如題:
深度強化學習演算法(深度強化學習框架)為考慮可以快速適用多種深度學習框架建議采用弱耦合的軟體設計方法
今日在看強化學習的框架,發現現在的深度強化學習框架不論是依賴Tensorflow的還是PyTorch的,在設計時都沒有考慮過耦合這個問題,雖然強化學習演算法源于學術界,而且現在也還是主要停留于學術界,但是畢竟現在在慢慢的向工業界靠攏,而不論是考慮到工業界的快速使用還是學術領域方面很好的follow作業,一個可以快速適用于多種深度學習計算框架的深度強化學習框架都是很為需要的,
強化學習與其他繼續學習演算法的不同之處:
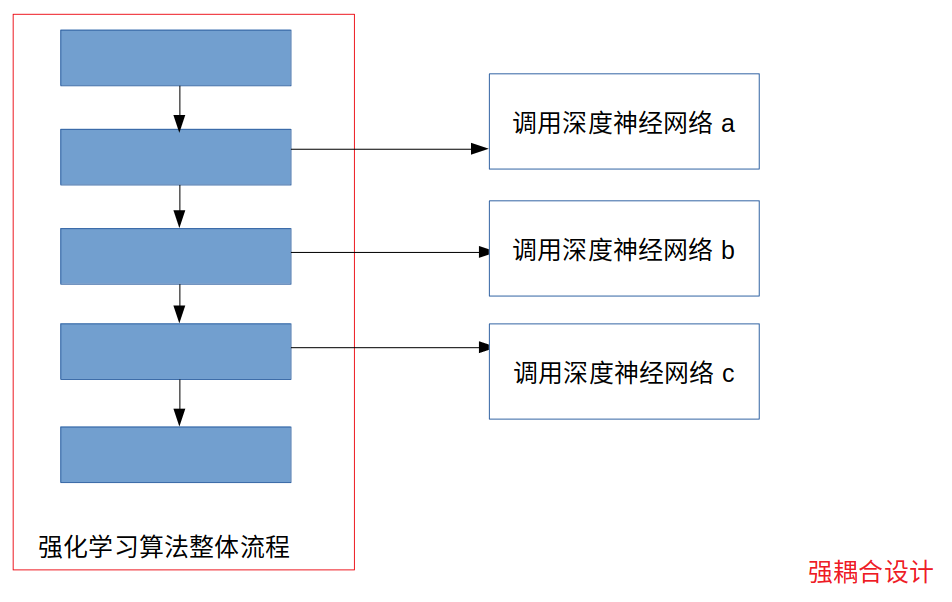
像其他的強化學習演算法,如NLP,CV等,演算法本身就與深度學習計算框架是弱耦合的關聯,因此這些演算法如果要更換具體的深度學習計算框架的話只需要替換為另一種計算框架下的網路定義方式,并更換損失函式和優化器以及資料匯入方式即可,這這些模塊本身也是弱耦合的,因此這些非深度強化學習演算法可以較為容易的更換具體的深度學習計算框架,而強化學習演算法與其他機器學習演算法不同,深度學習模塊在深度強化學習演算法只是一個組成部分,是一個子模塊,而往往深度強化學習演算法的主體部分不是深度學習的計算網路,再加上強化學習演算法本身又需要與環境進行互動,因此最終導致深度強化學習演算法的代碼中神經網路體現在整個演算法的各個部分,形成了一種強耦合的狀態,由于現如今的大多數深度強化學習演算法代碼都是神經網路與強化學習演算法主體部分形成了強耦合形式,因此我們難以快速的使現有代碼快速適用不同的深度學習計算框架,比如從pytorch框架遷移到TensorFlow框架,亦如從TensorFlow框架遷移到pytorch框架,這樣不論是學術研究還是工業領域的直接使用都難以快速實作,那么我們怎么來解決這個問題呢,如何使我們的代碼可以快速適應不同的深度學習計算框架,較少人力花費的進行迭代變更,快速的使他人fellow呢?
這里我給出了一個個人的建議,那就是對于深度強化學習演算法采用弱耦合的軟體設計方法,
現有的強耦合式的深度強化學習演算法設計:(示意圖)
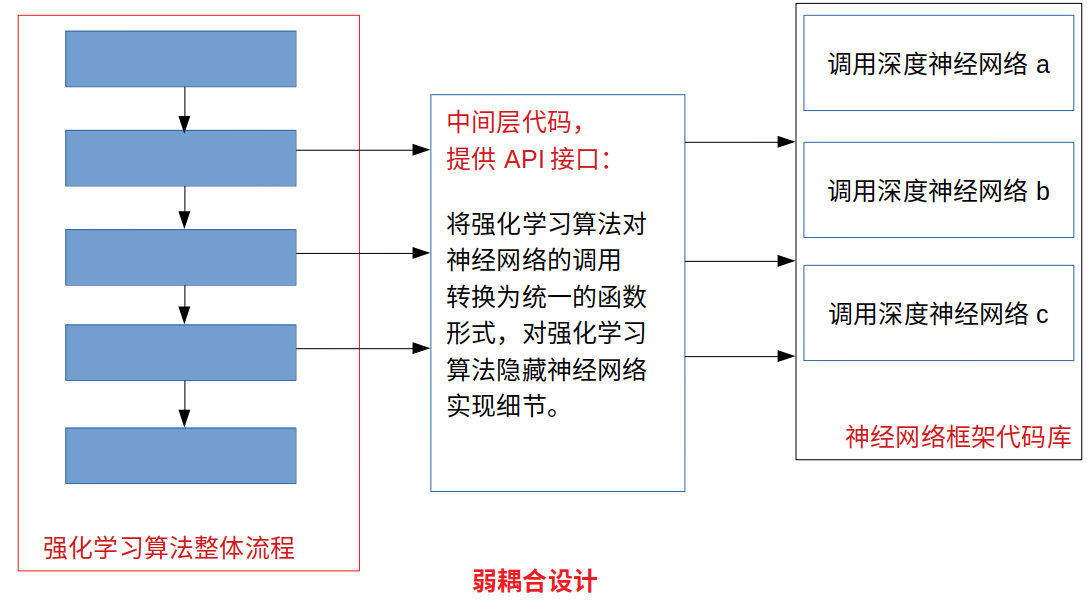
建議使用的弱耦合設計:(示意圖)
=================================================================
這種弱耦合的設計可以很好的隔離掉神經網路的實作細節與呼叫細節,而我們以后不管是要替換掉具體的后臺深度學習計算框架還是要進行代碼版本的迭代更新都可以進行組件方式的操作,如果我們要把深度強化學習的網路框架由Tensorflow和Pytorch之間進行轉換,我們只需要替換掉神經網路代碼庫這一部分,同時對中間層代碼的api呼叫進行修改,而對強化學習的邏輯代碼部分不進行任何修改,而如果我們要對強化學習演算法的主體部分的邏輯進行修改,我們的中間層代碼和后端的神經網路代碼是不需要進行大幅度修改的,不論是修改強化學習演算法主體邏輯還是進行版本更迭都會節省掉很大的人力物力,提高我們的效率,
本文的想法概括的來說就是將以往的耦合成一體的深度強化學習演算法分解成三部分,即:
1. 前端(強化學習主體邏輯部分)
2. 中間層 (對強化學習主體演算法隱藏掉具體的神經網路代碼細節,只提供統一的呼叫介面)
3. 后端(深度學習計算框架代碼部分,根據具體的運行平臺,快速的、獨立的替換成不同版本的Tensorflow、Pytorch、MindSpore代碼,同時也能快速使用不同的計算平臺:CPU、GPU、移動端Lite、Ascend平臺)
ps:
當然本文最初的構想還是為了解決學術研究時要根據不同深度強化學習演算法及框架去看不同深度學習框架代碼而來的,畢竟一邊搞著強化學習的各種論文及演算法邏輯代碼還能很好的cover掉不同深度學習計算框架的代碼是一件蠻難的事情,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/289151.html
標籤:其他
上一篇:HCNA Routing&Switching之動態路由協議OSPF建立鄰居的條件
下一篇:php-18個魔法函式