一、為什么要使用kafka
1、解耦、異步、削峰
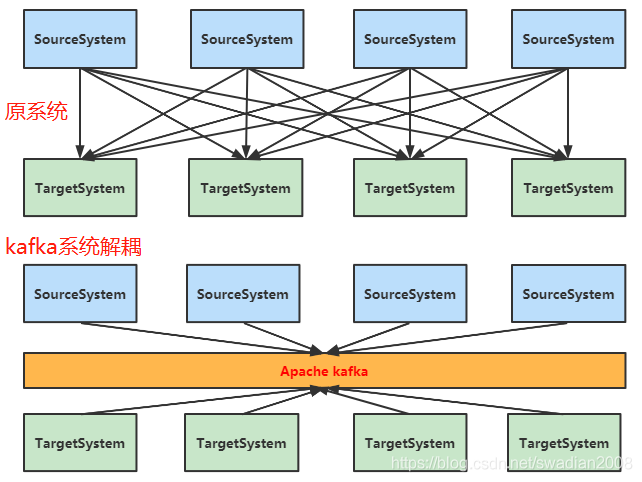
2、kafka生態系統
簡單的生產者、消費者還有注冊中心
整合部分代碼
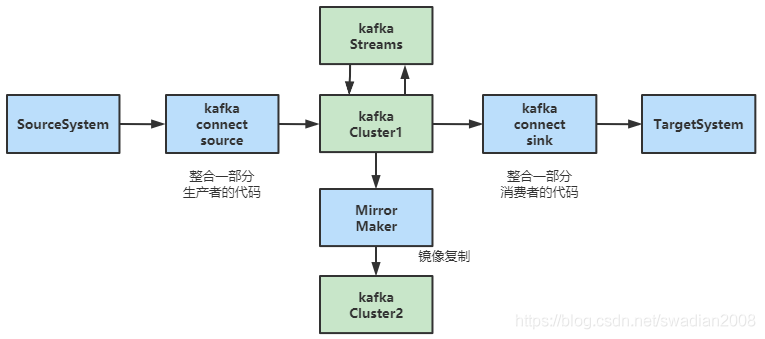
二、kafka中核心組成部分
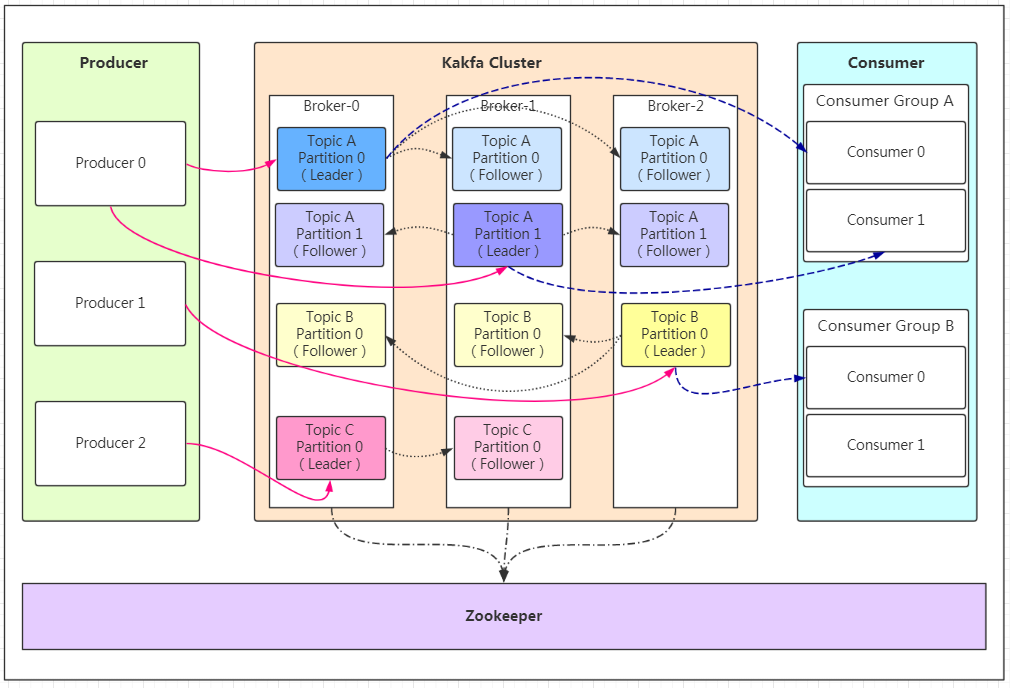
如果看到這張圖你很懵逼,木有關系!我們先來分析相關概念
Producer:Producer即生產者,訊息的產生者,是訊息的入口,
kafka cluster:
Broker:Broker是kafka實體,每個服務器上有一個或多個kafka的實體,我們姑且認為每個broker對應一臺服務器,每個kafka集群內的broker都有一個不重復的編號,如圖中的broker-0、broker-1等……
Topic:訊息的主題,可以理解為訊息的分類,kafka的資料就保存在topic,在每個broker上都可以創建多個topic,
Partition:Topic的磁區,每個topic可以有多個磁區,磁區的作用是做負載,提高kafka的吞吐量,同一個topic在不同的磁區的資料是不重復的,partition的表現形式就是一個一個的檔案夾!
Replication:每一個磁區都有多個副本,副本的作用是做備胎,當主磁區(Leader)故障的時候會選擇一個備胎(Follower)上位,成為Leader,在kafka中默認副本的最大數量是10個,且副本的數量不能大于Broker的數量,follower和leader絕對是在不同的機器,同一機器對同一個磁區也只可能存放一個副本(包括自己),
Message:每一條發送的訊息主體,
Consumer:消費者,即訊息的消費方,是訊息的出口,
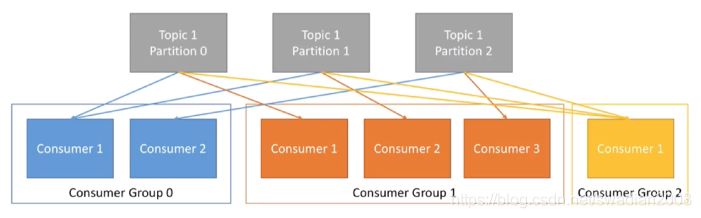
Consumer Group:我們可以將多個消費組組成一個消費者組,在kafka的設計中同一個磁區的資料只能被消費者組中的某一個消費者消費,同一個消費者組的消費者可以消費同一個topic的不同磁區的資料,這也是為了提高kafka的吞吐量!
Zookeeper:kafka集群依賴zookeeper來保存集群的的元資訊,來保證系統的可用性,
不錯的文章,kfka作業原理
https://www.cnblogs.com/sujing/p/10960832.html
三、生產資料——作業流程分析
我們看上面的架構圖中,producer就是生產者,是資料的入口,注意看圖中的紅色箭頭,Producer在寫入資料的時候永遠找的是leader,不會直接將資料寫入follower!那leader怎么找呢?寫入的流程又是什么樣的呢?我們看下圖:
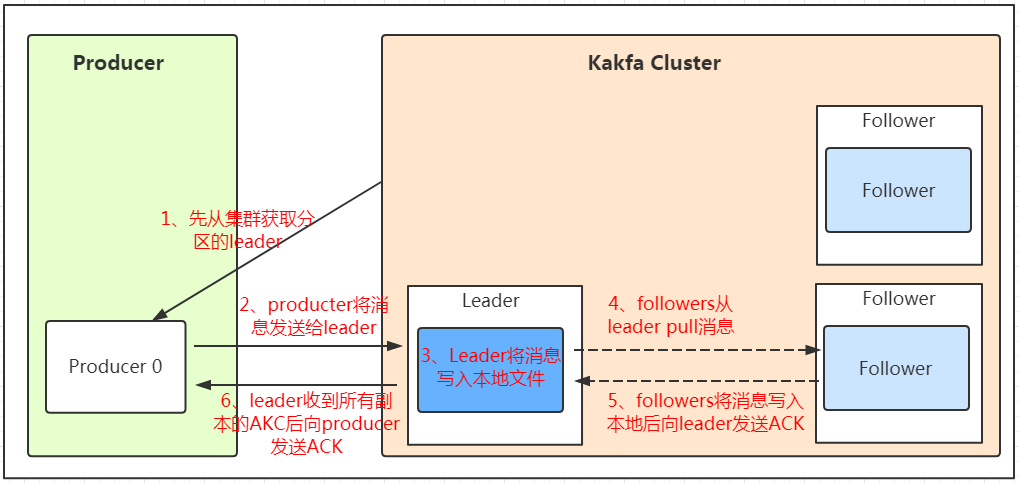
發送的流程就在圖中已經說明了,就不單獨在文字列出來了!需要注意的一點是,訊息寫入leader后,follower是主動的去leader進行同步的!producer采用push模式將資料發布到broker,每條訊息追加到磁區中,順序寫入磁盤,所以保證同一磁區內的資料是有序的!寫入示意圖如下:
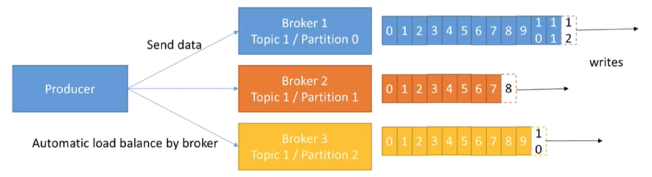
上面說到資料會寫入到不同的磁區,那kafka為什么要做磁區呢?相信大家應該也能猜到,磁區的主要目的是:
- 方便擴展,因為一個topic可以有多個partition,所以我們可以通過擴展機器去輕松的應對日益增長的資料量,
- 提高并發,以partition為讀寫單位,可以多個消費者同時消費資料,提高了訊息的處理效率,
1、寫入指定的partition,順序排列

熟悉負載均衡的朋友應該知道,當我們向某個服務器發送請求的時候,服務端可能會對請求做一個負載,將流量分發到不同的服務器,那在kafka中,如果某個topic有多個partition,producer又怎么知道該將資料發往哪個partition呢?kafka中有幾個原則:
- partition在寫入的時候可以指定需要寫入的partition,如果有指定,則寫入對應的partition,
- 如果沒有指定partition,但是設定了資料的key,則會根據key的值hash出一個partition,
- 如果既沒指定partition,又沒有設定key,則會輪詢選出一個partition,
2、確保資料不丟失
保證訊息不丟失是一個訊息佇列中間件的基本保證,那producer在向kafka寫入訊息的時候,怎么保證訊息不丟失呢?其實上面的寫入流程圖中有描述出來,那就是通過ACK應答機制!在生產者向佇列寫入資料的時候可以設定引數來確定是否確認kafka接收到資料,這個引數可設定的值為0、1、all,
- 0代表producer往集群發送資料不需要等到集群的回傳,不確保訊息發送成功,安全性最低但是效率最高,
- 1代表producer往集群發送資料只要leader應答就可以發送下一條,只確保leader發送成功,
- all代表producer往集群發送資料需要所有的follower都完成從leader的同步才會發送下一條,確保leader發送成功和所有的副本都完成備份,安全性最高,但是效率最低,
最后要注意的是,如果往不存在的topic寫資料,能不能寫入成功呢?kafka會自動創建topic,磁區和副本的數量根據默認配置都是1,
看這篇文章的作業流程分析,寫得很好
kfka作業原理
https://www.cnblogs.com/sujing/p/10960832.html
四、消費資料
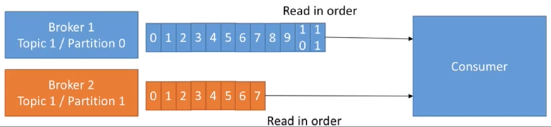
對于某一個topic來說,如果有多個partition,讀取是并行的,但是對于單獨的一個partition來說,讀取是順序的,按照時間順序,最老的資料先被讀出來
在實際的應用中,消費者組的consumer的數量與partition的數量一致是比較理想的情況,多出來的消費者不消費任何partition的資料,
consumer消費資料后,會向kafka提交committed offset,consumer下一次消費資料時,會從committed offset位置開始讀取
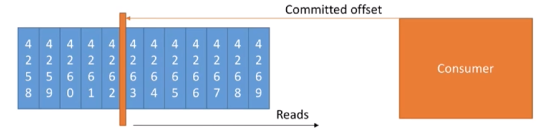
committed offset分為以下幾種情況:
最多一次:當訊息到達消費者時,馬上committed offset,如果此時消費者程式宕機,這條訊息將不會再被處理,造成資料丟失,
最少一次:當消費者消費完資料,再進行committed offset,如果消費程式崩潰(沒消費完),消費者重新啟動時,還會再次去讀取一次資料,這個時候,我們需要確保當前資料不會影響系統資料的準確性,比如,如果有3條message,前兩條已經插入了資料庫,此時程式崩潰,第二次讀取時,我們不應該再向資料庫插入相同的資料,應該把插入資料改成修改資料,盡最大可能的減少重復消費對系統的影響,
有且只有一次:此種場景比較難以實作,

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/289204.html
標籤:其他