文章目錄
- 第八章 影像內容分類
- (一)K鄰近分類法(KNN)
- (二)貝葉斯分類器
- (三)支持向量機
- (四)光學字符識別
第八章 影像內容分類
本章介紹影像分類和影像內容分類演算法,
先介紹一些簡單而有效的方法和一些性能最好的分類器,運用它們解決兩類和多類分類問題,再展示兩個用于手勢識別和目標識別的應用實體,
(一)K鄰近分類法(KNN)
在分類方法中,最簡單且用的最多的一種方法之一是KNN,
這種方法把要分類的物件(例如一個特征向量)與訓練集中已知類標記的所有物件進行對比,并由k近鄰對指派到哪個類進行投票,
缺點:需要預先設定k值,k值得選擇會影響分類得性能;這種方法要求將整個訓練集存盤起來,如果訓練集非常大,搜索起來就非常慢;可并行性一般
優點:這種方法在采用何種距離度量方面沒有限制
實作最基本的KNN形式:給定訓練樣本集和對應的標記串列,這些訓練樣本和標記可以在一個陣列里成行擺放或者干脆擺放到串列里,訓練樣本可能是數字、字串等任何形狀,將定義的物件添加到名為knn.py的檔案里,(此處采用的是歐氏距離進行度量)
一個簡單的二維示例
首先建立一些簡單的二維示例資料集來說明并可視化分類器的作業原理,
下面的腳本將創建兩個不同的二維點集,每個點集有兩類,用Pickle模塊來保存創建的資料,我們需要四個二維資料集檔案,每個分布都有兩個檔案,一個用來訓練,另一個用來做測驗,
如圖中所示:
先用Pickle模塊創建一個KNN分類器模型,再載入另一個資料集(測驗資料集),并在控制臺上列印第一個資料點估計出來的類標記,為了可視化所有測驗資料點的分類,并展示分類器將兩個不同的類分開的怎么樣,可以創建一個簡短的輔助函式以獲取x和y二維坐標陣列和分類器,并回傳一個預測的類標記陣列,
繪制出的結果如下圖所示:
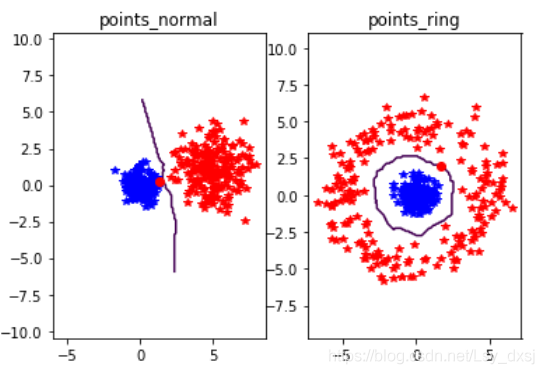
可以看到,KNN決策邊界適用于沒有任何明確模型的類分布
代碼為:
# -*- coding: utf-8 -*-
from numpy.random import randn
import pickle
from pylab import *
# create sample data of 2D points
n = 200
# two normal distributions
class_1 = 0.6 * randn(n,2)
class_2 = 1.2 * randn(n,2) + array([5,1])
labels = hstack((ones(n),-ones(n)))
# save with Pickle
#with open('points_normal.pkl', 'w') as f:
with open('points_normal.pkl', 'wb') as f:
pickle.dump(class_1,f)
pickle.dump(class_2,f)
pickle.dump(labels,f)
# normal distribution and ring around it
class_1 = 0.6 * randn(n,2)
r = 0.8 * randn(n,1) + 5
angle = 2*pi * randn(n,1)
class_2 = hstack((r*cos(angle),r*sin(angle)))
labels = hstack((ones(n),-ones(n)))
# save with Pickle
#with open('points_ring.pkl', 'w') as f:
with open('points_ring.pkl', 'wb') as f:
pickle.dump(class_1,f)
pickle.dump(class_2,f)
pickle.dump(labels,f)
# -*- coding: utf-8 -*-
import pickle
from pylab import *
import knn
import imtools
pklist=['points_normal.pkl','points_ring.pkl']
figure()
# load 2D points using Pickle
for i, pklfile in enumerate(pklist):
with open(pklfile, 'rb') as f:
class_1 = pickle.load(f)
class_2 = pickle.load(f)
labels = pickle.load(f)
# load test data using Pickle
with open(pklfile[:-4]+'_test.pkl', 'rb') as f:
class_1 = pickle.load(f)
class_2 = pickle.load(f)
labels = pickle.load(f)
model = knn.KnnClassifier(labels,vstack((class_1,class_2)))
# test on the first point
print(model.classify(class_1[0]))
#define function for plotting
def classify(x,y,model=model):
return array([model.classify([xx,yy]) for (xx,yy) in zip(x,y)])
# lot the classification boundary
subplot(1,2,i+1)
imtools.plot_2D_boundary([-6,6,-6,6],[class_1,class_2],classify,[1,-1])
titlename=pklfile[:-4]
title(titlename)
show()
用稠密SIFT作為影像特征
上一節是對點進行分類,這一節學習如何對影像進行分類,
要對影像進行分類,需要一個特征向量來表示一幅影像,這節學的是稠密SIFT特征向量,
創建名為dsift.py檔案,將幀陣列存盤在一個文本檔案中,例如用下面的代碼來計算稠密SIFT描述子,并可視化它們的位置:
# -*- coding: utf-8 -*-
import sift, dsift
from pylab import *
from PIL import Image
dsift.process_image_dsift('empire.jpg','empire.dsift',90,40,True)
l,d = sift.read_features_from_file('empire.dsift')
im = array(Image.open('empire.jpg'))
sift.plot_features(im,l,True)
title('dense SIFT')
show()
得到的結果為:

影像分類:手勢識別
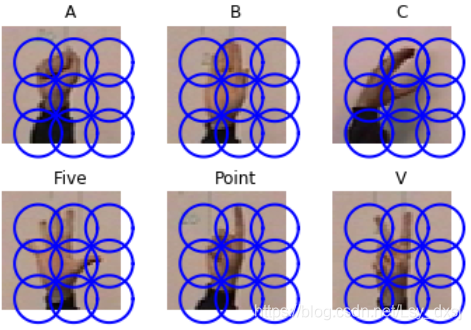
在此應用中,我們使用稠密SIFT描述子來表示這些收拾影像,并建立一個簡單的手勢識別系統,
我們使用靜態手勢資料庫中的一些影像進行演示,
如下圖所示:
代碼為:
# -*- coding: utf-8 -*-
import os
import sift, dsift
from pylab import *
from PIL import Image
imlist=['train/A-uniform01.ppm','train/B-uniform01.ppm',
'train/C-uniform02.ppm','train/Five-uniform01.ppm',
'train/Point-uniform01.ppm','train/V-uniform01.ppm']
figure()
for i, im in enumerate(imlist):
dsift.process_image_dsift(im,im[:-3]+'dsift',30,15,True)
l,d = sift.read_features_from_file(im[:-3]+'dsift')
dirpath, filename=os.path.split(im)
im = array(Image.open(im))
#顯示手勢含義title
titlename=filename[:-14]
subplot(2,3,i+1)
sift.plot_features(im,l,True)
title(titlename)
show()
得到的準確率和混淆矩陣為:
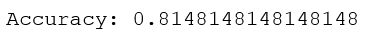
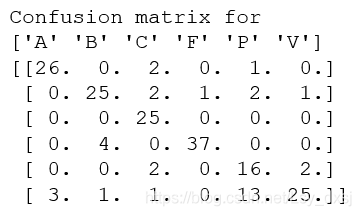
說明該例中有81%的影像是正確的,混淆矩陣可以顯示每類有多少個樣本被分在每一類中的矩陣,它可以顯示錯誤的分布情況,以及哪些類是經常“混淆”的,
代碼為:
#得到每幅圖的稠密sift特征
import dsift
# 將影像尺寸調為 (50,50),然后進行處理
for filename in imlist:
featfile = filename[:-3]+'dsift'
dsift.process_image_dsift(filename,featfile,10,5,resize=(50,50))
#輔助函式,用于從檔案中讀取稠密SIFT描述子
import os
import sift
def read_gesture_features_labels(path):
# create list of all files ending in .dsift
featlist = [os.path.join(path,f) for f in os.listdir(path) if f.endswith('.dsift')]
# read the features
features = []
for featfile in featlist:
l,d = sift.read_features_from_file(featfile)
features.append(d.flatten())
features = array(features)
# create labels
labels = [featfile.split('/')[-1][0] for featfile in featlist]
return features,array(labels)
#讀取訓練集、測驗集的特征和標記資訊
features,labels = read_gesture_features_labels('gesture/train/')
test_features,test_labels = read_gesture_features_labels('gesture/test/')
classnames = unique(labels)
#使用過前面的K近鄰代碼
# test kNN
import knn
k = 1
knn_classifier = knn.KnnClassifier(labels,features)
res = array([knn_classifier.classify(test_features[i],k) for i in range(len(test_labels))])
# accuracy
acc = sum(1.0*(res==test_labels)) / len(test_labels)
print('Accuracy:', acc)
#列印標記及相應的混淆矩陣
def print_confusion(res,labels,classnames):
n = len(classnames)
# confusion matrix
class_ind = dict([(classnames[i],i) for i in range(n)])
confuse = zeros((n,n))
for i in range(len(test_labels)):
confuse[class_ind[res[i]],class_ind[test_labels[i]]] += 1
print('Confusion matrix for')
print(classnames)
print(confuse)
print_confusion(res,test_labels,classnames)
(二)貝葉斯分類器
另一個簡單而有效的分類器是貝葉斯分類器(或稱樸素貝葉斯分類器),它是一種基于貝葉斯條件概率定理的概率分類器,它假設特征是彼此獨立不相關的,一旦學習了這個模型,就沒有必要存盤訓練資料,只需存盤模型的引數,
原理:該分類器是通過將各個特征的條件概率相乘得到一個類的總概率,然后選取概率最高的那個類構造出來的,
實體:創建名為bayes.py的檔案,添加Classifier類,該模型每一類都有兩個變數,類均值和協方差,將該貝葉斯分類器用于上一節的二維資料,下面的腳本載入上一節的二維資料,并訓練出一個分類器:
import pickle
import bayes
import imtools
# 用 Pickle 模塊載入二維樣本點
with open('points_normal.pkl', 'rb') as f:
class_1 = pickle.load(f)
class_2 = pickle.load(f)
labels = pickle.load(f)
# 訓練貝葉斯分類器
bc = bayes.BayesClassifier()
bc.train([class_1,class_2],[1,-1])
載入上一節中的二維測驗資料對分類器進行測驗:
import pickle
import bayes
import imtools
# 用 Pickle 模塊載入二維樣本點
with open('points_normal.pkl', 'rb') as f:
class_1 = pickle.load(f)
class_2 = pickle.load(f)
labels = pickle.load(f)
# 訓練貝葉斯分類器
bc = bayes.BayesClassifier()
bc.train([class_1,class_2],[1,-1])
該腳本將前10個二維資料點的分類結果列印輸出到控制臺,結果為:
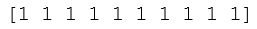
兩個資料集的分類結果如下圖所示:
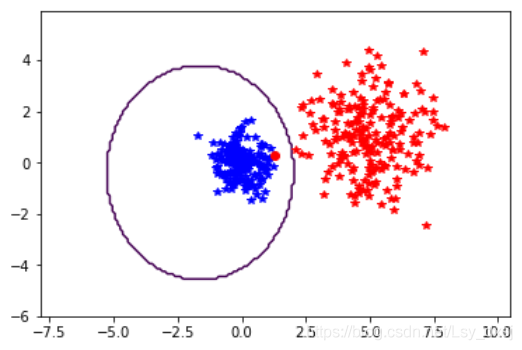
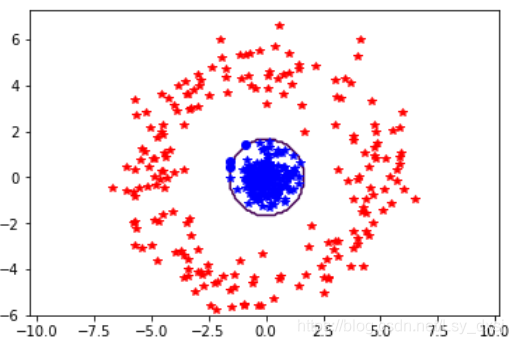
該例中,決策邊界是一個橢圓,類似于二維高斯函式的等值線,
接下來嘗試手勢識別問題,由于稠密SIFT描述子的特征向量十分龐大,所以在資料擬合模型之前需要進行降維處理,此時,采用PCA(主成分分析)來降維,創建名為pca.py的檔案,
在本例中,我們在訓練資料上用PCA降維,并保持在這50維具有最大的方差,
#輔助函式,用于從檔案中讀取稠密SIFT描述子
import os
import sift
from numpy import *
def read_gesture_features_labels(path):
# create list of all files ending in .dsift
featlist = [os.path.join(path,f) for f in os.listdir(path) if f.endswith('.dsift')]
# read the features
features = []
for featfile in featlist:
l,d = sift.read_features_from_file(featfile)
features.append(d.flatten())
features = array(features)
# create labels
labels = [featfile.split('/')[-1][0] for featfile in featlist]
return features,array(labels)
#讀取訓練集、測驗集的特征和標記資訊
features,labels = read_gesture_features_labels('gesture/train/')
test_features,test_labels = read_gesture_features_labels('gesture/test/')
classnames = unique(labels)
# PCA降維
import pca
V,S,m = pca.pca(features)
# 保持最重要的成分
V = V[:50]
features = array([dot(V,f-m) for f in features])
test_features = array([dot(V,f-m) for f in test_features])
訓練并測驗貝葉斯分類器如下:
import bayes
# 測驗貝葉斯分類器
bc = bayes.BayesClassifier()
blist = [features[where(labels==c)[0]] for c in classnames]
bc.train(blist,classnames)
res = bc.classify(test_features)[0]
檢查分類準確率:
import knn
k = 1
knn_classifier = knn.KnnClassifier(labels,features)
res = array([knn_classifier.classify(test_features[i],k) for i in range(len(test_labels))])
acc = sum(1.0*(res==test_labels)) / len(test_labels)
print('Accuracy:', acc)
輸出為:
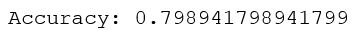
檢查混淆矩陣:
#列印標記及相應的混淆矩陣
def print_confusion(res,labels,classnames):
n = len(classnames)
# confusion matrix
class_ind = dict([(classnames[i],i) for i in range(n)])
confuse = zeros((n,n))
for i in range(len(test_labels)):
confuse[class_ind[res[i]],class_ind[test_labels[i]]] += 1
print('Confusion matrix for')
print(classnames)
print(confuse)
print_confusion(res,test_labels,classnames)
輸出結果為:
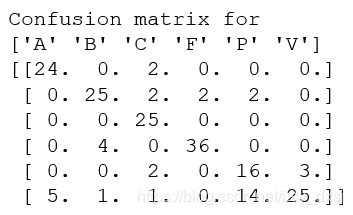
雖然分類效果不如K近鄰分類器,但貝葉斯分類器不需要保存任何訓練資料,而且只需保存每個類的模型引數,
(三)支持向量機
支持向量機(SVM)是一類強大的分類器,可以在很多分類問題中給出現有水準很高的分類結果,
方法:最簡單的SVM通過在高維空間中尋找一個最優線性分類面,盡可能地將兩類資料分開,
對于一特征向量x的決策函式為:
f
(
x
)
=
w
?
x
?
b
f(x)=w·x-b
f(x)=w?x?b
其中w是常規的超平面,b是偏移量常數,
可以寫成:
f
(
x
)
=
∑
i
α
i
y
i
x
i
?
x
?
b
f(x)=\sum_{i} \alpha_{i} y_{i} \boldsymbol{x}_{i} \cdot \boldsymbol{x}-b
f(x)=i∑?αi?yi?xi??x?b
這里的i是從訓練集中選出的部分樣本,這里選擇的樣本稱為支持向量,因為它們
可以幫助定義分類的邊界
優點:可以使用核函式,核函式能夠將特征向量映射到另外一個不同維度的空間中,比如高維度空間,通過核函式映射,依然可以保持對決策函式的控制,從而可以有效地解決非線性或者很難的分類問題,
最常見的核函式:
線性是最簡單的情況,即在特征空間中的超平面是線性的, K ( x i , x ) = x i ? x K\left(\boldsymbol{x}_{i}, \boldsymbol{x}\right)=\boldsymbol{x}_{i} \cdot \boldsymbol{x} K(xi?,x)=xi??x;
多項式用次數為 d 的多項式對特征進行映射, K ( x i , x ) = ( γ x i ? x + r ) d , γ > 0 K\left(\boldsymbol{x}_{i}, \boldsymbol{x}\right)=\left(\gamma \boldsymbol{x}_{i} \cdot \boldsymbol{x}+r\right)^{d}, \quad \gamma>0 K(xi?,x)=(γxi??x+r)d,γ>0;
徑向基函式,通常指數函式是一種極其有效的選擇, K ( x i , x ) = e ( ? γ ∣ ∣ x i ? x ∥ 2 ) , γ > 0 K\left(\boldsymbol{x}_{i}, \boldsymbol{x}\right)=\mathrm{e}^{\left(-\gamma|| \boldsymbol{x}_{i}-x \|^{2}\right)}, \quad \gamma>0 K(xi?,x)=e(?γ∣∣xi??x∥2),γ>0
Sigmoid 函式,一個更光滑的超平面替代方案, K ( x i , x ) = tanh ? ( γ x i ? x + r ) K\left(\boldsymbol{x}_{i}, \boldsymbol{x}\right)=\tanh \left(\gamma \boldsymbol{x}_{i} \cdot \boldsymbol{x}+r\right) K(xi?,x)=tanh(γxi??x+r),
每個核函式的引數都是在訓練階段確定的
使用LibSVM
LibSVM下載地址:http://www.csie.ntu.edu.tw/~cjlin/libsvm/index.html#download
LibSVM載入在前面KNN范例分類中用到的資料點,并用徑向基函式訓練一個SVM分類器:
import pickle
from svmutil import *
import imtools
# 用 Pickle 載入二維樣本點
with open('points_ring.pkl', 'rb') as f:
class_1 = pickle.load(f)
class_2 = pickle.load(f)
labels = pickle.load(f)
# 轉換成串列,便于使用 libSVM
class_1 = list(map(list,class_1))
class_2 = list(map(list,class_2))
labels = list(labels)
samples = class_1+class_2 # 連接兩個串列
# 創建 SVM
prob = svm_problem(labels,samples)
param = svm_parameter('-t 2')
# 在資料上訓練 SVM
m = svm_train(prob,param)
# 在訓練資料上分類效果如何?
res = svm_predict(labels,samples,m)
列印輸出結果如下:
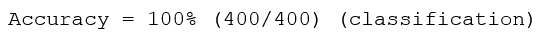
現在,載入其他資料集,并對該分類器進行測驗:
# 用 Pickle 模塊載入測驗資料
with open('points_normal_test.pkl', 'r') as f:
class_1 = pickle.load(f)
class_2 = pickle.load(f)
labels = pickle.load(f)
# 轉換成串列,便于使用 LibSVM
class_1 = map(list,class_1)
class_2 = map(list,class_2)
# 定義繪圖函式
def predict(x,y,model=m):
return array(svm_predict([0]*len(x),zip(x,y),model)[0])
# 繪制分類邊界
imtools.plot_2D_boundary([-6,6,-6,6],[array(class_1),array(class_2)],predict,[-1,1])
show()
(四)光學字符識別
光學字符識別(OCR)是一個多類問題實體,是一個理解手寫或機寫文本影像的處理程序,常見的例子是通過掃描檔案來提取文本,本節主要理解數度影像,
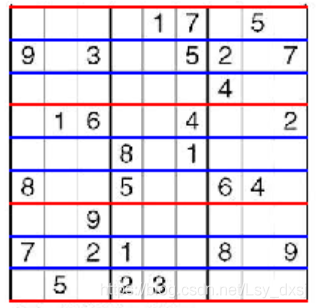
流程:我們假設數獨影像是已經對齊的,其水平和垂直網格線平行于影像的邊,在這些條件下,可以對影像進行閾值處理,并在水平和垂直方向上分別對像素值求和由于這些經閾值處理的邊界值為 1,而其他部分值為 0,所以這些邊界處會給出很強的回應,可以告訴我們從何處進行裁剪,
# -*- coding: utf-8 -*-
from PIL import Image
from pylab import *
from scipy.ndimage import measurements
def find_sudoku_edges(im, axis=0):
""" 尋找對齊后數獨影像的的單元邊線 """
# threshold and sum rows and columns
#閾值化,像素值小于128的閾值處理后為1,大于128的為0
trim = 1*(128 > im)
#閾值處理后對行(列)相加求和
s = trim.sum(axis=axis)
# print(s)
# find center of strongest lines
# 尋找連通區域
s_labels, s_nbr = measurements.label((0.5*max(s)) < s)
# print(s_labels)
# print(s_nbr)
#計算各連通域的質心
m = measurements.center_of_mass(s, s_labels, range(1, s_nbr+1))
# print(m)
#對質心取整,質心即為粗線條所在位置
x = [int(x[0]) for x in m]
# print(x)
# if only the strong lines are detected add lines in between
# 如果檢測到了粗線條,便在粗線條間添加直線
if 4 == len(x):
dx = diff(x)
x = [x[0], x[0]+dx[0]/3, x[0]+2*dx[0]/3, x[1], x[1]+dx[1]/3, x[1]+2*dx[1]/3, x[2], x[2]+dx[2]/3, x[2]+2*dx[2]/3, x[3]]
if 10 == len(x):
return x
else:
raise RuntimeError('Edges not detected.')
接下來輸入原圖:
imname = '2.png'
im = array(Image.open(imname).convert('L'))
print(im.shape)
figure()
gray()
imshow(im)
axis('off')
得到單元邊界線,并進行繪制輸出
# find the cell edges
# 尋找x方向的單元邊線
x = find_sudoku_edges(im, axis=0)
#尋找y方向的單元邊線
y = find_sudoku_edges(im, axis=1)
figure()
gray()
y1=[y[0],y[3],y[6],y[-1]]
y2=[y[1],y[2],y[4],y[5],y[7],y[8]]
#畫直線
for i, ch in enumerate(y1):
x1 = range(x[0], x[-1]+1, 1)
y1 = ch*ones(len(x1))
#畫散點圖
plot(x1, y1, 'r', linewidth=2)
for i, ch in enumerate(y2):
x1 = range(x[0], x[-1]+1, 1)
y1 = ch*ones(len(x1))
#畫散點圖
plot(x1, y1, 'b', linewidth=2)
'''for i, ch in enumerate(x):
y1 = range(x[0], x[-1]+1, 1)
x1 = ch*ones(len(x1))
#畫散點圖
plot(x1, y1, 'r', linewidth=2)
plot(x, y, 'or', linewidth=2)'''
imshow(im)
axis('off')
show()
得到的結果為:
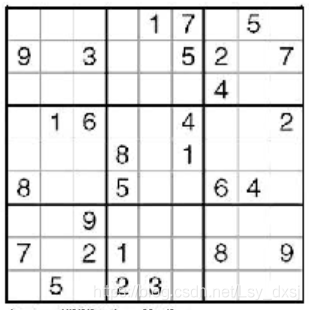
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/289406.html
標籤:其他
上一篇:【游戲開發進階】教你Unity通過Jenkins實作自動化打包,打包這種事情就交給策劃了(保姆級教程 | 命令列打包 | 自動構建)