文章目錄
- 前言:
- 什么是Spark Streaming
- SparkStreaming的原理介紹
- SparkStreaming的優點
- SparkStreaming獲取kafka資料有兩種方式
- DStream的概念
- DataStream
- DStream的Transformation(轉換)
- DStream的Output(輸出)
- SparkStreaming程式WordCount
- 視窗操作案例實作
- 視窗函式
- SparkStreaming的背壓機制
- 反壓(背壓Back Pressure)機制
- 流量控制
- 令牌桶機制
- Spark的maven依賴
- Spark Streaming與Storm對比
前言:
十年生死兩茫茫,千行代碼,Bug何處藏,
縱使產品經理祭蒼天,又怎樣?
朝令改,夕斷腸,
相顧無言,惟有淚千行,
每晚燈火闌珊處,夜難寐,加班狂

什么是Spark Streaming
Spark Streaming類似于Apache Storm,用于流式資料的處理,
根據其官方檔案介紹,SparkStreaming有高吞吐量和容錯能力強等特點,Spark Streaming支持的資料輸入源很多,例如:Kafka、Flume、Twitter、ZeroMQ和簡單的TCP套接字等等,資料輸入后可以用Spark的高度抽象原語如:map、reduce、join、window等進行運算,而結果也能保存在很多地方,如HDFS,資料庫等,另外Spark Streaming也能和MLlib(機器學習)以及Graphx完美融合,
SparkStreaming的原理介紹
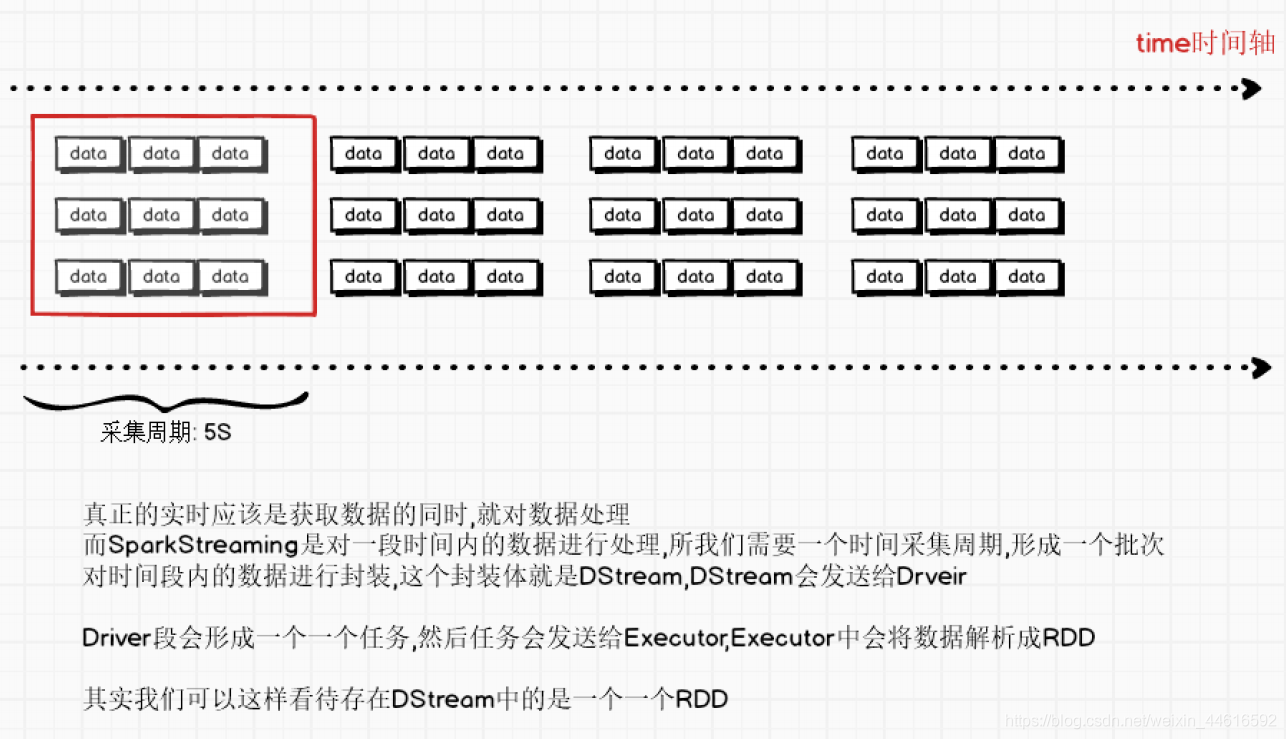
SparkStreaming使用的是"微批次"的架構,把流式計算當作一些列的小規模批次處理來對待,SparkStreaming從各種輸入源中讀取資料,并把資料分組為小的批次,新的批次按均勻的時間間隔創建出來.在每個時間區間開始的時候,一個新的批次就創建出來,在改區間內收到的資料都會被添加到這個批次中,在時間區間結束時,批次停止增長,時間區間的大小是由批次間隔引數決定此
批次間隔一般設定在500毫秒起到幾秒之間,由開大人員來進行配置
ps:人類間隔批次可讀時間5s
每個輸入批次都會形成一個RDD以Spark作業的方式會處理并生成其他的RDD處理的結果可以以批次處理并發送和給外部存盤系統
SparkStreaming的優點
- 易用
SparkStreaming將ApacheSpark的語言集成API引入到流處理中,使您可以像撰寫批處理作業一樣撰寫流式作業,它支持Java、Scala和Python, - 容錯
Spark Streaming可以從盒子中恢復丟失的作業和操作員狀態(如滑動視窗),而不需要任何額外的代碼, - 易整合到spark體系
ps: SparkStreming可以保證每條資料只會被處理一次
通過在Spark上運行,Spark流允許您重用相同的代碼進行批處理、根據歷史資料連接流,或者對流狀態運行即席查詢,構建強大的互動式應用程式,而不僅僅是分析,
SparkStreaming獲取kafka資料有兩種方式
Receiver(接收器)
Receiver方式是通過zookeeper來維護偏移量的,Kafka的topic磁區和Spark Streaming中生成的RDD磁區沒有關系,在KafkaUtils.createStream中增加磁區數量只會增加單個receiver的執行緒數,不會增加Spark的并行度,可以創建多個的Kafka節點輸入DStream,使用不同的group和topic,使用多個receiver并行接收資料,
Direct(直連)
簡化的并行性:不需要創建多個流輸入Kafka并將其合并, 使用directStream,Spark Streaming將創建與使用Kafka磁區一樣多的RDD磁區,這些磁區將全部從Kafka并行讀取資料, 所以在Kafka和RDD磁區之間有一對一的映射關系,
效率:
在第一種方法中實作零資料丟失需要將資料存盤在預寫日志中,這會進一步復制資料,這實際上是效率低下的,因為資料被有效地復制了兩次 一次是Kafka,另一次是由預先寫入日志(Write Ahead Log)復制,
第二種方法消除了這個問題,因為沒有接收器,因此不需要預先寫入日志,
SparkCore中提供一個概念叫做RDD來用存盤和處理資料
SparkSQL中提供一個概念叫做DataFrame和DataSet用來存盤和處理資料
SparkStreaming中提供了一個叫做DStream用存盤和處理資料
DStream的概念
SparkCore中提供一個概念叫做RDD來用存盤和處理資料
SparkSQL中提供一個概念叫做DataFrame和DataSet用來存盤和處理資料
SparkStreaming中提供了一個叫做DStream用存盤和處理資料
SparkStreaming使用離散化流(discretized Stream)作為抽象表示,作為SparkStreaming中存盤資料的抽象,和Spark中RDD有著類似概念,DStream是隨著時間他推移而可以得到不同資料序列,在其內部,每個時間區間接收到的資料都作為RDD存在,而DStream是由這個些RDD所組成的(因為此得名"離散化流")
DataStream
DStream的Transformation(轉換)

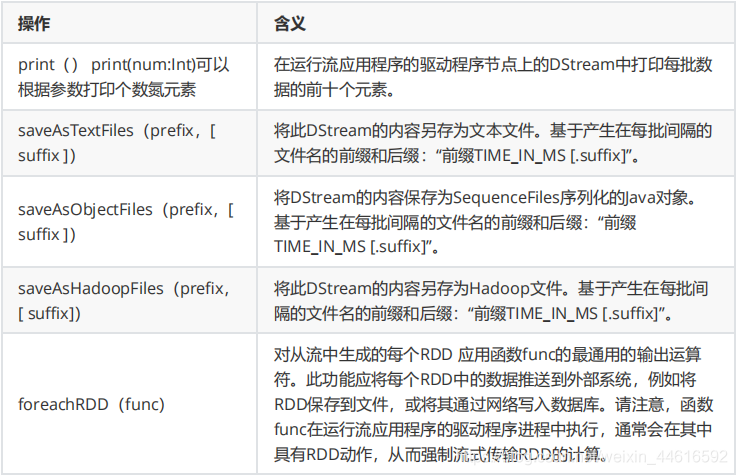
DStream的Output(輸出)
SparkStreaming程式WordCount
package SparkStreaming_01
import org.apache.spark.streaming.dstream.ReceiverInputDStream
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.streaming.{Seconds, StreamingContext}
/*
寫SparkStreaming程式的時候不能使用local作為本地程式開啟模式,原因在于它需要使用一個執行緒進行
接收
還需要一個執行緒進行任務執行,所以不能使用local單執行緒模式
我們開啟SparkStreaming執行的時候需要使用 local[值]形式 或 local[*]形式
*/
object SparkStreamingWC {
def main(args: Array[String]): Unit = {
//創建SparkStreaming物件
//1.需要創建SparkConf
val conf = new
SparkConf().setAppName("SparkStreamingWC").setMaster("local[*]")
//2.創建SparkStreaming物件 第一個引數是conf配置,第二個引數批次間隔
val ssc = new StreamingContext(conf,Seconds(5))
//第二種. 使用SparkContext物件
// val sc = new SparkContext(conf)
// val ssc1 = new StreamingContext(sc,Seconds(5))
//獲取實時資料, 從netcat服務器中獲取資料
//第一個引數是節點名稱(沒有配置hosts就需要些IP地址),第二個引數是埠號從什么埠獲取資料
val dStream: ReceiverInputDStream[String] =
ssc.socketTextStream("hadoop01",6666)
//處理DStream和RDD處理是沒有什么區別的
//但是需要注意含義不用當前這里呼叫算子的時候回傳的是一個DStream
val sumed = dStream.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
//將結果打到控制臺上
sumed.print()
//開啟任務(將任務提交到集群)
ssc.start()
//等待任務,處理下一個批次(執行緒等待)
ssc.awaitTermination()
}
}
無狀態轉換
操作就是把簡單的RDD轉換為操作應用在每個批次上,也就是將DStream中每一個RDD進行轉換,轉換程序中所產生的資料結果,不會影響下一個批次中的資料進行計算,批次和批次之間不會產生影響
有狀態轉換
批次資料計算的結果會直接影響下一個批次的計算結果,因為使用是實時流,資料是不斷輸入的,所以需要計算上一個批次和當前批次的結果,那么就需要將上一個批次的計算結果進行保存,保存資料無非就是兩種
1.保存在記憶體中
2.保存在磁盤中(磁盤)
視窗操作案例實作
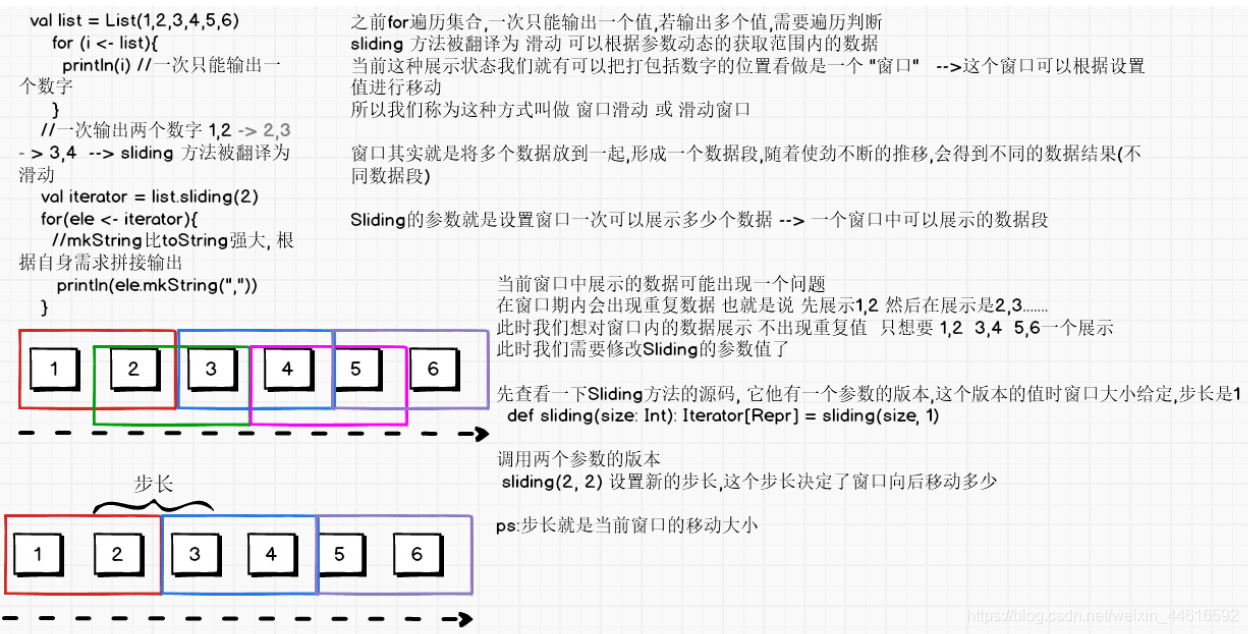
SparkStreaming中也提供了這樣的操作叫做Window Operations
Window Operations可以設定視窗的大小和滑動視窗的間隔來動態的獲取當前Steaming的允許狀態,基于視窗的操作會在一個比StreamingContext的批次間隔更長的時間范圍內,通過整合多個批次的結果,計算出整個視窗的結果,
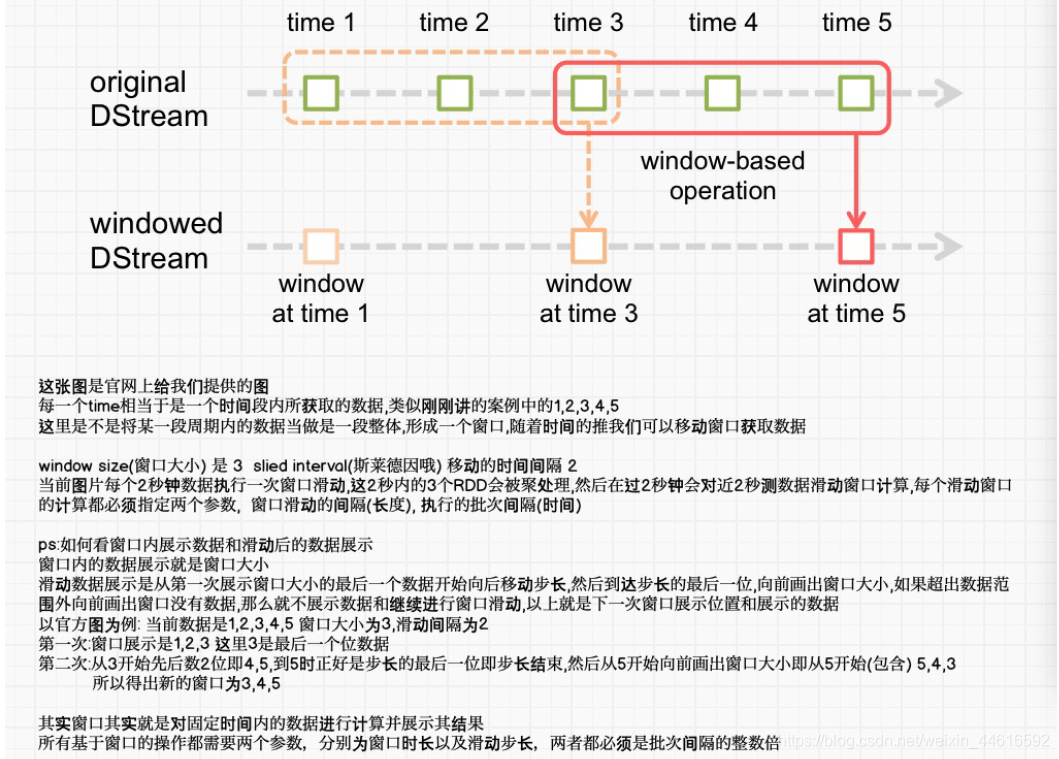
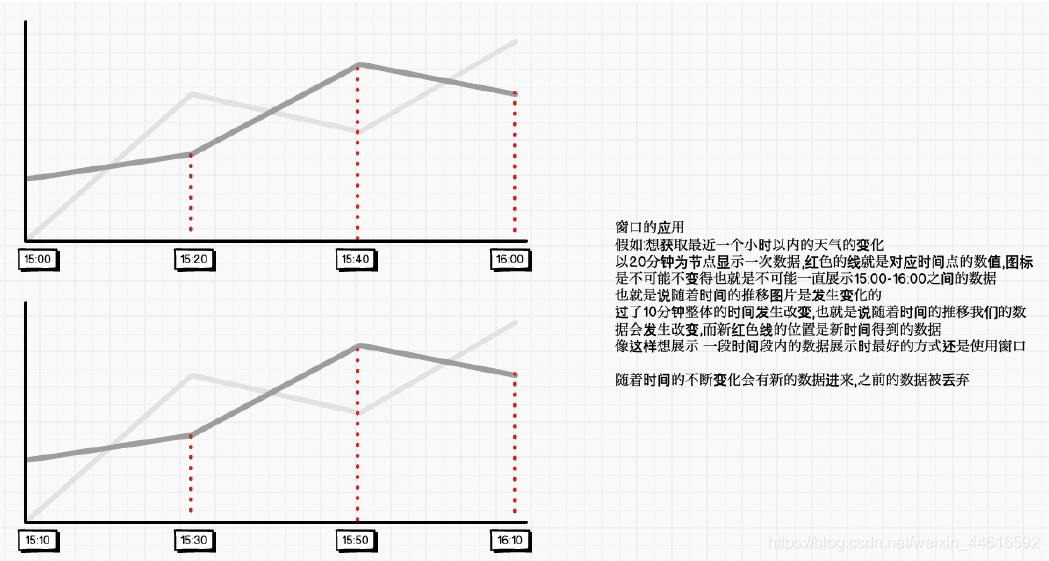
視窗函式

SparkStreaming的背壓機制
在默認情況下,Spark Streaming 通過 receivers (或者是 Direct(直連) 方式) 以生產者生產資料的速率接收資料,當 batch processing time > batch interval 的時候,也就是每個批次資料處理的時間要比Spark Streaming 批處理間隔時間長;越來越多的資料被接收,但是資料的處理速度沒有跟上,導致系統開始出現資料堆積,可能進一步導致 Executor 端出現 OOM 問題而出現失敗的情況,
而在 Spark 1.5 版本之前,為了解決這個問題,對于 Receiver-based 資料接收器,我們可以通過配置spark.streaming.receiver.maxRate 引數來限制每個 receiver 每秒最大可以接收的記錄的資料;對于Direct Approach 的資料接收,我們可以通過置spark.streaming.kafka.maxRatePerPartition 引數來限制每次作業中每個 Kafka 磁區最多讀取的記錄條數,這種方法雖然可以通過限制接收速率,來適配當前的處理能力,但這種方式存在以下幾個問題:
- 我們需要事先估計好集群的處理速度以及訊息資料的產生速度;
- 這兩種方式需要人工參與,修改完相關引數之后,我們需要手動重啟 Spark Streaming 應用程式;
如果當前集群的處理能力高于我們配置的 maxRate,而且 producer 產生的資料高于 maxRate,這會導致集群資源利用率低下,而且也會導致資料不能夠及時處理,
反壓(背壓Back Pressure)機制
那么有沒有可能不需要人工干預,Spark Streaming 系統自動處理這些問題呢?
當然有了!Spark 1.5引入了反壓(Back Pressure)機制,其通過動態收集系統的一些資料來自動地適配集群資料處理能力,
流量控制
當Receiver開始接收資料時,會通過supervisor.pushSingle()方法將接收的資料存入currentBuffer等待BlockGenerator定時將資料取走,包裝成block. 在將資料存放入currentBuffer之時,要獲取許可(令牌),如果獲取到許可就可以將資料存入buffer, 否則將被阻塞,進而阻塞Receiver從資料源拉取資料,
ReceiverRateController來不斷的計算RDD的處理速度和RDD的生成速度
這里的核心就是它,是自動完成的其令牌投放采用令牌桶機制進行, 原理如下圖所示:
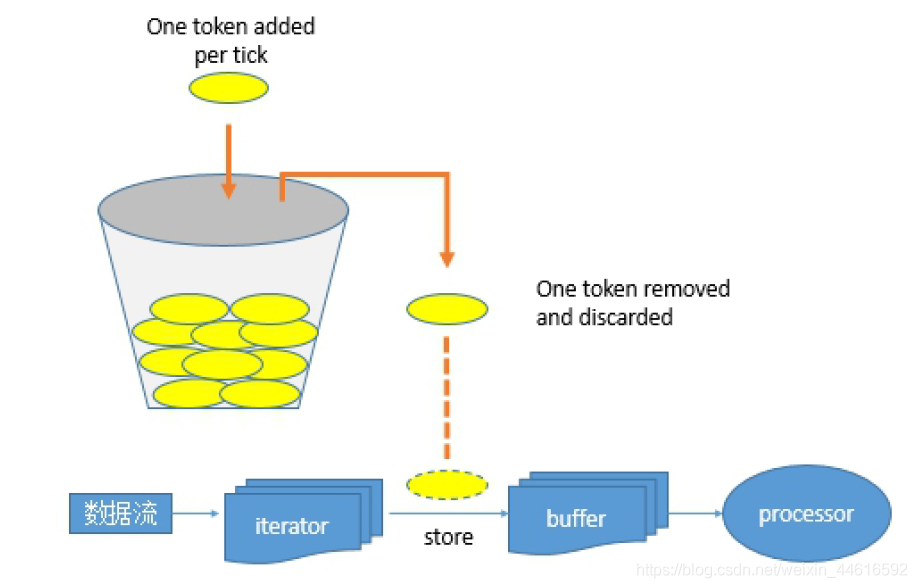
令牌桶機制
大小固定的令牌桶可自行以恒定的速率源源不斷地產生令牌,如果令牌不被消耗,或者被消耗的速度小于產生的速度,令牌就會不斷地增多,直到把桶填滿,后面再產生的令牌就會從桶中溢位,最后桶中可以保存的最大令牌數永遠不會超過桶的大小,當進行某操作時需要令牌時會從令牌桶中取出相應的令牌數,如果獲取到則繼續操作,否則阻塞,用完之后不用放回,
Spark的maven依賴
<properties>
<spark.version>2.2.0</spark.version>
<scala.version>2.11</scala.version>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-yarn_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.16</version>
</dependency>
</dependencies>
Spark Streaming與Storm對比
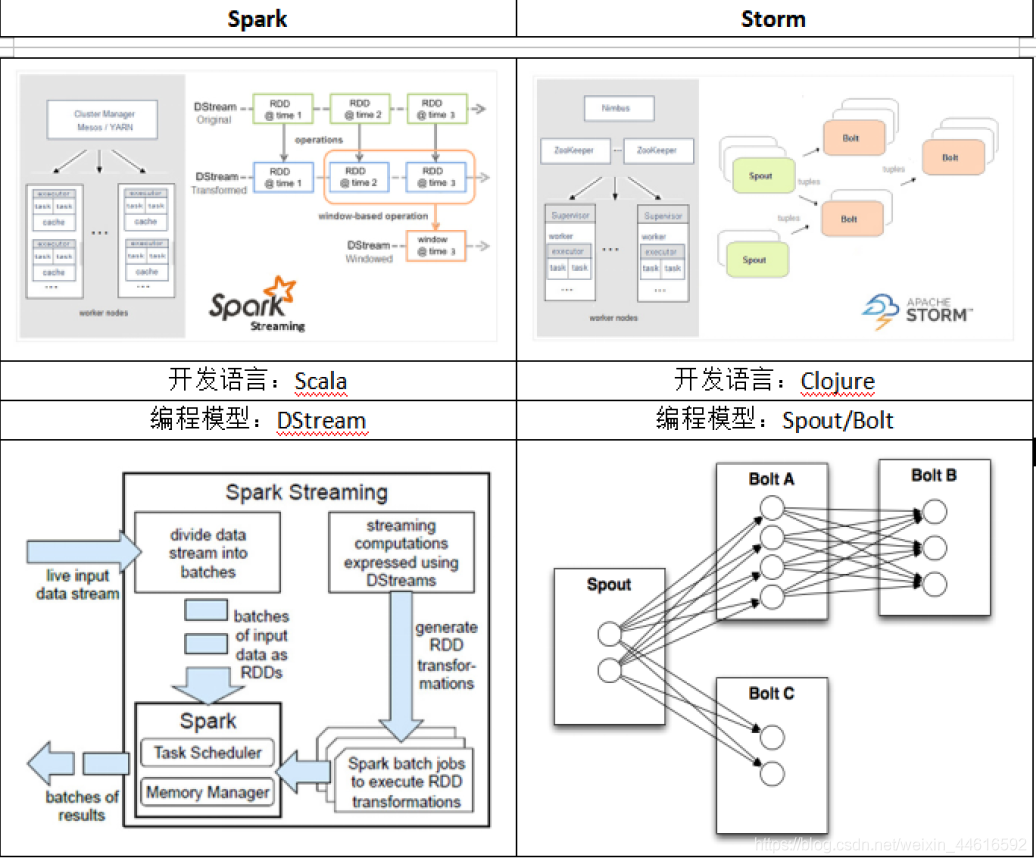
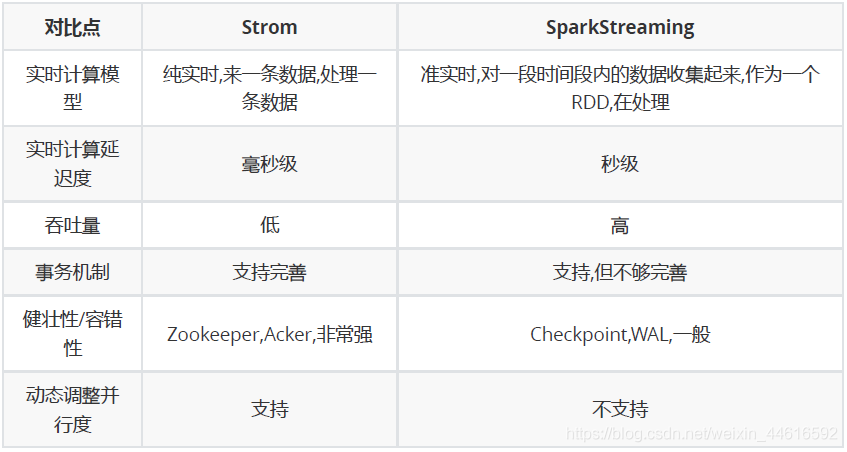
對于Storm來說:
- 建議在那種需要純實時,不能忍受1秒以上延遲的場景下使用,比如實時金融系統,要求純實時進行金融交易和分析
- 此外,如果對于實時計算的功能中,要求可靠的事務機制和可靠性機制,即資料的處理完全精準,一條也不能多,一條也不能少,也可以考慮使用Storm
- 如果還需要針對高峰低峰時間段,動態調整實時計算程式的并行度,以最大限度利用集群資源(通常是在小型公司,集群資源緊張的情況),也可以考慮用Storm
- 如果一個大資料應用系統,它就是純粹的實時計算,不需要在中間執行SQL互動式查詢、復雜的transformation算子等,那么用Storm是比較好的選擇對于
Spark Streaming來說:
- 如果對上述適用于Storm的三點,一條都不滿足的實時場景,即,不要求純實時,不要求強大可靠的事務機制,不要求動態調整并行度,那么可以考慮使用SparkStreaming
- 考慮使用Spark Streaming最主要的一個因素,應該是針對整個專案進行宏觀的考慮,即,如果一個專案除了實時計算之外,還包括了離線批處理、互動式查詢等業務功能,而且實時計算中,可能還會牽扯到高延遲批處理、互動式查詢等功能,那么就應該首選Spark生態,用Spark Core開發離線批處理,用Spark SQL開發互動式查詢,用Spark Streaming開發實時計算,三者可以無縫整合,給系統提供非常高的可擴展性
有識訓?希望烙鐵們來個三連擊,讓更多的同學看到這篇文章
1、烙鐵們,關注我看完保證有所識訓,不信你打我,
2、點個贊唄,可以讓更多的人看到這篇文章,后續還會有很哇塞的產出,
本文章僅供學習及個人復習使用,如需轉載請標明轉載出處,如有錯漏歡迎指出
務必注明來源(注明: 來源:csdn , 作者:-馬什么梅-)

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/289220.html
標籤:其他
上一篇:分布式鎖-三種實作方式簡述