@Author:Runsen
YOLO,是目前速度更快的物體檢測演算法之一,雖然它不再是最準確的物體檢測演算法,但當您需要實時檢測時,它是一個非常好的選擇,而不會損失太多的準確性,
YOLO 框架
在本篇博客中,我將介紹 YOLO 在給定影像中檢測物件所經過的步驟,
- YOLO 首先獲取輸入影像:

然后框架將輸入影像劃分為網格(比如 3 X 3 網格):
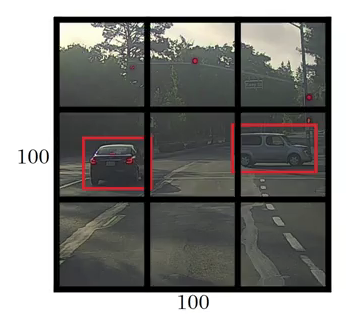
影像分類和定位分別應用于每個網格,然后 YOLO 預測邊界框及其對應的物件類別概率,
因此,下一步的方法是將標記資料傳遞給模型以對其進行訓練,假設已將影像劃分為大小為 3 X 3 的網格,并且存在有 3 個希望將物件分類的類,
假設這些類分別是 Pedestrian行人、Car 和 Motorcycle摩托車,對于每個網格單元,標簽 y 將是一個八維向量:
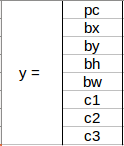
- pc定義物件是否存在于網格中(這是概率)
- bx , by , bh , bw指定邊界框,如果有物件
- c1、c2、c3表示類別,因此,如果物件是汽車,則 c2將為 1,c1 和 c3將為 0
從上面的例子中選擇了第一個網格:

由于此網格中沒有物件,因此 pc 將為零,此網格的 y 標簽為
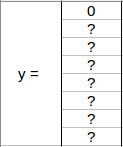
這里, ‘?’ 是沒有的意思,
采用另一個網格,其中這里有一輛汽車 (c2 = 1):

在我們為這個網格撰寫 y 標簽之前,首先要知道 YOLO 如何確定網格中是否確實存在物件,在最上面圖中,有兩個物件(兩輛車),因此 YOLO 將取這兩個物件的中點,并將這些物件分配到包含這些物件中點的網格,上面的 y 標簽將是:
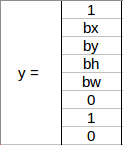
由于此網格中有一個物件,因此 p c 將等于 1, bx、 by、 bh、 bw將相對于正在處理的特定網格單元,由于汽車是第二類,c2 = 1 且 c1和 c3 = 0,因此,對于9個網格中的每一個,將有一個八維輸出向量,此輸出的形狀為 3 X 3 X 8,
所以現在我們有一個輸入影像,它是對應的目標向量,使用上面的例子(輸入影像 – 100 X 100 X 3,輸出 – 3 X 3 X 8),模型將訓練如下:
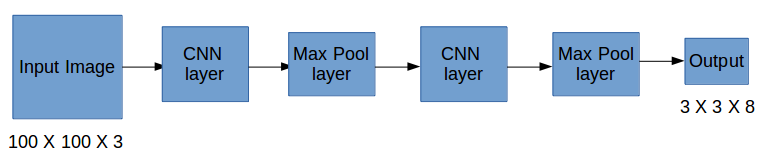
在測驗階段,我們將影像傳遞給模型并運行前向傳播,直到我們得到輸出 y,在這里使用 3 X 3 網格進行了解釋,但通常在實際場景中采用更大的網格(一般是 19 X 19),
如何得到編碼邊界框?
bx、 by、 bh和 bw是相對于正在處理的網格單元計算的,
下面通過一個例子來理解這個概念,考慮包含汽車的中右網格:

bx、 by、 bh和bw將僅相對于該網格進行計算,此網格的 y 標簽將是:
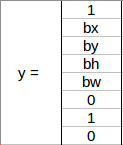
pc = 1 因為在這個網格中有一個物體并且它是一輛汽車,所以 c2 = 1,現在,看看怎么確定 bx、 by、 bh和 bw,在YOLO中,分配給所有網格的坐標是:
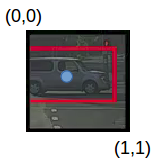
bx , by是物件中點相對于該網格的 x 和 y 坐標,在這種情況下,它將是(大約)bx = 0.4 和 by = 0.3:
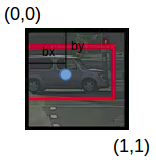
bh 是邊界框(上例中的紅色框)的高度與相應網格單元的高度之比,在例子中約為 0.9,因此,bh = 0.9,bw是邊界框的寬度與網格單元格的寬度之比,因此,大約bw = 0.5,此網格的 y 標簽將是:
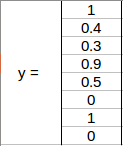
請注意,bx和 by將始終介于 0 和 1 之間,因為中點始終位于網格內,而 bh和 bw可以大于 1,這樣邊界框的尺寸大于網格的尺寸,
如何確定預測的邊界框是否給了我們一個好的結果還是一個壞的結果)?判斷的方法就是 Intersection over Union ,計算實際邊界框和預測結合框的并集的交集,
Intersection over Union
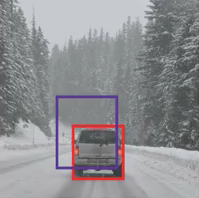
在上圖,紅色框是實際的邊界框,藍色框是預測的邊界框,我們如何確定它是否是一個好的預測?IoU ,全稱 Intersection over Union,將計算這兩個框的并集上的交集面積,該區域將是:
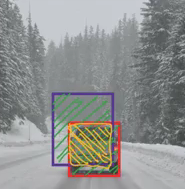
IoU = 交集面積/并集面積,即 IoU = 黃框面積/綠框面積
如果 IoU 大于 0.5,我們可以說預測足夠好,0.5 是此處采用的任意閾值,
還有一種技術可以顯著提高 YOLO 的輸出——Non-Max Suppression,
因為物件檢測演算法中,有的物件可能會多次檢測到一個物件,而不是只檢測一次,比如下圖:

在這里,汽車被多次識別,Non-Max Suppression 技術對此進行了清理,以便我們對每個物件僅進行一次檢測,
Non-Max Suppression首先查看與每個檢測相關的概率并取最大的一個,在上圖中,0.9 是最高概率,因此將首先選擇概率為 0.9 的框:

現在,它查看影像中的所有其他框,與當前框具有高 IoU 的框被抑制,因此,在上面的圖片中,概率為 0.6 和 0.7 的框將被抑制:
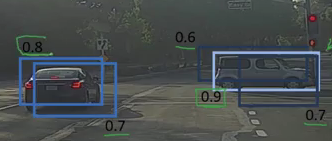
在這些框被抑制后,它從所有具有最高概率的框中選擇下一個框,在圖片中為 0.8,不斷重復這些步驟,直到所有的框都被選中或壓縮,得到最終的邊界框,
這就是非最大抑制Intersection over Union,以最大概率取框并以非最大概率抑制附近的框,
Anchor Boxes
由于每個網格只能識別一個物件,但是如果一個網格中有多個物件呢?現實中經常是這樣,這將我們引向了 Anchor Boxes錨盒的概念,考慮下圖,分為 3 X 3 網格:

取物件的中點并根據其位置將物件分配到相應的網格,在上面的例子中,兩個物件的中點位于同一個網格中,

我們只會得到兩個盒子中的一個,要么是汽車,要么是人,但是如果我們使用錨框,可能可以同時輸出兩個框!
首先,我們預先定義了兩種不同的形狀,稱為錨盒,對于每個網格,我們將有兩個輸出,而不是一個輸出,我們也可以隨時增加錨框的數量,在這里拿了兩個來使這個概念易于理解:
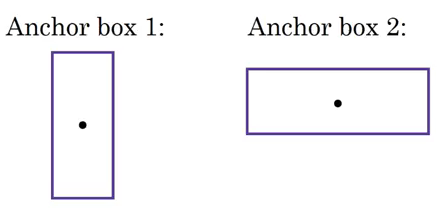
這是沒有錨框的 YOLO 的 y 標簽的樣子:
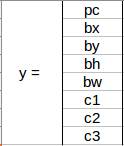
如果有 2 個錨框,你認為 y 標簽會是什么?我希望你在進一步閱讀之前花點時間思考一下,知道了y 標簽將是:
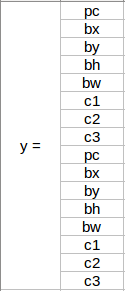
前 8 行屬于錨框 1,其余 8 行屬于錨框 2,
根據邊界框和錨框形狀的相似性將物件分配給錨框,
由于anchor box 1的形狀類似于person的bounding box,后者將被分配給anchor box 1,car將被分配給anchor box 2,這種情況下的輸出,而不是3 X 3 X 8 ,使用 3 X 3 網格和 3 個類將是 3 X 3 X 16(因為使用了 2 個錨點),
因此,對于每個網格,可以根據錨點的數量檢測兩個或多個物件,
訓練yolo模型的輸入顯然是影像及其相應的 y 標簽,讓我們看一個影像如何制作 y 標簽:

考慮使用 3 X 3 網格,每個網格有兩個錨點,并且有 3 個不同的物件類,所以對應的 y 標簽將有 3 X 3 X 16的形狀,現在,假設我們每個網格使用 5 個錨框并且類的數量已經增加到 5,所以目標將是3 X 3 X 10 X 5 = 3 X 3 X 50,
在測驗中,新影像將被劃分為我們在訓練期間選擇的相同數量的網格,對于每個網格,模型將預測形狀為 3 X 3 X 16 的輸出,此預測中的 16 個值將采用與訓練標簽相同的格式,
前 8 個值將對應于錨框 1,其中第一個值將是該網格中物件的概率,值 2-5 將是該物件的邊界框坐標,最后三個值將告訴我們該物件屬于哪個類,接下來的 8 個值將用于錨框 2 并且格式相同,即首先是概率,然后是邊界框坐標,最后是類別,
最后,非最大抑制Intersection over Union技術將應用于預測框以獲得每個物件的單個預測,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/289161.html
標籤:AI
上一篇:我讀研第一年