文章目錄
- 前言
- 第一步:正向傳播激活神經網路
- A.變數說明
- B.正向傳播
- C.偏置單元
- 第二步:誤差逆向傳播
- 1.損失函式
- 2.哈達瑪積(Hadamard product)
- 3.理解誤差逆向傳播
- 4.關于偏置項的梯度
- 5.誤差逆向傳播公式總結
- 5.梯度檢測
- 6.初始化的重要性
- 7.代碼實作
- 總結
前言
BP神經網路(Back propagation neural network)全稱為多層前饋神經網路,其用于解決非線性問題,整個神經網路的步驟為:輸入層接收外界的輸入,隱藏層和輸出層的神經元對輸入的特征或信號通過權重矩陣進行加工,最終輸出結果,程序中最重要的是獲得加工所要的權重,本質上說神經網路的學習程序就是在學習神經元與神經元之間連接的權重,
提示:以下是本篇文章正文內容,下面案例可供參考
第一步:正向傳播激活神經網路
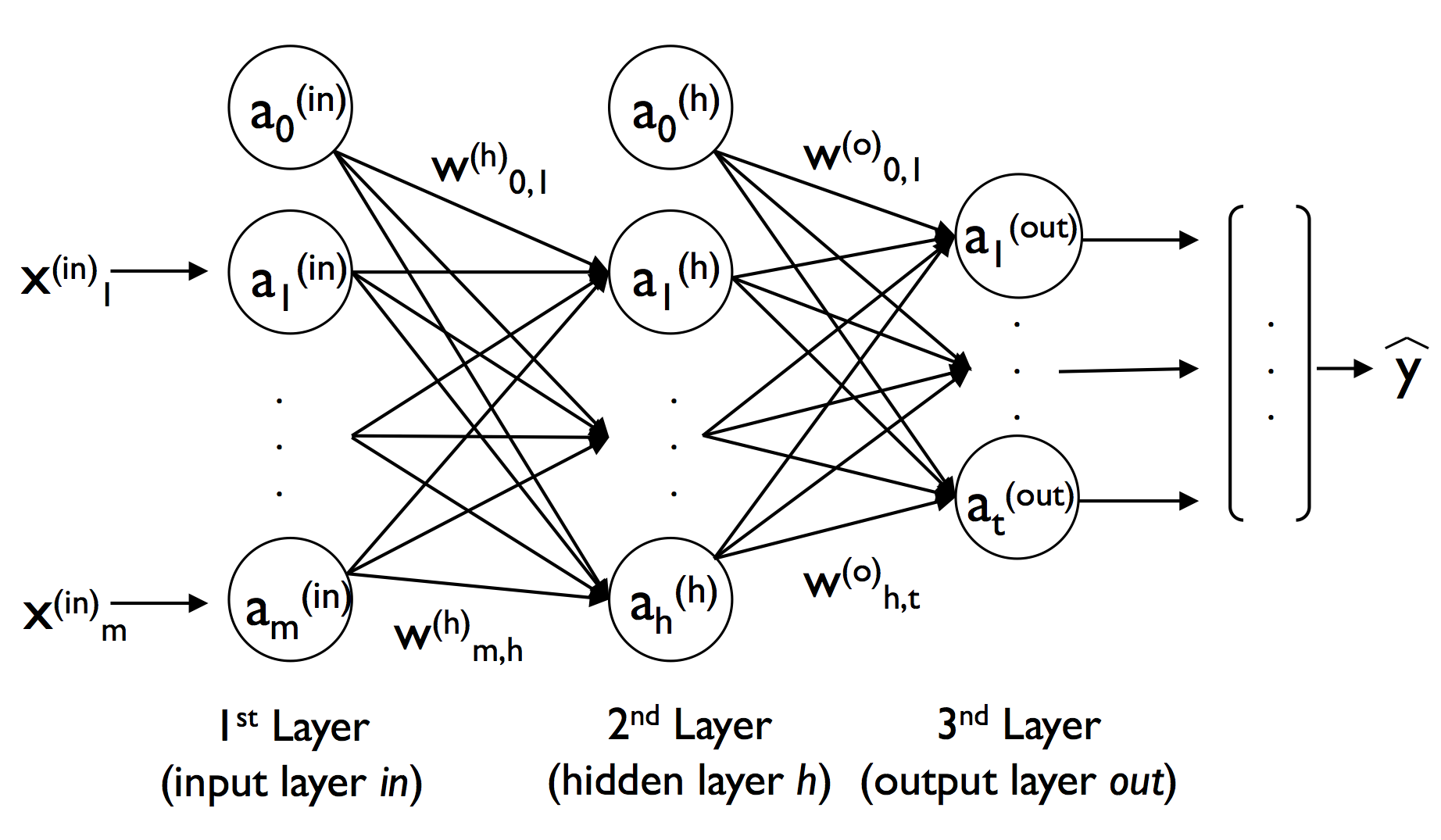
A.變數說明
關于BP神經網路的正向傳播,我們以上圖為例對變數進行一下說明:
- x i ( i n ) , a i ( i n ) x^{(in)}_i ,a^{(in)}_i xi(in)?,ai(in)? : 二者均表示輸入層的第 i i i個輸入單元(這樣做是為了和后面的進行統一,二者相等的原因是輸入層的神經元不起激活作用);
- w m , h ( h ) w^{(h)}_{m,h} wm,h(h)? :輸入層的第 m m m個單元與隱藏層的的第 h h h個單元之間的權重(??權重的標識很重要,而且不同的參考書用的也不同,讀者一定要弄清楚)
- z i ( h ) z^{(h)}_i zi(h)? : 隱藏層的第 i i i的凈輸入單元, z i ( h ) = w 1 , i ( h ) a 1 ( i n ) + . . . + w m , i ( h ) a m ( i n ) z^{(h)}_i =w^{(h)}_{1,i}a^{(in)}_1+ ...+w^{(h)}_{m,i}a^{(in)}_m zi(h)?=w1,i(h)?a1(in)?+...+wm,i(h)?am(in)?;
- a i ( h ) a^{(h)}_i ai(h)? : 隱藏層的第 i i i的隱藏單元, a i ( h ) = ? ( z i ( h ) ) a^{(h)}_i = \phi (z^{(h)}_i) ai(h)?=?(zi(h)?);
- w h , t ( o ) w^{(o)}_{h,t} wh,t(o)? :隱藏層的第 h h h個單元與輸出層的的第 t t t個單元之間的權重(??權重的標識很重要,而且不同的參考書用的也不同,讀者一定要弄清楚)
- z i ( o u t ) z^{(out)}_i zi(out)? : 輸出層的第 i i i的凈輸入單元, z i ( o u t ) = w 1 , i ( o u t ) a 1 ( h ) + . . . + w h , i ( o u t ) a h ( h ) z^{(out)}_i =w^{(out)}_{1,i}a^{(h)}_1+ ...+w^{(out)}_{h,i}a^{(h)}_h zi(out)?=w1,i(out)?a1(h)?+...+wh,i(out)?ah(h)?;
- a i ( o u t ) a^{(out)}_i ai(out)? : 輸出層的第 i i i的輸出單元, a i ( o u t ) = ? ( z i ( o u t ) ) a^{(out)}_i = \phi (z^{(out)}_i) ai(out)?=?(zi(out)?);
- y [ i ] , a [ i ] y^{[i]},a^{[i]} y[i],a[i]: 分別代表一組資料的實際結果中的第 i i i個(上角標視為索引),經過神經網路輸出的第 i i i個;
- 關于激活函式,我們采用 sigmoid 函式 ? ( x ) = 1 1 + e ? x \phi (x) = \cfrac{1}{1 + e^{-x}} ?(x)=1+e?x1? ;
B.正向傳播
熟悉完上面的量的意義之后,我們通過線性代數的知識匯出BP神經網路的正向傳播程序:
首先,輸入層的各個單元 A ( i n ) \bm A^{(in)} A(in)(不妨設階數為:n*m )和通過指向隱藏層的權重矩陣 W ( h ) \bm W^{(h)} W(h)(階數:m * h)做點乘,得到隱藏層的凈輸入向量: Z ( h ) \bm Z^{(h)} Z(h)(階數: n * h);
其次,將隱藏層的凈輸入向量進行激活,得到 A ( h ) \bm A^{(h)} A(h), A ( h ) = ? ( Z ( h ) ) \bm A^{(h)} = \phi(\bm Z^{(h)}) A(h)=?(Z(h))(階數:n * h);
再其次: a ( h ) \bm a^{(h)} a(h)通過指向輸出層的權重矩陣 W ( o u t ) \bm W^{(out)} W(out)(階數:h * t),得到輸出層的凈輸入向量: Z ( o u t ) \bm Z^{(out)} Z(out)(n * t);
最后,將輸出層的凈輸入向量進行激活,得到得到 A ( o u t ) \bm A^{(out)} A(out), A ( o u t ) = ? ( Z ( o u t ) \bm A^{(out)} = \phi(\bm Z^{(out}) A(out)=?(Z(out)(階數:n * t),即我們的輸出結果,
這其中涉及的矩陣運算羅列如下:
- Z ( h ) = A ( i n ) W ( h ) \bm Z^{(h)} = \bm A^{(in)}\bm W^{(h)} Z(h)=A(in)W(h);
- Z ( o u t ) = A ( h ) W ( o u t ) \bm Z^{(out)} = \bm A^{(h)}\bm W^{(out)} Z(out)=A(h)W(out);
BP神經網路的正向傳播程序相對比較簡單,弄清楚需要對上面變數的標識熟練掌控以及要有線性代數的基礎,另外上面👆的表述并沒牽扯到偏置單元,下面我們介紹下偏置單元的內容
C.偏置單元
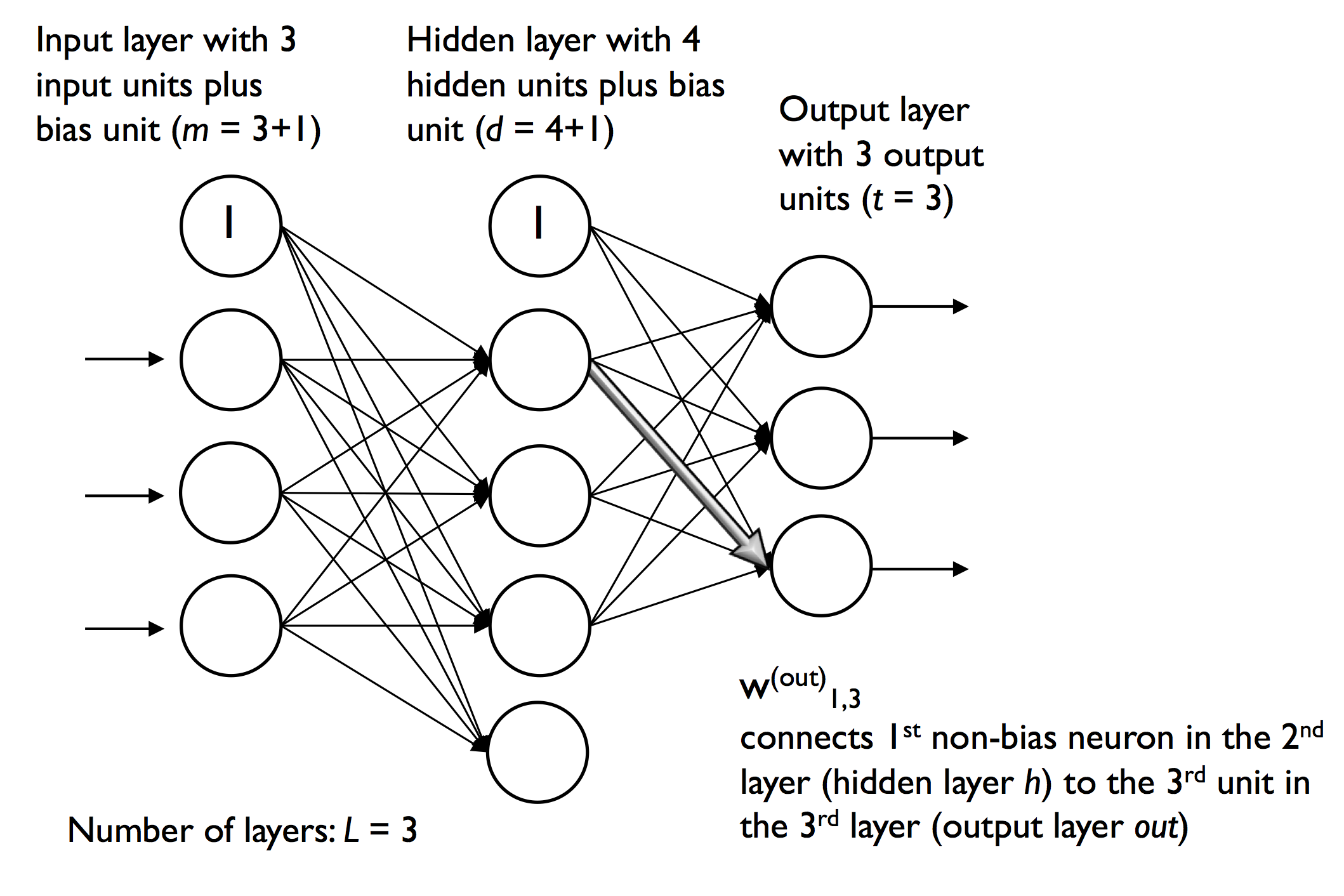
關于偏置單元的設定,通常輸入層的激發單元(神經元)組成的是輸入單元和偏置單元,隱藏層的激發單元(神經元)組成的是隱藏單元和偏置單元,但是為方便起見,將偏置單元更改為單獨的偏置向量,單獨的偏置向量的設定和之前的以權重變數作為偏置(也就是偏置單元設定為1)的操作二者相同,只是形式不同,
采用這樣形式的優點:
- 代碼更加高效并且便于閱讀,權重矩陣的維度可完全用層與層之間的神經元個數表示,而無偏置單元的參與;
- 這樣的操作也在常用的深度學習庫中被采用;
如上圖所示:輸入層(Input layer)中共有3+1個輸入單元,1個為偏置單元,隱藏層(Hidden layer)中共有4 + 1個隱藏單元,1個為偏置單元,采用偏置單元更改為單獨的偏置向量的形式,尚若我們有100組資料,一組資料對應3個特征值,那么我們就只需考慮輸入層(Input layer)和隱藏層(Hidden layer)之間的權重矩陣為: 一個 3 * 4的權重矩陣 + 一個 1 * 4 的偏置向量;
可能讀者有疑問🤔?兩個向量個維度不相同,那么計算不會報錯嗎?不會,因為numpy具有廣博機制,一個權重矩陣的列數和第二個單元的行數相同,就會采用廣播機制,見下面👇代碼示例,
print(np.array([[1,2],[1,2]]),'\n')
print(np.array([3,2]),'\n')
print(np.array([[1,2],[1,2]])+np.array([3,2]),'\n')
#s輸出結果如下,可見計算正常進行
[[1 2]
[1 2]]
[3 2]
[[4 4]
[4 4]]
第二步:誤差逆向傳播
1.損失函式
我們通過第一步進行了BP神經網路的正向傳播,得到輸出結果向量,輸出結果向量和實際的向量之間存在差異,如何用數學的形式進行表示?這就需要損失函式的發揮作用,為簡單起見,我們首先從1組輸入資料(階數:1 * m)入手再過渡到多組資料(階數:n * m)的形式,由易到難,
損失函式的一般形式(線性回歸形式):
J
(
W
)
=
1
2
∥
a
o
u
t
?
y
∥
2
2
=
1
2
∑
i
=
1
m
(
y
[
i
]
?
a
[
i
]
)
2
J(\bm W)= \bf\tfrac{1}{2}{\lVert a^{out}-y \rVert ^{2}_{2}= \tfrac{1}{2}\displaystyle\sum_{i=1}^m(y^{[i]}-a^{[i]})^2}
J(W)=21?∥aout?y∥22?=21?i=1∑m?(y[i]?a[i])2
損失函式的一般形式(邏輯回歸形式):
J
(
W
)
=
1
2
∥
a
o
u
t
?
y
∥
2
2
=
?
∑
i
=
1
m
[
y
[
i
]
l
o
g
(
a
[
i
]
+
(
1
?
y
[
i
]
)
l
o
g
(
1
?
a
[
i
]
)
]
J(\bm W)= \bf\tfrac{1}{2}{\lVert a^{out - y} \rVert ^{2}_{2}} = -\displaystyle\sum_{i=1}^m[y^{[i]}log(a^{[i]}+(1-y^{[i]})log(1-a^{[i]})]
J(W)=21?∥aout?y∥22?=?i=1∑m?[y[i]log(a[i]+(1?y[i])log(1?a[i])]
注: y [ i ] , z [ i ] y^{[i]},z^{[i]} y[i],z[i]: 分別代表一組資料的實際結果中的第 i i i個(上角標視為索引),經過神經網路輸出的第 i i i個(上角標視為索引);
可以看到損失函式是 a o u t a^{out} aout的函式,而 a o u t a^{out} aout又是通過已知的輸入變數(固定)通過層與層之間的權重矩陣得到,所以損失函式是整個神經網路的權重矩陣的函式,此時我們明確了損失函式的自變數是權重,按照梯度下降的思想,要想損失函式最小化,就要找到損失函式關于各個權重的梯度(偏導數),然后在其相反的方向上進行變化,
2.哈達瑪積(Hadamard product)
為了更好的表達誤差,我們采用一種運算方式,可以讓我們的結果更加簡潔:哈達瑪積
這種運算方式定義如下:
[
a
b
]
⊙
[
c
d
]
=
[
a
c
b
d
]
\begin{bmatrix} a \\ b \end{bmatrix}\odot\begin{bmatrix} c \\ d \end{bmatrix} = \begin{bmatrix} ac \\ bd \end{bmatrix}
[ab?]⊙[cd?]=[acbd?]
即:
[
1
3
]
⊙
[
2
4
]
=
[
2
12
]
\begin{bmatrix} 1 \\ 3 \end{bmatrix}\odot\begin{bmatrix} 2 \\ 4 \end{bmatrix} = \begin{bmatrix} 2 \\ 12 \end{bmatrix}
[13?]⊙[24?]=[212?]
哈達瑪乘積如何由numpy實作?
np.array([1,2,3]) * np.array([1,2,3])
#輸出結果為:
array([1, 4, 9])
#所以,在numpy中,實作哈達瑪乘積只需將兩個大小相同的向量直接相乘
3.理解誤差逆向傳播
上面👆我們介紹了損失函式和一種運算方式,我們提到想要通過計算損失函式關于權重的梯度也就是偏導數來實作梯度下降,那么我們該如何下手?也就是如何得到以下二式?
? J ( W ) ? w m , h ( h ) \dfrac{\partial{J(\bm W)}}{\partial{w^{(h)}_{m,h}}} ?wm,h(h)??J(W)?
? J ( W ) ? w h , t ( o u t ) \dfrac{\partial{J(\bm W)}}{\partial{w^{(out)}_{h,t}}} ?wh,t(out)??J(W)?
上面我們提到損失函式是 a o u t a^{out} aout的函式, a o u t a^{out} aout是權重變數的函式,通過最開始神經網路的描述,我們直觀的感覺這里面層層環繞,一層接著一層,直接獲得上面兩個式子看來不太容易,我們不妨一層層一層看,離我們損失函式最近(也就是直接影響損失函式)的是 a i o u t a^{out}_i aiout?,其次是 z i ( o u t ) z^{(out)}_i zi(out)?(輸出層的凈輸入單元,尚未激活),最后才是權重 w h , t ( o u t ) w^{(out)}_{h,t} wh,t(out)?,考慮到這種關系,我們不妨先求損失函式關于 z i ( o u t ) z^{(out)}_i zi(out)?偏導數,然后再求解關于其 w h , t ( o u t ) w^{(out)}_{h,t} wh,t(out)?的偏導數,
這里的計算本質上是鏈式求導法則,計算機代數中自動微分(Automatic Differentiation)可以很好的解決這樣的問題,但是我們作為初學者,要用代碼一行一行的將其表示出來,
基于上面的分析,我們從輸出層考慮:
δ
i
o
u
t
=
?
J
(
W
)
?
a
i
(
o
u
t
)
?
a
i
(
o
u
t
)
?
z
i
(
o
u
t
)
\delta^{out}_i = \dfrac{\partial{J(\bm W)}}{\partial{a^{(out)}_{i}}}\dfrac{\partial{a^{(out)}_{i}}}{\partial{z^{(out)}_{i}}}
δiout?=?ai(out)??J(W)??zi(out)??ai(out)??
這其中
δ
i
o
u
t
\delta^{out}_i
δiout?稱為誤差項,而
a
i
(
o
u
t
)
=
?
(
z
i
(
o
u
t
)
)
a^{(out)}_{i} = \phi (z^{(out)}_i)
ai(out)?=?(zi(out)?),所以:
?
a
i
(
o
u
t
)
?
z
i
(
o
u
t
)
=
?
′
(
z
i
(
o
u
t
)
)
\dfrac{\partial{a^{(out)}_{i}}}{\partial{z^{(out)}_{i}}}=\phi^{'} (z^{(out)}_i)
?zi(out)??ai(out)??=?′(zi(out)?)
即:
δ
i
o
u
t
=
?
J
(
W
)
?
a
i
(
o
u
t
)
?
′
(
z
i
(
o
u
t
)
)
\delta^{out}_i=\dfrac{\partial{J(\bm W)}}{\partial{a^{(out)}_{i}}}\phi^{'} (z^{(out)}_i)
δiout?=?ai(out)??J(W)??′(zi(out)?)
利用哈達瑪積并且寫成向量的形式更加簡潔:
δ
o
u
t
=
?
J
(
W
)
?
a
(
o
u
t
)
⊙
?
′
(
Z
(
o
u
t
)
)
\bm\delta^{out} = \dfrac{\partial{J(\bm W)}}{\partial{\bm a^{(out)}}}\odot\bm\phi^{'} (\bm{Z^{(out)}})
δout=?a(out)?J(W)?⊙?′(Z(out))
又因為我們知道損失函式關于
a
(
o
u
t
)
\bm a^{(out)}
a(out)的函式運算式,求偏導可得
?
J
(
W
)
?
a
(
o
u
t
)
=
a
o
u
t
?
y
\dfrac{\partial{J(\bm W)}}{\partial{\bm a^{(out)}}}= \bm{a^{out}-y}
?a(out)?J(W)?=aout?y
所以:
δ
o
u
t
=
(
a
o
u
t
?
y
)
⊙
?
′
(
Z
(
o
u
t
)
)
\bm\delta^{out} = (\bm{a^{out}-y})\odot\bm\phi^{'} (\bm{Z^{(out)}})
δout=(aout?y)⊙?′(Z(out))
至此,我們得到 δ o u t \bm\delta^{out} δout也就是損失函式關于 z ( o u t ) \bm z^{(out)} z(out)的偏導數,但是我們最終的目的是其關于權重的偏導數,考慮到 Z ( o u t ) \bm Z^{(out)} Z(out) = A h W o u t \bm{A^{h}W^{out}} AhWout,所以:
? J ( W ) ? W ( o u t ) = ( A h ) T δ o u t = ( A h ) T ( a o u t ? y ) ⊙ ? ′ ( Z ( o u t ) ) \dfrac{\partial{J(\bm W)}}{\partial{\bm{W^{(out)}}}} = \bm{(A^{h}) ^T}\bm\delta^{out}=\bm{(A^{h})^T}(\bm{a^{out}-y})\odot\bm\phi^{'} (\bm{Z^{(out)}}) ?W(out)?J(W)?=(Ah)Tδout=(Ah)T(aout?y)⊙?′(Z(out))
這里我們可以類比求偏導的方式求 Z ( o u t ) \bm Z^{(out)} Z(out) 對 W o u t W^{out} Wout的偏導數,按理說應該是 A h \bm A^h Ah,那為啥是 ( A h ) T \bm{(A^h)^T} (Ah)T😯?思考一下🤔,如果糾一下細節,確實是 ( A h ) T \bm{(A^h)^T} (Ah)T!這是因為矩陣的乘法所導致: Z ( o u t ) \bm Z^{(out)} Z(out) = A h W o u t \bm{A^{h}W^{out}} AhWout,我們可以舉個具體的例子:影響 W o u t \bm W^{out} Wout第一行第二個的元素其實是 A h \bm A^{h} Ah中的第二行第一個元素,也就是 A ( m , n ) \bm A(m,n) A(m,n)----> W ( n , m ) \bm W(n,m) W(n,m),所以 A \bm A A矩陣要轉置(這里不理解也無所謂,可以選擇記住或者跳過😄),
下面我們談談如何求 ? J ( W ) ? w m , h ( h ) \dfrac{\partial{J(\bm W)}}{\partial{w^{(h)}_{m,h}}} ?wm,h(h)??J(W)?(建議先把上面關于 ? J ( W ) ? w h , t ( o u t ) \dfrac{\partial{J(\bm W)}}{\partial{w^{(out)}_{h,t}}} ?wh,t(out)??J(W)?弄清楚一些):
我們上面成功的推匯出來了 ? J ( W ) ? w m , h ( h ) \dfrac{\partial{J(\bm W)}}{\partial{w^{(h)}_{m,h}}} ?wm,h(h)??J(W)?,并且用我們定義了一個叫做誤差項的量,我們演算法的名稱叫做誤差逆向傳播演算法,故名思義,就是將誤差進行逆向傳播,既然我們已經成功的計算出來了 δ o u t \bm\delta^{out} δout,那么我們可不可以通過 δ o u t \bm\delta^{out} δout計算 δ h \bm\delta^{h} δh,然后按照同樣的步驟計算 ? J ( W ) ? w h , t ( o u t ) \dfrac{\partial{J(\bm W)}}{\partial{w^{(out)}_{h,t}}} ?wh,t(out)??J(W)??答案是🉑?,下面我們具體推導說明,
我們已經求得:
δ
i
o
u
t
=
?
J
(
W
)
?
z
i
(
o
u
t
)
=
?
J
(
W
)
?
a
i
(
o
u
t
)
?
′
(
z
i
(
o
u
t
)
)
\delta^{out}_i=\colorbox{aqua}{$\dfrac{\partial{J(\bm W)}}{\partial{z^{(out)}_{i}}}$}=\dfrac{\partial{J(\bm W)}}{\partial{a^{(out)}_{i}}}\phi^{'} (z^{(out)}_i)
δiout?=?zi(out)??J(W)??=?ai(out)??J(W)??′(zi(out)?)
目標是(為一般起見我們用i,j進行區分):
δ
j
h
=
?
J
(
W
)
?
z
j
(
h
)
\delta^{h}_j = \dfrac{\partial{J(\bm W)}}{\partial{z^{(h)}_{j}}}
δjh?=?zj(h)??J(W)?
如果將目標與已求聯系,在求偏導程序中引入
z
i
(
o
u
t
)
z^{(out)}_i
zi(out)?(已用藍色框標明):
δ
j
h
=
?
J
(
W
)
?
z
i
(
o
u
t
)
?
z
i
(
o
u
t
)
?
z
j
(
h
)
=
δ
i
o
u
t
?
z
i
(
o
u
t
)
?
z
j
(
h
)
\delta^{h}_j = \colorbox{aqua}{$\dfrac{\partial{J(\bm W)}}{\partial{z^{(out)}_{i}}}$} \dfrac{\partial z^{(out)}_i}{\partial{z^{(h)}_j}}=\delta^{out}_i\colorbox{yellow}{$\dfrac{\partial z^{(out)}_i}{\partial{z^{(h)}_j}}$}
δjh?=?zi(out)??J(W)???zj(h)??zi(out)??=δiout??zj(h)??zi(out)???
δ
i
o
u
t
\delta^{out}_i
δiout?為已知項,現在則需要求:
?
z
i
(
o
u
t
)
?
z
j
(
h
)
\colorbox{yellow}{$\dfrac{\partial z^{(out)}_i}{\partial{z^{(h)}_j}}$}
?zj(h)??zi(out)???
那 z i ( o u t ) z^{(out)}_i zi(out)?又與 z i ( h ) z^{(h)}_i zi(h)?有什么關系🤔??
回答這個問題并不難,但是需要你對正向傳播激活神經網路有充分的了解, z i ( h ) z^{(h)}_i zi(h)?通過激活函式得到 a i ( h ) a^{(h)}_i ai(h)?,而 a i ( h ) a^{(h)}_i ai(h)?又通過和權重的結合得到 z i ( o u t ) z^{(out)}_i zi(out)?(可以回頭看看第一步:正向傳播),
所以:
?
z
i
(
o
u
t
)
?
z
j
(
h
)
=
?
z
i
(
o
u
t
)
?
a
j
(
h
)
?
a
j
(
h
)
?
z
j
(
h
)
=
w
j
,
i
(
o
u
t
)
?
′
(
z
j
(
h
)
)
\colorbox{yellow}{$\dfrac{\partial z^{(out)}_i}{\partial{z^{(h)}_j}}=\dfrac{\partial z^{(out)}_i}{\partial{a^{(h)}_j}}\dfrac{\partial a^{(h)}_j}{\partial{z^{(h)}_j}}=w^{(out)}_{j,i}\phi^{'}(z^{(h)}_j$)}
?zj(h)??zi(out)??=?aj(h)??zi(out)???zj(h)??aj(h)??=wj,i(out)??′(zj(h)?)?
整理以上式子有:
δ
j
h
=
δ
j
o
u
t
w
j
,
i
(
o
u
t
)
?
′
(
z
j
(
h
)
)
\delta^{h}_j =\delta^{out}_j w^{(out)}_{j,i}\phi^{'}(z^{(h)}_j)
δjh?=δjout?wj,i(out)??′(zj(h)?)
用向量以及哈達瑪運算子的形式表達:
δ
h
=
δ
o
u
t
(
w
(
o
u
t
)
)
T
⊙
?
′
(
z
(
h
)
)
\bm{\delta^{h} =\delta^{out} (w^{(out)})^T\odot\phi^{'}(z^{(h)})}
δh=δout(w(out))T⊙?′(z(h))
至此,我們得到
δ
h
\bm\delta^{h}
δh也就是損失函式關于
z
(
h
)
\bm z^{(h)}
z(h)的偏導數,但是我們最終的目的是其關于權重的偏導數,考慮到
Z
(
h
)
\bm Z^{(h)}
Z(h) =
A
o
u
t
W
h
\bm{A^{out}W^{h}}
AoutWh,所以:
? J ( W ) ? W ( h ) = ( A i n ) T δ h \dfrac{\partial{J(\bm W)}}{\partial{\bm{W^{(h)}}}} = \bm{(A^{in}) ^T}\bm\delta^{h} ?W(h)?J(W)?=(Ain)Tδh
得到這個結果的方式和我們算 ? J ( W ) ? W ( o u t ) \dfrac{\partial{J(\bm W)}}{\partial{\bm{W^{(out)}}}} ?W(out)?J(W)?相同,可以翻上去回看,
4.關于偏置項的梯度
上面我們已經推匯出損失函式關于層與層之間權重的偏導數,但是不要忘記了偏置向量的作用,我們在一開始介紹到:在實際操作中偏置單元更改為單獨的偏置向量,那么損失函式關于偏執向量的梯度如何求解?
我先把結果寫下:
?
J
(
W
)
?
b
(
o
u
t
)
=
δ
o
u
t
\dfrac{\partial{J(\bm W)}}{\partial{\bm{b^{(out)}}}} = \bm\delta^{out}
?b(out)?J(W)?=δout
?
J
(
W
)
?
b
(
h
)
=
δ
h
\dfrac{\partial{J(\bm W)}}{\partial{\bm{b^{(h)}}}} = \bm\delta^{h}
?b(h)?J(W)?=δh
即:
?
J
(
W
)
?
b
=
δ
\dfrac{\partial{J(\bm W)}}{\partial{\bm{b}}} = \bm\delta
?b?J(W)?=δ
可以看到損失函式關于偏置向量的偏導數是其所在層的誤差向量,這里我做一下簡單的說明(其實大家可以當作練習自己推導一番,和上面的推導類似并且要簡單,檢驗下自己是否學會)
我們從就從輸出層下手進行推導,我們已知:
δ i o u t = ? J ( W ) ? a i ( o u t ) ? a i ( o u t ) ? z i ( o u t ) \delta^{out}_i = \dfrac{\partial{J(\bm W)}}{\partial{a^{(out)}_{i}}}\dfrac{\partial{a^{(out)}_{i}}}{\partial{z^{(out)}_{i}}} δiout?=?ai(out)??J(W)??zi(out)??ai(out)??
又
z
i
(
o
u
t
)
z^{(out)}_{i}
zi(out)?又取決于
b
i
(
o
u
t
)
b^{(out)}_{i}
bi(out)?,所以再次在上面的式子中設法添加
b
i
(
o
u
t
)
b^{(out)}_{i}
bi(out)?項:
?
J
(
W
)
?
b
i
(
o
u
t
)
=
?
J
(
W
)
?
a
i
(
o
u
t
)
?
a
i
(
o
u
t
)
?
z
i
(
o
u
t
)
?
z
i
(
o
u
t
)
?
b
i
(
o
u
t
)
=
δ
i
o
u
t
?
z
i
(
o
u
t
)
?
b
i
(
o
u
t
)
\dfrac{\partial{J(\bm W)}}{\partial{b^{(out)}_{i}}}=\dfrac{\partial{J(\bm W)}}{\partial{a^{(out)}_{i}}}\dfrac{\partial{a^{(out)}_{i}}}{\partial{z^{(out)}_{i}}}\dfrac{\partial{z^{(out)}_i}}{\partial{b^{(out)}_{i}}}=\delta^{out}_i \dfrac{\partial{z^{(out)}_i}}{\partial{b^{(out)}_{i}}}
?bi(out)??J(W)?=?ai(out)??J(W)??zi(out)??ai(out)???bi(out)??zi(out)??=δiout??bi(out)??zi(out)??
而
?
z
i
(
o
u
t
)
?
b
i
(
o
u
t
)
=
1
\dfrac{\partial{z^{(out)}_i}}{\partial{b^{(out)}_{i}}}=1
?bi(out)??zi(out)??=1,所以:
?
J
(
W
)
?
b
i
(
o
u
t
)
=
δ
i
o
u
t
\dfrac{\partial{J(\bm W)}}{\partial{b^{(out)}_{i}}}=\delta^{out}_i
?bi(out)??J(W)?=δiout?
于是得證,至于其他的層可以類比得到最終結果:
? J ( W ) ? b = δ \dfrac{\partial{J(\bm W)}}{\partial{\bm{b}}} = \bm\delta ?b?J(W)?=δ
5.誤差逆向傳播公式總結
? J ( W ) ? W ( o u t ) = ( A h ) T δ o u t \dfrac{\partial{J(\bm W)}}{\partial{\bm{W^{(out)}}}} = \bm{(A^{h}) ^T}\bm\delta^{out} ?W(out)?J(W)?=(Ah)Tδout
? J ( W ) ? W ( h ) = ( A i n ) T δ h \dfrac{\partial{J(\bm W)}}{\partial{\bm{W^{(h)}}}} = \bm{(A^{in}) ^T}\bm\delta^{h} ?W(h)?J(W)?=(Ain)Tδh
? J ( W ) ? b = δ \dfrac{\partial{J(\bm W)}}{\partial{\bm{b}}} = \bm\delta ?b?J(W)?=δ
至此我們已經把誤差逆向傳播演算法所需的公式推導并且總結完畢,充分理解好這些公式將有助于對這個演算法的認識,其實,我們回過頭來看,這里面用的最最核心的就是鏈式求導法則,所以我覺得要真正的弄明白這個演算法:首先要對整個神經網路的傳播程序以及各個符號有充分的認識并掌握熟練,其次要會利用鏈式求導法則進行梯度的求解,最后就是用代碼實作
5.梯度檢測
代碼如下(示例):
未完待續!
6.初始化的重要性
代碼如下(示例):
未完待續!
7.代碼實作
具體代碼請參考:我的另一篇文章(包含代碼注釋)
總結
以上是我在學習BP神經網路的個人理解,上面的推導數學形式偏多,所以本文章適合數學基礎相對較好的而且強烈想弄清楚BP演算法的一些公式由來的人參考,另外勺ò干能有錯誤,還望各位多多包含,希望找到的朋友可以在評論區留言告訴我好讓我及時更改🙏🙏🙏,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/289460.html
標籤:AI
上一篇:IDEA常用插件推薦