ctfshow資訊收集web1~10
前言
是時候結束半年的摸魚期了,找套題來慢慢從頭開始做,另外文中的flag都已做了部分洗掉 打碼,
知識點總結
| web1 | 源代碼 |
|---|---|
| web2 | js前臺攔截=沒有攔截 |
| web3 | 抓包 |
| web4 | robots協議 |
| web5 | phps檔案泄露 |
| web6 | 代碼泄露 |
| web7 | git代碼泄露 |
| web8 | svn資訊泄露 |
| web9 | vim快取資訊泄露 |
| web10 | cookie |
web1
題目提示:開發注釋未及時洗掉

第一題自然也最簡單,直接查看原始碼即可找到flag

web2
題目提示:js前臺攔截 === 無效操作

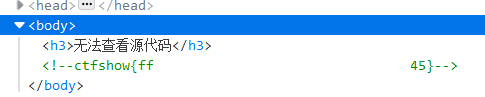
進入網站,發現滑鼠右鍵以及鍵盤的F12都無法使用,對應了“無法查看源代碼”這句話,根據提示,這里是js前臺攔截,因此,直接“更多工具---->web開發者工具”

在查看器中找到flag
web3
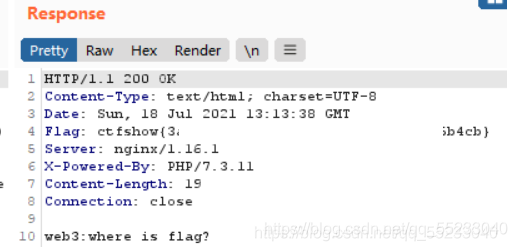
題目提示:沒思路的時候抓個包看看,可能會有意外識訓
提示給的足夠明顯,進來直接代理抓包,在response中發現flag
web4
題目提示:總有人把后臺地址寫入robots,幫黑闊大佬們引路,
這里用到了robots協議
百度百科:robots協議也叫robots.txt(統一小寫)是一種存放于網站根目錄下的ASCII編碼的文本檔案,它通常告訴網路搜索引擎的漫游器(又稱網路蜘蛛),此網站中的哪些內容是不應被搜索引擎的漫游器獲取的,哪些是可以被漫游器獲取的,因為一些系統中的URL是大小寫敏感的,所以robots.txt的檔案名應統一為小寫,robots.txt應放置于網站的根目錄下,如果想單獨定義搜索引擎的漫游器訪問子目錄時的行為,那么可以將自定的設定合并到根目錄下的robots.txt,或者使用robots元資料(Metadata,又稱元資料)
因此我們直接訪問/robots.txt
頁面如下:
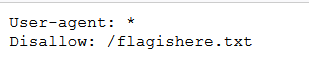
根據提示訪問圖中的/flagishere.txt,得到flag

web5
題目提示:phps原始碼泄露有時候能幫上忙
訪問/index.phps
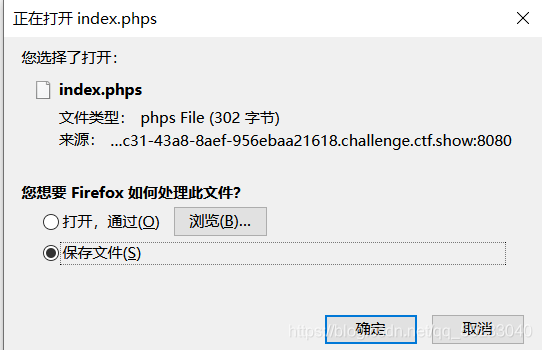
記事本打開,發現flag

web6
題目提示:解壓原始碼到當前目錄,測驗正常,收工
本題考察代碼泄露,用dirsearch掃出檔案
dirsearch命令:
dirsearch.py -u http://1606ba0b-d935-4c7e-838f-970d26d37ecf.challenge.ctf.show:8080/ -e*
掃出檔案:

根據掃出檔案,訪問/www.zip
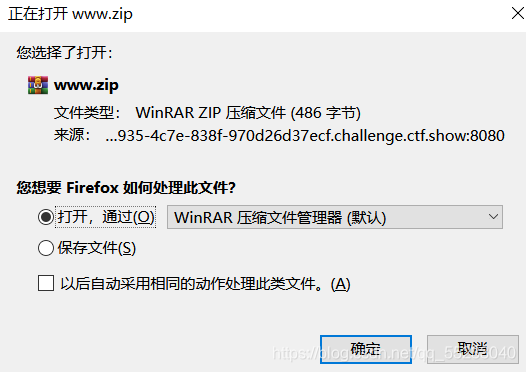
打開發現flag地址

再訪問此/fl000g.txt地址,得到flag

web7
題目提示:版本控制很重要,但不要部署到生產環境更重要,
類似上一題,直接用dirsearch掃
掃出/.git/

在網址后加上/.git/二次掃描

訪問圖中的/.git/index.php,得到flag

web8
題目提示:版本控制很重要,但不要部署到生產環境更重要,
本題考查svn資訊泄露
.svn目錄:使用svn checkout后,專案目錄下會生成隱藏的.svn檔案夾(Linux上用ls命令看不到,要用ls -al命令),
訪問/.svn,得到flag

web9
題目提示:發現網頁有個錯別字?趕緊在生產環境vim改下,不好,死機了
本題考查vim快取資訊泄露(vim快取資訊泄露具體介紹:https://blog.csdn.net/a597934448/article/details/105431367)
訪問/index.php.swp
保存打開,得到flag

web10
題目提示:cookie 只是一塊餅干,不能存放任何隱私資料
提示很明顯,線索就在cookie中,直接F12—>網路---->cookie,即可找到flag
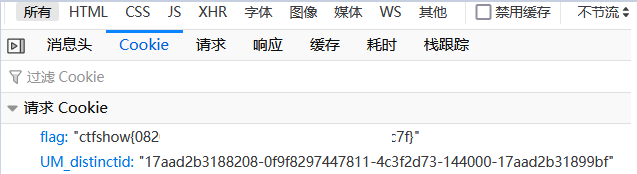
當然這道題的flag也可以抓包獲得,不過會稍微麻煩點
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/289183.html
標籤:其他
下一篇:ARP欺騙&&永恒之藍復現