目錄
- 二進制資料結構Struct
- 函式與Struct類
- 打包
- 解包
- 位元組序指示符
- 緩沖區
二進制資料結構Struct
在C/C++語言中,struct被稱為結構體,而在Python中,struct是一個專門的庫,用于處理位元組串與原生Python資料結構型別之間的轉換,
本篇,將詳細介紹二進制資料結構struct的使用方式,
函式與Struct類
struct庫包含了一組處理結構值得模塊級函式,以及一個Struct類,格式指示符將由字串格式轉換為一種編譯表示,這與處理正則運算式得方式類似,
這個轉換會耗費一些資源,所以創建一個Struct實體并再這個實體上呼叫方法時,只完成一次轉換,往往會更高效,
打包
Struct支持使用格式指示符將資料打包為字串,另外支持從字串解包資料,格式指示符由表示資料型別的字串和可選的數量及位元組序指示符構成,
下面,我們來打包一個元組,將其轉換為16進制位元組序列,示例如下:
import struct
import binascii
values = (2, 'lyj'.encode('UTF-8'), 3.8)
s = struct.Struct('I 3s f')
packed_data = s.pack(*values)
print("原值:", values)
print("格式指示符:", s.format)
print("大小:", s.size, 'bytes')
print("打包值:", binascii.hexlify(packed_data))
運行之后,效果如下:
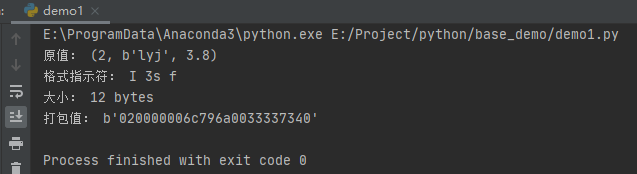
這里的格式指示符為“I 3s f”,前面介紹array陣列時,我們已經列出過一個表格,其中I標識一個整型或長整型,3s表示3個位元組字串(lyj),f表示浮點數,
解包
struct庫使用unpack()可以從打包的表示資料中抽取資料,這里直接復制上面的打包值,進行測驗,示例如下:
import struct
import binascii
packed_data = binascii.unhexlify(b'020000006c796a0033337340')
s = struct.Struct('I 3s f')
unpacked_data = s.unpack(packed_data)
print("解包值:", unpacked_data)
運行之后,效果如下:

雖然使用unpack()解包基本會得到相同值,但浮點數的值有微小的差別,
位元組序指示符
默認情況下,值會使用原生C庫的位元組序(endianness)來編碼,Struct的位元組序指示符如下表所示:
| 代碼 | 含義 |
|---|---|
| @ | 原生順序 |
| = | 原生標準 |
| < | 小端 |
| > | 大端 |
| ! | 網路順序 |
示例如下:
import struct
import binascii
values = (2, 'lyj'.encode('UTF-8'), 3.8)
endianness = [
('@', '原生順序'),
('=', '原生標準'),
('<', '小端'),
('>', '大端'),
('!', '網路順序'),
]
for code, name in endianness:
s = struct.Struct(code + ' I 3s f')
packed_data = s.pack(*values)
print("格式化字串:", s.format, ' for ', name)
print("大小:", s.size, 'bytes')
print("打包:", binascii.hexlify(packed_data))
print("解包:", s.unpack(packed_data))
運行之后,效果如下:
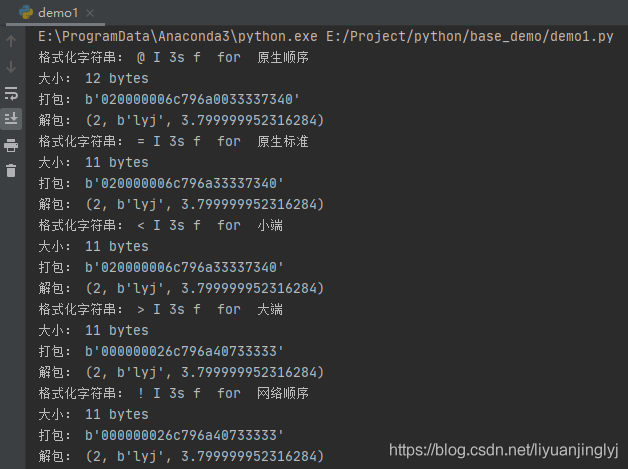
如果想改變位元組序來編碼,如上面代碼所示,只需要改變格式串中提供一個顯式的位元組序指令,就可以很容易地覆寫這個默認選擇,
緩沖區
通常在強調性能的情況下或者向擴展模塊傳入或傳出資料時才會處理二進制打包資料,
為了避免為每個打包結構分配一個新緩沖區所帶來的開銷,通常情況下,我們使用pack_into()和unpack_from()方法支持直接寫入預分配的緩沖區,
示例如下:
import struct
import binascii
import ctypes
import array
values = (2, 'lyj'.encode('UTF-8'), 3.8)
s = struct.Struct('I 3s f')
print("原始值:", values)
b = ctypes.create_string_buffer(s.size)
print("打包之前(緩沖區的值):", binascii.hexlify(b.raw))
s.pack_into(b, 0, *values)
print("打包之后(緩沖區的值):", binascii.hexlify(b.raw))
print("解包:", s.unpack_from(b, 0))
a = array.array('b', b'\0' * s.size)
print("打包之前(緩沖區的值):", binascii.hexlify(a))
s.pack_into(a, 0, *values)
print('打包之后(緩沖區的值):', binascii.hexlify(a))
print("解包:", s.unpack_from(a, 0))
運行之后,效果如下:
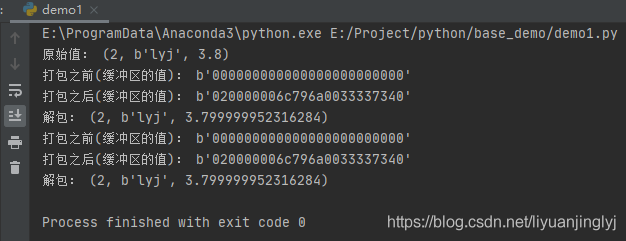
這里通過兩種方式,創建緩沖區,其中size屬性用于指出緩沖區需要的大小,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/287947.html
標籤:其他
上一篇:聊天尬死名場面,你遇到過嗎?教你一鍵獲取斗圖表情包,晉升聊天達人
下一篇:什么是多執行緒