文章目錄
- 1 從矩陣的角度來理解Self-Attention的運作
- 2 進階版本:Multi-head Self-attention
- 3 通過Positional Encoding考慮輸入的位置資訊
- 4 Self-attention 的應用
- 4.1 Self-attention 在語音上的應用
- 4.2 Self-attention 在影像上的應用
- 4.3 Self-attention 可以替換 RNN
- 4.4 Self-attention 在圖神經網路上的應用
- 5 Self-Attention 的未來展望
1 從矩陣的角度來理解Self-Attention的運作
接下來我們從矩陣乘法的角度來看一下Self-Attention是如何運作的,
我們現在已經知道每一個 a a a 都產生一個對應的 q , k , v q, k, v q,k,v:
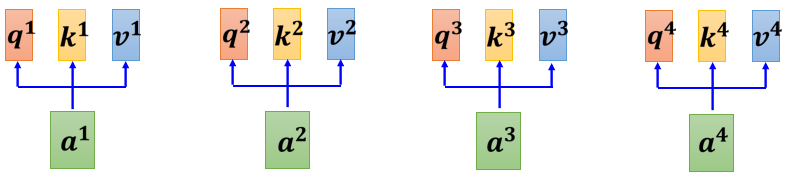
我們每一個 a a a 都要乘上一個矩陣 W q W^q Wq 來得到對應的 q i q^i qi ,這些不同的 a a a 其實合起來,當作一個矩陣來看待,這個矩陣我們用 I I I 來表示,這個 I I I 矩陣的四個 column 就是 a 1 a^1 a1 到 a 4 a^4 a4,
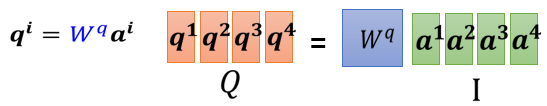
I I I 乘上 W q W^q Wq 就得到另外一個矩陣,我們用 Q Q Q 來表示它,這個 Q Q Q 矩陣的四個 column 就是 q 1 q^1 q1 到 q 4 q^4 q4 ,所以我們之前那個從 a 1 a^1 a1 到 a 4 a^4 a4,得到 q 1 q^1 q1 到 q 4 q^4 q4 的操作,看起來好像是分開計算的,但實際上就是把 I I I 這個矩陣,乘上矩陣 W q W^q Wq,得到矩陣 Q Q Q,所以說 q 1 q^1 q1 到 q 4 q^4 q4 其實是并行產生的,而** W q W^q Wq是 network 的引數,它是會被 learn 出來的**,
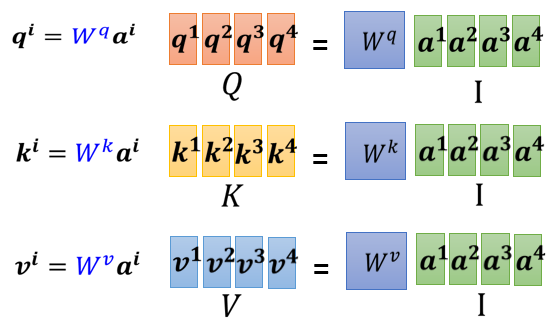
那事實上呢,我們把 I I I 分別乘上矩陣 W q , W k , W v W^q, W^k, W^v Wq,Wk,Wv 就能得到相應的 Q , K , V Q, K, V Q,K,V 矩陣,也就得到了 a 1 a^1 a1 到 a 4 a^4 a4 分別對應的 q , k , v q, k, v q,k,v,
下一步是,每一個 q q q 都會去跟每一個 k k k,去計算 inner product,也就是對應位置逐元素相乘后相加,從而得到 attention 的分數,就比如 q 1 q^1 q1 跟 k 1 k^1 k1 做 inner product 會得到 α 1 , 1 α_{1,1} α1,1?, q 1 q^1 q1 跟 k 2 k^2 k2 做 inner product 會得到 α 1 , 2 α_{1,2} α1,2?, 以此類推,
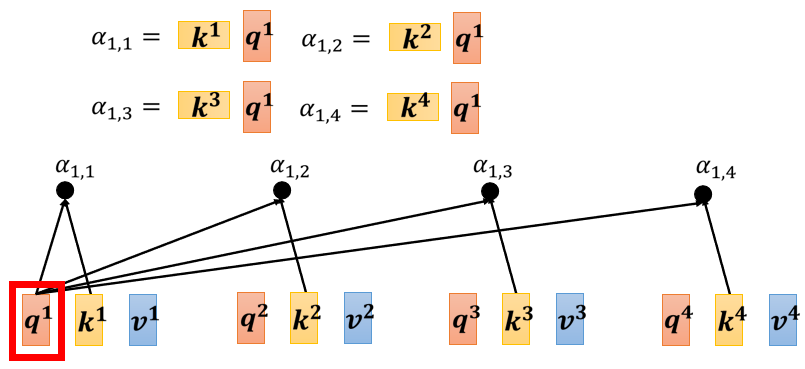
如果我們從矩陣運算的角度來看,這四個步驟的操作同樣可以拼起來,我們可以把把 k 1 k^1 k1 到 k 4 k^4 k4 拼起來,當作是一個矩陣的四個 row,然后把整個程序看作是矩陣跟向量相乘,
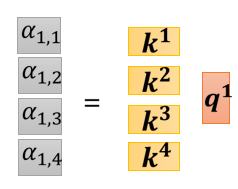
當然我們不只是 q 1 q^1 q1 要對 k 1 k^1 k1 到 k 4 k^4 k4 計算 attention 的分數, q 2 , q 3 , q 4 q^2,q^3,q^4 q2,q3,q4 也要對 k 1 k^1 k1 到 k 4 k^4 k4 計算 attention 的分數,所以其實我們也可以把把 q 1 q^1 q1 到 q 4 q^4 q4 拼起來,當作是一個矩陣的四個 column,所以這些 attention 的分數實際上可以看作是兩個矩陣的相乘,一個矩陣它的 row 就是 k 1 k^1 k1 到 k 4 k^4 k4,另外一個矩陣它的 column 就是 q 1 q^1 q1 到 q 4 q^4 q4 ,

我們會在 attention 的分數輸出之前做一下 normalization,比如說用 softmax,對 A A A 矩陣的每一個 column 做 softmax,讓每一個 column 里面的值相加是 1,這樣我們就得到了新的矩陣 A ′ A' A′,
同樣的,我們把 v 1 v^1 v1 到 v 4 v^4 v4 拼起來,當成是 V V V 這個矩陣的四個 column,然后接下來你把 V V V 乘上 A ′ A' A′ 的第一個 column 以后,得到的結果就是 b 1 b^1 b1:
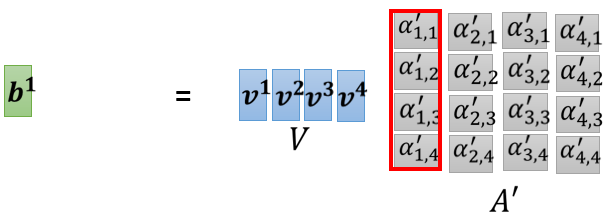
接下來就是以此類推得到剩下的 b 2 , b 3 , b 4 b^2,b^3,b^4 b2,b3,b4:
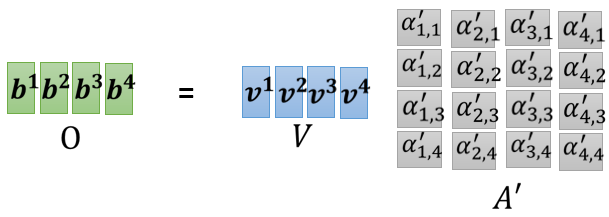
所以總的來看我們就是把 A ′ A' A′ 這個矩陣,乘上 V V V 這個矩陣,得到 O O O 這個矩陣, O O O 這個矩陣里面的每一個 column就是 Self-attention 的輸出,也就是 b 1 b^1 b1 到 b 4 b^4 b4,所以整個Self-attention的程序其實就是一連串矩陣的乘法而已,下圖是一個總結:
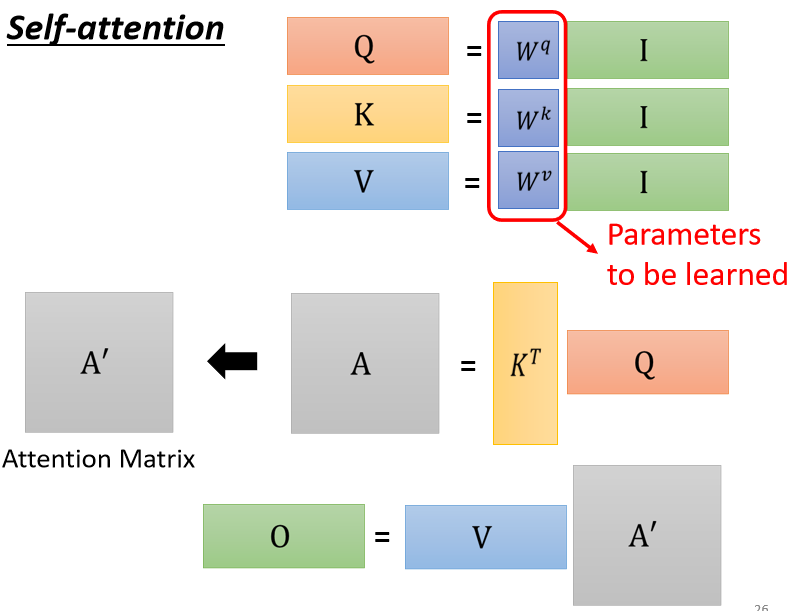
最后你會發現其實 Self-attention layer 里面,唯一需要學出來的引數就只有 W q W^q Wq W k W^k Wk W v W^v Wv 而已,
2 進階版本:Multi-head Self-attention
Self-attention 有一個進階的版本,叫做 Multi-head Self-attention, 這個進階版本今天的使用也是非常廣泛的,所謂的多個head,其實就是對于每一個輸入的向量,可以有不止一個query,因為我們在做 Self-attention 的時候,就是用 q q q 去找相關的 k k k,但是相關這件事情有很多種不同的形式,有很多種不同的定義,所以也許我們不能只有一個 q q q,我們應該要有多個 q q q,不同的 q q q 負責不同種類的相關性,
至于我們需要用多少個 head,這個又是另外一個 hyperparameter,也是需要我們自己根據具體任務進行調整的,所以假設你要做 Multi-head Self-attention 的話,該如何操作呢?這里舉一個有兩個head的例子:
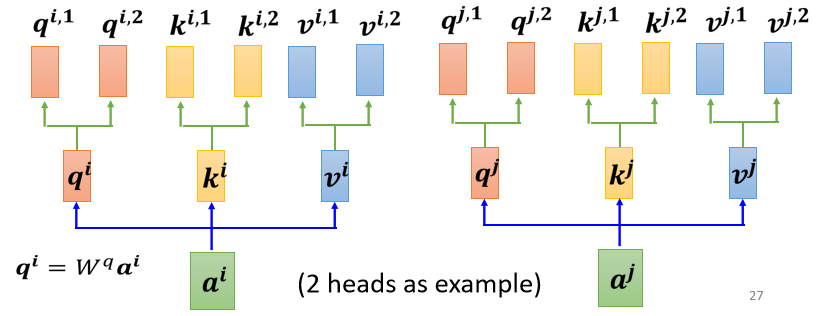
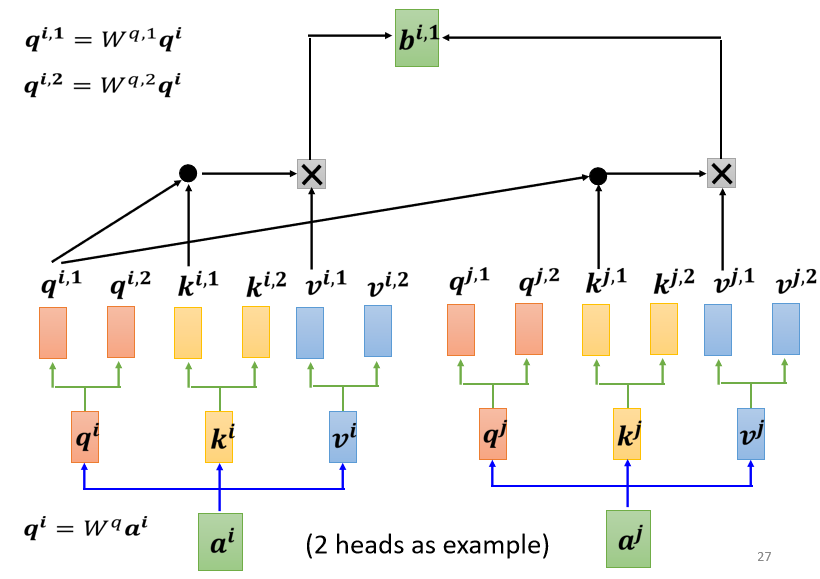
我們認為當前要處理的問題里面有兩種不同的相關性,所以我們需要產生兩種不同的 head,來分別尋找兩種不同的相關性,我們來看其中的兩個輸入 a i a j a^i a^j aiaj,對于 a i a^i ai 來說,產生對應的 q i , k i , v i q_i, k_i, v_i qi?,ki?,vi? 的步驟跟之前不是 Multi-head 時的情況一樣,也就是 a i a^i ai 分別乘上矩陣 W q , W k , W v W^q,W^k,W^v Wq,Wk,Wv ,但接下來我們還需要將 q i q_i qi? 乘上另外兩個矩陣得到 q i , 1 q^{i,1} qi,1 和 q i , 2 q^{i,2} qi,2,這里的兩個上標中, i i i 代表的是位置,然后這個 1 跟 2 代表的是這個位置的第幾個 q q q,
那既然 q q q 有兩個, k k k 和 v v v 也要有兩個,從 q q q 得到 q 1 q 2 q^1 q^2 q1q2,從 k k k 得到 k 1 k 2 k^1 k^2 k1k2,從 v v v 得到 v 1 v 2 v^1 v^2 v1v2,其實接下來的程序與之前不是 Multi-head 時是完全一樣的,只是因為現在我們的在算 Attention 的分數時,我們的 q , k , v q, k, v q,k,v 都有兩份,所以計算的輸出 b b b 也有兩份,在計算 b i , 1 b^{i,1} bi,1 時,就只看 q i , 1 , k i , 1 , v i , 1 q^{i,1},k^{i,1},v^{i,1} qi,1,ki,1,vi,1:
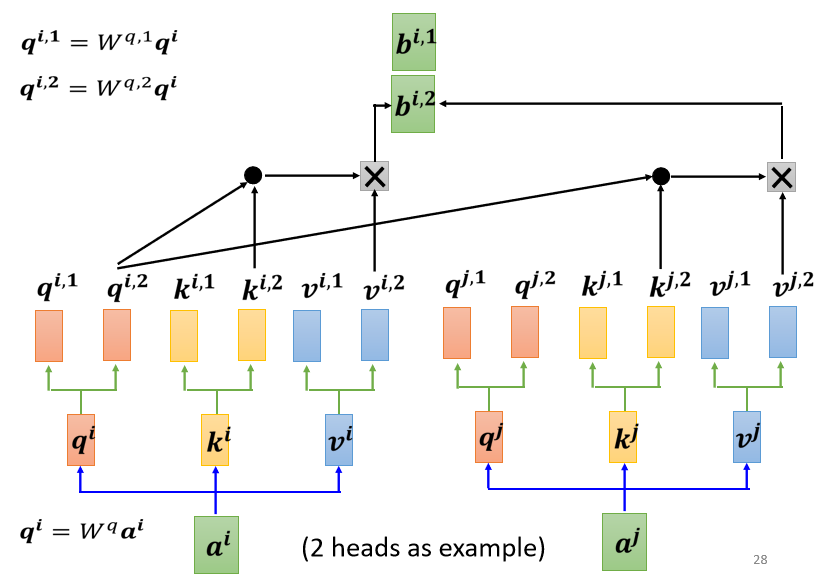
而在計算 b i , 2 b^{i,2} bi,2 時,就只看 q i , 2 , k i , 2 , v i , 2 q^{i,2},k^{i,2},v^{i,2} qi,2,ki,2,vi,2:
然后接下來我們可能會把 b i , 1 b^{i,1} bi,1 跟 b i , 2 b^{i,2} bi,2 拼起來,再乘上一個矩陣,得到我們最終的輸出 b i b_i bi?,這就是 Multi-head attention 的整個運作程序,
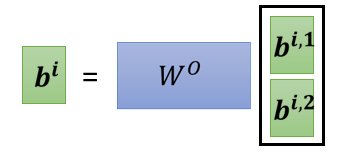
3 通過Positional Encoding考慮輸入的位置資訊
那到目前位置,其實你會發現對 Self-attention 而言,位置 1 跟位置 2,3,4完全沒有任何差別,這四個位置的操作其實是一模一樣,對它來說 q1 到跟 q4 的距離,并沒有特別遠,2 跟 3 的距離也沒有特別近,
但是這樣的設計可能會有一些問題,因為有時候位置的資訊也許很重要,舉例來說,我們在做 POS tagging,就是詞性標記的時候,我們知道動詞比較不容易出現在句首,所以如果我們知道某一個詞匯它是放在句首的,那它是動詞的可能性可能就比較低,
那我們要怎樣把位置的資訊加到我們的輸入中呢,這里就會用到一個叫做 positional encoding 的技術,
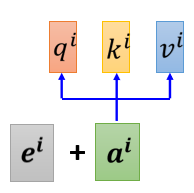
我們為每一個位置設定一個 vector,叫做 positional vector,用 e i e^i ei 來表示,上標 i i i 代表是位置,不同的位置都有一個它專屬的 e e e,然后把這個 e e e 加到 a i a^i ai 上面,就結束了,這就是告訴你的 Self-attention 的Network,如果它看到說 a i a^i ai 好像有被加上 $ e^i$,它就知道說現在的輸入 a i a^i ai 應該是在 i i i 這個位置出現的,
Attention Is All You Need 那篇 paper 里面,使用的 e i e^i ei 是下面這個樣子:
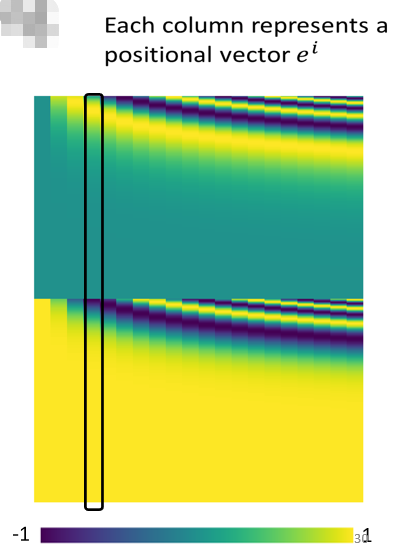
這個圖上每一個 column 就代表一個 e e e,第一個位置就是 e 1 e^1 e1,第二個位置就是 e 2 e^2 e2,第三個位置就是 e 3 e^3 e3,以此類推,這樣的 positional vector,是人為設定的,但既然是人設的那就會存在一些問題,就比如我在設計這個 positional vector 的時候只設計了128個位置,那對于長度為 129的 sequence 來說就會有問題,所以我們需要探尋一個規則來產生這個 positional vector,這個規則就是所謂的 positional encoding,
positional encoding 仍然是一個尚待研究的問題,你可以創造自己新的方法,甚至可以把 positional encoding 作為一個Network的引數,是根據資料學出來的,
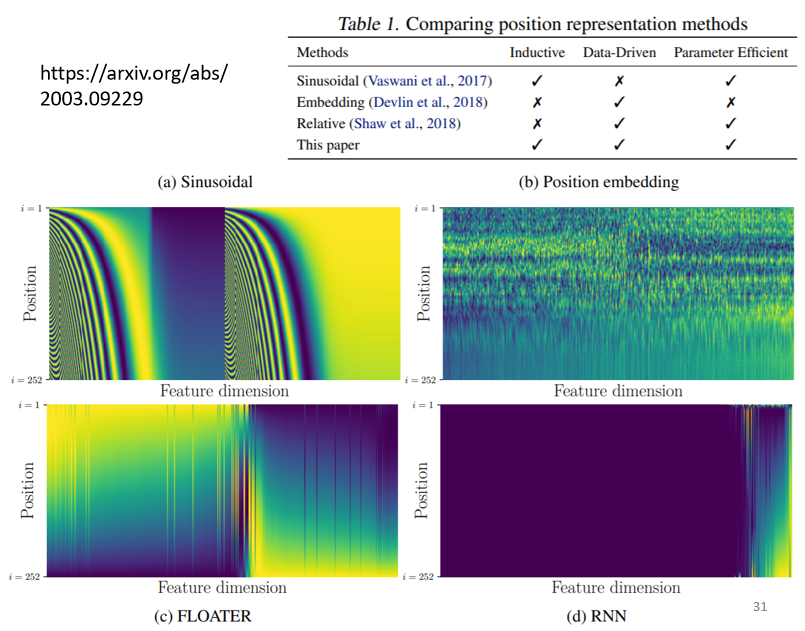
至于這個 positional encoding 的方法有很多,其中一篇可以參考的文獻: Learning to Encode Position for Transformer with Continuous Dynamical Model (arxiv.org),總之這是仍然是一個尚待研究的問題,你永遠可以提出新的做法,
4 Self-attention 的應用
Self-attention 的應用是非常廣泛的,我們之前已經提過很多次 transformer 這個東西:

那大家也都知道,在 NLP 的領域有一個東西叫做BERT,這個BERT我們后面會詳細介紹,BERT里面也用到了 Self-attention,所以 Self-attention 在 NLP 上面的應用是大家耳熟能詳的,但 Self-attention不是只能用在 NLP 相關的應用上,它還可以用在很多其他的問題上,
4.1 Self-attention 在語音上的應用
在做語音識別相關的應用時,我們也可以用 Self-attention 來做,不過要把一段聲音訊號表示成一排向量的話,這排向量可能會非常地長,

在聲音訊號的處理程序中,一般我們每一個向量只代表了 10 millisecond 的長度而已,所以如果今天是 1 秒鐘的聲音訊號,它就有 100 個向量了,隨便講一句話,都是上千個向量了,那表示聲音訊號的向量過長會帶來什么問題呢?我們其實知道在計算 attention matrix 的時候,它的計算復雜度是矩陣長度L的平方,那如果這個L的值很大,它的計算量就很可觀,也需要非常大的memory,才能夠把這個矩陣存下來,
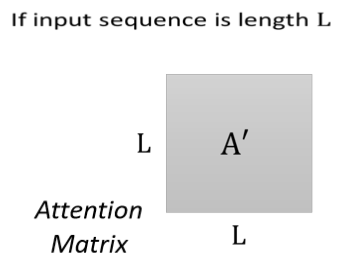
所以在用Self-attention做語音識別的時候,有一招叫做 Truncated Self-attention,
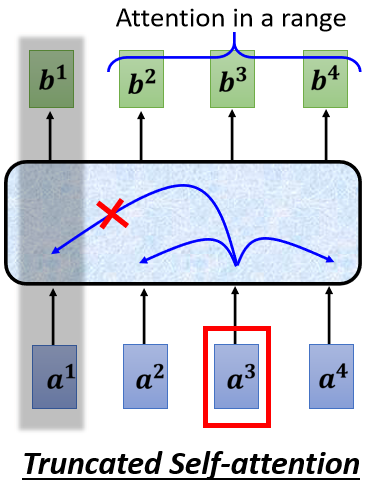
Truncated Self-attention 就是我們今天在做 Self-attention 的時候,**不要需要看完一整句話,而是只看一個小的范圍就好,至于這個范圍是多大則是人為設定的,**這樣就能夠在語音處理這種輸入的向量很大的情況下,加快運算的速度,
那你可能要問之前提出 Self-attention 就是因為需要考慮整個Sequence的資訊,這里憑什么就可以只看一個小范圍的資訊呢?這也是與語音識別本身的特性有關的,也許我們要辨識某個位置的音素是什么,某個位置有怎樣的內容,大部分情況下我們并不需要看完整句話,而是只要看目標位置跟它前后一定范圍之內的資訊就可以判斷,總而言之,對于網路結構的選取和設計,一直都是具體問題具體分析,絕不是一成不變的,
4.2 Self-attention 在影像上的應用
一張圖片,在講到CNN的時候,我們把它看作是一個很長的向量,那其實一張圖片,我們也可以換一個觀點,把它看作是一個 vector set,

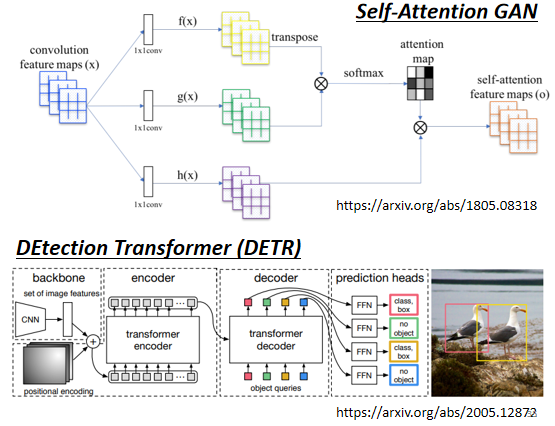
上面這個示例中的圖片是一個決議度 5 × 10,channel為3的圖片,你可以把每一個位置的 pixel,看作是一個三維的向量,所以整張圖片其實就是 5 × 10個向量的set,這樣一來,我們應該也可以用 Self-attention 來處理圖片了,事實上也已經有了很多把 Self-attention 用在影像處理上的作業,這里放兩篇Paper的鏈接供參考:
-
Self-Attention Generative Adversarial Networks (arxiv.org)
-
End-to-End Object Detection with Transformers (arxiv.org)
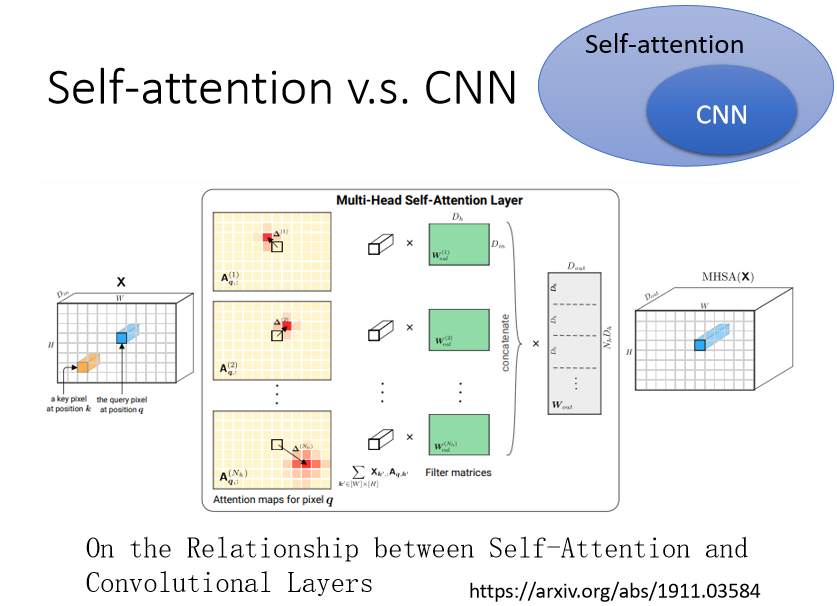
接下來我們來比較一下,Self-attention 跟 CNN 之間有什么樣的差異或者是關聯性,
如果我們用 Self-attention 來處理一張圖片,這就是說假設其中某一個pixel使我們要考慮的,那它自己需要產生 query,其他所有的 pixel 都要產生key,并與其計算一個attention的分數,這也就是說,我們對每一個像素點的處理都考慮到了整張圖片的資訊,
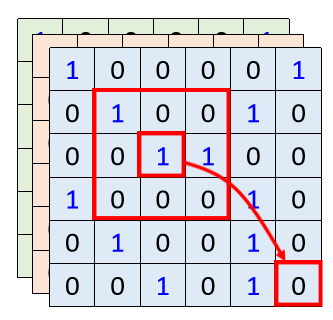
但是我們在做 CNN 的時候,會設定一個 receptive field,每一個 filter,每一個 neural,都只考慮它自己的 receptive field 范圍內的資訊,
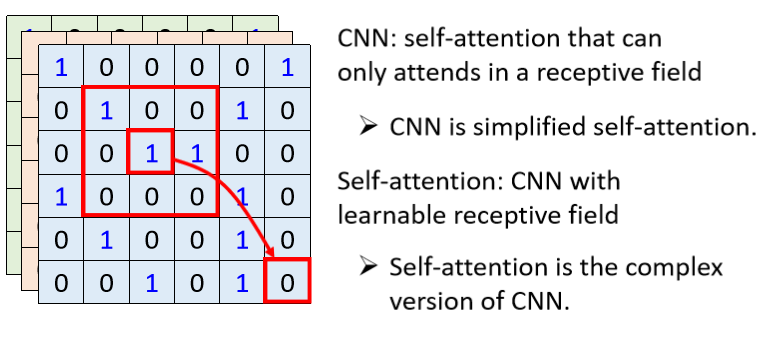
所以事實上,CNN 可以看作是一種簡化版的 Self-attention,反過來說,Self-attention 是一個復雜化的 CNN,
在 CNN 里面,我們要人為劃定 receptive field 的大小和范圍,而對 Self-attention 而言,我們用 attention 去找出相關的 pixel,就好像是 receptive field 是自動被學出來的,network 自己決定說,receptive field 的形狀長什么樣子,哪些 pixel 是我們真正需要考慮的,所以在 Self-attention 下 receptive field 的范圍不再是人工劃定,而是讓機器自己學出來,
On the Relationship between Self-Attention and Convolutional Layers (arxiv.org),這篇論文的作者在他的文章中就闡明了這個觀點,并且用數學的方式嚴謹的告訴你說,其實CNN 就是 Self-attention 的特例,Self-attention 只要設定合適的引數,它可以做到跟 CNN 一模一樣的事情,
所以 Self-attention 是彈性更大的 CNN,而 CNN 是受限制的 Self-attention,那之前就已經說過彈性比較大 的 model,訓練的時候需要更多的 data,并且 overfitting 的風險更大,
下面這個例子證實了剛剛的說法,下圖的實驗結果來自這篇文章: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (arxiv.org)
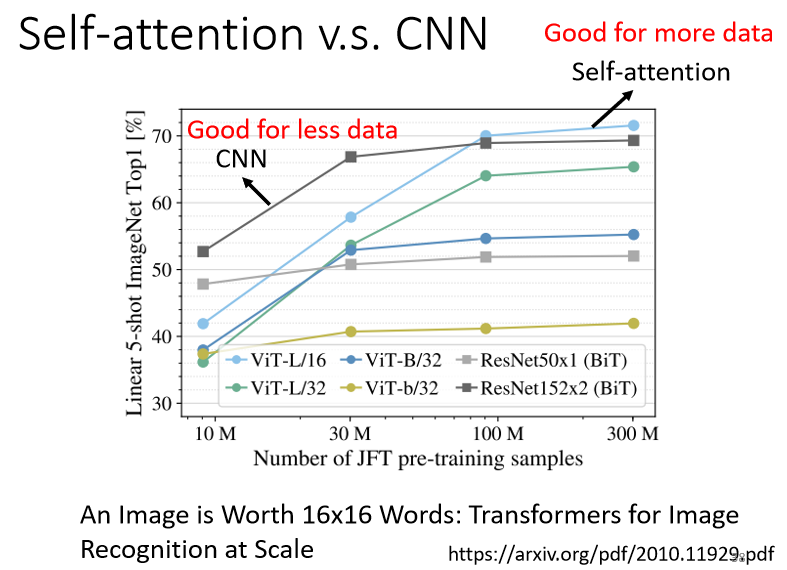
橫軸是訓練集的資料量,從10M到300M,Self-attention 是淺藍色的這一條線,而 CNN 是深灰色的這條線,可以看到,隨著資料量越來越多,Self-attention 的結果就越來越好,最終在資料量達到300M的時候,Self-attention 的表現可以超過 CNN,但在資料量少的時候,CNN 的表現比 Self-attention 好很多,
這個結果可以從 CNN 跟 Self-attention 的彈性大小來解釋:
- Self-attention 的彈性比較大,所以需要比較多的訓練資料,訓練資料少的時候容易 overfitting 導致結果不好,而訓練資料足夠的情況下結果會比較好,
- CNN 彈性比較小,在訓練資料少的時候結果比較好,但訓練資料多的時候,它沒有辦法從更大量的訓練資料得到好處,
4.3 Self-attention 可以替換 RNN
我們來比較一下 Self-attention 跟 RNN,RNN就是 recurrent neural network(回圈神經網路),目前看來, RNN的角色很大一部分都可以用 Self-attention 來取代了,
至于 RNN 是什么可以參考這篇文章:一文搞懂RNN(回圈神經網路)基礎篇 - 知乎 (zhihu.com),這里只是簡單介紹一下,RNN 跟 Self-attention 一樣,都是要處理 input 是一個 sequence 的狀況,
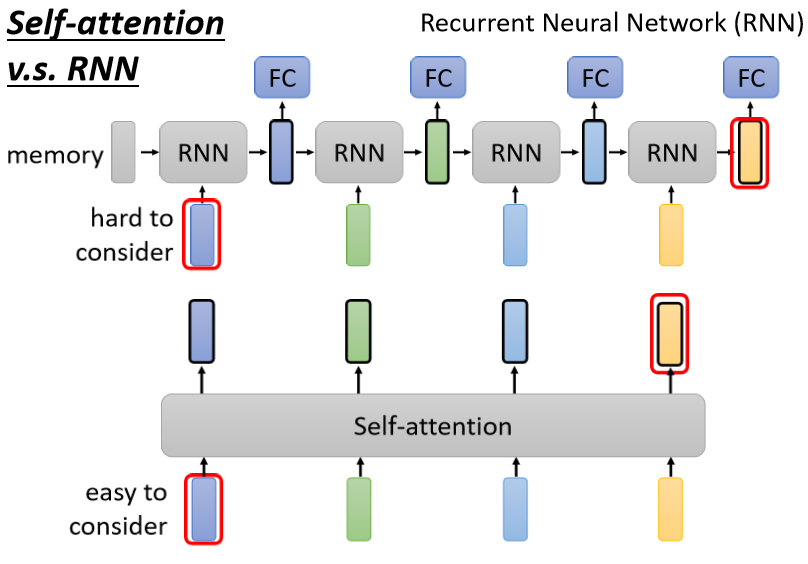
那 Self-attention 跟 RNN 有什么不同呢?
一個顯而易見的不同是,對于 Self-attention,輸出的每一個 vector都考慮了整個 input 的 sequence,而 RNN 輸出的每一個 vector只考慮了左邊已經輸入的 vector,但是 RNN 也可以是雙向的,所以如果用 bidirectional 的 RNN,那每一個輸出的vector也可以看作是考慮了整個 input 的 sequence,
但是比較兩者的 output 產生的程序,就算是用 bidirectional 的 RNN,仍然存在差別:
-
對 RNN 來說,假設最右邊這個輸出的黃色的 vector 與最左邊的這個輸入相關性很大,那它必須要把最左邊的輸入存在 memory 里面,然后接下來都不能夠忘掉,一路帶到最右邊,這樣才能夠在最后一個時間點被考慮,
-
但對 Self-attention 來說沒有這個問題,它只要這邊輸出一個 query,另一邊輸出一個 key,只要它們 match 的相關性很大,就可以很輕易地從非常遠的 vector 上抽取資訊,所以這是 RNN 跟 Self-attention 一個不一樣的地方,
另外一個更主要的不同是,RNN 在處理的程序中是沒有辦法并行化的,因為每一個 RNN 模塊的輸入都依賴上一個時刻 RNN 模塊的輸出,但之前我們就提到過 Self-attention 是可以并行處理所有輸入的,**輸出的四個 vector 是并行產生的,并不需要等誰先運算完才能把其他運算出來,**所以在運算速度上,Self-attention 會比 RNN 更有效率,這是 Self-attention 相較于 RNN 一個非常大的優勢,
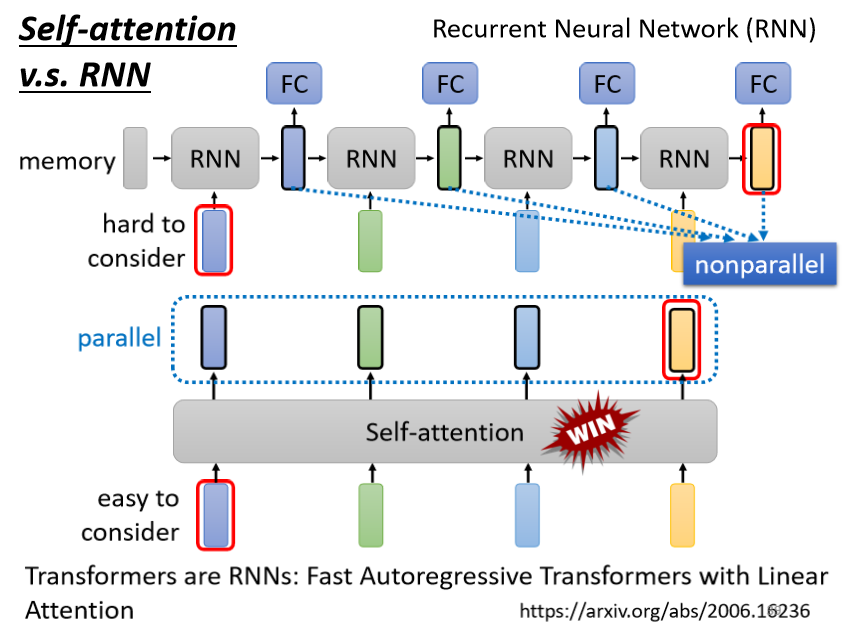
所以你會發現如今很多的應用都把 RNN 的架構,逐漸改成 Self-attention 的架構了,
4.4 Self-attention 在圖神經網路上的應用
Graph 也可以看作是一堆 vector,那如果是一堆 vector,就可以用 Self-attention 來處理,但是當我們把 Self-attention用在Graph 上面的時候,又有什么特別的地方呢?
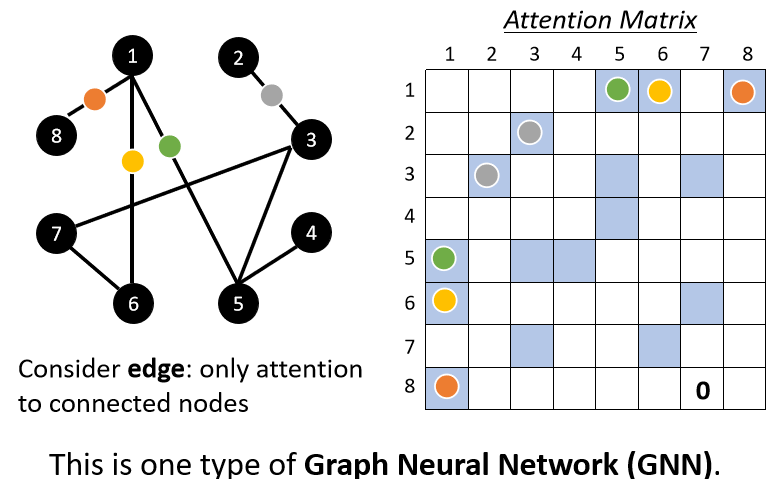
在 Graph 上面,每一個 node 可以表示成一個向量,但不只有 node 的資訊,還有 edge 的資訊,我們知道哪些 node 之間是有相連的,也就是哪些 node 是有關聯的,
既然我們已經知道哪些向量間是有關聯的,之前我們在做 Self-attention 的時候,所謂的關聯性是需要 network 自己找出來的,但是現在已經有了 edge 的資訊,這個圖上面的 edge 已經暗示了我們 node 跟 node 之間的關聯性,
所以在我們把 Self-attention 用在 Graph 上面的時候,有一個選擇是在做 Attention Matrix 計算的時候,可以只計算有 edge 相連的 node 就好,如果兩個 node 之間沒有相連,那其實很有可能就暗示我們這兩個 node 之間沒有關系,既然沒有關系,我們就不需要再去計算它們的 attention score,直接設為 0 即可,
5 Self-Attention 的未來展望
其實 Self-attention 有非常多的變種,你可以看一篇 paper 叫做 Long Range Arena: A Benchmark for Efficient Transformers (arxiv.org),里面比較了各種不同的 Self-attention 的變種:
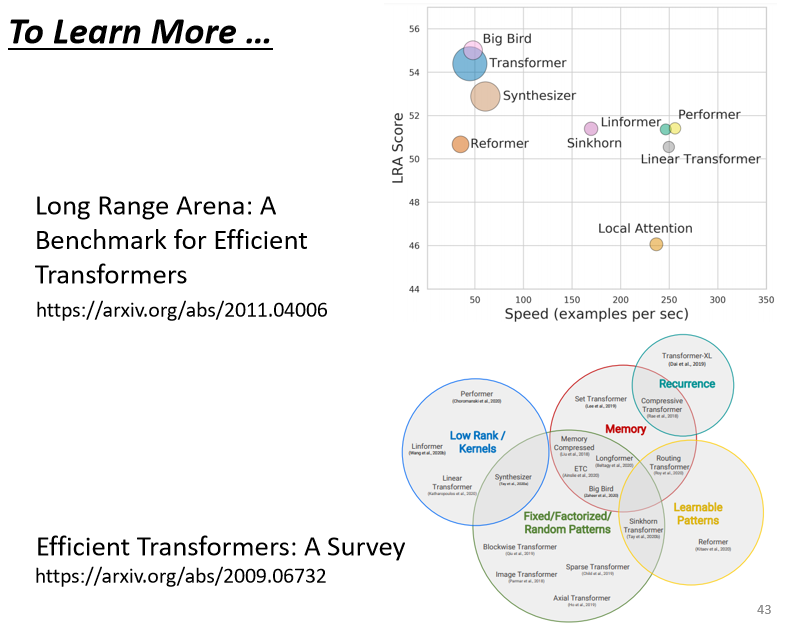
因為 Self-attention 最大的問題就是它的運算量非常地大,所以怎樣減少 Self-attention 的運算量,是一個未來的重點,到底什么樣的 Self-attention 才能夠真的又快又好,這仍然是一個尚待研究的問題,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/289436.html
標籤:AI