作者介紹:大羅,黑格智造架構師,主要從事云原生,大資料系統開發,曾參與國家示范級工業互聯網系統建設等,
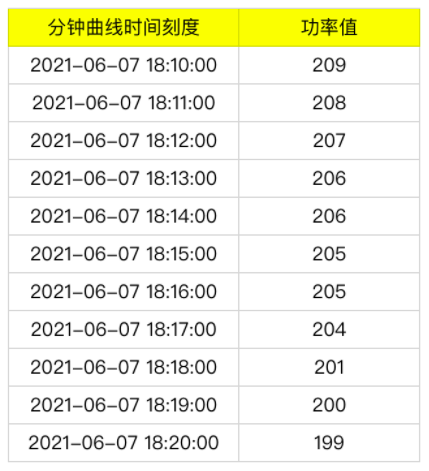
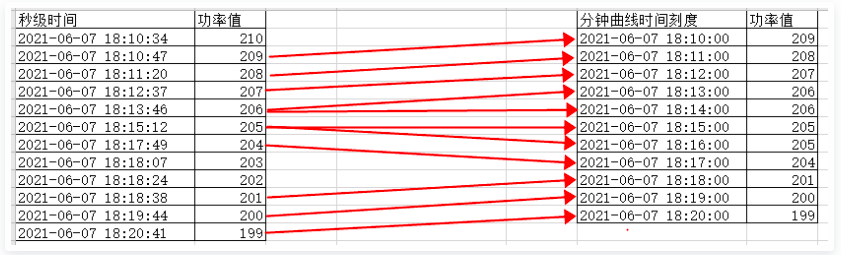
做工業互聯網或物聯網系統,最基本的需求是展示資料曲線,比如功率曲線,類似于股票的分時圖,通常我們會取每分鐘內該設備上報的最后一次功率值為這一分鐘的功率,如果某一分鐘內,設備沒有上報,則取上一分鐘的功率值,以此類推,舉例如下:
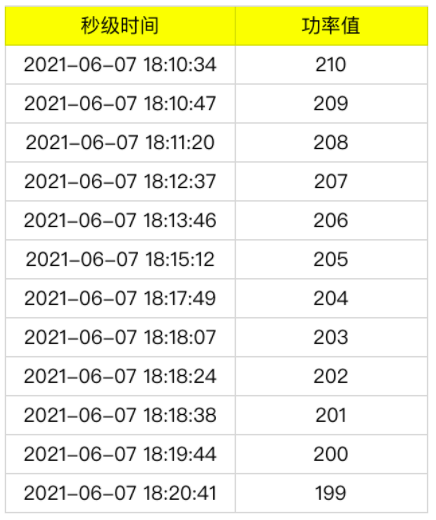
得到的分鐘曲線:
通常我們會把設備上報的資料先寫入Apache Kafka,如果是離線計算場景,可能會考慮把資料寫入Hive,然后使用Spark SQL定時讀取Hive,再把計算結果寫入HBase;如果是實時計算場景,則會使用Apache Flink消費Kafka資料,把結果寫入HBase,這種情況下還需要考慮資料亂序和延遲投遞計算等問題,
而且,基于傳統大資料Hadoop的架構,需要搭建ZooKeeper和HDFS,然后才是Hive和HBase,整個體系維護成本很高,此外,HBase基于鍵值存盤時序資料,會浪費很多空間在同一鍵值的資料設計架構上面,
以上所舉,是物聯網設備屬性曲線計算場景的其中一個痛點,另外還需要考慮資料增長、資料核對以及資料容災等特點,
筆者所在的公司,要基于3D列印技術給客戶提供整體化解決方案,自然需要對設備的運行狀態做持續追蹤,需要存盤設備的運行資料,這時候我們找到了開源的物聯網大資料平臺TDengine(https://github.com/taosdata/TDengine),
參考TDengine的檔案中SQL的寫法,在資料齊全的情況下,可以輕松地用一句SQL解決上面的問題:
select last(val) a from super_table_xx where ts >= '2021-06-07 18:10:00' and ts <= '2021-06-07 18:20:00' interval(60s) fill(value, 0);
為什么類似的SQL,TDengine的執行效率可以如此之高呢?
這就在于它的超級表以及子表,針對單個設備的資料,TDengine設計了按照時間連續存盤的特性,而事實上,業務系統在使用物聯網資料的時候,無論是即時查詢還是離線分析,存在讀取單個設備的一個連續時間段資料的特點,
假設,我們要存盤設備的溫度與濕度,我們可以設計超級表如下:
create stable if not exists s_device (ts TIMESTAMP,
temperature double,
humidity double
) TAGS (device_sn BINARY(1000));實際使用中,例如針對設備’d1’和’d2’的資料執行插入的SQL如下:
insert into s_device_d1 (ts, temperature, humidity) USING s_device (device_sn) TAGS ('d1') values (1623157875000, 35.34, 80.24);
insert into s_device_d2 (ts, temperature, humidity) USING s_device (device_sn) TAGS ('d2') values (1623157891000, 29.63, 79.48);搜索設備’d1’某個時間段的資料,其SQL如下:
select * from s_device where device_sn = 'd1' and ts > 1623157871000 and ts < 1623157890000 ;假設統計過去7天的平均溫度曲線,每小時1個點:
select avg(temperature) temperature from s_device where device_sn = #{deviceSn} and ts >= #{startTime} and ts < #{endTime} interval(1h)
TDengine還提供了很多聚合函式,類似上面的計算1分鐘連續曲線的last和fill,以及其他常用的sum和max等,
在和應用程式結合的程序中,我們選用MyBatis這種靈活易上手的ORM框架,例如,針對上面的資料表’s_device’,我們先定義entity :
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.sql.Timestamp;
/**
* @author: DaLuo
* @date: 2021/06/25
* @description:
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
@Builder
@TableName(value = "s_device")
public class TestSuperDeviceEntity {
private Timestamp ts;
private Float temperature;
private Float humidity;
@TableField(value = "device_sn")
private String device_sn ;
}再定義 mapper:
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.hg.device.kafka.tdengine.entity.TestSuperDeviceEntity;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.ibatis.annotations.Insert;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Param;
import org.apache.ibatis.annotations.Select;
import java.sql.Timestamp;
import java.util.List;
/**
* @author: DaLuo
* @date: 2021/06/25
* @description:
*/
@Mapper
public interface TestSuperDeviceMapper extends BaseMapper<TestSuperDeviceEntity> {
/**
* 單個插入
* @param entity
* @return
*/
@Insert({
"INSERT INTO 's_device_${entity.deviceSn}' (ts ,temperature, humidity ) ",
"USING s_device (device_sn) TAGS (#{entity.deviceSn}) ",
"VALUES (#{entity.ts}, #{entity.temperature}, #{entity.humidity})"
})
int insertOne(@Param(value = "entity") TestSuperDeviceEntity entity);
/**
* 批量插入
* @param entities
* @return
*/
@Insert({
"<script>",
"INSERT INTO ",
"<foreach collection='list' item='item' separator=' '>",
"'s_device_${item.deviceSn}' (ts ,temperature, humidity) USING s_device (device_sn) TAGS (#{item.deviceSn}) ",
"VALUES (#{item.ts}, #{item.temperature}, #{item.humidity})",
"</foreach>",
"</script>"
})
int batchInsert(@Param("list") List<TestSuperDeviceEntity> entities);
/**
* 查詢過去一段時間范圍的平均溫度,每小時1個資料點
* @param deviceSn
* @param startTime inclusive
* @param endTime exclusive
* @return
*/
@Select("select avg(temperature) temperature from s_device where device_sn = #{deviceSn} and ts >= #{startTime} and ts < #{endTime} interval(1h)")
List<TempSevenDaysTemperature> selectSevenDaysTemperature(
@Param(value = "deviceSn") String deviceSn,
@Param(value = "startTime") long startTime,
@Param(value = "endTime") long endTime);
@AllArgsConstructor
@NoArgsConstructor
@Data
@Builder
class TempSevenDaysTemperature {
private Timestamp ts;
private float temperature;
}
}TDengine有一個很巧妙的設計,就是不用預先創建子表,所以我們可以很方便地利用’tag’標簽作為子表名稱的一部分,即時插入資料同時創建子表,
注意:考慮到跨時區的國際化特性,我們所有的時間存盤查詢互動,都是使用的時間戳,而非”yyyy-mm-dd hh:MM:ss”格式,因為資料存盤涉及到應用程式時區,連接字串時區,TDengine服務時區,使用”yyyy-mm-dd hh:MM:ss”格式容易導致時間存盤的不準確性,而使用時間戳,長整型的資料格式則可以完美地避免此類問題,
Java使用TDengine JDBC-driver目前有兩種方式:JDBC-JNI和JDBC-RESTful,前者在寫入性能上更有優勢,但是需要在應用程式運行的服務器上安裝TDengine客戶端驅動,
我們的應用程式用到了Kubernetes集群,程式是運行在Docker里面,為此我們制作了一個適合我們應用程式運行的鏡像,例如基礎鏡像的Dockerfile如下所示:
FROM openjdk:8-jdk-oraclelinux7
COPY TDengine-client-2.0.16.0-Linux-x64.tar.gz /
RUN tar -xzvf /TDengine-client-2.0.16.0-Linux-x64.tar.gz && cd /TDengine-client-2.0.16.0 && pwd && ls && ./install_client.shbuild:
docker build -t tdengine-openjdk-8-runtime:2.0.16.0 -f Dockerfile .
參考程式鏡像Dockerfile所示:
FROM tdengine-openjdk-8-runtime:2.0.16.0
ENV JAVA_OPTS="-Duser.timezone=Asia/Shanghai -Djava.security.egd=file:/dev/./urandom"
COPY app.jar /app.jar
ENTRYPOINT ["java","-jar","/app.jar"]這樣我們的應用程式就可以調度在任意的K8s節點上了,
另外,我們的程式涉及到任務自動化調度,需要頻繁地和設備下位機進行MQTT資料互動,比如,云端發送指令1000-“開始任務A”,下位機回復指令2000-“收到任務A”,把指令理解成設備,把指令序列號以及內容理解成它的屬性,自然這種資料也是非常適合存盤在TDengine時序資料庫中的:
*************************** 1.row ***************************
ts: 2021-06-23 16:10:30.000
msg: {"task_id":"7b40ed4edc1149f1837179c77d8c3c1f","action":"start"}
device_sn: deviceA
kind: 1000
*************************** 2.row ***************************
ts: 2021-06-23 16:10:31.000
msg: {"task_id":"7b40ed4edc1149f1837179c77d8c3c1f","action":"received"}
device_sn: deviceA
kind: 2000我們云端在和設備對接的程序中,頻繁需要考究訊息是否發送的問題,所以迫切需要對指令進行保存,從而在應用程式中新辟執行緒,專門訂閱指令集訊息,批量寫入到TDengine資料庫,
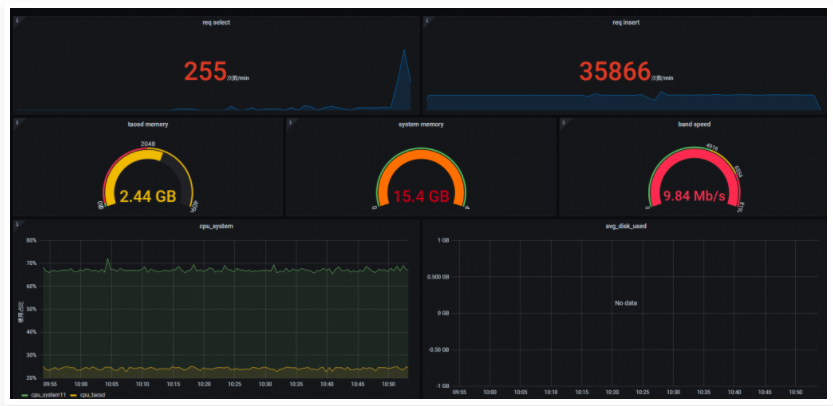
最后,TDengine還有一個超級表log.dn,里面保留了記憶體、CPU等使用資訊,所以我們可以利用Grafana展示這些資料,為監控提供可靠的運營資料參照!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/289392.html
標籤:其他
上一篇:反向改考,從408改考資料結構!浙江理工大學軟體工程
下一篇:51單片機系列--定時器中斷