全網最詳細的大資料HBase文章系列,強烈建議收藏加關注!
新文章都已經列出歷史文章目錄,幫助大家回顧前面的知識重點,
目錄
系列歷史文章
前言
Apache Phoenix 二級索引
一、索引分類
二、索引分類_全域索引
三、索引分類_本地索引
四、索引分類_覆寫索引
五、索引分類_函式索引
六、索引案例一: 創建全域索引+覆寫索引
1、需求
2、創建索引
3、查詢資料
4、查詢執行計劃
5、洗掉索引
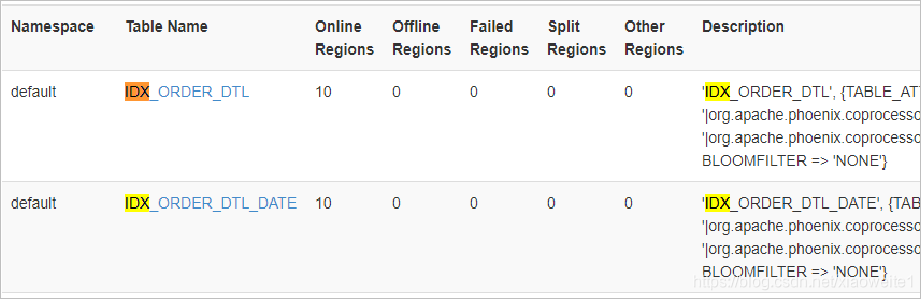
6、查看索引
7、測驗查詢所有列是否會使用索引
8、使用Hint強制使用索引
七、索引案例二: 創建本地索引
1、查看資料
2、洗掉索引
八、陌陌案例二級索引構建
1、創建本地函式索引
2、執行資料查詢
系列歷史文章
2021年大資料HBase(十一):Apache Phoenix的視圖操作
2021年大資料HBase(十):Apache Phoenix的基本入門操作
2021年大資料HBase(九):Apache Phoenix的安裝
2021年大資料HBase(八):Apache Phoenix的基本介紹
2021年大資料HBase(七):Hbase的架構!【建議收藏】
2021年大資料HBase(六):HBase的高可用!【建議收藏】
2021年大資料HBase(五):HBase的相關操作-JavaAPI方式!【建議收藏】
2021年大資料HBase(四):HBase的相關操作-客戶端命令式!【建議收藏】
2021年大資料HBase(三):HBase資料模型
2021年大資料HBase(二):HBase集群安裝操作
2021年大資料HBase(一):HBase基本簡介
前言
2021大資料領域優質創作博客,帶你從入門到精通,該博客每天更新,逐漸完善大資料各個知識體系的文章,幫助大家更高效學習,

Apache Phoenix 二級索引
因為沒有建立索引,組合條件查詢效率較低,而通過使用Phoenix,我們可以非常方便地創建二級索引,Phoenix中的索引,其實底層還是表現為HBase中的表結構,這些索引表專門用來加快查詢速度,
一、索引分類
- 全域索引
- 本地索引
- 覆寫索引
- 函式索引
二、索引分類_全域索引
- 全域索引適用于讀多寫少業務
- 全域索引絕大多數負載都發生在寫入時,當構建了全域索引時,Phoenix會攔截寫入(DELETE、UPSERT值和UPSERT SELECT)上的資料表更新,構建索引更新,同時更新所有相關的索引表,開銷較大
- 讀取時,Phoenix將選擇最快能夠查詢出資料的索引表,默認情況下,除非使用Hint,如果SELECT查詢中參考了其他非索引列,該索引是不會生效的
- 全域索引一般和覆寫索引搭配使用,讀的效率很高,但寫入效率會受影響
- 創建語法: CREATE INDEX 索引名稱 ON 表名 (列名1, 列名2, 列名3...)
三、索引分類_本地索引
- 本地索引適合寫操作頻繁,讀相對少的業務
- 當使用SQL查詢資料時,Phoenix會自動選擇是否使用本地索引查詢資料
- 在本地索引中,索引資料和業務表資料存盤在同一個服務器上,避免寫入期間的其他網路開銷
- 在Phoenix 4.8.0之前,本地索引保存在一個單獨的表中,在Phoenix 4.8.1中,本地索引的資料是保存在一個影子列蔟中
- 本地索引查詢即使SELECT參考了非索引中的欄位,也會自動應用索引的
- 注意:創建表的時候指定了SALT_BUCKETS,是不支持本地索引的
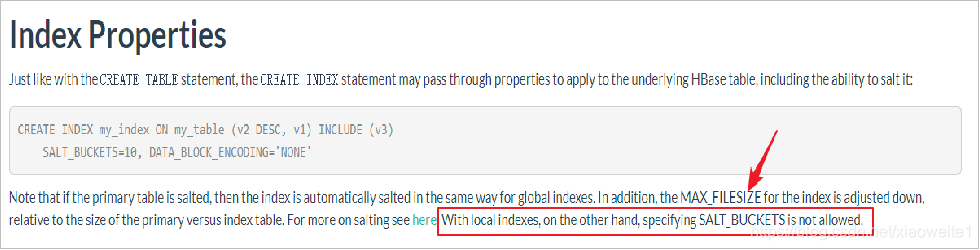
- 創建語法: CREATE LOCAL INDEX 索引名稱 ON 表名 (列名1, 列名2, 列名3...)
四、索引分類_覆寫索引
hoenix提供了覆寫的索引,可以不需要在找到索引條目后回傳到主表,Phoenix可以將關心的資料捆綁在索引行中,從而節省了讀取時間的開銷,
例如,以下語法將在v1和v2列上創建索引,并在索引中包括v3列,也就是通過v1、v2就可以直接把資料查詢出來,
CREATE INDEX my_index ON my_table (v1,v2) INCLUDE(v3)-
可以被表中任意的欄位構建覆寫 索引, 建立之后, 可以在查詢的時候, 不需要在去到主表查詢, 可以減少查詢的時間, 提升效率, 但是帶來弊端, 導致資料出現冗余情況
-
注意: 無法單獨使用, 必須結合全域或者本地索引
-
創建語法: create [local] index my_index on 目標表(列1,列2...) include(覆寫索引列....)
五、索引分類_函式索引
函式索引(4.3和更高版本)可以支持在列上創建索引,還可以基于任意運算式上創建索引,然后,當查詢使用該運算式時,可以使用索引來檢索結果,而不是資料表,例如,可以在UPPER(FIRST_NAME||‘ ’||LAST_NAME)上創建一個索引,這樣將來搜索兩個名字拼接在一起時,索引依然可以生效,
-- 創建索引
CREATE INDEX UPPER_NAME_IDX ON EMP (UPPER(FIRST_NAME||' '||LAST_NAME)) -- 以下查詢會走索引
SELECT EMP_ID FROM EMP WHERE UPPER(FIRST_NAME||' '||LAST_NAME)='JOHN DOE'- 可以針對某一個函式的結果 構建索引, 將結果資料建好索引, 這樣當我們使用這個函式時可以直接將結果回傳
- 創建語法: create index 索引名稱 on 表名(函式)
六、索引案例一: 創建全域索引+覆寫索引
1、需求
我們需要根據用戶ID來查詢訂單的ID以及對應的支付金額,
例如:查詢已付款的訂單ID和支付金額
此時,就可以在USER_ID列上創建索引,來加快查詢
2、創建索引
create index GBL_IDX_ORDER_DTL on ORDER_DTL(C1."user_id") INCLUDE("id", C1."money"); 可以在HBase shell中看到,Phoenix自動幫助我們創建了一張GBL_IDX_ORDER_DTL的表,這種表就是一張索引表
3、查詢資料
select "user_id", "id", "money" from ORDER_DTL where "user_id" = '8237476';4、查詢執行計劃
explain select "user_id", "id", "money" from ORDER_DTL where "user_id" = '8237476';
5、洗掉索引
使用drop index 索引名 ON 表名
drop index IDX_ORDER_DTL_DATE on ORDER_DTL;
6、查看索引
!table
7、測驗查詢所有列是否會使用索引
explain select * from ORDER_DTL where "user_id" = '8237476';
8、使用Hint強制使用索引
explain select /*+ INDEX(ORDER_DTL GBL_IDX_ORDER_DTL) */ * from ORDER_DTL where USER_ID = '8237476'; 通過執行計劃,我們可以觀察到查看全域索引,找到ROWKEY,然后執行全表的JOIN,其實就是把對應ROWKEY去查詢ORDER_DTL表,
通過執行計劃,我們可以觀察到查看全域索引,找到ROWKEY,然后執行全表的JOIN,其實就是把對應ROWKEY去查詢ORDER_DTL表,
七、索引案例二: 創建本地索引
1、查看資料
explain select * from ORDER_DTL WHERE "status" = '已提交';
explain select * from ORDER_DTL WHERE "status" = '已提交' AND "pay_way" = 1;

通過觀察上面的兩個執行計劃發現,兩個查詢都是通過RANGE SCAN來實作的,說明本地索引生效
2、洗掉索引
drop index LOCAL_IDX_ORDER_DTL on ORDER_DTL;
八、陌陌案例二級索引構建
1、創建本地函式索引
CREATE LOCAL INDEX LOCAL_IDX_MOMO_MSG ON MOMO_CHAT.MSG(substr("msg_time", 0, 10), "sender_account", "receiver_account");
2、執行資料查詢
explain select "C1"."sender_account", "C1"."receiver_account","C1"."msg_time","C1"."message" from "MOMO_CHAT"."MSG" where substr("C1"."msg_time",0,10) = '2021-01-16' and "C1"."sender_account" = '17344828999' and "C1"."receiver_account" = '18040049394';
可以看到,查詢速度非常快,0.1秒就查詢出來了資料,
- 📢博客主頁:https://lansonli.blog.csdn.net
- 📢歡迎點贊 👍 收藏 ?留言 📝 如有錯誤敬請指正!
- 📢本文由 Lansonli 原創,首發于 CSDN博客🙉
- 📢大資料系列文章會每天更新,停下休息的時候不要忘了別人還在奔跑,希望大家抓緊時間學習,全力奔赴更美好的生活?
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/289222.html
標籤:其他