哈希表(HashMap、字典)是日常編程當中所經常用到的一種資料結構,程式員經常接解到的大資料Hadoop技術堆疊、Redis快取資料庫等等最近熱度很高的技術,其實都是對鍵值(key-value)資料的高效存盤與提取,而key-value恰恰就是哈希表中存盤的元素結構,可以說Redis、HDFS這些都是哈希表的經典應用,不過筆者之前也只知道哈希表比較快,但對于具體什么場景下快,怎么用才快等等知識卻一知半解,因此這里把目前的一些研究成果分享給大家,
重新認識哈希表
所謂的哈希表就是通過哈希演算法快速搜索查詢元素的方法,比如說你要在茫茫人海當中找到一位筆名叫做beyondma的博主,但卻并不知道他具體的博客地址,在這種情況下就只能在所有的博主范圍內展開逐個的排查與摸索,運氣差的話我可能以找遍所有n個博主的主頁,才到beyondma,這也就是這種遍歷查找的時間復雜度是o(n),查找的時間會隨著博主的數量而線增長,
而哈希演算法就是直接將beyondma這個名字進行演算法處理,直接得到beyondma的博客地址資訊,在哈希演算法的加持下定位某一元素的時間度變成了o(1),由于哈希演算法能夠將key(鍵值本例中指beyond)和value(本例中指beyond.csdn.net)以o(1)的時間復雜度,直接對應起來,因此哈希表被人稱為key-value表,存盤的元素也被稱為key-value對(鍵值對),哈希表的查找程序特別像查字典,給出一個字并找到這個字在字典中的位置,只是哈希表在一般情況下都很快,當然哈希表也有代價:
以空間換時間:哈希演算法也稱為散列演算法,這種叫法相對比較直觀,由于哈希演算法是通過計算確認存盤地址的,因此首先進入到哈希表的元素并不一定存到第一個位置,存盤n個鍵值對的哈希表往往會消耗比切片多很多的記憶體空間,
哈希碰撞:哈希碰撞是指不同的鍵值,在經過哈希計算后得到的記憶體地址槽位是相同的,也就是說相同的地址上要存盤兩個以上的鍵值對,一旦發生這種情況,也就是哈希碰撞了,在發生碰撞的場景下哈希表會進行退化,其中Java會在碰撞強度到達一定級別后,會使用紅黑樹的方式來進行哈希鍵值對的存盤,而Go和Rust一般都是退化成為鏈表,
下面我們首先來詳細講講兩個哈希表的常見誤用,
哈希表的誤用
不要遍歷哈希表!:區域快,不意味著整體快,由于哈希表提取單個元素的速度很快,因此整個遍歷整個集合所需要的時間也會更短,這種看法明顯是個美麗的誤會,
我們后文也會具體講到,哈希表在遍歷方面的表現結果,是由計算機組成原理決定的,與Go、Rust和Java的區別不大,因此以下例子先以Go語言的代碼為例來說明,
package main
import (
"fmt"
"time"
)
func main() {
testmap := make(map[int]int)
len := 1000000
//tests1ice := make([]int, len, len)
for i := 0; i < len; i++ {
testmap[i] = i + 1
}
sum := 0
now := time.Now().UnixNano()
for k, v := range testmap {
sum = sum + k + v
}
diff := time.Now().UnixNano() - now
fmt.Println("sum=", sum)
fmt.Println("diff=", diff)
// fmt PrintIn("slice=", slice)
}可以看到使用哈希表進行遍歷的話,以上代碼運行的結果為:
sum= 1000000000000
diff= 29297200
成功: 行程退出代碼 0.而對比使用切片遍歷的代碼如下:
package main
import (
"fmt"
"time"
)
func main() {
//testmap := make(map[int]int)
len := 1000000
tests1ice := make([]int, len, len)
for i := 0; i < len; i++ {
tests1ice[i] = i + 1
}
sum := 0
now := time.Now().UnixNano()
for k, v := range tests1ice {
sum = sum + k + v
}
diff := time.Now().UnixNano() - now
fmt.Println("sum=", sum)
fmt.Println("diff=", diff)
// fmt PrintIn("slice=", slice)
}以上代碼運行結果為:
sum= 1000000000000
diff= 1953900
成功: 行程退出代碼 0.可以看到同樣長度的集合遍歷性能表現,切片的耗時只有哈希表的5%左右,兩者幾乎相差兩個數量級,
資料訪問區域性原理的制約:區域性原理可能是計算機基本原理中威力最強的基本定理之一,也是程式員在編程程序中必須要考慮的規律,因此我們看到在計算機世界中區域性原理,經常在速度不匹配的存盤介質中得到運用,比如英特爾的CPU往往分為三級高速快取,彼此之間的速度差距大概在8到10倍之間,其中高速快取中的第三級快取又比記憶體快10倍,這樣彼此之間各差10倍左右的快取體系加速效果最好,這就像軍事行動中,先鋒部隊既要率先行動,又不能與大部隊過于脫節,才能圓滿的完成任務,在實際CPU的作業當中,如果資料單元A1被訪問了,那么A1的鄰居A0和A2被訪問到的可能性也會極大的增加,因此CPU一般都會在資料單元A1被訪問的同時,將他的鄰居們調入高速快取,
也就是說切片這種在記憶體當中連續分布的資料結構,其元素都是以高速快取行的大小為單位讀入到高速快取的,而高速快取的平均速度又是記憶體的幾十倍,因此相當于一次讀取操作,就能快速處理好幾個元素;但由于哈希表實際也是稀疏表,一個鍵值對的周圍可能沒有其它有效鍵值對,因此哈希表在遍歷時實際上只能一個一個元素的處理,這樣比較下來哈希表在單個元素的訪問上快,但在整體遍歷上慢也就不足為奇了,
在元素不多不要用哈希表!我經常看到有不少程式員在元素不多的情況下,還堅持使用哈希表來建立key-value的對應關系,其實這樣的做法并不會帶來效率的提升,正如我們剛剛所說,哈希演算法也被稱為散列演算法,鍵值對的記憶體地址分布很可能并不連續,這就特別不方便區域性原理發揮作用,剛剛我們上文也提到了記憶體快取行的大小通常是64byte,在實際測驗程序中可以看到如果元素能在一個記憶體快取行存盤下來,就不要用哈希表了,這時候用資料切片,每次遍歷查找的性能反而比哈希表更快,具體代碼如下:
哈希表實作示例
package main
import (
"fmt"
"time"
)
func main() {
testmap := make(map[int]int)
len := 10
times := 100000
//tests1ice := make([]int, len, len)
for i := 0; i < len; i++ {
testmap[i] = i + 1
}
sum := 0
now := time.Now().UnixNano()
for i := 0; i < times; i++ {
//for k, v := range testmap {
//if i%len == v {
sum = sum + i%len + testmap[i%len]
//break
//}
//}
//sum = sum + k + v
//tests1ice[i%len] = i + 1
}
diff := time.Now().UnixNano() - now
fmt.Println("sum=", sum)
fmt.Println("diff=", diff)
// fmt PrintIn("slice=", slice)
}以上代碼結果如下:
sum= 1000000
diff= 2929500而切片遍歷查找的實作如下:
package main
import (
"fmt"
"time"
)
func main() {
//testmap := make(map[int]int)
len := 10
times := 100000
tests1ice := make([]int, len, len)
for i := 0; i < len; i++ {
tests1ice[i] = i + 1
}
sum := 0
now := time.Now().UnixNano()
for i := 0; i < times; i++ {
for k, v := range tests1ice {
if i%len == k {
sum = sum + k + v
break
}
}
//sum = sum + k + v
//tests1ice[i%len] = i + 1
}
diff := time.Now().UnixNano() - now
fmt.Println("sum=", sum)
fmt.Println("diff=", diff)
// fmt PrintIn("slice=", slice)
}sum= 810000
diff= 1953000
成功: 行程退出代碼 0.少元素方面集合的元素定位性能上,哈希表比切片慢了40%,當然這也是區域性原理造成的,由于元素比較少,因此切片這樣記憶體連續資料結構,完全可以在高速快取中完成資料的查找定位,這樣綜合下來其性能反而還要比哈希表要快,
正如前文所述,哈希演算法的作業機制本身就決定了哈希表對存盤空間就有一定的浪費,因此在沒有性能優勢的情況下,尤其是上述遍歷及短表的場景下,就不要再用哈希表了,完全沒有必要,
哈希表的實作機制要點
在筆者看了部分哈希表的代碼之后,Java、Go和Rust這三種語言有一些相同的機制,也有一些不同,其中有兩點值得關注,當然由于水平有限,如有錯誤之處敬請指正,
避免使用連續記憶體塊:我們知道在記憶體、硬碟等存盤設備的管理中,連續的空間往往是比較寶貴的,而哈希表是相對比較稀疏的資料結構,因此Java、Go和Rust基本都參考了一些比如桶的機制,盡量避免占用連續的記憶體塊,以Go語言的實作為例:
type hmap struct {
count int // map的長度
flags uint8
B uint8 // map中的bucket的數量,
noverflow uint16 //
hash0 uint32 // hash 種子
buckets unsafe.Pointer // 指向桶的指標
oldbuckets unsafe.Pointer // 指向舊桶的指標,這里用于溢位
nevacuate uintptr
extra *mapextra // optional fields
}
// 在桶溢位的時候會用到extra
type mapextra struct {
overflow *[]*bmap
oldoverflow *[]*bmap
nextOverflow *bmap
}
type bmap struct {
tophash [bucketCnt]uint8// Map中的哈希值的高8位為桶的地址
}在訪問Map中的鍵值對時,需要先計算key的哈希值,其中哈希的值的低8位定位到具體的桶(bucket),通過高8位在桶內定位到具體的位置,而不同桶之間所占用的記憶體區域也不需要是連續的空間,這樣也就從一定程度上彌補哈希表占用空間較大的缺點,
哈希碰撞處理:我們剛剛也介紹了哈希表碰撞的內容,也就是出現了不同的鍵值對要存盤在同一個記憶體槽位的場景,極端情況下是所有鍵值對全部發生碰撞,這樣哈希表實際也就退化成了鏈表,Java對碰撞的處理相對比較成熟,如果退化的鏈表長度大于8,那么Java會選擇用紅黑樹這種近似于二叉排序樹的資料結構進行替代,從而保證定位性能不低于O(logn)
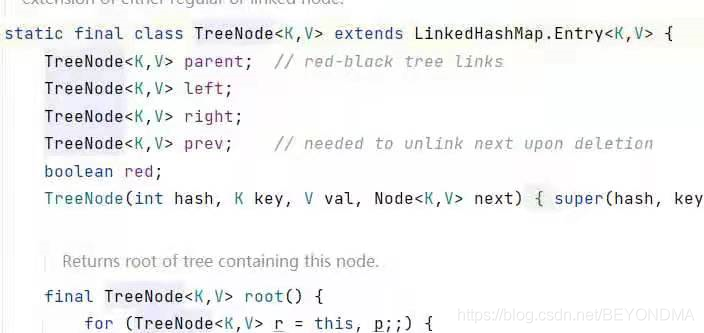
而如果鏈表的長度小于等于8,那么如我們上文介紹,在資料長度比較短的情況下其實鏈表的性能可能還會更好,沒必要使用引入紅黑樹,由此可見Java這門語言的確已經非常成熟,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/289280.html
標籤:其他