
6 月 19-25 日,備受全球矚目的國際頂級視徑訓議 CVPR2021(Computer Vision and Pattern Recognition,即國際機器視覺與模式識別)在線上舉行,但依然人氣爆棚,參會者的激情正如夏日般火熱,
今年阿里云多媒體 AI 團隊(由阿里云視頻云和達摩院視覺團隊組成,以下簡稱 MMAI)參加了大規模人體行為理解公開挑戰賽 ActivityNet、當前最大時空動作定位挑戰賽 AVA-Kinetics、超大規模時序行為檢測挑戰賽 HACS 和第一視角人體行為理解挑戰賽 EPIC-Kitchens 上的總共** 6 個賽道,一舉拿下了 5 項冠軍和 1 項亞軍**,其中在 ActivityNet 和 HACS 兩個賽道上連續兩年蟬聯冠軍!
頂級挑戰賽戰績顯赫
大規模時序動作檢測挑戰賽 ActivityNet 于 2016 年開始,由 KAUST、Google、DeepMind 等主辦,至今已經成功舉辦六屆,
該挑戰賽主要解決時序行為檢測問題,以驗證 AI 演算法對長時視頻的理解能力,是該領域最具影響力的挑戰賽之一,歷屆參賽者來自許多國內外知名機構,包括微軟、百度、上交、華為、商湯、北大、哥大等,
今年阿里云 MMAI 團隊最終以 Avg. mAP 44.67% 的成績獲得該項挑戰賽的冠軍!

圖 1 ActivityNet 挑戰賽證書
**時空動作定位挑戰賽 AVA-Kinetics **由 2018 年開始,至今已成功舉辦四屆,由 Google、DeepMind 和 Berkeley 舉辦,旨在時空兩個維度識別視頻中發生的原子級別行為,
因其難度與實用性,歷年來吸引了眾多國際頂尖高校與研究機構參與,如 DeepMind、FAIR、SenseTime-CUHK、清華大學等,
今年阿里云 MMAI 團隊以 40.67% mAP 擊敗對手,獲得第一!

圖 2 AVA-Kinetics 挑戰賽獲獎證書
超大規模行為檢測挑戰賽 HACS 始于 2019 年,由 MIT 主辦,是當前時序行為檢測任務中的最大挑戰賽,該項挑戰賽包括兩個賽道:全監督行為檢測和弱監督行為檢測,
由于資料量是 ActivityNet 的兩倍以上,因此具有很大的挑戰性,歷屆參賽隊伍包括微軟、三星、百度、上交、商湯、西交等,
今年阿里云 MMAI 團隊同時參加兩個賽道,并分別以 Avg. mAP 44.67% 和 22.45% 雙雙奪冠!

圖 3 HACS 挑戰賽兩個賽道的獲獎證書
第一視角人體動作理解挑戰賽 EPIC-Kitchens 于 2019 年開始,至今已經舉辦三屆,由 University of Bristol 主辦,致力于解決第一視角條件下的人體動作和目標物體的互動理解問題,
歷年的參賽隊伍包括百度、FAIR、NTU、NUS、Inria-Facebook、三星(SAIC-Cambridge)等,
今年阿里云 MMAI 團隊參加其中時序動作檢測和動作識別兩個賽道,分別以 Avg. mAP 16.11% 和 Acc. 48.5% 獲得兩項挑戰賽的冠軍和亞軍!

圖 4 EPIC-Kitchens 挑戰賽獲獎證書
四大挑戰的關鍵技術探索
行為理解挑戰賽主要面臨四大挑戰:
首先是行為時長分布廣,從 0.5 秒到 400 秒不等,以一個 200 秒的測驗視頻為例,每 1 秒采集 15 幀影像,演算法必須在 3000 幀影像中精確定位,
其次是視頻背景復雜,通常具有很多不規則的非目標行為嵌入在視頻中,極大的增加了行為檢測的難度,
再者是類內差較大,相同行為的視覺表現會因個體、視角、環境的變換而發生明顯的變化,
最后是演算法檢測人體動作還面臨人體之間的互相遮擋、視頻解析度不足、光照、視角等變化多樣的其他干擾,
在本次挑戰賽中,該團隊之所以能夠取得如此出色的成績,主要是由其背后先進技術框架 EMC2 支撐,該框架主要對如下幾個核心技術進行探索:
(1)強化基礎網路的優化訓練
基礎網路是行為理解的核心要素之一,
在本次挑戰賽中,阿里云 MMAI 團隊主要對以下兩方面進行探索:深入研究 Video Transformer (ViViT);探索 Transformer 和 CNN 異構模型的互補性,
作為主要的基礎網路,ViViT 的訓練同樣包括預訓練和微調兩個程序,在微調程序,MMAI 團隊充分分析包括輸入尺寸、資料增廣等變數的影響,找到適合當前任務的最佳配置,
此外,考慮 Transformer 和 CNN 結構互補性,還使用了 Slowfast、CSN 等結構,最終通過集成學習分別在 EPIC-Kitchens、ActivityNet、HACS 上取得 48.5%、93.6%、96.1% 的分類性能,相較于去年的冠軍成績,有著明顯的提升,
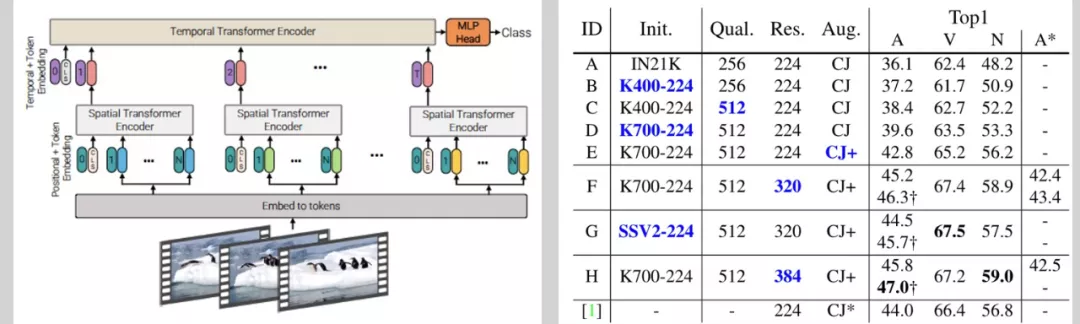
圖 5 ViViT 的結構及其性能
(2)視頻理解中的物體時空關系建模
對于時空域動作檢測任務而言,基于關系建模學習視頻中的人 - 人關系、人 - 物關系、人 - 場景關系對于正確實作動作識別,特別是互動性動作識別而言是尤為重要的,
因此在本次挑戰賽中阿里云 MMAI 重點對這些關系進行建模分析,
具體地,首先定位視頻中的人和物體,并分別提取人和物的特征表示;為了更加細粒度地建模不同型別的動作關系,將上述特征與全域視頻特征在時空域結合以增強特征,并分別在不同的時域或空域位置間應用基于 Transformer 結構的關系學習模塊,同時不同位置的關聯學習通過權重共享的方式實作對關聯區域的位置不變性,
為了進一步建模長序時域關聯,我們構建了結合在線和離線維護的兩階段時序特征池,將視頻片段前后的特征資訊融合到關聯學習當中,
最后,經過關聯學習的人體特征被用于進行動作識別任務,基于解耦學習的方式實作了在動作類別長尾分布下對困難和少量樣本類別的有效學習,
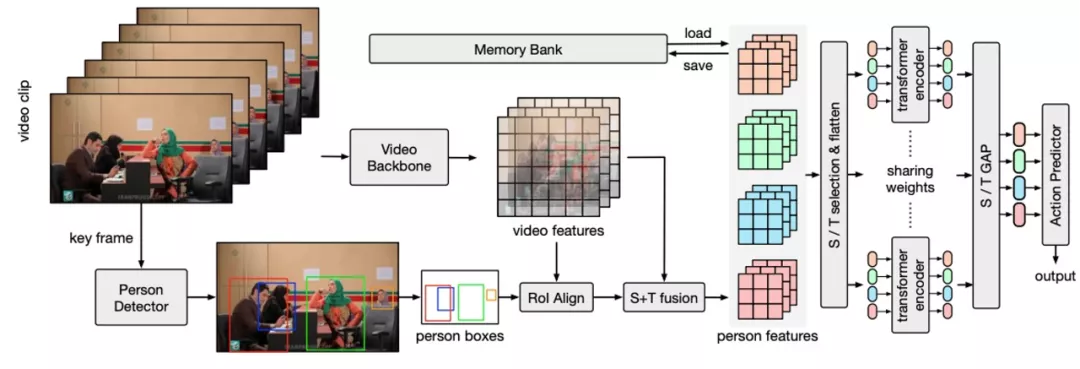
圖 6 關系建模網路
(3)基于動作提名關系編碼的長視頻理解
在動作理解相關的多項任務上,在有限的計算條件下,視頻持續時間較長是其主要的挑戰之一,而時序關系學習是解決長時視頻理的重要手段,
在 EMC2 中,設計了基于動作提名關系編碼的模塊來提升演算法的長時感知能力,
具體地,利用基礎行為檢測網路生產出密集的動作提名,其中每個動作提名可以粗略視為特定動作物體發生的時間區間,
然后基于自注意力機制,在時間維度上對這些提名物體進行時序關系編碼,使得每個動作提名均能感知到全域資訊,從而能夠預測出更加準確的行為位置,憑借此技術,EMC2 在 AcitivityNet 等時序行為檢測上取得冠軍的成績,
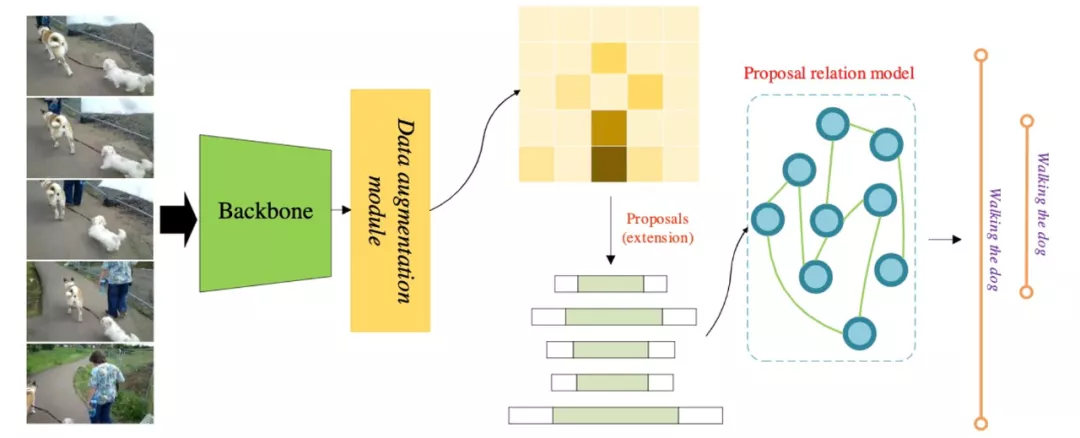
圖 7 動作提名間的關系編碼
(4)基于自監督學習的網路初始化訓練
初始化是深度網路訓練的重要程序,也是 EMC2 的主要組件之一,
阿里云 MMAI 團隊設計了一種基于自訓練的初始化方法 MoSI,即從靜態影像訓練視頻模型,
MoSI 主要包含兩個組件:偽運動生成和靜態掩碼設計,
首先根據滑動視窗的方式按照指定的方向和速度生成偽視頻片段,然后通過設計合適的掩碼只保留其區域區域的運動模式,使網路能夠具有區域運動感知的能力,最后,在訓練程序中,模型優化目標是成功預測輸入偽視頻的速度大小和方向,
通過這種方式,訓練的模型將具有感知視頻運動的能力,在挑戰賽中,考慮到不使用額外資料的規則,僅在有限的挑戰賽視頻幀做 MoSI 訓練,便可取得明顯的性能提升,保證了各項挑戰賽的模型訓練質量,
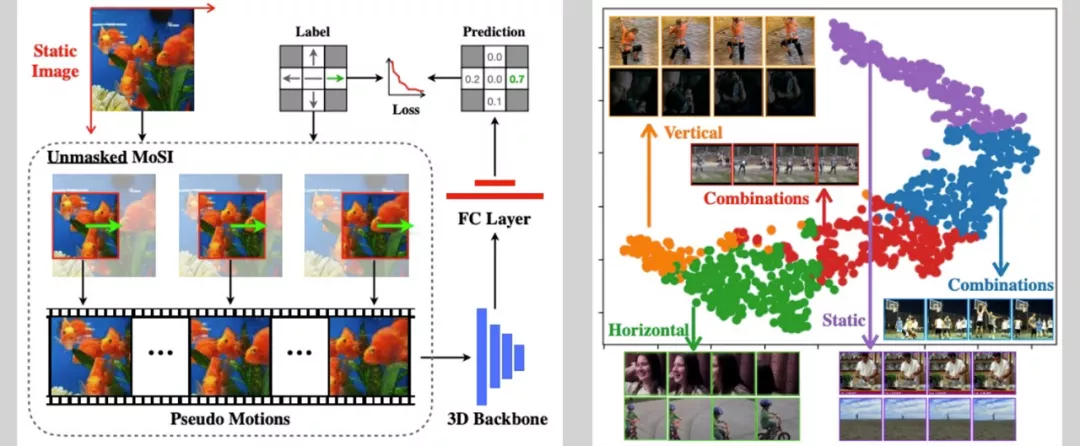
圖 8 MoSI 訓練程序及其語意分析
“視頻行為分析一直都被認為是一項非常具有挑戰性的任務,主要源于其內容的多樣性,
盡管基礎機器視覺中各種先進的技術被提出,我們在此次競賽的創新主要包括:
1)對自監督學習和 Transformer+CNN 異構融合的深度探索;
2)視頻中不同物體間關系建模方法的持續研究,
這些探索確認了當前先進技術(如自監督學習)對視頻內容分析的重要性,
此外,我們的成功也說明了物體關系建模對視頻內容理解的重要作用,但其并沒有得到業界足夠的關注,” 阿里巴巴高級研究員金榕總結道,
基于視頻理解技術打造多媒體 AI 云產品
基于 EMC2 的技術底座,阿里云 MMAI 團隊在進行視頻理解的深度研究同時,也積極進行了產業化,推出了多媒體 AI(MultiMedia AI)的技術產品:Retina 視頻云多媒體 AI 體驗中心(點擊?? 多媒體 AI 云產品體驗中心 進行體驗 ),
該產品實作視頻搜索、審核、結構化和生產等核心功能,日處理視頻資料數百萬小時,為客戶在視頻搜索、視頻推薦、視頻審核、著作權保護、視頻編目、視頻互動、視頻輔助生產等應用場景中提供了核心能力,極大提高了客戶的作業效率和流量效率,

圖 9 多媒體 AI 產品
目前,多媒體 AI 云產品在傳媒行業、泛娛樂行業、短視頻行業、體育行業以及電商行業均有落地:
1)在傳媒行業,主要支撐央視、人民日報等傳媒行業頭部客戶的業務生產流程,極大提升生產效率,降低人工成本,例如在新聞生成場景中提升了 70% 的編目效率和 50% 的搜索效率;
2)在泛娛樂行業以及短視頻行業,主要支撐集團內業務方優酷、微博、趣頭條等泛娛樂視頻行業下視頻結構化、影像 / 視頻審核、視頻指紋搜索、著作權溯源、視頻去重、封面圖生成、集錦生成等場景,幫助保護視頻著作權、提高流量分發效率,日均呼叫數億次;
3)在體育行業,支撐第 21 屆世界杯足球賽,打通了視覺、運動、音頻、語音等多模態資訊,實作足球賽事直播流跨模態分析,相比傳統剪輯效率提升一個數量級;
4)在電商行業,支撐淘寶、閑魚等業務方,支持新發視頻的結構化,視頻 / 影像審核,輔助客戶快速生成短視頻,提升分發效率,
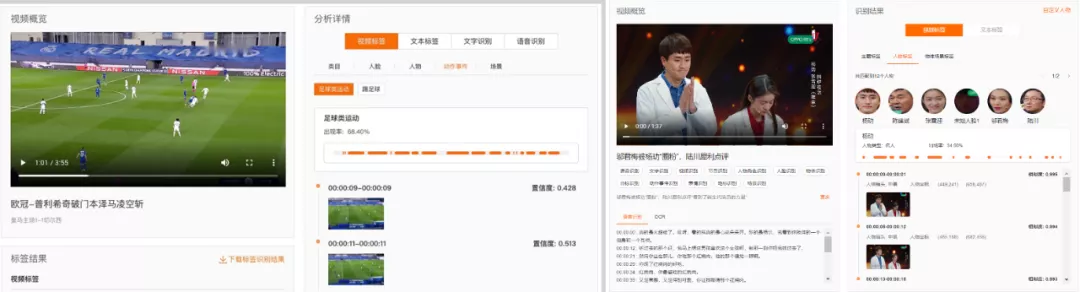
圖 10 多媒體 AI 對體育行業和影視行業標簽識別
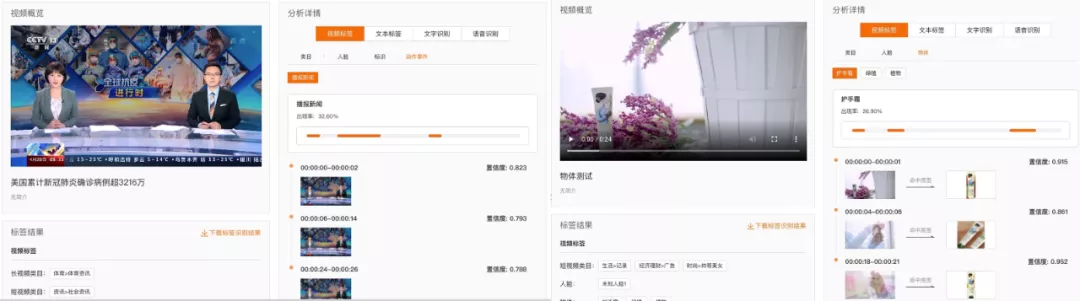
圖 11 多媒體 AI 對傳媒行業和電商行業的標簽識別
在 EMC2 的支撐下,Retina 視頻云多媒體 AI 體驗中心具有如下優勢:
1)多模態學習:利用視頻、音頻、文本等海量多模態資料,進行跨媒體理解,融合不同領域知識的理解 / 生產體系;
2)輕量化定制:用戶可自主注冊需要識別的物體,演算法對新增物體標簽可實作 “即插即用”,且對新增類別使用輕量資料可接近已知類別效果;
3)高效能:自研高性能音視頻編解碼庫、深度學習推理引擎、GPU 預處理庫,針對視頻場景 IO 和計算密集型特點定向優化,在不同場景達到近 10 倍性能提升;
4)通用性強:多媒體 AI 云產品在傳媒行業、泛娛樂行業、短視頻行業、體育行業以及電商行業等均有落地應用案例,
“視頻非常有助于提升內容的易理解、易接受和易傳播性,在過去的幾年我們也看到了各行各業,各種場景都在加速內容視頻化的行程,整個社會對于視頻產量的訴求越來越強烈,如何高效、高質的生產出符合用戶需求的視頻,就成為了核心問題,這里面涉及到了非常多的細節問題,例如熱點的發現、大量視頻素材的內容理解、多模檢索、基于用戶畫像 / 場景的模板構建等,這些都需要大量的依賴視覺 AI 技術的發展,MMAI 團隊結合行業、場景不斷的改進在視覺 AI 方面的技術,并基于此打磨和構建業務級的多媒體 AI 云產品,使得視頻得以高質、高效的進行生產,從而有效的推進各行各業、各場景的內容視頻化行程,” 阿里云視頻云負責人畢玄評價道,
在本次 CVPR2021 中,MMAI 通過多項學術挑戰賽一舉擊敗多個國內外強勁對手,拿下了多項冠軍,是對其過硬的技術的有力驗證,其云產品多媒體 AI 已經服務多個行業的頭部客戶,并將持續創造多行業應用價值,
??點擊體驗
多媒體 AI 云產品體驗中心:http://retina.aliyun.com
原始碼開源地址:https://github.com/alibaba-mmai-research/pytorch-video-understanding
參考文獻:
[1] Huang Z, Zhang S, Jiang J, et al. Self-supervised motion learning from static images. CVPR2021: 1276-1285.
[2] Arnab A, Dehghani M, Heigold G, et al. Vivit: A video vision transformer[J]. arXiv preprint arXiv:2103.15691, 2021.
[3] Feichtenhofer C, Fan H, Malik J, et al. Slowfast networks for video recognition. ICCV2019: 6202-6211.
[4] Tran D, Wang H, Torresani L, et al. Video classification with channel-separated convolutional networks. ICCV2019: 5552-5561.
[5] Lin T, Liu X, Li X, et al. Bmn: Boundary-matching network for temporal action proposal generation. ICCV2019: 3889-3898.
[6] Feng Y, Jiang J, Huang Z, et al. Relation Modeling in Spatio-Temporal Action Localization[J]. arXiv preprint arXiv:2106.08061, 2021.
[7] Qing Z, Huang Z, Wang X, et al. A Stronger Baseline for Ego-Centric Action Detection[J]. arXiv preprint arXiv:2106.06942, 2021.
[8] Huang Z, Qing Z, Wang X, et al. Towards training stronger video vision transformers for epic-kitchens-100 action recognition[J]. arXiv preprint arXiv:2106.05058, 2021.
[9] Wang X, Qing Z., et al. Proposal Relation Network for Temporal Action Detection[J]. arXiv preprint arXiv:2106.11812, 2021.
[10] Wang X, Qing Z., et al. Weakly-Supervised Temporal Action Localization Through Local-Global Background Modeling[J]. arXiv preprint arXiv:2106.11811, 2021.
[11] Qing Z, Huang Z, Wang X, et al. Exploring Stronger Feature for Temporal Action Localization
「視頻云技術」你最值得關注的音視頻技術公眾號,每周推送來自阿里云一線的實踐技術文章,在這里與音視頻領域一流工程師交流切磋,公眾號后臺回復【技術】可加入阿里云視頻云技術交流群,和作者一起探討音視頻技術,獲取更多行業最新資訊,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/288465.html
標籤:其他
下一篇:Bagging和Boosting