RDD編程初級實踐
一、實驗目的
(1)熟悉Spark的RDD基本操作及鍵值對操作;
(2)熟悉使用RDD編程解決實際具體問題的方法,
二、實驗平臺
作業系統:Ubuntu16.04
Spark版本:2.4.0
Python版本:3.4.3
三、實驗內容和要求
1.pyspark互動式編程
本作業提供分析資料data.txt,該資料集包含了某大學計算機系的成績,資料格式如下所示:
Tom,DataBase,80
Tom,Algorithm,50
Tom,DataStructure,60
Jim,DataBase,90
Jim,Algorithm,60
Jim,DataStructure,80
……
請根據給定的實驗資料,在pyspark中通過編程來計算以下內容:
(1)該系總共有多少學生;
(2)該系共開設了多少門課程;
(3)Tom同學的總成績平均分是多少;
(4)求每名同學的選修的課程門數;
(5)該系DataBase課程共有多少人選修;
(6)各門課程的平均分是多少;
(7)使用累加器計算共有多少人選了DataBase這門課,
2.撰寫獨立應用程式實作資料去重
對于兩個輸入檔案A和B,撰寫Spark獨立應用程式,對兩個檔案進行合并,并剔除其中重復的內容,得到一個新檔案C,本文給出門課的成績(A.txt、B.txt)下面是輸入檔案和輸出檔案的一個樣例,供參考,
輸入檔案A的樣例如下:
20200101 x
20200102 y
20200103 x
20200104 y
20200105 z
20200106 z
輸入檔案B的樣例如下:
20200101 y
20200102 y
20200103 x
20200104 z
20200105 y
根據輸入的檔案A和B合并得到的輸出檔案C的樣例如下:
20200101 x
20200101 y
20200102 y
20200103 x
20200104 y
20200104 z
20200105 y
20200105 z
20200106 z
3.撰寫獨立應用程式實作求平均值問題
每個輸入檔案表示班級學生某個學科的成績,每行內容由兩個欄位組成,第一個是學生名字,第二個是學生的成績;撰寫Spark獨立應用程式求出所有學生的平均成績,并輸出到一個新檔案中,本文給出門課的成績(Algorithm.txt、Database.txt、Python.txt),下面是輸入檔案和輸出檔案的一個樣例,供參考,
Algorithm成績:
小明 92
小紅 87
小新 82
小麗 90
Database成績:
小明 95
小紅 81
小新 89
小麗 85
Python成績:
小明 82
小紅 83
小新 94
小麗 91
平均成績如下:
(小紅,83.67)
(小新,88.33)
(小明,89.67)
(小麗,88.67)
四、實驗結果與分析
1.pyspark互動式編程
本作業提供分析資料data.txt,該資料集包含了某大學計算機系的成績,資料格式如下所示:
Tom,DataBase,80
Tom,Algorithm,50
Tom,DataStructure,60
Jim,DataBase,90
Jim,Algorithm,60
Jim,DataStructure,80
……
請根據給定的實驗資料,在pyspark中通過編程來計算以下內容:
(1)該系總共有多少學生;
首先將 data.txt檔案復制到 /usr/local/spark/sparksqldata 檔案目錄下,cp data.txt /usr/local/spark/sparksqldata,如圖所示:

然后輸入pyspark打開spark-shell就可以開始編程,如下圖:
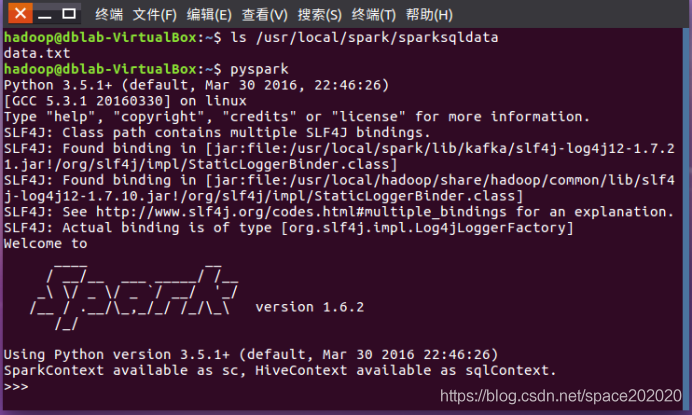
該系總共有多少學生的代碼撰寫:
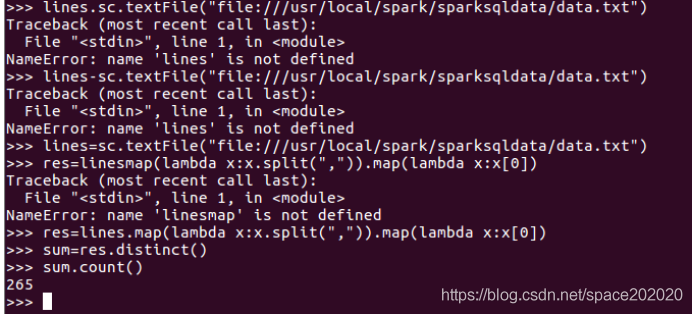
(2)該系共開設了多少門課程:

(3)Tom同學的總成績平均分是多少:
先求Tom的各科成績,如圖:
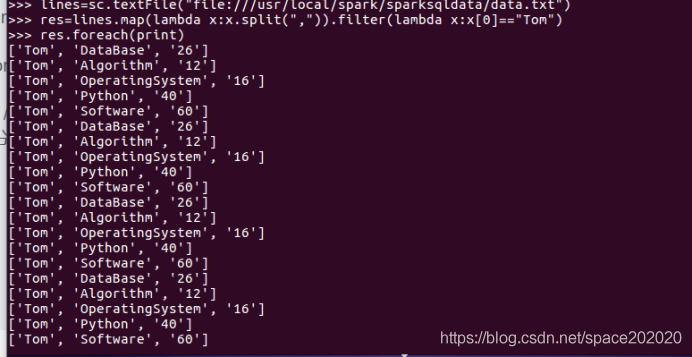
再求Tom同學的總成績平均分,如圖:
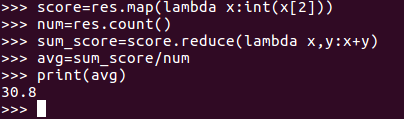
(4)求每名同學的選修的課程門數;
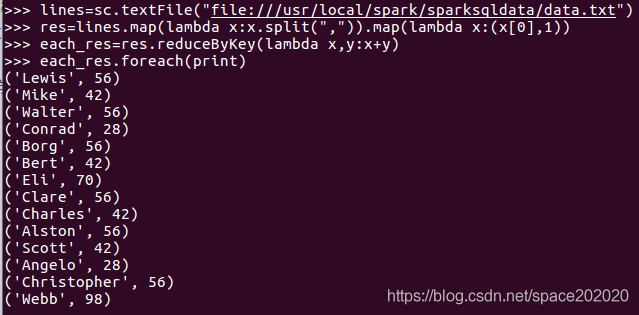
(5)該系DataBase課程共有多少人選修;
lines = sc.textFile(“file:///usr/local/spark/sparksqldata/Data01.txt”)
res = lines.map(lambda x:x.split(",")).filter(lambda x:x[1]==“DataBase”)
res.count()
//126
答案為126人
(6)各門課程的平均分是多少;
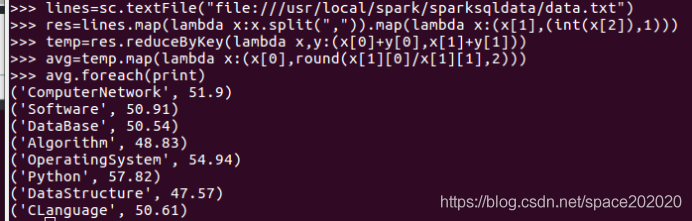
(7)使用累加器計算共有多少人選了DataBase這門課,
lines = sc.textFile(“file:///usr/local/spark/sparksqldata/Data01.txt”)
res = lines.map(lambda x:x.split(",")).filter(lambda x:x[1]==“DataBase”)//篩選出選了DataBase課程的資料
accum = sc.accumulator(0) //定義一個從0開始的累加器accum
res.foreach(lambda x:accum.add(1))//遍歷res,每掃描一條資料,累加器加1
accum.value //輸出累加器的最終值
//126
答案:共有126人
2.撰寫獨立應用程式實作資料去重
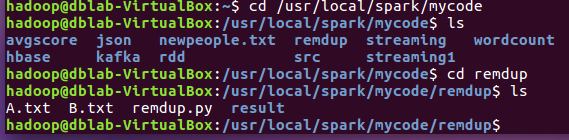
(1)首先將 ~/下載/大資料實踐期末大作業 檔案夾中的A.txt和B.txt檔案復制到 /usr/local/spark/mycode/remdup 檔案目錄下,如圖:
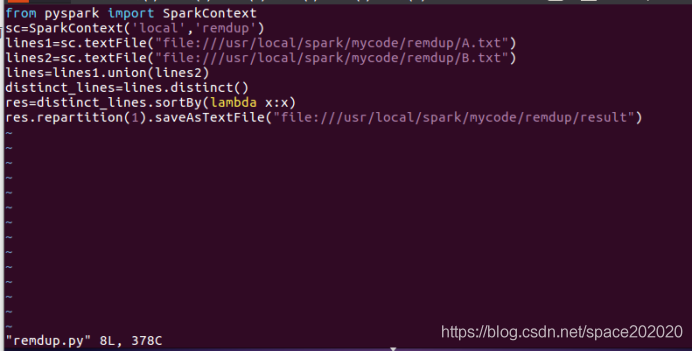
(2)在remdup目錄下撰寫remdup.py檔案,如圖:

(3)在/usr/local/spark/mycode/remdup檔案目錄下運行remdup.py檔案:python3 remdup.py,如圖:
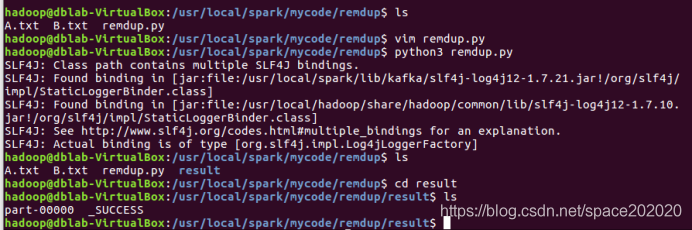
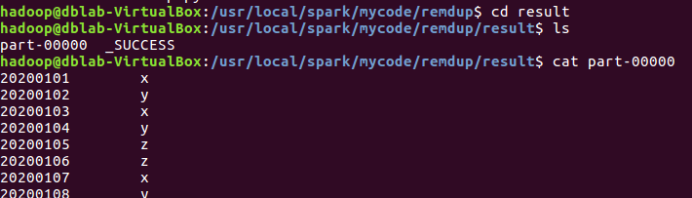
(4)運行了remdup.py檔案后,會出現result目錄,在該目錄下可查看part-00000檔案結果,如圖:
3.撰寫獨立應用程式實作求平均值問題
(1)首先將 ~/下載/大資料實踐期末大作業 檔案夾中的Algorithm.txt、Database.txt和Python.txt檔案復制到 /usr/local/spark/mycode/avgscore 檔案目錄下,如圖所示:

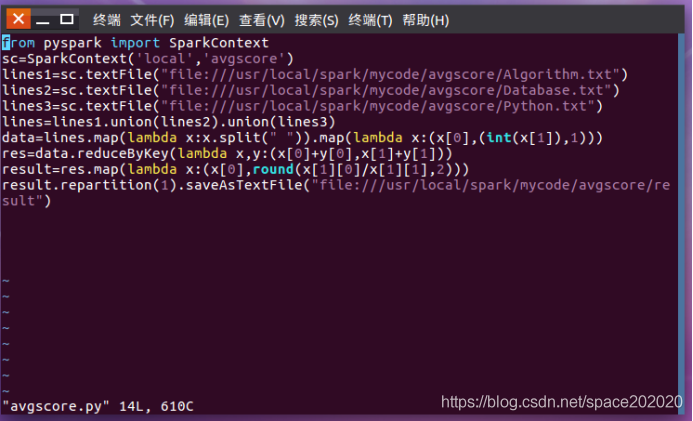
(2)在avgscore目錄下撰寫avgscore.py檔案,vim avgscore.py如下圖所示:
(3)在/usr/local/spark/mycode/avgscore 檔案目錄下運行avgscore.py檔案:python3 avgscore.py,在avgscore目錄下得到result目錄,在result下得到part-00000檔案結果,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/287899.html
標籤:其他