友情提示:先關注收藏,再查看,13 萬字保姆級 C 語言從入門到精通教程,
文章目錄
- 計算機常識
- 什么是計算機程式 ?
- 什么是計算機語言 ?
- 常見的計算機語言型別有哪些 ?
- 什么是C語言?
- C語言歷史
- C語言標準
- C語言現狀
- 為什么要學習C語言?
- 如何學好C語言
- 工欲善其事必先利其器
- 撰寫C語言程式用什么工具 ?
- 什么是Qt Creator ?
- Qt Creator安裝
- 什么是環境變數?
- 為什么要配置系統變數,不配置用戶變數
- Qt Creator快捷鍵
- 如何創建C語言程式
- 如何創建C語言檔案
- C語言程式組成
- 函式定義格式
- 如何執行定義好的函式
- 如何運行撰寫好的程式
- main函式注意點及其它寫法
- C語言程式練習
- 初學者如何避免程式出現BUG
- 多語言對比
- 什么是注釋?
- 為什么要使用注釋?
- 注釋的分類
- 注釋的注意點
- 注釋的應用場景
- 使用注釋的好處
- 什么是關鍵字?
- 關鍵字分類
- 什么是識別符號?
- 識別符號命名規則
- 練習
- 識別符號命名規范
- 什么是資料?
- 資料分類
- C語言資料型別
- 什么是常量?
- 常量的型別
- 什么是變數?
- 如何定義變數
- 如何使用變數?
- 變數的初始化
- 如何修改變數值?
- 變數之間的值傳遞
- 如何查看變數的值?
- 變數的作用域
- 變數記憶體分析(簡單版)
- printf函式
- Scanf函式
- scanf運行原理
- putchar和getchar
- 運算子基本概念
- 運算子分類
- 運算子的優先級和結合性
- 算數運算子
- 賦值運算子
- 自增自減運算子
- sizeof運算子
- 逗號運算子
- 關系運算子
- 邏輯運算子
- 三目運算子
- 型別轉換
- 階段練習
- 流程控制基本概念
- 選擇結構
- 選擇結構switch
- 回圈結構
- 回圈結構while
- 回圈結構do while
- 回圈結構for
- 四大跳轉
- 回圈的嵌套
- 圖形列印
- 函式基本概念
- 函式的分類
- 函式的定義
- 函式的引數和回傳值
- 函式的宣告
- main函式分析
- 遞回函式(了解)
- 進制基本概念
- 進制轉換
- 十進制小數轉換為二進制小數
- 二進制小數轉換為十進制小數
- 原碼反碼補碼
- 位運算子
- 變數記憶體分析
- char型別記憶體存盤細節
- 型別說明符
- short和long
- signed和unsigned
- 陣列的基本概念
- 定義陣列
- 初始化陣列
- 陣列的使用
- 陣列的遍歷
- 陣列長度計算方法
- 練習
- 陣列內部存盤細節
- 陣列的越界問題
- 陣列注意事項
- 陣列和函式
- 陣列元素作為函式引數
- 陣列名作為函式引數
- 陣列名作函式引數的注意點
- 計數排序(Counting Sort)
- 選擇排序
- 冒泡排序
- 插入排序
- 希爾排序
- 折半查找
- 進制轉換(查表法)
- 二維陣列
- 二維陣列的定義
- 二維陣列的初始化
- 二維陣列的應用場景
- 二維陣列的遍歷和存盤
- 二維陣列的遍歷
- 二維陣列的存盤
- 二維陣列與函式
- 二維陣列作為函式引數注意點
- 作業
- 字串的基本概念
- 字串的初始化
- 字串輸出
- 字串常用方法
- 練習
- 字串陣列基本概念
- 指標基本概念
- 什么是指標
- 什么是指標變數
- 定義指標變數的格式
- 指標變數的初始化方法
- 訪問指標所指向的存盤空間
- 指標型別
- 二級指標
- 練習
- 指標訪問陣列元素
- 指標與字串
- 指向函式指標
- 什么是結構體
- 定義結構體型別
- 定義結構體變數
- 結構體成員訪問
- 結構體變數的初始化
- 結構體型別作用域
- 結構體陣列
- 結構體指標
- 結構體記憶體分析
- 結構體變數占用存盤空間大小
- 結構體嵌套定義
- 結構體和函式
- 共用體
- 列舉
- 全域變數和區域變數
- auto和register關鍵字
- static關鍵字
- extern關鍵字
- static與extern對函式的作用
- Qt Creator編譯程序做了什么?
- 計算機是運算程序分析
- 預處理指令
- 預處理指令的概念
- 宏定義
- 帶引數的宏定義
- 條件編譯
- typedef關鍵字
- 宏定義與函式以及typedef區別
- const關鍵字
- 如何使用const?
- 記憶體管理
- 行程空間
- 堆疊記憶體(Stack)
- 堆記憶體(Heap)
- malloc函式
- free函式
- calloc函式
- realloc函式
- 鏈表
- 靜態鏈表
- 動態鏈表
- 動態鏈表頭插法
- 動態鏈表尾插法
- 動態鏈優化
- 鏈表銷毀
- 鏈表長度計算
- 鏈表查找
- 鏈表洗掉
- 作業
- 檔案基本概念
- 檔案的打開和關閉
- 一次讀寫一個字符
- 一次讀寫一行字符
- 一次讀寫一塊資料
- 讀寫結構體
- 其它檔案操作函式
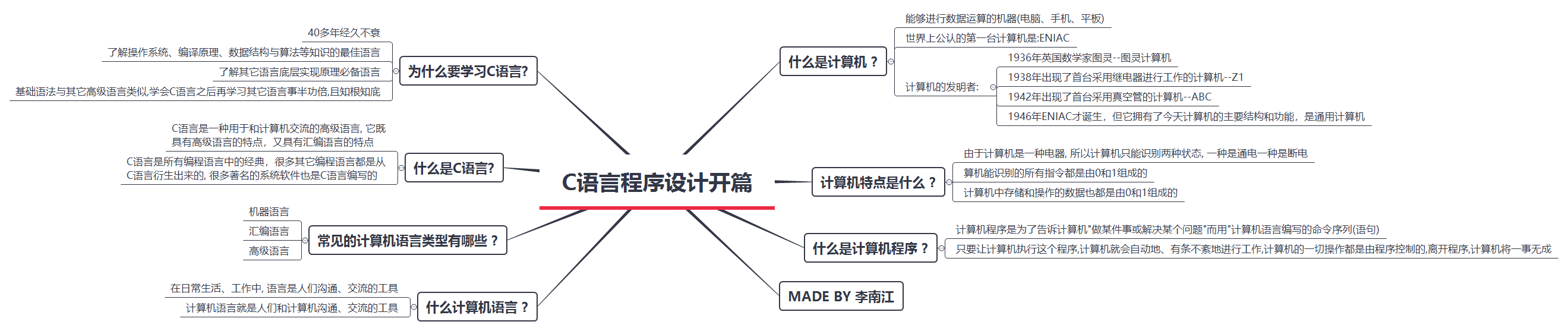
計算機常識
-
什么是計算機 ?
- 顧名思義,就是能夠進行資料運算的機器(臺式電腦、筆記本電腦、平板電腦、智能手機)
- 計算機_百度百科
-
計算機的發明者是誰 ?
- 關于電子計算機的發明者是誰這一問題,有好幾種答案:
- 1936年***英國數學家圖靈***首先提出了一種以程式和輸入資料相互作用產生輸出的計算機***構想***,后人將這種機器命名為通用圖靈計算機
- 1938年***克蘭德·楚澤***發明了首臺采用***繼電器***進行作業的計算機,這臺計算機命名為***Z1***,但是繼電器是機械式的,并不是完全的電子器材
- 1942年***阿坦那索夫和貝利***發明了首臺采用***真空管***的計算機,這臺計算機命名為***ABC***
- 1946年ENIAC誕生,它擁有了今天計算機的主要結構和功能,是通用計算機
- 關于電子計算機的發明者是誰這一問題,有好幾種答案:
- 現在世界上***公認***的第一臺現代電子計算機是1946年在美國賓夕法尼亞大學誕生的ENIAC(Electronic Numerical Integrator And Calculator)
- 計算機特點是什么 ?
-
計算機是一種電器, 所以計算機只能識別兩種狀態, 一種是通電一種是斷電
-
正是因為如此, 最初ENIAC的程式是由很多開關和連接電線來完成的,但是這樣導致***改動一次程式要花很長時間***(需要人工重新設定很多開關的狀態和連接線)
-

-
為了提高效率,工程師們想能不能把程式和資料都放在存盤器中, 數學家馮·諾依曼將這個思想以數學語言系統闡述,提出了存盤程式計算機模型(這是所謂的馮·諾依曼機)
-
那利用數學語言如何表示計算機能夠識別的通電和斷電兩種狀態呢?
- 非常簡單用0和1表示即可
- 所以計算機能識別的所有指令都是由0和1組成的
- 所以計算機中存盤和操作的資料也都是由0和1組成的
-
0和1更準確的是應該是高電平和低電平, 但是這個不用了解, 只需要知道計算機只能識別0和1以及存盤的資料都是由0和1組成的即可,
什么是計算機程式 ?
-
計算機程式是為了告訴計算機"做某件事或解決某個問題"而用"***計算機語言***撰寫的命令集合(陳述句)
-
只要讓計算機執行這個程式,計算機就會自動地、有條不紊地進行作業,計算機的一切操作都是由程式控制的,離開程式,計算機將一事無成
-
現實生活中你如何告訴別人如何做某件事或者解決某個問題?
- 通過人能聽懂的語言: 張三你去樓下幫我買一包煙, 然后順便到快遞箱把我的快遞也帶上來
- 其實我們通過人能聽懂的語言告訴別人做某件事就是在發送一條條的指令
- 計算機中也一樣, 我們可以通過計算機語言告訴計算機我們想做什么, 每做一件事情就是一條指令, 一潭訓多條指令的集合我們就稱之為一個計算機程式
什么是計算機語言 ?
- 在日常生活、作業中, 語言是人們交流的工具
- 中國人和中國人交流,使用中文語言
- 美國人和美國人交流,使用英文語言
- 人想要和計算機交流,使用計算機語言
- 可以看出在日常生活、作業中,人們使用的語言種類很多
- 如果一個很牛人可能同時掌握了中文語言和英文語言, 那么想要和這個人交流既可以使用中文語言,也可以使用英文語言
- 計算機其實就是一個很牛的人, 計算機同時掌握了幾十門甚至上百門語言, 所以我們只要使用任何一種計算機已經掌握的語言就可以和計算機交流
常見的計算機語言型別有哪些 ?
- 機器語言
- 所有的代碼里面只有0和1, 0表示不加電,1表示加電(紙帶存盤時 1有孔,0沒孔)
- 優點:直接對硬體產生作用,程式的執行效率非常非常高
- 缺點:指令又多又難記、可讀性差、無可移植性
- 匯編語言
- 符號化的機器語言,用一個符號(英文單詞、數字)來代表一潭訓器指令
- 優點:直接對硬體產生作用,程式的執行效率非常高、可讀性稍好
- 缺點:符號非常多和難記、無可移植性
- 高級語言
- 非常接近自然語言的高級語言,語法和結構類似于普通英文
- 優點:簡單、易用、易于理解、遠離對硬體的直接操作、有可移植性
- 缺點:有些高級語言寫出的程式執行效率并不高
- 對比(利用3種型別語言撰寫1+1)
- 機器語言
10111000 00000001 00000000 00000101 00000001 00000000
- 匯編語言
MOV AX, 1 ADD AX, 1
- 高級語言
1 + 1
- 機器語言
什么是C語言?
- C語言是一種用于和計算機交流的高級語言, 它既具有高級語言的特點,又具有匯編語言的特點
- 非常接近自然語言
- 程式的執行效率非常高
- C語言是所有編程語言中的經典,很多高級語言都是從C語言中衍生出來的,
- 例如:C++、C#、Object-C、Java、Go等等
- C語言是所有編程語言中的經典,很多著名的系統軟體也是C語言撰寫的
- 幾乎所有的作業系統都是用C語言撰寫的
- 幾乎所有的計算機底層軟體都是用C語言撰寫的
- 幾乎所有的編輯器都是C語言撰寫的
C語言歷史
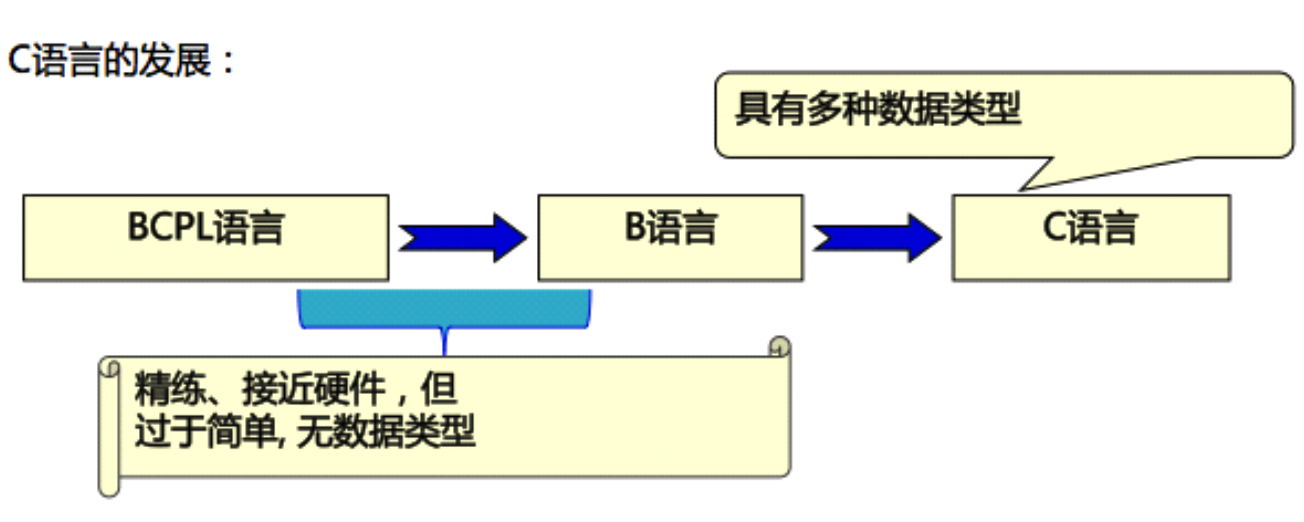
- 最早的高級語言:FORTRAN–>ALGOL–>CPL–>BCPL–>C–>C++等
“初,世間無語言,僅電路與連線,及大牛出,天地開,始有 FORTRAN、 LISP、ALGOL 隨之, 乃有萬種語”
- 1963年英國劍橋大學推出了CPL(Combined Programming Langurage)語言, CPL語言在ALGOL 60的基礎上接近硬體一些,但規模比較大,難以實作
- 1967年英國劍橋大學的 Matin Richards(理查茲)對CPL語言做了簡化,推出了 BCPL (Base Combined Programming Langurage)語言
- 1970年美國貝爾實驗室的 Ken Thompson(肯·湯普遜) 以 BCPL 語言為基礎,又作了進一步的簡化,設計出了很簡單的而且很接近硬體的 B 語言(取BCPL的第一個字母),并用B語言寫出了第一個 UNIX 作業系統,但B語言過于簡單,功能有限
- 1972年至1973年間,貝爾實驗室的 Dennis.Ritchie(丹尼斯·里奇) 在 B語言的基礎上設計出了C語言(取BCPL的第二個字母),C語言即保持 BCPL 語言和B語言的優點(精練、接近硬體),又克服了他們的缺點(過于簡單,資料無型別等)

C語言標準
- 1983年美國國家標準局(American National Standards Institute,簡稱ANSI)成立了一個委員會,開始制定C語言標準的作業
- 1989年C語言標準被批準,這個版本的C語言標準通常被稱為ANSI C(C89)
- 1999年,國際標準化組織ISO又對C語言標準進行修訂,在基本保留原C語言特征的基礎上,針對應該的需要,增加了一些功能,命名為***C99***
- 2011年12月,ANSI采納了ISO/IEC 9899:2011標準,這個標準通常即***C11,它是C程式語言的現行標準***
C語言現狀
- 年度編程語言
- 該獎項頒發給了一年中最熱門的編程語言
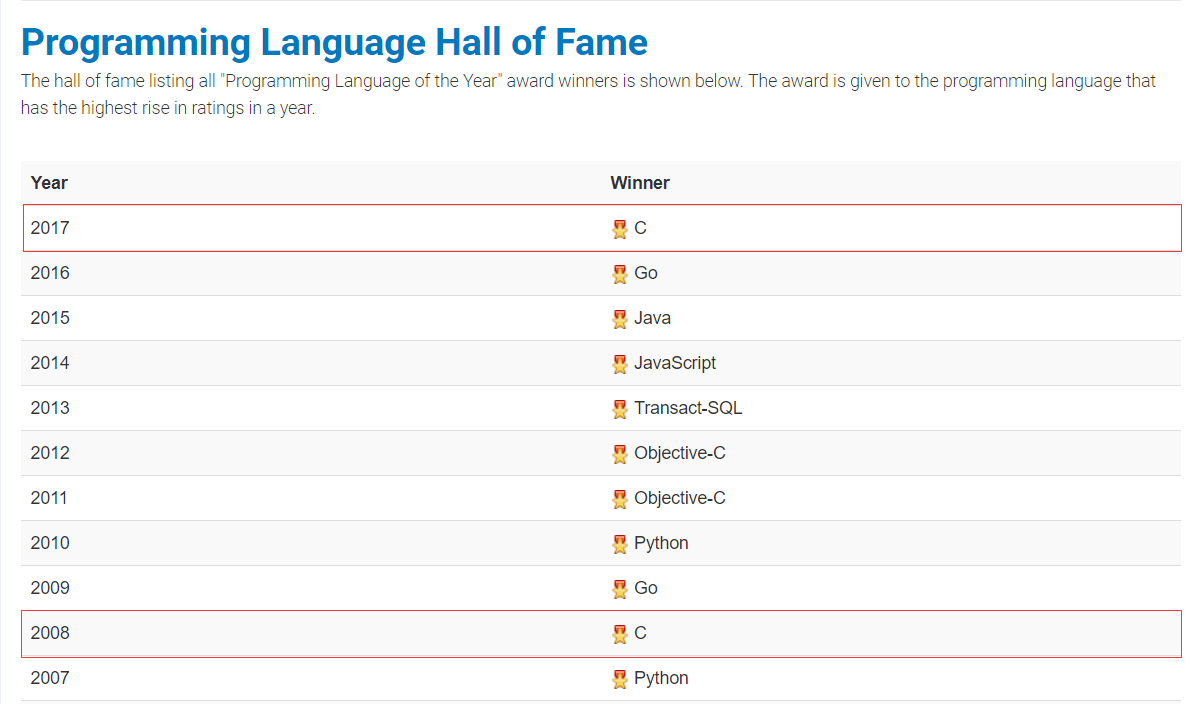
- 該獎項頒發給了一年中最熱門的編程語言
- 編程語言排行榜查看
為什么要學習C語言?
- 40多年經久不衰
- 了解作業系統、編譯原理、資料結構與演算法等知識的最佳語言
- 了解其它語言底層實作原理必備語言
- 基礎語法與其它高級語言類似,學會C語言之后再學習其它語言事半功倍,且知根知底
當你想了解底層原理時,你才會發現后悔當初沒有學習C語言
當你想學習一門新的語言時, 你才會發現后悔當初沒有學習C語言
當你使用一些高級框架、甚至系統框架時發現提供的API都是C語言撰寫的, 你才發現后悔當初沒有學習C語言
學好數理化,走遍天下都不拍
學好C語言,再多語言都不怕
如何學好C語言
| 學習本套課程之前 | 學習本套課程中 | 學習本套課程之后 |
|---|---|---|
 |  | [外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-gHyaoC72-1623039894713)(https://upload-images.jianshu.io/upload_images/647982-c724f6cd01191121.png?imageMogr2/auto-orient/strip)] |
- 如何達到這樣的效果

工欲善其事必先利其器
撰寫C語言程式用什么工具 ?
- 記事本(開發效率低)
- Vim(初學者入門門檻高)
- VSCode(不喜歡)
- eclipse(不喜歡)
- CLion(深愛, 但收費)
- Xcode(逼格高, 但得有蘋果電腦)
- Qt Creator(開源免費,跨平臺安裝和運行)
什么是Qt Creator ?
- Qt Creator 是一款新的輕量級集成開發環境(IDE),它能夠跨平臺運行,支持的系統包括 Windows、Linux(32 位及 64 位)以及 Mac OS X
- Qt Creator 的設計目標是使開發人員能夠利用 Qt 這個應用程式框架更加快速及輕易的完成開發任務
- 開源免費, 簡單易用, 能夠滿足學習需求
集成開發環境(IDE,Integrated Development Environment )是用于提供程式開發環境的應用程式,一般包括代碼編輯器、編譯器、除錯器和圖形用戶界面等工具,集成了代碼撰寫功能、分析功能、編譯功能、除錯功能等一體化的開發軟體服務套,
Qt Creator安裝
-
切記囫圇吞棗, 不要糾結里面的東西都是什么含義, 初學者安裝成功就是一種成功
-
下載Qt Creator離線安裝包:
- http://download.qt.io/archive/qt/
- 極速下載地址:
- 鏈接:https://pan.baidu.com/s/1gx0hNDBJkA2gx5wF1Jx34w
提取碼:0fg9
-
以管理身份運行離線安裝包
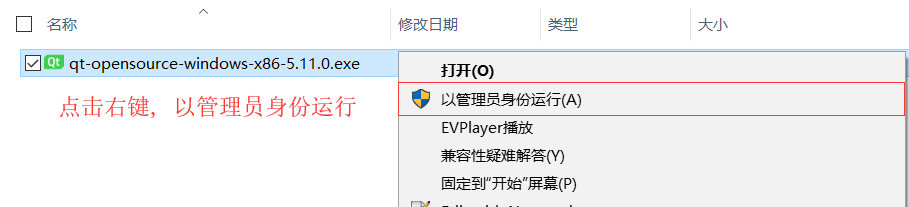
-
下一步,下一步,下一步,等待ing…

+
+
-
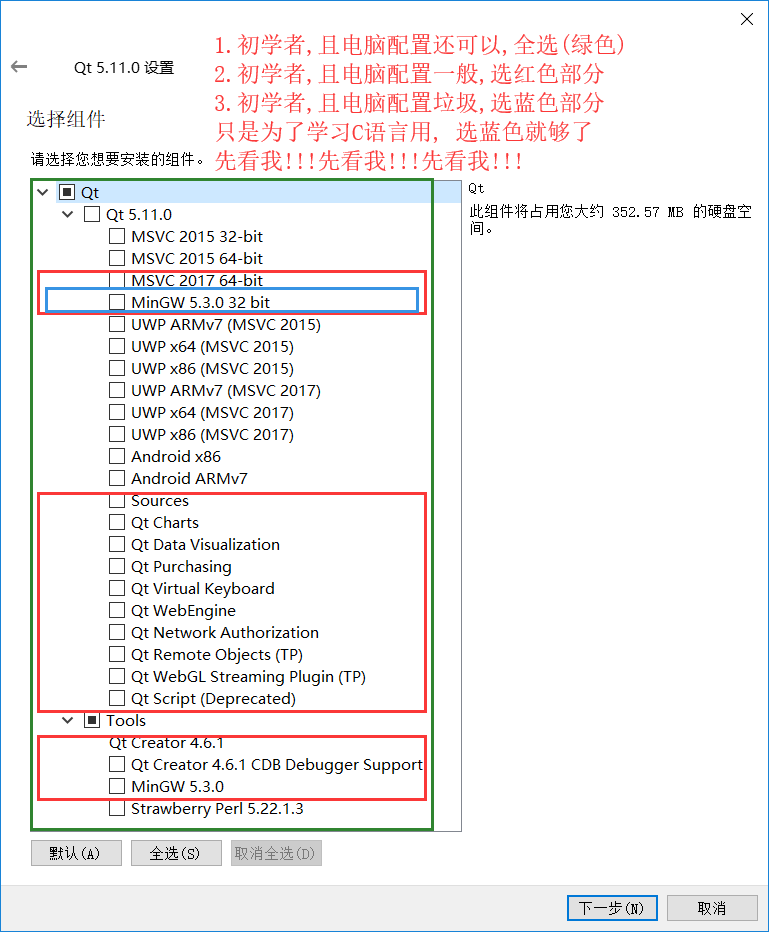
注意安裝路徑中最好不要出現中文
-
對于初學者而言全選是最簡單的方式(重點!!!)
-
配置Qt Creator開發環境變數
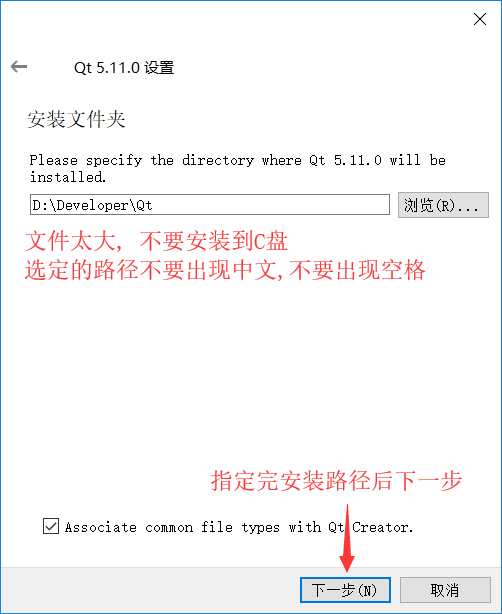


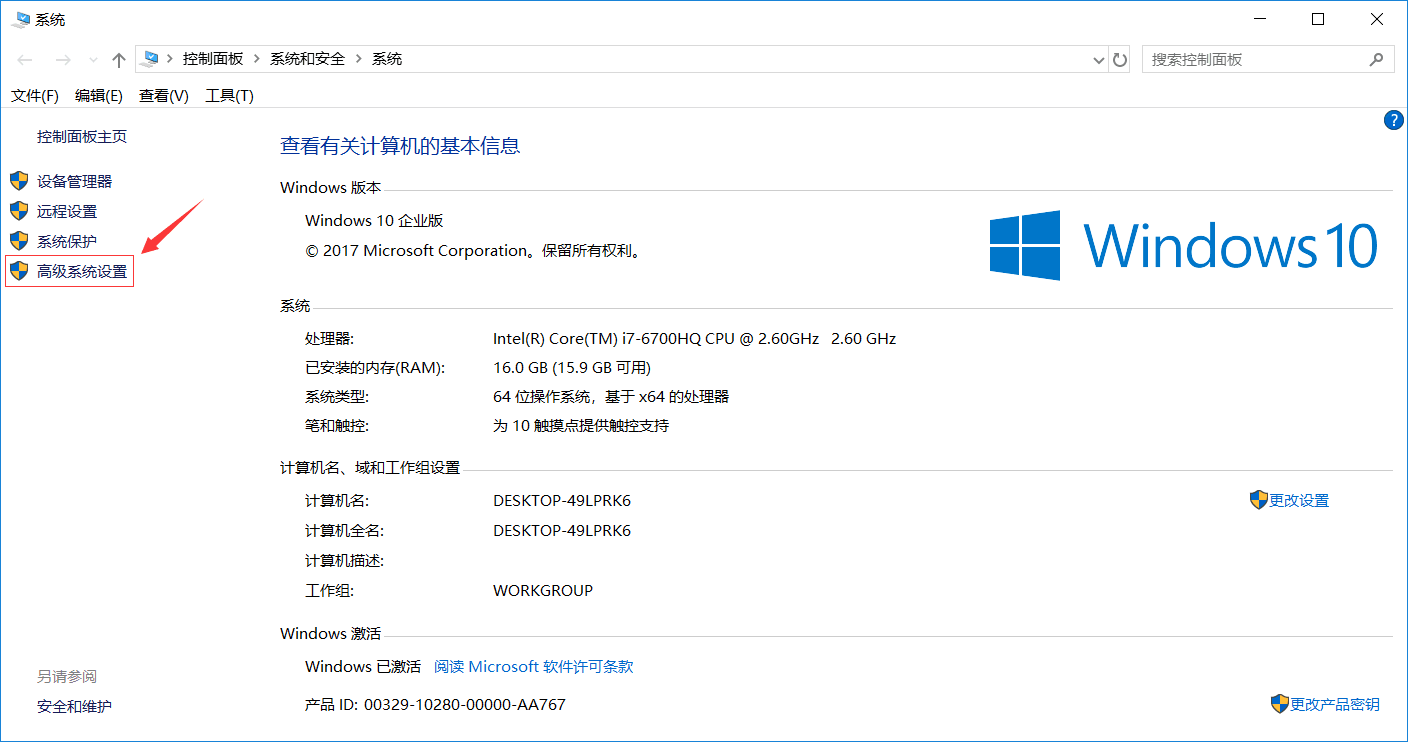
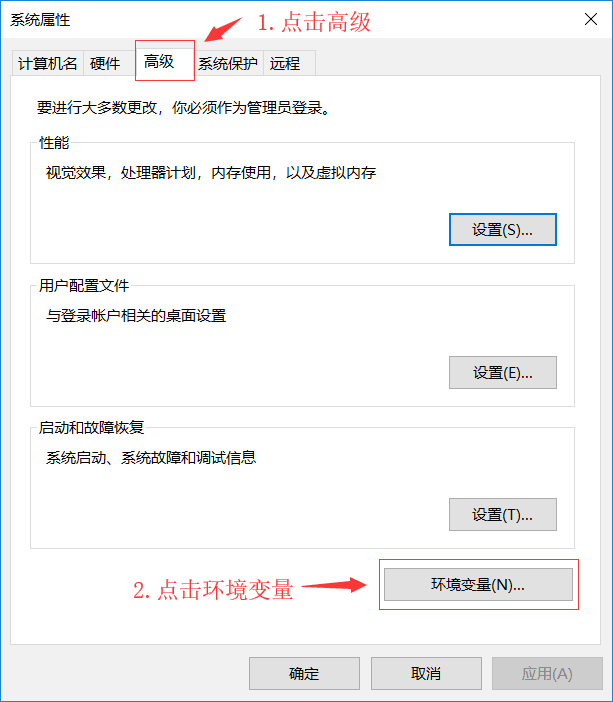
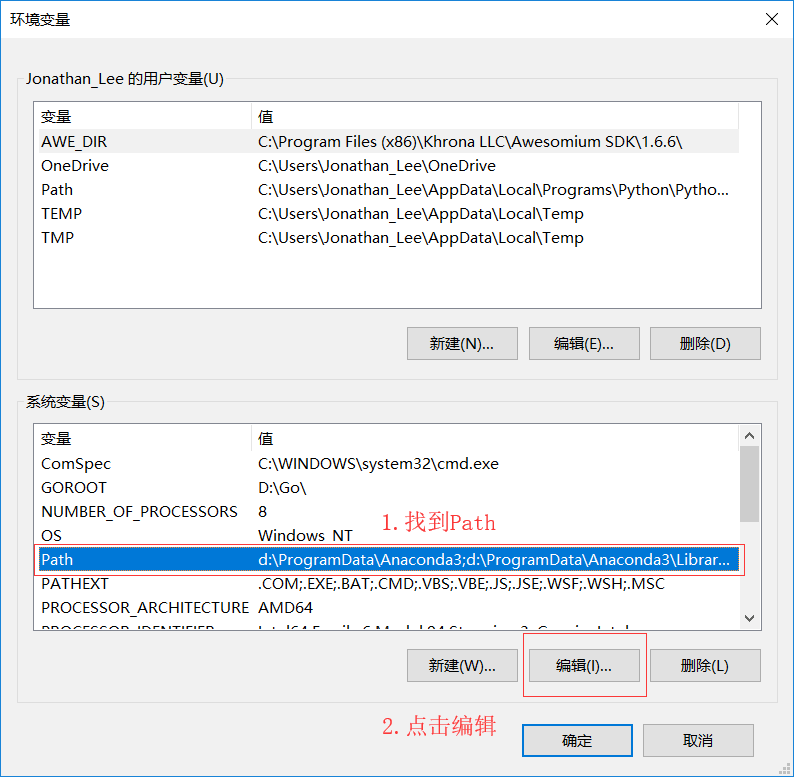
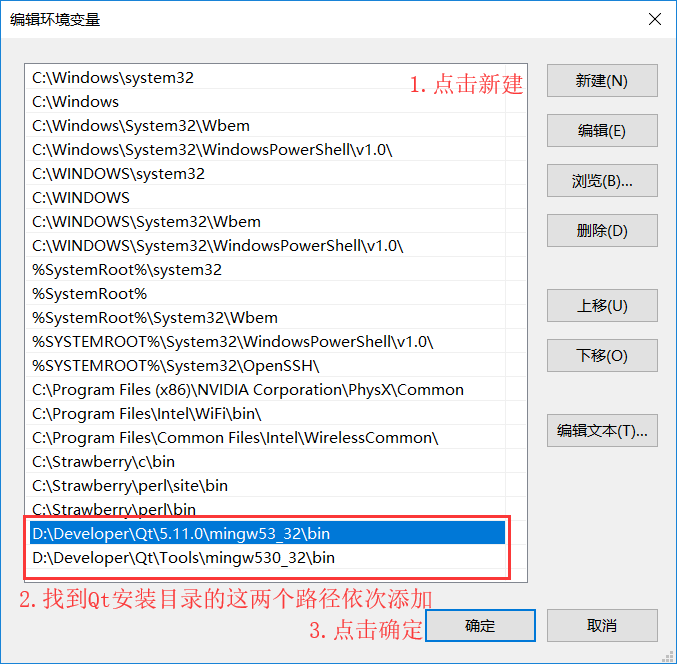
你的安裝路徑\5.11.0\mingw53_32\bin
你的安裝路徑\Tools\mingw530_32\bin
- 啟動安裝好的Qt Creator
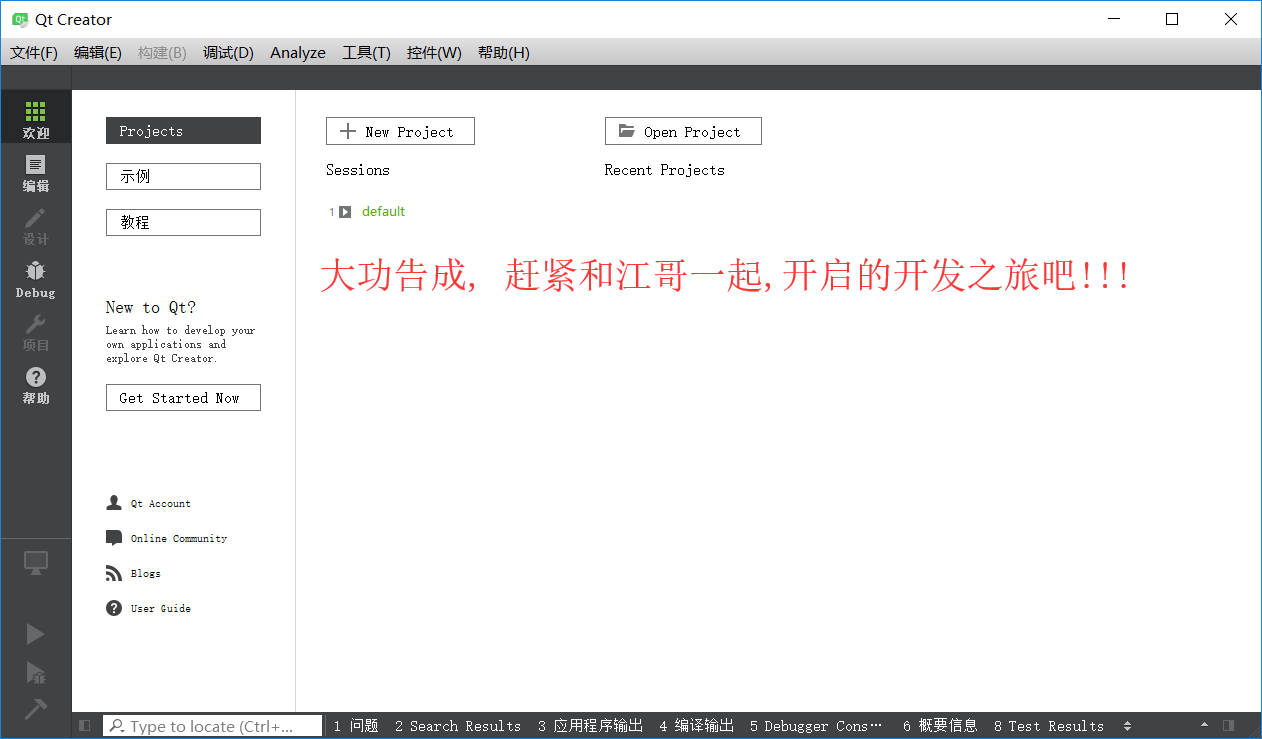
- 非全選安裝到此為止, 全選安裝繼續往下看
- 出現這個錯誤, 忽略這個錯誤即可
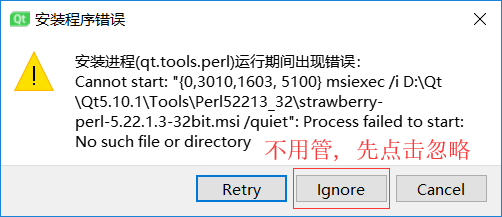
- 等待安裝完畢之后解決剛才的錯誤
- 找到安裝目錄下的strawberry.msi,雙擊運行
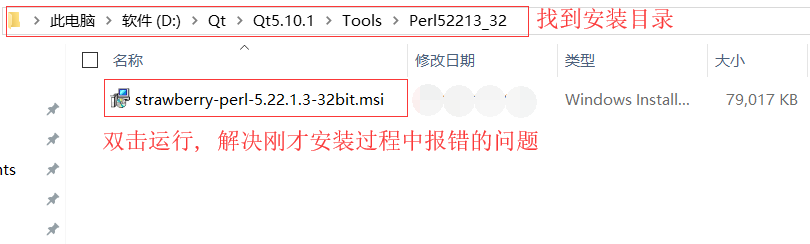
- 找到安裝目錄下的strawberry.msi,雙擊運行
什么是環境變數?
- 打開我們添加環境變數的兩個目錄, 不難發現里面大部分都是.exe的可執行程式
- 如果我們不配置環境變數, 那么每次我們想要使用這些"可執行程式"都必須"先找到這些應用程式對應的檔案夾"才能使用
- 為了方便我們在電腦上"任何地方"都能夠使用這些"可執行程式", 那么我們就必須添加環境變數, 因為Windows執行某個程式的時候, 會先到"環境變數中Path指定的路徑中"去查找
為什么要配置系統變數,不配置用戶變數
- 用戶變數只針對使用這臺計算機指定用戶
- 一個計算機可以設定多個用戶, 不同的用戶用不同的用戶名和密碼
- 當給計算機設定了多個用戶的時候,啟動計算機的時候就會讓你選擇哪個用戶登錄
- 系統變數針對使用這臺計算機的所有用戶
- 也就是說設定了系統變數, 無論哪個用戶登錄這臺計算機都可以使用你配置好的工具
Qt Creator快捷鍵
- Qt Creator Keyboard Shortcuts(Documentation)
- Qt Creator Keyboard Shortcuts(Wiki)
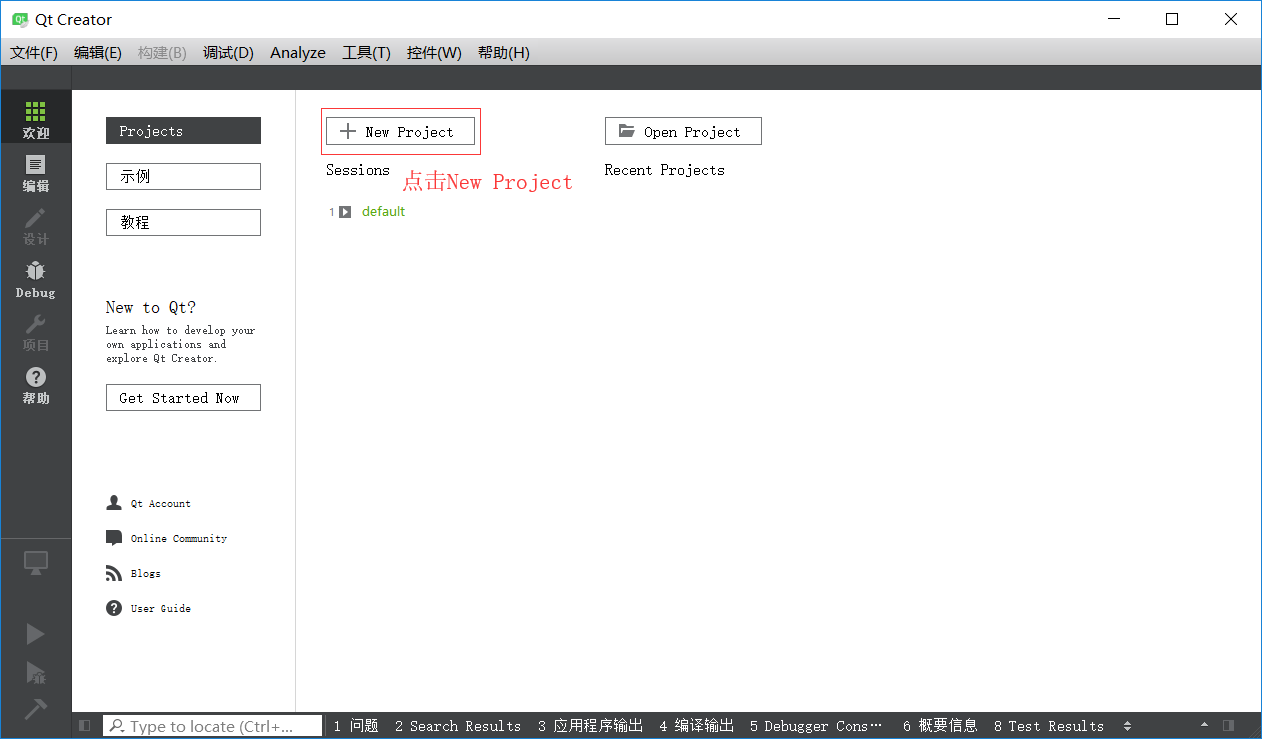
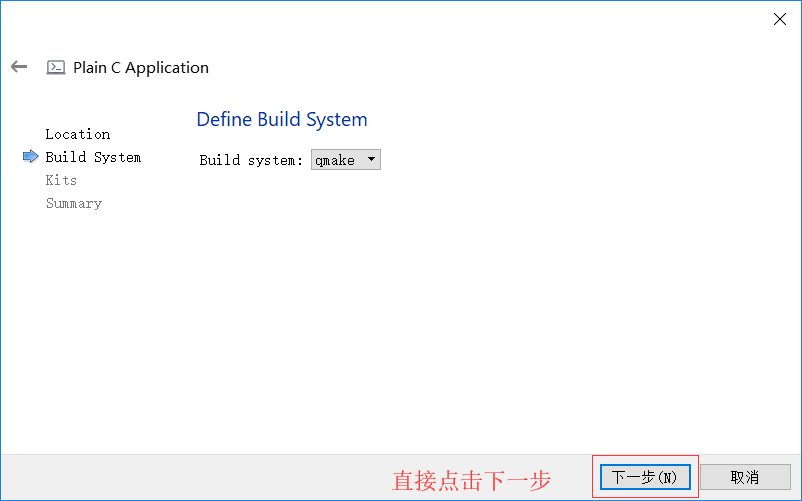
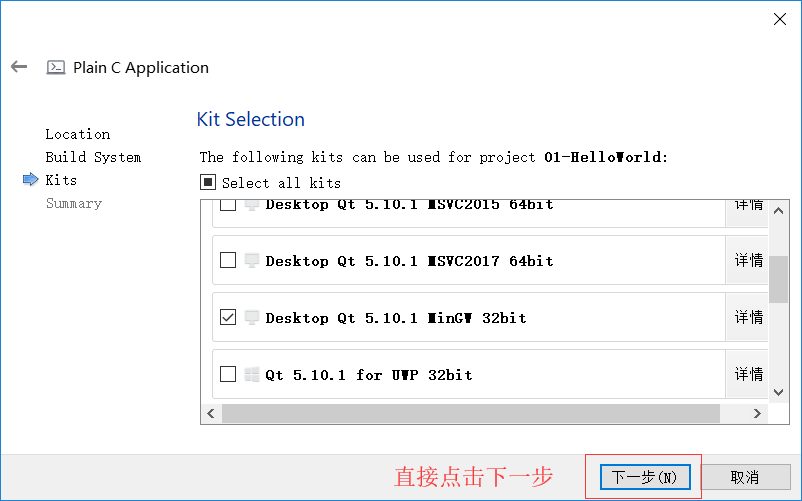
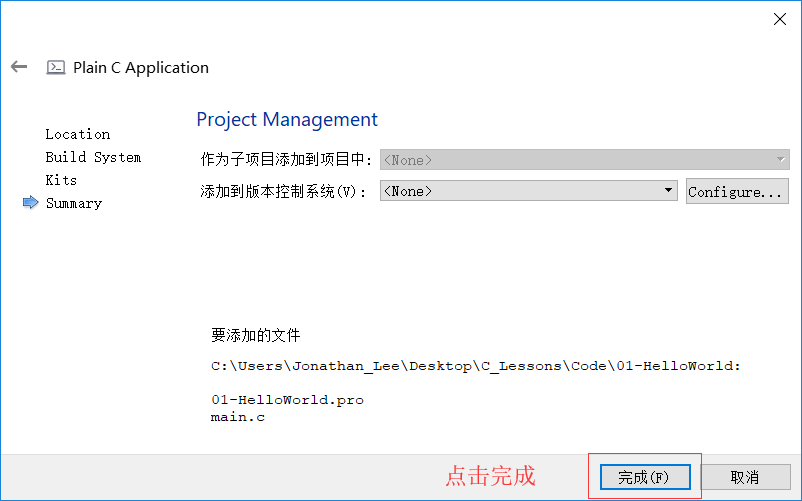
如何創建C語言程式
- 這個世界上, 幾乎所有程式員入門的第一段代碼都是Hello World.
- 原因是當年C語言的作者Dennis Ritchie(丹尼斯 里奇)在他的名著中第一次引入, 傳為后世經典, 其它語言亦爭相效仿, 以示敬意
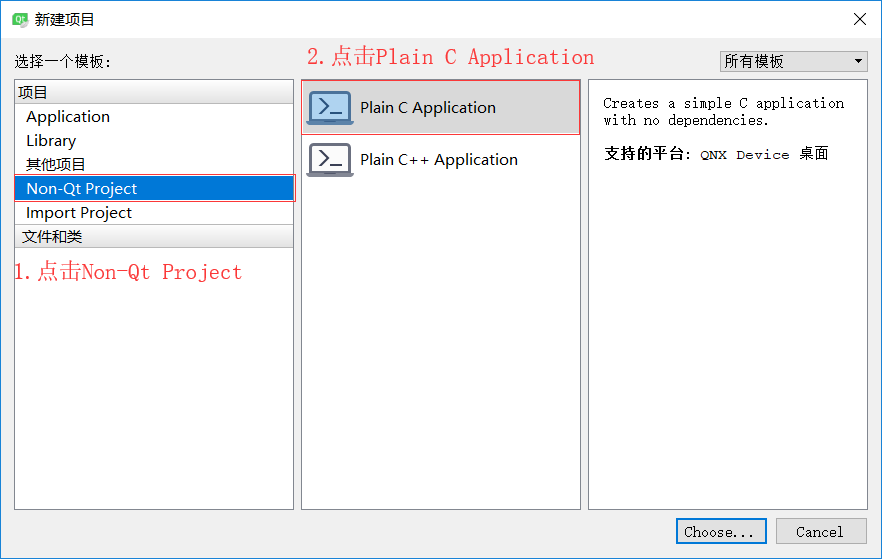
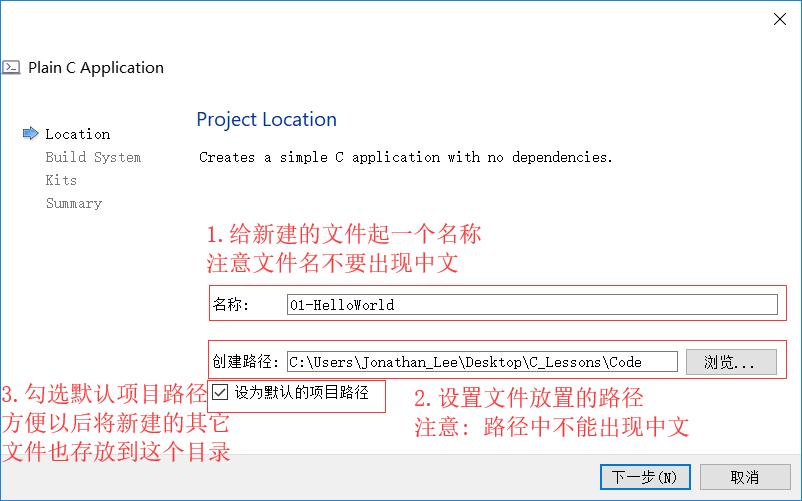
如何創建C語言檔案
C語言程式組成
-
手機有很多功能, “開機”,“關機”,“打電話”,“發短信”,"拍照"等等
-
手機中的每一個功能就相當于C語言程式中的一個程式段(函式)
-
眾多功能中總有一個會被先執行,不可能多個功能一起執行
-
想使用手機必須先執行手機的開機功能
-
所以C語言程式也一樣,由眾多功能、眾多程式段組成, 眾多C語言程式段中總有一個會被先執行, 這個先執行的程式段我們稱之為"主函式"

-
一個C語言程式由多個"函式"構成,每個函式有自己的功能
-
一個程式***有且只有一個主函式***
-
如果一個程式沒有主函式,則這個程式不具備運行能力
-
程式運行時系統會***自動呼叫***主函式,而其它函式需要開發者***手動呼叫***
-
主函式有固定書寫的格式和范寫

函式定義格式
- 主函式定義的格式:
- int 代表函式執行之后會回傳一個整數型別的值
- main 代表這個函式的名字叫做main
- () 代表這是一個函式
- {} 代表這個程式段的范圍
- return 0; 代表函式執行完之后回傳整數0
int main() {
// insert code here...
return 0;
}
- 其它函式定義的格式
- int 代表函式執行之后會回傳一個整數型別的值
- call 代表這個函式的名字叫做call
- () 代表這是一個函式
- {} 代表這個程式段的范圍
- return 0; 代表函式執行完之后回傳整數0
int call() {
return 0;
}
如何執行定義好的函式
- 主函式(main)會由系統自動呼叫, 但其它函式不會, 所以想要執行其它函式就必須在main函式中手動呼叫
- call 代表找到名稱叫做call的某個東西
- () 代表要找到的名稱叫call的某個東西是一個函式
- ; 代表呼叫函式的陳述句已經撰寫完成
- 所以call();代表找到call函式, 并執行call函式
int main() {
call();
return 0;
}
- 如何往螢屏上輸出內容
- 輸出內容是一個比較復雜的操作, 所以系統提前定義好了一個專門用于輸出內容的函式叫做printf函式,我們只需要執行系統定義好的printf函式就可以往螢屏上輸出內容
- 但凡需要執行一個函式, 都是通過函式名稱+圓括號的形式來執行
- 如下代碼的含義是: 當程式運行時系統會自動執行main函式, 在系統自動執行main函式時我們手動執行了call函式和printf函式
- 經過對代碼的觀察, 我們發現兩個問題
- 并沒有告訴printf函式,我們要往螢屏上輸出什么內容
- 找不到printf函式的實作代碼
int call(){
return 0;
}
int main(){
call();
printf();
return 0;
}
- 如何告訴printf函式要輸出的內容
- 將要輸出的內容撰寫到printf函式后面的圓括號中即可
- 注意: 圓括號中撰寫的內容必須用雙引號引起來
printf("hello world\n");
- 如何找到printf函式的實作代碼
- 由于printf函式是系統實作的函式, 所以想要使用printf函式必須在使用之前告訴系統去哪里可以找到printf函式的實作代碼
- #include <stdio.h> 就是告訴系統可以去stdio這個檔案中查找printf函式的宣告和實作
#include <stdio.h>
int call(){
return 0;
}
int main(){
call();
printf("hello world\n");
return 0;
}
如何運行撰寫好的程式
- 方式1:
- 點擊小榔頭將"源代碼"編譯成"可執行檔案"
- 找到編譯后的源代碼, 打開終端(CMD)運行可執行檔案
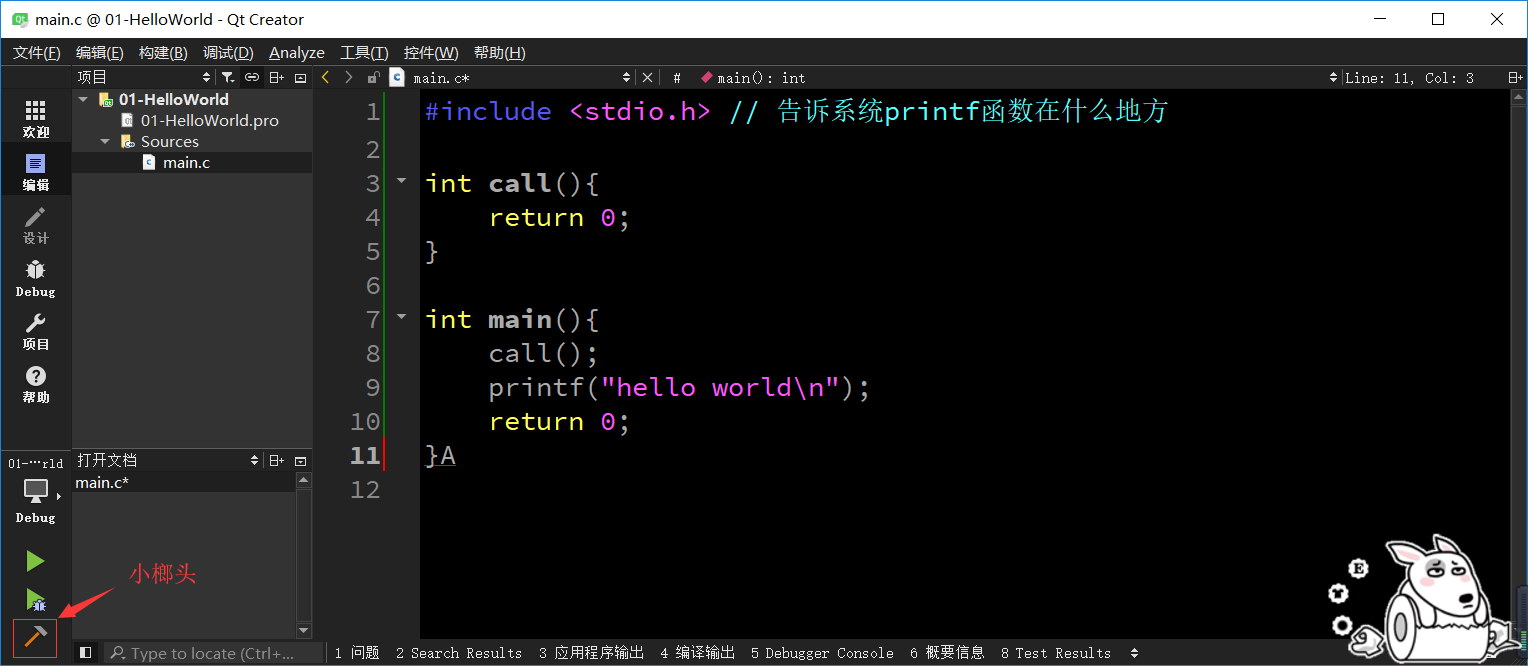
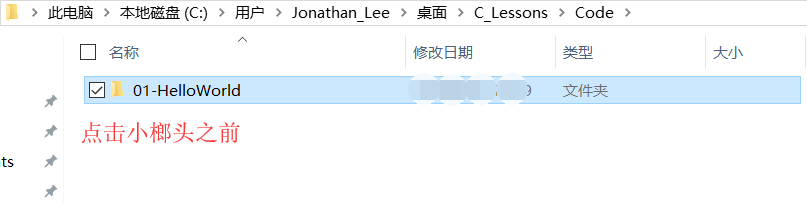
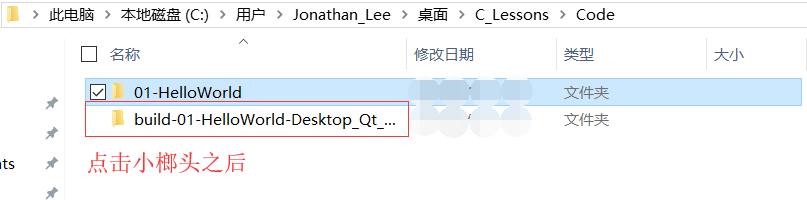
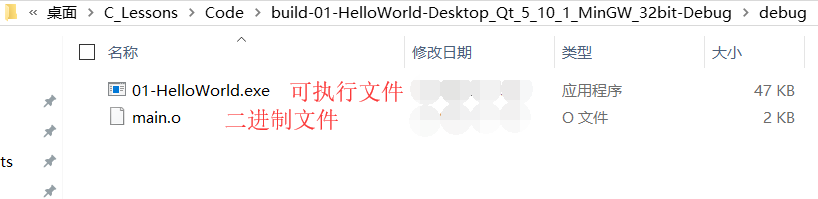

- 方式2
- 直接點擊Qt開發工具運行按鈕
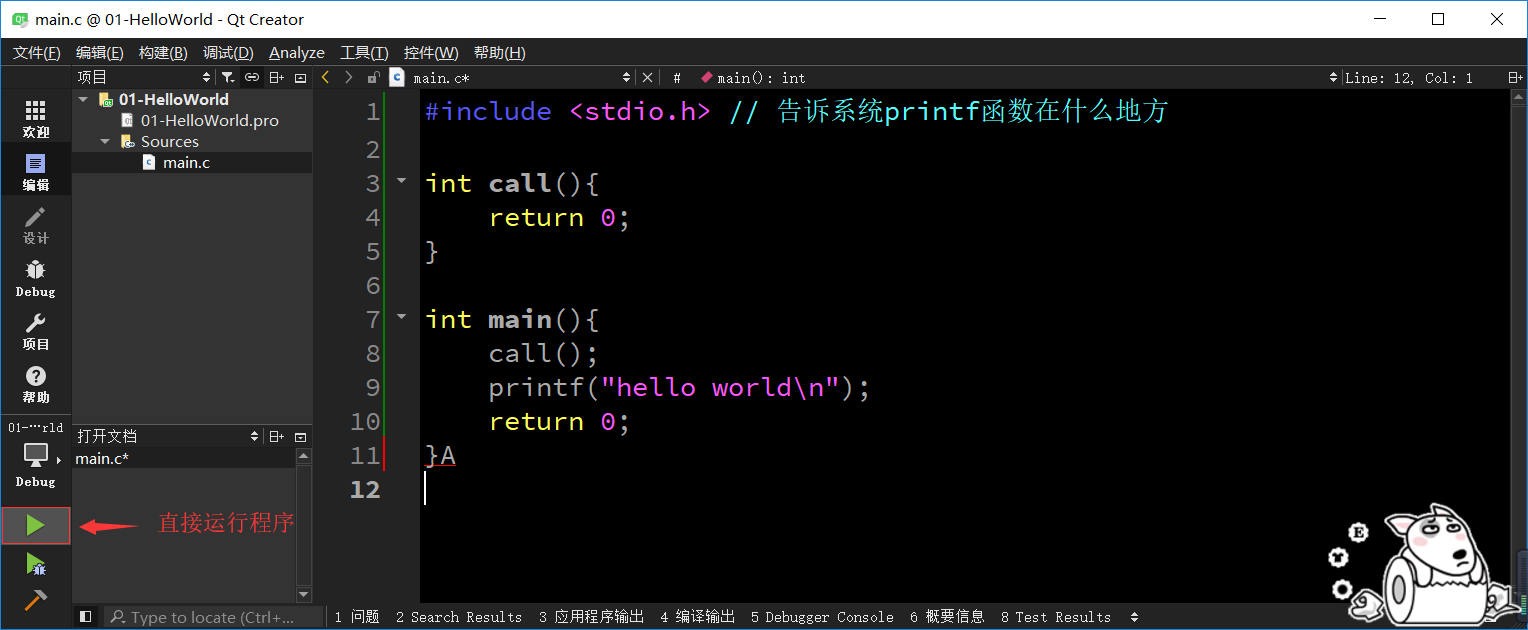

- 直接點擊Qt開發工具運行按鈕
main函式注意點及其它寫法
- C語言中,每條完整的陳述句后面都必須以分號結尾
int main(){
printf("hello world\n") // 如果沒有分號編譯時會報錯
return 0;
}
int main(){
// 如果沒有分號,多條陳述句合并到一行時, 系統不知道從什么地方到什么地方是一條完整陳述句
printf("hello world\n") return 0;
}
- C語言中除了注釋和雙引號引起來的地方以外都不能出現中文
int main(){
printf("hello world\n"); // 這里的分號如果是中文的分號就會報錯
return 0;
}
- 一個C語言程式只能有一個main函式
int main(){
return 0;
}
int main(){ // 編譯時會報錯, 重復定義
return 0;
}
- 一個C語言程式不能沒有main函式
int call(){ // 編譯時報錯, 因為只有call函式, 沒有main函式
return 0;
}
int mian(){ // 編譯時報錯, 因為main函式的名稱寫錯了,還是相當于沒有main函式
return 0;
}
- main函式前面的int可以不寫或者換成void
#include <stdio.h>
main(){ // 不會報錯
printf("hello world\n");
return 0;
}
#include <stdio.h>
void main(){ // 不會報錯
printf("hello world\n");
return 0;
}
- main函式中的return 0可以不寫
int main(){ // 不會報錯
printf("hello world\n");
}
- 多種寫法不報錯的原因
- C語言最早的時候只是一種規范和標準(例如C89, C11等)
- 標準的推行需要各大廠商的支持和實施
- 而在支持的實施的時候由于各大廠商利益、理解等問題,導致了實施的標準不同,發生了變化
- Turbo C
- Visual C(VC)
- GNU C(GCC)
- 所以大家才會看到不同的書上書寫的格式有所不同, 有的回傳int,有的回傳void,有的甚至沒有回傳值
- 所以大家只需要記住最標準的寫法即可, no zuo no die
#include <stdio.h>
int main(){
printf("hello world\n");
return 0;
}
Tips:
語法錯誤:編譯器會直接報錯
邏輯錯誤:沒有語法錯誤,只不過運行結果不正確
C語言程式練習
- 撰寫一個C語言程式,用至少2種方式在螢屏上輸出以下內容
*** ***
*********
*******
****
**
- 普通青年實作
printf(" *** *** \n");
printf("*********\n");
printf(" *******\n");
printf(" ****\n");
printf(" **\n");
- 2B青年實作
printf(" *** *** \n*********\n *******\n ****\n **\n");
- 文藝青年實作(裝逼的, 先不用理解)
int i = 0;
while (1) {
if (i % 2 == 0) {
printf(" *** *** \n");
printf("*********\n");
printf(" *******\n");
printf(" ****\n");
printf(" **\n");
}else
{
printf("\n");
printf(" ** ** \n");
printf(" *******\n");
printf(" *****\n");
printf(" **\n");
}
sleep(1);
i++;
system("cls");
}
初學者如何避免程式出現BUG
_ooOoo_
o8888888o
88" . "88
(| -_- |)
O\ = /O
____/`---'\____
. ' \\| |// `.
/ \\||| : |||// \
/ _||||| -:- |||||- \
| | \\\ - /// | |
| \_| ''\---/'' | |
\ .-\__ `-` ___/-. /
___`. .' /--.--\ `. . __
."" '< `.___\_<|>_/___.' >'"".
| | : `- \`.;`\ _ /`;.`/ - ` : | |
\ \ `-. \_ __\ /__ _/ .-` / /
======`-.____`-.___\_____/___.-`____.-'======
`=---='
.............................................
佛祖保佑 有無BUG
━━━━━━神獸出沒━━━━━━
┏┓ ┏┓
┏┛┻━━━━━━┛┻┓
┃ ┃
┃ ━ ┃
┃ ┳┛ ┗┳ ┃
┃ ┃
┃ ┻ ┃
┃ ┃
┗━┓ ┏━┛Code is far away from bug with the animal protecting
┃ ┃ 神獸保佑,代碼無bug
┃ ┃
┃ ┗━━━┓
┃ ┣┓
┃ ┏━━┛┛
┗┓┓┏━┳┓┏┛
┃┫┫ ┃┫┫
┗┻┛ ┗┻┛
━━━━━━感覺萌萌噠━━━━━━
′′′′′′′′██′′′′′′′
′′′′′′′████′′′′′′
′′′′′████████′′′′
′′`′███????███′′′′′
′′′███?●??●?██′′′
′′′███??????██′′′′′
′′′███????██′ 專案:第一個C語言程式
′′██████??███′′′′′ 語言: C語言
′██████????███′′ 編輯器: Qt Creator
██████??????███′′′′ 版本控制:git-github
′′▓▓▓▓▓▓▓▓▓▓▓▓▓?′′ 代碼風格:江哥style
′′????▓▓▓▓▓▓▓▓▓?′′′′′
′.???′′▓▓▓▓▓▓▓▓?′′′′′
′.??′′′′▓▓▓▓▓▓▓?
..??.′′′′▓▓▓▓▓▓▓?
′????????????
′′′′′′′′′███████′′′′′
′′′′′′′′████████′′′′′′′
′′′′′′′█████████′′′′′′
′′′′′′██████████′′′′ 大部分人都在關注你飛的高不高,卻沒人在乎你飛的累不累,這就是現實!
′′′′′′██████████′′′ 我從不相信夢想,我,只,相,信,自,己!
′′′′′′′█████████′′
′′′′′′′█████████′′′
′′′′′′′′████████′′′′′
________?????
_________????
_________????
________??_??
_______??__??
_____ ??___??
_____??___??
____??____??
___??_____??
███____ ??
████____███
█ _███_ _█_███
——————————————————————————女神保佑,代碼無bug——————————————————————
多語言對比
- C語言
#include<stdio.h>
int main() {
printf("南哥帶你裝B帶你飛");
return 0;
}
- C++語言
#include<iostream>
using namespace std;
int main() {
cout << "南哥帶你裝B帶你飛" << endl;
return 0;
}
- OC語言
#import <Foundation/Foundation.h>
int main() {
NSLog(@"南哥帶你裝B帶你飛");
return 0;
}
- Java語言
class Test
{
public static viod main()
{
system.out.println("南哥帶你裝B帶你飛");
}
}
- Go語言
package main
import "fmt" //引入fmt庫
func main() {
fmt.Println("南哥帶你裝B帶你飛")
}
什么是注釋?
- 注釋是在所有計算機語言中都非常重要的一個概念,從字面上看,就是注解、解釋的意思
- 注釋可以用來解釋某一段程式或者某一行代碼是什么意思,方便程式員之間的交流溝通
- 注釋可以是任何文字,也就是說可以寫中文
- 被注釋的內容在開發工具中會有特殊的顏色
為什么要使用注釋?
- 沒有撰寫任何注釋的程式
void printMap(char map[6][7] , int row, int col);
int main(int argc, const char * argv[])
{
char map[6][7] = {
{'#', '#', '#', '#', '#', '#', '#'},
{'#', ' ', ' ', ' ', '#' ,' ', ' '},
{'#', 'R', ' ', '#', '#', ' ', '#'},
{'#', ' ', ' ', ' ', '#', ' ', '#'},
{'#', '#', ' ', ' ', ' ', ' ', '#'},
{'#', '#', '#', '#', '#', '#', '#'}
};
int row = sizeof(map)/sizeof(map[0]);
int col = sizeof(map[0])/ sizeof(map[0][0]);
printMap(map, row, col);
int pRow = 2;
int pCol = 1;
int endRow = 1;
int endCol = 6;
while ('R' != map[endRow][endCol]) {
printf("親, 請輸入相應的操作\n");
printf("w(向上走) s(向下走) a(向左走) d(向右走)\n");
char run;
run = getchar();
switch (run) {
case 's':
if ('#' != map[pRow + 1][pCol]) {
map[pRow][pCol] = ' ';
pRow++;//3
map[pRow][pCol] = 'R';
}
break;
case 'w':
if ('#' != map[pRow - 1][pCol]) {
map[pRow][pCol] = ' ';
pRow--;
map[pRow][pCol] = 'R';
}
break;
case 'a':
if ('#' != map[pRow][pCol - 1]) {
map[pRow][pCol] = ' ';
pCol--;
map[pRow][pCol] = 'R';
}
break;
case 'd':
if ('#' != map[pRow][pCol + 1]) {
map[pRow][pCol] = ' ';
pCol++;
map[pRow][pCol] = 'R';
}
break;
}
printMap(map, row, col);
}
printf("你太牛X了\n");
printf("想挑戰自己,請購買完整版本\n");
return 0;
}
void printMap(char map[6][7] , int row, int col)
{
system("cls");
for (int i = 0; i < row; i++) {
for (int j = 0; j < col; j++) {
printf("%c", map[i][j]);
}
printf("\n");
}
}

- 撰寫了注釋的程式
/*
R代表一個人
#代表一堵墻
// 0123456
####### // 0
# # // 1
#R ## # // 2
# # # // 3
## # // 4
####### // 5
分析:
>1.保存地圖(二維陣列)
>2.輸出地圖
>3.操作R前進(控制小人行走)
3.1.接收用戶輸入(scanf/getchar)
w(向上走) s(向下走) a(向左走) d(向右走)
3.2.判斷用戶的輸入,控制小人行走
3.2.1.替換二維陣列中保存的資料
(
1.判斷是否可以修改(如果不是#就可以修改)
2.修改現有位置為空白
3.修改下一步為R
)
3.3.輸出修改后的二維陣列
4.判斷用戶是否走出出口
*/
// 宣告列印地圖方法
void printMap(char map[6][7] , int row, int col);
int main(int argc, const char * argv[])
{
// 1.定義二維陣列保存迷宮地圖
char map[6][7] = {
{'#', '#', '#', '#', '#', '#', '#'},
{'#', ' ', ' ', ' ', '#' ,' ', ' '},
{'#', 'R', ' ', '#', '#', ' ', '#'},
{'#', ' ', ' ', ' ', '#', ' ', '#'},
{'#', '#', ' ', ' ', ' ', ' ', '#'},
{'#', '#', '#', '#', '#', '#', '#'}
};
// 2.計算地圖行數和列數
int row = sizeof(map)/sizeof(map[0]);
int col = sizeof(map[0])/ sizeof(map[0][0]);
// 3.輸出地圖
printMap(map, row, col);
// 4.定義變數記錄人物位置
int pRow = 2;
int pCol = 1;
// 5.定義變數記錄出口的位置
int endRow = 1;
int endCol = 6;
// 6.控制人物行走
while ('R' != map[endRow][endCol]) {
// 6.1提示用戶如何控制人物行走
printf("親, 請輸入相應的操作\n");
printf("w(向上走) s(向下走) a(向左走) d(向右走)\n");
char run;
run = getchar();
// 6.2根據用戶輸入控制人物行走
switch (run) {
case 's':
if ('#' != map[pRow + 1][pCol]) {
map[pRow][pCol] = ' ';
pRow++;//3
map[pRow][pCol] = 'R';
}
break;
case 'w':
if ('#' != map[pRow - 1][pCol]) {
map[pRow][pCol] = ' ';
pRow--;
map[pRow][pCol] = 'R';
}
break;
case 'a':
if ('#' != map[pRow][pCol - 1]) {
map[pRow][pCol] = ' ';
pCol--;
map[pRow][pCol] = 'R';
}
break;
case 'd':
if ('#' != map[pRow][pCol + 1]) {
map[pRow][pCol] = ' ';
pCol++;
map[pRow][pCol] = 'R';
}
break;
}
// 6.3重新輸出行走之后的地圖
printMap(map, row, col);
}
printf("你太牛X了\n");
printf("想挑戰自己,請購買完整版本\n");
return 0;
}
/**
* @brief printMap
* @param map 需要列印的二維陣列
* @param row 二維陣列的行數
* @param col 二維陣列的列數
*/
void printMap(char map[6][7] , int row, int col)
{
// 為了保證視窗的干凈整潔, 每次列印都先清空上一次的列印
system("cls");
for (int i = 0; i < row; i++) {
for (int j = 0; j < col; j++) {
printf("%c", map[i][j]);
}
printf("\n");
}
}
注釋的分類
-
單行注釋
- // 被注釋內容
- 使用范圍:任何地方都可以寫注釋:函式外面、里面,每一條陳述句后面
- 作用范圍: 從第二個斜線到這一行末尾
- 快捷鍵:Ctrl+/
-
多行注釋
- /* 被注釋內容 */
- 使用范圍:任何地方都可以寫注釋:函式外面、里面,每一條陳述句后面
- 作用范圍: 從第一個/*到最近的一個*/
注釋的注意點
- 單行注釋可以嵌套單行注釋、多行注釋
// 南哥 // it666.com
// /* 江哥 */
// 帥哥
- 多行注釋可以嵌套單行注釋
/*
// 作者:LNJ
// 描述:第一個C語言程式作用:這是一個主函式,C程式的入口點
*/
- 多行注釋***不能***嵌套多行注釋
/*
哈哈哈
/*嘻嘻嘻*/
呵呵呵
*/
注釋的應用場景
- 思路分析
/*
R代表一個人
#代表一堵墻
// 0123456
####### // 0
# # // 1
#R ## # // 2
# # # // 3
## # // 4
####### // 5
分析:
>1.保存地圖(二維陣列)
>2.輸出地圖
>3.操作R前進(控制小人行走)
3.1.接收用戶輸入(scanf/getchar)
w(向上走) s(向下走) a(向左走) d(向右走)
3.2.判斷用戶的輸入,控制小人行走
3.2.1.替換二維陣列中保存的資料
(
1.判斷是否可以修改(如果不是#就可以修改)
2.修改現有位置為空白
3.修改下一步為R
)
3.3.輸出修改后的二維陣列
4.判斷用戶是否走出出口
*/
- 對變數進行說明
// 2.計算地圖行數和列數
int row = sizeof(map)/sizeof(map[0]);
int col = sizeof(map[0])/ sizeof(map[0][0]);
- 對函式進行說明
/**
* @brief printMap
* @param map 需要列印的二維陣列
* @param row 二維陣列的行數
* @param col 二維陣列的列數
*/
void printMap(char map[6][7] , int row, int col)
{
system("cls");
for (int i = 0; i < row; i++) {
for (int j = 0; j < col; j++) {
printf("%c", map[i][j]);
}
printf("\n");
}
}
- 多實作邏輯排序
// 1.定義二維陣列保存迷宮地圖
char map[6][7] = {
{'#', '#', '#', '#', '#', '#', '#'},
{'#', ' ', ' ', ' ', '#' ,' ', ' '},
{'#', 'R', ' ', '#', '#', ' ', '#'},
{'#', ' ', ' ', ' ', '#', ' ', '#'},
{'#', '#', ' ', ' ', ' ', ' ', '#'},
{'#', '#', '#', '#', '#', '#', '#'}
};
// 2.計算地圖行數和列數
int row = sizeof(map)/sizeof(map[0]);
int col = sizeof(map[0])/ sizeof(map[0][0]);
// 3.輸出地圖
printMap(map, row, col);
// 4.定義變數記錄人物位置
int pRow = 2;
int pCol = 1;
// 5.定義變數記錄出口的位置
int endRow = 1;
int endCol = 6;
// 6.控制人物行走
while ('R' != map[endRow][endCol]) {
... ...
}
使用注釋的好處
- 注釋是一個程式員必須要具備的良好習慣
- 幫助開發人員整理實作思路
- 解釋說明程式, 提高程式的可讀性
- 初學者撰寫程式可以養成習慣:先寫注釋再寫代碼
- 將自己的思想通過注釋先整理出來,在用代碼去體現
- 因為代碼僅僅是思想的一種體現形式而已
什么是關鍵字?
- 關鍵字,也叫作保留字,是指一些被C語言賦予了特殊含義的單詞
- 關鍵字特征:
- 全部都是小寫
- 在開發工具中會顯示特殊顏色
- 關鍵字注意點:
- 因為關鍵字在C語言中有特殊的含義, 所以不能用作變數名、函式名等
- C語言中一共有32個關鍵字
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|
| char | short | int | long | float | double | if | else |
| return | do | while | for | switch | case | break | continue |
| default | goto | sizeof | auto | register | static | extern | unsigned |
| signed | typedef | struct | enum | union | void | const | volatile |
這些不用專門去記住,用多了就會了,在編譯器里都是有特殊顏色的, 我們用到時候會一個一個講解這個些關鍵字怎么用,現在瀏覽下,有個印象就OK了
關鍵字分類
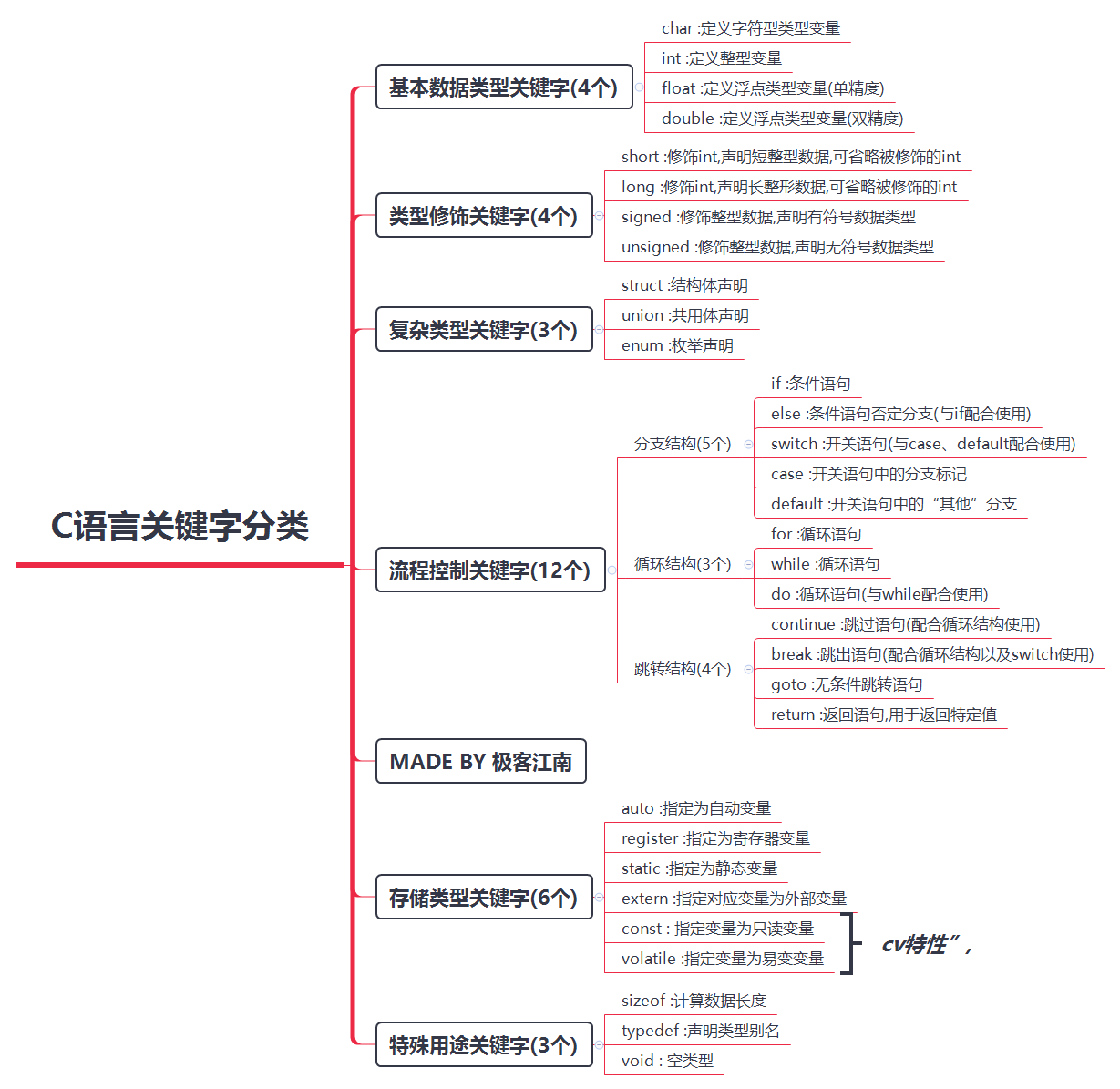
什么是識別符號?
- 從字面上理解,就是用來標識某些東西的符號,標識的目的就是為了將這些東西區分開來
- 其實識別符號的作用就跟人類的名字差不多,為了區分每個人,就在每個人出生的時候起了個名字
- C語言是由函式構成的,一個C程式中可能會有多個函式,為了區分這些函式,就給每一個函式都起了個名稱, 這個名稱就是識別符號
- 綜上所述: 程式員在程式中給函式、變數等起名字就是識別符號
識別符號命名規則
- 只能由字母(a~z、 A~Z)、數字、下劃線組成
- 不能包含除下劃線以外的其它特殊字串
- 不能以數字開頭
- 不能是C語言中的關鍵字
- 識別符號嚴格區分大小寫, test和Test是兩個不同的識別符號
練習
- 下列哪些是合法的識別符號
| fromNo22 | from#22 | my_Boolean | my-Boolean | 2ndObj | GUI | lnj |
| Mike2jack | 江哥 | _test | test!32 | haha(da)tt | jack_rose | jack&rose |
識別符號命名規范
- 見名知意,能夠提高代碼的可讀性
- 駝峰命名,能夠提高代碼的可讀性
- 駝峰命名法就是當變數名或函式名是由多個單詞連接在一起,構成識別符號時,第一個單詞以小寫字母開始;第二個單詞的首字母大寫.
- 例如: myFirstName、myLastName這樣的變數名稱看上去就像駝峰一樣此起彼伏


什么是資料?
-
生活中無時無刻都在跟資料打交道
- 例如:人的體重、身高、收入、性別等資料等
-
在我們使用計算機的程序中,也會接觸到各種各樣的資料
- 例如: 檔案資料、圖片資料、視頻資料等
資料分類
-
靜態的資料
- 靜態資料是指一些永久性的資料,一般存盤在硬碟中,硬碟的存盤空間一般都比較大,現在普通計算機的硬碟都有500G左右,因此硬碟中可以存放一些比較大的檔案
- 存盤的時長:計算機關閉之后再開啟,這些資料依舊還在,只要你不主動刪掉或者硬碟沒壞,這些資料永遠都在
- 哪些是靜態資料:靜態資料一般是以檔案的形式存盤在硬碟上,比如檔案、照片、視頻等,
-
動態的資料
- 動態資料指在程式運行程序中,動態產生的臨時資料,一般存盤在記憶體中,記憶體的存盤空間一般都比較小,現在普通計算機的記憶體只有8G左右,因此要謹慎使用記憶體,不要占用太多的記憶體空間
- 存盤的時長:計算機關閉之后,這些臨時資料就會被清除
- 哪些是動態資料:當運行某個程式(軟體)時,整個程式就會被加載到記憶體中,在程式運行程序中,會產生各種各樣的臨時資料,這些臨時資料都是存盤在記憶體中的,當程式停止運行或者計算機被強制關閉時,這個程式產生的所有臨時資料都會被清除,
-
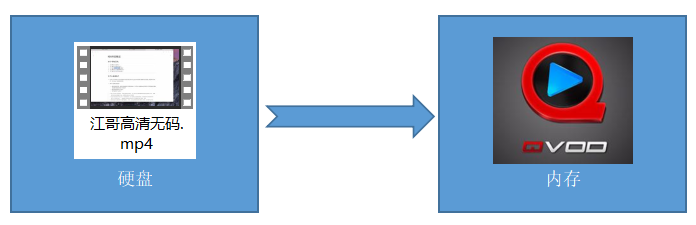
既然硬碟的存盤空間這么大,為何不把所有的應用程式加載到硬碟中去執行呢?
- 主要***原因就是記憶體的訪問速度比硬碟快N倍***
- 靜態資料和動態資料的相互轉換
- 也就是從磁盤加載到記憶體
- 也就是從磁盤加載到記憶體
- 動態資料和靜態資料的相互轉換
- 也就是從記憶體保存到磁盤

- 也就是從記憶體保存到磁盤
- 資料的計量單位
- 不管是靜態還是動態資料,都是0和1組成的
- 資料越大,包含的0和1就越多
1 B(Byte位元組) = 8 bit(位)
// 00000000 就是一個位元組
// 111111111 也是一個位元組
// 10101010 也是一個位元組
// 任意8個0和1的組合都是一個位元組
1 KB(KByte) = 1024 B
1 MB = 1024 KB
1 GB = 1024 MB
1 TB = 1024 GB
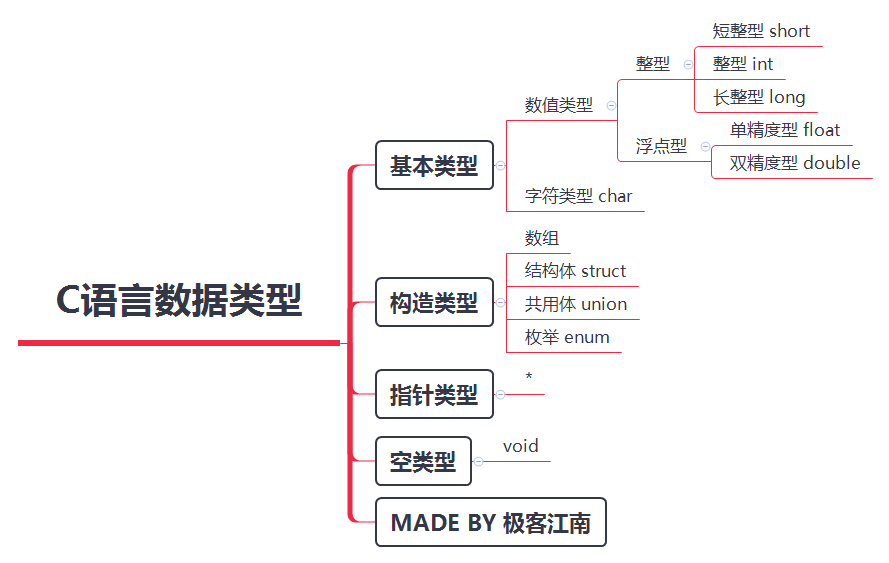
C語言資料型別
- 作為程式員, 我們最關心的是記憶體中的動態資料,因為我們寫的程式就是在記憶體中運行的
- 程式在運行程序中會產生各種各樣的臨時資料,為了方便資料的運算和操作, C語言對這些資料進行了分類, 提供了豐富的資料型別
- C語言中有4大類資料型別:基本型別、構造型別、指標型別、空型別
什么是常量?
- "量"表示資料,常量,則表示一些固定的資料,也就是不能改變的資料
- 就好比現實生活中生男生女一樣, 生下來是男孩永遠都是男孩, 生下來是女孩就永遠都是女孩, 所以性別就是現實生活中常量的一種體現
- 不要和江哥吹牛X說你是泰國來的, 如果你真的來自泰國, 我只能說你贏了
常量的型別
-
整型常量
- 十進制整數,例如:666,-120, 0
- 八進制整數,八進制形式的常量都以0開頭,例如:0123,也就是十進制的83;-011,也就是十進 制的-9
- 十六進制整數,十六進制的常量都是以0x開頭,例如:0x123,也就是十進制的291
- 二進制整數,逢二進一 0b開頭,例如: 0b0010,也就是十進制的2
-
實型常量
- 小數形式
- 單精度小數:以字母f或字母F結尾,例如:0.0f、1.01f
- 雙精度小數:十進制小數形式,例如:3.14、 6.66
- 默認就是雙精度
- 可以沒有整數位只有小數位,例如: .3、 .6f
- 指數形式
- 以冪的形式表示, 以字母e或字母E后跟一個10為底的冪數
- 上過初中的都應該知道科學計數法吧,指數形式的常量就是科學計數法的另一種表 示,比如123000,用科學計數法表示為1.23×10的5次方
- 用C語言表示就是1.23e5或1.23E5
- 字母e或字母E后面的指數必須為整數
- 字母e或字母E前后必須要有數字
- 字母e或字母E前后不能有空格
- 以冪的形式表示, 以字母e或字母E后跟一個10為底的冪數
- 小數形式
-
字符常量
- 字符型常量都是用’’(單引號)括起來的,例如:‘a’、‘b’、‘c’
- 字符常量的單引號中只能有一個字符
- 特殊情況: 如果是轉義字符,單引號中可以有兩個字符,例如:’\n’、’\t’
-
字串常量
- 字符型常量都是用""(雙引號)括起來的,例如:“a”、“abc”、“lnj”
- 系統會自動在字串常量的末尾加一個字符’\0’作為字串結束標志
-
自定義常量
- 后期講解內容, 此處先不用了解
-
常量型別練習
| 123 | 1.1F | 1.1 | .3 | ‘a’ | “a” | “李南江” |
什么是變數?
- "量"表示資料,變數,則表示一些不固定的資料,也就是可以改變的資料
- 就好比現實生活中人的身高、體重一樣, 隨著年齡的增長會不斷發生改變, 所以身高、體重就是現實生活中變數的一種體現
- 就好比現實生活中超市的儲物格一樣, 同一個格子在不同時期不同人使用,格子中存盤的物品是可以變化的,張三使用這個格子的時候里面放的可能是尿不濕, 但是李四使用這個格子的時候里面放的可能是面包
如何定義變數
- 格式1: 變數型別 變數名稱 ;
- 為什么要定義變數?
- 任何變數在使用之前,必須先進行定義, 只有定義了變數才會分配存盤空間, 才有空間存盤資料
- 為什么要限定型別?
- 用來約束變數所存放資料的型別,一旦給變數指明了型別,那么這個變數就只能存盤這種型別的資料
- 記憶體空間極其有限,不同型別的變數占用不同大小的存盤空間
- 為什么要指定變數名稱?
- 存盤資料的空間對于我們沒有任何意義, 我們需要的是空間中存盤的值
- 只有有了名稱, 我們才能獲取到空間中的值
- 為什么要定義變數?
int a;
float b;
char ch;
- 格式2:變數型別 變數名稱,變數名稱;
- 連續定義, 多個變數之間用逗號(,)號隔開
int a,b,c;
- 變數名的命名的規范
- 變數名屬于識別符號,所以必須嚴格遵守識別符號的命名原則
如何使用變數?
- 可以利用=號往變數里面存盤資料
- 在C語言中,利用=號往變數里面存盤資料, 我們稱之為給變數賦值
int value;
value = 998; // 賦值
- 注意:
- 這里的=號,并不是數學中的“相等”,而是C語言中的***賦值運算子***,作用是將右邊的整型常量998賦值給左邊的整型變數value
- 賦值的時候,= 號的左側必須是變數 (10=b,錯誤)
- 為了方便閱讀代碼, 習慣在 = 的兩側 各加上一個 空格
變數的初始化
- C語言中, 變數的第一次賦值,我們稱為“初始化”
- 初始化的兩種形式
- 先定義,后初始化
int value; value = 998; // 初始化- 定義時同時初始化
int a = 10; int b = 4, c = 2;- 其它表現形式(不推薦)
int a, b = 10; //部分初始化
int c, d, e;
c = d = e =0;
- 不初始化里面存盤什么?
- 亂數
- 上次程式分配的存盤空間,存數一些 內容,“垃圾”
- 系統正在用的一些資料
如何修改變數值?
- 多次賦值即可
- 每次賦值都會覆寫原來的值
int i = 10;
i = 20; // 修改變數的值
變數之間的值傳遞
- 可以將一個變數存盤的值賦值給另一個變數
int a = 10;
int b = a; // 相當于把a中存盤的10拷貝了一份給b
如何查看變數的值?
- 使用printf輸出一個或多個變數的值
int a = 10, c = 11;
printf("a=%d, c=%d", a, c);
- 輸出其它型別變數的值
double height = 1.75;
char blood = 'A';
printf("height=%.2f, 血型是%c", height, blood);
變數的作用域
- C語言中所有變數都有自己的作用域
- 變數定義的位置不同,其作用域也不同
- 按照作用域的范圍可分為兩種, 即區域變數和全域變數
- 區域變數
- 區域變數也稱為內部變數
- 區域變數是在***代碼塊內***定義的, 其作用域僅限于代碼塊內, 離開該代碼塊后無法使用
int main(){
int i = 998; // 作用域開始
return 0;// 作用域結束
}
int main(){
{
int i = 998; // 作用域開始
}// 作用域結束
printf("i = %d\n", i); // 不能使用
return 0;
}
int main(){
{
{
int i = 998;// 作用域開始
}// 作用域結束
printf("i = %d\n", i); // 不能使用
}
return 0;
}
- 全域變數
- 全域變數也稱為外部變數,它是在代碼塊外部定義的變數
int i = 666;
int main(){
printf("i = %d\n", i); // 可以使用
return 0;
}// 作用域結束
int call(){
printf("i = %d\n", i); // 可以使用
return 0;
}
- 注意點:
- 同一作用域范圍內不能有相同名稱的變數
int main(){
int i = 998; // 作用域開始
int i = 666; // 報錯, 重復定義
return 0;
}// 作用域結束
int i = 666;
int i = 998; // 報錯, 重復定義
int main(){
return 0;
}
- 不同作用域范圍內可以有相同名稱的變數
int i = 666;
int main(){
int i = 998; // 不會報錯
return 0;
}
int main(){
int i = 998; // 不會報錯
return 0;
}
int call(){
int i = 666; // 不會報錯
return 0;
}
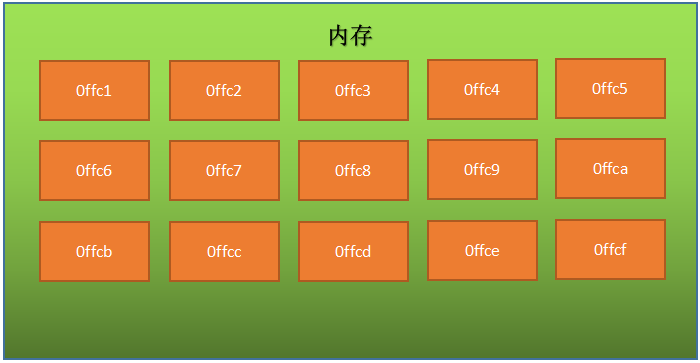
變數記憶體分析(簡單版)
- 位元組和地址
- 為了更好地理解變數在記憶體中的存盤細節,先來認識一下記憶體中的“位元組”和“地址”
- 每一個小格子代表一個位元組
- 每個位元組都有自己的記憶體地址
- 記憶體地址是連續的
- 變數存盤占用的空間
- 一個變數所占用的存盤空間,和***定義變數時宣告的型別***以及***當前編譯環境***有關
| 型別 | 16位編譯器 | 32位編譯器 | 64位編譯器 |
|---|---|---|---|
| char | 1 | 1 | 1 |
| int | 2 | 4 | 4 |
| float | 4 | 4 | 4 |
| double | 8 | 8 | 8 |
| short | 2 | 2 | 2 |
| long | 4 | 4 | 8 |
| long long | 8 | 8 | 8 |
| void* | 2 | 4 | 8 |
- 變數存盤的程序
- 根據定義變數時宣告的型別和當前編譯環境確定需要開辟多大存盤空間
- 在記憶體中開辟一塊存盤空間,開辟時從記憶體地址大的開始開辟(記憶體尋址從大到小)
- 將資料保存到已經開辟好的對應記憶體空間中
int main(){ int number; int value; number = 22; value = 666; }#include <stdio.h> int main(){ int number; int value; number = 22; value = 666; printf("&number = %p\n", &number); // 0060FEAC printf("&value = %p\n", &value); // 0060FEA8 }
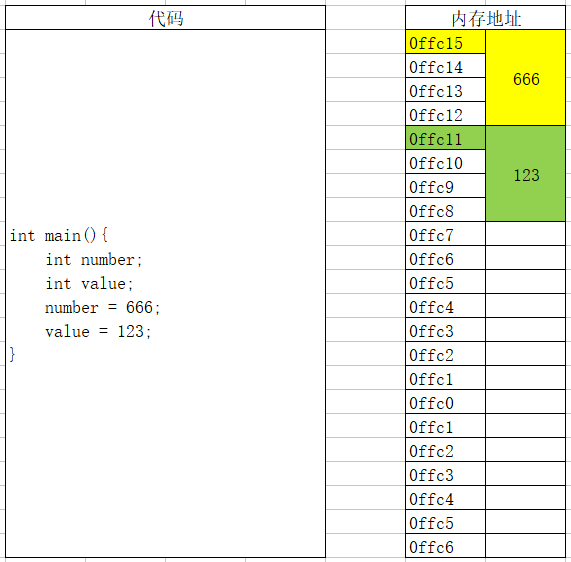
先不要著急, 剛開始接觸C語言, 我先了解這么多就夠了. 后面會再次更深入的講解存盤的各種細節,
printf函式
- printf函式稱之為格式輸出函式,方法名稱的最后一個字母f表示format,其功能是按照用戶指定的格式,把指定的資料輸出到螢屏上
- printf函式的呼叫格式為:
printf("格式控制字串",輸出項串列 );- 例如:
printf("a = %d, b = %d",a, b);

- 非格式字串原樣輸出, 格式控制字串會被輸出項串列中的資料替換
- 注意: 格式控制字串和輸出項在數量和型別上***必須一一對應***
- 格式控制字串
- 形式:
%[標志][輸出寬度][.精度][長度]型別
- 形式:
- 型別
- 格式:
printf("a = %型別", a); - 型別字串用以表示輸出資料的型別, 其格式符和意義如下所示
- 格式:
| 型別 | 含義 |
|---|---|
| d | 有符號10進制整型 |
| i | 有符號10進制整型 |
| u | 無符號10進制整型 |
| o | 無符號8進制整型 |
| x | 無符號16進制整型 |
| X | 無符號16進制整型 |
| f | 單、雙精度浮點數(默認保留6位小數) |
| e / E | 以指數形式輸出單、雙精度浮點數 |
| g / G | 以最短輸出寬度,輸出單、雙精度浮點數 |
| c | 字符 |
| s | 字串 |
| p | 地址 |
#include <stdio.h>
int main(){
int a = 10;
int b = -10;
float c = 6.6f;
double d = 3.1415926;
double e = 10.10;
char f = 'a';
// 有符號整數(可以輸出負數)
printf("a = %d\n", a); // 10
printf("a = %i\n", a); // 10
// 無符號整數(不可以輸出負數)
printf("a = %u\n", a); // 10
printf("b = %u\n", b); // 429496786
// 無符號八進制整數(不可以輸出負數)
printf("a = %o\n", a); // 12
printf("b = %o\n", b); // 37777777766
// 無符號十六進制整數(不可以輸出負數)
printf("a = %x\n", a); // a
printf("b = %x\n", b); // fffffff6
// 無符號十六進制整數(不可以輸出負數)
printf("a = %X\n", a); // A
printf("b = %X\n", b); // FFFFFFF6
// 單、雙精度浮點數(默認保留6位小數)
printf("c = %f\n", c); // 6.600000
printf("d = %lf\n", d); // 3.141593
// 以指數形式輸出單、雙精度浮點數
printf("e = %e\n", e); // 1.010000e+001
printf("e = %E\n", e); // 1.010000E+001
// 以最短輸出寬度,輸出單、雙精度浮點數
printf("e = %g\n", e); // 10.1
printf("e = %G\n", e); // 10.1
// 輸出字符
printf("f = %c\n", f); // a
}
- 寬度
- 格式:
printf("a = %[寬度]型別", a); - 用十進制整數來指定輸出的寬度, 如果實際位數多于指定寬度,則按照實際位數輸出, 如果實際位數少于指定寬度則以空格補位
- 格式:
#include <stdio.h>
int main(){
// 實際位數小于指定寬度
int a = 1;
printf("a =|%d|\n", a); // |1|
printf("a =|%5d|\n", a); // | 1|
// 實際位數大于指定寬度
int b = 1234567;
printf("b =|%d|\n", b); // |1234567|
printf("b =|%5d|\n", b); // |1234567|
}
- 標志
- 格式:
printf("a = %[標志][寬度]型別", a);
- 格式:
| 標志 | 含義 |
|---|---|
| - | 左對齊, 默認右對齊 |
| + | 當輸出值為正數時,在輸出值前面加上一個+號, 默認不顯示 |
| 0 | 右對齊時, 用0填充寬度.(默認用空格填充) |
| 空格 | 輸出值為正數時,在輸出值前面加上空格, 為負數時加上負號 |
| # | 對c、s、d、u型別無影響 |
| # | 對o型別, 在輸出時加前綴o |
| # | 對x型別,在輸出時加前綴0x |
#include <stdio.h>
int main(){
int a = 1;
int b = -1;
// -號標志
printf("a =|%d|\n", a); // |1|
printf("a =|%5d|\n", a); // | 1|
printf("a =|%-5d|\n", a);// |1 |
// +號標志
printf("a =|%d|\n", a); // |1|
printf("a =|%+d|\n", a);// |+1|
printf("b =|%d|\n", b); // |-1|
printf("b =|%+d|\n", b);// |-1|
// 0標志
printf("a =|%5d|\n", a); // | 1|
printf("a =|%05d|\n", a); // |00001|
// 空格標志
printf("a =|% d|\n", a); // | 1|
printf("b =|% d|\n", b); // |-1|
// #號
int c = 10;
printf("c = %o\n", c); // 12
printf("c = %#o\n", c); // 012
printf("c = %x\n", c); // a
printf("c = %#x\n", c); // 0xa
}
- 精度
- 格式:
printf("a = %[精度]型別", a); - 精度格式符以"."開頭, 后面跟上十進制整數, 用于指定需要輸出多少位小數, 如果輸出位數大于指定的精度, 則洗掉超出的部分
- 格式:
#include <stdio.h>
int main(){
double a = 3.1415926;
printf("a = %.2f\n", a); // 3.14
}
- 動態指定保留小數位數
- 格式:
printf("a = %.*f", a);
- 格式:
#include <stdio.h>
int main(){
double a = 3.1415926;
printf("a = %.*f", 2, a); // 3.14
}
- 實型(浮點型別)有效位數問題
- 對于單精度數,使用%f格式符輸出時,僅前6~7位是有效數字
- 對于雙精度數,使用%lf格式符輸出時,前15~16位是有效數字
- 有效位數和精度(保留多少位)不同, 有效位數是指從第一個非零數字開始,誤差不超過本數位半個單位的、精確可信的數位
- 有效位數包含小數點前的非零數位
#include <stdio.h>
int main(){
// 1234.567871093750000
float a = 1234.567890123456789;
// 1234.567890123456900
double b = 1234.567890123456789;
printf("a = %.15f\n", a); // 前8位數字是準確的, 后面的都不準確
printf("b = %.15f\n", b); // 前16位數字是準確的, 后面的都不準確
}
- 長度
- 格式:
printf("a = %[長度]型別", a);
- 格式:
| 長度 | 修飾型別 | 含義 |
|---|---|---|
| hh | d、i、o、u、x | 輸出char |
| h | d、i、o、u、x | 輸出 short int |
| l | d、i、o、u、x | 輸出 long int |
| ll | d、i、o、u、x | 輸出 long long int |
#include <stdio.h>
int main(){
char a = 'a';
short int b = 123;
int c = 123;
long int d = 123;
long long int e = 123;
printf("a = %hhd\n", a); // 97
printf("b = %hd\n", b); // 123
printf("c = %d\n", c); // 123
printf("d = %ld\n", d); // 123
printf("e = %lld\n", e); // 123
}
- 轉義字符
- 格式:
printf("%f%%", 3.1415); - %號在格式控制字串中有特殊含義, 所以想輸出%必須添加一個轉移字符
- 格式:
#include <stdio.h>
int main(){
printf("%f%%", 3.1415); // 輸出結果3.1415%
}
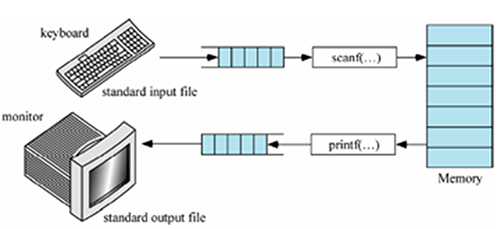
Scanf函式
- scanf函式用于接收鍵盤輸入的內容, 是一個阻塞式函式,程式會停在scanf函式出現的地方, 直到接收到資料才會執行后面的代碼
- printf函式的呼叫格式為:
scanf("格式控制字串", 地址串列);- 例如:
scanf("%d", &num);
- 基本用法
- 地址串列項中只能傳入變數地址, 變數地址可以通過&符號+變數名稱的形式獲取
#include <stdio.h>
int main(){
int number;
scanf("%d", &number); // 接收一個整數
printf("number = %d\n", number);
}
- 接收非字符和字串型別時, 空格、Tab和回車會被忽略
#include <stdio.h>
int main(){
float num;
// 例如:輸入 Tab 空格 回車 回車 Tab 空格 3.14 , 得到的結果還是3.14
scanf("%f", &num);
printf("num = %f\n", num);
}
- 非格式字串原樣輸入, 格式控制字串會賦值給地址項串列項中的變數
- 不推薦這種寫法
#include <stdio.h>
int main(){
int number;
// 用戶必須輸入number = 數字 , 否則會得到一個意外的值
scanf("number = %d", &number);
printf("number = %d\n", number);
}
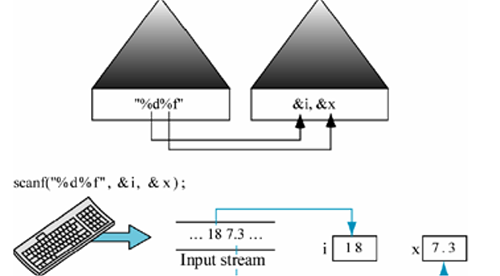
- 接收多條資料
- 格式控制字串和地址串列項在數量和型別上必須一一對應
- 非字符和字串情況下如果沒有指定多條資料的分隔符, 可以使用空格或者回車作為分隔符(不推薦這種寫法)
- 非字符和字串情況下建議明確指定多條資料之間分隔符
#include <stdio.h>
int main(){
int number;
scanf("%d", &number);
printf("number = %d\n", number);
int value;
scanf("%d", &value);
printf("value = %d\n", value);
}
#include <stdio.h>
int main(){
int number;
int value;
// 可以輸入 數字 空格 數字, 或者 數字 回車 數字
scanf("%d%d", &number, &value);
printf("number = %d\n", number);
printf("value = %d\n", value);
}
#include <stdio.h>
int main(){
int number;
int value;
// 輸入 數字,數字 即可
scanf("%d,%d", &number, &value);
printf("number = %d\n", number);
printf("value = %d\n", value);
}
- \n是scanf函式的結束符號, 所以格式化字串中不能出現\n
#include <stdio.h>
int main(){
int number;
// 輸入完畢之后按下回車無法結束輸入
scanf("%d\n", &number);
printf("number = %d\n", number);
}
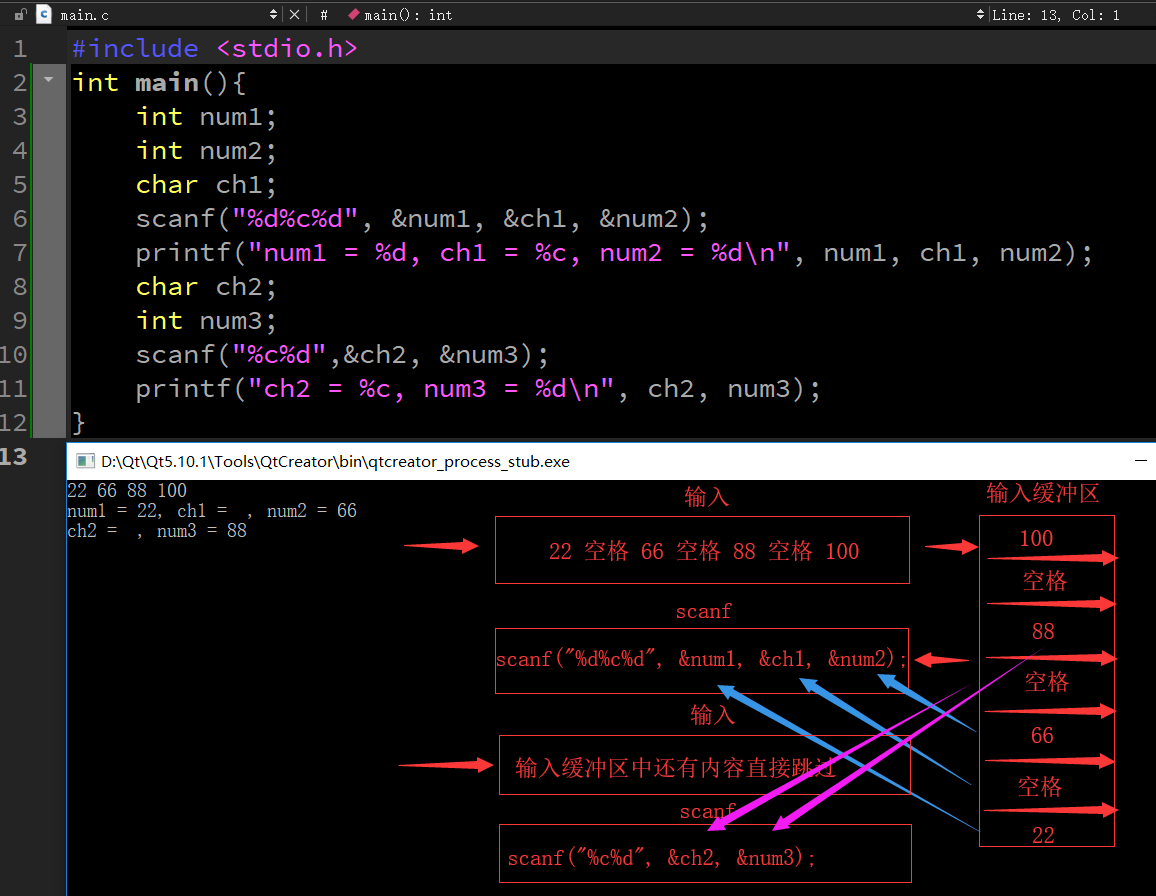
scanf運行原理
- 系統會將用戶輸入的內容先放入輸入緩沖區
- scanf方式會從輸入緩沖區中逐個取出內容賦值給變數
- 如果輸入緩沖區的內容不為空,scanf會一直從緩沖區中獲取,而不要求再次輸入
#include <stdio.h>
int main(){
int num1;
int num2;
char ch1;
scanf("%d%c%d", &num1, &ch1, &num2);
printf("num1 = %d, ch1 = %c, num2 = %d\n", num1, ch1, num2);
char ch2;
int num3;
scanf("%c%d",&ch2, &num3);
printf("ch2 = %c, num3 = %d\n", ch2, num3);
}
- 利用fflush方法清慷訓沖區(不是所有平臺都能使用)
- 格式:
fflush(stdin); - C和C++的標準里從來沒有定義過 fflush(stdin)
- MSDN 檔案里清除的描述著"fflush on input stream is an extension to the C standard" (fflush 是在標準上擴充的函式, 不是標準函式, 所以不是所有平臺都支持)
- 格式:
- 利用setbuf方法清慷訓沖區(所有平臺有效)
- 格式:
setbuf(stdin, NULL);
- 格式:
#include <stdio.h>
int main(){
int num1;
int num2;
char ch1;
scanf("%d%c%d", &num1, &ch1, &num2);
printf("num1 = %d, ch1 = %c, num2 = %d\n", num1, ch1, num2);
//fflush(stdin); // 清空輸入快取區
setbuf(stdin, NULL); // 清空輸入快取區
char ch2;
int num3;
scanf("%c%d",&ch2, &num3);
printf("ch2 = %c, num3 = %d\n", ch2, num3);
}
putchar和getchar
- putchar: 向螢屏輸出一個字符
#include <stdio.h>
int main(){
char ch = 'a';
putchar(ch); // 輸出a
}
- getchar: 從鍵盤獲得一個字符
#include <stdio.h>
int main(){
char ch;
ch = getchar();// 獲取一個字符
printf("ch = %c\n", ch);
}
運算子基本概念
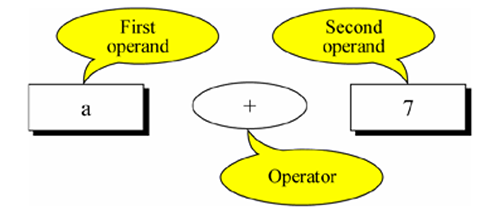
-
和數學中的運算子一樣, C語言中的運算子是告訴程式執行特定算識訓邏輯操作的符號
- 例如告訴程式, 某兩個數相加, 相減,相乘等
- 例如告訴程式, 某兩個數相加, 相減,相乘等
-
什么是運算式
- 運算式就是利用運算子鏈接在一起的有意義,有結果的陳述句;
- 例如: a + b; 就是一個算數運算式, 它的意義是將兩個數相加, 兩個數相加的結果就是運算式的結果
- 注意: 運算式一定要有結果
運算子分類
- 按照功能劃分:
- 算術運算子
- 賦值運算子
- 關系運算子
- 邏輯運算子
- 位運算子
- 按照參與運算的運算元個數劃分:
- 單目運算
- 只有一個運算元 如 : i++;
- 雙目運算
- 有兩個運算元 如 : a + b;
- 三目運算
- C語言中唯一的一個,也稱為問號運算式 如: a>b ? 1 : 0;
- 單目運算
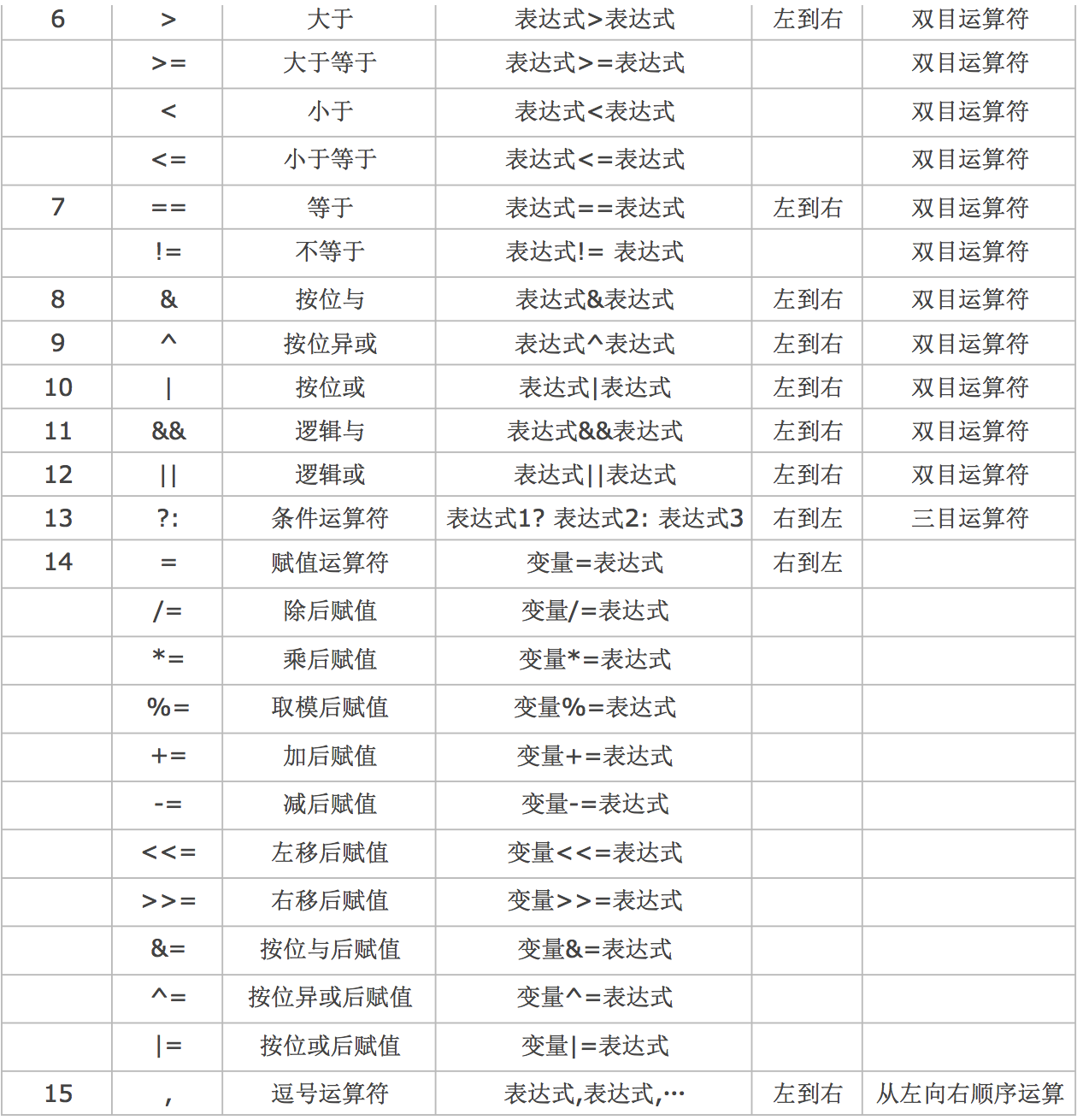
運算子的優先級和結合性
- 早在小學的數學課本中,我們就學習過"從左往右,先乘除后加減,有括號的先算括號里面的", 這句話就蘊含了優先級和結合性的問題
- C語言中,運算子的運算優先級共分為15 級,1 級最高,15 級最低
- 在C語言運算式中,不同優先級的運算子, 運算次序按照由高到低執行
- 在C語言運算式中,相同優先級的運算子, 運算次序按照結合性規定的方向執行
算數運算子
| 優先級 | 名稱 | 符號 | 說明 |
|---|---|---|---|
| 3 | 乘法運算子 | * | 雙目運算子,具有左結合性 |
| 3 | 除法運算子 | / | 雙目運算子,具有左結合性 |
| 3 | 求余運算子 (模運算子) | % | 雙目運算子,具有左結合性 |
| 4 | 加法運算子 | + | 雙目運算子,具有左結合性 |
| 4 | 減法運算子 | - | 雙目運算子,具有左結合性 |
- 注意事項
- 如果參與運算的兩個運算元皆為整數, 那么結果也為整數
- 如果參與運算的兩個運算元其中一個是浮點數, 那么結果一定是浮點數
- 求余運算子, 本質上就是數學的商和余"中的余數
- 求余運算子, 參與運算的兩個運算元必須都是整數, 不能包含浮點數
- 求余運算子, 被除數小于除數, 那么結果就是被除數
- 求余運算子, 運算結果的正負性取決于被除數,跟除數無關, 被除數是正數結果就是正數,被除數是負數結果就是負數
- 求余運算子, 被除數為0, 結果為0
- 求余運算子, 除數為0, 沒有意義(不要這樣寫)
#include <stdio.h>
int main(){
int a = 10;
int b = 5;
// 加法
int result = a + b;
printf("%i\n", result); // 15
// 減法
result = a - b;
printf("%i\n", result); // 5
// 乘法
result = a * b;
printf("%i\n", result); // 50
// 除法
result = a / b;
printf("%i\n", result); // 2
// 算術運算子的結合性和優先級
// 結合性: 左結合性, 從左至右
int c = 50;
result = a + b + c; // 15 + c; 65;
printf("%i\n", result);
// 優先級: * / % 大于 + -
result = a + b * c; // a + 250; 260;
printf("%i\n", result);
}
#include <stdio.h>
int main(){
// 整數除以整數, 結果還是整數
printf("%i\n", 10 / 3); // 3
// 參與運算的任何一個數是小數, 結果就是小數
printf("%f\n", 10 / 3.0); // 3.333333
}
#include <stdio.h>
int main(){
// 10 / 3 商等于3, 余1
int result = 10 % 3;
printf("%i\n", result); // 1
// 左邊小于右邊, 那么結果就是左邊
result = 2 % 10;
printf("%i\n", result); // 2
// 被除數是正數結果就是正數,被除數是負數結果就是負數
result = 10 % 3;
printf("%i\n", result); // 1
result = -10 % 3;
printf("%i\n", result); // -1
result = 10 % -3;
printf("%i\n", result); // 1
}
賦值運算子
| 優先級 | 名稱 | 符號 | 說明 |
|---|---|---|---|
| 14 | 賦值運算子 | = | 雙目運算子,具有右結合性 |
| 14 | 除后賦值運算子 | /= | 雙目運算子,具有右結合性 |
| 14 | 乘后賦值運算子 (模運算子) | *= | 雙目運算子,具有右結合性 |
| 14 | 取模后賦值運算子 | %= | 雙目運算子,具有右結合性 |
| 14 | 加后賦值運算子 | += | 雙目運算子,具有右結合性 |
| 14 | 減后賦值運算子 | -= | 雙目運算子,具有右結合性 |
- 簡單賦值運算子
#include <stdio.h>
int main(){
// 簡單的賦值運算子 =
// 會將=右邊的值賦值給左邊
int a = 10;
printf("a = %i\n", a); // 10
}
- 復合賦值運算子
#include <stdio.h>
int main(){
// 復合賦值運算子 += -= *= /= %=
// 將變數中的值取出之后進行對應的操作, 操作完畢之后再重新賦值給變數
int num1 = 10;
// num1 = num1 + 1; num1 = 10 + 1; num1 = 11;
num1 += 1;
printf("num1 = %i\n", num1); // 11
int num2 = 10;
// num2 = num2 - 1; num2 = 10 - 1; num2 = 9;
num2 -= 1;
printf("num2 = %i\n", num2); // 9
int num3 = 10;
// num3 = num3 * 2; num3 = 10 * 2; num3 = 20;
num3 *= 2;
printf("num3 = %i\n", num3); // 20
int num4 = 10;
// num4 = num4 / 2; num4 = 10 / 2; num4 = 5;
num4 /= 2;
printf("num4 = %i\n", num4); // 5
int num5 = 10;
// num5 = num5 % 3; num5 = 10 % 3; num5 = 1;
num5 %= 3;
printf("num5 = %i\n", num5); // 1
}
- 結合性和優先級
#include <stdio.h>
int main(){
int number = 10;
// 賦值運算子優先級是14, 普通運算子優先級是3和4, 所以先計算普通運算子
// 普通運算子中乘法優先級是3, 加法是4, 所以先計算乘法
// number += 1 + 25; number += 26; number = number + 26; number = 36;
number += 1 + 5 * 5;
printf("number = %i\n", number); // 36
}
自增自減運算子
- 在程式設計中,經常遇到“i=i+1”和“i=i-1”這兩種極為常用的操作,
- C語言為這種操作提供了兩個更為簡潔的運算子,即++和–
| 優先級 | 名稱 | 符號 | 說明 |
|---|---|---|---|
| 2 | 自增運算子(在后) | i++ | 單目運算子,具有左結合性 |
| 2 | 自增運算子(在前) | ++i | 單目運算子,具有右結合性 |
| 2 | 自減運算子(在后) | i– | 單目運算子,具有左結合性 |
| 2 | 自減運算子(在前) | –i | 單目運算子,具有右結合性 |
- 自增
- 如果只有***單個***變數, 無論++寫在前面還是后面都會對變數做+1操作
#include <stdio.h>
int main(){
int number = 10;
number++;
printf("number = %i\n", number); // 11
++number;
printf("number = %i\n", number); // 12
}
- 如果出現在一個運算式中, 那么++寫在前面和后面就會有所區別
- 前綴運算式:++x, --x;其中x表示變數名,先完成變數的自增自減1運算,再用x的值作為運算式的值;即“先變后用”,也就是變數的值先變,再用變數的值參與運算
- 后綴運算式:x++, x–;先用x的當前值作為運算式的值,再進行自增自減1運算,即“先用后變”,也就是先用變數的值參與運算,變數的值再進行自增自減變化
#include <stdio.h>
int main(){
int number = 10;
// ++在后, 先參與運算式運算, 再自增
// 運算式運算時為: 3 + 10;
int result = 3 + number++;
printf("result = %i\n", result); // 13
printf("number = %i\n", number); // 11
}
#include <stdio.h>
int main(){
int number = 10;
// ++在前, 先自增, 再參與運算式運算
// 運算式運算時為: 3 + 11;
int result = 3 + ++number;
printf("result = %i\n", result); // 14
printf("number = %i\n", number); // 11
}
- 自減
#include <stdio.h>
int main(){
int number = 10;
// --在后, 先參與運算式運算, 再自減
// 運算式運算時為: 10 + 3;
int result = number-- + 3;
printf("result = %i\n", result); // 13
printf("number = %i\n", number); // 9
}
#include <stdio.h>
int main(){
int number = 10;
// --在前, 先自減, 再參與運算式運算
// 運算式運算時為: 9 + 3;
int result = --number + 3;
printf("result = %i\n", result); // 12
printf("number = %i\n", number); // 9
}
- 注意點:
- 自增、自減運算只能用于單個變數,只要是標準型別的變數,不管是整型、實型,還是字符型變數等,但不能用于運算式或常量
- 錯誤用法:
++(a+b); 5++;
- 錯誤用法:
- 企業開發中盡量讓++ – 單獨出現, 盡量不要和其它運算子混合在一起
- 自增、自減運算只能用于單個變數,只要是標準型別的變數,不管是整型、實型,還是字符型變數等,但不能用于運算式或常量
int i = 10;
int b = i++; // 不推薦
或者
int b = ++i; // 不推薦
或者
int a = 10;
int b = ++a + a++; // 不推薦
- 請用如下代碼替代
int i = 10;
int b = i; // 推薦
i++;
或者;
i++;
int b = i; // 推薦
或者
int a = 10;
++a;
int b = a + a; // 推薦
a++;
- C語言標準沒有明確的規定,
同一個運算式中同一個變數自增或自減后如何運算, 不同編譯器得到結果也不同, 在企業開發中千萬不要這樣寫
int a = 1;
// 下列代碼利用Qt運行時6, 利用Xcode運行是5
// 但是無論如何, 最終a的值都是3
// 在C語言中這種代碼沒有意義, 不用深究也不要這樣寫
// 特點: 參與運算的是同一個變數, 參與運算時都做了自增自減操作, 并且在同一個運算式中
int b = ++a + ++a;
printf("b = %i\n", b);
sizeof運算子
-
sizeof可以用來計算一個變數或常量、資料型別所占的記憶體位元組數
- 標準格式: sizeof(常量 or 變數);
-
sizeof的幾種形式
- sizeof( 變數\常量 );
sizeof(10);char c = 'a'; sizeof(c);
- sizeof 變數\常量;
sizeof 10;char c = 'a'; sizeof c;
- sizeof( 資料型別);
sizeof(float);如果是資料型別不能省略括號
- sizeof( 變數\常量 );
-
sizeof面試題:
- sizeof()和+=、*=一樣是一個復合運算子, 由sizeof和()兩個部分組成, 但是代表的是一個整體
- 所以sizeof不是一個函式, 是一個運算子, 該運算子的優先級是2
#include <stdio.h>
int main(){
int a = 10;
double b = 3.14;
// 由于sizeof的優先級比+號高, 所以會先計算sizeof(a);
// a是int型別, 所以占4個位元組得到結果4
// 然后再利用計算結果和b相加, 4 + 3.14 = 7.14
double res = sizeof a+b;
printf("res = %lf\n", res); // 7.14
}
逗號運算子
- 在C語言中逗號“,”也是一種運算子,稱為逗號運算子, 其功能是把多個運算式連接起來組成一個運算式,稱為逗號運算式
- 逗號運算子會從左至右依次取出每個運算式的值, 最后整個逗號運算式的值等于最后一個運算式的值
- 格式:
運算式1,運算式2,… …,運算式n;- 例如:
int result = a+1,b=3*4;
- 例如:
#include <stdio.h>
int main(){
int a = 10, b = 20, c;
// ()優先級高于逗號運算子和賦值運算子, 所以先計算()中的內容
// c = (11, 21);
// ()中是一個逗號運算式, 結果是最后一個運算式的值, 所以計算結果為21
// 將逗號運算式的結果賦值給c, 所以c的結果是21
c = (a + 1, b + 1);
printf("c = %i\n", c); // 21
}
關系運算子
- 為什么要學習關系運算子
- 默認情況下,我們在程式中寫的每一句正確代碼都會被執行,但很多時候,我們想在某個條件成立的情況下才執行某一段代碼
- 這種情況的話可以使用條件陳述句來完成,但是學習條件陳述句之前,我們先來看一些更基礎的知識:如何判斷一個條件是否成立
- C語言中的真偽性
- 在C語言中,條件成立稱為“真”,條件不成立稱為“假”,因此,判斷條件是否成立,就是判斷條件的“真偽”
- 怎么判斷真偽呢?C語言規定,任何數值都有真偽性,任何非0值都為“真”,只有0才為“假”,也就是說,108、-18、4.5、-10.5等都是“真”,0則是“假”
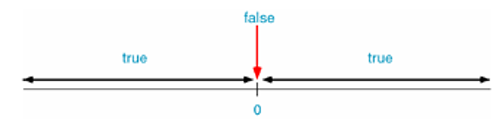
- 關系運算子的運算結果只有2種:如果條件成立,結果就為1,也就是“真”;如果條件不成立,結果就為0,也就是“假”
| 優先級 | 名稱 | 符號 | 說明 |
|---|---|---|---|
| 6 | 大于運算子 | > | 雙目運算子,具有左結合性 |
| 6 | 小于運算子 | < | 雙目運算子,具有左結合性 |
| 6 | 大于等于運算子 | >= | 雙目運算子,具有左結合性 |
| 6 | 小于等于運算子 | <= | 雙目運算子,具有左結合性 |
| 7 | 等于運算子 | == | 雙目運算子,具有左結合性 |
| 7 | 不等于運算子 | != | 雙目運算子,具有左結合性 |
#include <stdio.h>
int main(){
int result = 10 > 5;
printf("result = %i\n", result); // 1
result = 5 < 10;
printf("result = %i\n", result); // 1
result = 5 > 10;
printf("result = %i\n", result); // 0
result = 10 >= 10;
printf("result = %i\n", result); // 1
result = 10 <= 10;
printf("result = %i\n", result); // 1
result = 10 == 10;
printf("result = %i\n", result); // 1
result = 10 != 9;
printf("result = %i\n", result); // 1
}
- 優先級和結合性
#include <stdio.h>
int main(){
// == 優先級 小于 >, 所以先計算>
// result = 10 == 1; result = 0;
int result = 10 == 5 > 3;
printf("result = %i\n", result); // 0
}
#include <stdio.h>
int main(){
// == 和 != 優先級一樣, 所以按照結合性
// 關系運算子是左結合性, 所以從左至右計算
// result = 0 != 3; result = 1;
int result = 10 == 5 != 3;
printf("result = %i\n", result); // 1
}
- 練習: 計算result的結果
int result1 = 3 > 4 + 7
int result2 = (3>4) + 7
int result3 = 5 != 4 + 2 * 7 > 3 == 10
- 注意點:
- 無論是float還是double都有精度問題, 所以一定要避免利用==判斷浮點數是否相等
#include <stdio.h>
int main(){
float a = 0.1;
float b = a * 10 + 0.00000000001;
double c = 1.0 + + 0.00000000001;
printf("b = %f\n", b);
printf("c = %f\n", c);
int result = b == c;
printf("result = %i\n", result); // 0
}
邏輯運算子
| 優先級 | 名稱 | 符號 | 說明 |
|---|---|---|---|
| 2 | 邏輯非運算子 | ! | 單目運算子,具有右結合性 |
| 11 | 邏輯與運算子 | && | 雙目運算子,具有左結合性 |
| 12 | 邏輯或運算子 | \|\| | 雙目運算子,具有左結合性 |
- 邏輯非
- 格式:
! 條件A; - 運算結果: 真變假,假變真
- 運算程序:
- 先判斷條件A是否成立,如果添加A成立, 那么結果就為0,即“假”;
- 如果條件A不成立,結果就為1,即“真”
- 使用注意:
- 可以多次連續使用邏輯非運算子
- !!!0;相當于(!(!(!0)));最終結果為1
- 格式:
#include <stdio.h>
int main(){
// ()優先級高, 先計算()里面的內容
// 10==10為真, 所以result = !(1);
// !代表真變假, 假變真,所以結果是假0
int result = !(10 == 10);
printf("result = %i\n", result); // 0
}
- 邏輯與
- 格式:
條件A && 條件B; - 運算結果:一假則假
- 運算程序:
- 總是先判斷"條件A"是否成立
- 如果"條件A"成立,接著再判斷"條件B"是否成立, 如果"條件B"也成立,結果就為1,即“真”
- 如果"條件A"成立,"條件B"不成立,結果就為0,即“假”
- 如果"條件A"不成立,不會再去判斷"條件B"是否成立, 因為邏輯與只要一個不為真結果都不為真
- 使用注意:
- "條件A"為假, "條件B"不會被執行
- 格式:
#include <stdio.h>
int main(){
// 真 && 真
int result = (10 == 10) && (5 != 1);
printf("result = %i\n", result); // 1
// 假 && 真
result = (10 == 9) && (5 != 1);
printf("result = %i\n", result); // 0
// 真 && 假
result = (10 == 10) && (5 != 5);
printf("result = %i\n", result); // 0
// 假 && 假
result = (10 == 9) && (5 != 5);
printf("result = %i\n", result); // 0
}
#include <stdio.h>
int main(){
int a = 10;
int b = 20;
// 邏輯與, 前面為假, 不會繼續執行后面
int result = (a == 9) && (++b);
printf("result = %i\n", result); // 1
printf("b = %i\n", b); // 20
}
- 邏輯或
- 格式:
條件A || 條件B; - 運算結果:一真則真
- 運算程序:
- 總是先判斷"條件A"是否成立
- 如果"條件A"不成立,接著再判斷"條件B"是否成立, 如果"條件B"成立,結果就為1,即“真”
- 如果"條件A"不成立,"條件B"也不成立成立, 結果就為0,即“假”
- 如果"條件A"成立, 不會再去判斷"條件B"是否成立, 因為邏輯或只要一個為真結果都為真
- 使用注意:
- "條件A"為真, "條件B"不會被執行
- 格式:
#include <stdio.h>
int main(){
// 真 || 真
int result = (10 == 10) || (5 != 1);
printf("result = %i\n", result); // 1
// 假 || 真
result = (10 == 9) || (5 != 1);
printf("result = %i\n", result); // 1
// 真 || 假
result = (10 == 10) || (5 != 5);
printf("result = %i\n", result); // 1
// 假 || 假
result = (10 == 9) || (5 != 5);
printf("result = %i\n", result); // 0
}
#include <stdio.h>
int main(){
int a = 10;
int b = 20;
// 邏輯或, 前面為真, 不會繼續執行后面
int result = (a == 10) || (++b);
printf("result = %i\n", result); // 1
printf("b = %i\n", b); // 20
}
- 練習: 計算result的結果
int result = 3>5 || 2<4 && 6<1;
三目運算子
-
三目運算子,它需要3個資料或運算式構成條件運算式
-
格式:
運算式1?運算式2(結果A):運算式3(結果B)- 示例:
考試及格 ? 及格 : 不及格;
- 示例:
-
求值規則:
- 如果"運算式1"為真,三目運算子的運算結果為"運算式2"的值(結果A),否則為"運算式3"的值(結果B)
示例:
int a = 10;
int b = 20;
int max = (a > b) ? a : b;
printf("max = %d", max);
輸出結果: 20
等價于:
int a = 10;
int b = 20;
int max = 0;
if(a>b){
max=a;
}else {
max=b;
}
printf("max = %d", max);
- 注意點
- 條件運算子的運算優先級低于關系運算子和算術運算子,但高于賦值符
- 條件運算子?和:是一個整體,不能分開使用
#include <stdio.h>
int main(){
int a = 10;
int b = 5;
// 先計算 a > b
// 然后再根據計算結果判定回傳a還是b
// 相當于int max= (a>b) ? a : b;
int max= a>b ? a : b;
printf("max = %i\n", max); // 10
}
#include <stdio.h>
int main(){
int a = 10;
int b = 5;
int c = 20;
int d = 10;
// 結合性是從右至左, 所以會先計算:后面的內容
// int res = a>b?a:(c>d?c:d);
// int res = a>b?a:(20>10?20:10);
// int res = a>b?a:(20);
// 然后再計算最終的結果
// int res = 10>5?10:(20);
// int res = 10;
int res = a>b?a:c>d?c:d;
printf("res = %i\n", res);
}
型別轉換
| 強制型別轉換(顯示轉換) | 自動型別轉換(隱式轉換) |
|---|---|
| (需要轉換的型別)(運算式) | 1.算數轉換 2.賦值轉換 |
- 強制型別轉換(顯示轉換)
// 將double轉換為int
int a = (int)10.5;
- 算數轉換
- 系統會自動對占用記憶體較少的型別做一個“自動型別提升”的操作, 先將其轉換為當前算數運算式中占用記憶體高的型別, 然后再參與運算
// 當前運算式用1.0占用8個位元組, 2占用4個位元組
// 所以會先將整數型別2轉換為double型別之后再計算
double b = 1.0 / 2;
- 賦值轉換
// 賦值時左邊是什么型別,就會自動將右邊轉換為什么型別再保存
int a = 10.6;
- 注意點:
- 參與計算的是什么型別, 結果就是什么型別
// 結果為0, 因為參與運算的都是整型
double a = (double)(1 / 2);
// 結果為0.5, 因為1被強制轉換為了double型別, 2也會被自動提升為double型別
double b = (double)1 / 2;
- 型別轉換并不會影響到原有變數的值
#include <stdio.h>
int main(){
double d = 3.14;
int num = (int)d;
printf("num = %i\n", num); // 3
printf("d = %lf\n", d); // 3.140000
}
階段練習
- 從鍵盤輸入一個整數, 判斷這個數是否是100到200之間的數
- 運算式 6==6==6 的值是多少?
- 用戶從鍵盤上輸入三個整數,找出最大值,然后輸入最大值
- 用兩種方式交換兩個變數的保存的值
交換前
int a = 10; int b = 20;
交換后
int a = 20; int b = 10;
流程控制基本概念
-
默認情況下程式運行后,系統會按書寫順序從上至下依次執行程式中的每一行代碼,但是這并不能滿足我們所有的開發需求, 為了方便我們控制程式的運行流程,C語言提供3種流程控制結構,不同的流程控制結構可以實作不同的運行流程,
-
這3種流程結構分別是順序結構、選擇結構、回圈結構
-
順序結構:
- 按書寫順序從上至下依次執行
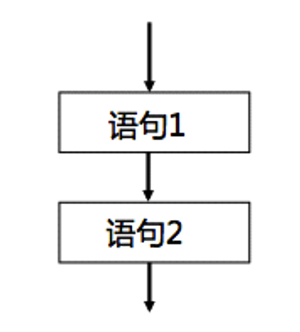
- 按書寫順序從上至下依次執行
-
選擇結構
- 對給定的條件進行判斷,再根據判斷結果來決定執行代碼
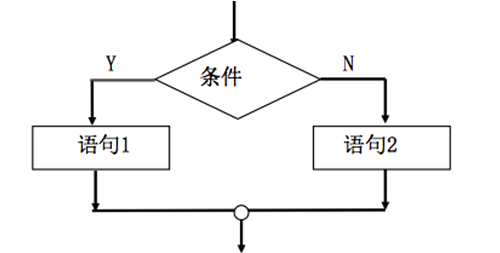
- 對給定的條件進行判斷,再根據判斷結果來決定執行代碼
-
回圈結構
- 在給定條件成立的情況下,反復執行某一段代碼
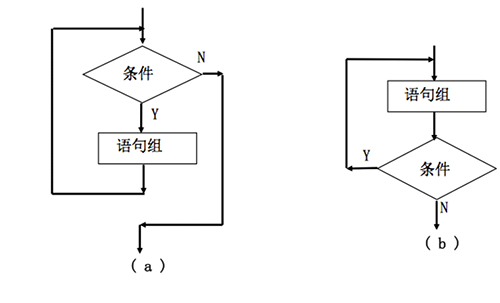
- 在給定條件成立的情況下,反復執行某一段代碼
選擇結構
- C語言中提供了兩大選擇結構, 分別是if和switch
##選擇結構if - if第一種形式
- 表示如果運算式為真,執行陳述句塊1,否則不執行
if(運算式) {
陳述句塊1;
}
后續陳述句;
if(age >= 18) {
printf("開網卡\n");
}
printf("買煙\n");
- if第二種形式
- 如果運算式為真,則執行陳述句塊1,否則執行陳述句塊2
- else不能脫離if單獨使用
if(運算式){
陳述句塊1;
}else{
陳述句塊2;
}
后續陳述句;
if(age > 18){
printf("開網卡\n");
}else{
printf("喊家長來開\n");
}
printf("買煙\n");
- if第三種形式
- 如果"運算式1"為真,則執行"陳述句塊1",否則判斷"運算式2",如果為真執行"陳述句塊2",否則再判斷"運算式3",如果真執行"陳述句塊3", 當運算式1、2、3都不滿足,會執行最后一個else陳述句
- 眾多大括號中,只有一個大括號中的內容會被執行
- 只有前面所有添加都不滿足, 才會執行else大括號中的內容
if(運算式1) {
陳述句塊1;
}else if(運算式2){
陳述句塊2;
}else if(運算式3){
陳述句塊3;
}else{
陳述句塊4;
}
后續陳述句;
if(age>40){
printf("給房卡");
}else if(age>25){
printf("給名片");
}else if(age>18){
printf("給網卡");
}else{
printf("給好人卡");
}
printf("買煙\n");
- if嵌套
- if中可以繼續嵌套if, else中也可以繼續嵌套if
if(運算式1){
陳述句塊1;
if(運算式2){
陳述句塊2;
}
}else{
if(運算式3){
陳述句塊3;
}else{
陳述句塊4;
}
}
- if注意點
- 任何數值都有真偽性
#include <stdio.h>
int main(){
if(0){
printf("執行了if");
}else{
printf("執行了else"); // 被執行
}
}
- 當if else后面只有一條陳述句時, if else后面的大括號可以省略
// 極其不推薦寫法
int age = 17;
if (age >= 18)
printf("開網卡\n");
else
printf("喊家長來開\n");
- 當if else后面的大括號被省略時, else會自動和距離最近的一個if匹配
#include <stdio.h>
int main(){
if(0)
if(1)
printf("A\n");
else // 和if(1)匹配
printf("B\n");
else // 和if(0)匹配, 因為if(1)已經被匹配過了
if (1)
printf("C\n"); // 輸出C
else // 和if(1)匹配
printf("D\n");
}
-
- 如果if else省略了大括號, 那么后面不能定義變數
#include <stdio.h>
int main(){
if(1)
int number = 10; // 系統會報錯
printf("number = %i\n", number);
}
#include <stdio.h>
int main(){
if(0){
int number = 10;
}else
int value = 20; // 系統會報錯
printf("value = %i\n", value);
}
- C語言中分號(;)也是一條陳述句, 稱之為空陳述句
// 因為if(10 > 2)后面有一個分號, 所以系統會認為if省略了大括號
// if省略大括號時只能管控緊隨其后的那條陳述句, 所以只能管控分號
if(10 > 2);
{
printf("10 > 2");
}
// 輸出結果: 10 > 2
- 但凡遇到比較一個變數等于或者不等于某一個常量的時候,把常量寫在前面
#include <stdio.h>
int main(){
int a = 8;
// if(a = 10){// 錯誤寫法, 但不會報錯
if (10 == a){
printf("a的值是10\n");
}else{
printf("a的值不是10\n");
}
}
-
if練習
- 從鍵盤輸入一個整數,判斷其是否是偶數,如果是偶數就輸出YES,否則輸出NO;
- 接收用戶輸入的1~7的整數,根據用戶輸入的整數,輸出對應的星期幾
- 接收用戶輸入的一個整數month代表月份,根據月份輸出對應的季節
- 接收用戶輸入的兩個整數,判斷大小后輸出較大的那個數
- 接收用戶輸入的三個整數,判斷大小后輸出較大的那個數
- 接收用戶輸入的三個整數,排序后輸出
-
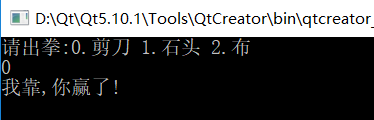
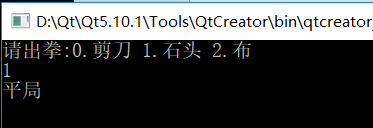
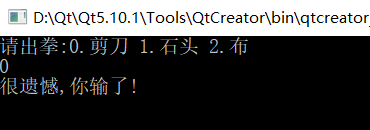
實作石頭剪刀布
剪刀石頭布游戲:
1)定義游戲規則
剪刀 干掉 布
石頭 干掉 剪刀
布 干掉石頭
2)顯示玩家開始猜拳
3)接收玩家輸入的內容
4)讓電腦隨機產生一種拳
5)判斷比較
(1)玩家贏的情況(顯示玩家贏了)
(2)電腦贏的情況(顯示電腦贏了)
(3)平局(顯示平局)
選擇結構switch
- 由于 if else if 還是不夠簡潔,所以switch 就應運而生了,他跟 if else if 互為補充關系,switch 提供了點的多路選擇
- 格式:
switch(運算式){
case 常量運算式1:
陳述句1;
break;
case 常量運算式2:
陳述句2;
break;
case 常量運算式n:
陳述句n;
break;
default:
陳述句n+1;
break;
}
- 語意:
- 計算"運算式"的值, 逐個與其后的"常量運算式"值相比較,當"運算式"的值與某個"常量運算式"的值相等時, 即執行其后的陳述句, 然后跳出switch陳述句
- 如果"運算式"的值與所有case后的"常量運算式"均不相同時,則執行default后的陳述句
- 示例:
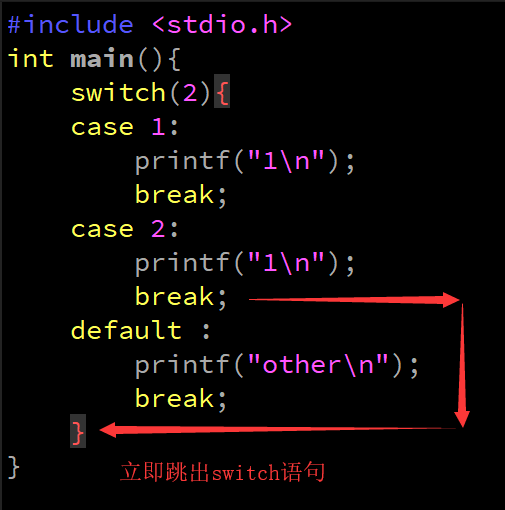
#include <stdio.h>
int main() {
int num = 3;
switch(num){
case 1:
printf("星期一\n");
break;
case 2:
printf("星期二\n");
break;
case 3:
printf("星期三\n");
break;
case 4:
printf("星期四\n");
break;
case 5:
printf("星期五\n");
break;
case 6:
printf("星期六\n");
break;
case 7:
printf("星期日\n");
break;
default:
printf("回火星去\n");
break;
}
}
- switch注意點
- switch條件運算式的型別必須是整型, 或者可以被提升為整型的值(char、short)
#include <stdio.h>
int main() {
switch(1.1){ // 報錯
case 1:
printf("星期一\n");
break;
case 2:
printf("星期二\n");
break;
default:
printf("回火星去\n");
break;
}
}
- +case的值只能是常量, 并且還必須是整型, 或者可以被提升為整型的值(char、short)
#include <stdio.h>
int main() {
int num = 3;
switch(1){
case 1:
printf("星期一\n");
break;
case 'a':
printf("星期二\n");
break;
case num: // 報錯
printf("星期三\n");
break;
case 4.0: // 報錯
printf("星期四\n");
break;
default:
printf("回火星去\n");
break;
}
}
- case后面常量運算式的值不能相同
#include <stdio.h>
int main() {
switch(1){
case 1: // 報錯
printf("星期一\n");
break;
case 1: // 報錯
printf("星期一\n");
break;
default:
printf("回火星去\n");
break;
}
}
- case后面要想定義變數,必須給case加上大括號
#include <stdio.h>
int main() {
switch(1){
case 1:{
int num = 10;
printf("num = %i\n", num);
printf("星期一\n");
break;
}
case 2:
printf("星期一\n");
break;
default:
printf("回火星去\n");
break;
}
}
- switch中只要任意一個case匹配, 其它所有的case和default都會失效. 所以如果case和default后面沒有break就會出現穿透問題
#include <stdio.h>
int main() {
int num = 2;
switch(num){
case 1:
printf("星期一\n");
break;
case 2:
printf("星期二\n"); // 被輸出
case 3:
printf("星期三\n"); // 被輸出
default:
printf("回火星去\n"); // 被輸出
break;
}
}
- switch中default可以省略
#include <stdio.h>
int main() {
switch(1){
case 1:
printf("星期一\n");
break;
case 2:
printf("星期一\n");
break;
}
}
- switch中default的位置不一定要寫到最后, 無論放到哪都會等到所有case都不匹配才會執行(穿透問題除外)
#include <stdio.h>
int main() {
switch(3){
case 1:
printf("星期一\n");
break;
default:
printf("Other,,,\n");
break;
case 2:
printf("星期一\n");
break;
}
}
- if和Switch轉換
- 看上去if和switch都可以實作同樣的功能, 那么在企業開發中我們什么時候使用if, 什么時候使用switch呢?
- if else if 針對于范圍的多路選擇
- switch 是針對點的多路選擇
- 判斷用戶輸入的資料是否大于100
#include <stdio.h>
int main() {
int a = -1;
scanf("%d", &a);
if(a > 100){
printf("用戶輸入的資料大于100");
}else{
printf("用戶輸入的資料不大于100");
}
}
#include <stdio.h>
int main() {
int a = -1;
scanf("%d", &a);
// 挺(T)萌(M)的(D)搞不定啊
switch (a) {
case 101:
case 102:
case 103:
case 104:
case 105:
printf("大于\n");
break;
default:
printf("不大于\n");
break;
}
}
- 練習
- 實作分數等級判定
要求用戶輸入一個分數,根據輸入的分數輸出對應的等級
A 90~100
B 80~89
C 70~79
D 60~69
E 0~59
- 實作+ - * / 簡單計算器
回圈結構
- C語言中提供了三大回圈結構, 分別是while、dowhile和for
- 回圈結構是程式中一種很重要的結構,
- 其特點是,在給定條件成立時,反復執行某程式段, 直到條件不成立為止,
- 給定的條件稱為"回圈條件",反復執行的程式段稱為"回圈體"
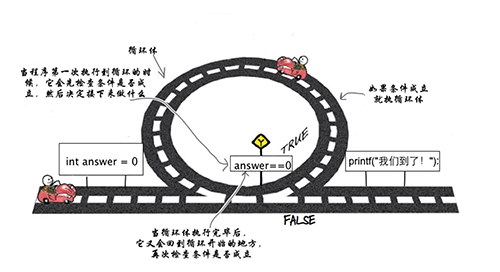
回圈結構while
- 格式:
while ( 回圈控制條件 ) {
回圈體中的陳述句;
能夠讓回圈結束的陳述句;
....
}
-
構成回圈結構的幾個條件
- 回圈控制條件
- 回圈退出的主要依據,來控制回圈到底什么時候退出
- 回圈體
- 回圈的程序中重復執行的代碼段
- 能夠讓回圈結束的陳述句(遞增、遞減、真、假等)
- 能夠讓回圈條件為假的依據,否則退出回圈
- 回圈控制條件
-
示例:
int count = 0;
while (count < 3) { // 回圈控制條件
printf("發射子彈~嗶嗶嗶嗶\n"); // 需要反復執行的陳述句
count++; // 能夠讓回圈結束的陳述句
}
- while回圈執行流程
- 首先會判定"回圈控制條件"是否為真, 如果為假直接跳到回圈陳述句后面
- 如果"回圈控制條件"為真, 執行一次回圈體, 然后再次判斷"回圈控制條件"是否為真, 為真繼續執行回圈體,為假跳出回圈
- 重復以上操作, 直到"回圈控制條件"為假為止
#include <stdio.h>
int main(){
int count = 4;
// 1.判斷回圈控制條件是否為真,此時為假所以跳過回圈陳述句
while (count < 3) {
printf("發射子彈~嗶嗶嗶嗶\n");
count++;
}
// 2.執行回圈陳述句后面的代碼, 列印"回圈執行完畢"
printf("回圈執行完畢\n");
}
#include <stdio.h>
int main(){
int count = 0;
// 1.判斷回圈控制條件是否為真,此時0 < 3為真
// 4.再次判斷回圈控制條件是否為真,此時1 < 3為真
// 7.再次判斷回圈控制條件是否為真,此時2 < 3為真
// 10.再次判斷回圈控制條件是否為真,此時3 < 3為假, 跳過回圈陳述句
while (count < 3) {
// 2.執行回圈體中的代碼, 列印"發子彈"
// 5.執行回圈體中的代碼, 列印"發子彈"
// 8.執行回圈體中的代碼, 列印"發子彈"
printf("發射子彈~嗶嗶嗶嗶\n");
// 3.執行"能夠讓回圈結束的陳述句" count = 1
// 6.執行"能夠讓回圈結束的陳述句" count = 2
// 9.執行"能夠讓回圈結束的陳述句" count = 3
count++;
}
// 11.執行回圈陳述句后面的代碼, 列印"回圈執行完畢"
printf("回圈執行完畢\n");
}
- while回圈注意點
- 任何數值都有真偽性
#include <stdio.h>
int main(){
while (1) { // 死回圈
printf("發射子彈~嗶嗶嗶嗶\n");
// 沒有能夠讓回圈結束的陳述句
}
}
- 當while后面只有一條陳述句時,while后面的大括號可以省略
#include <stdio.h>
int main(){
while (1) // 死回圈
printf("發射子彈~嗶嗶嗶嗶\n");
// 沒有能夠讓回圈結束的陳述句
}
- 如果while省略了大括號, 那么后面不能定義變數
#include <stdio.h>
int main(){
while (1) // 死回圈
int num = 10; // 報錯
// 沒有能夠讓回圈結束的陳述句
}
- C語言中分號(;)也是一條陳述句, 稱之為空陳述句
#include <stdio.h>
int main(){
int count = 0;
while (count < 3);{ // 死回圈
printf("發射子彈~嗶嗶嗶嗶\n");
count++;
}
}
- 最簡單的死回圈
// 死回圈一般在作業系統級別的應用程式會比較多, 日常開發中很少用
while (1);
- while練習
- 計算1 + 2 + 3 + …n的和
- 獲取1~100之間 7的倍數的個數
回圈結構do while
- 格式:
do {
回圈體中的陳述句;
能夠讓回圈結束的陳述句;
....
} while (回圈控制條件 );
- 示例
int count = 0;
do {
printf("發射子彈~嗶嗶嗶嗶\n");
count++;
}while(count < 10);
-
do-while回圈執行流程
- 首先不管while中的條件是否成立, 都會執行一次"回圈體"
- 執行完一次回圈體,接著再次判斷while中的條件是否為真, 為真繼續執行回圈體,為假跳出回圈
- 重復以上操作, 直到"回圈控制條件"為假為止
-
應用場景
- 口令校驗
#include<stdio.h>
int main()
{
int num = -1;
do{
printf("請輸入密碼,驗證您的身份\n");
scanf("%d", &num);
}while(123456 != num);
printf("主人,您終于回來了\n");
}
- while和dowhile應用場景
- 絕大多數情況下while和dowhile可以互換, 所以能用while就用while
- 無論如何都需要先執行一次回圈體的情況, 才使用dowhile
- do while 曾一度提議廢除,但是他在輸入性檢查方面還是有點用的
回圈結構for
- 格式:
for(初始化運算式;回圈條件運算式;回圈后的操作運算式) {
回圈體中的陳述句;
}
- 示例
for(int i = 0; i < 10; i++){
printf("發射子彈~嗶嗶嗶嗶\n");
}
-
for回圈執行流程
- 首先執行"初始化運算式",而且在整個回圈程序中,***只會執行一次***初始化運算式
- 接著判斷"回圈條件運算式"是否為真,為真執行回圈體中的陳述句
- 回圈體執行完畢后,接下來會執行"回圈后的操作運算式",然后再次判斷條件是否為真,為真繼續執行回圈體,為假跳出回圈
- 重復上述程序,直到條件不成立就結束for回圈
-
for回圈注意點:
- 和while一模一樣
- 最簡單的死回圈
for(;;);
-
for和while應用場景
- while能做的for都能做, 所以企業開發中能用for就用for, 因為for更為靈活
- 而且對比while來說for更節約記憶體空間
int count = 0; // 初始化運算式
while (count < 10) { // 條件運算式
printf("發射子彈~嗶嗶嗶嗶 %i\n", count);
count++; // 回圈后增量運算式
}
// 如果初始化運算式的值, 需要在回圈之后使用, 那么就用while
printf("count = %i\n", count);
// 注意: 在for回圈初始化運算式中定義的變數, 只能在for回圈后面的{}中訪問
// 所以: 如果初始化運算式的值, 不需要在回圈之后使用, 那么就用for
// 因為如果初始化運算式的值, 在回圈之后就不需要使用了 , 那么用while會導致性能問題
for (int count = 0; count < 10; count++) {
printf("發射子彈~嗶嗶嗶嗶 %i\n", count);
}
// printf("count = %i\n", count);
// 如果需要使用初始化運算式的值, 也可以將初始化運算式寫到外面
int count = 0;
for (; count < 10; count++) {
printf("發射子彈~嗶嗶嗶嗶\n", count);
}
printf("count = %i\n", count);
四大跳轉
-
C語言中提供了四大跳轉陳述句, 分別是return、break、continue、goto
-
break:
- 立即跳出switch陳述句或回圈
-
應用場景:
- switch
- 回圈結構
-
break注意點:
- break離開應用范圍,存在是沒有意義的
if(1) {
break; // 會報錯
}
- 在多層回圈中,一個break陳述句只向外跳一層
while(1) {
while(2) {
break;// 只對while2有效, 不會影響while1
}
printf("while1回圈體\n");
}
- break下面不可以有陳述句,因為執行不到
while(2){
break;
printf("打我啊!");// 執行不到
}
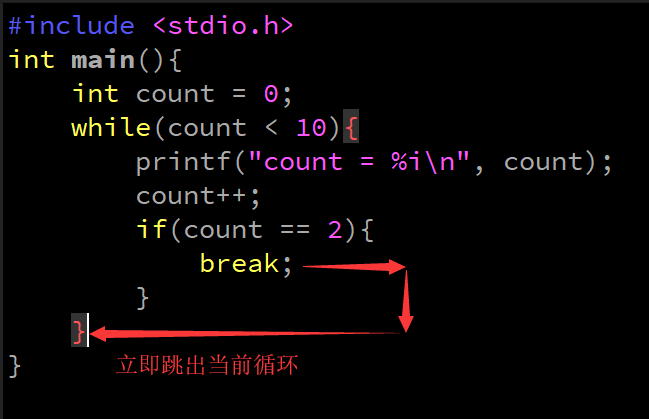
- continue
- 結束***本輪***回圈,進入***下一輪***回圈
- 應用場景:
- 回圈結構
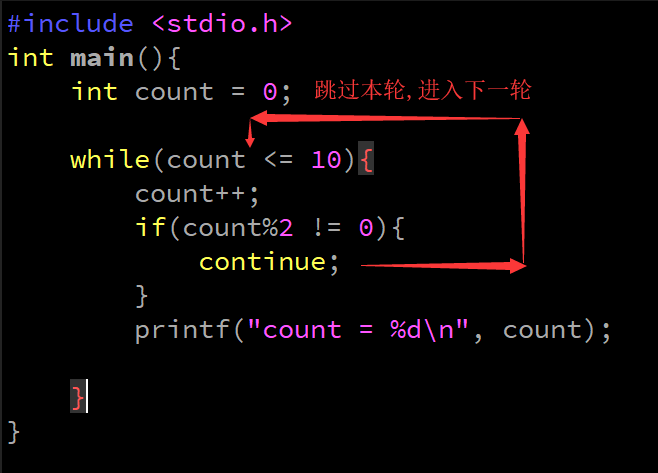
- 回圈結構
- continue注意點:
- continue離開應用范圍,存在是沒有意義的
if(1) {
continue; // 會報錯
}
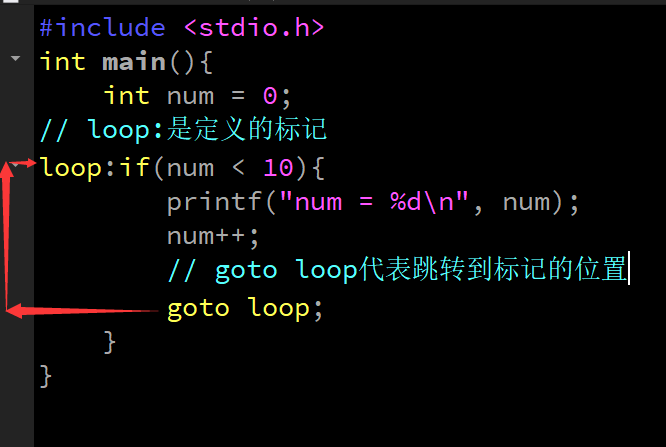
- goto
- 這是一個不太值得探討的話題,goto 會破壞結構化程式設計流程,它將使程式層次不清,且不易讀,所以慎用
- goto 陳述句,僅能在本函式內實作跳轉,不能實作跨函式跳轉(短跳轉),但是他在跳出多重回圈的時候效率還是蠻高的
#include <stdio.h>
int main(){
int num = 0;
// loop:是定義的標記
loop:if(num < 10){
printf("num = %d\n", num);
num++;
// goto loop代表跳轉到標記的位置
goto loop;
}
}
#include <stdio.h>
int main(){
while (1) {
while(2){
goto lnj;
}
}
lnj:printf("跳過了所有回圈");
}
- return
- 結束當前函式,將結果回傳給呼叫者
- 不著急, 放一放,學到函式我們再回頭來看它
回圈的嵌套
- 回圈結構的回圈體中存在其他的回圈結構,我們稱之為回圈嵌套
- 注意: 一般回圈嵌套不超過三層
- 外回圈執行的次數 * 內回圈執行的次數就是內回圈總共執行的次數
- 格式:
while(條件運算式) {
while回圈結構 or dowhile回圈結構 or for回圈結構
}
for(初始化運算式;回圈條件運算式;回圈后的操作運算式) {
while回圈結構 or dowhile回圈結構 or for回圈結構
}
do {
while回圈結構 or dowhile回圈結構 or for回圈結構
} while (回圈控制條件 );
- 回圈優化
- 在多重回圈中,如果有可能,應當將最長的回圈放在最內層,最短的回圈放在最外層,以減少 CPU 跨切回圈層的次數
for (row=0; row<100; row++) {
// 低效率:長回圈在最外層
for ( col=0; col<5; col++ ) {
sum = sum + a[row][col];
}
}
for (col=0; col<5; col++ ) {
// 高效率:長回圈在最內層
for (row=0; row<100; row++) {
sum = sum + a[row][col];
}
}
- 練習
- 列印好友串列
好友串列1
好友1
好友2
好友串列2
好友1
好友2
好友串列3
好友1
好友2
for (int i = 0; i < 4; i++) {
printf("好友串列%d\n", i+1);
for (int j = 0; j < 4; j++) {
printf(" 角色%d\n", j);
}
}
圖形列印
- 一重回圈解決線性的問題,而二重回圈和三重回圈就可以解決平面和立體的問題了
- 列印矩形
****
****
****
// 3行4列
// 外回圈控制行數
for (int i = 0; i < 3; i++) {
// 內回圈控制列數
for (int j = 0; j < 4; j++) {
printf("*");
}
printf("\n");
}
- 列印三角形
- 尖尖朝上,改變內回圈的條件運算式,讓內回圈的條件運算式隨著外回圈的i值變化
- 尖尖朝下,改變內回圈的初始化運算式,讓內回圈的初始化運算式隨著外回圈的i值變化
*
**
***
****
*****
/*
最多列印5行
最多列印5列
每一行和每一列關系是什么? 列數<=行數
*/
for(int i = 0; i< 5; i++) {
for(int j = 0; j <= i; j++) {
printf("*");
}
printf("\n");
}
*****
****
***
**
*
for(int i = 0; i< 5; i++) {
for(int j = i; j < 5; j++) {
printf("*");
}
printf("\n");
}
- 練習
- 列印特殊三角形
1
12
123
for (int i = 0; i < 3; i++) {
for (int j = 0; j <= i; j++) {
printf("%d", j+1);
}
printf("\n");
}
- 列印特殊三角形
1
22
333
for (int i = 1; i <= 3; i++) {
for (int j = 1; j <= i; j++) {
printf("%d", i);
}
printf("\n");
}
- 列印特殊三角形
--*
-***
*****
for (int i = 0; i <= 5; i++) {
for (int j = 0; j < 5 - i; j++) {
printf("-");
}
for (int m = 0; m < 2*i+1; m++) {
printf("*");
}
printf("\n");
}
- 列印99乘法表
1 * 1 = 1
1 * 2 = 2 2 * 2 = 4
1 * 3 = 3 2 * 3 = 6 3 * 3 = 9
for (int i = 1; i <= 9; i++) {
for (int j = 1; j <= i; j++) {
printf("%d * %d = %d \t", j, i, (j * i));
}
printf("\n");
}
函式基本概念
- C源程式是由函陣列成的
- 例如: 我們前面學習的課程當中,通過main函式+scanf函式+printf函式+邏輯代碼就可以組成一個C語言程式
- C語言不僅提供了極為豐富的庫函式, 還允許用戶建立自己定義的函式,用戶可把自己的演算法撰寫成一個個相對獨立的函式,然后再需要的時候呼叫它
- 例如:你用C語言撰寫了一個MP3播放器程式,那么它的程式結構如下圖所示
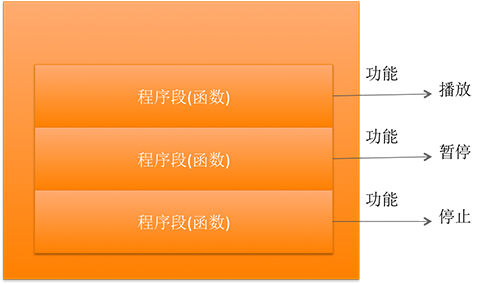
- 可以說C程式的全部作業都是由各式各樣的函式完成的,所以也把C語言稱為函式式語言
函式的分類
- 在C語言中可從不同的角度對函式分類
- 從函式定義的角度看,函式可分為庫函式和用戶定義函式兩種
- 庫函式: 由C語言系統提供,用戶無須定義,也不必在程式中作型別說明,只需在程式前包含有該函式原型的頭檔案即可在程式中直接呼叫,在前面各章的例題中反復用到printf、scanf、getchar、putchar等函式均屬此類
- ***用戶定義函式:***由用戶按需撰寫的函式,對于用戶自定義函式,不僅要在程式中定義函式本身,而且在主調函式模塊中還必須對該被調函式進行型別說明,然后才能使用
- 從函式執行結果的角度來看, 函式可分為有回傳值函式和無回傳值函式兩種
- 有回傳值函式: 此類函式被呼叫執行完后將向呼叫者回傳一個執行結果,稱為函式回傳值,(必須指定回傳值型別和使用return關鍵字回傳對應資料)
- 無回傳值函式: 此類函式用于完成某項特定的處理任務,執行完成后不向呼叫者回傳函式值,(回傳值型別為void, 不用使用return關鍵字回傳對應資料)
- 從主調函式和被調函式之間資料傳送的角度看,又可分為無參函式和有參函式兩種
- 無參函式: 在函式定義及函式說明及函式呼叫中均不帶引數,主調函式和被調函式之間不進行引數傳送,
- 有參函式: 在函式定義及函式說明時都有引數,稱為形式引數(簡稱為形參),在函式呼叫時也必須給出引數,稱為實際引數(簡稱為實參)
函式的定義
-
定義函式的目的
- 將一個常用的功能封裝起來,方便以后呼叫
-
自定義函式的書寫格式
回傳值型別 函式名(引數型別 形式引數1,引數型別 形式引數2,…) {
函式體;
回傳值;
}
- 示例
int main(){
printf("hello world\n");
retrun 0;
}
- 定義函式的步驟
- 函式名:函式叫什么名字
- 函式體:函式是干啥的,里面包含了什么代碼
- 回傳值型別: 函式執行完畢回傳什么和呼叫者
- 無參無回傳值函式定義
- 沒有回傳值時return可以省略
- 格式:
void 函式名() { 函式體; }- 示例:
// 1.沒有回傳值/沒有形參 // 如果一個函式不需要回傳任何資料給呼叫者, 那么回傳值型別就是void void printRose() { printf(" {@}\n"); printf(" |\n"); printf(" \\|/\n"); // 注意: \是一個特殊的符號(轉意字符), 想輸出\必須寫兩個斜線 printf(" |\n"); // 如果函式不需要回傳資料給呼叫者, 那么函式中的return可以不寫 }
- 無參有回傳值函式定義
- 格式:
回傳值型別 函式名() { 函式體; return 值; }- 示例:
int getMax() { printf("請輸入兩個整數, 以逗號隔開, 以回車結束\n"); int number1, number2; scanf("%i,%i", &number1, &number2); int max = number1 > number2 ? number1 : number2; return max; }
- 有參無回傳值函式定義
- 形式引數表串列的格式:
型別 變數名,型別 變數2,...... - 格式:
void 函式名(引數型別 形式引數1,引數型別 形式引數2,…) { 函式體; }- 示例:
void printMax(int value1, int value2) { int max = value1 > value2 ? value1 : value2; printf("max = %i\n", max); } - 形式引數表串列的格式:
- 有參有回傳值函式定義
- 格式:
回傳值型別 函式名(引數型別 形式引數1,引數型別 形式引數2,…) { 函式體; return 0; }- 示例:
int printMax(int value1, int value2) { int max = value1 > value2 ? value1 : value2; return max; }
- 函式定義注意
-
- 函式名稱不能相同
void test() { } void test() { // 報錯 }
函式的引數和回傳值
- 形式引數
- 在***定義函式***時,函式名后面小括號()中定義的變數稱為形式引數,簡稱形參
- 形參變數只有在被呼叫時才分配記憶體單元,在呼叫結束時,即刻釋放所分配的記憶體單元,
- 因此,形參只有在函式內部有效,函式呼叫結束回傳主調函式后則不能再使用該形參變數
int max(int number1, int number2) // 形式引數
{
return number1 > number2 ? number1 : number2;
}
- 實際引數
- 在***呼叫函式***時, 傳入的值稱為實際引數,簡稱實參
- 實參可以是常量、變數、運算式、函式等,無論實參是何種型別的量,在進行函式呼叫時,它們都必須具有確定的值,以便把這些值傳送給形參
- 因此應預先用賦值,輸入等辦法使實參獲得確定值
int main() {
int num = 99;
// 88, num, 22+44均能得到一個確定的值, 所以都可以作為實參
max(88, num, 22+44); // 實際引數
return 0;
}
- 形參、實參注意點
- 呼叫函式時傳遞的實參個數必須和函式的形參個數必須保持一致
int max(int number1, int number2) { // 形式引數 return number1 > number2 ? number1 : number2; } int main() { // 函式需要2個形參, 但是我們只傳遞了一個實參, 所以報錯 max(88); // 實際引數 return 0; } - 形參實參型別不一致, 會自動轉換為形參型別
void change(double number1, double number2) {// 形式引數
// 輸出結果: 10.000000, 20.000000
// 自動將實參轉換為double型別后保存
printf("number1 = %f, number2 = %f", number1, number2);
}
int main() {
change(10, 20);
return 0;
}
- 當使用基本資料型別(char、int、float等)作為實參時,實參和形參之間只是值傳遞,修改形參的值并不影響到實參函式可以沒有形參
void change(int number1, int number2) { // 形式引數 number1 = 250; // 不會影響實參 number2 = 222; } int main() { int a = 88; int b = 99; change(a, b); printf("a = %d, b = %d", a, b); // 輸出結果: 88, 99 return 0; }
- 回傳值型別注意點
- 如果沒有寫回傳值型別,默認是int
max(int number1, int number2) {// 形式引數 return number1 > number2 ? number1 : number2; } - 函式回傳值的型別和return實際回傳的值型別應保持一致,如果兩者不一致,則以回傳值型別為準,自動進行型別轉換
int height() {
return 3.14;
}
int main() {
double temp = height();
printf("%lf", temp);// 輸出結果: 3.000000
}
- 一個函式內部可以多次使用return陳述句,但是return陳述句后面的代碼就不再被執行
int max(int number1, int number2) {// 形式引數 return number1 > number2 ? number1 : number2; printf("執行不到"); // 執行不到 return 250; // 執行不到 }
函式的宣告
- 在C語言中,函式的定義順序是有講究的:
- 默認情況下,只有后面定義的函式才可以呼叫前面定義過的函式
- 如果想把函式的定義寫在main函式后面,而且main函式能正常呼叫這些函式,那就必須在main函式的前面進行函式的宣告, 否則
- 系統搞不清楚有沒有這個函式
- 系統搞不清楚這個函式接收幾個引數
- 系統搞不清楚這個函式的回傳值型別是什么
- 所以函式宣告,就是在函式呼叫之前告訴系統, 該函式叫什么名稱, 該函式接收幾個引數, 該函式的回傳值型別是什么
- 函式的宣告格式:
- 將自定義函式時{}之前的內容拷貝到呼叫之間即可
- 例如:
int max( int a, int b ); - 或者:
int max( int, int );
// 函式宣告
void getMax(int v1, int v2);
int main(int argc, const char * argv[]) {
getMax(10, 20); // 呼叫函式
return 0;
}
// 函式實作
void getMax(int v1, int v2) {
int max = v1 > v2 ? v1 : v2;
printf("max = %i\n", max);
}
- 函式的宣告與實作的關系
- 宣告僅僅代表著告訴系統一定有這個函式, 和這個函式的引數、回傳值是什么
- 實作代表著告訴系統, 這個函式具體的業務邏輯是怎么運作的
- 函式宣告注意點:
- 函式的實作不能重復, 而函式的宣告可以重復
// 函式宣告 void getMax(int v1, int v2); void getMax(int v1, int v2); void getMax(int v1, int v2); // 不會報錯 int main(int argc, const char * argv[]) { getMax(10, 20); // 呼叫函式 return 0; } // 函式實作 void getMax(int v1, int v2) { int max = v1 > v2 ? v1 : v2; printf("max = %i\n", max); } - 函式宣告可以寫在函式外面,也可以寫在函式里面, 只要在呼叫之前被宣告即可
int main(int argc, const char * argv[]) { void getMax(int v1, int v2); // 函式宣告, 不會報錯 getMax(10, 20); // 呼叫函式 return 0; } // 函式實作 void getMax(int v1, int v2) { int max = v1 > v2 ? v1 : v2; printf("max = %i\n", max); } - 當被調函式的函式定義出現在主調函式之前時,在主調函式中也可以不對被調函式再作宣告
// 函式實作
void getMax(int v1, int v2) {
int max = v1 > v2 ? v1 : v2;
printf("max = %i\n", max);
}
int main(int argc, const char * argv[]) {
getMax(10, 20); // 呼叫函式
return 0;
}
- 如果被調函式的回傳值是整型時,可以不對被調函式作說明,而直接呼叫
int main(int argc, const char * argv[]) { int res = getMin(5, 3); // 不會報錯 printf("result = %d\n", res ); return 0; } int getMin(int num1, int num2) {// 回傳int, 不用宣告 return num1 < num2 ? num1 : num2; }
main函式分析
- main的含義:
- main是函式的名稱, 和我們自定義的函式名稱一樣, 也是一個識別符號
- 只不過main這個名稱比較特殊, 程式已啟動就會自動呼叫它
- return 0;的含義:
- 告訴系統main函式是否正確的被執行了
- 如果main函式的執行正常, 那么就回傳0
- 如果main函式執行不正常, 那么就回傳一個非0的數
- 回傳值型別:
- 一個函式return后面寫的是什么型別, 函式的回傳值型別就必須是什么型別, 所以寫int
- 形參串列的含義
- int argc :
- 系統在啟動程式時呼叫main函式時傳遞給argv的值的個數
- const char * argv[] :
- 系統在啟動程式時傳入的的值, 默認情況下系統只會傳入一個值, 這個值就是main函式執行檔案的路徑
- 也可以通過命令列或專案設定傳入其它引數
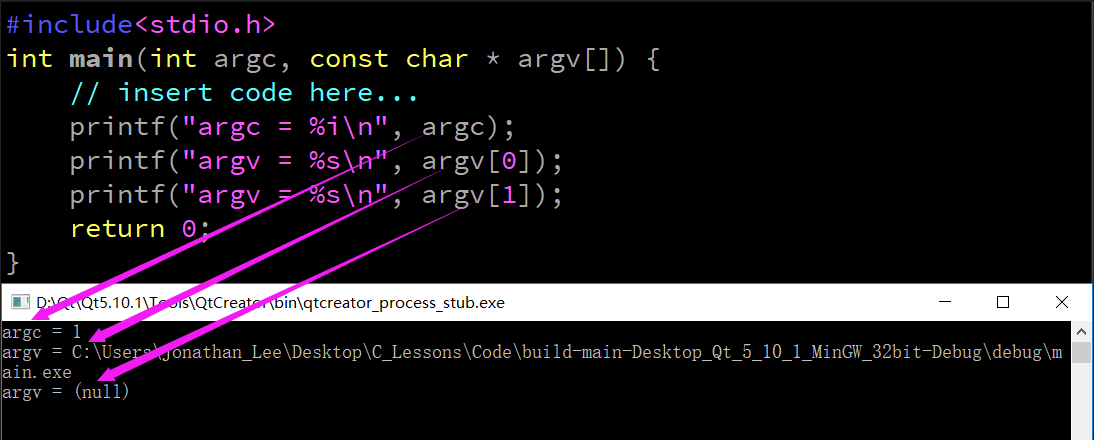
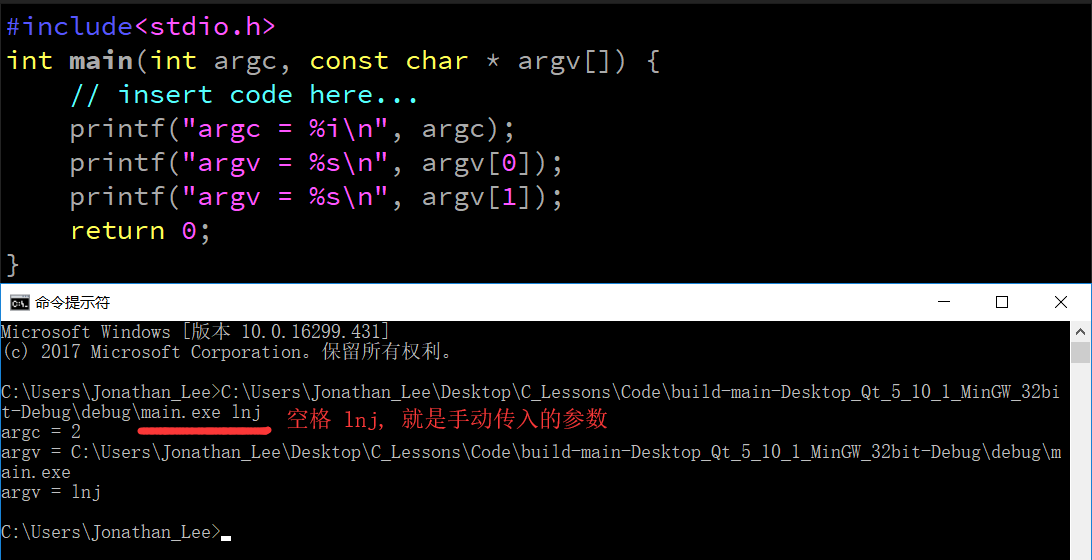
- int argc :
- 函式練習
- 寫一個函式從鍵盤輸入三個整型數字,找出其最大值
- 寫一個函式求三個數的平均值
遞回函式(了解)
- 什么是遞回函式?
- 一個函式在它的函式體內呼叫它自身稱為遞回呼叫
void function(int x){ function(x); } - 遞回函式構成條件
- 自己搞自己
- 存在一個條件能夠讓遞回結束
- 問題的規模能夠縮小
- 示例:
- 獲取用戶輸入的數字, 直到用戶輸入一個正數為止
void getNumber(){
int number = -1;
while (number < 0) {
printf("請輸入一個正數\n");
scanf("%d", &number);
}
printf("number = %d\n", number);
}
void getNumber2(){
int number = -1;
printf("請輸入一個正數abc\n");
scanf("%d", &number);
if (number < 0) {
// 負數
getNumber2();
}else{
// 正數
printf("number = %d\n", number);
}
}
-
遞回和回圈區別
- 能用回圈實作的功能,用遞回都可以實作
- 遞回常用于"回溯", “樹的遍歷”,"圖的搜索"等問題
- 但代碼理解難度大,記憶體消耗大(易導致堆疊溢位), 所以考慮到代碼理解難度和記憶體消耗問題, 在企業開發中一般能用回圈都不會使用遞回
-
遞回練習
- 有5個人坐在一起,問第5個人多少歲?他說比第4個人大兩歲,問 第4個人歲數,他說比第3個人大兩歲,問第3個人,又說比第2個 人大兩歲,問第2個人,說比第1個人大兩歲,最后問第1個人, 他說是10歲,請問第5個人多大?
- 用遞回法求N的階乘
- 設計一個函式用來計算B的n次方
進制基本概念
-
什么是進制?
- 進制是一種計數的方式,數值的表示形式
-
常見的進制
- 十進制、二進制、八進制、十六進制
-
進制書寫的格式和規律
- 十進制 0、1、2、3、4、5、6、7、8、9 逢十進一
- 二進制 0、1 逢二進一
- 書寫形式:需要以0b或者0B開頭,例如: 0b101
- 八進制 0、1、2、3、4、5、6、7 逢八進一
- 書寫形式:在前面加個0,例如: 061
- 十六進制 0、1、2、3、4、5、6、7、8、9、A、B、C、D、E、F 逢十六進一
- 書寫形式:在前面加個0x或者0X,例如: 0x45
-
練習
- 1.用不同進制表示如下有多少個方格

- 2.判斷下列數字是否合理
00011 0x001 0x7h4 10.98 0986 .089-109 +178 0b325 0b0010 0xffdc 96f 96.0f 96.oF -.003
進制轉換
- 10 進制轉 2 進制
- 除2取余, 余數倒序; 得到的序列就是二進制表示形式
- 例如: 將十進制(97) 10轉換為二進制數
- 2 進制轉 10 進制
- 每一位二進制進制位的值 * 2的當前索引次冪; 再將所有位求出的值相加
- 例如: 將二進制01100100轉換為十進制
01100100 索引從右至左, 從零開始 第0位: 0 * 2^0 = 0; 第1位: 0 * 2^1 = 0; 第2位: 1 * 2^2 = 4; 第3位: 0 * 2^3 = 0; 第4位: 0 * 2^4 = 0; 第5位: 1 * 2^5 = 32; 第6位: 1 * 2^6 = 64; 第7位: 0 * 2^7 = 0; 最終結果為: 0 + 0 + 4 + 0 + 0 + 32 + 64 + 0 = 100
- 2 進制轉 8 進制
- 三個二進制位代表一個八進制位, 因為3個二進制位的最大值是7,而八進制是逢8進1
- 例如: 將二進制01100100轉換為八進制數
從右至左每3位劃分為8進制的1位, 不夠前面補0 001 100 100 第0位: 100 等于十進制 4 第1位: 100 等于十進制 4 第2位: 001 等于十進制 1 最終結果: 144就是轉換為8進制的值
- 2 進制轉 16 進制
- 四個二進制位代表一個十六進制位,因為4個二進制位的最大值是15,而十六進制是逢16進1
- 例如: 將二進制01100100轉換為十六進制數
從右至左每4位劃分為16進制的1位, 不夠前面補0 0110 0100 第0位: 0100 等于十進制 4 第1位: 0110 等于十進制 6 最終結果: 64就是轉換為16進制的值
- 其它進制轉換為十進制
- 系數 * 基數 ^ 索引 之和
十進制 --> 十進制 12345 = 10000 + 2000 + 300 + 40 + 5 = (1 * 10 ^ 4) + (2 * 10 ^ 3) + (3 * 10 ^ 2) + (4 * 10 ^ 1) + (5 * 10 ^ 0) = (1 * 10000) + (2 + 1000) + (3 * 100) + (4 * 10) + (5 * 1) = 10000 + 2000 + 300 + 40 + 5 = 12345 規律: 其它進制轉換為十進制的結果 = 系數 * 基數 ^ 索引 之和 系數: 每一位的值就是一個系數 基數: 從x進制轉換到十進制, 那么x就是基數 索引: 從最低位以0開始, 遞增的數二進制 --> 十進制 543210 101101 = (1 * 2 ^ 5) + (0 * 2 ^ 4) + (1 * 2 ^ 3) + (1 * 2 ^ 2) + (0 * 2 ^ 1) + (1 * 2 ^ 0) = 32 + 0 + 8 + 4 + 0 + 1 = 45 八進制 --> 十進制 016 = (0 * 8 ^ 2) + (1 * 8 ^ 1) + (6 * 8 ^ 0) = 0 + 8 + 6 = 14 十六進制 --> 十進制 0x11f = (1 * 16 ^ 2) + (1 * 16 ^ 1) + (15 * 16 ^ 0) = 256 + 16 + 15 = 287
- 十進制快速轉換為其它進制
- 十進制除以
基數取余, 倒敘讀取
十進制 --> 二進制 100 --> 1100100 100 / 2 = 50 0 50 / 2 = 25 0 25 / 2 = 12 1 12 / 2 = 6 0 6 / 2 = 3 0 3 / 2 = 1 1 1 / 2 = 0 1 十進制 --> 八進制 100 --> 144 100 / 8 = 12 4 12 / 8 = 1 4 1 / 8 = 0 1 十進制 --> 十六進制 100 --> 64 100 / 16 = 6 4 6 / 16 = 0 6 - 十進制除以
十進制小數轉換為二進制小數
- 整數部分,直接轉換為二進制即可
- 小數部分,使用"乘2取整,順序排列"
- 用2乘十進制小數,可以得到積,將積的整數部分取出,再用2乘余下的小數部分,直到積中的小數部分為零,或者達到所要求的精度為止
- 然后把取出的整數部分按順序排列起來, 即是小數部分二進制
- 最后將整數部分的二進制和小數部分的二進制合并起來, 即是一個二進制小數
- 例如: 將12.125轉換為二進制
// 整數部分(除2取余)
12
/ 2
------
6 // 余0
/ 2
------
3 // 余0
/ 2
------
1 // 余1
/ 2
------
0 // 余1
//12 --> 1100
// 小數部分(乘2取整數積)
0.125
* 2
------
0.25 //0
0.25
* 2
------
0.5 //0
0.5
* 2
------
1.0 //1
0.0
// 0.125 --> 0.001
// 12.8125 --> 1100.001
二進制小數轉換為十進制小數
- 整數部分按照二進制轉十進制即可
- 小數部分從最高位開始乘以2的負n次方, n從1開始
- 例如: 將 1100.001轉換為十進制
// 整數部分(乘以2的n次方, n從0開始)
0 * 2^0 = 0
0 * 2^1 = 0
1 * 2^2 = 4
1 * 2^3 = 8
// 1100 == 8 + 4 + 0 + 0 == 12
// 小數部分(乘以2的負n次方, n從0開始)
0 * (1/2) = 0
0 * (1/4) = 0
1 * (1/8) = 0.125
// .100 == 0 + 0 + 0.125 == 0.125
// 1100.001 --> 12.125
- 練習:
- 將0.8125轉換為二進制
- 將0.1101轉換為十進制
0.8125
* 2
--------
1.625 // 1
0.625
* 2
--------
1.25 // 1
0.25
* 2
--------
0.5 // 0
* 2
--------
1.0 // 1
0.0
// 0. 8125 --> 0.1101
1*(1/2) = 0.5
1*(1/4)=0.25
0*(1/8)=0
1*(1/16)=0.0625
//0.1101 --> 0.5 + 0.25 + 0 + 0.0625 == 0.8125
原碼反碼補碼
- 計算機只能識別0和1, 所以計算機中存盤的資料都是以0和1的形式存盤的
- 資料在計算機內部是以補碼的形式儲存的, 所有資料的運算都是以補碼進行的
- 正數的原碼、反碼和補碼
- 正數的原碼、反碼和補碼都是它的二進制
- 例如: 12的原碼、反碼和補碼分別為
0000 0000 0000 0000 0000 0000 0000 11000000 0000 0000 0000 0000 0000 0000 11000000 0000 0000 0000 0000 0000 0000 1100
- 負數的原碼、反碼和補碼
- 二進制的最高位我們稱之為符號位, 最高位是0代表是一個正數, 最高位是1代表是一個負數
- 一個負數的原碼, 是將該負數的二進制最高位變為1
- 一個負數的反碼, 是將該數的原碼
除了符號位以外的其它位取反 - 一個負數的補碼, 就是它的反碼 + 1
- 例如: -12的原碼、反碼和補碼分別為
0000 0000 0000 0000 0000 0000 0000 1100 // 12二進制 1000 0000 0000 0000 0000 0000 0000 1100 // -12原碼 1111 1111 1111 1111 1111 1111 1111 0011 // -12反碼 1111 1111 1111 1111 1111 1111 1111 0100 // -12補碼 - 負數的原碼、反碼和補碼逆向轉換
- 反碼 = 補碼-1
- 原碼= 反碼最高位不變, 其它位取反
1111 1111 1111 1111 1111 1111 1111 0100 // -12補碼 1111 1111 1111 1111 1111 1111 1111 0011 // -12反碼 1000 0000 0000 0000 0000 0000 0000 1100 // -12原碼
- 為什么要引入反碼和補碼
- 在學習本節內容之前,大家必須明白一個東西, 就是計算機只能做加法運算, 不能做減法和乘除法, 所以的減法和乘除法內部都是用加法來實作的
- 例如: 1 - 1, 內部其實就是 1 + (-1);
- 例如: 3 * 3, 內部其實就是 3 + 3 + 3;
- 例如: 9 / 3, 內部其實就是 9 + (-3) + (-3) + (-3);
- 首先我們先來觀察一下,如果只有原碼會存盤什么問題
- 很明顯, 通過我們的觀察, 如果只有原碼, 1-1的結果不對
// 1 + 1 0000 0000 0000 0000 0000 0000 0000 0001 // 1原碼 +0000 0000 0000 0000 0000 0000 0000 0001 // 1原碼 --------------------------------------- 0000 0000 0000 0000 0000 0000 0000 0010 == 2 // 1 - 1; 1 + (-1); 0000 0000 0000 0000 0000 0000 0000 0001 // 1原碼 +1000 0000 0000 0000 0000 0000 0000 0001 // -1原碼 --------------------------------------- 1000 0000 0000 0000 0000 0000 0000 0010 == -2
- 在學習本節內容之前,大家必須明白一個東西, 就是計算機只能做加法運算, 不能做減法和乘除法, 所以的減法和乘除法內部都是用加法來實作的
- 正是因為對于減法來說,如果使用原碼結果是不正確的, 所以才引入了反碼
- 通過反碼計算減法的結果, 得到的也是一個反碼;
- 將計算的結果符號位不變其余位取反,就得到了計算結果的原碼
- 通過對原碼的轉換, 很明顯我們計算的結果是-0, 符合我們的預期
// 1 - 1; 1 + (-1); 0000 0000 0000 0000 0000 0000 0000 0001 // 1反碼 1111 1111 1111 1111 1111 1111 1111 1110 // -1反碼 --------------------------------------- 1111 1111 1111 1111 1111 1111 1111 1111 // 計算結果反碼 1000 0000 0000 0000 0000 0000 0000 0000 // 計算結果原碼 == -0 - 雖然反碼能夠滿足我們的需求, 但是對于0來說, 前面的負號沒有任何意義, 所以才引入了補碼
- 由于int只能存盤4個位元組, 也就是32位資料, 而計算的結果又33位, 所以最高位溢位了,符號位變成了0, 所以最終得到的結果是0
// 1 - 1; 1 + (-1); 0000 0000 0000 0000 0000 0000 0000 0001 // 1補碼 1111 1111 1111 1111 1111 1111 1111 1111 // -1補碼 --------------------------------------- 10000 0000 0000 0000 0000 0000 0000 0000 // 計算結果補碼 0000 0000 0000 0000 0000 0000 0000 0000 // == 0
位運算子
- 程式中的所有資料在計算機記憶體中都是以二進制的形式儲存的,
- 位運算就是直接對整數在記憶體中的二進制位進行操作
- C語言提供了6個位操作運算子, 這些運算子只能用于整型運算元
| 符號 | 名稱 | 運算結果 |
|---|---|---|
| & | 按位與 | 同1為1 |
| | | 按位或 | 有1為1 |
| ^ | 按位異或 | 不同為1 |
| ~ | 按位取反 | 0變1,1變0 |
| << | 按位左移 | 乘以2的n次方 |
| >> | 按位右移 | 除以2的n次方 |
- 按位與:
- 只有對應的兩個二進位均為1時,結果位才為1,否則為0
- 規律: 二進制中,與1相&就保持原位,與0相&就為0
9&5 = 1
1001
&0101
------
0001
- 按位或:
- 只要對應的二個二進位有一個為1時,結果位就為1,否則為0
9|5 = 13
1001
|0101
------
1101
- 按位異或
- 當對應的二進位相異(不相同)時,結果為1,否則為0
- 規律:
- 相同整數相的結果是0,比如55=0
- 多個整數相^的結果跟順序無關,例如: 567=576
- 同一個數異或另外一個數兩次, 結果還是那個數,例如: 577 = 5
9^5 = 12
1001
^0101
------
1100
- 按位取反
- 各二進位進行取反(0變1,1變0)
~9 =-10
0000 0000 0000 0000 0000 1001 // 取反前
1111 1111 1111 1111 1111 0110 // 取反后
// 根據負數補碼得出結果
1111 1111 1111 1111 1111 0110 // 補碼
1111 1111 1111 1111 1111 0101 // 反碼
1000 0000 0000 0000 0000 1010 // 原始碼 == -10
- 位運算應用場景:
- 判斷奇偶(按位或)
偶數: 的二進制是以0結尾 8 -> 1000 10 -> 1010 奇數: 的二進制是以1結尾 9 -> 1001 11 -> 1011 任何數和1進行&操作,得到這個數的最低位 1000 &0001 ----- 0000 // 結果為0, 代表是偶數 1011 &0001 ----- 0001 // 結果為1, 代表是奇數- 權限系統
enum Unix { S_IRUSR = 256,// 100000000 用戶可讀 S_IWUSR = 128,// 10000000 用戶可寫 S_IXUSR = 64,// 1000000 用戶可執行 S_IRGRP = 32,// 100000 組可讀 S_IWGRP = 16,// 10000 組可寫 S_IXGRP = 8,// 1000 組可執行 S_IROTH = 4,// 100 其它可讀 S_IWOTH = 2,// 10 其它可寫 S_IXOTH = 1 // 1 其它可執行 }; // 假設設定用戶權限為可讀可寫 printf("%d\n", S_IRUSR | S_IWUSR); // 384 // 110000000- 交換兩個數的值(按位異或)
a = a^b; b = b^a; a = a^b;
- 按位左移
- 把整數a的各二進位全部左移n位,高位丟棄,低位補0
- 由于左移是丟棄最高位,0補最低位,所以符號位也會被丟棄,左移出來的結果值可能會改變正負性
- 規律: 左移n位其實就是乘以2的n次方
- 把整數a的各二進位全部左移n位,高位丟棄,低位補0
2<<1; //相當于 2 *= 2 // 4
0010
<<0100
2<<2; //相當于 2 *= 2^2; // 8
0010
<<1000
- 按位右移
- 把整數a的各二進位全部右移n位,保持符號位不變
- 為正數時, 符號位為0,最高位補0
- 為負數時,符號位為1,最高位是補0或是補1(取決于編譯系統的規定)
- 規律: 快速計算一個數除以2的n次方
- 把整數a的各二進位全部右移n位,保持符號位不變
2>>1; //相當于 2 /= 2 // 1
0010
>>0001
4>>2; //相當于 4 /= 2^2 // 1
0100
>>0001
- 練習:
- 寫一個函式把一個10進制數按照二進制格式輸出
#include <stdio.h>
void printBinary(int num);
int main(int argc, const char * argv[]) {
printBinary(13);
}
void printBinary(int num){
int len = sizeof(int)*8;
int temp;
for (int i=0; i<len; i++) {
temp = num; //每次都在原數的基礎上進行移位運算
temp = temp>>(31-i); //每次移動的位數
int t = temp&1; //取出最后一位
if(i!=0&&i%4==0)printf(" "); printf("%d",t);
}
}
變數記憶體分析
- 記憶體模型
- 記憶體模型是線性的(有序的)
- 對于 32 機而言,最大的記憶體地址是2^32次方bit(4294967296)(4GB)
- 對于 64 機而言,最大的記憶體地址是2^64次方bit(18446744073709552000)(171億GB)

- CPU 讀寫記憶體
- CPU 在運作時要明確三件事
- 存盤單元的地址(地址資訊)
- 器件的選擇,讀 or 寫 (控制資訊)
- 讀寫的資料 (資料資訊)
- CPU 在運作時要明確三件事
- 如何明確這三件事情
- 通過地址總線找到存盤單元的地址
- 通過控制總線發送記憶體讀寫指令
- 通過資料總線傳輸需要讀寫的資料
- 地址總線: 地址總線寬度決定了CPU可以訪問的物理地址空間(尋址能力)
- 例如: 地址總線的寬度是1位, 那么表示可以訪問 0 和 1的記憶體
- 例如: 地址總線的位數是2位, 那么表示可以訪問 00、01、10、11的記憶體
- 資料總線: 資料總線的位數決定CPU單次通信能交換的資訊數量
- 例如: 資料總線:的寬度是1位, 那么一次可以傳輸1位二進制資料
- 例如: 地址總線的位數是2位,那么一次可以傳輸2位二進制資料
- 控制總線: 用來傳送各種控制信號
-
寫入流程
- CPU 通過地址線將找到地址為 FFFFFFFB 的記憶體
- CPU 通過控制線發出記憶體寫入命令,選中存盤器芯片,并通知它,要其寫入資料,
- CPU 通過資料線將資料 8 送入記憶體 FFFFFFFB 單元中
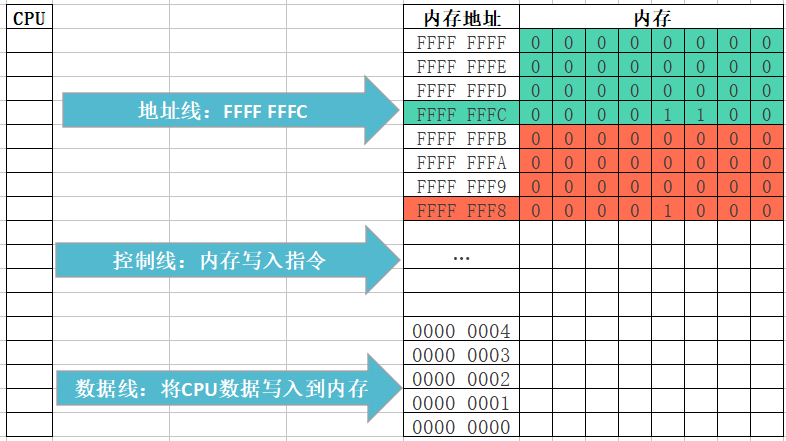
-
讀取流程
- CPU 通過地址線將找到地址為 FFFFFFFB 的記憶體
- CPU 通過控制線發出記憶體讀取命令,選中存盤器芯片,并通知它,將要從中讀取資料
- 存盤器將 FFFFFFFB 號單元中的資料 8 通過資料線送入 CPU暫存器中
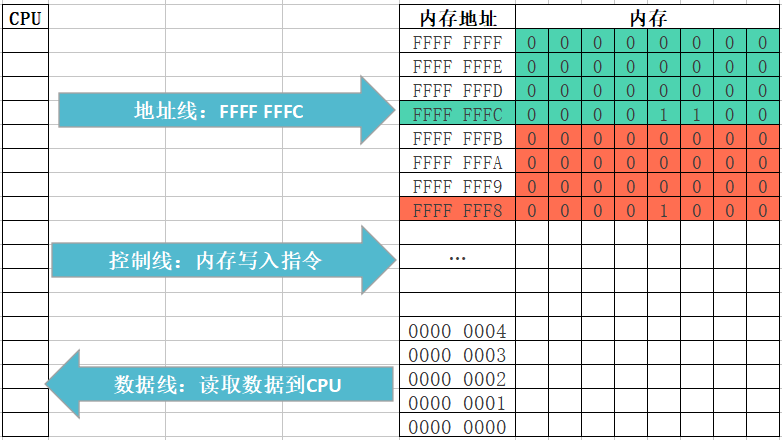
-
變數的存盤原則
- 先分配位元組地址大記憶體,然后分配位元組地址小的記憶體(記憶體尋址是由大到小)
- 變數的首地址,是變數所占存盤空間位元組地址(最小的那個地址 )
- 低位保存在低地址位元組上,高位保存在高地址位元組上
10的二進制: 0b00000000 00000000 00000000 00001010 高位元組← →低位元組
char型別記憶體存盤細節
- char型別基本概念
- char是C語言中比較靈活的一種資料型別,稱為“字符型”
- char型別變數占1個位元組存盤空間,共8位
- 除單個字符以外, C語言的的轉義字符也可以利用char型別存盤
| 字符 | 意義 |
|---|---|
| \b | 退格(BS)當前位置向后回退一個字符 |
| \r | 回車(CR),將當前位置移至本行開頭 |
| \n | 換行(LF),將當前位置移至下一行開頭 |
| \t | 水平制表(HT),跳到下一個 TAB 位置 |
| \0 | 用于表示字串的結束標記 |
\ | 代表一個反斜線字符 \ |
| \" | 代表一個雙引號字符" |
| \’ | 代表一個單引號字符’ |
- char型資料存盤原理
- 計算機只能識別0和1, 所以char型別存盤資料并不是存盤一個字符, 而是將字符轉換為0和1之后再存盤
- 正是因為存盤字符型別時需要將字符轉換為0和1, 所以為了統一, 老美就定義了一個叫做ASCII表的東東
- ASCII表中定義了每一個字符對應的整數
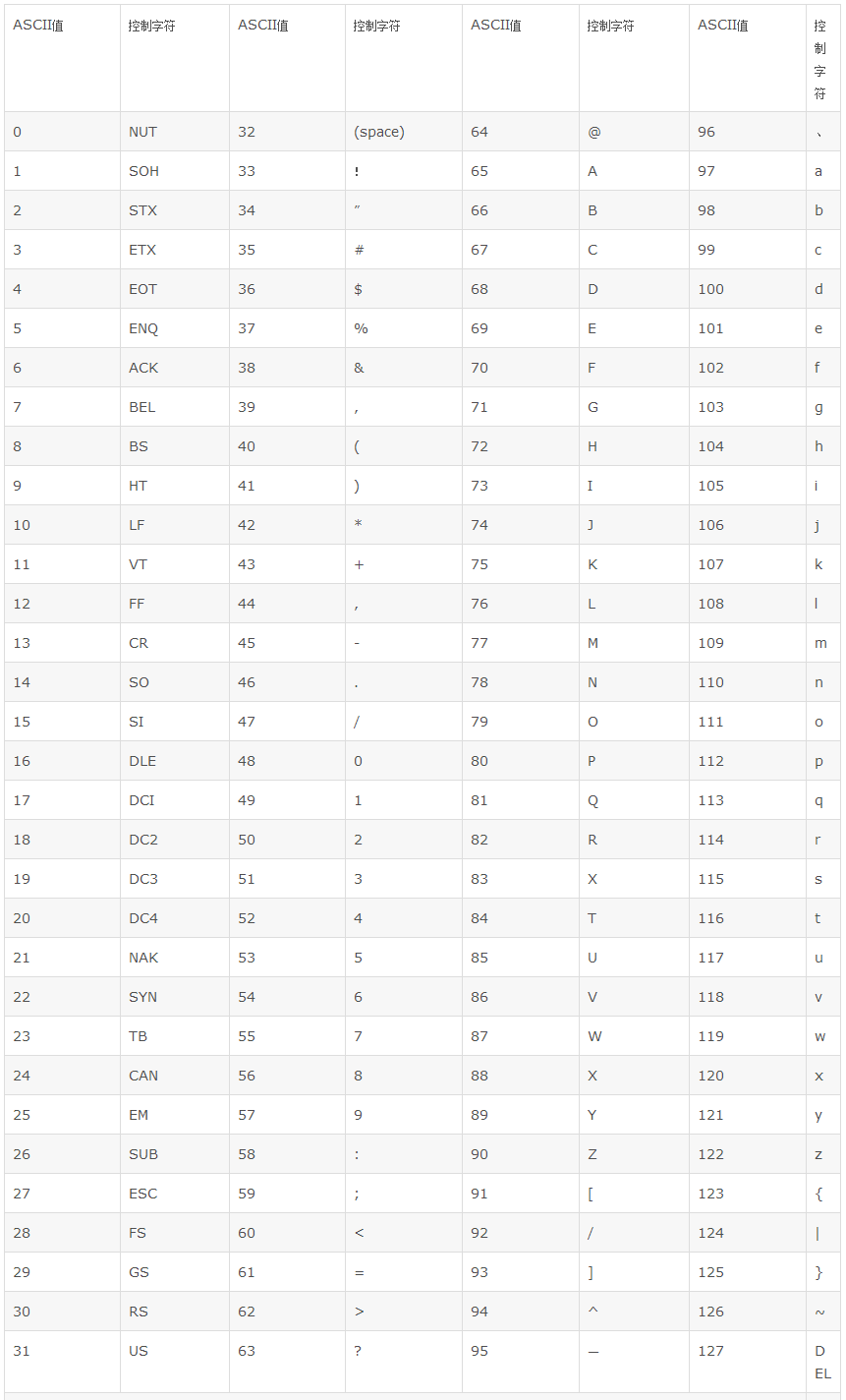
char ch1 = 'a';
printf("%i\n", ch1); // 97
char ch2 = 97;
printf("%c\n", ch2); // a
- char型別注意點
- char型別占一個位元組, 一個中文字符占3位元組(unicode表),所有char不可以存盤中文
char c = '我'; // 錯誤寫法- 除轉義字符以外, 不支持多個字符
char ch = 'ab'; // 錯誤寫法- char型別存盤字符時會先查找對應的ASCII碼值, 存盤的是ASCII值, 所以字符6和數字6存盤的內容不同
char ch1 = '6'; // 存盤的是ASCII碼 64 char ch2 = 6; // 存盤的是數字 6 - 練習
- 定義一個函式, 實作輸入一個小寫字母,要求轉換成大寫輸出
型別說明符
- 型別說明符基本概念
- C語言提供了說明長度和說明符號位的兩種型別說明符, 這兩種型別說明符一共有4個:
- short 短整型 (說明長度)
- long 長整型 (說明長度)
- signed 有符號型 (說明符號位)
- unsigned 無符號型 (說明符號位)
- C語言提供了說明長度和說明符號位的兩種型別說明符, 這兩種型別說明符一共有4個:
- 這些說明符一般都是用來修飾int型別的,所以在使用時可以省略int
- 這些說明符都屬于C語言關鍵字
short和long
- short和long可以提供不同長度的整型數,也就是可以改變整型數的取值范圍,
- 在64bit編譯器環境下,int占用4個位元組(32bit),取值范圍是-2^31 ~ 2^31-1;
- short占用2個位元組(16bit),取值范圍是-2^15 ~ 2^15-1;
- long占用8個位元組(64bit),取值范圍是-2^63 ~ 2^63-1
- 總結一下:在64位編譯器環境下:
- short占2個位元組(16位)
- int占4個位元組(32位)
- long占8個位元組(64位),
- 因此,如果使用的整數不是很大的話,可以使用short代替int,這樣的話,更節省記憶體開銷,
- 世界上的編譯器林林總總,不同編譯器環境下,int、short、long的取值范圍和占用的長度又是不一樣的,比如在16bit編譯器環境下,long只占用4個位元組,不過幸運的是,ANSI \ ISO制定了以下規則:
- short跟int至少為16位(2位元組)
- long至少為32位(4位元組)
- short的長度不能大于int,int的長度不能大于long
- char一定為為8位(1位元組),畢竟char是我們編程能用的最小資料型別
- 可以連續使用2個long,也就是long long,一般來說,long long的范圍是不小于long的,比如在32bit編譯器環境下,long long占用8個位元組,long占用4個位元組,不過在64bit編譯器環境下,long long跟long是一樣的,都占用8個位元組,
#include <stdio.h>
int main()
{
// char占1個位元組, char的取值范圍 -2^7~2^7
char num = 129;
printf("size = %i\n", sizeof(num)); // 1
printf("num = %i\n", num); // -127
// short int 占2個位元組, short int的取值范圍 -2^15~2^15-1
short int num1 = 32769;// -32767
printf("size = %i\n", sizeof(num1)); // 2
printf("num1 = %hi\n", num1);
// int占4個位元組, int的取值范圍 -2^31~2^31-1
int num2 = 12345678901;
printf("size = %i\n", sizeof(num2)); // 4
printf("num2 = %i\n", num2);
// long在32位占4個位元組, 在64位占8個位元組
long int num3 = 12345678901;
printf("size = %i\n", sizeof(num3)); // 4或8
printf("num3 = %ld\n", num3);
// long在32位占8個位元組, 在64位占8個位元組 -2^63~2^63-1
long long int num4 = 12345678901;
printf("size = %i\n", sizeof(num4)); // 8
printf("num4 = %lld\n", num4);
// 由于short/long/long long一般都是用于修飾int, 所以int可以省略
short num5 = 123;
printf("num5 = %lld\n", num5);
long num6 = 123;
printf("num6 = %lld\n", num6);
long long num7 = 123;
printf("num7 = %lld\n", num7);
return 0;
}
signed和unsigned
- 首先要明確的:signed int等價于signed,unsigned int等價于unsigned
- signed和unsigned的區別就是它們的最高位是否要當做符號位,并不會像short和long那樣改變資料的長度,即所占的位元組數,
- signed:表示有符號,也就是說最高位要當做符號位,但是int的最高位本來就是符號位,因此signed和int是一樣的,signed等價于signed int,也等價于int,signed的取值范圍是-2^31 ~ 2^31 - 1
- unsigned:表示無符號,也就是說最高位并不當做符號位,所以不包括負數,
- 因此unsigned的取值范圍是:0000 0000 0000 0000 0000 0000 0000 0000 ~ 1111 1111 1111 1111 1111 1111 1111 1111,也就是0 ~ 2^32 - 1
#include <stdio.h>
int main()
{
// 1.默認情況下所有型別都是由符號的
int num1 = 9;
int num2 = -9;
int num3 = 0;
printf("num1 = %i\n", num1);
printf("num2 = %i\n", num2);
printf("num3 = %i\n", num3);
// 2.signed用于明確說明, 當前保存的資料可以是有符號的, 一般情況下很少使用
signed int num4 = 9;
signed int num5 = -9;
signed int num6 = 0;
printf("num4 = %i\n", num4);
printf("num5 = %i\n", num5);
printf("num6 = %i\n", num6);
// signed也可以省略資料型別, 但是不推薦這樣撰寫
signed num7 = 9;
printf("num7 = %i\n", num7);
// 3.unsigned用于明確說明, 當前不能保存有符號的值, 只能保存0和正數
// 應用場景: 保存銀行存款,學生分數等不能是負數的情況
unsigned int num8 = -9;
unsigned int num9 = 0;
unsigned int num10 = 9;
// 注意: 不看怎么存只看怎么取
printf("num8 = %u\n", num8);
printf("num9 = %u\n", num9);
printf("num10 = %u\n", num10);
return 0;
}
- 注意點:
- 修飾符號的說明符可以和修飾長度的說明符混合使用
- 相同型別的說明符不能混合使用
signed short int num1 = 666;
signed unsigned int num2 = 666; // 報錯
陣列的基本概念
-
陣列,從字面上看,就是一組資料的意思,沒錯,陣列就是用來存盤一組資料的
- 在C語言中,陣列屬于構造資料型別
-
陣列的幾個名詞
- 陣列:一組
相同資料型別資料的有序的集合 - 陣列元素: 構成陣列的每一個資料,
- 陣列的下標: 陣列元素位置的索引(從0開始)
- 陣列:一組
-
陣列的應用場景
- 一個int型別的變數能保存一個人的年齡,如果想保存整個班的年齡呢?
- 第一種方法是定義很多個int型別的變數來存盤
- 第二種方法是只需要定義一個int型別的陣列來存盤
- 一個int型別的變數能保存一個人的年齡,如果想保存整個班的年齡呢?
#include <stdio.h>
int main(int argc, const char * argv[]) {
/*
// 需求: 保存2個人的分數
int score1 = 99;
int score2 = 60;
// 需求: 保存全班同學的分數(130人)
int score3 = 78;
int score4 = 68;
...
int score130 = 88;
*/
// 陣列: 如果需要保存`一組``相同型別`的資料, 就可以定義一個陣列來保存
// 只要定義好一個陣列, 陣列內部會給每一塊小的存盤空間一個編號, 這個編號我們稱之為 索引, 索引從0開始
// 1.定義一個可以保存3個int型別的陣列
int scores[3];
// 2.通過陣列的下標往陣列中存放資料
scores[0] = 998;
scores[1] = 123;
scores[2] = 567;
// 3.通過陣列的下標從陣列中取出存放的資料
printf("%i\n", scores[0]);
printf("%i\n", scores[1]);
printf("%i\n", scores[2]);
return 0;
}
定義陣列
- 元素型別 陣列名[元素個數];
// int 元素型別
// ages 陣列名稱
// [10] 元素個數
int ages[10];
初始化陣列
- 定義的同時初始化
- 指定元素個數,完全初始化
- 其中在{ }中的各資料值即為各元素的初值,各值之間用逗號間隔
int ages[3] = {4, 6, 9};
- 不指定元素個數,完全初始化
- 根據大括號中的元素的個數來確定陣列的元素個數
int nums[] = {1,2,3,5,6};
- 指定元素個數,部分初始化
- 沒有顯式初始化的元素,那么系統會自動將其初始化為0
int nums[10] = {1,2};
- 指定元素個數,部分初始化
int nums[5] = {[4] = 3,[1] = 2};
- 不指定元素個數,部分初始化
int nums[] = {[4] = 3};
- 先定義后初始化
int nums[3];
nums[0] = 1;
nums[1] = 2;
nums[2] = 3;
- 沒有初始化會怎樣?
- 如果定義陣列后,沒有初始化,陣列中是有值的,是隨機的垃圾數,所以如果想要正確使用陣列應該要進行初始化,
int nums[5];
printf("%d\n", nums[0]);
printf("%d\n", nums[1]);
printf("%d\n", nums[2]);
printf("%d\n", nums[3]);
printf("%d\n", nums[4]);
輸出結果:
0
0
1606416312
0
1606416414
- 注意點:
- 使用陣列時不能超出陣列的索引范圍使用, 索引從0開始, 到元素個數-1結束
- 使用陣列時不要隨意使用未初始化的元素, 有可能是一個隨機值
- 對于陣列來說, 只能在定義的同時初始化多個值, 不能先定義再初始化多個值
int ages[3];
ages = {4, 6, 9}; // 報錯
陣列的使用
- 通過下標(索引)訪問:
// 找到下標為0的元素, 賦值為10
ages[0]=10;
// 取出下標為2的元素保存的值
int a = ages[2];
printf("a = %d", a);
陣列的遍歷
- 陣列的遍歷:遍歷的意思就是有序地查看陣列的每一個元素
int ages[4] = {19, 22, 33, 13};
for (int i = 0; i < 4; i++) {
printf("ages[%d] = %d\n", i, ages[i]);
}
陣列長度計算方法
- 因為陣列在記憶體中占用的位元組數取決于其存盤的資料型別和資料的個數
- 陣列所占用存盤空間 = 一個元素所占用存盤空間 * 元素個數(陣列長度)
- 所以計算陣列長度可以使用如下方法
陣列的長度 = 陣列占用的總位元組數 / 陣列元素占用的位元組數
int ages[4] = {19, 22, 33, 13};
int length = sizeof(ages)/sizeof(int);
printf("length = %d", length);
輸出結果: 4
練習
- 正序輸出(遍歷)陣列
int ages[4] = {19, 22, 33, 13};
for (int i = 0; i < 4; i++) {
printf("ages[%d] = %d\n", i, ages[i]);
}
- 逆序輸出(遍歷)陣列
int ages[4] = {19, 22, 33, 13};
for (int i = 3; i >=0; i--) {
printf("ages[%d] = %d\n", i, ages[i]);
}
- 從鍵盤輸入陣列長度,構建一個陣列,然后再通過for回圈從鍵 盤接收數字給陣列初始化,并使用for回圈輸出查看
陣列內部存盤細節
-
存盤方式:
- 1)記憶體尋址從大到小, 從高地址開辟一塊連續沒有被使用的記憶體給陣列
- 2)從分配的連續存盤空間中, 地址小的位置開始給每個元素分配空間
- 3)從每個元素分配的存盤空間中, 地址最大的位置開始存盤資料
- 4)用陣列名指向整個存盤空間最小的地址
-
示例
#include <stdio.h>
int main()
{
int num = 9;
char cs[] = {'l','n','j'};
printf("cs = %p\n", &cs); // cs = 0060FEA9
printf("cs[0] = %p\n", &cs[0]); // cs[0] = 0060FEA9
printf("cs[1] = %p\n", &cs[1]); // cs[1] = 0060FEAA
printf("cs[2] = %p\n", &cs[2]); // cs[2] = 0060FEAB
int nums[] = {2, 6};
printf("nums = %p\n", &nums); // nums = 0060FEA0
printf("nums[0] = %p\n", &nums[0]);// nums[0] = 0060FEA0
printf("nums[1] = %p\n", &nums[1]);// nums[1] = 0060FEA4
return 0;
}
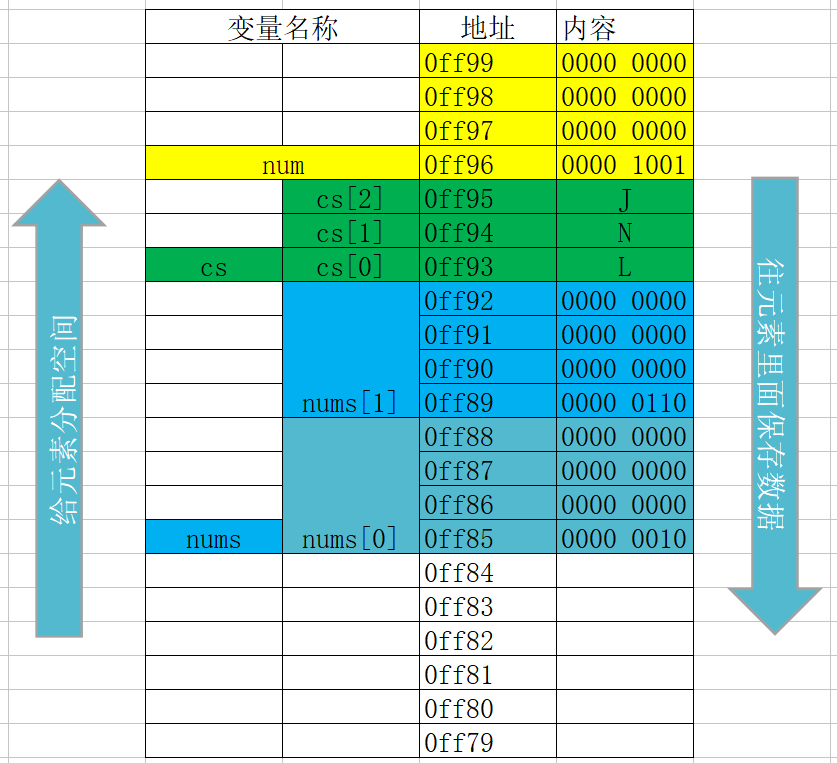
- 注意:字符在記憶體中是以對應ASCII碼值的二進制形式存盤的,而非上述的形式,
陣列的越界問題
- 陣列越界導致的問題
- 約錯物件
- 程式崩潰
char cs1[2] = {1, 2};
char cs2[3] = {3, 4, 5};
cs2[3] = 88; // 注意:這句訪問到了不屬于cs1的記憶體
printf("cs1[0] = %d\n", cs1[0] );
輸出結果: 88
為什么上述會輸出88, 自己按照"陣列內部存盤細節"畫圖腦補
陣列注意事項
- 在定義陣列的時候[]里面只能寫整型常量或者是回傳整型常量的運算式
int ages4['A'] = {19, 22, 33};
printf("ages4[0] = %d\n", ages4[0]);
int ages5[5 + 5] = {19, 22, 33};
printf("ages5[0] = %d\n", ages5[0]);
int ages5['A' + 5] = {19, 22, 33};
printf("ages5[0] = %d\n", ages5[0]);
- 錯誤寫法
// 沒有指定元素個數,錯誤
int a[];
// []中不能放變數
int number = 10;
int ages[number]; // 老版本的C語言規范不支持
printf("%d\n", ages[4]);
int number = 10;
int ages2[number] = {19, 22, 33} // 直接報錯
// 只能在定義陣列的時候進行一次性(全部賦值)的初始化
int ages3[5];
ages10 = {19, 22, 33};
// 一個長度為n的陣列,最大下標為n-1, 下標范圍:0~n-1
int ages4[4] = {19, 22, 33}
ages4[8]; // 陣列角標越界
- 練習
- 從鍵盤錄入當天出售BTC的價格并計算出售的BTC的總價和平均價(比如說一天出售了10個位元幣)
陣列和函式
- 陣列可以作為函式的引數使用,陣列用作函式引數有兩種形式:
- 一種是把陣列元素作為實參使用
- 一種是把陣列名作為函式的形參和實參使用
陣列元素作為函式引數
- 陣列的元素作為函式實參,與同型別的簡單變數作為實參一樣,如果是基本資料型別, 那么形參的改變不影響實參
void change(int val)// int val = number
{
val = 55;
}
int main(int argc, const char * argv[])
{
int ages[3] = {1, 5, 8};
printf("ages[0] = %d", ages[0]);// 1
change(ages[0]);
printf("ages[0] = %d", ages[0]);// 1
}
- 用陣列元素作函式引數不要求形參也必須是陣列元素
陣列名作為函式引數
- 在C語言中,陣列名除作為變數的識別符號之外,陣列名還代表了該陣列在記憶體中的起始地址,因此,當陣列名作函式引數時,實參與形參之間不是"值傳遞",而是"地址傳遞"
- 實引陣列名將該陣列的起始地址傳遞給形引陣列,兩個陣列共享一段記憶體單元, 系統不再為形引陣列分配存盤單元
- 既然兩個陣列共享一段記憶體單元, 所以形引陣列修改時,實引陣列也同時被修改了
void change2(int array[3])// int array = 0ffd1
{
array[0] = 88;
}
int main(int argc, const char * argv[])
{
int ages[3] = {1, 5, 8};
printf("ages[0] = %d", ages[0]);// 1
change(ages);
printf("ages[0] = %d", ages[0]);// 88
}
陣列名作函式引數的注意點
- 在函式形參表中,允許不給出形引陣列的長度
void change(int array[])
{
array[0] = 88;
}
- 形引陣列和實引陣列的型別必須一致,否則將引起錯誤,
void prtArray(double array[3]) // 錯誤寫法
{
for (int i = 0; i < 3; i++) {
printf("array[%d], %f", i, array[i]);
}
}
int main(int argc, const char * argv[])
{
int ages[3] = {1, 5, 8};
prtArray(ages[0]);
}
- 當陣列名作為函式引數時, 因為自動轉換為了指標型別,所以在函式中無法動態計算除陣列的元素個數
void printArray(int array[])
{
printf("printArray size = %lu\n", sizeof(array)); // 8
int length = sizeof(array)/ sizeof(int); // 2
printf("length = %d", length);
}
- 練習:
- 設計一個函式int arrayMax(int a[], int count)找出陣列元素的最大值
- 從鍵盤輸入3個0-9的數字,然后輸出0~9中哪些數字沒有出現過
- 要求從鍵盤輸入6個0~9的數字,排序后輸出
計數排序(Counting Sort)
-
計數排序是一個非基于比較的排序演算法,該演算法于1954年由 Harold H. Seward 提出,它的優勢在于在
對一定范圍內的整數排序時,快于任何比較排序演算法, -
排序思路:
- 1.找出待排序陣列最大值
- 2.定義一個索引最大值為待排序陣列最大值的陣列
- 3.遍歷待排序陣列, 將待排序陣列遍歷到的值作新陣列索引
- 4.在新陣列對應索引存盤值原有基礎上+1
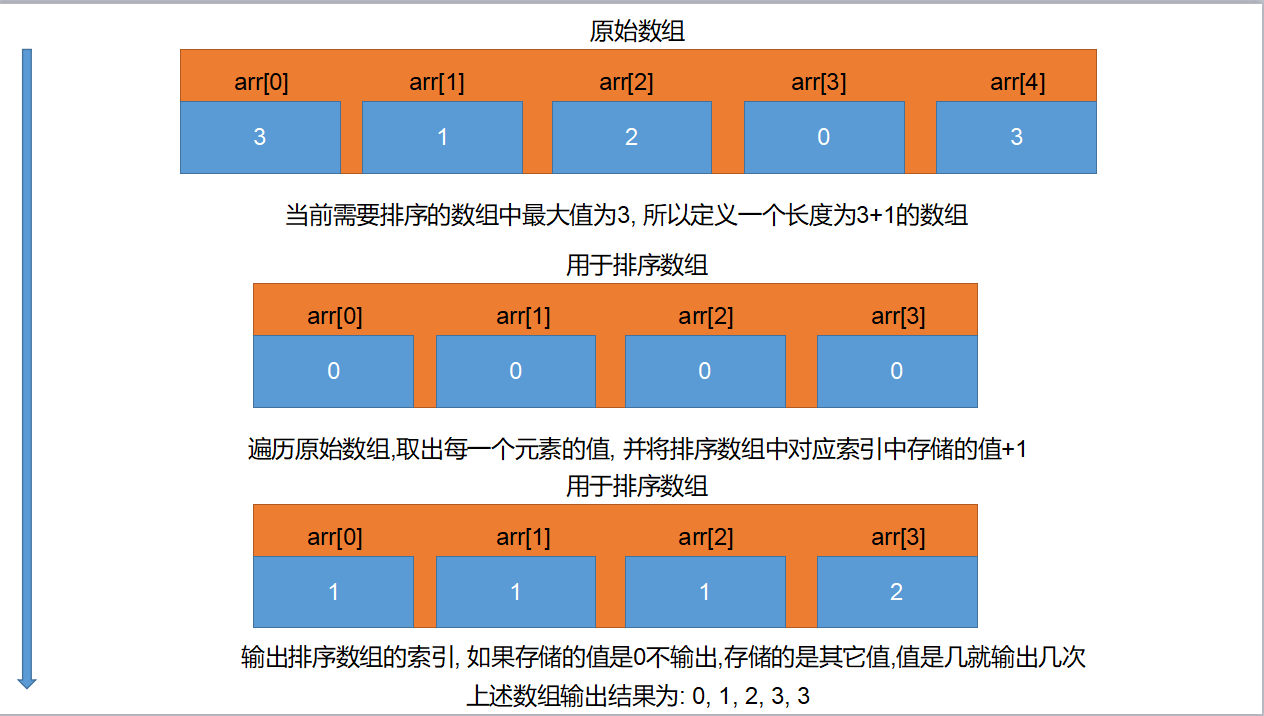
-
簡單代碼實作:
int main()
{
// 待排序陣列
int nums[5] = {3, 1, 2, 0, 3};
// 用于排序陣列
int newNums[4] = {0};
// 計算待排序陣列長度
int len = sizeof(nums) / sizeof(nums[0]);
// 遍歷待排序陣列
for(int i = 0; i < len; i++){
// 取出待排序陣列當前值
int index = nums[i];
// 將待排序陣列當前值作為排序陣列索引
// 將用于排序陣列對應索引原有值+1
newNums[index] = newNums[index] +1;
}
// 計算待排序陣列長度
int len2 = sizeof(newNums) / sizeof(newNums[0]);
// 輸出排序陣列索引, 就是排序之后結果
for(int i = 0; i < len2; i++){
for(int j = 0; j < newNums[i]; j++){
printf("%i\n", i);
}
}
/*
// 計算待排序陣列長度
int len2 = sizeof(newNums) / sizeof(newNums[0]);
// 還原排序結果到待排序陣列
for(int i = 0; i < len2; i++){
int index = 0;
for(int i = 0; i < len; i++){
for(int j = 0; j < newNums[i]; j++){
nums[index++] = i;
}
}
}
*/
return 0;
}
選擇排序
-
選擇排序(Selection sort)是一種簡單直觀的排序演算法,它的作業原理如下,首先在未排序序列中找到最小元素,存放到排序序列的起始位置,然后,再從剩余未排序元素中繼續尋找最小元素,然后放到排序序列末尾,以此類推,直到所有元素均排序完畢,
-
排序思路:
- 假設按照升序排序
- 1.用第0個元素和后面所有元素依次比較
- 2.判斷第0個元素是否大于當前被比較元素, 一旦小于就交換位置
- 3.第0個元素和后續所有元素比較完成后, 第0個元素就是最小值
- 4.排除第0個元素, 用第1個元素重復1~3操作, 比較完成后第1個元素就是倒數第二小的值
- 以此類推, 直到當前元素沒有可比較的元素, 排序完成
-
代碼實作:
// 選擇排序
void selectSort(int numbers[], int length) {
// 外回圈為什么要-1?
// 最后一位不用比較, 也沒有下一位和它比較, 否則會出現錯誤訪問
for (int i = 0; i < length; i++) {
for (int j = i; j < length - 1; j++) {
// 1.用當前元素和后續所有元素比較
if (numbers[i] < numbers[j + 1]) {
// 2.一旦發現小于就交換位置
swapEle(numbers, i, j + 1);
}
}
}
}
// 交換兩個元素的值, i/j需要交換的索引
void swapEle(int array[], int i, int j) {
int temp = array[i];
array[i] = array[j];
array[j] = temp;
}
冒泡排序
- 冒泡排序(Bubble Sort)是一種簡單的排序演算法,它重復 地走訪過要排序的數列,一次比較兩個元素,如果他們的順序錯誤就把他們交換過來,走訪數列的作業是重復地進行直到沒有再需要交換,也就是說該數列已經排序完成,這個演算法的名字由來是因為越小的元素會經由交換慢慢“浮”到數列的頂端,
- 排序思路:
- 假設按照升序排序
- 1.從第0個元素開始, 每次都用相鄰兩個元素進行比較
- 2.一旦發現后面一個元素小于前面一個元素就交換位置
- 3.經過一輪比較之后最后一個元素就是最大值
- 4.排除最后一個元素, 以此類推, 每次比較完成之后最大值都會出現再被比較所有元素的最后
- 直到當前元素沒有可比較的元素, 排序完成
- 代碼實作:
// 冒泡排序
void bubbleSort(int numbers[], int length) {
for (int i = 0; i < length; i++) {
// -1防止`角標越界`: 訪問到了不屬于自己的索引
for (int j = 0; j < length - i - 1; j++) {
// 1.用當前元素和相鄰元素比較
if (numbers[j] < numbers[j + 1]) {
// 2.一旦發現小于就交換位置
swapEle(numbers, j, j + 1);
}
}
}
}
// 交換兩個元素的值, i/j需要交換的索引
void swapEle(int array[], int i, int j) {
int temp = array[i];
array[i] = array[j];
array[j] = temp;
}
插入排序
- 插入排序(Insertion-Sort)的演算法描述是一種簡單直觀的排序演算法,它的作業原理是通過構建有序序列,對于未排序資料,在已排序序列中從后向前掃描,找到相應位置并插入,
- 排序思路:
- 假設按照升序排序
- 1.從索引為1的元素開始向前比較, 一旦前面一個元素大于自己就讓前面的元素先后移動
- 2.直到沒有可比較元素或者前面的元素小于自己的時候, 就將自己插入到當前空出來的位置
- 代碼實作:
int main()
{
// 待排序陣列
int nums[5] = {3, 1, 2, 0, 3};
// 0.計算待排序陣列長度
int len = sizeof(nums) / sizeof(nums[0]);
// 1.從第一個元素開始依次取出所有用于比較元素
for (int i = 1; i < len; i++)
{
// 2.取出用于比較元素
int temp = nums[i];
int j = i;
while(j > 0){
// 3.判斷元素是否小于前一個元素
if(temp < nums[j - 1]){
// 4.讓前一個元素向后移動一位
nums[j] = nums[j - 1];
}else{
break;
}
j--;
}
// 5.將元素插入到空出來的位置
nums[j] = temp;
}
}
int main()
{
// 待排序陣列
int nums[5] = {3, 1, 2, 0, 3};
// 0.計算待排序陣列長度
int len = sizeof(nums) / sizeof(nums[0]);
// 1.從第一個元素開始依次取出所有用于比較元素
for (int i = 1; i < len; i++)
{
// 2.遍歷取出前面元素進行比較
for(int j = i; j > 0; j--)
{
// 3.如果前面一個元素大于當前元素,就交換位置
if(nums[j-1] > nums[j]){
int temp = nums[j];
nums[j] = nums[j - 1];
nums[j - 1] = temp;
}else{
break;
}
}
}
}
希爾排序
- 1959年Shell發明,第一個突破O(n2)的排序演算法,是簡單插入排序的改進版,它與插入排序的不同之處在于,它會優先比較距離較遠的元素,希爾排序又叫縮小增量排序,
- 排序思路:
- 1.希爾排序可以理解為插入排序的升級版, 先將待排序陣列按照指定步長劃分為幾個小陣列
- 2.利用插入排序對小陣列進行排序, 然后將幾個排序的小陣列重新合并為原始陣列
- 3.重復上述操作, 直到步長為1時,再利用插入排序排序即可
- 代碼實作:
int main()
{
// 待排序陣列
int nums[5] = {3, 1, 2, 0, 3};
// 0.計算待排序陣列長度
int len = sizeof(nums) / sizeof(nums[0]);
// 2.計算步長
int gap = len / 2;
do{
// 1.從第一個元素開始依次取出所有用于比較元素
for (int i = gap; i < len; i++)
{
// 2.遍歷取出前面元素進行比較
int j = i;
while((j - gap) >= 0)
{
printf("%i > %i\n", nums[j - gap], nums[j]);
// 3.如果前面一個元素大于當前元素,就交換位置
if(nums[j - gap] > nums[j]){
int temp = nums[j];
nums[j] = nums[j - gap];
nums[j - gap] = temp;
}else{
break;
}
j--;
}
}
// 每個小陣列排序完成, 重新計算步長
gap = gap / 2;
}while(gap >= 1);
}
江哥提示:
對于初學者而言, 排序演算法一次不易于學習太多, 咋們先來5個玩一玩, 后續繼續講解其它5個
折半查找
- 基本思路
- 在有序表中,取中間元素作為比較物件,若給定值與中間元素的要查找的數相等,則查找成功;若給定值小于中間元素的要查找的數,則在中間元素的左半區繼續查找;
- 若給定值大于中間元素的要查找的數,則在中間元素的右半區繼續查找,不斷重復上述查找過 程,直到查找成功,或所查找的區域無資料元素,查找失敗
-
實作步驟
-
在有序表中,取中間元素作為比較物件,若給定值與中間元素的要查找的數相等,則查找成功;
-
若給定值小于中間元素的要查找的數,則在中間元素的左半區繼續查找;
-
若給定值大于中間元素的要查找的數,則在中間元素的右半區繼續查找,
-
不斷重復上述查找過 程,直到查找成功,或所查找的區域無資料元素,查找失敗,
-
代碼實作
int findKey(int values[], int length, int key) {
// 定義一個變數記錄最小索引
int min = 0;
// 定義一個變數記錄最大索引
int max = length - 1;
// 定義一個變數記錄中間索引
int mid = (min + max) * 0.5;
while (min <= max) {
// 如果mid對應的值 大于 key, 那么max要變小
if (values[mid] > key) {
max = mid - 1;
// 如果mid對應的值 小于 key, 那么min要變
}else if (values[mid] < key) {
min = mid + 1;
}else {
return mid;
}
// 修改完min/max之后, 重新計算mid的值
mid = (min + max) * 0.5;
}
return -1;
}
進制轉換(查表法)
- 實作思路:
- 將二進制、八進制、十進制、十六進制所有可能的字符都存入陣列
- 利用按位與運算子和右移依次取出當前進制對應位置的值
- 利用取出的值到陣列中查詢當前位輸出的結果
- 將查詢的結果存入一個新的陣列, 當所有位都查詢存盤完畢, 新陣列中的值就是對應進制的值
- 代碼實作
#include <stdio.h>
void toBinary(int num)
{
total(num, 1, 1);
}
void toOct(int num)
{
total(num, 7, 3);
}
void toHex(int num)
{
total(num, 15, 4);
}
void total(int num , int base, int offset)
{
// 1.定義表用于查詢結果
char cs[] = {
'0', '1', '2', '3', '4', '5',
'6', '7', '8', '9', 'a', 'b',
'c', 'd', 'e', 'f'
};
// 2.定義保存結果的陣列
char rs[32];
// 計算最大的角標位置
int length = sizeof(rs)/sizeof(char);
int pos = length;//8
while (num != 0) {
int index = num & base;
rs[--pos] = cs[index];
num = num >> offset;
}
for (int i = pos; i < length; i++) {
printf("%c", rs[i]);
}
printf("\n");
}
int main()
{
toBinary(9);
return 0;
}
二維陣列
- 所謂二維陣列就是一個一維陣列的每個元素又被宣告為一 維陣列,從而構成二維陣列. 可以說二維陣列是特殊的一維陣列,
- 示例:
- int a[2][3] = { {80,75,92}, {61,65,71}};
- 可以看作由一維陣列a[0]和一維陣列a[1]組成,這兩個一維陣列都包含了3個int型別的元素

二維陣列的定義
- 格式:
- 資料型別 陣列名[一維陣列的個數][一維陣列的元素個數]
- 其中"一維陣列的個數"表示當前二維陣列中包含多少個一維陣列
- 其中"一維陣列的元素個數"表示當前前二維陣列中每個一維陣列元素的個數
二維陣列的初始化
-
二維數的初始化可分為兩種:
- 定義的同時初始化
- 先定義后初始化
-
定義的同時初始化
int a[2][3]={ {80,75,92}, {61,65,71}};
- 先定義后初始化
int a[2][3];
a[0][0] = 80;
a[0][1] = 75;
a[0][2] = 92;
a[1][0] = 61;
a[1][1] = 65;
a[1][2] = 71;
- 按行分段賦值
int a[2][3]={ {80,75,92}, {61,65,71}};
- 按行連續賦值
int a[2][3]={ 80,75,92,61,65,71};
- 其它寫法
- 完全初始化,可以省略第一維的長度
int a[][3]={{1,2,3},{4,5,6}};
int a[][3]={1,2,3,4,5,6};
- 部分初始化,可以省略第一維的長度
int a[][3]={{1},{4,5}};
int a[][3]={1,2,3,4};
- 注意: 有些人可能想不明白,為什么可以省略行數,但不可以省略列數,也有人可能會問,可不可以只指定行數,但是省略列數?其實這個問題很簡單,如果我們這樣寫:
int a[2][] = {1, 2, 3, 4, 5, 6}; // 錯誤寫法
大家都知道,二維陣列會先存放第1行的元素,由于不確定列數,也就是不確定第1行要存放多少個元素,所以這里會產生很多種情況,可能1、2是屬于第1行的,也可能1、2、3、4是第一行的,甚至1、2、3、4、5、6全部都是屬于第1行的
- 指定元素的初始化
int a[2][3]={[1][2]=10};
int a[2][3]={[1]={1,2,3}}
二維陣列的應用場景

二維陣列的遍歷和存盤
二維陣列的遍歷
- 二維陣列a[3][4],可分解為三個一維陣列,其陣列名分別為:
- 這三個一維陣列都有4個元素,例如:一維陣列a[0]的 元素為a[0][0],a[0][1],a[0][2],a[0][3],
- 所以遍歷二維陣列無非就是先取出二維陣列中得一維陣列, 然后再從一維陣列中取出每個元素的值
- 示例
char cs[2][3] = {
{'a', 'b', 'c'},
{'d', 'e', 'f'}
};
printf("%c", cs[0][0]);// 第一個[0]取出一維陣列, 第二個[0]取出一維陣列中對應的元素
char cs[2][3] = {
{'a', 'b', 'c'},
{'d', 'e', 'f'}
};
for (int i = 0; i < 2; i++) { // 外回圈取出一維陣列
// i
for (int j = 0; j < 3; j++) {// 內回圈取出一維陣列的每個元素
printf("%c", cs[i][j]);
}
printf("\n");
}
注意: 必須強調的是,a[0],a[1],a[2]不能當作下標變數使用,它們是陣列名,不是一個單純的下標變數
二維陣列的存盤
- 和以為陣列一樣
- 給陣列分配存盤空間從記憶體地址大開始分配
- 給陣列元素分配空間, 從所占用記憶體地址小的開始分配
- 往每個元素中存盤資料從高地址開始存盤
#include <stdio.h>
int main()
{
char cs[2][3] = {
{'a', 'b', 'c'},
{'d', 'e', 'f'}
};
// cs == &cs == &cs[0] == &cs[0][0]
printf("cs = %p\n", cs); // 0060FEAA
printf("&cs = %p\n", &cs); // 0060FEAA
printf("&cs[0] = %p\n", &cs[0]); // 0060FEAA
printf("&cs[0][0] = %p\n", &cs[0][0]); // 0060FEAA
return 0;
}
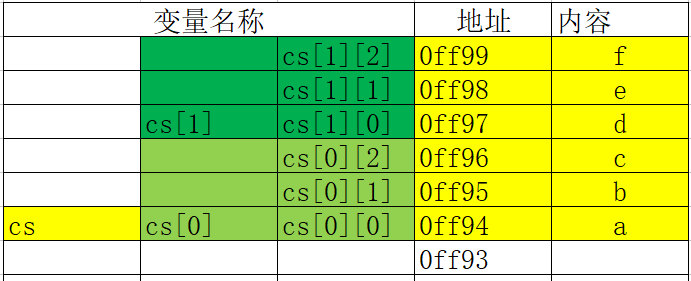
二維陣列與函式
- 值傳遞
#include <stdio.h>
// 和一位陣列一樣, 只看形參是基本型別還是陣列型別
// 如果是基本型別在函式中修改形參不會影響實參
void change(char ch){
ch = 'n';
}
int main()
{
char cs[2][3] = {
{'a', 'b', 'c'},
{'d', 'e', 'f'}
};
printf("cs[0][0] = %c\n", cs[0][0]); // a
change(cs[0][0]);
printf("cs[0][0] = %c\n", cs[0][0]); // a
return 0;
}
- 地址傳遞
#include <stdio.h>
// 和一位陣列一樣, 只看形參是基本型別還是陣列型別
// 如果是陣列型別在函式中修改形參會影響實參
void change(char ch[]){
ch[0] = 'n';
}
int main()
{
char cs[2][3] = {
{'a', 'b', 'c'},
{'d', 'e', 'f'}
};
printf("cs[0][0] = %c\n", cs[0][0]); // a
change(cs[0]);
printf("cs[0][0] = %c\n", cs[0][0]); // n
return 0;
}
#include <stdio.h>
// 和一位陣列一樣, 只看形參是基本型別還是陣列型別
// 如果是陣列型別在函式中修改形參會影響實參
void change(char ch[][3]){
ch[0][0] = 'n';
}
int main()
{
char cs[2][3] = {
{'a', 'b', 'c'},
{'d', 'e', 'f'}
};
printf("cs[0][0] = %c\n", cs[0][0]); // a
change(cs);
printf("cs[0][0] = %c\n", cs[0][0]); // n
return 0;
}
二維陣列作為函式引數注意點
- 形參錯誤寫法
void test(char cs[2][]) // 錯誤寫法
{
printf("我被執行了\n");
}
void test(char cs[2][3]) // 正確寫法
{
printf("我被執行了\n");
}
void test(char cs[][3]) // 正確寫法
{
printf("我被執行了\n");
}
- 二維陣列作為函式引數,在被調函式中不能獲得其有多少行,需要通過引數傳入
void test(char cs[2][3])
{
int row = sizeof(cs); // 輸出4或8
printf("row = %zu\n", row);
}
- 二維陣列作為函式引數,在被調函式中可以計算出二維陣列有多少列
void test(char cs[2][3])
{
size_t col = sizeof(cs[0]); // 輸出3
printf("col = %zd\n", col);
}
作業
-
玩家通過鍵盤錄入 w,s,a,d控制小人向不同方向移動,其中w代表向上移動,s代表向 下移動,a代表向左移動,d 代表向右移動,當小人移動到出口位置,玩家勝利
-
思路:
-
1.定義二維陣列存放地圖
######
#O #
# ## #
# # #
## #
######
- 2.規定地圖的方向
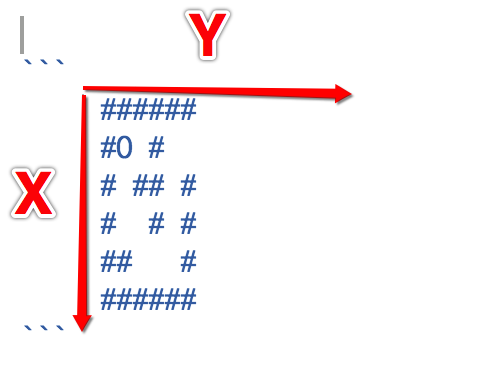
- 3.撰寫程式控制方向
- 當輸入w或者W, 小人向上移動. x-1
- 當輸入s 或者S, 小人向下. x+1
- 當輸入a或者A, 小人向左. y-1
- 當輸入d或者D, 小人向右. y+1
- 4.移動小人
- 用變數記錄小人當前的位置
- 1)如果小人將要移動的位置是墻,則無法移動
- 2)如果小人將要移動的位置是路,則可以移動
- 用變數記錄小人當前的位置
- 5.判斷是否走出迷宮
字串的基本概念
- 字串是位于雙引號中的字符序列
- 在記憶體中以“\0”結束,所占位元組比實際多一個

- 在記憶體中以“\0”結束,所占位元組比實際多一個
字串的初始化
- 在C語言中沒有專門的字串變數,通常用一個字符陣列來存放一個字串,
- 當把一個字串存入一個陣列時,會把結束符‘\0’存入陣列,并以此作為該字串是否結束的標志,
- 有了‘\0’標志后,就不必再用字符陣列 的長度來判斷字串的長度了
- 初始化
char name[9] = "lnj"; //在記憶體中以“\0”結束, \0ASCII碼值是0
char name1[9] = {'l','n','j','\0'};
char name2[9] = {'l','n','j',0};
// 當陣列元素個數大于存盤字符內容時, 未被初始化的部分默認值是0, 所以下面也可以看做是一個字串
char name3[9] = {'l','n','j'};
- 錯誤的初始化方式
//省略元素個數時, 不能省略末尾的\n
// 不正確地寫法,結尾沒有\0 ,只是普通的字符陣列
char name4[] = {'l','n','j'};
// "中間不能包含\0", 因為\0是字串的結束標志
// \0的作用:字串結束的標志
char name[] = "c\0ool";
printf("name = %s\n",name);
輸出結果: c
字串輸出
- 如果字符陣列中存盤的是一個字串, 那么字符陣列的輸入輸出將變得簡單方便,
- 不必使用回圈陳述句逐個地輸入輸出每個字符
- 可以使用printf函式和scanf函式一次性輸出輸入一個字符陣列中的字串
- 使用的格式字串為“%s”,表示輸入、輸出的是一個字串 字串的輸出
- 輸出
- %s的本質就是根據傳入的name的地址逐個去取陣列中的元素然后輸出,直到遇到\0位置
char chs[] = "lnj";
printf("%s\n", chs);
- 注意點:
- \0引發的臟讀問題
char name[] = {'c', 'o', 'o', 'l' , '\0'};
char name2[] = {'l', 'n', 'j'};
printf("name2 = %s\n", name2); // 輸出結果: lnjcool
- 輸入
char ch[10];
scanf("%s",ch);
- 注意點:
- 對一個字串陣列, 如果不做初始化賦值, 必須指定陣列長度
- ch最多存放由9個字符構成的字串,其中最后一個字符的位置要留給字串的結尾標示‘\0’
- 當用scanf函式輸入字串時,字串中不能含有空格,否則將以空格作為串的結束符
字串常用方法
- C語言中供了豐富的字串處理函式,大致可分為字串的輸入、輸出、合并、修改、比較、轉 換、復制、搜索幾類,
- 使用這些函式可大大減輕編程的負擔,
- 使用輸入輸出的字串函式,在使用前應包含頭檔案"stdio.h"
- 使用其它字串函式則應包含頭檔案"string.h"
- 字串輸出函式:puts
- 格式: puts(字符陣列名)
- 功能:把字符陣列中的字串輸出到顯示幕,即在螢屏上顯示該字串,
- 優點:
- 自動換行
- 可以是陣列的任意元素地址
- 缺點
- 不能自定義輸出格式, 例如 puts(“hello %i”);
char ch[] = "lnj";
puts(ch); //輸出結果: lnj
- puts函式完全可以由printf函式取代,當需要按一定格式輸出時,通常使用printf函式
- 字串輸入函式:gets
- 格式: gets (字符陣列名)
- 功能:從標準輸入設備鍵盤上輸入一個字串,
char ch[30];
gets(ch); // 輸入:lnj
puts(ch); // 輸出:lnj
- 可以看出當輸入的字串中含有空格時,輸出仍為全部字串,說明gets函式并不以空格作為字串輸入結束的標志,而只以回車作為輸入結束,這是與scanf函式不同的,
- 注意gets很容易導致陣列下標越界,是一個不安全的字串操作函式
- 字串長度
- 利用sizeof字串長度
- 因為字串在記憶體中是逐個字符存盤的,一個字符占用一個位元組,所以字串的結束符長度也是占用的記憶體單元的位元組數,
char name[] = "it666";
int size = sizeof(name);// 包含\0
printf("size = %d\n", size); //輸出結果:6
- 利用系統函式
- 格式: strlen(字符陣列名)
- 功能:測字串的實際長度(不含字串結束標志‘\0’)并作為函式回傳值,
char name[] = "it666";
size_t len = strlen(name2);
printf("len = %lu\n", len); //輸出結果:5
- 以“\0”為字串結束條件進行統計
/**
* 自定義方法計算字串的長度
* @param name 需要計算的字串
* @return 不包含\0的長度
*/
int myStrlen2(char str[])
{
// 1.定義變數保存字串的長度
int length = 0;
while (str[length] != '\0')
{
length++;//1 2 3 4
}
return length;
}
/**
* 自定義方法計算字串的長度
* @param name 需要計算的字串
* @param count 字串的總長度
* @return 不包含\0的長度
*/
int myStrlen(char str[], int count)
{
// 1.定義變數保存字串的長度
int length = 0;
// 2.通過遍歷取出字串中的所有字符逐個比較
for (int i = 0; i < count; i++) {
// 3.判斷是否是字串結尾
if (str[i] == '\0') {
return length;
}
length++;
}
return length;
}
- 字串連接函式:strcat
- 格式: strcat(字符陣列名1,字符陣列名2)
- 功能:把字符陣列2中的字串連接到字符陣列1 中字串的后面,并刪去字串1后的串標志 “\0”,本函式回傳值是字符陣列1的首地址,
char oldStr[100] = "welcome to";
char newStr[20] = " lnj";
strcat(oldStr, newStr);
puts(oldStr); //輸出: welcome to lnj"
- 本程式把初始化賦值的字符陣列與動態賦值的字串連接起來,要注意的是,字符陣列1應定義足 夠的長度,否則不能全部裝入被連接的字串,
- 字串拷貝函式:strcpy
- 格式: strcpy(字符陣列名1,字符陣列名2)- 功能:把字符陣列2中的字串拷貝到字符陣列1中,串結束標志“\0”也一同拷貝,字符數名2, 也可以是一個字串常量,這時相當于把一個字串賦予一個字符陣列,
char oldStr[100] = "welcome to";
char newStr[50] = " lnj";
strcpy(oldStr, newStr);
puts(oldStr); // 輸出結果: lnj // 原有資料會被覆寫
- 本函式要求字符陣列1應有足夠的長度,否則不能全部裝入所拷貝的字串,
- 字串比較函式:strcmp
- 格式: strcmp(字符陣列名1,字符陣列名2)
- 功能:按照ASCII碼順序比較兩個陣列中的字串,并由函式回傳值回傳比較結果,
- 字串1=字串2,回傳值=0;
- 字串1>字串2,回傳值>0;
- 字串1<字串2,回傳值<0,
char oldStr[100] = "0";
char newStr[50] = "1";
printf("%d", strcmp(oldStr, newStr)); //輸出結果:-1
char oldStr[100] = "1";
char newStr[50] = "1";
printf("%d", strcmp(oldStr, newStr)); //輸出結果:0
char oldStr[100] = "1";
char newStr[50] = "0";
printf("%d", strcmp(oldStr, newStr)); //輸出結果:1
練習
- 撰寫一個函式char_contains(char str[],char key), 如果字串str中包含字符key則回傳數值1,否則回傳數值0
字串陣列基本概念
- 字串陣列其實就是定義一個陣列保存所有的字串
- 1.一維字符陣列中存放一個字串,比如一個名字char name[20] = “nj”
- 2.如果要存盤多個字串,比如一個班所有學生的名字,則需要二維字符陣列,char names[15][20]可以存放15個學生的姓名(假設姓名不超過20字符)
- 如果要存盤兩個班的學生姓名,那么可以用三維字符陣列char names[2][15][20]
##字串陣列的初始化
char names[2][10] = { {'l','n','j','\0'}, {'l','y','h','\0'} };
char names2[2][10] = { {"lnj"}, {"lyh"} };
char names3[2][10] = { "lnj", "lyh" };
指標基本概念
-
什么是地址
- 生活中的地址:

- 記憶體地址:
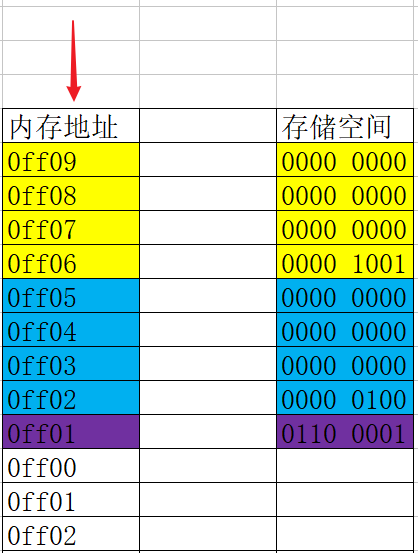
- 生活中的地址:
-
地址與記憶體單元中的資料是兩個完全不同的概念
- 地址如同房間編號, 根據這個編號我們可以找到對應的房間
- 記憶體單元如同房間, 房間是專門用于存盤資料的
-
變數地址:
- 系統分配給"變數"的"記憶體單元"的起始地址
int num = 6; // 占用4個位元組
//那么變數num的地址為: 0ff06
char c = 'a'; // 占用1個位元組
//那么變數c的地址為:0ff05
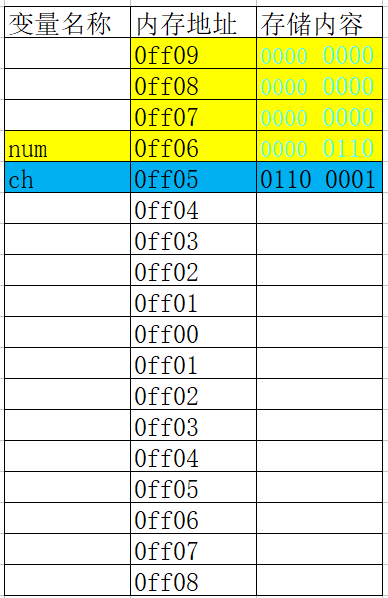
什么是指標
-
在計算機中所有資料都存盤在記憶體單元中,而每個記憶體單元都有一個對應的地址, 只要通過這個地址就能找到對應單元中存盤的資料.
-
由于通過地址能找到所需的變數單元,所以我們說該地址指向了該變數單元,將地址形象化的稱為“指標”
-
記憶體單元的指標(地址)和記憶體單元的內容是兩個不同的概念,

什么是指標變數
- 在C語言中,允許用一個變數來存放其它變數的地址, 這種專門用于存盤其它變數地址的變數, 我們稱之為指標變數
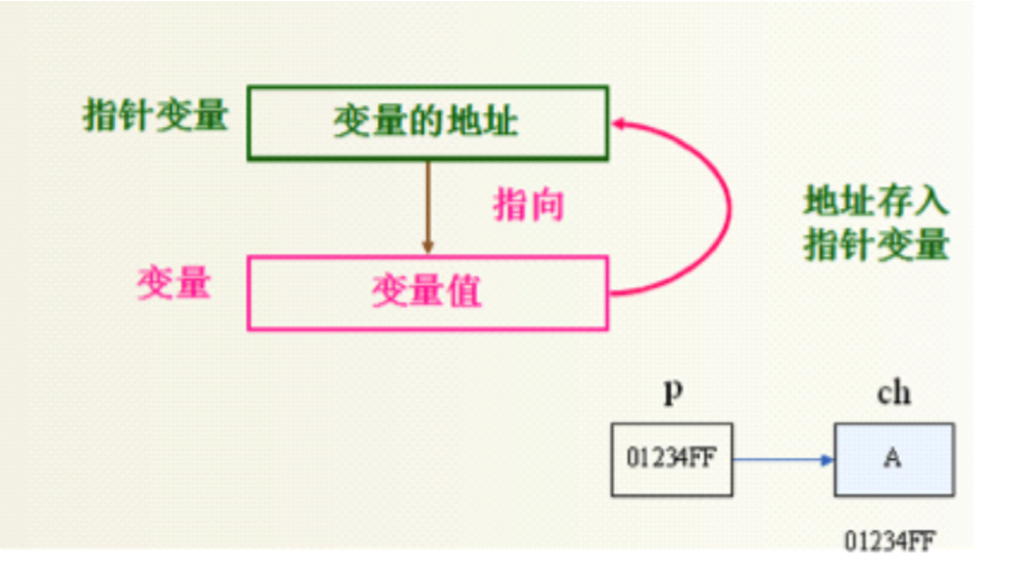
- 示例:
int age;// 定義一個普通變數
num = 10;
int *pnAge; // 定義一個指標變數
pnAge = &age;
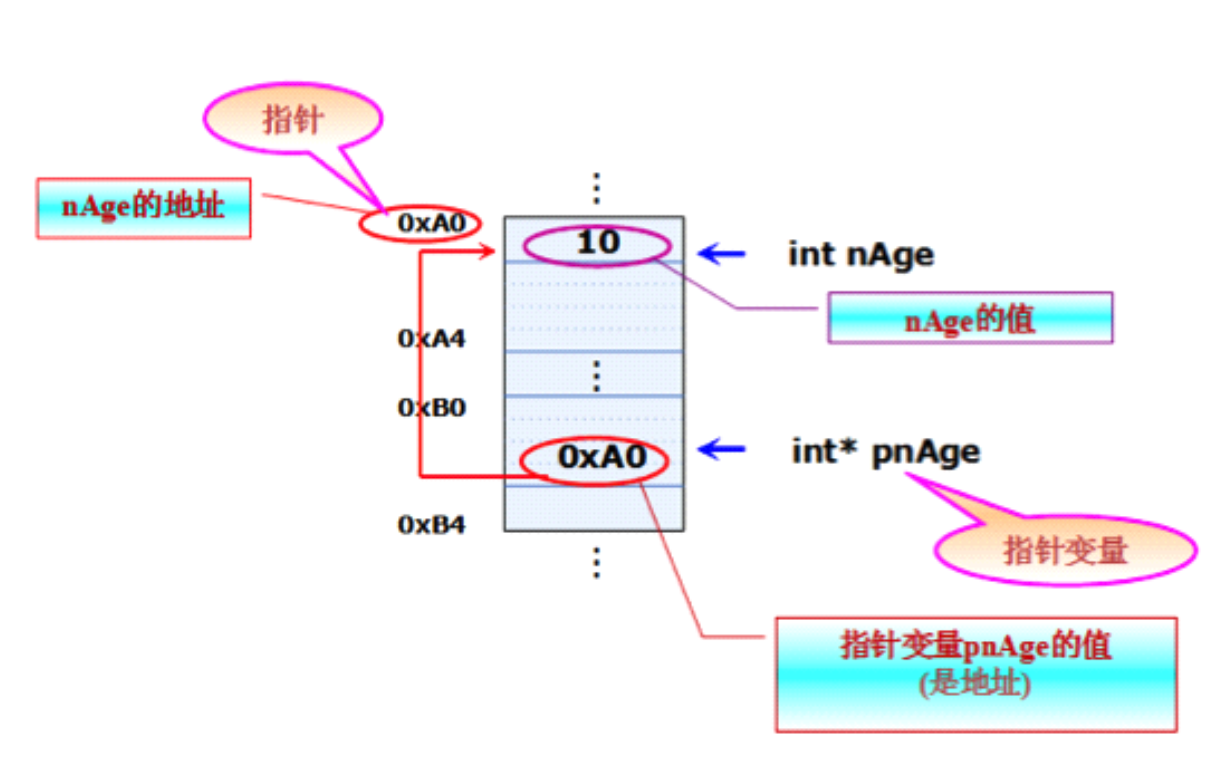
定義指標變數的格式
- 指標變數的定義包括兩個內容:
- 指標型別說明,即定義變數為一個指標變數;
- 指標變數名;

- 示例:
char ch = 'a';
char *p; // 一個用于指向字符型變數的指標
p = &ch;
int num = 666;
int *q; // 一個用于指向整型變數的指標
q = #
- 其中,*表示這是一個指標變數
- 變數名即為定義的指標變數名
- 型別說明符表示本指標變數所指向的變數的資料型別
指標變數的初始化方法
- 指標變數初始化的方法有兩種:定義的同時進行初始化和先定義后初始化
- 定義的同時進行初始化
int a = 5;
int *p = &a;
- 先定義后初始化
int a = 5;
int *p;
p=&a;
- 把指標初始化為NULL
int *p=NULL;
int *q=0;
- 不合法的初始化:
- 指標變數只能存盤地址, 不能存盤其它型別
int *p;
p = 250; // 錯誤寫法
- 給指標變數賦值時,指標變數前不能再加“*”
int *p;
*p=&a; //錯誤寫法
-
注意點:
- 多個指標變數可以指向同一個地址
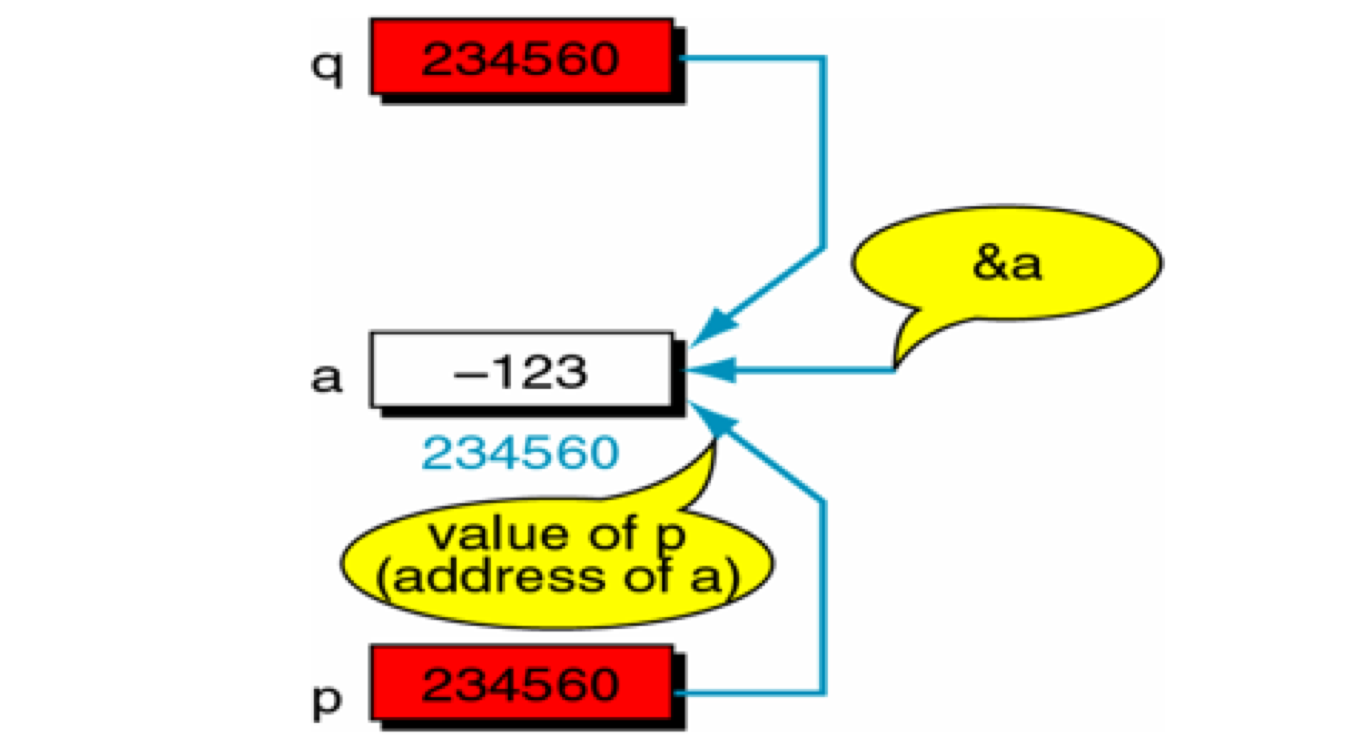
- 多個指標變數可以指向同一個地址
-
指標的指向是可以改變的
int a = 5;
int *p = &a;
int b = 10;
p = &b; // 修改指標指向
- 指標沒有初始化里面是一個垃圾值,這時候我們這是一個野指標
- 野指標可能會導致程式崩潰
- 野指標訪問你不該訪問資料
- 所以指標必須初始化才可以訪問其所指向存盤區域
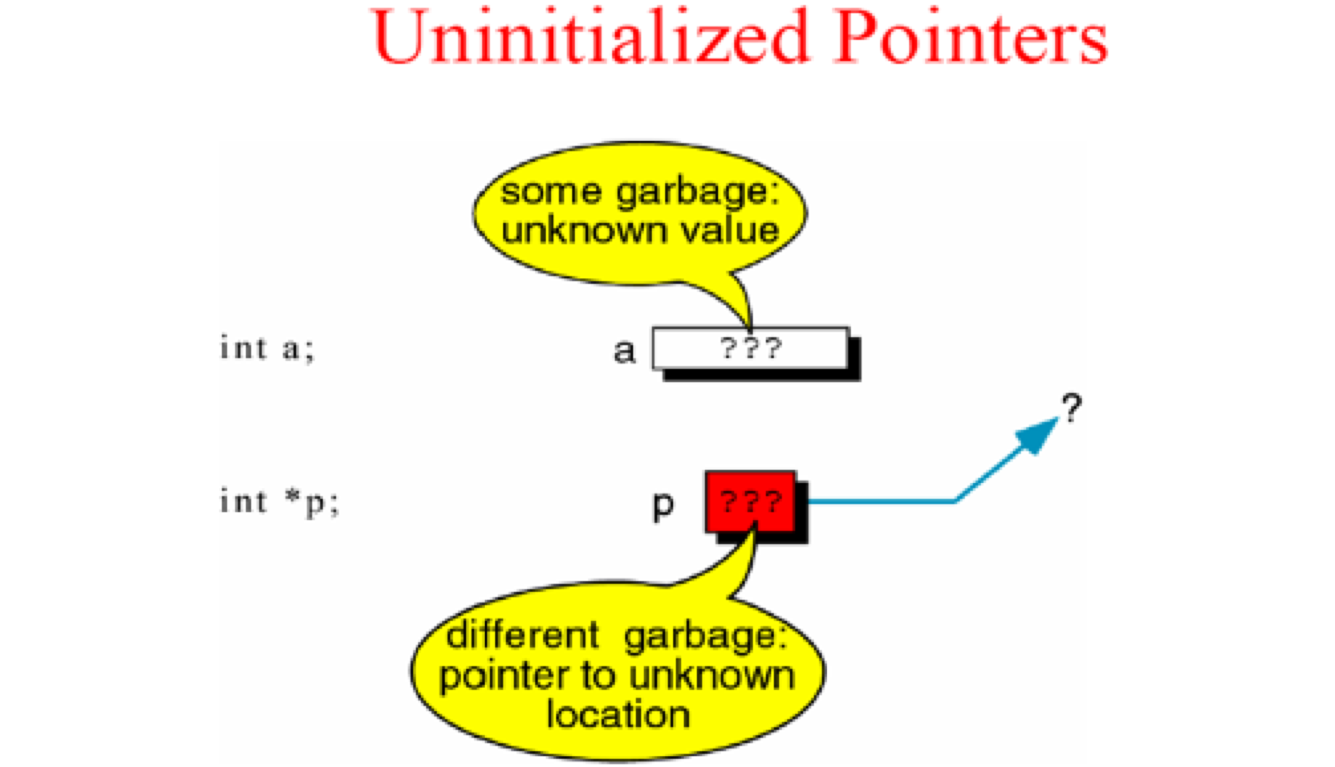
訪問指標所指向的存盤空間
- C語言中提供了地址運算子&來表示變數的地址,其一般形式為:
- &變數名;
- C語言中提供了*來定義指標變數和訪問指標變數指向的記憶體存盤空間
- 在定義變數的時候 * 是一個型別說明符,說明定義的這個變數是一個指標變數
int *p=NULL; // 定義指標變數
- 在不是定義變數的時候 *是一個運算子,代表訪問指標所指向存盤空間
int a = 5;
int *p = &a;
printf("a = %d", *p); // 訪問指標變數
指標型別
-
在同一種編譯器環境下,一個指標變數所占用的記憶體空間是固定的,

-
雖然在同一種編譯器下, 所有指標占用的記憶體空間是一樣的,但不同型別的變數卻占不同的位元組數
- 一個int占用4個位元組,一個char占用1個位元組,而一個double占用8位元組;
- 現在只有一個地址,我怎么才能知道要從這個地址開始向后訪問多少個位元組的存盤空間呢,是4個,是1個,還是8個,
- 所以指標變數需要它所指向的資料型別告訴它要訪問多少個位元組存盤空間

二級指標
- 如果一個指標變數存放的又是另一個指標變數的地址,則稱這個指標變數為指向指標的指標變數,也稱為“二級指標”
char c = 'a';
char *cp;
cp = &c;
char **cp2;
cp2 = &cp;
printf("c = %c", **cp2);
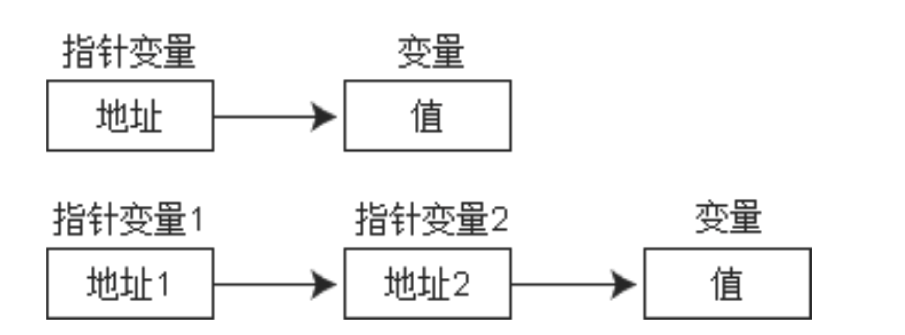
- 多級指標的取值規則
int ***m1; //取值***m1
int *****m2; //取值*****m2
練習
- 定義一個函式交換兩個變數的值
- 寫一個函式,同時回傳兩個數的和與差
##陣列指標的概念及定義
- 陣列元素指標
- 一個變數有地址,一個陣列包含若干元素,每個陣列元素也有相應的地址, 指標變數也可以保存陣列元素的地址
- 只要一個指標變數保存了陣列元素的地址, 我們就稱之為陣列元素指標

printf(“%p %p”, &(a[0]), a); //輸出結果:0x1100, 0x1100
- 注意: 陣列名a不代表整個陣列,只代表陣列首元素的地址,
- “p=a;”的作用是“把a陣列的首元素的地址賦給指標變數p”,而不是“把陣列a各元素的值賦給 p”
指標訪問陣列元素
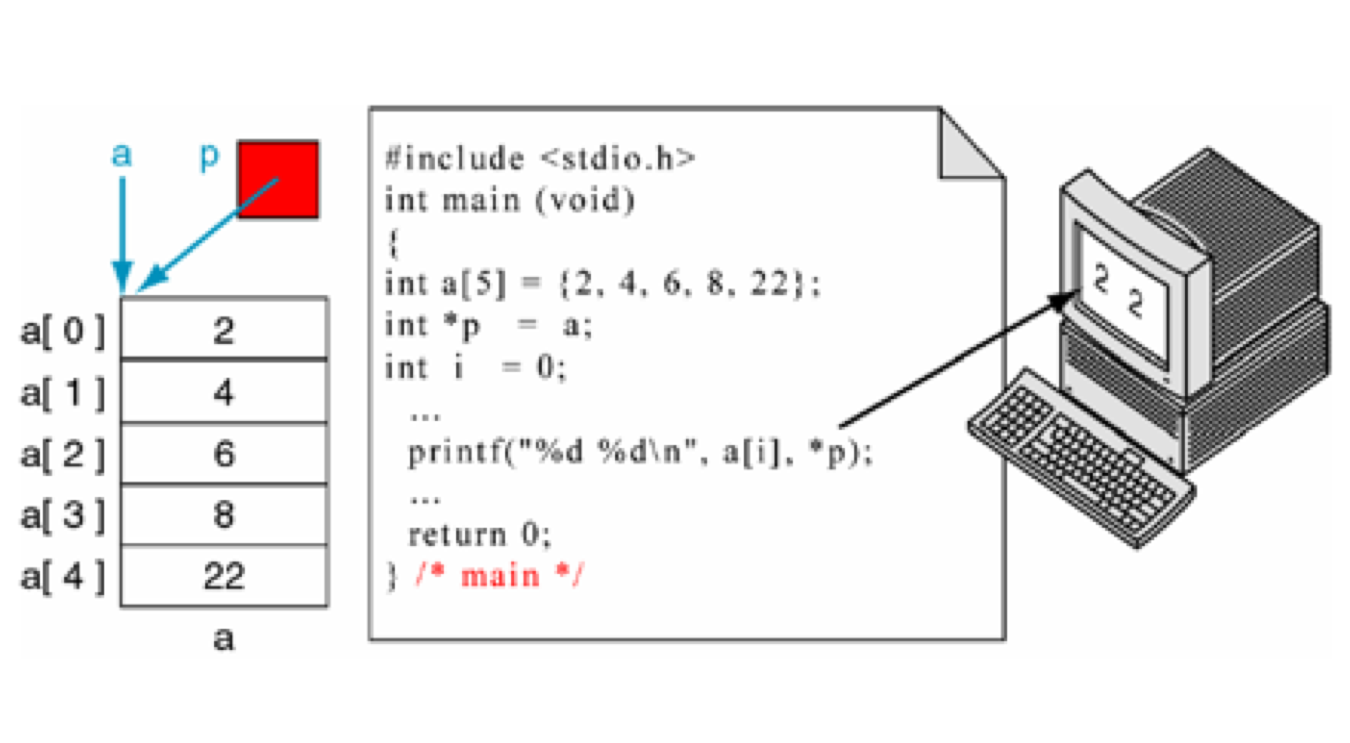
int main (void)
{
int a[5] = {2, 4, 6, 8, 22};
int *p;
// p = &(a[0]);
p = a;
printf(“%d %d\n”,a[0],*p); // 輸出結果: 2, 2
}
- 在指標指向陣列元素時,允許以下運算:
- 加一個整數(用+或+=),如p+1
- 減一個整數(用-或-=),如p-1
- 自加運算,如p++,++p
- 自減運算,如p–,--p
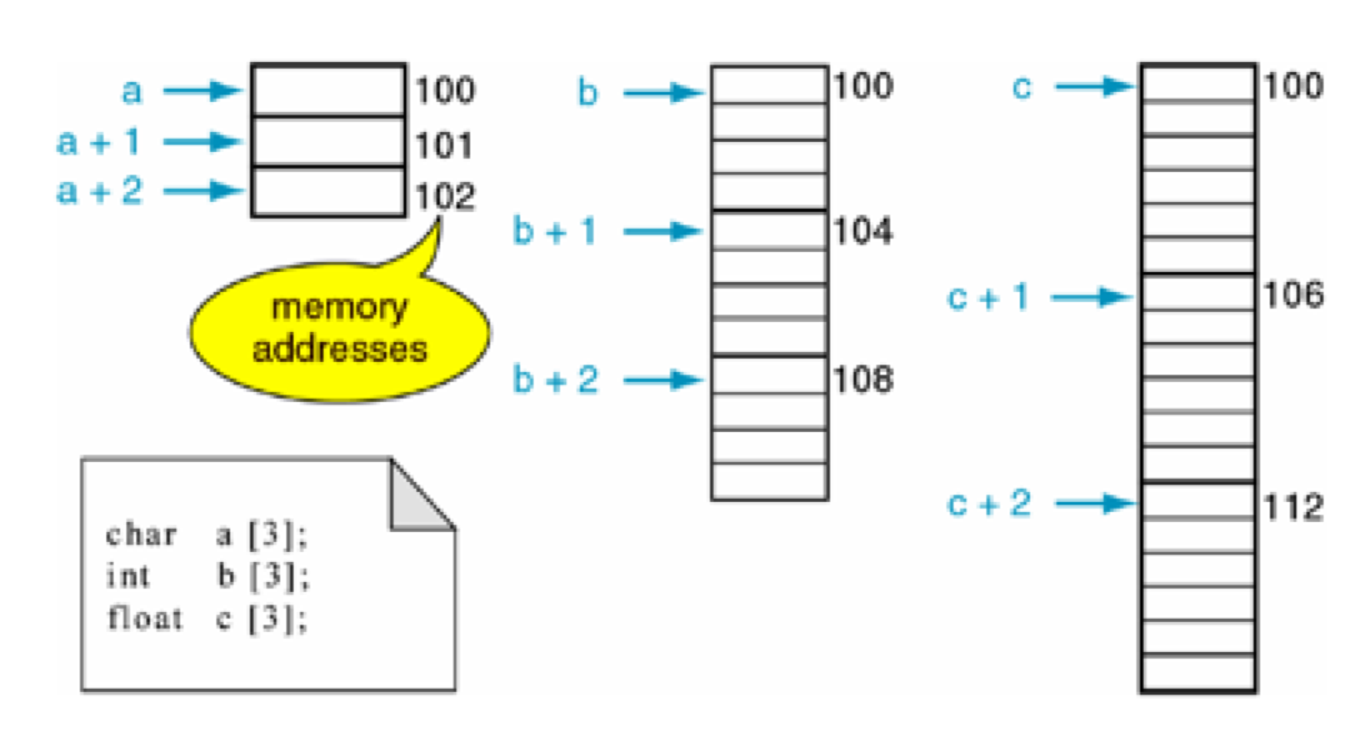
- 如果指標變數p已指向陣列中的一個元素,則p+1
指向同一陣列中的下一個元素,p-1指向同 一陣列中的上一個元素,
- 結論: 訪問陣列元素,可用下面兩種方法:
- 下標法, 如a[i]形式
- 指標法, *(p+i)形式
- 注意:
- 陣列名雖然是陣列的首地址,但是陣列名所所保存的陣列的首地址是不可以更改的
int x[10];
x++; //錯誤
int* p = x;
p++; //正確
指標與字串
- 定義字串的兩種方式
- 字符陣列
char string[]=”I love lnj!”;
printf("%s\n",string);
-
- 字串指標指向字串
// 陣列名保存的是陣列第0個元素的地址, 指標也可以保存第0個元素的地址
char *str = "abc"
- 字串指標使用注意事項
- 可以查看字串的每一個字符
har *str = "lnj";
for(int i = 0; i < strlen(str);i++)
{
printf("%c-", *(str+i)); // 輸出結果:l-n-j
}
-
- 不可以修改字串內容
// + 使用字符陣列來保存的字串是保存堆疊里的,保存堆疊里面東西是可讀可寫,所有可以修改字串中的的字符
// + 使用字符指標來保存字串,它保存的是字串常量地址,常量區是只讀的,所以我們不可以修改字串中的字符
char *str = "lnj";
*(str+2) = 'y'; // 錯誤
-
- 不能夠直接接收鍵盤輸入
// 錯誤的原因是:str是一個野指標,他并沒有指向某一塊記憶體空間
// 所以不允許這樣寫如果給str分配記憶體空間是可以這樣用 的
char *str;
scanf("%s", str);
指向函式指標
- 為什么指標可以指向一個函式?
- 函式作為一段程式,在記憶體中也要占據部分存盤空間,它也有一個起始地址
- 函式有自己的地址,那就好辦了,我們的指標變數就是用來存盤地址的,
- 因此可以利用一個指標指向一個函式,其中,函式名就代表著函式的地址,
- 指標函式的定義
- 格式:
回傳值型別 (*指標變數名)(形參1, 形參2, ...);
- 格式:
int sum(int a,int b)
{
return a + b;
}
int (*p)(int,int);
p = sum;
-
指標函式定義技巧
- 1、把要指向函式頭拷貝過來
- 2、把函式名稱使用小括號括起來
- 3、在函式名稱前面加上一個*
- 4、修改函式名稱
-
應用場景
- 呼叫函式
- 將函式作為引數在函式間傳遞
-
注意點:
- 由于這類指標變數存盤的是一個函式的入口地址,所以對它們作加減運算(比如p++)是無意義的
- 函式呼叫中"(指標變數名)"的兩邊的括號不可少,其中的不應該理解為求值運算,在此處它 只是一種表示符號
什么是結構體
- 結構體和陣列一樣屬于構造型別
- 陣列是用于保存一組相同型別資料的, 而結構體是用于保存一組不同型別陣列的
- 例如,在學生登記表中,姓名應為字符型;學號可為整型或字符型;年齡應為整型;性別應為字符型;成績可為整型或實型,
- 顯然這組資料不能用陣列來存放, 為了解決這個問題,C語言中給出了另一種構造資料型別——“結構(structure)”或叫“結構體”,
定義結構體型別
- 在使用結構體之前必須先定義結構體型別, 因為C語言不知道你的結構體中需要存盤哪些型別資料, 我們必須通過定義結構體型別來告訴C語言, 我們的結構體中需要存盤哪些型別的資料
- 格式:
struct 結構體名{
型別名1 成員名1;
型別名2 成員名2;
……
型別名n 成員名n;
};
- 示例:
struct Student {
char *name; // 姓名
int age; // 年齡
float height; // 身高
};
定義結構體變數
-
定好好結構體型別之后, 我們就可以利用我們定義的結構體型別來定義結構體變數
-
格式:
struct 結構體名 結構體變數名;

-
先定義結構體型別,再定義變數
struct Student {
char *name;
int age;
};
struct Student stu;
- 定義結構體型別的同時定義變數
struct Student {
char *name;
int age;
} stu;
- 匿名結構體定義結構體變數
struct {
char *name;
int age;
} stu;
- 第三種方法與第二種方法的區別在于,第三種方法中省去了結構體型別名稱,而直接給出結構變數,這種結構體最大的問題是結構體型別不能復用
結構體成員訪問
- 一般對結構體變數的操作是以成員為單位進行的,參考的一般形式為:
結構體變數名.成員名
struct Student {
char *name;
int age;
};
struct Student stu;
// 訪問stu的age成員
stu.age = 27;
printf("age = %d", stu.age);
結構體變數的初始化
- 定義的同時按順序初始化
struct Student {
char *name;
int age;
};
struct Student stu = {“lnj", 27};
- 定義的同時不按順序初始化
struct Student {
char *name;
int age;
};
struct Student stu = {.age = 35, .name = “lnj"};
- 先定義后逐個初始化
struct Student {
char *name;
int age;
};
struct Student stu;
stu.name = "lnj";
stu.age = 35;
- 先定義后一次性初始化
struct Student {
char *name;
int age;
};
struct Student stu;
stu2 = (struct Student){"lnj", 35};
結構體型別作用域
- 結構型別定義在函式內部的作用域與區域變數的作用域是相同的
- 從定義的那一行開始, 直到遇到return或者大括號結束為止
- 結構型別定義在函式外部的作用域與全域變數的作用域是相同的
- 從定義的那一行開始,直到本檔案結束為止
//定義一個全域結構體,作用域到檔案末尾
struct Person{
int age;
char *name;
};
int main(int argc, const char * argv[])
{
//定義區域結構體名為Person,會屏蔽全域結構體
//區域結構體作用域,從定義開始到“}”塊結束
struct Person{
int age;
};
// 使用區域結構體型別
struct Person pp;
pp.age = 50;
pp.name = "zbz";
test();
return 0;
}
void test() {
//使用全域的結構體定義結構體變數p
struct Person p = {10,"sb"};
printf("%d,%s\n",p.age,p.name);
}
結構體陣列
- 結構體陣列和普通陣列并無太大差異, 只不過是陣列中的元素都是結構體而已
- 格式:
struct 結構體型別名稱 陣列名稱[元素個數]
struct Student {
char *name;
int age;
};
struct Student stu[2];
- 結構體陣列初始化和普通陣列也一樣, 分為先定義后初始化和定義同時初始化
- 定義同時初始化
struct Student {
char *name;
int age;
};
struct Student stu[2] = {{"lnj", 35},{"zs", 18}};
-
- 先定義后初始化
struct Student {
char *name;
int age;
};
struct Student stu[2];
stu[0] = {"lnj", 35};
stu[1] = {"zs", 18};
結構體指標
- 一個指標變數當用來指向一個結構體變數時,稱之為結構體指標變數
- 格式:
struct 結構名 *結構指標變數名 - 示例:
// 定義一個結構體型別
struct Student {
char *name;
int age;
};
// 定義一個結構體變數
struct Student stu = {“lnj", 18};
// 定義一個指向結構體的指標變數
struct Student *p;
// 指向結構體變數stu
p = &stu;
/*
這時候可以用3種方式訪問結構體的成員
*/
// 方式1:結構體變數名.成員名
printf("name=%s, age = %d \n", stu.name, stu.age);
// 方式2:(*指標變數名).成員名
printf("name=%s, age = %d \n", (*p).name, (*p).age);
// 方式3:指標變數名->成員名
printf("name=%s, age = %d \n", p->name, p->age);
return 0;
}
- 通過結構體指標訪問結構體成員, 可以通過以下兩種方式
- (*結構指標變數).成員名
- 結構指標變數->成員名(用熟)
- (pstu)兩側的括號不可少,因為成員符“.”的優先級高于“”,
- 如去掉括號寫作pstu.num則等效于(pstu.num),這樣,意義就完全不對了,
結構體記憶體分析
- 給結構體變數開辟存盤空間和給普通開辟存盤空間一樣, 會從記憶體地址大的位置開始開辟
- 給結構體成員開辟存盤空間和給陣列元素開辟存盤空間一樣, 會從所占用記憶體地址小的位置開始開辟
- 結構體變數占用的記憶體空間永遠是所有成員中占用記憶體最大成員的倍數(對齊問題)
+多實際的計算機系統對基本型別資料在記憶體中存放的位置有限制,它們會要求這些資料的起始地址的值是 某個數k的倍數,這就是所謂的記憶體對齊,而這個k則被稱為該資料型別的對齊模數(alignment modulus),
- 這種強制的要求一來簡化了處理器與記憶體之間傳輸系統的設計,二來可以提升讀取資料的速度,比如這么一種處理器,它每次讀寫記憶體的時候都從某個8倍數的地址開始,一次讀出或寫入8個位元組的資料,假如軟體能 保證double型別的資料都從8倍數地址開始,那么讀或寫一個double型別資料就只需要一次記憶體操作,否則,我們就可能需要兩次記憶體操作才能完成這個動作,因為資料或許恰好橫跨在兩個符合對齊要求的8位元組 記憶體塊上
結構體變數占用存盤空間大小
struct Person{
int age; // 4
char ch; // 1
double score; // 8
};
struct Person p;
printf("sizeof = %i\n", sizeof(p)); // 16
- 占用記憶體最大屬性是score, 占8個位元組, 所以第一次會分配8個位元組
- 將第一次分配的8個位元組分配給age4個,分配給ch1個, 還剩下3個位元組
- 當需要分配給score時, 發現只剩下3個位元組, 所以會再次開辟8個位元組存盤空間
- 一共開辟了兩次8個位元組空間, 所以最終p占用16個位元組
struct Person{
int age; // 4
double score; // 8
char ch; // 1
};
struct Person p;
printf("sizeof = %i\n", sizeof(p)); // 24
- 占用記憶體最大屬性是score, 占8個位元組, 所以第一次會分配8個位元組
- 將第一次分配的8個位元組分配給age4個,還剩下4個位元組
- 當需要分配給score時, 發現只剩下4個位元組, 所以會再次開辟8個位元組存盤空間
- 將新分配的8個位元組分配給score, 還剩下0個位元組
- 當需要分配給ch時, 發現上一次分配的已經沒有了, 所以會再次開辟8個位元組存盤空間
- 一共開辟了3次8個位元組空間, 所以最終p占用24個位元組
結構體嵌套定義
- 成員也可以又是一個結構,即構成了嵌套的結構
struct Date{
int month;
int day;
int year;
}
struct stu{
int num;
char *name;
char sex;
struct Date birthday;
Float score;
}
- 在stu中嵌套存盤Date結構體內容

- 注意:
- 結構體不可以嵌套自己變數,可以嵌套指向自己這種型別的指標
struct Student { int age; struct Student stu; };
- 對嵌套結構體成員的訪問
- 如果某個成員也是結構體變數,可以連續使用成員運算子"."訪問最低一級成員
struct Date {
int year;
int month;
int day;
};
struct Student {
char *name;
struct Date birthday;
};
struct Student stu;
stu.birthday.year = 1986;
stu.birthday.month = 9;
stu.birthday.day = 10;
結構體和函式
- 結構體雖然是構造型別, 但是結構體之間賦值是值拷貝, 而不是地址傳遞
struct Person{
char *name;
int age;
};
struct Person p1 = {"lnj", 35};
struct Person p2;
p2 = p1;
p2.name = "zs"; // 修改p2不會影響p1
printf("p1.name = %s\n", p1.name); // lnj
printf("p2.name = %s\n", p2.name); // zs
- 所以結構體變數作為函式形參時也是值傳遞, 在函式內修改形參, 不會影響外界實參
#include <stdio.h>
struct Person{
char *name;
int age;
};
void test(struct Person per);
int main()
{
struct Person p1 = {"lnj", 35};
printf("p1.name = %s\n", p1.name); // lnj
test(p1);
printf("p1.name = %s\n", p1.name); // lnj
return 0;
}
void test(struct Person per){
per.name = "zs";
}
共用體
- 和結構體不同的是, 結構體的每個成員都是占用一塊獨立的存盤空間, 而共用體所有的成員都占用同一塊存盤空間
- 和結構體一樣, 共用體在使用之前必須先定義共用體型別, 再定義共用體變數
- 定義共用體型別格式:
union 共用體名{
資料型別 屬性名稱;
資料型別 屬性名稱;
... ....
};
- 定義共用體型別變數格式:
union 共用體名 共用體變數名稱;
- 特點: 由于所有屬性共享同一塊記憶體空間, 所以只要其中一個屬性發生了改變, 其它的屬性都會受到影響
- 示例:
union Test{
int age;
char ch;
};
union Test t;
printf("sizeof(p) = %i\n", sizeof(t));
t.age = 33;
printf("t.age = %i\n", t.age); // 33
t.ch = 'a';
printf("t.ch = %c\n", t.ch); // a
printf("t.age = %i\n", t.age); // 97
- 共用體的應用場景
- (1)通信中的資料包會用到共用體,因為不知道對方會發送什么樣的資料包過來,用共用體的話就簡單了,定義幾種格式的包,收到包之后就可以根據包的格式取出資料,
- (2)節約記憶體,如果有2個很長的資料結構,但不會同時使用,比如一個表示老師,一個表示學生,要統計老師和學生的情況,用結構體就比較浪費記憶體,這時就可以考慮用共用體來設計,
+(3)某些應用需要大量的臨時變數,這些變數型別不同,而且會隨時更換,而你的堆疊空間有限,不能同時分配那么多臨時變數,這時可以使用共用體讓這些變數共享同一個記憶體空間,這些臨時變數不用長期保存,用完即丟,和暫存器差不多,不用維護,
列舉
-
什么是列舉型別?
- 在實際問題中,有些變數的取值被限定在一個有限的范圍內,例如,一個星期內只有七天,一年只有十二個月,一個班每周有六門課程等等,如果把這些量說明為整型,字符型或其它型別 顯然是不妥當的,
- C語言提供了一種稱為“列舉”的型別,在“列舉”型別的定義中列舉出所有可能的取值, 被說明為該“列舉”型別的變數取值不能超過定義的范圍,
- 該說明的是,列舉型別是一種基本資料型別,而不是一種構造型別,因為它不能再分解為任何基本型別,

-
列舉型別的定義
- 格式:
enum 列舉名 {
列舉元素1,
列舉元素2,
……
};
-
- 示例:
// 表示一年四季
enum Season {
Spring,
Summer,
Autumn,
Winter
};
- 列舉變數
- 先定義列舉型別,再定義列舉變數
enum Season {
Spring,
Summer,
Autumn,
Winter
};
enum Season s;
-
- 定義列舉型別的同時定義列舉變數
enum Season {
Spring,
Summer,
Autumn,
Winter
} s;
- 省略列舉名稱,直接定義列舉變數
enum {
Spring,
Summer,
Autumn,
Winter
} s;
- 列舉型別變數的賦值和使用
enum Season {
Spring,
Summer,
Autumn,
Winter
} s;
s = Spring; // 等價于 s = 0;
s = 3; // 等價于 s = winter;
printf("%d", s);
- 列舉使用的注意
- C語言編譯器會將列舉元素(spring、summer等)作為整型常量處理,稱為列舉常量,
- 列舉元素的值取決于定義時各列舉元素排列的先后順序,默認情況下,第一個列舉元素的值為0,第二個為1,依次順序加1,
- 也可以在定義列舉型別時改變列舉元素的值
enum Season {
Spring,
Summer,
Autumn,
Winter
};
// 也就是說spring的值為0,summer的值為1,autumn的值為2,winter的值為3
enum Season {
Spring = 9,
Summer,
Autumn,
Winter
};
// 也就是說spring的值為9,summer的值為10,autumn的值為11,winter的值為12
全域變數和區域變數
- 變數作用域基本概念
- 變數作用域:變數的可用范圍
- 按照作用域的不同,變數可以分為:區域變數和全域變數
- 區域變數
- 定義在函式內部的變數以及函式的形參, 我們稱為區域變數
- 作用域:從定義的那一行開始, 直到遇到}結束或者遇到return為止
- 生命周期: 從程式運行到定義哪一行開始分配存盤空間到程式離開該變數所在的作用域
- 存盤位置: 區域變數會存盤在記憶體的堆疊區中
- 特點:
- 相同作用域內不可以定義同名變數
- 不同作用范圍可以定義同名變數,內部作用域的變數會覆寫外部作用域的變數
- 全域變數
- 定義在函式外面的變數稱為全域變數
- 作用域范圍:從定義哪行開始直到檔案結尾
- 生命周期:程式一啟動就會分配存盤空間,直到程式結束
- 存盤位置:靜態存盤區
- 特點: 多個同名的全域變數指向同一塊存盤空間
auto和register關鍵字
- auto關鍵字(忘記)
- 只能修飾區域變數, 區域變數如果沒有其它修飾符, 默認就是auto的
- 特點: 隨用隨開, 用完即銷
auto int num; // 等價于 int num;
- register關鍵字(忘記)
- 只能修飾區域變數, 原則上將記憶體中變數提升到CPU暫存器中存盤, 這樣訪問速度會更快
- 但是由于CPU暫存器數量相當有限, 通常不同平臺和編譯器在優化階段會自動轉換為auto
register int num;
static關鍵字
- 對區域變數的作用
- 延長區域變數的生命周期,從程式啟動到程式退出,但是它并沒有改變變數的作用域
- 定義變數的代碼在整個程式運行期間僅僅會執行一次
#include <stdio.h>
void test();
int main()
{
test();
test();
test();
return 0;
}
void test(){
static int num = 0; // 區域變數
num++;
// 如果不加static輸出 1 1 1
// 如果添加static輸出 1 2 3
printf("num = %i\n", num);
}
- 對全域變數的作用
- 全域變數分類:
- 內部變數:只能在本檔案中訪問的變數
- 外部變數:可以在其他檔案中訪問的變數,默認所有全域變數都是外部變數
- 默認情況下多個同名的全域變數共享一塊空間, 這樣會導致全域變數污染問題
- 如果想讓某個全域變數只在某個檔案中使用, 并且不和其他檔案中同名全域變數共享同一塊存盤空間, 那么就可以使用static
// A檔案中的代碼
int num; // 和B檔案中的num共享
void test(){
printf("ds.c中的 num = %i\n", num);
}
// B檔案中的代碼
#include <stdio.h>
#include "ds.h"
int num; // 和A檔案中的num共享
int main()
{
num = 666;
test(); // test中輸出666
return 0;
}
// A檔案中的代碼
static int num; // 不和B檔案中的num共享
void test(){
printf("ds.c中的 num = %i\n", num);
}
// B檔案中的代碼
#include <stdio.h>
#include "ds.h"
int num; // 不和A檔案中的num共享
int main()
{
num = 666;
test(); // test中輸出0
return 0;
}
extern關鍵字
- 對區域變數的作用
- extern不能用于區域變數
- extern代表宣告一個變數, 而不是定義一個變數, 變數只有定義才會開辟存盤空間
- 所以如果是區域變數, 雖然提前宣告有某個區域變數, 但是區域變數只有執行到才會分配存盤空間
#include <stdio.h>
int main()
{
extern int num;
num = 998; // 使用時并沒有存盤空間可用, 所以宣告了也沒用
int num; // 這里才會開辟
printf("num = %i\n", num);
return 0;
}
- 對全域變數的作用
- 宣告一個全域變數, 代表告訴編譯器我在其它地方定義了這個變數, 你可以放心使用
#include <stdio.h>
int main()
{
extern int num; // 宣告我們有名稱叫做num變數
num = 998; // 使用時已經有對應的存盤空間
printf("num = %i\n", num);
return 0;
}
int num; // 全域變數, 程式啟動就會分配存盤空間
static與extern對函式的作用
-
內部函式:只能在本檔案中訪問的函式
-
外部函式:可以在本檔案中以及其他的檔案中訪問的函式
-
默認情況下所有的函式都是外部函式
-
static 作用
- 宣告一個內部函式
static int sum(int num1,int num2);
- 定義一個內部函式
static int sum(int num1,int num2)
{
return num1 + num2;
}
- extern作用
- 宣告一個外部函式
extern int sum(int num1,int num2);
-
- 定義一個外部函式
extern int sum(int num1,int num2)
{
return num1 + num2;
}
- 注意點:
- 由于默認情況下所有的函式都是外部函式, 所以extern一般會省略
- 如果只有函式聲明添加了static與extern, 而定義中沒有添加static與extern, 那么無效
Qt Creator編譯程序做了什么?
- 當我們按下運行按鈕的時, 其實Qt Creator編譯器做了5件事情
- 對源檔案進行預處理, 生成預處理檔案
- 對預處理檔案進行編譯, 生成匯編檔案
- 對匯編檔案進行編譯, 生成二進制檔案
- 對二進制檔案進行鏈接, 生成可執行檔案
- 運行可執行檔案
- Qt Creator編譯程序驗證
- 1.撰寫代碼, 保存源檔案:
#include <stdio.h> int main(){ printf("hello lnj\n"); return 0; } - 2.執行預處理編譯

- 執行預處理編譯后生成的檔案

- 打開預處理編譯后生成的檔案
- 處理源檔案中預處理相關的指令
- 處理源檔案中多余注釋等
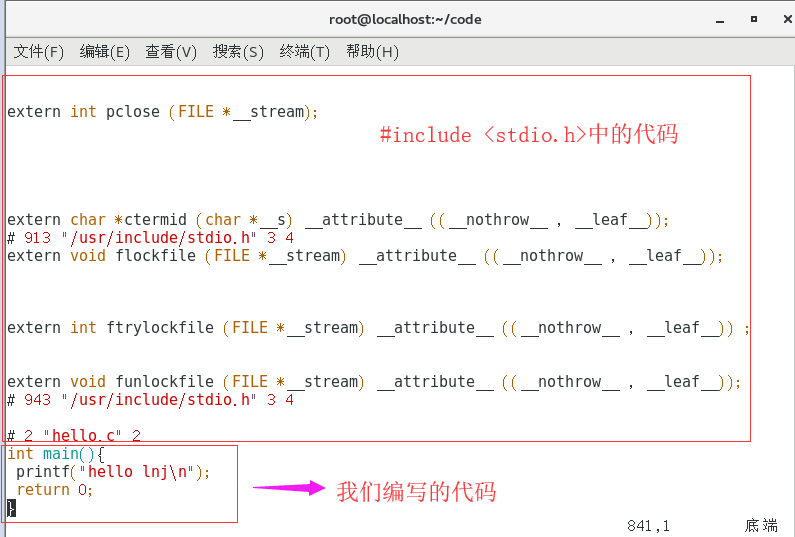
- 3.執行匯編編譯

- 執行匯編編譯后生成的檔案

- 打開匯編編譯后生成的檔案
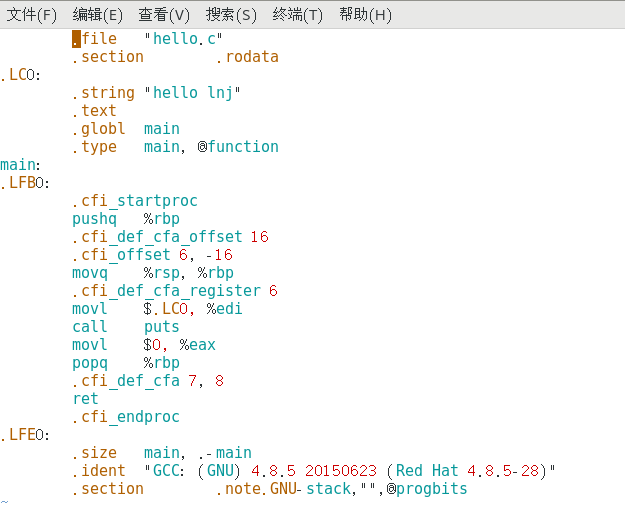
- 4.執行二進制編譯
- 執行二進制編譯后生成的檔案

- 打開二進制編譯后生成的檔案

- 5.執行鏈接操作
- 將依賴的一些C語言函式庫和我們編譯好的二進制合并為一個檔案
- 將依賴的一些C語言函式庫和我們編譯好的二進制合并為一個檔案
- 執行鏈接操作后生成的檔案
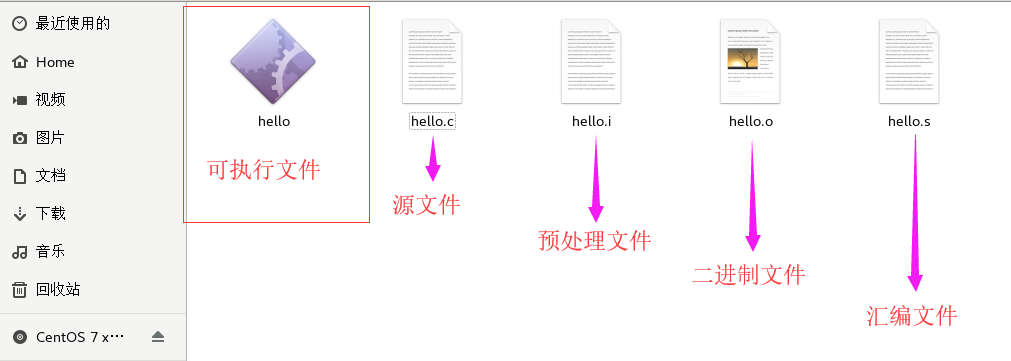
- 6.運行鏈接后生成的檔案
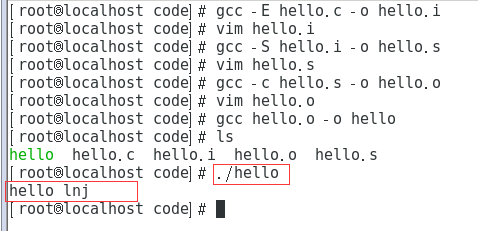
計算機是運算程序分析
- 1.撰寫一個簡單的加法運算
- 2.除錯撰寫好的代碼, 查看對應的匯編檔案
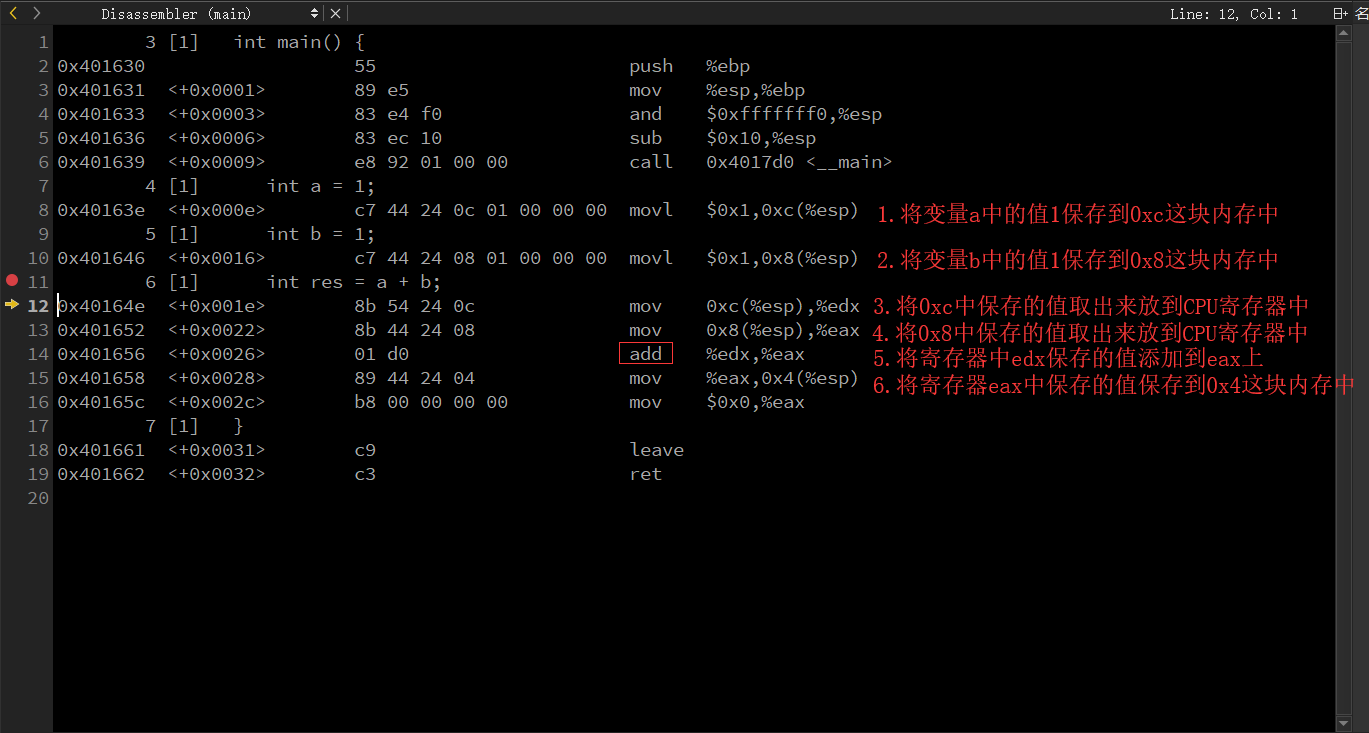
- 結論:
- 1.通過地址線找到對應地址的存盤單元
- 2.通過控制線發送記憶體讀取指令
- 3.通過資料線將記憶體中的值傳輸到CPU暫存器中
- 4.在CPU中完成計算操作
- 5.通過地址線找到對應地址的存盤單元
- 6.通過控制線發送記憶體寫入指令
- 7.通過資料線將計算結果傳輸到記憶體中
預處理指令
預處理指令的概念
- C語言在對源程式進行編譯之前,會先對一些特殊的預處理指令作解釋(比如之前使用的#include檔案包含指令),產生一個新的源程式(這個程序稱為編譯預處理),之后再進行通常的編譯
- 為了區分預處理指令和一般的C陳述句,所有預處理指令都以符號“#”開頭,并且結尾不用分號
- 預處理指令可以出現在程式的任何位置,它的作用范圍是從它出現的位置到檔案尾,習慣上我們盡可能將預處理指令寫在源程式開頭,這種情況下,它的作用范圍就是整個源程式檔案
- C語言提供了多種預處理功能,如宏定義、檔案包含、條件編譯等,合理地使用預處理功能撰寫的程式便于閱讀、修改、移植和除錯,也有利于模塊化程式設計,
宏定義
- 被定義為“宏”的識別符號稱為“宏名”,在編譯預處理時,對程式中所有出現的“宏名”,都用宏定義中的字串去代換,這稱為“宏代換”或“宏展開”,
- 宏定義是由源程式中的宏定義命令完成的,宏代換是由預處理程式自動完成的,在C語言中,“宏”分為有引數和無引數兩種,
##不帶引數的宏定義 - 格式:
#define 識別符號 字串- 其中的“#”表示這是一條預處理命令,凡是以“#”開頭的均為預處理命令,“define”為宏定義命令,“識別符號”為所定義的宏名,“字串”可以是常數、運算式、格式串等,
#include <stdio.h>
// 源程式中所有的宏名PI在編譯預處理的時候都會被3.14所代替
#define PI 3.14
// 根據圓的半徑計radius算周長
float girth(float radius) {
return 2 * PI *radius;
}
int main ()
{
float g = girth(2);
printf("周長為:%f", g);
return 0;
}
- 注意點:
- 宏名一般用大寫字母,以便與變數名區別開來,但用小寫也沒有語法錯誤
- 2)對程式中用雙引號擴起來的字串內的字符,不進行宏的替換操作
#define R 10
int main ()
{
char *s = "Radio"; // 在第1行定義了一個叫R的宏,但是第4行中"Radio"里面的'R'并不會被替換成10
return 0;
}
- 3)在編譯預處理用字串替換宏名時,不作語法檢查,只是簡單的字串替換,只有在編譯的時候才對已經展開宏名的源程式進行語法檢查
#define I 100
int main ()
{
int i[3] = I;
return 0;
}
-
- 宏名的有效范圍是從定義位置到檔案結束,如果需要終止宏定義的作用域,可以用#undef命令
#define PI 3.14
int main ()
{
printf("%f", PI);
return 0;
}
#undef PI
void test()
{
printf("%f", PI); // 不能使用
}
-
- 定義一個宏時可以參考已經定義的宏名
#define R 3.0
#define PI 3.14
#define L 2*PI*R
#define S PI*R*R
-
- 可用宏定義表示資料型別,使書寫方便
#define String char *
int main(int argc, const char * argv[])
{
String str = "This is a string!";
return 0;
}
帶引數的宏定義
- C語言允許宏帶有引數,在宏定義中的引數稱為形式引數,在宏呼叫中的引數稱為實際引數,對帶引數的宏,在呼叫中,不僅要宏展開,而且要用實參去代換形參
- 格式:
#define 宏名(形參表) 字串
// 第1行中定義了一個帶有2個引數的宏average,
#define average(a, b) (a+b)/2
int main ()
{
// 第4行其實會被替換成:int a = (10 + 4)/2;,
int a = average(10, 4);
// 輸出結果為:7是不是感覺這個宏有點像函式呢?
printf("平均值:%d", a);
return 0;
}
- 注意點:
- 1)宏名和引數串列之間不能有空格,否則空格后面的所有字串都作為替換的字串.
#define average (a, b) (a+b)/2
int main ()
{
int a = average(10, 4);
return 0;
}
注意第1行的宏定義,宏名average跟(a, b)之間是有空格的,于是,第5行就變成了這樣:
int a = (a, b) (a+b)/2(10, 4);
這個肯定是編譯不通過的
- 2)帶引數的宏在展開時,只作簡單的字符和引數的替換,不進行任何計算操作,所以在定義宏時,一般用一個小括號括住字串的引數,
#include <stdio.h>
// 下面定義一個宏D(a),作用是回傳a的2倍數值:
#define D(a) 2*a
// 如果定義宏的時候不用小括號括住引數
int main ()
{
// 將被替換成int b = 2*3+4;,輸出結果10,如果定義宏的時候用小括號括住引數,把上面的第3行改成:#define D(a) 2*(a),注意右邊的a是有括號的,第7行將被替換成int b = 2*(3+4);,輸出結果14
int b = D(3+4);
printf("%d", b);
return 0;
}
- 3)計算結果最好也用括號括起來
#include <stdio.h>
// 下面定義一個宏P(a),作用是回傳a的平方
#define Pow(a) (a) * (a) // 如果不用小括號括住計算結果
int main(int argc, const char * argv[]) {
// 代碼被替換為:int b = (10) * (10) / (2) * (2);
// 簡化之后:int b = 10 * (10 / 2) * 2;,最后變數b為:100
int b = Pow(10) / Pow(2);
printf("%d", b);
return 0;
}
#include <stdio.h>
// 計算結果用括號括起來
#define Pow(a) ( (a) * (a) )
int main(int argc, const char * argv[]) {
// 代碼被替換為:int b = ( (10) * (10) ) / ( (2) * (2) );
// 簡化之后:int b = (10 * 10) / (2 *2);,最后輸出結果:25
int b = Pow(10) / Pow(2);
printf("%d", b);
return 0;
}
條件編譯
- 在很多情況下,我們希望程式的其中一部分代碼只有在滿足一定條件時才進行編譯,否則不參與編譯(只有參與編譯的代碼最終才能被執行),這就是條件編譯,
- 為什么要使用條件編譯
- 1)按不同的條件去編譯不同的程式部分,因而產生不同的目標代碼檔案,有利于程式的移植和除錯,
- 2)條件編譯當然也可以用條件陳述句來實作, 但是用條件陳述句將會對整個源程式進行編譯,生成 的目標代碼程式很長,而采用條件編譯,則根據條件只編譯其中的程式段1或程式段2,生成的目 標程式較短,
##if-#else 條件編譯指令
- 第一種格式:
- 它的功能是,如常量運算式的值為真(非0),則將code1 編譯到程式中,否則對code2編譯到程式中,
- 注意:
- 是將代碼編譯進可執行程式, 而不是執行代碼
- 條件編譯后面的條件運算式中不能識別變數,它里面只能識別常量和宏定義
#if 常量運算式
..code1...
#else
..code2...
#endif
#define SCORE 67
#if SCORE > 90
printf("優秀\n");
#else
printf("不及格\n");
#endif
- 第二種格式:
#if 條件1
...code1...
#elif 條件2
...code2...
#else
...code3...
#endif
#define SCORE 67
#if SCORE > 90
printf("優秀\n");
#elif SCORE > 60
printf("良好\n");
#else
printf("不及格\n");
#endif
typedef關鍵字
- C語言不僅供了豐富的資料型別,而且還允許由用戶自己定義型別說明符,也就是說允許由用戶為資料型別取“別名”,
- 格式:
typedef 原型別名 新型別名;- 其中原型別名中含有定義部分,新型別名一般用大寫表示,以便于區別,
- 有時也可用宏定義來代替typedef的功能,但是宏定義是由預處理完成的,而typedef則是在編譯 時完成的,后者更為靈活方便,
##typedef使用
- 基本資料型別
typedef int INTEGER
INTEGER a; // 等價于 int a;
- 也可以在別名的基礎上再起一個別名
typedef int Integer;
typedef Integer MyInteger;
-
用typedef定義陣列、指標、結構等型別將帶來很大的方便,不僅使程式書寫簡單而且使意義更為 明確,因而增強了可讀性,
-
陣列型別
typedef char NAME[20]; // 表示NAME是字符陣列型別,陣列長度為20,然后可用NAME 說明變數,
NAME a; // 等價于 char a[20];
- 結構體型別
- 第一種形式:
struct Person{
int age;
char *name;
};
typedef struct Person PersonType;
+ 第二種形式:
typedef struct Person{
int age;
char *name;
} PersonType;
+ 第三種形式:
typedef struct {
int age;
char *name;
} PersonType;
- 列舉
- 第一種形式:
enum Sex{
SexMan,
SexWoman,
SexOther
};
typedef enum Sex SexType;
+ 第二種形式:
typedef enum Sex{
SexMan,
SexWoman,
SexOther
} SexType;
+ 第三種形式:
typedef enum{
SexMan,
SexWoman,
SexOther
} SexType;
- 指標
- typedef與指向結構體的指標
// 定義一個結構體并起別名
typedef struct {
float x;
float y;
} Point;
// 起別名
typedef Point *PP;
- typedef與指向函式的指標
// 定義一個sum函式,計算a跟b的和
int sum(int a, int b) {
int c = a + b;
printf("%d + %d = %d", a, b, c);
return c;
}
typedef int (*MySum)(int, int);
// 定義一個指向sum函式的指標變數p
MySum p = sum;
宏定義與函式以及typedef區別
- 與函式的區別
- 從整個使用程序可以發現,帶引數的宏定義,在源程式中出現的形式與函式很像,但是兩者是有本質區別的:
- 1> 宏定義不涉及存盤空間的分配、引數型別匹配、引數傳遞、回傳值問題
- 2> 函式呼叫在程式運行時執行,而宏替換只在編譯預處理階段進行,所以帶引數的宏比函式具有更高的執行效率
- 從整個使用程序可以發現,帶引數的宏定義,在源程式中出現的形式與函式很像,但是兩者是有本質區別的:
- typedef和#define的區別
- 用宏定義表示資料型別和用typedef定義資料說明符的區別,
- 宏定義只是簡單的字串替換,是在預處理完成的
- typedef是在編譯時處理的,它不是作簡單的代換,而是對型別說明符重新命名,被命名的識別符號具有型別定義說明的功能
- 用宏定義表示資料型別和用typedef定義資料說明符的區別,
typedef char *String;
int main(int argc, const char * argv[])
{
String str = "This is a string!";
return 0;
}
#define String char *
int main(int argc, const char * argv[])
{
String str = "This is a string!";
return 0;
}
typedef char *String1; // 給char *起了個別名String1
#define String2 char * // 定義了宏String2
int main(int argc, const char * argv[]) {
/*
只有str1、str2、str3才是指向char型別的指標變數
由于String1就是char *,所以上面的兩行代碼等于:
char *str1;
char *str2;
*/
String1 str1, str2;
/*
宏定義只是簡單替換, 所以相當于
char *str3, str4;
*號只對最近的一個有效, 所以相當于
char *str3;
char str4;
*/
String2 str3, str4;
return 0;
}
const關鍵字
- const是一個型別修飾符
- 使用const修飾變數則可以讓變數的值不能改變
##const有什么主要的作用?
- 使用const修飾變數則可以讓變數的值不能改變
- (1)可以定義const常量,具有不可變性
const int Max=100;
int Array[Max];
- (2)便于進行型別檢查,使編譯器對處理內容有更多了解,消除了一些隱患,
void f(const int i) { .........}
+ 編譯器就會知道i是一個常量,不允許修改;
-
(3)可以避免意義模糊的數字出現,同樣可以很方便地進行引數的調整和修改, 同宏定義一樣,可以做到不變則已,一變都變!如(1)中,如果想修改Max的內容,只需要:const int Max=you want;即可!
-
(4)可以保護被修飾的東西,防止意外的修改,增強程式的健壯性, 還是上面的例子,如果在 函式體內修改了i,編譯器就會報錯;
void f(const int i) { i=10;//error! }
- (5) 可以節省空間,避免不必要的記憶體分配,
#define PI 3.14159 //常量宏
const doulbe Pi=3.14159; //此時并未將Pi放入ROM中 ...... double i=Pi; //此時為Pi分配記憶體,以后不再分配!
double I=PI; //編譯期間進行宏替換,分配記憶體
double j=Pi; //沒有記憶體分配
double J=PI; //再進行宏替換,又一次分配記憶體! const定義常量從匯編的角度來看,只是給出了對應的記憶體地址,而不是象#define一樣給出的是立即數,所以,const定義的常量在程式運行程序中只有一份拷貝,而#define定義的常量在記憶體 中有若干個拷貝,
- (6) 高了效率,編譯器通常不為普通const常量分配存盤空間,而是將它們保存在符號表 中,這使得它成為一個編譯期間的常量,沒有了存盤與讀記憶體的操作,使得它的效率也很高,
如何使用const?
- (1)修飾一般常量一般常量是指簡單型別的常量,這種常量在定義時,修飾符const可以用在型別說明符前,也可以用在型別說明符后
int const x=2; 或 const int x=2;
- (當然,我們可以偷梁換柱進行更新: 通過強制型別轉換,將地址賦給變數,再作修改即可以改變const常量值,)
// const對于基本資料型別, 無論寫在左邊還是右邊, 變數中的值不能改變
const int a = 5;
// a = 666; // 直接修改會報錯
// 偷梁換柱, 利用指標指向變數
int *p;
p = &a;
// 利用指標間接修改變數中的值
*p = 10;
printf("%d\n", a);
printf("%d\n", *p);
- (2)修飾常陣列(值不能夠再改變了)定義或說明一個常陣列可采用如下格式:
int const a[5]={1, 2, 3, 4, 5};
const int a[5]={1, 2, 3, 4, 5};
const int a[5]={1, 2, 3, 4, 5};
a[1] = 55; // 錯誤
-
(3)修飾函式的常引數const修飾符也可以修飾函式的傳遞引數,格式如下:void Fun(const int Var); 告訴編譯器Var在函式體中的無法改變,從而防止了使用者的一些無 意的或錯誤的修改,
-
(4)修飾函式的回傳值: const修飾符也可以修飾函式的回傳值,是回傳值不可被改變,格式如 下:
const int Fun1();
const MyClass Fun2();
-
(5)修飾常指標
- const int *A; //const修飾指標,A可變,A指向的值不能被修改
- int const *A; //const修飾指向的物件,A可變,A指向的物件不可變
- int *const A; //const修飾指標A, A不可變,A指向的物件可變
- const int *const A;//指標A和A指向的物件都不可變
-
技巧
先看“*”的位置
如果const 在 *的左側 表示值不能修改,但是指向可以改,
如果const 在 *的右側 表示指向不能改,但是值可以改
如果在“*”的兩側都有const 標識指向和值都不能改,
記憶體管理
行程空間
- 程式,是經原始碼編譯后的可執行檔案,可執行檔案可以多次被執行,比如我們可以多次打開 office,
- 而行程,是程式加載到記憶體后開始執行,至執行結束,這樣一段時間概念,多次打開的wps,每打開一次都是一個行程,當我們每關閉一個 office,則表示該行程結束,
- 程式是靜態概念,而行程動態/時間概念,
###行程空間圖示
有了行程和程式的概念以后,我們再來看一下,程式被加載到記憶體以后記憶體空間布局是什么樣的
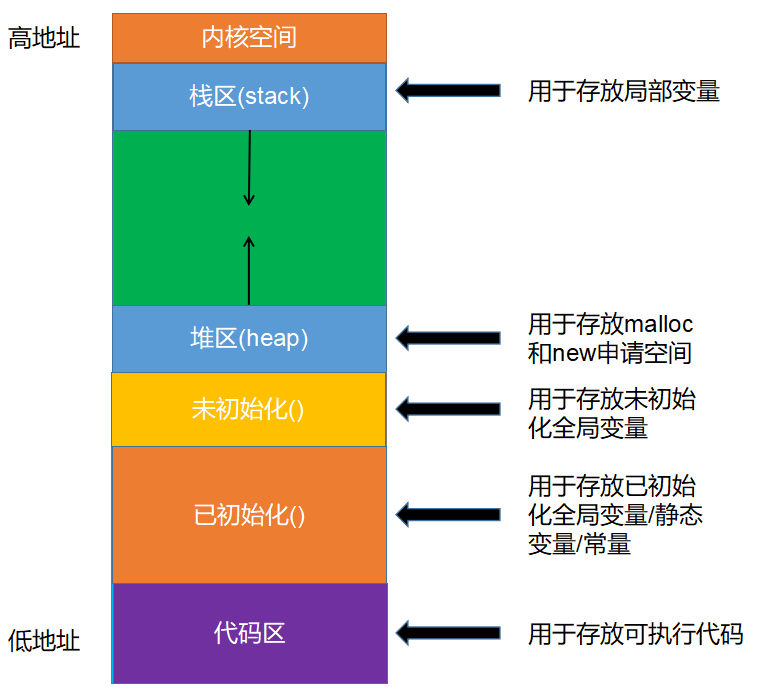
堆疊記憶體(Stack)
- 堆疊中存放任意型別的變數,但必須是 auto 型別修飾的,即自動型別的區域變數, 隨用隨開,用完即消,
- 記憶體的分配和銷毀系統自動完成,不需要人工干預
- 堆疊的最大尺寸固定,超出則引起堆疊溢位
- 區域變數過多,過大 或 遞回層數太多等就會導致堆疊溢位
int ages[10240*10240]; // 程式會崩潰, 堆疊溢位
#include <stdio.h>
int main()
{
// 存盤在堆疊中, 記憶體地址從大到小
int a = 10;
int b = 20;
printf("&a = %p\n", &a); // &a = 0060FEAC
printf("&b = %p\n", &b); // &b = 0060FEA8
return 0;
}
堆記憶體(Heap)
- 堆記憶體可以存放任意型別的資料,但需要自己申請與釋放
- 堆大小,想像中的無窮大,但實際使用中,受限于實際記憶體的大小和記憶體是否連續性
int *p = (int *)malloc(10240 * 1024); // 不一定會崩潰
#include <stdio.h>
#include <stdlib.h>
int main()
{
// 存盤在堆疊中, 記憶體地址從小到大
int *p1 = malloc(4);
*p1 = 10;
int *p2 = malloc(4);
*p2 = 20;
printf("p1 = %p\n", p1); // p1 = 00762F48
printf("p2 = %p\n", p2); // p2 = 00762F58
return 0;
}
malloc函式
| 函式宣告 | void * malloc(size_t _Size); |
|---|---|
| 所在檔案 | stdlib.h |
| 函式功能 | 申請堆記憶體空間并回傳,所申請的空間并未初始化, |
| 常見的初始化方法是 | memset 位元組初始化, |
| 引數及回傳決議 | |
| 引數 | size_t _size 表示要申請的字符數 |
| 回傳值 | void * 成功回傳非空指標指向申請的空間 ,失敗回傳 NULL |
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main()
{
/*
* malloc
* 第一個引數: 需要申請多少個位元組空間
* 回傳值型別: void *
*/
int *p = (int *)malloc(sizeof(int));
printf("p = %i\n", *p); // 保存垃圾資料
/*
* 第一個引數: 需要初始化的記憶體地址
* 第二個初始: 需要初始化的值
* 第三個引數: 需要初始化對少個位元組
*/
memset(p, 0, sizeof(int)); // 對申請的記憶體空間進行初始化
printf("p = %i\n", *p); // 初始化為0
return 0;
}
free函式
- 注意: 通過malloc申請的存盤空間一定要釋放, 所以malloc和free函式總是成對出現
| 函式宣告 | void free(void *p); |
|---|---|
| 所在檔案 | stdlib.h |
| 函式功能 | 釋放申請的堆記憶體 |
| 引數及回傳決議 | |
| 引數 | void* p 指向手動申請的空間 |
| 回傳值 | void 無回傳 |
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main()
{
// 1.申請4個位元組存盤空間
int *p = (int *)malloc(sizeof(int));
// 2.初始化4個位元組存盤空間為0
memset(p, 0, sizeof(int));
// 3.釋放申請的存盤空間
free(p);
return 0;
}
calloc函式
| 函式宣告 | void *calloc(size_t nmemb, size_t size); |
|---|---|
| 所在檔案 | stdlib.h |
| 函式功能 | 申請堆記憶體空間并回傳,所申請的空間,自動清零 |
| 引數及回傳決議 | |
| 引數 | size_t nmemb 所需記憶體單元數量 |
| 引數 | size_t size 記憶體單元位元組數量 |
| 回傳值 | void * 成功回傳非空指標指向申請的空間 ,失敗回傳 NULL |
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main()
{
/*
// 1.申請3塊4個位元組存盤空間
int *p = (int *)malloc(sizeof(int) * 3);
// 2.使用申請好的3塊存盤空間
p[0] = 1;
p[1] = 3;
p[2] = 5;
printf("p[0] = %i\n", p[0]);
printf("p[1] = %i\n", p[1]);
printf("p[2] = %i\n", p[2]);
// 3.釋放空間
free(p);
*/
// 1.申請3塊4個位元組存盤空間
int *p = calloc(3, sizeof(int));
// 2.使用申請好的3塊存盤空間
p[0] = 1;
p[1] = 3;
p[2] = 5;
printf("p[0] = %i\n", p[0]);
printf("p[1] = %i\n", p[1]);
printf("p[2] = %i\n", p[2]);
// 3.釋放空間
free(p);
return 0;
}
realloc函式
| 函式宣告 | void *realloc(void *ptr, size_t size); |
|---|---|
| 所在檔案 | stdlib.h |
| 函式功能 | 擴容(縮小)原有記憶體的大小,通常用于擴容,縮小會會導致記憶體縮去的部分資料丟失, |
| 引數及回傳決議 | |
| 引數 | void * ptr 表示待擴容(縮小)的指標, ptr 為之前用 malloc 或者 calloc 分配的記憶體地址, |
| 引數 | size_t size 表示擴容(縮小)后記憶體的大小, |
| 回傳值 | void* 成功回傳非空指標指向申請的空間 ,失敗回傳 NULL, |
- 注意點:
- 若引數ptr==NULL,則該函式等同于 malloc
- 回傳的指標,可能與 ptr 的值相同,也有可能不同,若相同,則說明在原空間后面申請,否則,則可能后續空間不足,重新申請的新的連續空間,原資料拷貝到新空間, 原有空間自動釋放
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main()
{
// 1.申請4個位元組存盤空間
int *p = NULL;
p = realloc(p, sizeof(int)); // 此時等同于malloc
// 2.使用申請好的空間
*p = 666;
printf("*p = %i\n", *p);
// 3.釋放空間
free(p);
return 0;
}
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main()
{
// 1.申請4個位元組存盤空間
int *p = malloc(sizeof(int));
printf("p = %p\n", p);
// 如果能在傳入存盤空間地址后面擴容, 回傳傳入存盤空間地址
// 如果不能在傳入存盤空間地址后面擴容, 回傳一個新的存盤空間地址
p = realloc(p, sizeof(int) * 2);
printf("p = %p\n", p);
// 2.使用申請好的空間
*p = 666;
printf("*p = %i\n", *p);
// 3.釋放空間
free(p);
return 0;
}
鏈表
- 鏈表實作了,記憶體零碎資料的有效組織,比如,當我們用 malloc 來進行記憶體申請的時候,當記憶體足夠,但是由于碎片太多,沒有連續記憶體時,只能以申請失敗而告終,而用鏈表這種資料結構來組織資料,就可以解決上類問題,

靜態鏈表
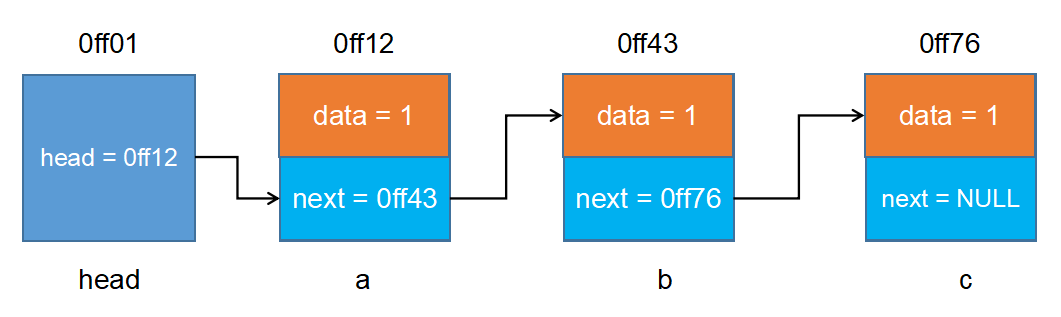
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
// 1.定義鏈表節點
typedef struct node{
int data;
struct node *next;
}Node;
int main()
{
// 2.創建鏈表節點
Node a;
Node b;
Node c;
// 3.初始化節點資料
a.data = 1;
b.data = 3;
c.data = 5;
// 4.鏈接節點
a.next = &b;
b.next = &c;
c.next = NULL;
// 5.創建鏈表頭
Node *head = &a;
// 6.使用鏈表
while(head != NULL){
int currentData = head->data;
printf("currentData = %i\n", currentData);
head = head->next;
}
return 0;
}
動態鏈表
-
靜態鏈表的意義不是很大,主要原因,資料存盤在堆疊上,堆疊的存盤空間有限,不能動態分配,所以鏈表要實作存盤的自由,要動態的申請堆里的空間,
-
有一個點要說清楚,我們的實作的鏈表是帶頭節點,至于,為什么帶頭節點,需等大家對鏈表有個整體的的認知以后,再來體會,會更有意義,
-
空鏈表
- 頭指標帶了一個空鏈表節點, 空鏈表節點中的next指向NULL
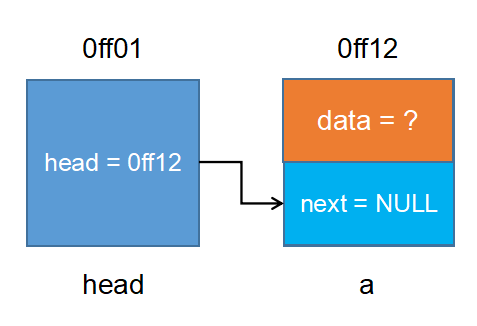
- 頭指標帶了一個空鏈表節點, 空鏈表節點中的next指向NULL
#include <stdio.h>
#include <stdlib.h>
// 1.定義鏈表節點
typedef struct node{
int data;
struct node *next;
}Node;
int main()
{
Node *head = createList();
return 0;
}
// 創建空鏈表
Node *createList(){
// 1.創建一個節點
Node *node = (Node *)malloc(sizeof(Node));
if(node == NULL){
exit(-1);
}
// 2.設定下一個節點為NULL
node->next = NULL;
// 3.回傳創建好的節點
return node;
}
- 非空鏈表
- 頭指標帶了一個非空節點, 最后一個節點中的next指向NULL
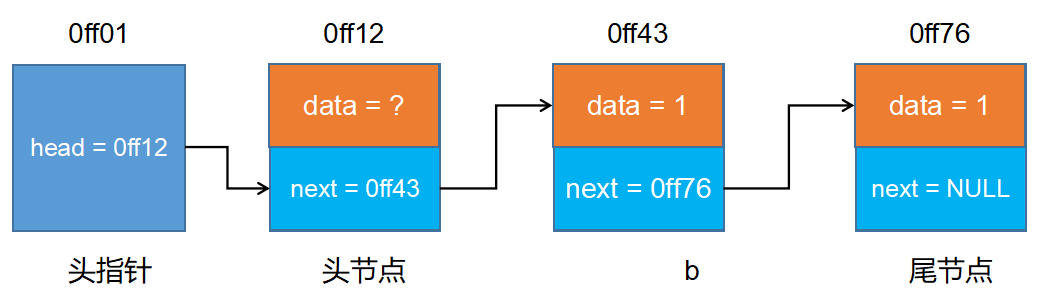
- 頭指標帶了一個非空節點, 最后一個節點中的next指向NULL
動態鏈表頭插法
- 1.讓新節點的下一個節點等于頭結點的下一個節點
- 2.讓頭節點的下一個節點等于新節點
#include <stdio.h>
#include <stdlib.h>
// 1.定義鏈表節點
typedef struct node{
int data;
struct node *next;
}Node;
Node *createList();
void printNodeList(Node *node);
int main()
{
Node *head = createList();
printNodeList(head);
return 0;
}
/**
* @brief createList 創建鏈表
* @return 創建好的鏈表
*/
Node *createList(){
// 1.創建頭節點
Node *head = (Node *)malloc(sizeof(Node));
if(head == NULL){
return NULL;
}
head->next = NULL;
// 2.接收用戶輸入資料
int num = -1;
printf("請輸入節點資料\n");
scanf("%i", &num);
// 3.通過回圈創建其它節點
while(num != -1){
// 3.1創建一個新的節點
Node *cur = (Node *)malloc(sizeof(Node));
cur->data = num;
// 3.2讓新節點的下一個節點指向頭節點的下一個節點
cur->next = head->next;
// 3.3讓頭節點的下一個節點指向新節點
head->next = cur;
// 3.4再次接收用戶輸入資料
scanf("%i", &num);
}
// 3.回傳創建好的節點
return head;
}
/**
* @brief printNodeList 遍歷鏈表
* @param node 鏈表指標頭
*/
void printNodeList(Node *node){
Node *head = node->next;
while(head != NULL){
int currentData = head->data;
printf("currentData = %i\n", currentData);
head = head->next;
}
}
動態鏈表尾插法
- 1.定義變數記錄新節點的上一個節點
- 2.將新節點添加到上一個節點后面
- 3.讓新節點成為下一個節點的上一個節點
#include <stdio.h>
#include <stdlib.h>
// 1.定義鏈表節點
typedef struct node{
int data;
struct node *next;
}Node;
Node *createList();
void printNodeList(Node *node);
int main()
{
Node *head = createList();
printNodeList(head);
return 0;
}
/**
* @brief createList 創建鏈表
* @return 創建好的鏈表
*/
Node *createList(){
// 1.創建頭節點
Node *head = (Node *)malloc(sizeof(Node));
if(head == NULL){
return NULL;
}
head->next = NULL;
// 2.接收用戶輸入資料
int num = -1;
printf("請輸入節點資料\n");
scanf("%i", &num);
// 3.通過回圈創建其它節點
// 定義變數記錄上一個節點
Node *pre = head;
while(num != -1){
// 3.1創建一個新的節點
Node *cur = (Node *)malloc(sizeof(Node));
cur->data = num;
// 3.2讓新節點鏈接到上一個節點后面
pre->next = cur;
// 3.3當前節點下一個節點等于NULL
cur->next = NULL;
// 3.4讓當前節點編程下一個節點的上一個節點
pre = cur;
// 3.5再次接收用戶輸入資料
scanf("%i", &num);
}
// 3.回傳創建好的節點
return head;
}
/**
* @brief printNodeList 遍歷鏈表
* @param node 鏈表指標頭
*/
void printNodeList(Node *node){
Node *head = node->next;
while(head != NULL){
int currentData = head->data;
printf("currentData = %i\n", currentData);
head = head->next;
}
}
動態鏈優化
#include <stdio.h>
#include <stdlib.h>
// 1.定義鏈表節點
typedef struct node{
int data;
struct node *next;
}Node;
Node *createList();
void printNodeList(Node *node);
void insertNode1(Node *head, int data);
void insertNode2(Node *head, int data);
int main()
{
// 1.創建一個空鏈表
Node *head = createList();
// 2.往空鏈表中插入資料
insertNode1(head, 1);
insertNode1(head, 3);
insertNode1(head, 5);
printNodeList(head);
return 0;
}
/**
* @brief createList 創建空鏈表
* @return 創建好的空鏈表
*/
Node *createList(){
// 1.創建頭節點
Node *head = (Node *)malloc(sizeof(Node));
if(head == NULL){
return NULL;
}
head->next = NULL;
// 3.回傳創建好的節點
return head;
}
/**
* @brief insertNode1 尾插法插入節點
* @param head 需要插入的頭指標
* @param data 需要插入的資料
* @return 插入之后的鏈表
*/
void insertNode1(Node *head, int data){
// 1.定義變數記錄最后一個節點
Node *pre = head;
while(pre != NULL && pre->next != NULL){
pre = pre->next;
}
// 2.創建一個新的節點
Node *cur = (Node *)malloc(sizeof(Node));
cur->data = data;
// 3.讓新節點鏈接到上一個節點后面
pre->next = cur;
// 4.當前節點下一個節點等于NULL
cur->next = NULL;
// 5.讓當前節點編程下一個節點的上一個節點
pre = cur;
}
/**
* @brief insertNode1 頭插法插入節點
* @param head 需要插入的頭指標
* @param data 需要插入的資料
* @return 插入之后的鏈表
*/
void insertNode2(Node *head, int data){
// 1.創建一個新的節點
Node *cur = (Node *)malloc(sizeof(Node));
cur->data = data;
// 2.讓新節點的下一個節點指向頭節點的下一個節點
cur->next = head->next;
// 3.讓頭節點的下一個節點指向新節點
head->next = cur;
}
/**
* @brief printNodeList 遍歷鏈表
* @param node 鏈表指標頭
*/
void printNodeList(Node *node){
Node *head = node->next;
while(head != NULL){
int currentData = head->data;
printf("currentData = %i\n", currentData);
head = head->next;
}
}
鏈表銷毀
/**
* @brief destroyList 銷毀鏈表
* @param head 鏈表頭指標
*/
void destroyList(Node *head){
Node *cur = NULL;
while(head != NULL){
cur = head->next;
free(head);
head = cur;
}
}
鏈表長度計算
/**
* @brief listLength 計算鏈表長度
* @param head 鏈表頭指標
* @return 鏈表長度
*/
int listLength(Node *head){
int count = 0;
head = head->next;
while(head){
count++;
head = head->next;
}
return count;
}
鏈表查找
/**
* @brief searchList 查找指定節點
* @param head 鏈表頭指標
* @param key 需要查找的值
* @return
*/
Node *searchList(Node *head, int key){
head = head->next;
while(head){
if(head->data == key){
break;
}else{
head = head->next;
}
}
return head;
}
鏈表洗掉
void deleteNodeList(Node *head, Node *find){
while(head->next != find){
head = head->next;
}
head->next = find->next;
free(find);
}
作業
- 給鏈表排序
/**
* @brief bubbleSort 對鏈表進行排序
* @param head 鏈表頭指標
*/
void bubbleSort(Node *head){
// 1.計算鏈表長度
int len = listLength(head);
// 2.定義變數記錄前后節點
Node *cur = NULL;
// 3.相鄰元素進行比較, 進行冒泡排序
for(int i = 0; i < len - 1; i++){
cur = head->next;
for(int j = 0; j < len - 1 - i; j++){
printf("%i, %i\n", cur->data, cur->next->data);
if((cur->data) > (cur->next->data)){
int temp = cur->data;
cur->data = cur->next->data;
cur->next->data = temp;
}
cur = cur->next;
}
}
}
/**
* @brief sortList 對鏈表進行排序
* @param head 鏈表頭指標
*/
void sortList(Node *head){
// 0.計算鏈表長度
int len = listLength(head);
// 1.定義變數保存前后兩個節點
Node *sh, *pre, *cur;
for(int i = 0; i < len - 1; i ++){
sh = head; // 頭節點
pre = sh->next; // 第一個節點
cur = pre->next; // 第二個節點
for(int j = 0; j < len - 1 - i; j++){
if(pre->data > cur->data){
// 交換節點位置
sh->next = cur;
pre->next = cur->next;
cur->next = pre;
// 恢復節點名稱
Node *temp = pre;
pre = cur;
cur = temp;
}
// 讓所有節點往后移動
sh = sh->next;
pre = pre->next;
cur = cur->next;
}
}
}
- 鏈表反轉
/**
* @brief reverseList 反轉鏈表
* @param head 鏈表頭指標
*/
void reverseList(Node *head){
// 1.將鏈表一分為二
Node *pre, *cur;
pre = head->next;
head->next = NULL;
// 2.重新插入節點
while(pre){
cur = pre->next;
pre->next = head->next;
head->next = pre;
pre = cur;
}
}
檔案基本概念
- 檔案流:
- C 語言把檔案看作是一個字符的序列,即檔案是由一個一個字符組成的字符流,因此 c 語言將檔案也稱之為檔案流,
- 檔案分類
-
文本檔案
- 以 ASCII 碼格式存放,一個位元組存放一個字符,
文本檔案的每一個位元組存放一個 ASCII 碼,代表一個字符,這便于對字符的逐個處理,但占用存盤空間
較多,而且要花費時間轉換, - .c檔案就是以文本檔案形式存放的
- 以 ASCII 碼格式存放,一個位元組存放一個字符,
-
二進制檔案
- 以補碼格式存放,二進制檔案是把資料以二進制數的格式存放在檔案中的,其占用存盤空間較少,
資料按其記憶體中的存盤形式原樣存放 - .exe檔案就是以二進制檔案形式存放的
- 以補碼格式存放,二進制檔案是把資料以二進制數的格式存放在檔案中的,其占用存盤空間較少,
-
- 文本檔案和二進制檔案示例
- 下列代碼暫時不要求看懂, 主要理解什么是文本檔案什么是二進制檔案
#include <stdio.h>
int main()
{
/*
* 以文本形式存盤
* 會將每個字符先轉換為對應的ASCII,
* 然后再將ASCII碼的二進制存盤到計算機中
*/
int num = 666;
FILE *fa = fopen("ascii.txt", "w");
fprintf(fa, "%d", num);
fclose(fa);
/*
* 以二進制形式存盤
* 會將666的二進制直接存盤到檔案中
*/
FILE *fb = fopen("bin.txt", "w");
fwrite(&num, 4, 1, fb);
fclose(fb);
return 0;
}
-
記憶體示意圖
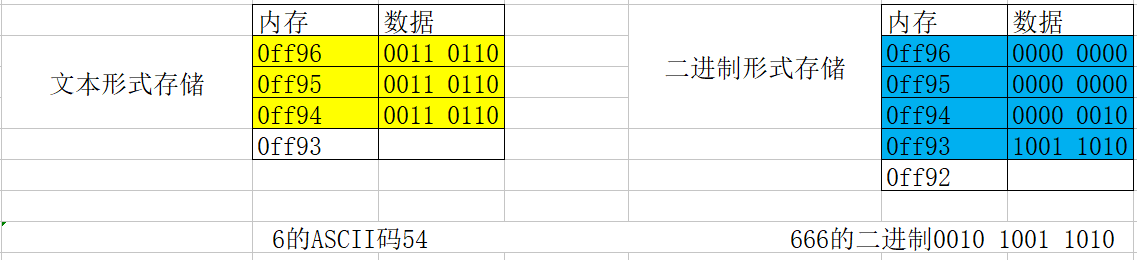
-
通過文本工具打開示意圖
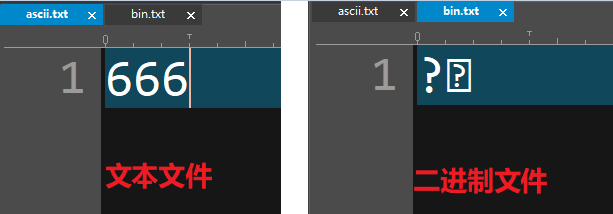
- 文本工具默認會按照ASCII碼逐個直接解碼檔案, 由于文本檔案存盤的就是ASCII碼, 所以可以正常決議顯示, 由于二進制檔案存盤的不是ASCII碼, 所以決議出來之后是亂碼
檔案的打開和關閉
- FILE 結構體
- FILE 結構體是對緩沖區和檔案讀寫狀態的記錄者,所有對檔案的操作,都是通過FILE 結構體完成的,
struct _iobuf {
char *_ptr; //檔案輸入的下一個位置
int _cnt; //當前緩沖區的相對位置
char *_base; //檔案的起始位置)
int _flag; //檔案標志
int _file; //檔案的有效性驗證
int _charbuf; //檢查緩沖區狀況,如果無緩沖區則不讀取
int _bufsiz; // 緩沖區大小
char *_tmpfname; //臨時檔案名
};
typedef struct _iobuf FILE;
- fileopen函式
| 函式宣告 | FILE * fopen ( const char * filename, const char * mode ); |
|---|---|
| 所在檔案 | stdio.h |
| 函式功能 | 以 mode 的方式,打開一個 filename 命名的檔案,回傳一個指向該檔案緩沖的 FILE 結構體指標, |
| 引數及回傳決議 | |
| 引數 | char*filaname :要打開,或是創建檔案的路徑, |
| 引數 | char*mode :打開檔案的方式, |
| 回傳值 | FILE* 回傳指向檔案緩沖區的指標,該指標是后序操作檔案的句柄, |
| mode | 處理方式 | 當檔案不存在時 | 當檔案存在時 | 向檔案輸入 | 從檔案輸出 |
|---|---|---|---|---|---|
| r | 讀取 | 出錯 | 打開檔案 | 不能 | 可以 |
| w | 寫入 | 建立新檔案 | 覆寫原有檔案 | 可以 | 不能 |
| a | 追加 | 建立新檔案 | 在原有檔案后追加 | 可以 | 不能 |
| r+ | 讀取/寫入 | 出錯 | 打開檔案 | 可以 | 可以 |
| w+ | 寫入/讀取 | 建立新檔案 | 覆寫原有檔案 | 可以 | 可以 |
| a+ | 讀取/追加 | 建立新檔案 | 在原有檔案后追加 | 可以 | 可以 |
注意點:
- Windows如果讀寫的是二進制檔案,則還要加 b,比如 rb, r+b 等, unix/linux 不區分文本和二進制檔案
- fclose函式
| 函式宣告 | int fclose ( FILE * stream ); |
|---|---|
| 所在檔案 | stdio.h |
| 函式功能 | fclose()用來關閉先前 fopen()打開的檔案. |
| 函式功能 | 此動作會讓緩沖區內的資料寫入檔案中, 并釋放系統所提供的檔案資源 |
| 引數及回傳決議 | |
| 引數 | FILE* stream :指向檔案緩沖的指標, |
| 回傳值 | int 成功回傳 0 ,失敗回傳 EOF(-1), |
#include <stdio.h>
int main()
{
FILE *fp = fopen("test.txt", "w+");
fclose(fp);
return 0;
}
–
一次讀寫一個字符
- 寫入
| 函式宣告 | int fputc (int ch, FILE * stream ); |
|---|---|
| 所在檔案 | stdio.h |
| 函式功能 | 將 ch 字符,寫入檔案, |
| 引數及回傳決議 | |
| 引數 | FILE* stream :指向檔案緩沖的指標, |
| 引數 | int : 需要寫入的字符, |
| 回傳值 | int 寫入成功,回傳寫入成功字符,如果失敗,回傳 EOF, |
#include <stdio.h>
int main()
{
// 1.打開一個檔案
FILE *fp = fopen("test.txt", "w+");
// 2.往檔案中寫入內容
for(char ch = 'a'; ch <= 'z'; ch++){
// 一次寫入一個字符
char res = fputc(ch, fp);
printf("res = %c\n", res);
}
// 3.關閉打開的檔案
fclose(fp);
return 0;
}
- 讀取
| 函式宣告 | int fgetc ( FILE * stream ); |
|---|---|
| 所在檔案 | stdio.h |
| 函式功能 | 從檔案流中讀取一個字符并回傳, |
| 引數及回傳決議 | |
| 引數 | FILE* stream :指向檔案緩沖的指標, |
| 回傳值 | int 正常,回傳讀取的字符;讀到檔案尾或出錯時,為 EOF, |
#include <stdio.h>
int main()
{
// 1.打開一個檔案
FILE *fp = fopen("test.txt", "r+");
// 2.從檔案中讀取內容
char res = EOF;
while((res = fgetc(fp)) != EOF){
printf("res = %c\n", res);
}
// 3.關閉打開的檔案
fclose(fp);
return 0;
}
- 判斷檔案末尾
- feof函式
| 函式宣告 | int feof( FILE * stream ); |
|---|---|
| 所在檔案 | stdio.h |
| 函式功能 | 判斷檔案是否讀到檔案結尾 |
| 引數及回傳決議 | |
| 引數 | FILE* stream :指向檔案緩沖的指標, |
| 回傳值 | int 0 未讀到檔案結尾,非零 讀到檔案結尾, |
#include <stdio.h>
int main()
{
// 1.打開一個檔案
FILE *fp = fopen("test.txt", "r+");
// 2.從檔案中讀取內容
char res = EOF;
// 注意: 由于只有先讀了才會修改標志位,
// 所以通過feof判斷是否到達檔案末尾, 一定要先讀再判斷, 不能先判斷再讀
while((res = fgetc(fp)) && (!feof(fp))){
printf("res = %c\n", res);
}
// 3.關閉打開的檔案
fclose(fp);
return 0;
}
- 注意點:
- feof 這個函式,是去讀標志位判斷檔案是否結束的,
- 而標志位只有讀完了才會被修改, 所以如果先判斷再讀標志位會出現多打一次的的現象
- 所以企業開發中使用feof函式一定要先讀后判斷, 而不能先判斷后讀
- 作業
- 實作檔案的簡單加密和解密
#include <stdio.h>
#include <string.h>
void encode(char *name, char *newName, int code);
void decode(char *name, char *newName, int code);
int main()
{
encode("main.c", "encode.c", 666);
decode("encode.c", "decode.c", 666);
return 0;
}
/**
* @brief encode 加密檔案
* @param name 需要加密的檔案名稱
* @param newName 加密之后的檔案名稱
* @param code 秘鑰
*/
void encode(char *name, char *newName, int code){
FILE *fw = fopen(newName, "w+");
FILE *fr = fopen(name, "r+");
char ch = EOF;
while((ch = fgetc(fr)) && (!feof(fr))){
fputc(ch ^ code, fw);
}
fclose(fw);
fclose(fr);
}
/**
* @brief encode 解密檔案
* @param name 需要解密的檔案名稱
* @param newName 解密之后的檔案名稱
* @param code 秘鑰
*/
void decode(char *name, char *newName, int code){
FILE *fw = fopen(newName, "w+");
FILE *fr = fopen(name, "r+");
char ch = EOF;
while((ch = fgetc(fr)) && (!feof(fr))){
fputc(ch ^ code, fw);
}
fclose(fw);
fclose(fr);
}
一次讀寫一行字符
- 什么是行
- 行是文本編輯器中的概念,檔案流中就是一個字符,這個在不同的平臺是有差異的,window 平臺 ‘\r\n’,linux 平臺是’\n’
- 平臺差異
- windows 平臺在寫入’\n’是會體現為’\r\n’,linux 平臺在寫入’\n’時會體現為’\n’,windows 平臺在讀入’\r\n’時,體現為一個字符’\n’,linux 平臺在讀入’\n’時,體現為一個字符’\n’
- linux 讀 windows 中的換行,則會多讀一個字符,windows 讀 linux 中的換行,則沒有問題
#include <stdio.h>
int main()
{
FILE *fw = fopen("test.txt", "w+");
fputc('a', fw);
fputc('\n', fw);
fputc('b', fw);
fclose(fw);
return 0;
}
- 寫入一行
| 函式宣告 | int fputs(char *str,FILE *fp) |
|---|---|
| 所在檔案 | stdio.h |
| 函式功能 | 把 str 指向的字串寫入 fp 指向的檔案中, |
| 引數及回傳決議 | |
| 引數 | char * str : 表示指向的字串的指標, |
| 引數 | FILE *fp : 指向檔案流結構的指標, |
| 回傳值 | int 正常,返 0;出錯返 EOF, |
#include <stdio.h>
int main()
{
FILE *fw = fopen("test.txt", "w+");
// 注意: fputs不會自動添加\n
fputs("lnj\n", fw);
fputs("it666\n", fw);
fclose(fw);
return 0;
}
- 遇到\0自動終止寫入
#include <stdio.h>
int main()
{
FILE *fp = fopen("test.txt", "w+");
// 注意: fputs寫入時遇到\0就會自動終止寫入
fputs("lnj\0it666\n", fp);
fclose(fp);
return 0;
}
- 讀取一行
| 函式宣告 | char *fgets(char *str,int length,FILE *fp) |
|---|---|
| 所在檔案 | stdio.h |
| 函式功能 | 從 fp 所指向的檔案中,至多讀 length-1 個字符,送入字符陣列 str 中, 如果在讀入 length-1 個字符結束前遇\n 或 EOF,讀入即結束,字串讀入后在最后加一個‘\0’字符, |
| 引數及回傳決議 | |
| 引數 | char * str :指向需要讀入資料的緩沖區, |
| 引數 | int length :每一次讀數字符的字數, |
| 引數 | FILE* fp :檔案流指標, |
| 回傳值 | char * 正常,返 str 指標;出錯或遇到檔案結尾 返空指標 NULL, |
- 最多只能讀取N-1個字符
#include <stdio.h>
int main()
{
FILE *fp = fopen("test.txt", "w+");
// 注意: fputs不會自動添加\n
fputs("it666\n", fp);
// 將FILE結構體中的讀寫指標重新移動到最前面
// 注意: FILE結構體中讀寫指標每讀或寫一個字符后都會往后移動
rewind(fp);
char str[1024];
// 從fp中讀取4個字符, 存入到str中
// 最多只能讀取N-1個字符, 會在最后自動添加\0
fgets(str, 4, fp);
printf("str = %s", str); // it6
fclose(fp);
return 0;
}
- 遇到\n自動結束
#include <stdio.h>
int main()
{
FILE *fp = fopen("test.txt", "w+");
// 注意: fputs不會自動添加\n
fputs("lnj\n", fp);
fputs("it666\n", fp);
// 將FILE結構體中的讀寫指標重新移動到最前面
// 注意: FILE結構體中讀寫指標每讀或寫一個字符后都會往后移動
rewind(fp);
char str[1024];
// 從fp中讀取1024個字符, 存入到str中
// 但是讀到第4個就是\n了, 函式會自動停止讀取
// 注意點: \n會被讀取進來
fgets(str, 1024, fp);
printf("str = %s", str); // lnj
fclose(fp);
return 0;
}
- 讀取到EOF自動結束
#include <stdio.h>
int main()
{
FILE *fp = fopen("test.txt", "w+");
// 注意: fputs不會自動添加\n
fputs("lnj\n", fp);
fputs("it666", fp);
// 將FILE結構體中的讀寫指標重新移動到最前面
// 注意: FILE結構體中讀寫指標每讀或寫一個字符后都會往后移動
rewind(fp);
char str[1024];
// 每次從fp中讀取1024個字符, 存入到str中
// 讀取到檔案末尾自動結束
while(fgets(str, 1024, fp)){
printf("str = %s", str);
}
fclose(fp);
return 0;
}
- 注意點:
- 企業開發中能不用feof函式就不用feof函式
- 如果最后一行,沒有行‘\n’的話則少讀一行
#include <stdio.h>
int main()
{
FILE *fp = fopen("test.txt", "w+");
// 注意: fputs不會自動添加\n
fputs("12345678910\n", fp);
fputs("12345678910\n", fp);
fputs("12345678910", fp);
// 將FILE結構體中的讀寫指標重新移動到最前面
// 注意: FILE結構體中讀寫指標每讀或寫一個字符后都會往后移動
rewind(fp);
char str[1024];
// 每次從fp中讀取1024個字符, 存入到str中
// 讀取到檔案末尾自動結束
while(fgets(str, 1024, fp) && !feof(fp)){
printf("str = %s", str);
}
fclose(fp);
return 0;
}
- 作業:
- 利用fgets(str, 5, fp)讀取下列文本會讀取多少次?
12345678910
12345
123
一次讀寫一塊資料
- C 語言己經從介面的層面區分了,文本的讀寫方式和二進制的讀寫方式,前面我們講的是文本的讀寫方式,
- 所有的檔案介面函式,要么以 ‘\0’,表示輸入結束,要么以 ‘\n’, EOF(0xFF)表示讀取結束, ‘\0’ ‘\n’ 等都是文本檔案的重要標識,而所有的二進制介面對于這些標識,是不敏感的,
+二進制的介面可以讀文本,而文本的介面不可以讀二進制
- 一次寫入一塊資料
| 函式宣告 | int fwrite(void *buffer, int num_bytes, int count, FILE *fp) |
|---|---|
| 所在檔案 | stdio.h |
| 函式功能 | 把buffer 指向的資料寫入fp 指向的檔案中 |
| 引數 | char * buffer : 指向要寫入資料存盤區的首地址的指標 |
| int num_bytes: 每個要寫的欄位的位元組數count | |
| int count : 要寫的欄位的個數 | |
| FILE* fp : 要寫的檔案指標 | |
| 回傳值 | int 成功,回傳寫的欄位數;出錯或檔案結束,回傳 0, |
#include <stdio.h>
#include <string.h>
int main()
{
FILE *fp = fopen("test.txt", "wb+");
// 注意: fwrite不會關心寫入資料的格式
char *str = "lnj\0it666";
/*
* 第一個引數: 被寫入資料指標
* 第二個引數: 每次寫入多少個位元組
* 第三個引數: 需要寫入多少次
* 第四個引數: 已打開檔案結構體指標
*/
fwrite((void *)str, 9, 1, fp);
fclose(fp);
return 0;
}
- 一次讀取一塊資料
| 函式宣告 | int fread(void *buffer, int num_bytes, int count, FILE *fp) |
|---|---|
| 所在檔案 | stdio.h |
| 函式功能 | 把fp 指向的檔案中的資料讀到 buffer 中, |
| 引數 | char * buffer : 指向要讀入資料存盤區的首地址的指標 |
| int num_bytes: 每個要讀的欄位的位元組數count | |
| int count : 要讀的欄位的個數 | |
| FILE* fp : 要讀的檔案指標 | |
| 回傳值 | int 成功,回傳讀的欄位數;出錯或檔案結束,回傳 0, |
#include <stdio.h>
int main()
{
// test.txt中存放的是"lnj\0it666"
FILE *fr = fopen("test.txt", "rb+");
char buf[1024] = {0};
// fread函式讀取成功回傳讀取到的位元組數, 讀取失敗回傳0
/*
* 第一個引數: 存盤讀取到資料的容器
* 第二個引數: 每次讀取多少個位元組
* 第三個引數: 需要讀取多少次
* 第四個引數: 已打開檔案結構體指標
*/
int n = fread(buf, 1, 1024, fr);
printf("%i\n", n);
for(int i = 0; i < n; i++){
printf("%c", buf[i]);
}
fclose(fr);
return 0;
}
- 注意點:
- 讀取時num_bytes應該填寫讀取資料型別的最小單位, 而count可以隨意寫
- 如果讀取時num_bytes不是讀取資料型別最小單位, 會引發讀取失敗
- 例如: 存盤的是char型別 6C 6E 6A 00 69 74 36 36 36
如果num_bytes等于1, count等于1024, 那么依次取出 6C 6E 6A 00 69 74 36 36 36 , 直到取不到為止
如果num_bytes等于4, count等于1024, 那么依次取出[6C 6E 6A 00][69 74 36 36] , 但是最后還剩下一個36, 但又不滿足4個位元組, 那么最后一個36則取不到
#include <stdio.h>
#include <string.h>
int main()
{
// test.txt中存放的是"lnj\0it666"
FILE *fr = fopen("test.txt", "rb+");
char buf[1024] = {0};
/*
while(fread(buf, 4, 1, fr) > 0){
printf("%c\n", buf[0]);
printf("%c\n", buf[1]);
printf("%c\n", buf[2]);
printf("%c\n", buf[3]);
}
*/
/*
while(fread(buf, 1, 4, fr) > 0){
printf("%c\n", buf[0]);
printf("%c\n", buf[1]);
printf("%c\n", buf[2]);
printf("%c\n", buf[3]);
}
*/
while(fread(buf, 1, 1, fr) > 0){
printf("%c\n", buf[0]);
}
fclose(fr);
return 0;
}
- 注意: fwrite和fread本質是用來操作二進制的
- 所以下面用法才是它們的正確打開姿勢
#include <stdio.h>
int main()
{
FILE *fp = fopen("test.txt", "wb+");
int ages[4] = {1, 3, 5, 6};
fwrite(ages, sizeof(ages), 1, fp);
rewind(fp);
int data;
while(fread(&data, sizeof(int), 1, fp) > 0){
printf("data = %i\n", data);
}
return 0;
}
讀寫結構體
- 結構體中的資料型別不統一,此時最適合用二進制的方式進行讀寫
- 讀寫單個結構體
#include <stdio.h>
typedef struct{
char *name;
int age;
double height;
} Person;
int main()
{
Person p1 = {"lnj", 35, 1.88};
// printf("name = %s\n", p1.name);
// printf("age = %i\n", p1.age);
// printf("height = %lf\n", p1.height);
FILE *fp = fopen("person.stu", "wb+");
fwrite(&p1, sizeof(p1), 1, fp);
rewind(fp);
Person p2;
fread(&p2, sizeof(p2), 1, fp);
printf("name = %s\n", p2.name);
printf("age = %i\n", p2.age);
printf("height = %lf\n", p2.height);
return 0;
}
- 讀寫結構體陣列
#include <stdio.h>
typedef struct{
char *name;
int age;
double height;
} Person;
int main()
{
Person ps[] = {
{"zs", 18, 1.65},
{"ls", 21, 1.88},
{"ww", 33, 1.9}
};
FILE *fp = fopen("person.stu", "wb+");
fwrite(&ps, sizeof(ps), 1, fp);
rewind(fp);
Person p;
while(fread(&p, sizeof(p), 1, fp) > 0){
printf("name = %s\n", p.name);
printf("age = %i\n", p.age);
printf("height = %lf\n", p.height);
}
return 0;
}
- 讀寫結構體鏈表
#include <stdio.h>
#include <stdlib.h>
typedef struct person{
char *name;
int age;
double height;
struct person* next;
} Person;
Person *createEmpty();
void insertNode(Person *head, char *name, int age, double height);
void printfList(Person *head);
int saveList(Person *head, char *name);
Person *loadList(char *name);
int main()
{
// Person *head = createEmpty();
// insertNode(head, "zs", 18, 1.9);
// insertNode(head, "ls", 22, 1.65);
// insertNode(head, "ws", 31, 1.78);
// printfList(head);
// saveList(head, "person.list");
Person *head = loadList("person.list");
printfList(head);
return 0;
}
/**
* @brief loadList 從檔案加載鏈表
* @param name 檔案名稱
* @return 加載好的鏈表頭指標
*/
Person *loadList(char *name){
// 1.打開檔案
FILE *fp = fopen(name, "rb+");
if(fp == NULL){
return NULL;
}
// 2.創建一個空鏈表
Person *head = createEmpty();
// 3.創建一個節點
Person *node = (Person *)malloc(sizeof(Person));
while(fread(node, sizeof(Person), 1, fp) > 0){
// 3.進行插入
// 3.1讓新節點的下一個節點 等于 頭節點的下一個節點
node->next = head->next;
// 3.2讓頭結點的下一個節點 等于 新節點
head->next = node;
// 給下一個節點申請空間
node = (Person *)malloc(sizeof(Person));
}
// 釋放多余的節點空間
free(node);
fclose(fp);
return head;
}
/**
* @brief saveList 存盤鏈表到檔案
* @param head 鏈表頭指標
* @param name 存盤的檔案名稱
* @return 是否存盤成功 -1失敗 0成功
*/
int saveList(Person *head, char *name){
// 1.打開檔案
FILE *fp = fopen(name, "wb+");
if(fp == NULL){
return -1;
}
// 2.取出頭節點的下一個節點
Person *cur = head->next;
// 3.將所有有效節點保存到檔案中
while(cur != NULL){
fwrite(cur, sizeof(Person), 1, fp);
cur = cur->next;
}
fclose(fp);
return 0;
}
/**
* @brief printfList 遍歷鏈表
* @param head 鏈表的頭指標
*/
void printfList(Person *head){
// 1.取出頭節點的下一個節點
Person *cur = head->next;
// 2.判斷是否為NULL, 如果不為NULL就開始遍歷
while(cur != NULL){
// 2.1取出當前節點的資料, 列印
printf("name = %s\n", cur->name);
printf("age = %i\n", cur->age);
printf("height = %lf\n", cur->height);
printf("next = %x\n", cur->next);
printf("-----------\n");
// 2.2讓當前節點往后移動
cur = cur->next;
}
}
/**
* @brief insertNode 插入新的節點
* @param head 鏈表的頭指標
* @param p 需要插入的結構體
*/
void insertNode(Person *head, char *name, int age, double height){
// 1.創建一個新的節點
Person *node = (Person *)malloc(sizeof(Person));
// 2.將資料保存到新節點中
node->name = name;
node->age = age;
node->height = height;
// 3.進行插入
// 3.1讓新節點的下一個節點 等于 頭節點的下一個節點
node->next = head->next;
// 3.2讓頭結點的下一個節點 等于 新節點
head->next = node;
}
/**
* @brief createEmpty 創建一個空鏈表
* @return 鏈表頭指標, 創建失敗回傳NULL
*/
Person *createEmpty(){
// 1.定義頭指標
Person *head = NULL;
// 2.創建一個空節點, 并且賦值給頭指標
head = (Person *)malloc(sizeof(Person));
if(head == NULL){
return head;
}
head->next = NULL;
// 3.回傳頭指標
return head;
}
其它檔案操作函式
- ftell 函式
| 函式宣告 | long ftell ( FILE * stream ); |
|---|---|
| 所在檔案 | stdio.h |
| 函式功能 | 得到流式檔案的當前讀寫位置,其回傳值是當前讀寫位置偏離檔案頭部的位元組數. |
| 引數及回傳決議 | |
| 引數 | FILE * 流檔案句柄 |
| 回傳值 | int 成功,回傳當前讀寫位置偏離檔案頭部的位元組數,失敗, 回傳-1 |
#include <stdio.h>
int main()
{
char *str = "123456789";
FILE *fp = fopen("test.txt", "w+");
long cp = ftell(fp);
printf("cp = %li\n", cp); // 0
// 寫入一個位元組
fputc(str[0], fp);
cp = ftell(fp);
printf("cp = %li\n", cp); // 1
fclose(fp);
return 0;
}
- rewind 函式
| 函式宣告 | void rewind ( FILE * stream ); |
|---|---|
| 所在檔案 | stdio.h |
| 函式功能 將檔案指標重新指向一個流的開頭, | |
| 引數及回傳決議 | |
| 引數 | FILE * 流檔案句柄 |
| 回傳值 | void 無回傳值 |
#include <stdio.h>
int main()
{
char *str = "123456789";
FILE *fp = fopen("test.txt", "w+");
long cp = ftell(fp);
printf("cp = %li\n", cp); // 0
// 寫入一個位元組
fputc(str[0], fp);
cp = ftell(fp);
printf("cp = %li\n", cp); // 1
// 新指向一個流的開頭
rewind(fp);
cp = ftell(fp);
printf("cp = %li\n", cp); // 0
fclose(fp);
return 0;
}
- fseek 函式
| 函式宣告 | int fseek ( FILE * stream, long offset, int where); |
|---|---|
| 所在檔案 | stdio.h |
| 函式功能 | 偏移檔案指標, |
| 引數及回傳決議 | |
| 參 數 | FILE * stream 檔案句柄 |
| long offset 偏移量 | |
| int where 偏移起始位置 | |
| 回傳值 | int 成功回傳 0 ,失敗回傳-1 |
- 常用宏
#define SEEK_CUR 1 當前文字
#define SEEK_END 2 檔案結尾
#define SEEK_SET 0 檔案開頭
#include <stdio.h>
int main()
{
FILE *fp = fopen("test.txt", "w+");
fputs("123456789", fp);
// 將檔案指標移動到檔案結尾, 并且偏移0個單位
fseek(fp, 0, SEEK_END);
int len = ftell(fp); // 計算檔案長度
printf("len = %i\n", len);
fclose(fp);
return 0;
}
#include <stdio.h>
int main()
{
FILE *fp;
fp = fopen("file.txt","w+");
fputs("123456789", fp);
fseek( fp, 7, SEEK_SET );
fputs("lnj", fp);
fclose(fp);
return 0;
}
如果覺得文章對你有幫助,點贊、收藏、關注、評論,一鍵四連支持,你的支持就是江哥持續更新的動力
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/287888.html
標籤:其他