一、根節點列舉
上一篇文章已經介紹過GC Roots了,那么如何在GC Roots找到參考鏈的呢
我們以可達性分析演算法中從GC Roots集合找參考鏈這個操作作為介紹虛擬機高效實作的第一個例子,固定可作為GC Roots的節點主要在全域性的參考(例如常量或類靜態屬性)與執行背景關系(例如堆疊幀中的本地變數表)中,盡管目標明確,但查找程序要做到高效并非一件容易的事情,現在Java應 用越做越龐大,光是方法區的大小就常有數百上千兆,里面的類、常量等更是恒河沙數,若要逐個檢查以這里為起源的參考肯定得消耗不少時間,
迄今為止,所有收集器在根節點列舉這一步驟時都是必須暫停用戶執行緒的,因此毫無疑問根節點列舉與之前提及的整理記憶體碎片一樣會面臨相似的“Stop The World”的困擾
由于目前主流Java虛擬機使用的都是準確式垃圾收集,所以當用戶執行緒停頓下來之后,其實并不需要一個不漏地檢查完所有 執行背景關系和全域的參考位置,虛擬機應當是有辦法直接得到哪些地方存放著物件參考的,在HotSpot 的解決方案里,是使用一組稱為OopMap的資料結構來達到這個目的,一旦類加載動作完成的時候, HotSpot就會把物件內什么偏移量上是什么型別的資料計算出來,在即時編譯程序中,也會在特定的位置記錄下堆疊里和暫存器里哪些位置是參考,這樣收集器在掃描時就可以直接得知這些信 息了,并不需要真正一個不漏地從方法區等GC Roots開始查找
二、安全點
1.概述
在OopMap的協助下,HotSpot可以快速準確地完成GC Roots列舉,但一個很現實的問題隨之而來:可能導致參考關系變化,或者說導致OopMap內容變化的指令非常多,如果為每一條指令都生成 對應的OopMap,那將會需要大量的額外存盤空間,這樣垃圾收集伴隨而來的空間成本就會變得無法 忍受的高昂,
實際上HotSpot也的確沒有為每條指令都生成OopMap,前面已經提到,只是在“特定的位置”記錄了這些資訊,這些位置被稱為安全點(Safepoint),有了安全點的設定,也就決定了用戶程式執行時 并非在代碼指令流的任意位置都能夠停頓下來開始垃圾收集,而是強制要求必須執行到達安全點后才 能夠暫停,
2.安全點設定的原則
GC的目的是幫助我們回收不再使用的記憶體,在多執行緒環境下這種回收將會變得非常復雜,要安全地回收需要滿足一下兩個條件:
1.堆記憶體的變化是受控制的,最好所有的執行緒全部停止,
2.堆中的物件是已知的,不存在不再使用的物件很難找到或者找不到即堆中的物件狀態都是可知的,
3.搶占式、主動式
對于安全點,另外一個需要考慮的問題是,如何在垃圾收集發生時讓所有執行緒(這里其實不包括
執行JNI呼叫的執行緒)都跑到最近的安全點,然后停頓下來,這里有兩種方案可供選擇:搶先式中斷 (Preemptive Suspension)和主動式中斷(Voluntary Suspension),
(1)搶先式中斷
不需要執行緒的執行代碼 主動去配合,在垃圾收集發生時,系統首先把所有用戶執行緒全部中斷,如果發現有用戶執行緒中斷的地方不在安全點上,就恢復這條執行緒執行,讓它一會再重新中斷,直到跑到安全點上,現在幾乎沒有虛 擬機實作采用搶先式中斷來暫停執行緒回應GC事件,
(2)主動式中斷
思想是當垃圾收集需要中斷執行緒的時候,不直接對執行緒操作,僅僅簡單地設定一個標志位,各個執行緒執行程序時會不停地主動去輪詢這個標志,一旦發現中斷標志為真時就自己在最近的安全點上主動中斷掛起,輪詢標志的地方和安全點是重合的,另外還要加上所有創建物件和其他 需要在Java堆上分配記憶體的地方,這是為了檢查是否即將要發生垃圾收集,避免沒有足夠記憶體分配新物件
4.安全點設定位置
HostSop虛擬機采用的是主動式使執行緒中斷,那么應該在什么地方設定全域變數呢?顯然不能隨意設定全域變數,進入安全點有個默認策略那就是:“避免程式長時間運行而不進入Safe Point”,程式要GC了必須要等執行緒進入安全點,如果執行緒長時間不進入安全點這樣就比較糟糕了,因此安全點主要咋以下位置設定:
(1)回圈的末尾
(2)方法回傳前
(3)呼叫方法的call之后
(4)拋出例外的位置
三.安全區域
安全點完美的解決了如何進入GC問題,實際情況可能比這個更復雜,但是如果程式長時間不執行,比如執行緒呼叫的sleep方法,這時候程式無法回應JVM中斷請求這時候執行緒無法到達安全點,顯然JVM也不可能等待程式喚醒,這時候就需要安全區域了,
安全區域是指能夠確保在某一段代碼片段之中,參考關系不會發生變化,因此,在這個區域中任
意地方開始垃圾收集都是安全的,我們也可以把安全區域看作被擴展拉伸了的安全點,
當用戶執行緒執行到安全區域里面的代碼時,首先會標識自己已經進入了安全區域,那樣當這段時
間里虛擬機要發起垃圾收集時就不必去管這些已宣告自己在安全區域內的執行緒了,當執行緒要離開安全 區域時,它要檢查虛擬機是否已經完成了根節點列舉(或者垃圾收集程序中其他需要暫停用戶執行緒的 階段),如果完成了,那執行緒就當作沒事發生過,繼續執行;否則它就必須一直等待,直到收到可以 離開安全區域的信號為止,
四、記憶集與卡表
上篇文章提到過部分垃圾回收器是分代回收的,既然將java堆分成不同的代那么必然會存在跨代參考的問題所以垃圾收集器在新生代中建 立了名為記憶集(Remembered Set)的資料結構,用以避免把整個老年代加進GC Roots掃描范圍,事 實上并不只是新生代、老年代之間才有跨代參考的問題,所有涉及部磁區域收集(Partial GC)行為的
垃圾收集器,典型的如G1、ZGC和Shenandoah收集器,都會面臨相同的問題,因此我們有必要進一步理清記憶集的原理和實作方式
1.記憶集
記憶集是一種用于記錄從非收集區域指向收集區域的指標集合的抽象資料結構,如果我們不考慮
效率和成本的話,最簡單的實作可以用非收集區域中所有含跨代參考的物件陣列來實作這個資料結
構
Class RememberedSet {
Object[] set[OBJECT_INTERGENERATIONAL_REFERENCE_SIZE];
}
這種記錄全部含跨代參考物件的實作方案,無論是空間占用還是維護成本都相當高昂,而在垃圾
收集的場景中,收集器只需要通過記憶集判斷出某一塊非收集區域是否存在有指向了收集區域的指標 就可以了,并不需要了解這些跨代指標的全部細節,那設計者在實作記憶集的時候,便可以選擇更為 粗獷的記錄粒度來節省記憶集的存盤和維護成本,下面列舉了一些可供選擇(當然也可以選擇這個范圍以外的)的記錄精度:
(1)字長精度:每個記錄精確到一個機器字長(就是處理器的尋址位數,如常見的32位或64位,這個精度決定了機器訪問物理記憶體地址的指標長度),該字包含跨代指標,
(2)物件精度:每個記錄精確到一個物件,該物件里有欄位含有跨代指標,
(3)卡精度:每個記錄精確到一塊記憶體區域,該區域內有物件含有跨代指標
2.卡表
上面說到的第三種“卡精度”所指的是用一種稱為“卡表”(Card Table)的方式去實作記憶集,這也是 目前最常用的一種記憶集實作形式,一些資料中甚至直接把它和記憶集混為一談,前面定義中提到記憶集其實是一種“抽象”的資料結構,抽象的意思是只定義了記憶集的行為意圖,并沒有定義其行為的 具體實作,卡表就是記憶集的一種具體實作,它定義了記憶集的記錄精度、與堆記憶體的映射關系等,
卡表最簡單的形式可以只是一個位元組陣列,而HotSpot虛擬機確實也是這樣做的,以下這行代
碼是HotSpot默認的卡表標記邏輯
CARD_TABLE [this address >> 9] = 0;
位元組陣列CARD_TABLE的每一個元素都對應著其標識的記憶體區域中一塊特定大小的記憶體塊,這個
記憶體塊被稱作“卡頁”(Card Page),一般來說,卡頁大小都是以2的N次冪的位元組數,通過上面代碼可 以看出HotSpot中使用的卡頁是2的9次冪,即512位元組(地址右移9位,相當于用地址除以512)
一個卡頁的記憶體中通常包含不止一個物件,只要卡頁內有一個(或更多)物件的欄位存在著跨代
指標,那就將對應卡表的陣列元素的值標識為1,稱為這個元素變臟(Dirty),沒有則標識為0,在垃 圾收集發生時,只要篩選出卡表中變臟的元素,就能輕易得出哪些卡頁記憶體塊中包含跨代指標,把它們加入GC Roots中一并掃描,
五、寫屏障
1.概述
我們已經解決了如何使用記憶集來縮減GC Roots掃描范圍的問題,但還沒有解決卡表元素如何維
護的問題,例如它們何時變臟、誰來把它們變臟等,所以HotSpot通過寫屏障(write barrier)來維護卡表
“寫屏障”這個詞雖然看起來高深,但是它的含義卻相當naive——就是對一個物件參考進行寫操作(即參考賦值)之前或之后附加執行的邏輯,相當于為參考賦值前后加了一層aop,這樣就可以維護卡表了,
2.偽共享
卡表在高并發場景下還面臨著“偽共享”(False Sharing)問題,偽共享是處
理并發底層細節時一種經常需要考慮的問題,現代中央處理器的快取系統中是以快取行(Cache Line) 為單位存盤的,當多執行緒修改互相獨立的變數時,如果這些變數恰好共享同一個快取行,就會彼此影響(寫回、無效化或者同步)而導致性能降低,這就是偽共享問題,
六、并發的可達性分析-三色標記法
1.概述
前面文章中曾經提到了當前主流編程語言的垃圾收集器基本上都是依靠可達性分析演算法來判定物件 是否存活的,可達性分析演算法理論上要求全程序都基于一個能保障一致性的快照中才能夠進行分析, 這意味著必須全程凍結用戶執行緒的運行,在根節點列舉這個步驟中,由于GC Roots相比起整個Java堆中全部的物件畢竟還算是極少數,且在各種優化技巧(如OopMap)的加持下,它帶來 的停頓已經是非常短暫且相對固定(不隨堆容量而增長)的了,
可從GC Roots再繼續往下遍歷物件 這一步驟的停頓時間就必定會與Java堆容量直接成正比例關系了:堆越大,存盤的物件越多,物件圖結構越復雜,要標記更多物件而產生的停頓時間自然就更長,這聽起來是理所當然的事情, 而三色標記法可以優化這部分的耗時
2.垃圾回收的原則
(1)可以把是垃圾的遺漏
(2)不可以把不是垃圾的回收
3.基本實作
(1)白色:
表示物件尚未被垃圾收集器訪問過,顯然在可達性分析剛剛開始的階段,所有的物件都是白色的,若在分析結束的階段,仍然是白色的物件,即代表不可達,
(2)黑色:表示物件已經被垃圾收集器訪問過,且這個物件的所有參考都已經掃描過,黑色的物件代 表已經掃描過,它是安全存活的,如果有其他物件參考指向了黑色物件,無須重新掃描一遍,黑色對 象不可能直接(不經過灰色物件)指向某個白色物件,
(3)灰色:表示物件已經被垃圾收集器訪問過,但這個物件上至少存在一個參考還沒有被掃描過,
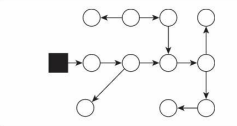
初始狀態:
中間狀態:
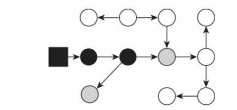
最終狀態:
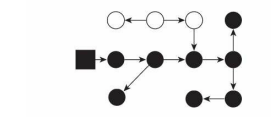
由圖所示是關于可達性分析的掃描程序,其實就是黑向白推進的程序,灰色收集程序中的中間狀態,最終狀態是只有黑和白,白色是可以被回收的黑色是不可被回收的,如果用戶執行緒此時是凍結的,只有收集器執行緒在作業,那不會有任何問題,但如果用戶執行緒與收集器是并發作業呢?
4.產生不是垃圾的回收的條件
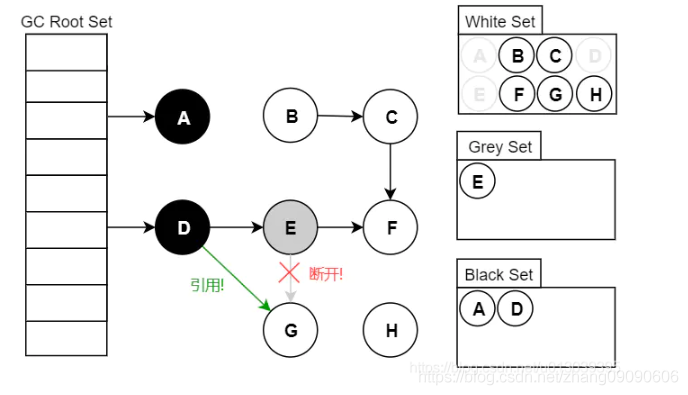
如圖所示情況在收集程序中斷開了全部參考G的灰色節點參考,并且建立了黑色節點D的參考,此時因為黑色表示子節點全部被收集了所以不會再掃描,而與全部灰色節點的參考全部斷開了所以該白色節點永遠也無法被掃描到,這就導致最終態該白色物件雖然存在參考不是垃圾但是還是被回收掉,綜上所訴把不是垃圾回收掉必須滿足以下兩個條件
(1)在收集程序中賦值器插入了一潭訓多條從黑色物件到白色物件的新參考
(2)在收集程序中賦值器洗掉了全部從灰色物件到該白色物件的直接或間接參考
這兩個條件只需破壞一個就可以避免,所以,由此分別 產生了兩種解決方案:增量更新(Incremental Update)和原始快照(Snapshot At The Beginning,SATB),
5.增量更新
增量更新要破壞的是第一個條件,當黑色物件插入新的指向白色物件的參考關系時,就將這個新
插入的參考記錄下來,等并發掃描結束之后,再將這些記錄過的參考關系中的黑色物件為根,重新掃描一次,這可以簡化理解為,黑色物件一旦新插入了指向白色物件的參考之后,它就變回灰色物件 了,
6.原始快照
原始快照要破壞的是第二個條件,當灰色物件要洗掉指向白色物件的參考關系時,就將這個要刪
除的參考記錄下來,在并發掃描結束之后,再將這些記錄過的參考關系中的灰色物件為根,重新掃 一次,這也可以簡化理解為,無論參考關系洗掉與否,都會按照剛剛開始掃描那一刻的物件圖快照來 進行搜索,
7.總結
以上無論是對參考關系記錄的插入還是洗掉,虛擬機的記錄操作都是通過寫屏障實作的,在 HotSpot虛擬機中,增量更新和原始快照這兩種解決方案都有實際應用,譬如,CMS是基于增量更新來做并發標記的,G1、Shenandoah則是用原始快照來實作,