網路安全課設:語音識別搜索檔案
通過查詢網上的方法,這里采用百度AI的方式來實作,百度語音識別鏈接:https://ai.baidu.com/tech/speech/asr 自己注冊即可使用,
先上效果圖:
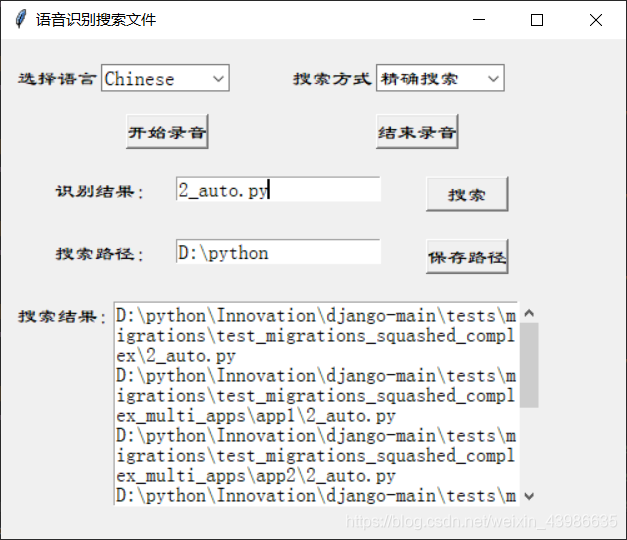
百度AI需要區分中文和英文,故添加了一個復選框,搜索方式按照課設要求支持模糊搜索和精確搜索,保存路徑下面會有介紹,主要是存盤路徑下的所有檔案,這里就不詳細說明了,
要實作語音識別搜索檔案第一步肯定就是語音識別了,實作代碼如下:
import pyaudio
import wave
from aip import AipSpeech
import threading
class Audio:
def __init__(self, chunk=1024, channels=1, rate=16000):
self.CHUNK = chunk
self.FORMAT = pyaudio.paInt16 # 量化位數
self.CHANNELS = channels # 單聲道
self.RATE = rate # 16000采樣頻率
self.running = True
self.frames = []
self.result = ""
self.language = 1537 # 中文
def start(self): # 啟動執行緒開始錄音
thread = threading.Thread(target=self.recording)
thread.start()
def recording(self): # 錄音
self.running = True
self.frames = []
p = pyaudio.PyAudio()
stream = p.open(format=self.FORMAT,
channels=self.CHANNELS,
rate=self.RATE,
input=True,
frames_per_buffer=self.CHUNK)
while self.running:
data = stream.read(self.CHUNK)
self.frames.append(data)
stream.stop_stream()
stream.close()
p.terminate()
def stop(self): # 停止錄音,保存音頻
self.running = False
p = pyaudio.PyAudio()
wf = wave.open('test.wav', 'wb')
wf.setnchannels(self.CHANNELS)
wf.setsampwidth(p.get_sample_size(self.FORMAT))
wf.setframerate(self.RATE)
wf.writeframes(b''.join(self.frames))
wf.close()
print("Saved")
def change_language(self, str_language): # 切換語音識別的語言
if str_language == "Chinese":
self.language = 1537
elif str_language == "English":
self.language = 1737
else:
print("選擇語言例外")
@staticmethod
def get_file_content():
with open('test.wav', 'rb') as fp:
return fp.read()
def recognition(self): # 語音識別
app_id = '24040013' # 根據自己百度AI進行更換
api_key = 'QsS4t8bfRDE6e9BIpDyZBaaV'
secret_key = '8BugGc4o6UGStaXAGTHRdsGlrccxs96b'
client = AipSpeech(app_id, api_key, secret_key)
result = client.asr(self.get_file_content(), 'wav', 16000, {
'dev_pid': self.language,
})
print(result)
if 'result' in result:
self.result = result['result']
else:
self.result = result
然后是搜索檔案,首先是模糊搜索:
def fuzzy_search(start_path, filename):
text1.delete(1.0, END)
for path, lists, files in os.walk(start_path):
for file in files:
if filename in file:
write = os.path.join(path, file)
print(write)
text1.insert(END, write)
text1.insert(tkinter.INSERT, '\n')
tips = '查詢完成!'
text1.insert(END, tips)
精確搜索需要提供檔案后綴,一般語音識別的話識別不出來后綴,可以采用將所有檔案都去除后綴的方法,但是我當時為了省事沒有這樣做,后來也就忘記了,,,
精確搜索我想的是通過二分法查找檔案名,進而取出其所有路徑,
def binary_search(files, filename): # 二分法查找檔案
length = len(files)
if length > 0:
mid = length // 2
if filename == files[mid]:
return True
elif filename < files[mid]:
return binary_search(files[:mid], filename)
elif filename > files[mid]:
return binary_search(files[mid + 1:], filename)
else:
return False
def accurate_search(path, name):
text1.delete(1.0, END)
with open('Allfiles.json', 'r', encoding='utf-8') as f: # 這里的json檔案是之前通過保存路徑按鈕將目錄下所有檔案以{檔案名:所有路徑名}的形式存盤的
file_dict = json.load(f)
file_list = list(file_dict.keys())
# path_list = file_dict.values()
# if path in path_list:
if binary_search(file_list, name):
for root_path in file_dict[name]:
final_path = os.path.join(root_path, name)
print(final_path)
text1.insert(END, final_path)
text1.insert(tkinter.INSERT, '\n')
else:
tips = '查詢無結果!'
text1.insert(END, tips)
所有代碼如下:
import tkinter
from tkinter import *
from tkinter import scrolledtext
from tkinter import ttk
from create_fname import Audio # 這里的create_fname即上文語音識別
import os
import json
import threading
audio = Audio()
root = Tk()
root.title('語音識別搜索檔案')
root.geometry('500x400')
language = StringVar()
def change_language(event):
global language
choice = choose_language.get()
print(choice)
audio.change_language(choice)
def start():
audio.start()
tips = '錄音開始!'
text1.insert(END, tips)
text1.insert(tkinter.INSERT, '\n')
def over():
audio.stop()
audio.recognition()
print(audio.result)
result = ''.join(audio.result)
result = result.replace(',', '')
result = result.replace('.', '')
print(result)
text.delete(1.0, END)
text.insert(END, result)
def search_start():
thread = threading.Thread(target=file_search())
thread.start()
def file_search():
# global search
choice = search.get()
print(choice)
start_path = text_path.get()
filename = text.get('0.0', 'end')
filename = filename.strip('\n')
print(choice)
print(filename)
if choice == '模糊搜索':
fuzzy_search(start_path, filename)
elif choice == '精確搜索':
accurate_search(start_path, filename)
def fuzzy_search(start_path, filename):
text1.delete(1.0, END)
for path, lists, files in os.walk(start_path):
for file in files:
if filename in file:
write = os.path.join(path, file)
print(write)
text1.insert(END, write)
text1.insert(tkinter.INSERT, '\n')
tips = '查詢完成!'
text1.insert(END, tips)
def binary_search(files, filename):
length = len(files)
if length > 0:
mid = length // 2
if filename == files[mid]:
return True
elif filename < files[mid]:
return binary_search(files[:mid], filename)
elif filename > files[mid]:
return binary_search(files[mid + 1:], filename)
else:
return False
def accurate_search(path, name):
text1.delete(1.0, END)
with open('Allfiles.json', 'r', encoding='utf-8') as f:
file_dict = json.load(f)
file_list = list(file_dict.keys())
# path_list = file_dict.values()
# if path in path_list:
if binary_search(file_list, name):
for root_path in file_dict[name]:
final_path = os.path.join(root_path, name)
print(final_path)
text1.insert(END, final_path)
text1.insert(tkinter.INSERT, '\n')
else:
tips = '查詢無結果!'
text1.insert(END, tips)
def file_save():
start_path = text_path.get()
file_roots = {}
text1.delete(0.0, END)
for root_path, lists, files in os.walk(start_path):
for file in files:
file_roots.setdefault(file, []).append(root_path)
data_list = dict(sorted(file_roots.items(), key=lambda d: d[0], reverse=False))
with open('Allfiles.json', 'w', encoding='utf-8') as json_file:
json.dump(data_list, json_file, ensure_ascii=False, indent=4)
tips = '路徑保存完成!'
text1.insert(END, tips)
text1.insert(tkinter.INSERT, '\n')
choose_language = ttk.Combobox(root, textvariable=language, font=('隸書', 12), width=10)
choose_language["value"] = ("Chinese", "English")
choose_language.current(0)
choose_language.place(x=80, y=20)
choose_language.bind("<<ComboboxSelected>>", change_language)
label_language = Label(root, text='選擇語言', font=('隸書', 12))
label_language.place(x=10, y=20)
# Chinese = Radiobutton(root, text='Chinese', variable=language, font=('隸書', 12),
# value='Chinese', command=change_language, width=7)
# English = Radiobutton(root, text="English", variable=language, font=('隸書', 12),
# value='English', command=change_language, width=7)
# Chinese.place(x=100, y=20)
# English.place(x=300, y=20)
start_button = Button(root, text='開始錄音', font=('隸書', 12), width=7, height=1, command=start)
start_button.place(x=100, y=60)
over_button = Button(root, text='結束錄音', font=('隸書', 12), width=7, height=1, command=over)
over_button.place(x=300, y=60)
search = StringVar()
search_method = ttk.Combobox(root, textvariable=search, font=('隸書', 12), width=10)
search_method["value"] = ("模糊搜索", "精確搜索")
search_method.current(1)
search_method.place(x=300, y=20)
# search_method.bind("<<ComboboxSelected>>", file_search)
label_search = Label(root, text='搜索方式', font=('隸書', 12))
label_search.place(x=230, y=20)
# fuzzy = Radiobutton(root, text='模糊搜索', variable=search, font=('隸書', 12),
# value='fuzzy', width=7)
# accurate = Radiobutton(root, text='精確搜索', variable=search, font=('隸書', 12),
# value='accurate', width=7)
# fuzzy.place(x=100, y=100)
# accurate.place(x=300, y=100)
label = Label(root, text='識別結果:', font=('隸書', 12))
label.place(x=40, y=110)
text = Text(root, font=('隸書', 12), width=20, height=1)
text.place(x=140, y=110)
label_path = Label(root, text='搜索路徑:', font=('隸書', 12))
label_path.place(x=40, y=160)
addr = StringVar()
addr.set('D:\\python')
text_path = Entry(root, textvariable=addr, font=('隸書', 12), width=20)
text_path.place(x=140, y=160)
search_button = Button(root, text='搜索', font=('隸書', 12), width=7, command=search_start)
search_button.place(x=340, y=110)
save_button = Button(root, text='保存路徑', font=('隸書', 12), width=7, command=file_save)
save_button.place(x=340, y=160)
label1 = Label(root, text='搜索結果:', font=('隸書', 12))
label1.place(x=10, y=210)
text1 = scrolledtext.ScrolledText(root, font=('隸書', 12), width=40, height=10)
text1.place(x=90, y=210)
root.mainloop()
寫完整個課設之后才忽然想起來二分法雖然在時間效率上更優,但是其只是判斷檔案是否存在,最侄訓要去字典中找,而在字典中查找鍵值的時間遠低于二分查找,因此完全沒有必要再進行二分查找,(字典查找是根據哈希值進行查找其效率很高,理論上單純論查找復雜度:對于無沖突的Hash表而言,查找復雜度為O(1))
寫這篇博客距離課設結束已經過去了很久,很多問題也許考慮的不夠周全,歡迎各位指正,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/289410.html
標籤:其他