TensorFlow實作自注意力機制(Self-attention)
- 自注意力機制(Self-attention)
- 計算機視覺中的自注意力
- Tensorflow實作自注意力模塊
自注意力機制(Self-attention)
自注意力機制 (Self-attention) 隨著自然語言處理 (Natural Language Processing, NLP) 模型(稱為“Transformer”)的引入而變得流行,在諸如語言翻譯之類的NLP應用程式中,模型通常需要逐字閱讀句子以理解它們,然后再產生輸出,Transformer問世之前使用的神經網路是遞回神經網路 (Recurrent Neural Network, RNN) 或者其變體,例如長短期記憶網路 (Long Short-Term Memory, LSTM), RNN 具有其內部狀態,能夠更好的處理序列資訊,例如句子中前面的單詞輸入和后面的單詞輸入是有關系的,但是 RNN 也具有其缺陷,例如當單詞數量增加時,那么第一個單詞的梯度就可能消失,也就是說,隨著RNN讀取更多單詞,句子開頭的單詞逐漸變得不那么重要,
Transformer 的處理方式有所不同,它會一次讀取所有單詞,并權衡每個單詞的重要性,因此,更多的注意力集中在更重要的單詞上,因此也稱為注意力,
而自注意力機制是注意力機制的變體,其減少了對外部資訊的依賴,更擅長捕捉資料或特征的內部相關性,自注意力是最新的NLP模型 (例如BERT和GPT-3) 的基石,
計算機視覺中的自注意力
首先簡單回顧下卷積神經網路 (Convolutional Neural Networks, CNN) 的要點:CNN 主要由卷積層組成,對于卷積核大小為 3×3 的卷積層,它僅查看輸入激活中的 3×3 = 9 個特征(也可以將此區域稱為卷積核的感受野)以計算每個輸出特征,它并不會查看超出此范圍的像素,為了捕獲超出此范圍的像素,我們可以將核大小略微增加到 5×5 或 7×7,但與特征圖大小相比感受野仍然很小,
我們必須增加網路的深度,以使卷積核的感受野足夠大以捕獲我們想要的內容,與RNN一樣,輸入特征的相對重要性隨著我們在網路層中的移動而下降,因此,我們可以利用自注意力來觀察特征圖中的每個像素,并注意力集中在更加重要的像素上,
現在,我們將研究自注意力機制的作業原理,自注意力的第一步是將每個輸入特征投影到三個向量中,這些向量稱為鍵 (key),查詢 (query) 和值 (value),雖然這些術語在計算機視覺中較少出現,但是首先介紹有關這些術語的知識,以便可以更好地理解自注意力,Transformer或NLP有關的文獻:
- 值 (value) 表示輸入特征,我們不希望自注意力模塊查看每個像素,因為這在計算上過于昂貴且不必要,相反,我們對輸入激活的區域區域更感興趣,因此,值在激活圖尺寸(例如,它可以被下采樣以具有較小的高度和寬度)和通道的數目方面都減小了來自輸入特征的維數, 對于卷積層激活,通過使用1x1卷積來減少通道數,并通過最大池化或平均池化來減小空間大小,
- 鍵和查詢 (Keys and queries) 用于計算自注意圖中特征的重要性,為了計算位置
x
x
x 處的輸出特征,我們在位置
x
x
x 處進行查詢,并將其與所有位置處的鍵進行比較,
為了進一步說明這一點,假設我們有一個肖像畫,當網路處理肖像的一只眼睛時,它將首先進行查詢,該查詢具有“眼睛”的語意含義,并使用肖像的其他區域的鍵進行檢查,如果其他區域的鍵之一是眼睛,那么網路知道其找到了另一只眼睛,這就是網路要注意的區域,以便網路可以進一步的處理,
更一般的,使用數學方程表達:對于特征 0 0 0,我們計算向量 q 0 × k 0 , q 0 × k 1 , q 0 × k 2 , q 0 × k N ? 1 q_0×k_0, q_0×k_1, q_0×k_2, q_0×k_{N-1} q0?×k0?,q0?×k1?,q0?×k2?,q0?×kN?1?,然后使用 s o f t m a x softmax softmax 將向量歸一化,因此它們的總和為 $1.0,這就是是我們要求的注意力得分,將注意力得分用作權重以執行值的逐元素乘法,以獲取注意力輸出,
下圖說明了如何從查詢中生成注意力圖:

上圖紅,最左邊一列的圖是帶有點標記的查詢 (queries) 的影像,接下來的五個影像顯示了通過查詢獲得的注意力圖,頂部的第一個注意力圖查詢兔子的一只眼睛;注意圖的兩只眼睛周圍有更多白色區域(指示重要區域),其他區域接近全黑(重要性較低),
有多種實作自注意力的方法,下圖顯示了 SAGAN 中的所使用的注意力模塊,其中 θ θ θ, φ φ φ 和 g g g 對應于鍵,查詢和值:
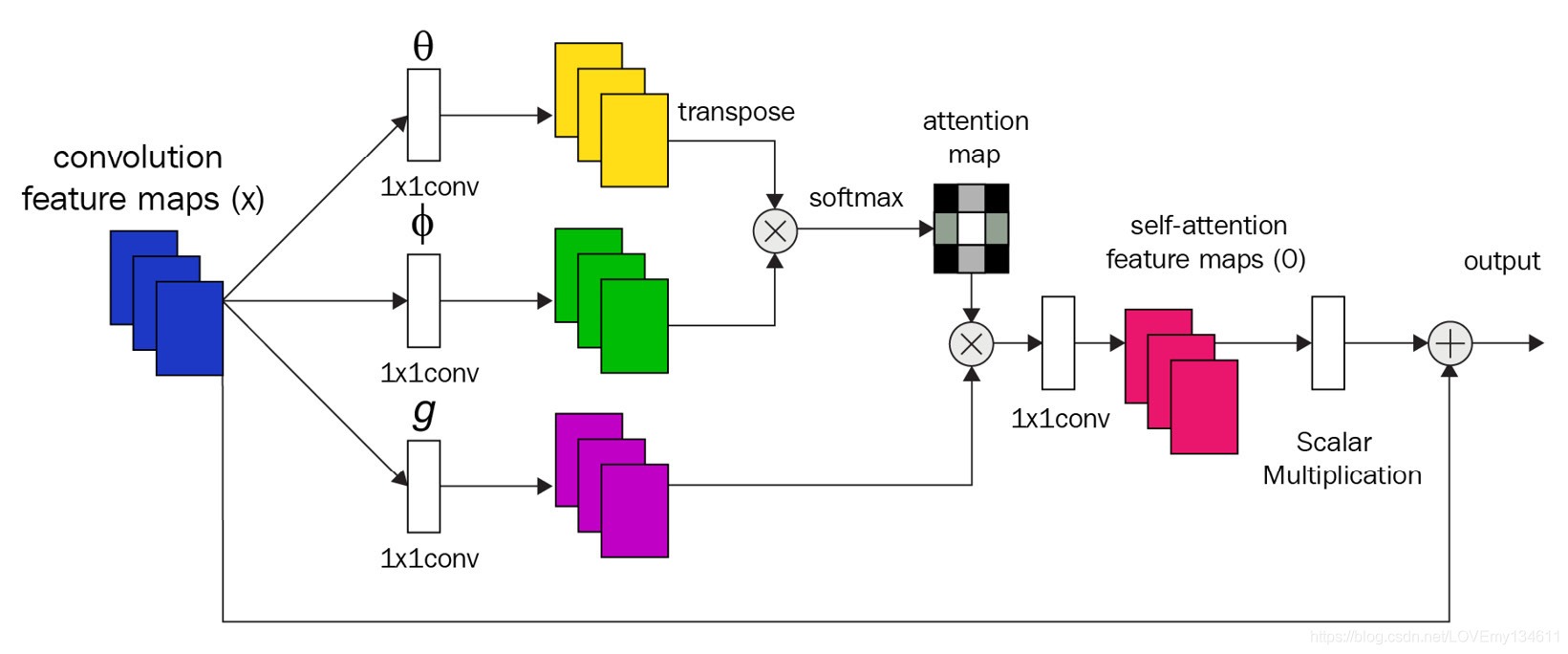
深度學習中的大多數計算都是為了提高速度性能而矢量化的,而對于自注意力也沒有什么不同,如果為簡單起見忽略 batch 維度,則 1×1 卷積后的激活將具有 (H, W, C) 的形狀,第一步是將其重塑為形狀為 (H×W, C) 的2D矩陣,并使用
θ
θ
θ 與
φ
φ
φ 的矩陣相乘來計算注意力圖,在SAGAN中使用的自注意力模塊中,還有另一個1×1卷積,用于將通道數恢復到與輸入通道數相同的數量,然后使用可學習的引數進行縮放操作,
Tensorflow實作自注意力模塊
首先在自定義層的build()中定義所有 1×1 卷積層和權重,這里,使用頻譜歸一化函式作為卷積層的核約束:
class SelfAttention(Layer):
def __init__(self):
super(SelfAttention, self).__init__()
def build(self, input_shape):
n,h,w,c = input_shape
self.conv_theta = Conv2D(c//8, 1, padding='same', kernel_constraint=SpectralNorm(), name='Conv_Theta')
self.conv_phi = Conv2D(c//8, 1, padding='same', kernel_constraint=SpectralNorm(), name='Conv_Phi')
self.conv_g = Conv2D(c//8, 1, padding='same', kernel_constraint=SpectralNorm(), name='Conv_g')
self.conv_attn_g = Conv2D(c//8, 1, padding='same', kernel_constraint=SpectralNorm(), name='Conv_AttnG')
self.sigma = self.add_weight(shape=[1], initializer='zeros', trainable=True, name='sigma')
需要注意的是:
- 內部的激活可以減小尺寸,以使計算運行更快,
- 在每個卷積層之后,激活由形狀 (H, W, C) 被重塑為形狀為 (H*W, C) 的二維矩陣,然后,我們可以在矩陣上使用矩陣乘法,
接下來在 call() 函式中將各層進行連接,用于執行自注意力操作,首先計算 θ \theta θ, φ φ φ 和 g g g:
def call(self, x):
n, h, w, c = x.shape
theta = self.conv_theta(x)
theta = tf.reshape(theta, (-1, self.n_feats, theta.shape[-1]))
phi = self.conv_phi(x)
phi = tf.nn.max_pool2d(phi, ksize=2, strides=2, padding='VALID')
phi = tf.reshape(phi, (-1, self.n_feats//4, phi.shape[-1]))
g = self.conv_g(x)
g = tf.nn.max_pool2d(g, ksize=2, strides=2, padding='VALID')
g = tf.reshape(g, (-1, self.n_feats//4, g.shape[-1]))
然后,將按以下方式計算注意力圖:
attn = tf.matmul(theta, phi, transpose_b=True)
attn = tf.nn.softmax(attn)
最后,將注意力圖與查詢 g g g 相乘,并產生最終輸出:
attn_g = tf.matmul(attn, g)
attn_g = tf.reshape(attn_g, (-1, h, w, attn_g.shape[-1]))
attn_g = self.conv_attn_g(attn_g)
output = x + self.sigma * attn_g
return output
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/289164.html
標籤:AI
上一篇:機器學習入門要學習什么內容呢?