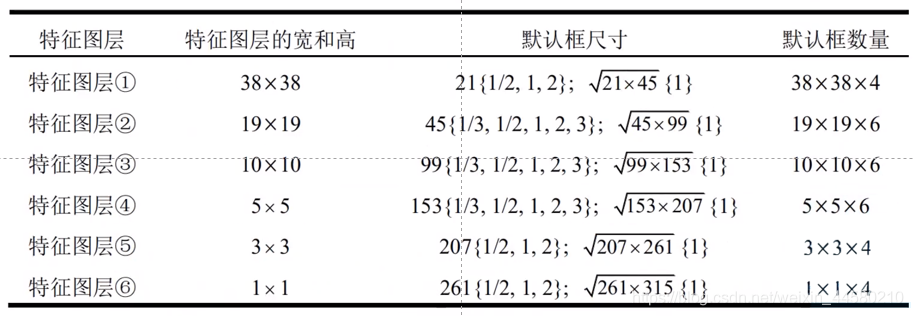
細心的同學可能會注意到,在第一、五、六個特征層中,實際Default Box的尺寸只有4種,那是因為在這幾層忽略了Aspect為3和1/3的兩個Default Box,那么整個SSD網路中Default Box的數量一共為
38
×
38
×
4
+
19
×
19
×
6
+
10
×
10
×
6
+
5
×
5
×
6
+
3
×
3
×
4
+
1
×
1
×
4
=
8732
38 \times 38 \times 4+19 \times 19 \times 6+10 \times 10 \times 6+5 \times 5 \times 6+3 \times 3 \times 4+1 \times 1 \times 4=8732
38×38×4+19×19×6+10×10×6+5×5×6+3×3×4+1×1×4=8732我們這里還需要注意的一點是,這里的尺度Scale指的是原圖中Default Box大小,對于這一點視頻作者還畫了一個圖我覺得非常有助于我們理解,如下
對于第一個特征層,左上角的Anchor使用如圖三種Scale較小的Default Box(大小為21個像素左右)去檢測左上角的那輛面積較小的白車,而對于第四個特征層,中間區域的Anchor使用如果所示的六種Scale較大的Default Box(大小為153個像素左右)去檢測中間那輛面積較大的紅車,
2.2.2 關鍵知識點——Predictor的實作
這里所謂的Predictor其實指的就是最后的用于進行分類和回歸損失計算,在Faster RCNN中最后獲得的特征矩陣是通過ROI Pooling Layer變換成大小相同的特征矩陣,再展開成ROI Pooling Vector,最后通過兩個全連接層再進行分類和回歸損失計算的,而在SSD中,是通過小尺寸的卷積核對特征矩陣進行變換在進行分類和回歸層計算的,具體說來
- 對于尺寸為 m × n × p m \times n \times p m×n×p的特征矩陣,是通過 3 × 3 × p 3 \times 3 \times \ p 3×3× p的卷積核來生成概率分數以及相對Default Box的坐標偏移量,那么一共需要多少個這樣的卷積核呢?對于每個Anchor會輸出 k k k個Default Box,而每個Default Box會輸出 c c c個類別的概率分數(包括背景的概率)以及 4 4 4個坐標偏移量,因此對于每個Anchor會需要 ( c + 4 ) k (c+4)k (c+4)k個卷積和,對于一個 m × n m\times n m×n的特征矩陣就會需要 ( c + 4 ) k m n (c+4)kmn (c+4)kmn個卷積核,
- 這里有一個值得注意的是,在SSD中每個Default Box輸出 ( c + 4 ) (c+4) (c+4)個值,而在Faster RCNN中是對于每個類別都輸出一個位置偏移量的估計,因此是 c × 4 c \times 4 c×4個值,因此Faster RCNN中輸入到Predictor中的值要多一些,
- 當獲得網路輸出的概率分數以及坐標偏移量后,接下來就是進行損失計算了,損失計算公式如下:
L
(
x
,
c
,
l
,
g
)
=
1
N
(
L
conf
(
x
,
c
)
i
+
α
′
L
l
o
c
(
x
,
l
,
g
)
)
L(x, c, l, g)=\frac{1}{N}\left(L_{\text {conf }}(x, c)_{i}+\alpha^{\prime} L_{l o c}(x, l, g)\right)
L(x,c,l,g)=N1?(Lconf ?(x,c)i?+α′Lloc?(x,l,g))其中
N
N
N為匹配到正樣本的個數,損失計算公式中前半部分為類別損失,后半部分為定位損失:
對于類別損失,具體計算公式為 L conf ( x , c ) = ? ∑ i ∈ Pos N x i j p log ? ( c ^ i p ) ? ∑ i ∈ N e g log ? ( c ^ i 0 ) where c ^ i p = exp ? ( c i p ) ∑ p exp ? ( c i p ) L_{\text {conf }}(x, c)=-\sum_{i \in \text { Pos }}^{N} x_{i j}^{p} \log \left(\hat{c}_{i}^{p}\right)-\sum_{i \in N e g} \log \left(\hat{c}_{i}^{0}\right) \quad \text { where } \quad \hat{c}_{i}^{p}=\frac{\exp \left(c_{i}^{p}\right)}{\sum_{p} \exp \left(c_{i}^{p}\right)} Lconf ?(x,c)=?i∈ Pos ∑N?xijp?log(c^ip?)?i∈Neg∑?log(c^i0?) where c^ip?=∑p?exp(cip?)exp(cip?)?從類別損失的計算公式可以看出來,類別損失又可以分為兩部分,前半部分為正樣本類別損失的計算公式,所謂正樣本就是與Ground Truth Box的IOU大于0.5的Default Box,第二部分為負樣本類別損失的計算公式,所謂負樣本就是與Ground Truth Box的IOU為0.1到0.5的Default Box,這些正負樣本的損失其實就是Softmax交叉熵損失,其中
c ^ i p \hat{c}_{i}^{p} c^ip?為預測第 i i i個Default Box對應的Ground Truth類別為 P P P的類別概率,通過公式可以看出其實就是一個經過Softmax處理后的一個概率;
x i j p = { 0 , 1 } x_{i j}^{p}=\{0,1\} xijp?={0,1}表示第 i i i個Default Box匹配到的第 j j j個Ground Truth Box,而第 j j j個Ground Truth Box的類別又為 P P P時該值為1,否則為0,我理解為類似于艾弗森括號的作用;
c ^ i p \hat{c}_{i}^{p} c^ip?為預測第 i i i個Default Box對應的Ground Truth類別為背景的概率;
對于定位損失,僅僅是針對正樣本而言,和Faster RCNN的定位損失函式是一樣的,具體公式如下: L l o c ( x , l , g ) = ∑ i ∈ Pos ? N ∑ m ∈ { c x , c y , w , h } x i j k smooth ? L 1 ( l i m ? g ^ j m ) L_{l o c}(x, l, g)=\sum_{i \in \operatorname{Pos}}^{N} \sum_{m \in\{c x, c y, w, h\}} x_{i j}^{k} \operatorname{smooth}_{\mathrm{L} 1}\left(l_{i}^{m}-\hat{g}_{j}^{m}\right) Lloc?(x,l,g)=i∈Pos∑N?m∈{cx,cy,w,h}∑?xijk?smoothL1?(lim??g^?jm?)其中 g ^ j c x = ( g j c x ? d i c x ) / d i w \hat{g}_{j}^{c x}=\left(g_{j}^{c x}-d_{i}^{c x}\right) / d_{i}^{w} g^?jcx?=(gjcx??dicx?)/diw? g ^ j c y = ( g j c y ? d i c y ) / d i h \hat{g}_{j}^{c y}=\left(g_{j}^{c y}-d_{i}^{c y}\right) / d_{i}^{h} g^?jcy?=(gjcy??dicy?)/dih? g ^ j w = log ? ( g j w d i w ) \hat{g}_{j}^{w}=\log \left(\frac{g_{j}^{w}}{d_{i}^{w}}\right) g^?jw?=log(diw?gjw??) g ^ j h = log ? ( g j h d i h ) \hat{g}_{j}^{h}=\log \left(\frac{g_{j}^{h}}{d_{i}^{h}}\right) g^?jh?=log(dih?gjh??) l i m l_{i}^{m} lim?為預測對應第 i i i個正樣本回歸引數, g ^ j m \hat{g}_{j}^{m} g^?jm?為正樣本 i i i匹配的第 j j j個Ground Truth Box的回歸引數, g j m {g}_{j}^{m} gjm?為第 j j j個Ground Truth Box的位置和長寬引數,Smooth L1的計算公式為: smooth ? L 1 ( x ) = { 0.5 x 2 if ∣ x ∣ < 1 ∣ x ∣ ? 0.5 otherwise \operatorname{smooth}_{L_{1}}(x)=\left\{\begin{array}{ll} 0.5 x^{2} & \text { if }|x|<1 \\ |x|-0.5 & \text { otherwise } \end{array}\right. smoothL1??(x)={0.5x2∣x∣?0.5? if ∣x∣<1 otherwise ?
3. YOLO系列
YOLO是我之前接觸過的一個演算法,當時還寫過一篇博客關于如何呼叫Darknet版的YOLO v3的博客深度學習框架YOLOv3的C++呼叫,但是當時只是覺得好用卻不懂原理,這里總結下,
3.1 YOLO v1
YOLO v1是和SSD同年在CVPR上發表的文章,當時的速度達到了45FPS,準確率達到了63.4mAP,速度和準確率都不及SSD,但是經過一步一步的發展, YOLO系列最終在性能上超過了SSD,這里先介紹下YOLO v1的基本方法
3.1.1 關鍵知識點——網路結構及特點
YOLO v1中實作目標檢測的的主要思想如下:
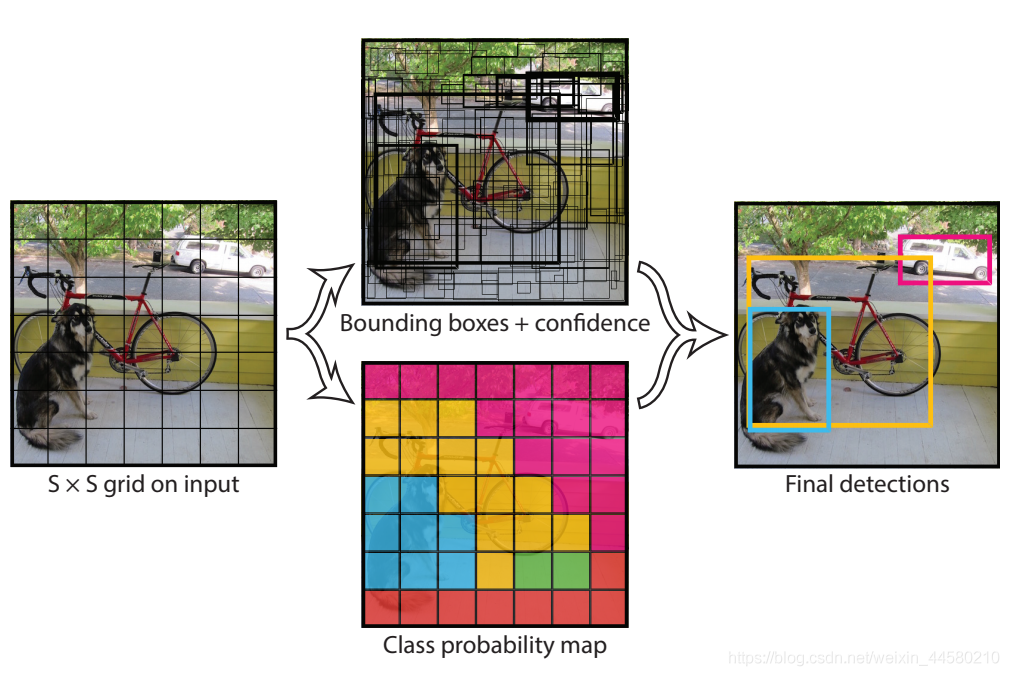
- 將一幅影像分成 S × S S \times S S×S個網格,如果某個物體的中心落在這個網格中,則這個網格就負責預測這個物體;
- 每個網格要預測 B B B個Bounding Box(在YOLO v1中沒有Faster RCNN和SSD中的Anchor的概念),每個Bounding Box包括4個位置引數和1個Confidence值,除此之外,每個網格還要預測 C C C個類別的分數,即每個網格輸出的引數個數為 B × ( 4 + 1 ) + C B \times (4 +1) + C B×(4+1)+C,其中,位置引數包括 x , y , w , h x,y,w,h x,y,w,h這4個引數, x , y x,y x,y表示預測的Bounding Box的中心相對對應網格中心的偏移,而 w , h w,h w,h表示Bounding Box的長寬相對整幅影像長寬的比,Confidence這個引數在Faster RCNN和SSD中都是沒有的,具體來說,Confidence的計算公式為: Pr ? ( Object ) ? IOU pred truth \operatorname{Pr}(\text { Object }) * \text { IOU }_{\text {pred }}^{\text {truth }} Pr( Object )? IOU pred truth ?其中, Pr ? ( Object ) \operatorname{Pr}(\text { Object }) Pr( Object )指的是當Bounding Box中存在物體時,該值為1,不存在物體時,該值為0, IOU pred truth \text { IOU }_{\text {pred }}^{\text {truth }} IOU pred truth ?指的是預測的Bounding Box與真實Bounding Box的交并比,在Test時,網格除了會輸出每一個目標的Bounding Box的位置之外,還會輸出每一個目標的檢測概率,這個概率的計算公式為: Pr ? ( Class i ∣ Object ) ? Pr ? ( Object ) ? IOU pred truth = Pr ? ( Class i ) ? IOU pred truth \operatorname{Pr}\left(\text { Class }_{i} \mid \text { Object }\right) * \operatorname{Pr}(\text { Object }) * \text { IOU }_{\text {pred }}^{\text {truth }}=\operatorname{Pr}\left(\text { Class }_{i}\right) * \text { IOU }_{\text {pred }}^{\text {truth }} Pr( Class i?∣ Object )?Pr( Object )? IOU pred truth ?=Pr( Class i?)? IOU pred truth ?其中 Pr ? ( Class i ∣ Object ) \operatorname{Pr}\left(\text { Class }_{i} \mid \text { Object }\right) Pr( Class i?∣ Object )為網格預測的 C C C個類別的分數,而 Pr ? ( Object ) ? IOU pred truth \operatorname{Pr}(\text { Object }) * \text { IOU }_{\text {pred }}^{\text {truth }} Pr( Object )? IOU pred truth ?就是預測的Bounding Box的Confidence值,從化簡公式可以看出,目標的檢測概率既包含了該目標為某一個類別的概率,也包含了該目標與真實邊界框的交并比,(因為是在Test時使用,這個目標的檢測概率只是一個評測指標嗎?這個需要后面自己去驗證下)
YOLO v1網路的具體結構如下:
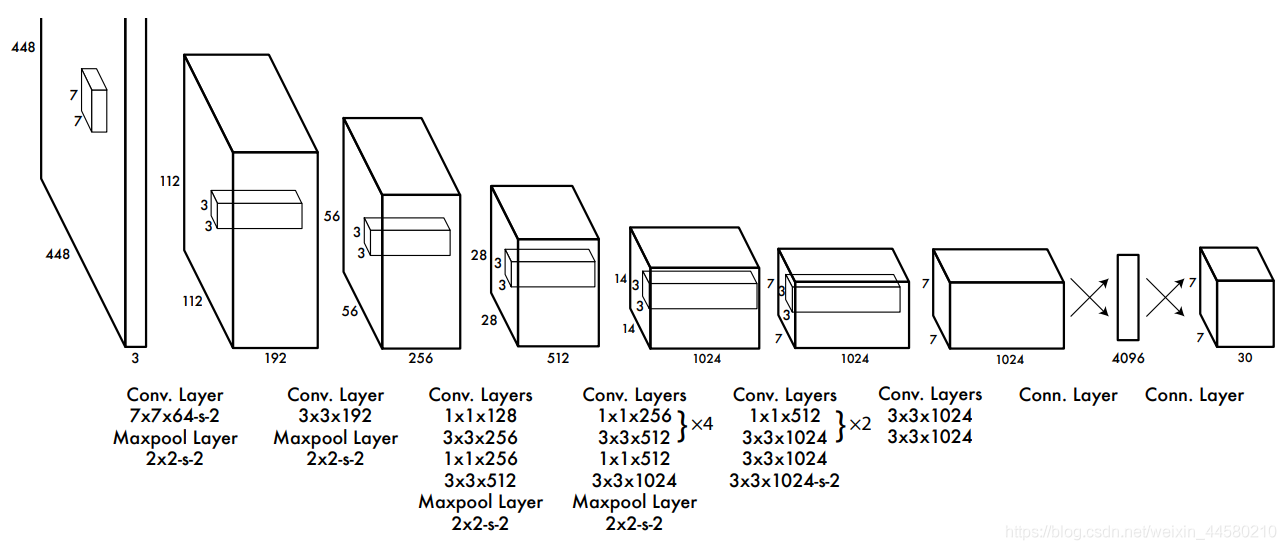
- 使用多層的卷積作為BackBone進行特征提取,最終輸出 7 × 7 × 1024 7 \times 7 \times 1024 7×7×1024的特征矩陣;
- 將 7 × 7 × 1024 7 \times 7 \times 1024 7×7×1024的特征矩陣展平為向量,再連接一個全連接網路,輸出長度為 4096 4096 4096維的特征向量;
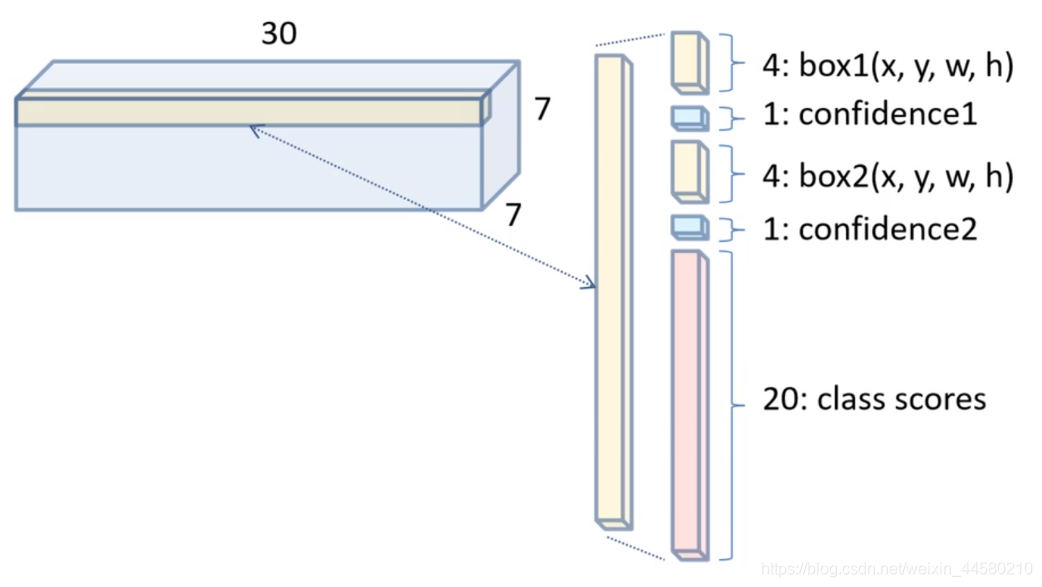
- 將 4096 4096 4096維的特征向量再接一個全連接網路,輸出長度為 1470 1470 1470維的特征向量,并最終將向量Reshape為 7 × 7 × 30 7 \times 7 \times 30 7×7×30的特征矩陣作為輸出,
那么輸出特征矩陣的尺寸為什么為
7
×
7
×
30
7 \times 7 \times 30
7×7×30呢?結合前文所說的YOLO v1進行目標檢測的主要思想,我們對此進行分析,在實際的YOLO v1的搭建程序中,影像被劃分為
S
×
S
=
7
×
7
S \times S = 7 \times 7
S×S=7×7的網格,每個網格預測
B
=
2
B = 2
B=2個Bounding Box以及
C
=
20
C = 20
C=20個類別概率,即每個網格輸出
B
×
(
4
+
1
)
+
C
=
2
×
(
4
+
1
)
+
20
=
30
B \times (4 +1) + C = 2 \times (4 + 1) + 20 = 30
B×(4+1)+C=2×(4+1)+20=30個引數,因此輸出的特征矩陣尺寸為
7
×
7
×
30
7 \times 7 \times 30
7×7×30,如下圖所示,這是可以一一對應上的,
3.1.2 關鍵知識點——損失計算函式
在YOLO v1中,采用的是誤差平方和的作為損失函式計算公式,具體公式如下:
如上圖所示,損失計算函式主要包括三部分,下sunshi面分別介紹
- Bounding Box損失:對于Bounding Box的損失計算主要是對 ( x , y , w , h ) (x,y,w,h) (x,y,w,h)四個預測引數相對真實值的誤差進行平方求和,其中表示位置的 x , y x,y x,y是直接計算,而表示寬高的 w , h w,h w,h是先開根號再計算,開根號的目的是為了保證大目標和小目標在偏移相同距離時,小目標的損失值要更大一些,
- Confidence損失:Confidence分為兩部分,其中 ∑ i = 0 S 2 ∑ j = 0 B 1 i j obj ( C i ? C ^ i ) 2 \sum_{i=0}^{S^{2}} \sum_{j=0}^{B} \mathbb{1}_{i j}^{\text {obj }}\left(C_{i}-\hat{C}_{i}\right)^{2} ∑i=0S2?∑j=0B?1ijobj ?(Ci??C^i?)2為正樣本損失,此時真實值 C ^ i \hat{C}_{i} C^i?為1,而 λ noobj ∑ i = 0 S 2 ∑ j = 0 B 1 i j noobj ( C i ? C ^ i ) 2 \lambda_{\text {noobj }} \sum_{i=0}^{S^{2}} \sum_{j=0}^{B} \mathbb{1}_{i j}^{\text {noobj }}\left(C_{i}-\hat{C}_{i}\right)^{2} λnoobj ?∑i=0S2?∑j=0B?1ijnoobj ?(Ci??C^i?)2為負樣本損失,此時真實值 C ^ i \hat{C}_{i} C^i?為0,
- Class損失:類別損失即預測與真實值的平方和損失,
3.1.3 關鍵知識點——YOLO v1存在的問題
- YOLO v1對群體性的小目標檢測效果差,造成這個問題的主要原因是對每個網格只預測一種型別的目標以及兩個Bounding Box,因此對于小目標的檢測能力有限;
- 對于具備新比例的目標檢測效果差;
- 網路主要的檢測誤差來源與定位不準確,造成這個問題的主要原因YOLO v1中是直接回歸的目標的坐標資訊,而不是像Faster RCNN和SSD那樣回歸到Anchor的引數;
3.2 YOLO v2
YOLO v2是發表于2017年的CVPR,由于其檢測目標可以達到9000個,因此YOLO v2還有一個別名叫做YOLO 9000,從下面這張表格可以看出,YOLO v2在網路性能方面確實有了非常大的提升:
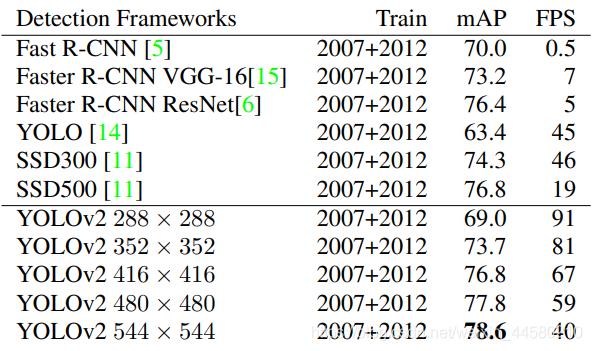 YOLO v2的論文一共分為三部分:Better、Faster、Stronger,下面主要介紹網路結構以及論文是如何各種方法提高網路性能的,
YOLO v2的論文一共分為三部分:Better、Faster、Stronger,下面主要介紹網路結構以及論文是如何各種方法提高網路性能的,
3.2.1 關鍵知識點——網路的結構及特點
論文中用于目標檢測網路的BackBone網路Darknet-19,該網路一共有19層卷積層,網路結構如下:
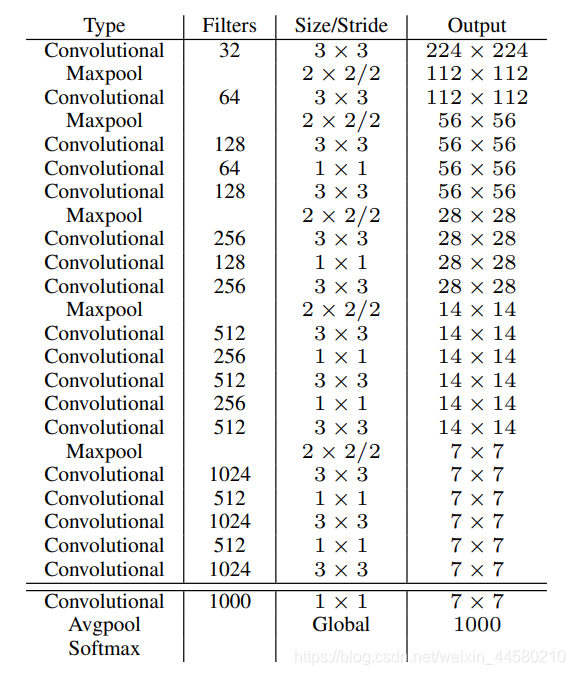
其中
- 表格中每一個Convolutional層指代的都包括Conv2d-BatchNornalization-LeakyReLU這樣三層結構,并且由于使用的Batch Normalization層,因此Conv2d中的卷積是沒有偏置Bais的,
- 在Darknet-19的基礎上,如下圖所示:
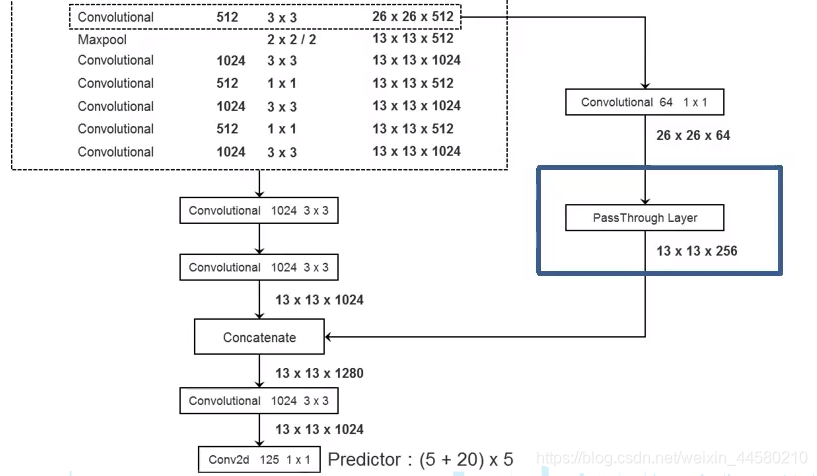
YOLO v2再接了兩個
1024
×
3
×
3
1024 \times 3 \times 3
1024×3×3的卷積層,然后在與來自前文提到的Passthrough Layer的底層特征資訊進行Concate,再接一個
1024
×
3
×
3
1024 \times 3 \times 3
1024×3×3的卷積層,此時特征矩陣的大小為
13
×
13
×
1024
13 \times 13 \times 1024
13×13×1024,最后再接125維的
1
×
1
1 \times 1
1×1矩陣,最終輸出的特征矩陣的大小即為
13
×
13
×
125
13 \times 13 \times 125
13×13×125.
4. 我們來解釋下這個輸出特征矩陣維度
13
×
13
×
125
13 \times 13 \times 125
13×13×125的意義,其中
13
×
13
13 \times 13
13×13可以理解為將影像劃分為
13
×
13
13 \times 13
13×13的網格,每個網格輸出5個Anchor Box,每個Anchor Box負責輸出4個位置回歸引數,1個置信度以及20個類別引數,因此每個網格一共需要輸出
5
×
(
1
+
4
+
20
)
=
125
5 \times (1 + 4 + 20) = 125
5×(1+4+20)=125個引數,
3.2.1 關鍵知識點——提升mAP引數的方法
論文的Better章節中一共從這一下7個方面對進行了嘗試提升網路的mAP引數:
- Batch Normalization,作者提出加入Batch Normalization層對于網路收斂有非常大的幫助,同時可以減少一系列正則化的操作(例如移除dropout層),加入Batch Normalization層后YOLO模型的mAP提升了2%,
- High Resolution Classifier,在YOLO v1中作者使用的是 224 × 224 224 \times 224 224×224的影像作為訓練網路的輸入,而在YOLO v2網路中使用的是 448 × 448 448 \times 448 448×448的影像作為網路輸入,采用更高解析度的分類器可以在模型的mAP引數上提升4%,
- Convolutional With Anchor Boxes,作者提出使用預測Bounding Box相對Anchor Box的Offset相對于直接學習Bounding Box的坐標要簡化網路的學習難度,在沒有使用Anchor Box時,模型的mAP為69.5,召回率為81%,而使用Anchor Box后,模型的mAP為69.2,召回率為88%,作者認為召回率的提高意味著模型有更大的提升空間,
- Dimension Clusters,這里指的是如何獲得Anchor Box的預設尺寸,在Faster RCNN以及SSD中,Anchor Box的預設尺寸更多地像是工程經驗獲得的,而在YOLO v2中明確提出,在訓練集上使用K-Means的方式來獲得Anchor Box的預設尺寸,具體說來,步驟如下:
(1) 用來聚類的原始資料帶有標注框的檢測資料集,標注框的引數為 ( x j , y j , w j , h j ) , j ∈ { 1 , 2 , … , N } \left(x_{j}, y_{j}, w_{j}, h_{j}\right), j \in\{1,2, \ldots, N\} (xj?,yj?,wj?,hj?),j∈{1,2,…,N},因為和標注框位置無關,因此這里實際用到的引數只有 w j , h j w_j,h_j wj?,hj?;
(2) 首先給定 k k k個聚類中心點 ( W i , H i ) , i ∈ { 1 , 2 , … , k } \left(W_{i}, H_{i}\right), i \in\{1,2, \ldots, k\} (Wi?,Hi?),i∈{1,2,…,k},其中 k k k我們需要預設Anchor Box的尺寸的個數;
(3) 計算每個標注框和聚類中心點的距離 d = 1 ? IOU ? d=1-\operatorname{IOU} d=1?IOU,這里計算的IOU指的是當每個標注框中心與Anchor Box中心重合的面積交并比,即 d = 1 ? IOU ? [ ( x j , y j , w j , h j ) , ( x j , y j , W i , H i ) ] , j ∈ { 1 , 2 , … , N } , i ∈ { 1 , 2 , … , k } d=1-\operatorname{IOU}\left[\left(x_{j}, y_{j}, w_{j}, h_{j}\right),\left(x_{j}, y_{j}, W_{i}, H_{i}\right)\right], j \in\{1,2, \ldots, N\}, i \in\{1,2, \ldots, k\} d=1?IOU[(xj?,yj?,wj?,hj?),(xj?,yj?,Wi?,Hi?)],j∈{1,2,…,N},i∈{1,2,…,k},將每個標注框分配給距離最近的聚類中心,
(4) 所有標注框分配完畢后,對每個簇的重新計算聚類中心 W i ′ = 1 N i ∑ w i , H i ′ = 1 N i ∑ h i W_{i}^{\prime}=\frac{1}{N_{i}} \sum w_{i}, H_{i}^{\prime}=\frac{1}{N_{i}} \sum h_{i} Wi′?=Ni?1?∑wi?,Hi′?=Ni?1?∑hi?,然后重復(3)(4)步驟,
如下圖:論文中展示了在COCO資料集上VOC資料集上通過以上方法獲得的不同的Achor Box的預設尺寸: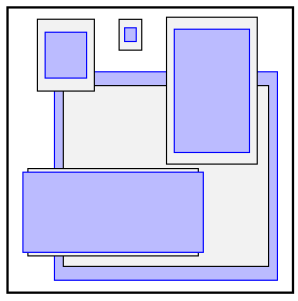
可以觀察到,白色框與紫色框在不同尺度下長寬都有些許不同,通過聚類的方式獲得的相對認為人為設定的方法更加充分地利用了資料集的資訊,讓網路回歸更加輕松, - Direct location prediction,在論文中,作者提出,如果直接使用Faster RCNN或者SSD中的引數回歸方法,會導致在訓練程序中,模型會出現不穩定的情況,而這中間導致不穩定的主要因素又是位置引數 x , y x,y x,y,我們知道,Faster RCNN和SSD中的位置引數方法如下: x = ( t x ? w a ) + x a x=\left(t_{x} * w_{a}\right)+x_{a} x=(tx??wa?)+xa? y = ( t y ? h a ) + y a y=\left(t_{y} * h_{a}\right)+y_{a} y=(ty??ha?)+ya?其中, t x , t y t_x,t_y tx?,ty?為網路預測的引數, x a , x b , w a , w b x_a,x_b,w_a,w_b xa?,xb?,wa?,wb?為Anchor Box的中心坐標以及寬高,作者提出,以上公式是沒有收到限制的,因此網路預測的Bounding Box位置可能出現在影像中的任何位置,因此,在YOLO v2中,作者給出的位置 b x = σ ( t x ) + c x b_{x}=\sigma\left(t_{x}\right)+c_{x} bx?=σ(tx?)+cx? b y = σ ( t y ) + c y b_{y}=\sigma\left(t_{y}\right)+c_{y} by?=σ(ty?)+cy? b w = p w e t w b_{w}=p_{w} e^{t_{w}} bw?=pw?etw? b h = p h e t h b_{h}=p_{h} e^{t_{h}} bh?=ph?eth?其中, t x , t y , t w , t h t_x,t_y,t_w,t_h tx?,ty?,tw?,th?為網路預測的引數, σ ( ) \sigma() σ()其實就是logistic激活函式,該函式的輸出可以將網路預測的輸出限制在一定范圍內,論文指出,通過限制網路的輸出以及通過聚類的方式獲得Anchor Box使得網路mAP提升了5%,
- Fine-Grained Features,這一點指的是使用網路中更加低層的特征資訊,因為低層的特征資訊包含更多的細節,這對檢測小目標是有幫助的,在YOLO v2中的操作方式是通過Passthrough Layer這樣一種網路層將高層特征資訊和底層特征資訊融合的,具體說來,YOLO v2實際上就是將網路BackBone中
26
×
26
×
512
26 \times 26 \times 512
26×26×512的特征取出與最后輸出的
13
×
13
×
1024
13 \times 13 \times 1024
13×13×1024的特征進行Concatenate操作,兩個特征的維度不是不一樣嗎?對!PassThrough Layer的作用就是將
26
×
26
×
512
26 \times 26 \times 512
26×26×512的特征重新組合成維度為
13
×
13
×
2048
13 \times 13 \times 2048
13×13×2048的特征,具體操作方式如下圖所示:
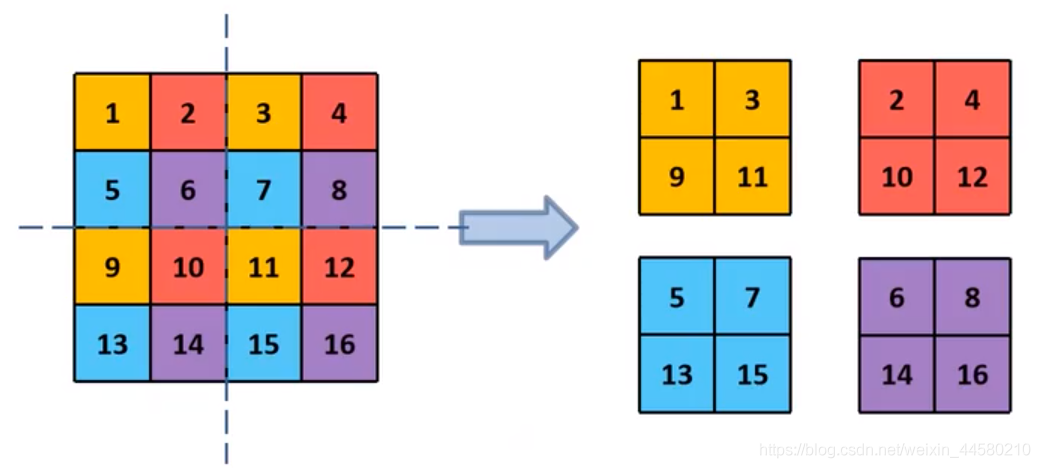 通過這種方式,YOLO v2的mAP提升了1%.
通過這種方式,YOLO v2的mAP提升了1%. - Multi-Scale Training,即采用多尺度的訓練方法,在訓練程序中使用隨機的輸入圖片大小替換掉固定的輸入圖片大小,具體來說,每迭代10個batch就將網路的輸入圖片大小進行隨機選擇,由于YOLO v2的網路縮放因子為32,因此輸入圖片的大小應該為32的整數倍,作者采用的是從 { 320 , 352 , … , 608 } \{320,352, \ldots, 608\} {320,352,…,608}這一些列大小中進行隨機選擇的,
3.3 YOLO v3
YOLO V3發表于2018年的CVPR,其優勢主要體現在如下這張圖中
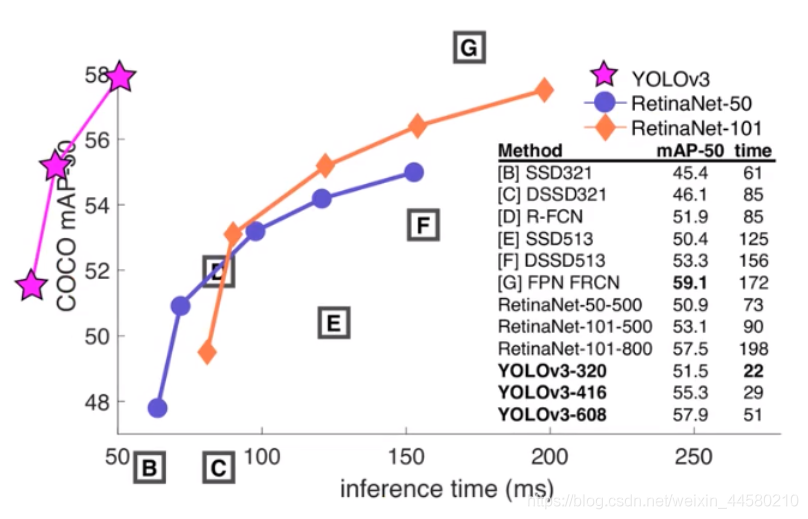
在極高的檢測速度下仍然保證了很高的mAP-50的值,下面我們來簡單看下網路的特點
3.3.1 關鍵知識點——網路結構及特點
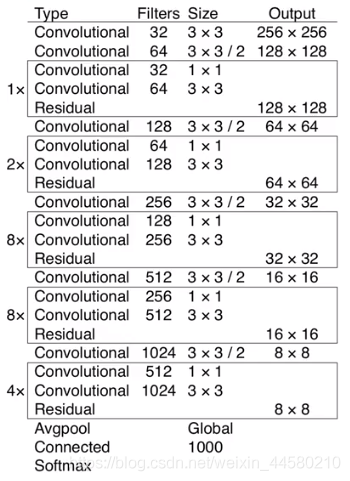
YOLO v3中相對YOLO v2在網路的BackBone上又有了進一步的提升,YOLO v3使用的BackBone為Darknet-53,結構如下圖所示:
其特點主要如下:
- Darknet-53和其他網路準確率以及速度的對比如下:

可以看到,相對于ResNet來說,網路在運行速度上有明顯優勢,在準確率上也有明顯優勢, - 在Darknet-53中沒有最大池化下采樣層,而是通過卷基層代替了最大池化下采樣層,最大池化下采樣層能夠增大感受野,讓卷積看到更多的資訊,但是它在降維的程序中丟失了一些資訊,而步距等于2的卷積層相當于保留了相對更多的資訊,因此效果會更好?(這是觀點屬于個人推測)
- 上圖中Convolutional模塊指的是Convolution層,Batch Normalization層,Leaky ReLU層的集合,結構如下圖所示:

Residual模塊加上它前兩層的Convolutional模塊,就是我們通常理解的殘差模塊,結構如下圖所示: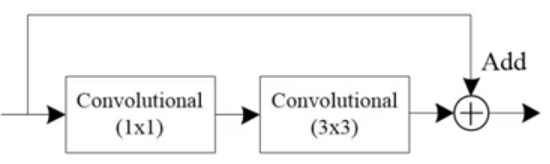
- 在BackBone網路后接的預測特征層如下圖所示,圖片來源自YOLO v3網路結構分析:
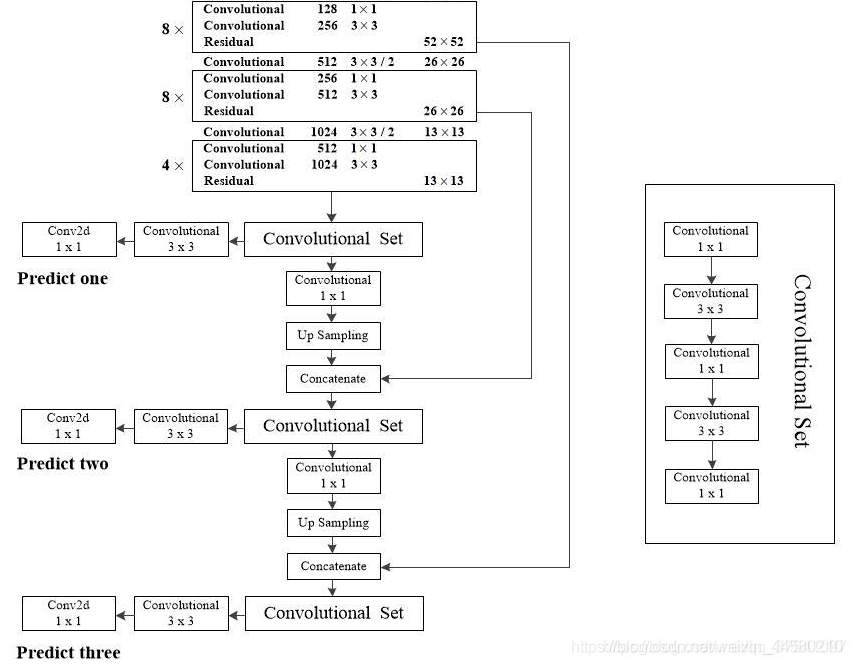
從BackBone網路的后三層Residual模塊開始就會輸出分別接到不同尺度的預測特征層,以Predict One為例,Residual輸出的特征矩陣會先輸入至Convolutional Set模塊,Convolutional Set模塊入上右圖所示,是由一系列Convolutional模塊組成,通過Convolutional Set模塊后,
一方面(圖中向左的鏈路)經過Convolutional模塊和 1 × 1 1\times1 1×1的卷積層輸出,這里輸出的特征的大小為 N × N × [ 3 ? ( 4 + 1 + 80 ) ] N \times N \times[3 *(4+1+80)] N×N×[3?(4+1+80)],其中 N N N指輸出特征層的維度,在Predict One中就是13,此外3指3個Anchor Box,4指位置相關的預測引數,1指Confidence,80指Coco資料集80個預測類別的分數,網路最后基于以上輸出計算損失,
另一方面(圖中向右的鏈路)經過Convolutional模塊、UpSampling模塊后,和BackBone中更低層的特征進行Concate,Concate后得到的特征矩陣,通過Convolutional Set后重復以上步驟,至此就完成了網路預測特征層的搭建,這里值得注意的是相對于YOLO v2的預測特征層網路來說,YOLO v3更加充分地利用了低層網路的資訊,因此YOLO v3在小物體檢測的能力上有了更大的提升,
3.3.2 關鍵知識點——損失計算函式
在進行損失計算函式之前,我們先提一下正負樣本匹配的問題,也就是我們用哪些樣本來計算損失,在YOLO v3的原文中提到, 對于正樣本,只將與Ground Truth的IOU最大的預測Bounding Box作為正樣本計算坐標、類別和置信度損失,其他與Ground Truth的IOU大于0.5的Bouding Box直接忽略掉,而與Ground Truth的IOU小于0.5的Bounding Box作為負樣本,只計置信度損失,YOLO v3的算是計算函式與前兩版有較大不同,在YOLO v1中我們介紹的使用的是誤差平方損失,而在YOLO v3中主要使用的是二值交叉熵損失,具體如下:
- YOLO v3的損失函式主要由三部分組成,分別是置信度損失、類別損失、定位損失,如下所示: L ( o , c , O , C , l , g ) = λ 1 L conf ( o , c ) + λ 2 L cla ( O , C ) + λ L l o c ( l , g ) L(o, c, O, C, l, g)=\lambda_{1} L_{\text {conf }}(o, c)+\lambda_{2} L_{\text {cla }}(O, C)+\lambda L_{l o c}(l, g) L(o,c,O,C,l,g)=λ1?Lconf ?(o,c)+λ2?Lcla ?(O,C)+λLloc?(l,g)其中 L conf ( o , c ) L_{\text {conf }}(o, c) Lconf ?(o,c)是置信讀損失, L cla ( O , C ) L_{\text {cla }}(O, C) Lcla ?(O,C)是分類損失, L l o c ( l , g ) L_{l o c}(l, g) Lloc?(l,g)是定位損失, λ 1 , λ 2 , λ 3 \lambda_{1}, \lambda_{2}, \lambda_{3} λ1?,λ2?,λ3?為各項損失的平衡系數,
- 置信度損失采用的是二值交叉熵損失,公式如下所示: L conf ( o , c ) = ? ∑ i ( o i ln ? ( c ^ i ) + ( 1 ? o i ) ln ? ( 1 ? c ^ i ) ) N L_{\text {conf }}(o, c)=-\frac{\sum_{i}\left(o_{i} \ln \left(\hat{c}_{i}\right)+\left(1-o_{i}\right) \ln \left(1-\hat{c}_{i}\right)\right)}{N} Lconf ?(o,c)=?N∑i?(oi?ln(c^i?)+(1?oi?)ln(1?c^i?))? c ^ i = Sigmoid ? ( c i ) \hat{c}_{i}=\operatorname{Sigmoid}\left(c_{i}\right) c^i?=Sigmoid(ci?)其中, o i ∈ [ 0 , 1 ] o_{i} \in[0,1] oi?∈[0,1]表示預測目標邊界框與真實目標邊界框的IOU, c c c為預測值, c ^ \hat c c^為 c c c通過Sigmoid函式得到的預測置信度, N N N為正負樣本個數,
- 類別損失采用的同樣是二值交叉熵損失,公式如下: L c l a ( O , C ) = ? ∑ i ∈ p o s j ∈ c l a ( O i j ln ? ( C ^ i j ) + ( 1 ? O i j ) ln ? ( 1 ? C ^ i j ) ) N p o s L_{c l a}(O, C)=-\frac{\sum_{i \in p o s j \in c l a}\left(O_{i j} \ln \left(\hat{C}_{i j}\right)+\left(1-O_{i j}\right) \ln \left(1-\hat{C}_{i j}\right)\right)}{N_{p o s}} Lcla?(O,C)=?Npos?∑i∈posj∈cla?(Oij?ln(C^ij?)+(1?Oij?)ln(1?C^ij?))? C ^ i j = Sigmoid ? ( C i j ) \hat{C}_{i j}=\operatorname{Sigmoid}\left(C_{i j}\right) C^ij?=Sigmoid(Cij?)其中 O i j ∈ { 0 , 1 } O_{i j} \in\{0,1\} Oij?∈{0,1},表示預測目標邊界框 i i i中是否存在第 j j j類目標, C i j C_{i j} Cij?為預測值, C ^ i j \hat{C}_{i j} C^ij?為 C i j C_{i j} Cij?通過Sigmoid函式得到的目標概率,由于不是Softmax,因此輸出的所有目標概率和并不為0, N pos N_{\text {pos }} Npos ?為正樣本的個數,
- 定位損失采用的仍然是誤差平方和的計算公式: L l o c ( l , g ) = ∑ i ∈ p o s ∑ m ∈ { x , y , w , h } ( l ^ i m ? g ^ i m ) 2 N p o s L_{l o c}(l, g)=\frac{\sum_{i \in p o s} \sum_{m \in\{x, y, w, h\}}\left(\hat{l}_{i}^{m}-\hat{g}_{i}^{m}\right)^{2}}{N_{p o s}} Lloc?(l,g)=Npos?∑i∈pos?∑m∈{x,y,w,h}?(l^im??g^?im?)2? l ^ i x = Sigmoid ? ( t x ) , l ^ i y = Sigmoid ? ( t y ) \hat{l}_{i}^{x}=\operatorname{Sigmoid}\left(t_{x}\right), \quad \hat{l}_{i}^{y}=\operatorname{Sigmoid}\left(t_{y}\right) l^ix?=Sigmoid(tx?),l^iy?=Sigmoid(ty?) l ^ i w = t w , l ^ i h = t h \hat{l}_{i}^{w}=t_{w}, \quad \hat{l}_{i}^{h}=t_{h} l^iw?=tw?,l^ih?=th? g ^ i x = g i x ? c i x , g ^ i y = g i y ? c i y \hat{g}_{i}^{x}=g_{i}^{x}-c_{i}^{x}, \quad \hat{g}_{i}^{y}=g_{i}^{y}-c_{i}^{y} g^?ix?=gix??cix?,g^?iy?=giy??ciy? g ^ i w = ln ? ( g i w / p i w ) , g ^ i h = ln ? ( g i h / p i h ) \hat{g}_{i}^{w}=\ln \left(g_{i}^{w} / p_{i}^{w}\right), \quad \hat{g}_{i}^{h}=\ln \left(g_{i}^{h} / p_{i}^{h}\right) g^?iw?=ln(giw?/piw?),g^?ih?=ln(gih?/pih?)
3.4 YOLO v3 SPP
YOLO v3 SPP是在YOLO v3基礎上使用了很多Trick是的網路的mAP進一步的得到了提高,這里同樣做一個記錄看看網路是如何錦上添花的
3.4.1 關鍵知識點——Mosaic影像增強
我們通常使用的影像增強演算法指的是影像隨機裁剪、影像隨機翻轉、影像色度和飽和度的隨機調整,而Mosaic影像增強指的是將影像進行隨機拼接再輸入到網路中進行訓練,Mosaic影像增強的好處是:
- 增加了資料的多樣性;
- 增加了目標的個數;
- Batch Normalization能一次性統計多張圖片的引數;
3.4.2 關鍵知識點——SPP模塊
SPP模塊的結構及位置如下圖所示,就是將YOLO v3網路中的第一個預測特征中Convolutional Set拆開,在中間部分插入SPP結構: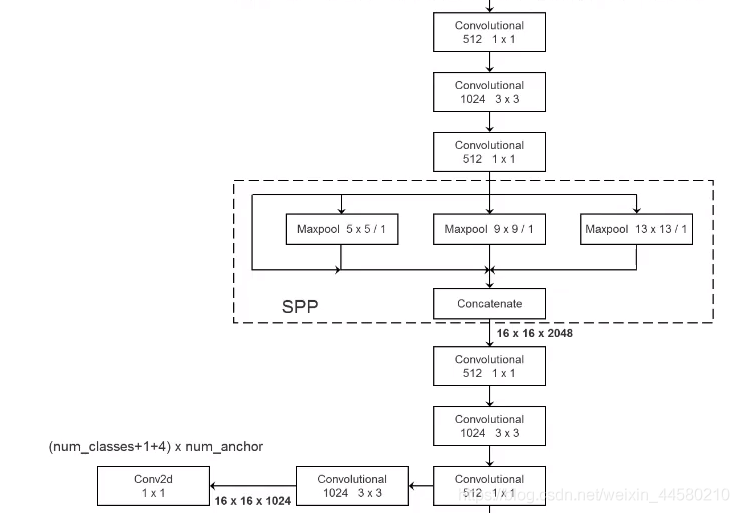
這里的SPP模塊和SPPNet中的SPP結構(Spatial Pyramid Pooling)不同,SPP模塊結構也相對簡單,第一個分支是直連的,第二個分支為大小為
5
×
5
5 \times 5
5×5的最大池化下采樣層,第三個分支大小為
9
×
9
9 \times 9
9×9d的最大池化下采樣層,第四個分之為大小
13
×
13
13 \times 13
13×13的最大池化下采樣層 ,四個分支最后通過Concatenate組合在一起,實作了不同尺度的特征融合,對于網路的mAP值會有明顯的提升,
3.4.3 關鍵知識點——CloU Loss
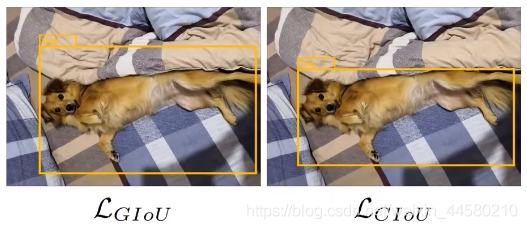
- IoU Loss:在原始的YOLO v3網路中使用的定位損失計算公式為誤差平方和損失,而這里剔除的CloU損失是一種基于IoU的損失計算方法,如下圖所示
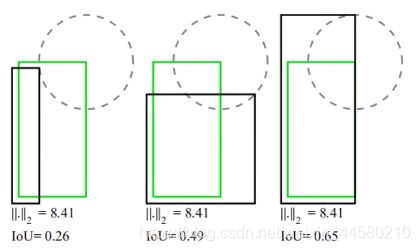
其中綠色方框為真值,黑色方框為預測值,以上三種不同的結果如果計算誤差平方和損失是一樣的,這顯然是不合理的,但是計算IoU就有明顯不同,因為就有前輩提出IoU Loss,計算公式如下是: L I o U = ? ln ? I o U L_{IoU} =-\ln{IoU} LIoU?=?lnIoU通過這里例子我們就可以發現,IOU損失能夠更好的反應重合程度并具有尺度不變形,但是缺點是不相交時損失為0. - GIoU Loss:為了解決這個問題,在IoU Loss的基礎上又有人提出Generalized IoU,即GIoU,計算公式如下:
G
I
o
U
=
I
o
U
?
A
c
?
u
A
c
G I o U={IoU}-\frac{A^{c}-u}{A^{c}}
GIoU=IoU?AcAc?u?
L
G
I
o
U
=
1
?
G
I
o
U
L_{G I o U}=1-G I o U
LGIoU?=1?GIoU
0
≤
L
GIoU
≤
2
0 \leq L_{\text {GIoU }} \leq 2
0≤LGIoU ?≤2其中
A
c
A^c
Ac為下圖中藍色框區域,
u
u
u為下圖中紅色加上綠色區域
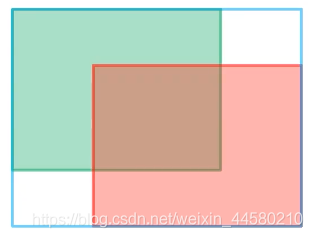 可以看出當兩個邊界框完全重合時,GIoU損失為0,當兩個邊界框相距無窮遠時,GIoU損失為2,但是GIoU孫是同樣擁有缺點,就是當預測邊界框與真實邊界框重合時,GIoU就退化為IoU,
可以看出當兩個邊界框完全重合時,GIoU損失為0,當兩個邊界框相距無窮遠時,GIoU損失為2,但是GIoU孫是同樣擁有缺點,就是當預測邊界框與真實邊界框重合時,GIoU就退化為IoU, - DIoU Loss:在GIoU的基礎上又進一步優化出來了Distance IoU,即DIoU,計算公式如下: D I o U = IoU ? ? ρ 2 ( b , b g t ) c 2 = IoU ? ? d 2 c 2 D I oU=\operatorname{IoU}-\frac{\rho^{2}\left(b, b^{g t}\right)}{c^{2}}=\operatorname{IoU}-\frac{d^{2}}{c^{2}} DIoU=IoU?c2ρ2(b,bgt)?=IoU?c2d2? L DIoU = 1 ? DIoU L_{\text {DIoU }}=1-\text { DIoU } LDIoU ?=1? DIoU 0 ≤ L D I o U ≤ 2 0 \leq L_{D I o U} \leq 2 0≤LDIoU?≤2其中 c c c為上圖中藍色方框對角線距離, d d d為上圖中綠色方框與紅色方框的中心點的距離,DIoU損失可以直接最小化兩個邊界框之間的距離,因此收斂速度更快,
- CIoU Loss:最后引出我們標題上的Complete IoU,即CIoU,計算公式如下:
C
I
o
U
=
IoU
?
?
(
ρ
2
(
b
,
b
g
t
)
c
2
+
α
v
)
C I o U=\operatorname{IoU}-\left(\frac{\rho^{2}\left(b, b^{g t}\right)}{c^{2}}+\alpha v\right)
CIoU=IoU?(c2ρ2(b,bgt)?+αv)
v
=
4
π
2
(
arctan
?
w
g
t
h
g
t
?
arctan
?
w
h
)
2
v=\frac{4}{\pi^{2}}\left(\arctan \frac{w^{g t}}{h^{g t}}-\arctan \frac{w}{h}\right)^{2}
v=π24?(arctanhgtwgt??arctanhw?)2
α
=
v
(
1
?
I
o
U
)
+
v
\alpha=\frac{v}{(1-I o U)+v}
α=(1?IoU)+vv?
L
C
I
o
U
=
1
?
C
I
o
U
L_{C I o U}=1-C I o U
LCIoU?=1?CIoU從公式可以看出來,相對DIoU,CIoU還多了一項
α
v
\alpha v
αv,這一項考慮了邊界框的長寬比,如下圖展示了分別使用GIoU和CIoU的檢測結果
4. FPN系列
FPN是Feature Pyramid Networks的簡稱,下圖展現了FPN結構與其他網路結構的區別,如下圖為四種不同的類金字塔網路結構:
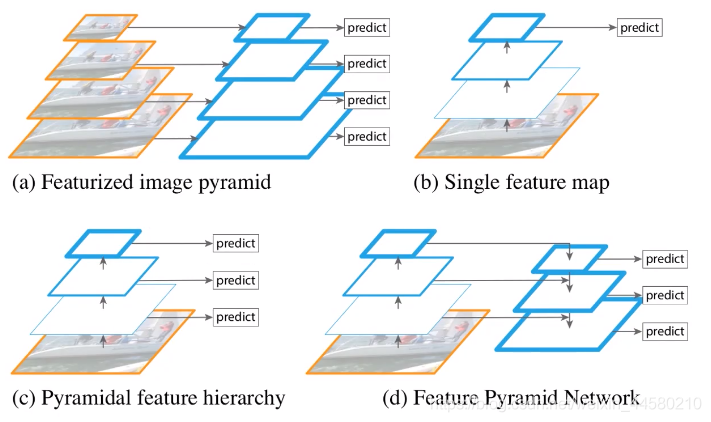
- 圖(a)為影像特征金字塔,即在不同尺度影像上生成特征層再進行目標檢測,該結構的缺點就是計算量巨大,
- 圖(b)為Faster RCNN的簡化結構圖,即通過BackBone網路提取特征,并在最終的特征圖上進行預測,該結構對于小目標的檢測效果較差,
- 圖(c)的結構類似與SSD的網路結構,該網路同樣會使用BackBone進行特征提取,但是會在BackBone的不同特征層上進行預測,
- 圖(d)就是本節要介紹的的FPN結構,該結構的特征就是對BackBone網路中的不同特征層進行融合再進行預測,
實驗證明FPN結構能有效提高目標檢測精度,除此之外,據我了解,Feature Pyramid結構其實除了在目標檢測領域,在很多其他領域也能夠起到提升性能的作用,
4.1 FPN
首先提出該結構的論文《Feature Pyramid Networks for Object Detection》發表于2016年的CVPR,在Fast RCNN網路基礎上使用了FPN結構后,在cocoAP上提升2.3個點,在pascalAP上提升3.8個點,
4.1.1 關鍵知識點——網路結構與特點
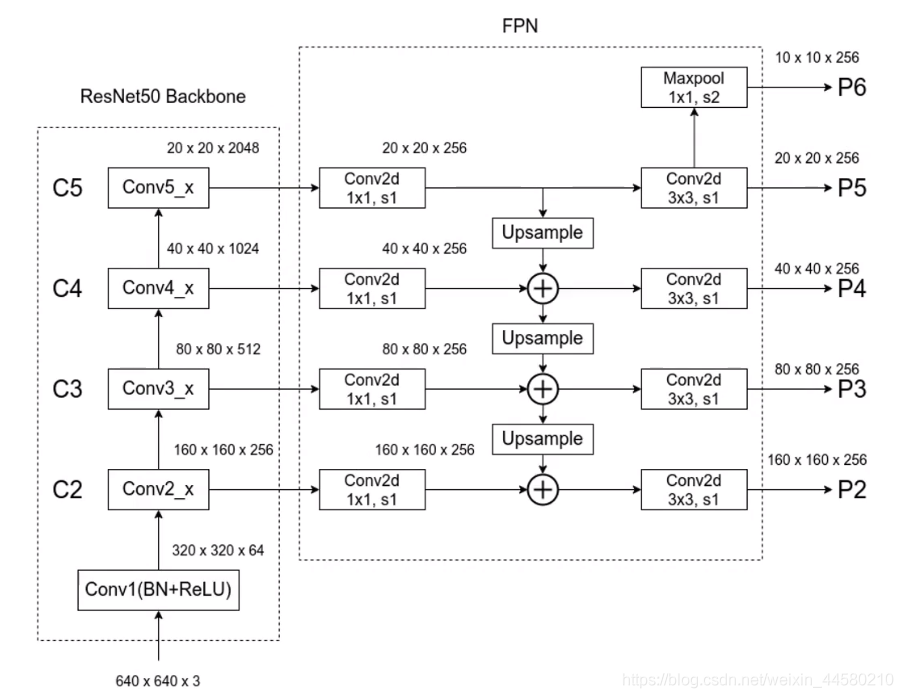
FPN網路中的細節如下,圖片來源1.1.2 FPN結構詳解:
如上圖所示,
- 網路的BackBone采用的是ResNet50;
- 在上圖右側FPNj結構中,所有卷基層在進行融合之前都會先通過一個 1 × 1 1 \times 1 1×1的卷積層處理,目的就是為了使得不同特征層的Channel相同,然后高層的特征圖需要進行2倍的上采樣,目的是與低層的特征圖達到同尺度然后進行融合,而融合方法就是對應通道的特征進行相加,
- 網路運行是首先是通過RPN網路在P2-P6特征層上運行獲得Proposal,然后在通過Fast RCNN網路獲得最終的預測結果,對于不同的預測特征層,RPN和Fast RCNN的權重共享,也就是說使用同一個RPN網路和Fast RCNN網路在不同的特征層上獲得預測結果,
- 在原始的Faster RCNN網路中,是在相同的特征層上生成不同尺寸不同比例的Anchor,而在FPN網路中,在不同的特征層上對不同尺度的目標進行預測,換句話說,就是不同的特征層預測不同面積大小的物體,具體說來,一共有五種尺寸的Anchor分別是 { 3 2 2 , 6 4 2 , 12 8 2 , 25 6 2 , 51 2 2 } \left\{32^{2}, 64^{2}, 128^{2}, 256^{2}, 512^{2}\right\} {322,642,1282,2562,5122}分別對應 { P 2 , P 3 , P 4 , P 5 , P 6 } \left\{P_{2}, P_{3}, P_{4}, P_{5}, P_{6}\right\} {P2?,P3?,P4?,P5?,P6?},每個尺寸都有 { 1 : 2 , 1 : 1 , 2 : 1 } \{1: 2,1: 1,2: 1\} {1:2,1:1,2:1}三種比例,因此在整個FPN網路中一種有15中不同的Anchor,
4.2 RetinaNet
RetinaNet的原論文為《Focal Loss for Dense Object Detection》,發表于2017年的CVPR上,其代表One-Stage網路首次超越Two-Stage網路,RetinaNet就是在FPN網路上的進一步升級,
4.2.1 關鍵知識點——網路結構及特點
RetinaNet的網路結構如下:
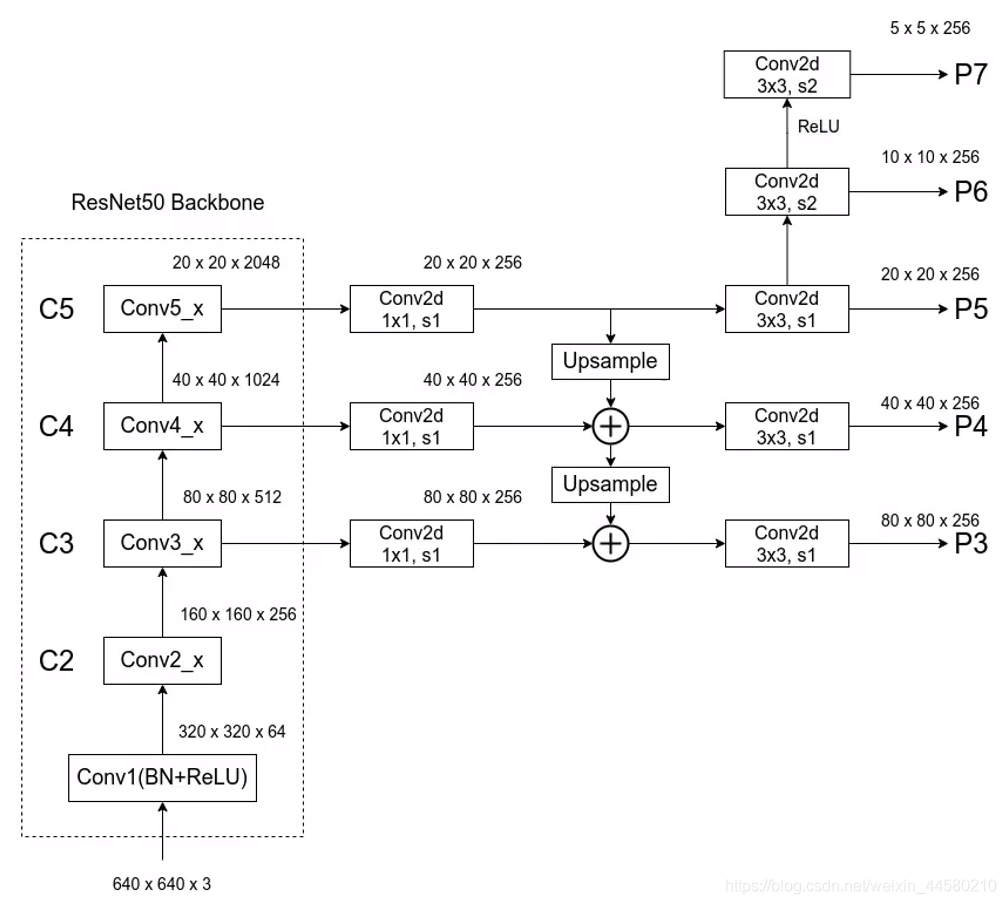
與FPN網路中不同之處主要有如下幾點
- FPN結構中減少了P2層,由于P2層輸出的特征層的維度較大,因此論文認為P2層占用了較大的計算資源,因此論文去掉了P2層,最大維度的特征層為P3層
- P6層在FPN網路中是通過 1 × 1 1 \times 1 1×1的最大池化下采樣層獲得的,而在RetinaNet網路中是通過卷積層獲得;
- RetinaNet中增加了P7層用于檢測更大的目標,
- 在FPN網路中同一種尺度下三種比例的的Anchar,而在Retina網路中,一共有三種尺度對應三種比例,在ReitinaNet網路中一共有 32 { 2 0 , 2 1 3 , 2 2 3 } 32\left\{2^{0}, \quad 2^{\frac{1}{3}}, \quad 2^{\frac{2}{3}}\right\} 32{20,231?,232?}, 64 { 2 0 , 2 1 3 , 2 2 3 } 64\left\{2^{0}, 2^{\frac{1}{3}}, 2^{\frac{2}{3}}\right\} 64{20,231?,232?}, 128 { 2 0 , 2 1 3 , 2 2 3 } 128\left\{2^{0}, 2^{\frac{1}{3}}, 2^{\frac{2}{3}}\right\} 128{20,231?,232?}, 256 { 2 0 , 2 1 3 , 2 2 3 } 256\left\{2^{0}, \quad 2^{\frac{1}{3}}, \quad 2^{\frac{2}{3}}\right\} 256{20,231?,232?}, 512 { 2 0 , 2 1 3 , 2 2 3 } 512\left\{2^{0}, \quad 2^{\frac{1}{3}}, \quad 2^{\frac{2}{3}}\right\} 512{20,231?,232?}共15中尺深度,每個尺寸同樣對應 { 1 : 2 , 1 : 1 , 2 : 1 } \{1: 2,1: 1,2: 1\} {1:2,1:1,2:1}三種比例,
對于每個特征層,都會對應同一個預測器,注意不同層特征層之間的預測器權值共享,預測器的結構如下圖所示:
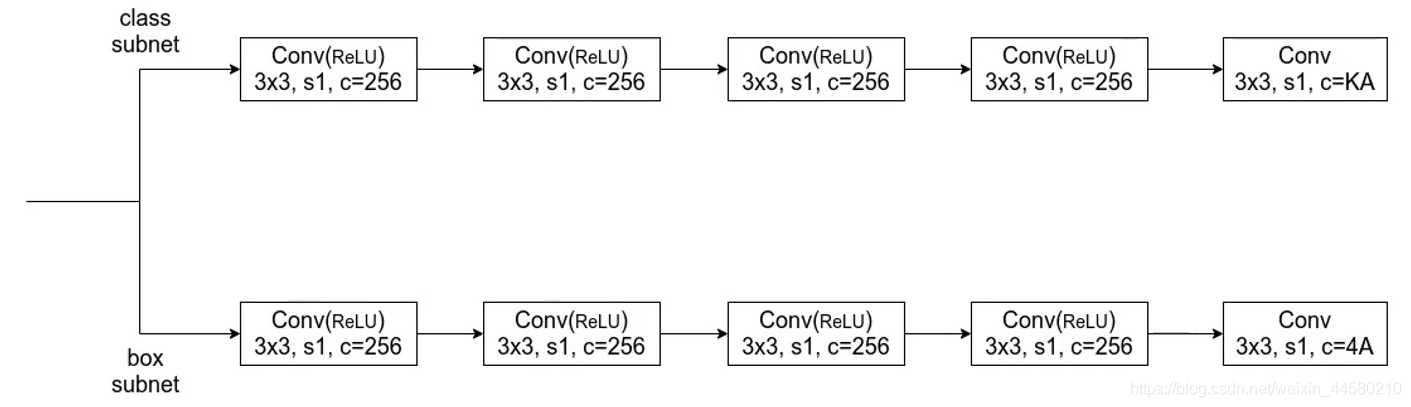
- 預測器中一共有兩個分之,一個負責檢測類別,每個Anchor預測 K K K個物體類別,一個負責檢測邊界框位置,每個Anchor預測 4 4 4個和位置相關的引數,
4.2.2 關鍵知識點——Focal Loss
在RetinaNet中除了網路結構外,最終的一個部分就是Focal Loss的計算了,這一點在標題中就已經體現出來了,Focal Loss的提出主要是為了解決One Stage網路中經常遇到的正負樣本不匹配的問題,對于普通的交叉熵損失計算公式如下:
C
E
(
p
,
y
)
=
{
?
log
?
(
p
)
if
y
=
1
?
log
?
(
1
?
p
)
otherwise.
\mathrm{CE}(p, y)=\left\{\begin{array}{ll} -\log (p) & \text { if } y=1 \\ -\log (1-p) & \text { otherwise. } \end{array}\right.
CE(p,y)={?log(p)?log(1?p)? if y=1 otherwise. ?為了表示簡單,我們可以令
p
t
=
{
p
if
y
=
1
1
?
p
otherwise
p_{\mathrm{t}}=\left\{\begin{array}{ll} p & \text { if } y=1 \\ 1-p & \text { otherwise } \end{array}\right.
pt?={p1?p? if y=1 otherwise ?因此二值交叉熵損失可以重寫為
C
E
(
p
,
y
)
=
C
E
(
p
t
)
=
?
log
?
(
p
t
)
\mathrm{CE}(p, y)=\mathrm{CE}\left(p_{\mathrm{t}}\right)=-\log \left(p_{\mathrm{t}}\right)
CE(p,y)=CE(pt?)=?log(pt?)所謂Focal Loss就是引入一個
α
\alpha
α因子,對于正樣本采用的系數為
α
\alpha
α,對于負樣本采用的是
1
?
α
1-\alpha
1?α,我們進一步重寫為
C
E
(
p
t
)
=
?
α
t
log
?
(
p
t
)
\mathrm{CE}\left(p_{\mathrm{t}}\right)=-\alpha_{\mathrm{t}} \log \left(p_{\mathrm{t}}\right)
CE(pt?)=?αt?log(pt?)進一步地,我們引入一個新的因子
(
1
?
p
t
)
γ
\left(1-p_{\mathrm{t}}\right)^{\gamma}
(1?pt?)γ,那么最終Focal Loss的計算公式為:
F
L
(
p
t
)
=
?
(
1
?
p
t
)
γ
log
?
(
p
t
)
\mathrm{FL}\left(p_{\mathrm{t}}\right)=-\left(1-p_{\mathrm{t}}\right)^{\gamma} \log \left(p_{\mathrm{t}}\right)
FL(pt?)=?(1?pt?)γlog(pt?)在上文中,
a
l
p
h
a
alpha
alpha是一個超引數,并不能區分哪些是適合用來訓練的樣本,而
(
1
?
p
t
)
γ
\left(1-p_{\mathrm{t}}\right)^{\gamma}
(1?pt?)γ這個因子能夠降低容易區分的樣本的損失貢獻,而增強困難區分的樣本的損失,如下圖所示: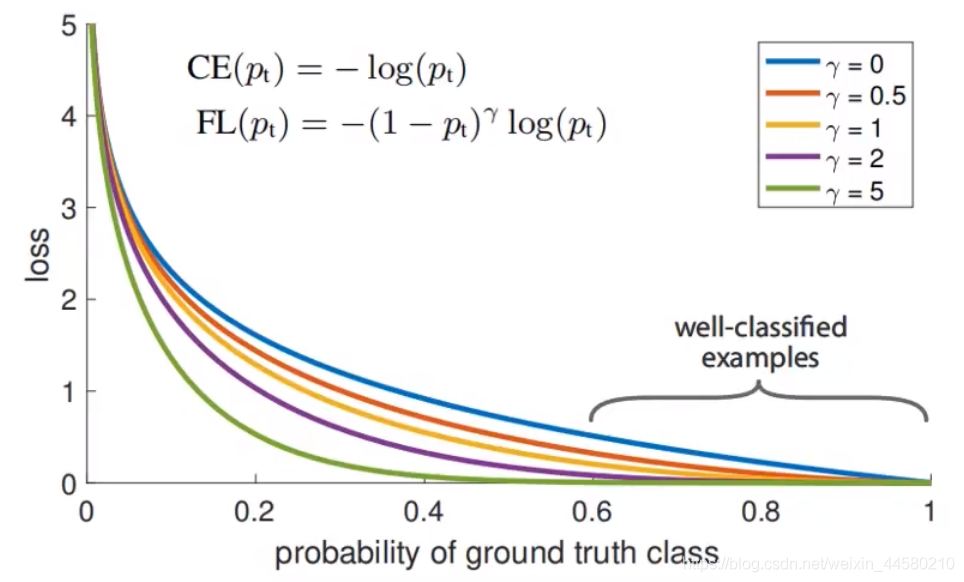 從上圖可以看出來,當
γ
\gamma
γ不等于零時,概率為0.6-1的這些高概率類別獲得的損失相應減小,這樣網路就可以將更多的資源應用到區分難以區分的類別上,以上大概就是Focal Loss的基本思想,
從上圖可以看出來,當
γ
\gamma
γ不等于零時,概率為0.6-1的這些高概率類別獲得的損失相應減小,這樣網路就可以將更多的資源應用到區分難以區分的類別上,以上大概就是Focal Loss的基本思想,
如上就完成了計算機網路中目標檢測網路的流水賬式的學習,再一次感謝Up主霹靂吧啦Wz,以上論文并沒有時間去仔細閱讀論文,僅僅是根據霹靂吧啦Wz的學習視頻過了一遍,以后有用到的時候再去仔細研究,如果文章中有理解不對之處還請大家多多指出,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/287833.html
標籤:其他
上一篇:YOLO v2實作影像目標檢測